







目录
1. 进程创建
1.1 pro目录(process)与工作目录
- 在操作系统中,正在运行的可执行程序其会在
/proc的系统目录下生成一个以其PID为名的目录,此目录中中有着各种各样这个可执行程序的相关信息。- proc目录下的进程目录,随着进程的开始运行产生,进程的运行结束删除。
- 进程目录中有着需要关键信息,比如进程的可执行文件
exe在操作系统中的存储路径,进程当前的工作目录cwd。
//可查看进程号持续运行的程序
#include <stdio.h>
//getpid所在头文件
#include <sys/types.h>
//sleep所在头文件
#include <unistd.h>
int main()
{
while(1)
{
printf("process pid is %d\n", getpid());
//休眠一秒
sleep(1);
}
return 0;
}
- 执行上述代码的可执行程序时,我们根据得到的PID进程标识在操作系统
/proc目录下搜索查看相应目录,指令:ll -d /proc/[进程号]
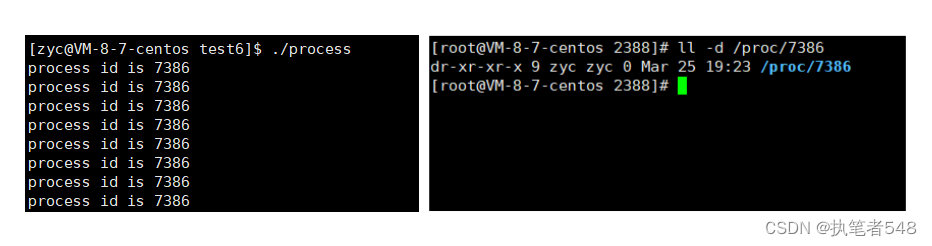
- 当我们进入此进程目录中,可以发现两个高亮显示的信息:
<1>exe:当前进程的执行程序在操作系统中的存储路径
<2>cwd:当前进程的工作目录

- 在C语言中,我们学习过文件操作相关的函数,
fopen函数在打开文件时,需要指定文件所在的路径,与打开文件的模式。
<1> 当文件不存在时,此函数则会在相应路径下创建一个指定名称的文件。
<2> 当我们未给出绝对路径仅仅给出文件名时,fopen函数则会在当前的工作目录下搜寻与创建该文件。
<3> 当前工作目录(current working directory)默认为当前进程所在目录,不过,我们也可以同函数chdir来更改工作目录。
#include <sys/types.h>
int main()
{
//更改工作目录
chdir("/home/zyc");
//文件指针,打开文件
FILE* fp = fopen("file.txt", "w");
//关闭文件
fclose(fp);
return 0;
}
- 补充: 执行上述代码后,文件并没有在当前程序所在目录创建,而是在更改后的工作目录下
1.2 进程创建
- 通过前面的学习,我们已经大概了解了一些进程相关的知识,关于进程的创建我们是通过编写代码生成可执行程序,而后运行可执行程序最终得到一个进程。
- 除了上述的方法外,我们还有其他能够主动创建进程方式吗,接下来我们来学习一个新的C语言库函数
fork,一个专门用来创建子进程的函数。通过对fork函数的学习再对进程创建做进一步的学习。
pid_t fork();
- 在C程序中,我们调用fork函数后,它会建立一个此进程的子进程,并返回创建后的进程号,程序从这一行开始分流产生分支。
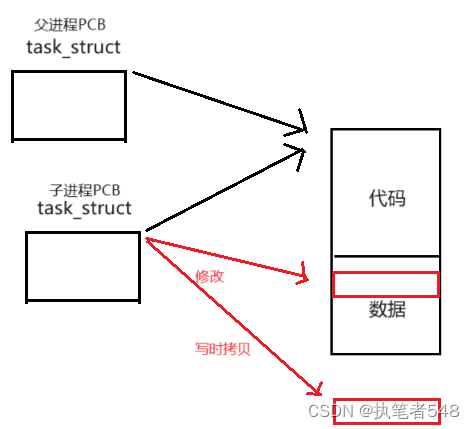
- 在前面的学习中,我们知道进程由内核数据结构(PCB)与代码数据组成的。
<1> 通过fork创建的子进程其只会新建一个PCB,且此PCB是以其父进程为模板的,其继承了伏见城的大部分属性,除开pid与ppid外,大部分信息都相同。
<2> 父进程会与创建出的子进程共享代码,子进程不会额外在创建一份自己的代码。
<3> 当代码出现对数据的修改等操作时,子进程才会再进行专门调用值写时拷贝。
int main()
{
//创建一个当前进程的子进程
fork();
//同一份代码,两个进程各执行一次
printf("this is a process\n");
return 0;
}
- fork的返回值
<1> 父进程中,fork会返回子进程的pid
<2> 子进程中,fork会返回0
<3> 创建进程失败,返回-1- 父子进程中fork返回值不同的意义:父进程可能会拥有多个子进程,所以要依靠创建进程的pid来确认指定的子进程,而每个子进程只会有一个父进程(父进程具有唯一性)
- 父子进程共用代码又执行不同代码的方式:通过fork返回值的不同,使用
if...else...分支语句对进程进行分流,使其执行不同的代码块
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
pid id = fork();
if(id < 0)
{
return 1;
}
else if(id == 0)
{
//子进程执行代码
//...
}
else
{
//父进程执行代码
//...
}
return 0;
}
- 同名id变量为什么存储的值不同:
<1> fork函数执行到return返回时,其就已经开始了对父子进程进行了分支,父子进程分别返回不同的返回值。
<2> 代码在完成编译后,变量就被替换为对应存储数据的地址,变量名就不存在了。
1.3 进程销毁
- 进程的生命周期从被执行开始,执行完毕结束,那么,除开进程生命周期自动销毁外,还有其他销毁进程的方式吗?
- 指令:
kill -9 [进程PID]
指令意义:主动杀死一个正在被执行的进程
#include <stdlib.h>
//包含exit的头文件
int main()
{
//创建多个子进程
for(int i = 0; i < 10; i++)
{
pid_t id = fork();
if(id)
{
printf("创建一个子进程,其PID为%d\n", id);
}
else
{
//退出子进程
exit(0);
}
}
return 0;
}
- 进程之间时相互独立的,即使销毁了创建子进程的父进程也不会导致子进程无法运行,一个进程的崩溃不会影响另一个进程。
2. 进程状态
2.1 进程排队
- 进程在内存上并不是一直被运行的,内存上也不止有一个进程,进程会以时间片(1ms)为单位被执行。
- 内存上的进程是进行排队,而后按照排队顺序等待被CPU执行的。进程排队并非是进程整个进程进行排队,而是每个进程的PCB进行排队。
- 每个进程的task_struct中都有结点指针类型的成员,在进程排队时,这些指针会按照一定顺序指向链接。以这样的方式维护进程队列,进程排队的操作就变为了链表的增删改查操作。
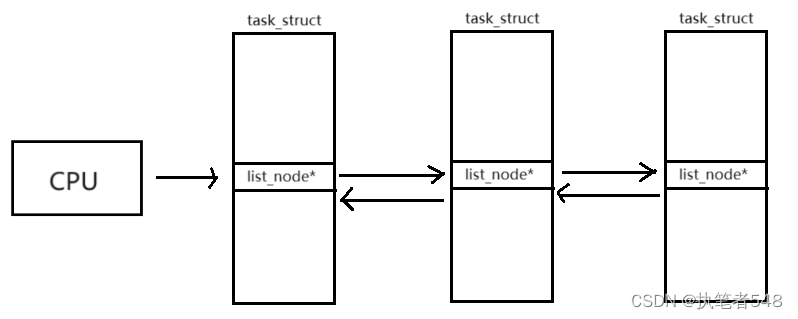
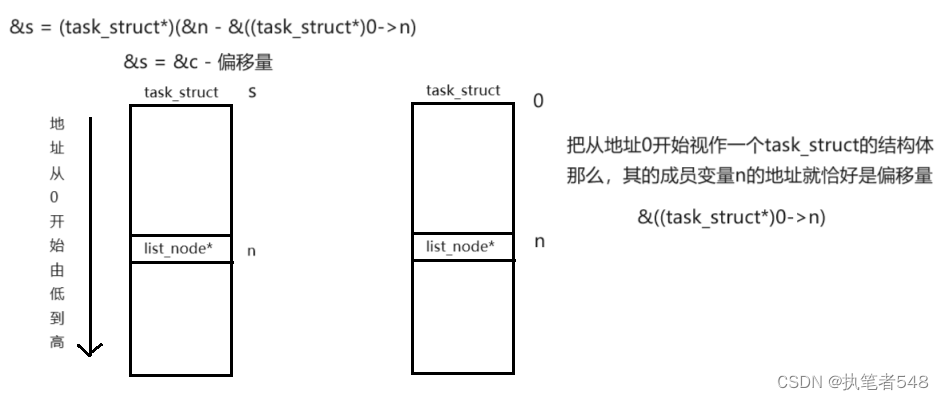
- 进程队列进行排队的参考指针知识task_struct的一部分,这样嵌入定义的方式使得task_struct可以被链入到多种数据结构中。
- 根据队列指针获得进程各种PCB属性的方式:队列指针 - 偏移量
2.2 操作系统的进程状态:运行,阻塞,挂起
- 在task_struct结构中,标识进程状态的方式为使用宏定义方式,赋予状态标识整形变量不同的值。
- 进程的不同状态决定了进程的后续动作。
- 我们知道进程会以进程队列的方式排列等待CPU的执行,而每一个CPU只有一个运行队列。
1. 运行状态
- 进程处于运行状态(R),那么代表其已经做好了被执行的准备,且现处于运行队列上。
2. 阻塞状态
- 当进程执行到需要调度其他软硬件资源时,并且恰好其所需的硬件资源等未做好准备,此时就会将当前进程从运行队列中迁移走。
#include <stdio.h>
//执行中需要从键盘设备处获取数据
int main()
{
int i = 0;
scanf("%d", &i);
printf("%d\n", i);
return 0;
}
- 在之前的学习中我们了解到,操作系统是计算机软硬件资源的管理者,而其采用的管理方式为信息管理。想要进行信息上的管理就要对各种软件硬件做描述,之后再将这些信息组织起来,做好这些准备后才能够进行相应的管理操作。
- CPU属于计算机的硬件设备之一,CPU有属于自己的运行队列,而其他的硬件设备也有。当进程需要从相应指定的硬件设备处获取资源时,也要进行排队。
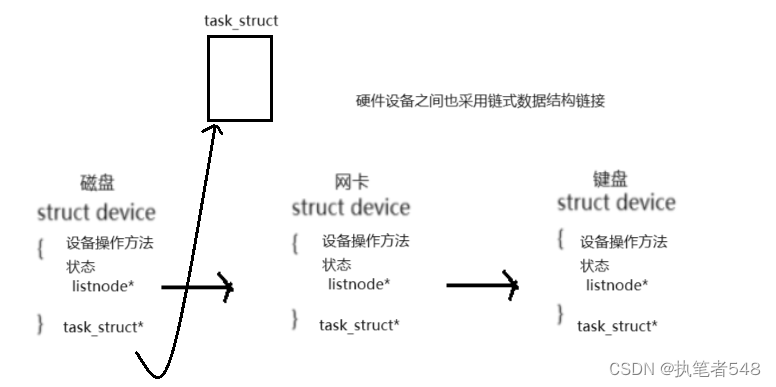
- 阻塞状态:进程因为欠缺相应的软硬件资源信息从CPU的运行队列变迁到不同的队列中去。此时,其状态也就进行了变迁,如上情况就被称为进程的阻塞状态。
3. 阻塞挂起
- 当进程需要调用软硬件资源进程在内存中进行等待,并且相对来说短时间内此进程在软件建资源的运行队列中不会排到。
- 当内存中有十分多的进程,内存空间已经什十分吃紧时,操作系统为了防止系统因为内存爆满而挂掉,就会将类似如上队列的代码与数据部分临时拷贝到磁盘中,等到使用时,再将对应进程的所需资源拷贝会内存。(这一动作被称为资源的唤入,唤出)
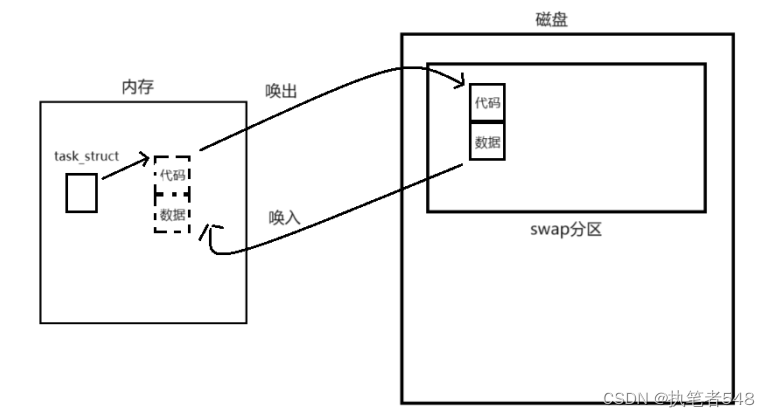
- 上述的过程中,被进行上面操作的进程其的状态就被称为挂起,挂起时会被拷贝出内存的只有进程的代码与数据,PCB不会被拷贝出内存。
- 磁盘中有专门的分区来进行挂起程序的代码数据临时存储,这一分区被称为swap分区。swap分区的大小一般与内存一致或者为内存的一半。
- 磁盘中,swap分区的大小不可太大,都其空间过大时,操作系统就会对它过度依赖,频繁的进行进程的唤入,唤出操作,IO频率过高会使得计算机的运行效率极低。
- 操作系统的挂起操作是用一定的效率交换获得内存可用性的方法。
注:C99支持循环语句处定义变量的语法,在编译时尾部带上-std=c99选项
2.3 Linux的进程状态
- 上面我们所讲的是所有操作系统都通用的进程状态概念,在具体的不同操作系统中,又对进程状态的具体实现各有不同,接下来,就让我们来对Linux操作系统中各种进程状态学习。
- Linux操作系统中,具体进程状态可以分为以下几类:
<1> R(running)准备就绪
<2> S (sleeping)浅度休眠
<3> D(dick sleep)深度休眠
<4> T(stopped)暂停
<5> t(tracing stop)调试暂停,等待软件资源中
<6> Z(zombie)僵尸状态
<7> X(dead)死亡状态- Linux源码中进程状态的数据实现为宏定义了整形变量,在数据管理上想要进行状态切换只要进行状态变量值的切换即可。
1. R状态
- 进程被运行或者正处于运行队列中。
2. S状态
- 进程未被执行,也未处于运行队列上,正处于等待对应软硬件资源的运行队列上。
补充1:运行状态的判定
- 进程的状态取决于这一进程大部分所处的状态。
示例:
#include <stdio.h>
#include <unistd.h>
int main()
{
while(1)
{
printf("hello Linux,PID:%d\n", getpid());
}
return 0;
}
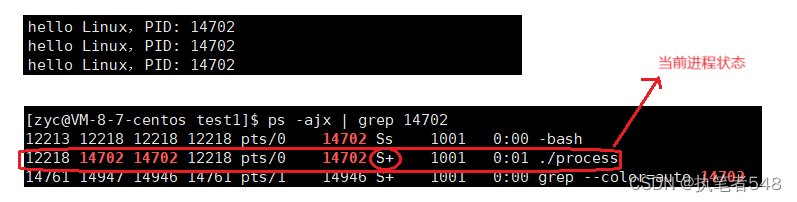
- 为何Xshell上一直在循环打印,可是在我们查询进程状态后却显示此进程为休眠状态。
- 云服务与本地计算机所处位置相对很远,而CPU的执行速度是极快的,而显示器的写入是相对很慢的,在CPU处理完指令后,过了 “很长一段时间” 后,数据才在显示器上写入打印出来,而后再CPU才能再执行之后的指令。正因如此,这个程序实际上95%以上的时间都是在等待硬件资源写入信息,所以才会显示为休眠状态。(不执行其他语句,一直死循环,进程状态就显示为R)
- 指令:
ps -ajx | grep [可执行程序名]

- grep文本过滤器也是一个进程,当查看其状态时,因为是用其过滤出自身的进程信息,所以其状态总显示是R。
补充2:前台与后台进程
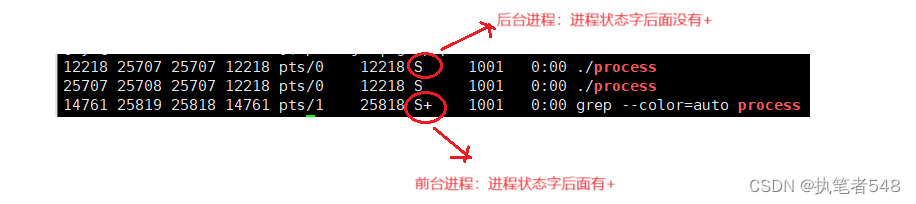
- 正常执行的进程都是前台进程,通过指令
./[可执行程序] &运行起来的可执行程序就后台进程。- 前台进程可以直接使用
Ctrl + C中断,后台进程只能通过指令kill -9 []进程号将进程杀死。
3. D状态(深度睡眠)
- 操作系统在极度繁忙与内存空间极度吃紧的情况下是会杀死S状态的程序的,操作系统不得不以此来确保自己与内存中大部分的进程的正常运行,不至于整体崩溃。
- 可是,S状态的进程可能正在等待硬件设备进行重要数据写入后的结果反馈,当操作系统因为内存资源极度不足将此类进程杀死后会造成进程数据的丢失,可能会造成信息丢失等严重后果。
- 因此,为了避免上述情况的出现,Linux操作系统为进程设置了一种新的状态,D状态,此种状态的进程也属于处于休眠状态的一种,与S状态的进程不同的是,在操作系统内存资源极度吃紧的情况下,其不会杀死D状态的休眠进程。(免死金牌)
- 当出现D状态进程时,这也预示着操作系统快要崩溃了。
4. T状态与t状态
- 指令:
kill -l,可以查看所有kill指令的参数选项与对应信号效果- 指令:
kill -19 [进程号],暂停对应进程- 指令:
kill -18 [进程],让对应进程继续运行- T状态:当某些进程执行到一些危险的操作行为时,操作系统会将其暂停,此时,这个进程处于的暂停状态就是T
- t状态:当我们使用调试工具gdb调试代码时,会产生对应进程,在进行打断点逐行运行等操作期间,程序处于的暂停等待软件资源的状态就称为t
5. Z(僵尸)状态与X(dead)状态
- 操作系统中所有的子进程在运行结束时都不会即可完全销毁,它们会暂时保留自己的PCB表,等待父进程从中读取子进程完成工作的结果,即返回信息,数据属性。
- 操作系统中,除开bash(命令行解释器)进程会主动读取子进程的返回信息外,我们自己创建的子进程其父进程不会主动读取子进程的返回信息,需要我们去控制。
- 处于上述情况中的已经运行结束又未被父进程读取返回信息的进程状态,就被称为Z(僵尸)状态,僵尸进程的PCB表会一直存在,导致内存泄漏。
- 进程创建子进程的操作,fork函数,需要配合wait函数来让父进程主动等待读取子进程执行结束的返回信息。(头文件:
sys/types.h)- 当进程正常执行结束,进程终止时,其的这一刻终止状态就被称为(死亡状态),死亡状态是瞬时性的,我们几乎抓拍不到。
6. 孤儿进程
#include <stdio.h>
#include <sys/types.h>
int main()
{
pid_t id = fork();
if(id)
{
sleep(5);
}
else
{
sleep(10);
}
return 0;
}

- 父进程先于子进程执行结束。
- 当出现如上情况时,为了避免子进程执行结束后称为僵尸进程,操作系统(进程号1)会 "领养"这一没有父进程的进程,在此进程执行结束时,返回信息被操作系统读取。
- 孤儿进程会从前台进程转为后台进程。














 1798
1798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









