






File
- File对象就表示一个路径,可以是文件路径也可以是文件夹路径
- 这个路径可以存在也可以不存在
绝对路径:是相对于电脑的,在电脑的文件夹里面带盘符的路径
相对路径:是不带盘符的,默认在当前项目下面去找
| public File (String pathName) | 把字符串对象路径变成File对象 |
| public File(String parent,String child) | 把父级路径和子级路径进行拼接 |
| public File(File parent,String child) | 把父级File对象的路径和子级Strig对象的路径进行拼接 |
判断功能
isDirectory()——判断该路径是否是文件夹
public boolean isDirectory();
isFile()——判断该路径是否是文件
public boolean isFile();
exists()——判断该路径是否存在
public boolean exists();
获取功能
length()——返回文件的大小(字节数量)
- 这个方法只能获取文件的大小,单位是字节,如果是M,G的话需要用结果除以1024
- 这个方法无法获取文件夹的大小,如果想要获取文件夹的大小,需要将文件夹下面的所有文件大小累加起来
public long length()getAbsolutePath()——返回文件的绝对路径
public String getAbsolutePath();getPath()——返回定义文件时使用的路径
简单来说,转换成File对象传入的什么参数就返回什么
public String getPath();getName——返回文件的名字,带后缀名
public String getName();lastModified()——返回文件的最后修改时间
public long lastModified();创建方法
createNewFile——创建一个新的空的文件
createNewFile创建的一定是个文件,如果没有后缀,也肯定是文件
public boolean createNewFile();mkdir()——创建单级文件夹
windows路径是唯一的,如果路径已经存在则创建失败返回false
public boolean mkdir();mkdirs()——创建多级文件夹
既可以创建多级的也可以创建单级的
public boolean mkdirs();删除方法
delete()——删除文件,空的文件夹
delete删除的时候不经过回收站直接被删除
删除有内容的文件夹删除失败
public boolean delete();获取并遍历
listFiles()——获取当前路径下的所有内容
将调用者对象的当前文件夹下,,每一个文件或者文件夹都单独封装成一个File对象,并装进File[]
- 当调用者表示的路径不存在时,返回null
- 当调用者File表示的路径是文件时,返回null
- 当调用者File表示的路径是一个空文件夹时,返回长度为0的数组
- 当调用者File表示的路径是一个需要访问权限才能访问的文件夹时,返回null
public File[] listFiles();IO
IO流:用于读写文件中的数据(可以读写文件)
I:Input O;Output
是程序在读数据,是程序在写数据,是程序在对文件中的数据进行操作
一个流可以理解为一个数据的序列。输入流表示从一个源读取数据,输出流表示向一个目标写数据
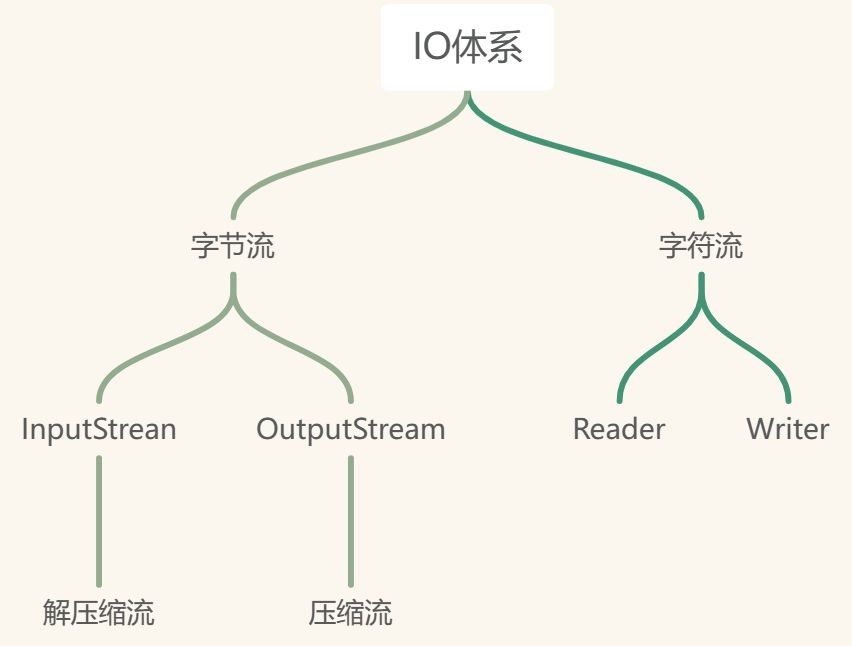
按照操作文件类型分类可以分为字节流和字符流 字节流可以操作所有类型的文件,字符流只能操作纯文本文件

字节流
概述:可以直接操作字节信息的流对象
字节输入流的顶层抽象父类:InputStream
字节输出流的顶层抽象父类:OuputStream
FileOutputStream(字节输出流)
- 创建FileOutStream对象
- 参数是字符串表示的路径或者是File对象都可以
- 如果文件不存在会自动创建文件,但要保证父路径要存在
- 如果文件已经存在,构造方法会清空文件的内容
- 写入数据
- write方法的参数是整数,实际上对应的是ASCII码上对应的字符
- 释放资源
- 解除了资源的占用
write的三个重载方法
void write();
void write(byte[] b);
void write(byte[] b,int off,int len);
换行写
windows:换行符:\r\n
FileOutputStream fos = new FileOutputStream("aaa\\a.txt");
String str = "dadjaodjaiodajdoaijdaiod";
byte[] bytes = str.getBytes();
fos.write(bytes);
String wrap = "\r\n";
byte[] wrapBytes = wrap.getBytes();
fos.write(wrapBytes);
String str2 = "666";
byte[] str2Bytes = str2.getBytes();
fos.write(str2Bytes);
fos.close();续写
public FileOutputStream(File file,boolean append)thorws FileNotFoundExceptionappend参数表示:续写开关,默认是false,如果传入true,则将字节写入文件末尾处,而不是写入文件开始处。
FileInputStream(字节输入流)
- 创建字节输入流对象
- 如果文件不存在就直接报错
- 读数据
- 如果读不到了则会返回-1
- 一次读一个字节,读出来的是对应ASCII码上对应的数字
- 释放资源
- read方法是用来读取数据的,并且调用一次,指针就会往后移动一位,所以在循环读取的时候,最好把读取的数据赋给一个变量,打印这个变量
循环读取
FileInputStream fis = new FileInputStream(File file);
int b;
while((b = file.read())!=-1){
System.out.print((char)b);
}文件拷贝
核心思想:边读边写
关闭流的时候:遵循先开启的流后关闭
FileInputStream fis = new FileInputStream(File file);
FileOutputStream fos= new FileOutputStream(File file);
int b;
while((b = fis.read())!=-1){
fos.write(b);
}
fos.close();
fis.close();读取多个字节
在调用read()的时候,一次读取一个字节,要想提高效率,一次应该读取多个字节。
一次读取多个字节的方法——返回值一次读取到多少个字节
public int read(byte[] buffer)
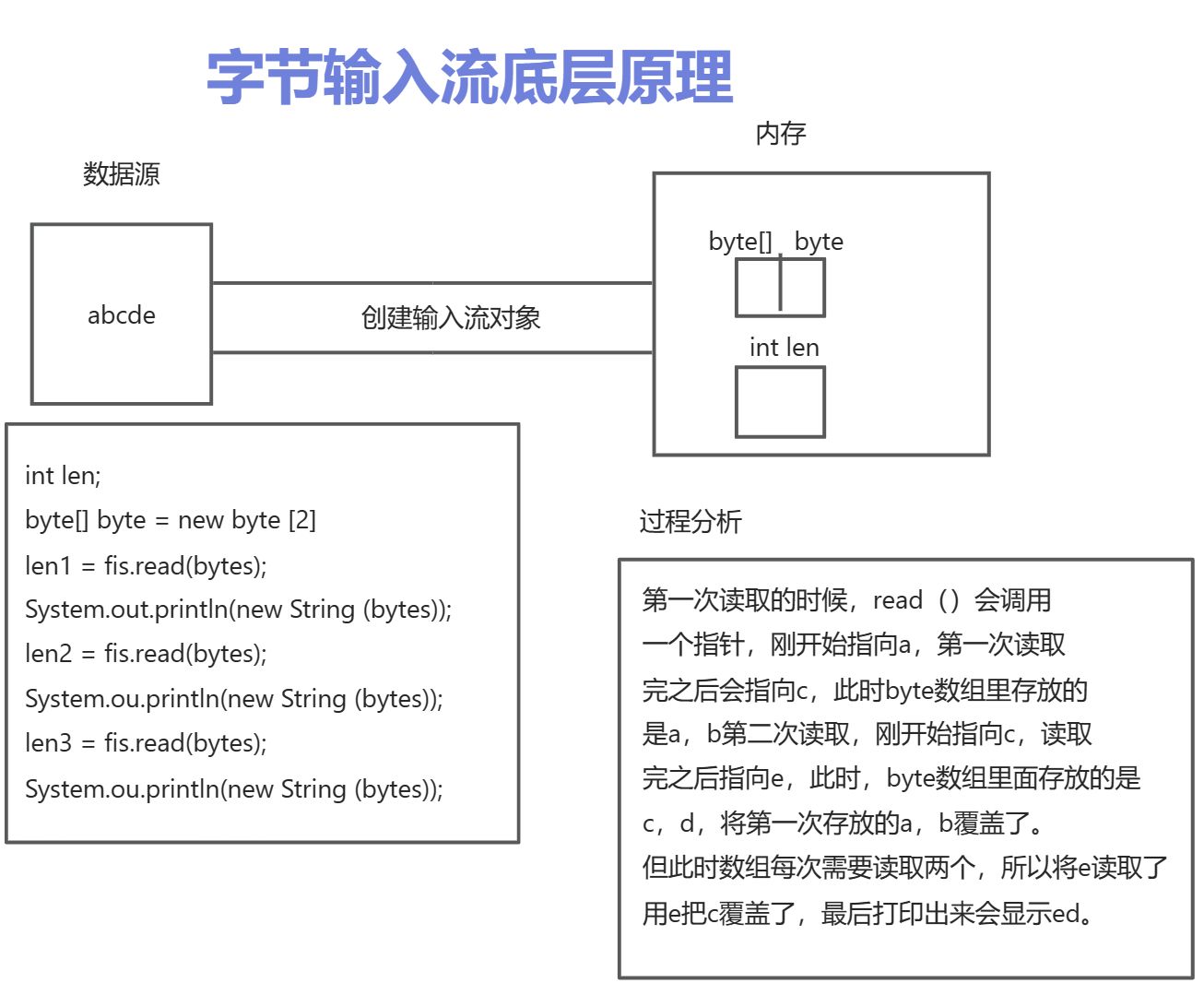
读取的时候也可以按照读取到的字节数进行输出即在转换成字符串的时候添加两个参数即可
new String(bytes,0,len1);
finally
被finally控制的语句一定会执行,除非JVM退出
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis= new FileInputStream("aaa\\a.txt");
fos = new FileOutputStream("b.txt");
int len;
byte[] bytes = new byte[2];
while ((len = fis.read(bytes))!=-1){
fos.write(bytes,0,len);
}
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
if (fos == null) {
try {
fos.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if (fis == null) {
try {
fis.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}字符集
- 计算机在存储英语的时候一个字节足以,因为ASCII码中对应的是0-127,一共128个
- 计算机在存储汉字的时候,使用GBK字符集,windows的默认使用的是GBK
- Unicode字符集:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言,跨平台的文本信息转换。
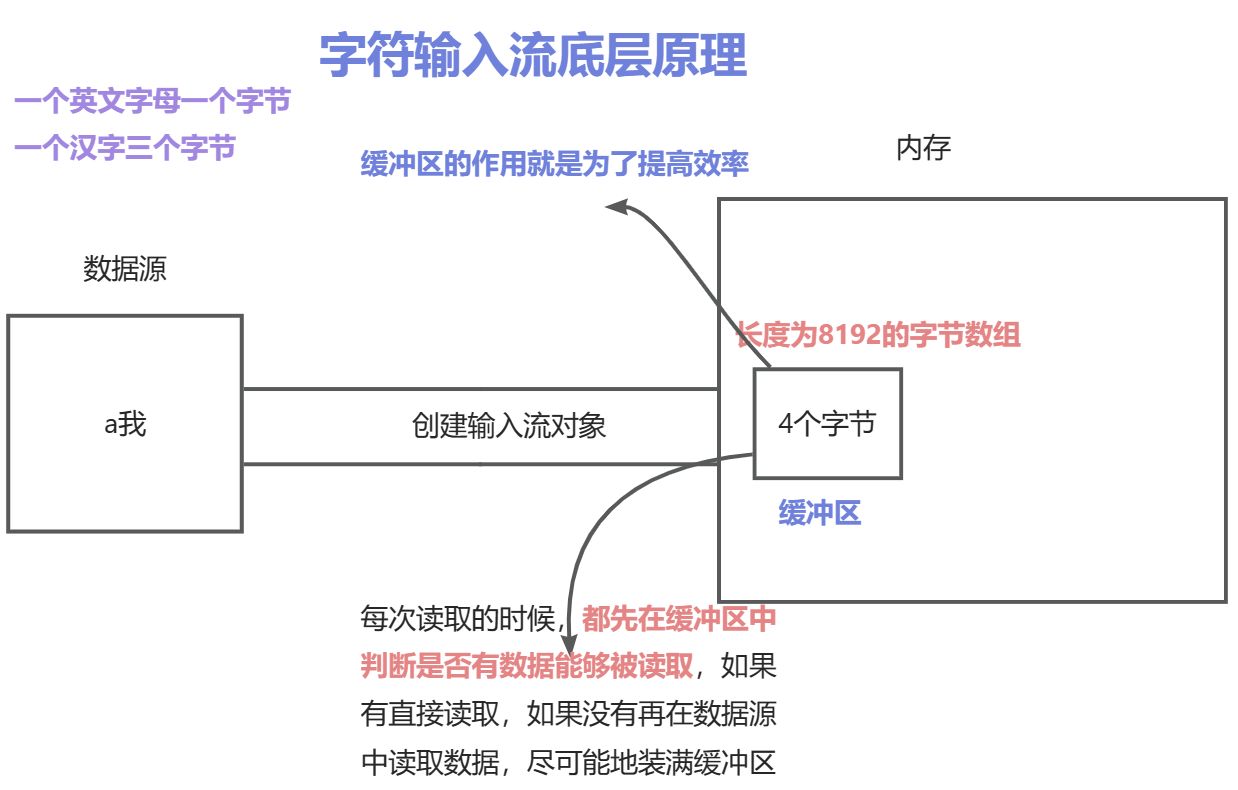
中文在存储的时候二进制的第一位一定是1,英文在存储的时候一定是0,中文在存储的时候占两个字节
在GBK字符集当中存储汉字的时候是两个字节,在UTF-8中存储的时候是三个字节
乱码现象:
- 读取数据时未读完整个汉字
- 编码和解码的方式不统一(默认使用的是UTF-8)
字符流
字符输入流(FileReader)
- 先创建对象
- 如果文件不存在,直接报错
- 读取数据
- 按字节读取,遇到中文,一次读取多个字节,读取后解码,返回一个整数
- 读到文件末尾,返回-1
- 释放资源
read():在读取英文的时候,read方法进行读取,解码然后转成十进制
在读取中文的时候,read方法进行读取,解码然后转成十进制,要想看见汉字就要把十进制数据,还需要强转成char类型
//空参的read方法只进行了读取数据和解码,如果想要看到汉字,还要进行强制类型转换
FileReader fr = new FileReader("aaa\\a.txt");
int b = 0;
while ((b = fr.read()) != -1) {
System.out.print((char) b);
}//有参的read方法相当于把读取数据,解码,强制转换结合在一起了
//相当于read()+强制类型转换
FileReader fr = new FileReader("aaa\\a.txt");
char[] arr = new char[2];
int b;
while((b = fr.read(arr))!=-1){
System.out.print(new String(arr,0,b));
}字符输出流(FileWriter)
字符输出流的构造方法中也有两个参数,append是续写开关,默认是false,改成true后,可以进行续写
- 创建字符输出流对象(创建缓冲区:长度为8192的字节数组)
- 参数是字符串表示的路径或者File对象
- 如果文件不存在会创建一个新的文件,但要保证父路径是存在的
- 如果文件已经存在,则会清空文件,如果不想清空可以打开续写装置
- 写数据
- 如果write方法的参数是整数,实际上对应的是字符集上的字符
- 释放资源
字节输出流是按照一个字节输出的,不能超过一个字节的范围
字符输出流也有缓冲区,输出的时候会先把数据写到缓冲区当中
- 当缓冲区满的时候会自动把缓冲区中的所有数据写到文件当中
- 手动调用flush(),close()表示将存入缓冲区中的数据刷新到文件当中
flush()和close()的区别:
close表示流已经断开,下面不能再对流进行操作不然代码会报错,但flush只是刷新流,下面可以对流进行其他操作
字节流和字符流的使用场景
字节流:拷贝任意类型的文件
字符流:读取纯文本文件中的数据,往纯文本文件中写数据
缓冲流
把基本流包装成高级流,给基本流的底层添加了缓冲区,提高了读取数据和写入数据的效率
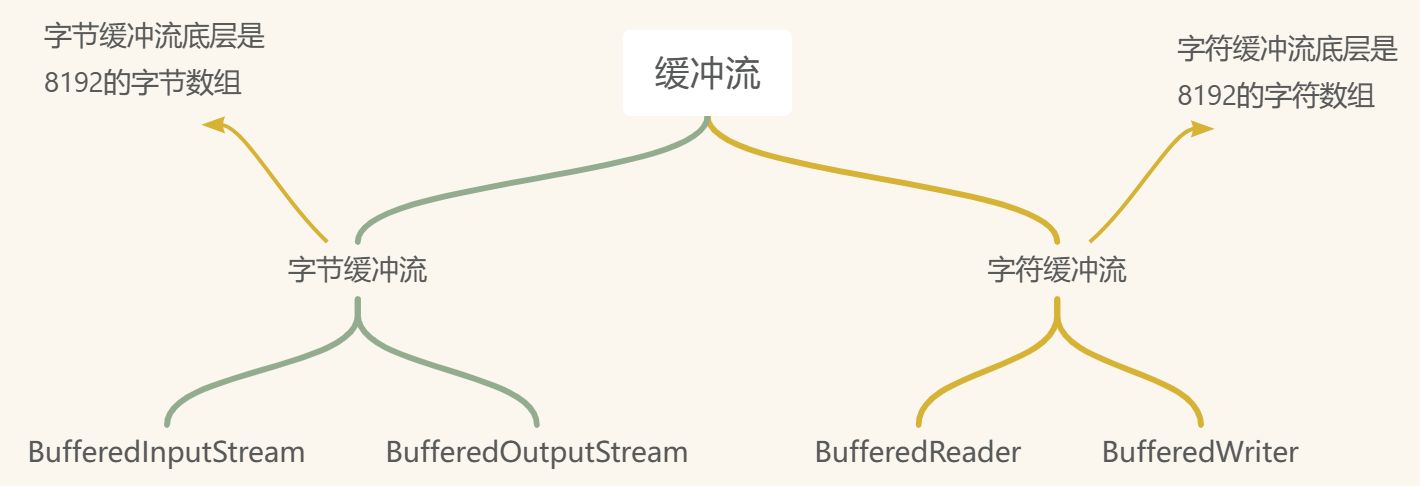
缓冲输入流中的缓冲区和缓冲输出流中的缓冲区不是同一个
字符缓冲流特有方法()
readLine():读取一行数据
readLine在读取的时候遇到回车换行就会结束,但是不会把回车换行读取到内存当中
public String readLine()
BufferedReader br = new BufferedReader(new FileReader("aaa\\a.txt"));
String str;
while ((str=br.readLine())!=null){
System.out.println(str);
}
br.close();newLine():换行
public void newLine();
转换流
转换流是字符流的一种,是一种高级流,是字符流和字节流的桥梁
输入流:InputStreamReader(将字节流转换成字符流)
输出流:OutputStreamWriter(将字符流转换成字节流)
当字节流想要使用字符流中的方法的时候,可以用转换流,将字节流转换成字符流,在内存中读取后,再转换成字节流进行写入
关闭的时候只需要关闭高级流,因为底层高级流会关闭基础流
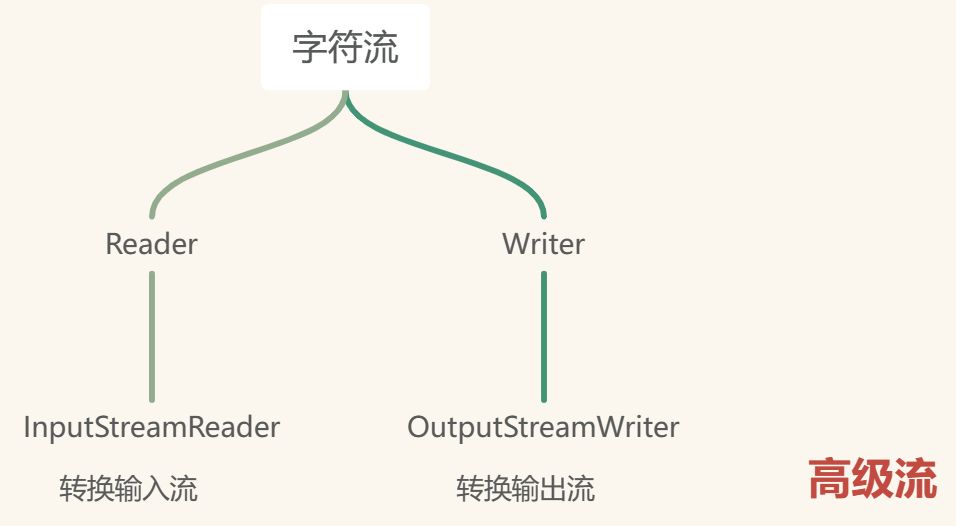
转换输入流
InputStreamReader的构造方法:
第一个参数是传入的字节输入流
第二个参数是传入指定编码集名字
InputStreamReader(InputStream In,String charsetName);
OutputStreamWriter的构造方法
OutputStreamWriter(OutputStream out , String charsetName)
在JDK11以后,就不再用转换输入流来指定编码集进行编码解码了
在JDK11以后,FileWriter和FileReader新增了一个构造方法可以传入Charset的参数用来指定编码集
序列化流
序列化流属于字节流的一种,也属于高级流
序列化流:ObjectOutputStream
反序列化流:ObjectInputStream
序列化流:可以把Java对象写入本地文件当中
序列化流也叫做对象操作输出流
序列化流的构造方法
public ObjectOutputStream(OutputStream out);
序列化的写入操作
public void WriterObject(Object obj);
Student student = new Student("zhangsan",23);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("aaa\\a.txt"));
oos.writeObject(student);
oos.close();将要序列化的对象的Javabean类实现Serializable接口
Serializable接口中没有抽象方法,叫做标记性接口,一旦实现了这个接口说明该类可以被序列化。
反序列化流
反序列化流属于字节流的一种,属于高级流
反序列化流也叫做对象操作输入流
可以把本地文件的对象输入到程序当中
反序列化的构造方法
public ObjectInputStream(InputStream in)
反序列化的读取操作
public Object readObject();
反序列化的操作
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("aaa\\a.txt"));
Object o = ois.readObject();
System.out.println(o);
ois.close();序列化和反序列化的注意事项
- 如果一个JavaBean类实现了Serializable接口,说明这个类是可被序列化的
- 那么底层就会根据该类中的构造方法,静态变量,成员方法,成员变量来计算机这个类的序列号,该对象在序列化的时候也会存入序列号,但是由于业务需求,JavBean类发生了改变,那么底层会重新计算该类的序列号,序列号也会改变,在用反序列化读取到内存中之后,两个序列号不一样,所以会报错,我们需要固定版本号
序列号:
private static final long serialVersionUID = 1l;
当序列化多个对象的时候,把对象存储到集合当中,再序列化集合即可
反序列化的时候,直接反序列化集合,得到集合,再遍历集合中的每个元素即对象
运行的时候先运行序列化再运行反序列化
Student student = new Student("zhangsan",23);
Student student1 = new Student("lisi",24);
Student student2 = new Student("wangwu",25);
ArrayList<Student>students = new ArrayList<>();
students.add(student);
students.add(student1);
students.add(student2);
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("aaa\\a.txt"));
oos.writeObject(students);
oos.close();
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("aaa\\a.txt"));
ArrayList<Student> list = (ArrayList<Student>) ois.readObject();
for (Student student : list) {
System.out.println(student);
}
ois.close();
transient关键字
如果不想把某个属性序列化到本地文件当中,可以在属性前面添加transient
打印流
打印流分为两种:PrintStream,PrintWriter两类

打印流的特点
- 打印流只操作文件目的地,不操作数据源
- 特有的写出方法,数据原样写出
- 特有的写出方法,可以实现自动刷新,自动换行
System.out是一种特殊的打印流
字节打印流
常规方法:
public void write() //规则跟之前一样,将指定的字节写出,对应的ASCII码表
特有方法:
public void println() //打印任何数据,自动刷新,自动换行
public void print() //打印任何数据,不换行
public void printf() //带有占位符的打印方法,不换行
字符打印流
字符打印流的底层有缓冲区,想要刷新需要开启
构造方法
public PrintWriter(Writer/File/Stirng) 关联字节,文件,字符
public PrintWriter(String fileName,Charset charset) 指定字符编码
public PrintWriter(Write, boolean autoFlush) 自动刷新
解压缩流/压缩流
解压缩流和压缩流属于字节流
解压缩流
解压的本质:把压缩包中的每一个文件或文件夹读取出来,按照层级拷贝到目的地当中
压缩包里面的每个文件或文件夹都是一个Zipentry对象
getNextEntry()
这个方法可以把压缩包当中的每一个文件和文件夹都获取到,如果获取超过最后一个返回null
在处理完一个压缩包的时候需要调用zip.closeEntry();
//创建压缩包的路径
File file = new File("D:\\aaa");
//创建解压缩包的目的地
File dest = new File("D:");
unzip(file,dest);
}
public static void unzip(File file, File dest) throws IOException {
//创建一个解压缩流读取压缩包中的数据
ZipInputStream zis = new ZipInputStream(new FileInputStream(file));
ZipEntry zipEntry;
while((zipEntry = zis.getNextEntry())!=null){
//如果是文件夹,就需要创建一个文件夹
if (zipEntry.isDirectory()){
File file1 = new File(dest,zipEntry.getName());
file1.mkdirs();
}else {
//如果是文件,需要读取到压缩包中的文件,并把他按照层级存放在文件夹当中
FileOutputStream fos= new FileOutputStream(new File(dest,zipEntry.getName()));
int b;
while((b = zis.read())!=-1){
fos.write(b);
}
fos.close();
zis.closeEntry();
}
}
zis.close();压缩流
在压缩文件中,每一个压缩的内容都可以用一个ZipEntry表示,所以在进行压缩之前必须通过putNextEntry设置一个ZipEntry即可。
File src = new File("D:\\a.txt");
File desc = new File("D:");
tozip(src,desc);
}
private static void tozip(File src, File desc) throws IOException {
//创建一个压缩流对象,传入压缩的目的地
ZipOutputStream zos = new ZipOutputStream(new FileOutputStream(new File(desc,"a.zip")));
//创建ZipEntry对象,表示压缩包当中的每个文件
//传入的参数表示文件的名字
ZipEntry zipEntry = new ZipEntry("b.txt");
//把ZipEntry对象放到压缩包中
zos.putNextEntry(zipEntry);
//读取压缩包的数据并写入
FileInputStream fis = new FileInputStream(src);
int b;
while((b = fis.read())!=-1){
zos.write(b);
}
fis.close();
zos.closeEntry();
zos.close();
}Commons-io工具包
里面的方法都是静态方法
作用:提高IO流的开发效率
copyDirectory(File src,File dest):复制文件夹
- 这个方法是直接把文件夹,复制到目的地上
copyDirectorytoDirectory(File src,File dest):复制文件夹
- 这个方法只把src的文件夹拷贝到dest文件夹的目录下
Hutool工具包
里面的方法都是静态方法
FileUtils.file()——其中一个构造方法是传入的可变参数,可以将父路径和多个子路径进行拼接起来
FileUtils.touch()——根据参数创造文件,如果父路径不存在,也会把父路径一起创建出来
writeLines(Collection<T> list,String path,String cahrset,boolean isAppend)——将集合中的数据写入文件当中
appendLines()——是在writeLines开启了追加模式,即写的时候不覆盖之前的数据
readLines()——将文件中的数据读取到集合当中,一行数据是集合中的一个元素
















 879
879











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











