







目录
一、顺序语句
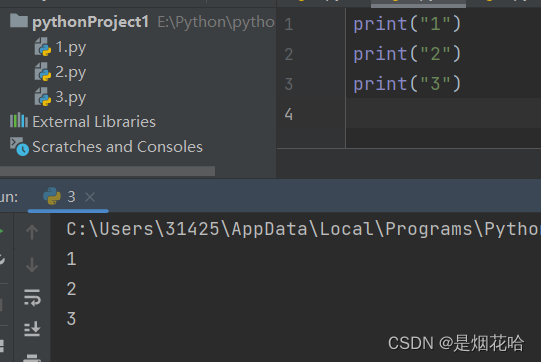
注意点:在后面学习到函数时,牢记 Python必须先定义函数,然后在调用。 Python中定义函数与Java中创建一个方法来调用是不相同的(牢记)
二、条件语句
(1) if
a = 10
if a < 2:
print("正确")
print("错误")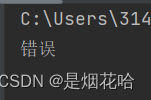
a = 1
if a < 2:
print("正确")
print("错误")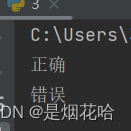
(2) if - else
a = 10
if a < 2:
print("正确")
else:
print("错误")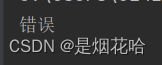
(3) if - elif - else
a = 10
if a < 2:
print("正确")
elif a == 3:
print("错误")
else:
print("无解")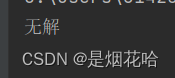
总结:Python中的条件语句写法, 和很多编程语言不太一样。Java 和C++使用判断语句与Python不同。
- if 后面的条件表达式, 没有 ( ), 使用 : 作为结尾,else和elif也是使用:作为结尾。
Python编程语言中凡是带有关键字开头的判断条件、函数定义、类定义都需要以冒号:结尾。(牢记)
缩进和代码块
a = input("请输入第一个整数: ")
b = input("请输入第二个整数: ")
if a == "1":
if b == "2":
print("hello")
print("world")
print("python")在这个代码中,print("hello") 具有两级缩进, 属于 if b == "2" 条件成立的代码块.print("world") 具有一级缩进, 属于 if a == "1" 条件成立的代码块.print("python") 没有缩进, 无论上述两个条件是否成立, 该语句都会执行
空语句 pass
代码示例: 输入一个数字, 如果数字为 1, 则打印 hello。
a = int(input("请输入一个整数:"))
if a == 1:
print("hello")这个代码也可以等价写成
a = int(input("请输入一个整数:"))
if a != 1:
pass
else:
print("hello")三、循环语句
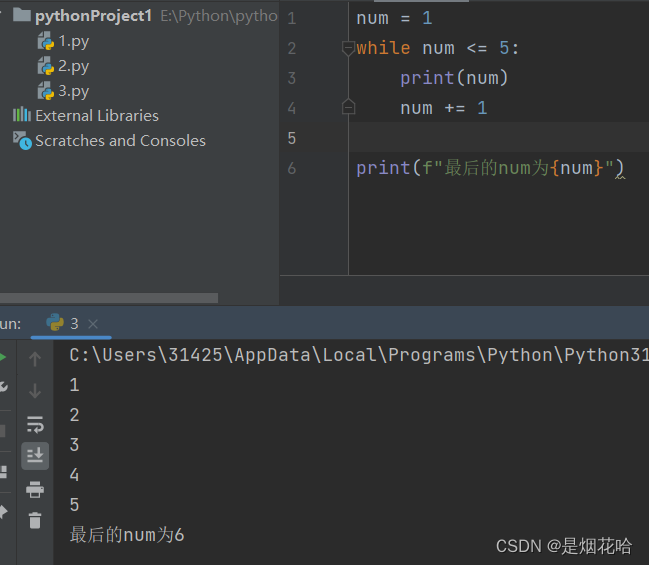
while 循环
while 条件:循环体
- 条件为真, 则执行循环体代码
- 条件为假, 则结束循环
for 循环
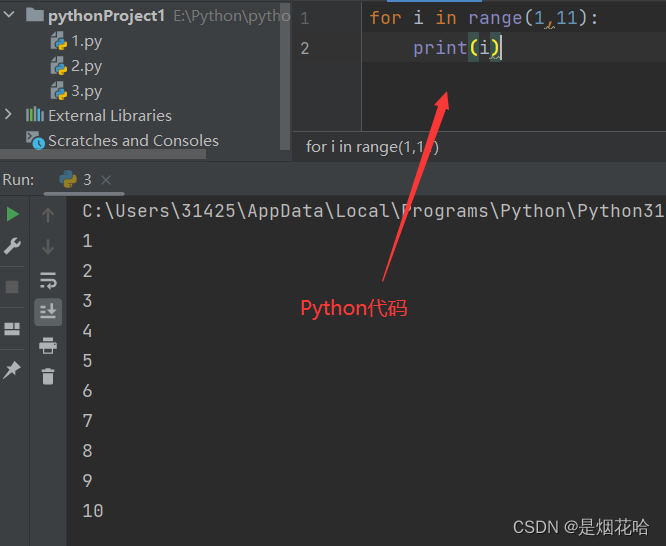
for 循环变量 in 可迭代对象:循环体
- Python 的 for 循环没有 "初始化语句", "循环条件判定语句", "循环变量更新语句"。比如Java和C++就需要自定义初始化语句,循环结束条件和变量更新语句。
- "可迭代对象"指的是 "内部包含多个元素, 能一个一个把元素取出来的特殊变量"。
Python语言可以使用 range函数来能够生成一个可迭代对象, range函数有3个参数:开始参数、结束参数、迭代步长1、开始参数是包含的,结束参数是不包含的,可以理解为 左闭右开2、迭代步长参数可以不写,默认为1,也可以指定迭代时候的 "步长", 也就是一次让循环变量加几。
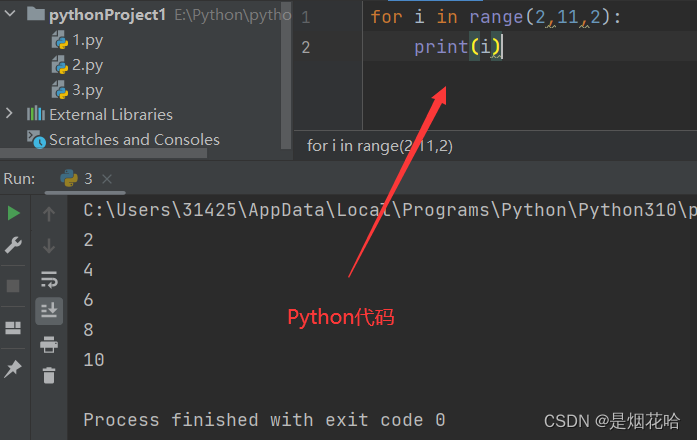
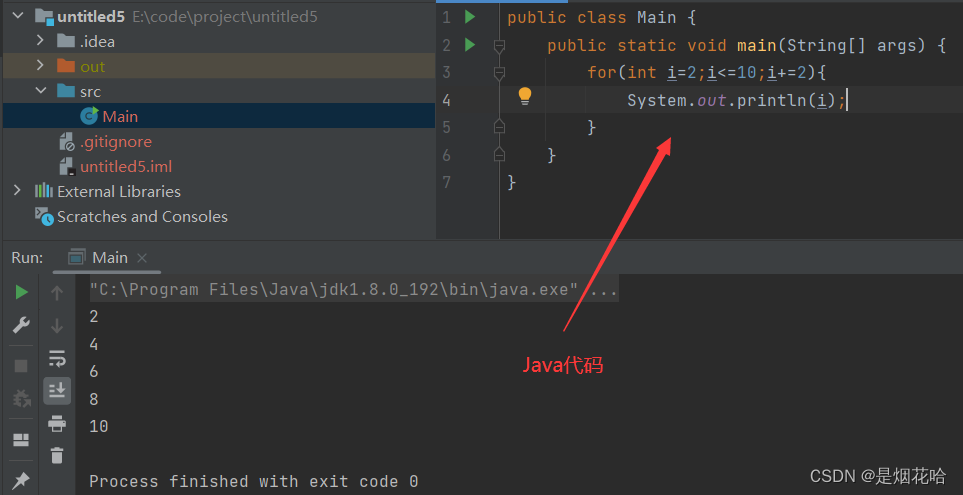
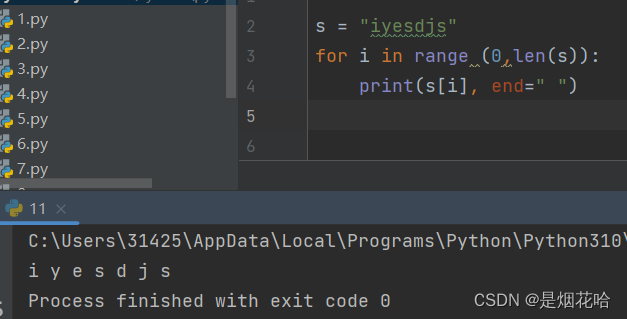
代码示例3: 循环打印字符串的每一个字符,不换行打印
continue
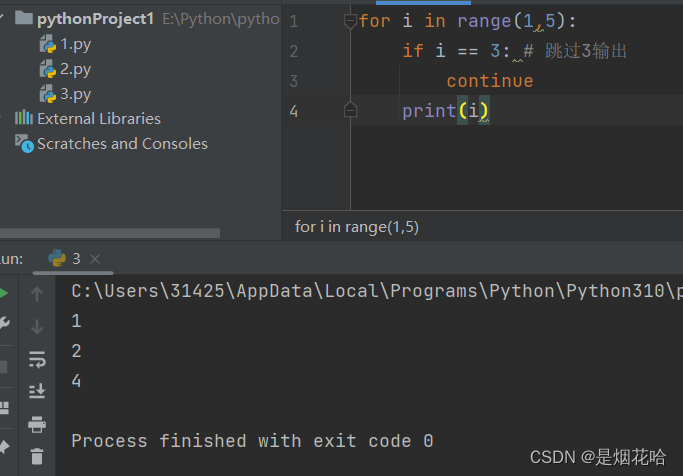
break
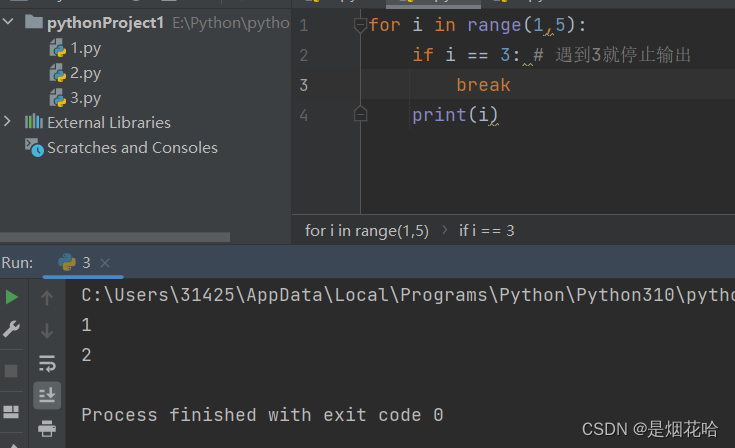
四、函数
Python语言中创建一个函数来供调用和使用,Java和C++中也有这种形式,来定义一个方法来供调用和使用。
创建函数
def 函数名(形参列表) :函数体return 返回值
注意点:函数的形参列表和返回值可以有,也可以没有。因此Python的函数类型有四种:
1、无参数,无返回值的函数
2、无参数,有返回值的函数
3、有参数,无返回值的函数
4、有参数,有返回值的函数
调用函数
函数名(实参列表) // 不考虑返回值返回值 = 函数名(实参列表) // 考虑返回值
注意点:
- 创建函数时必须使用 def 这个关键字,后面紧接函数名,括号里面包括形参列表,同时以 :结尾
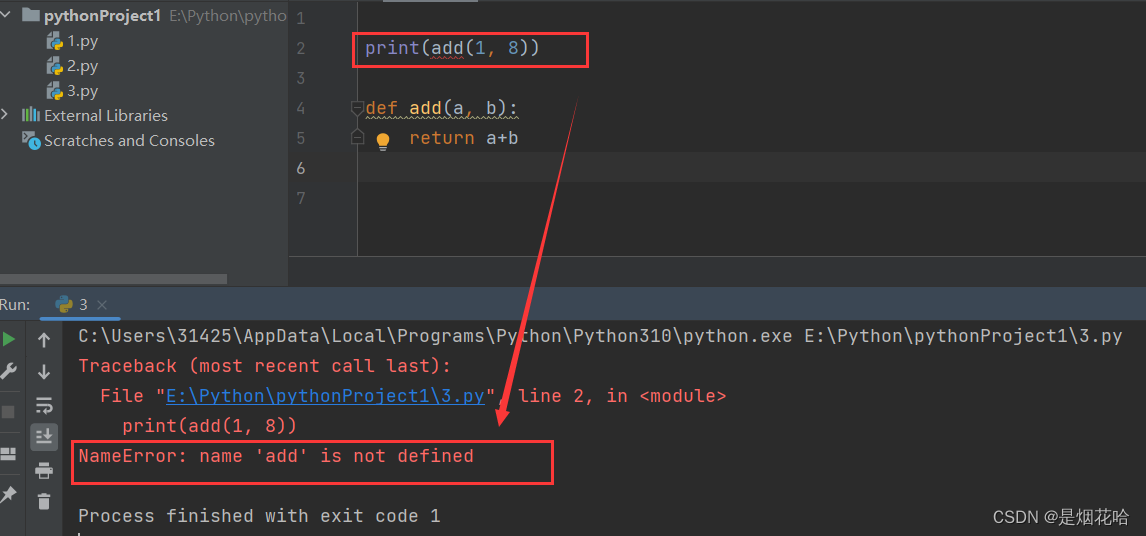
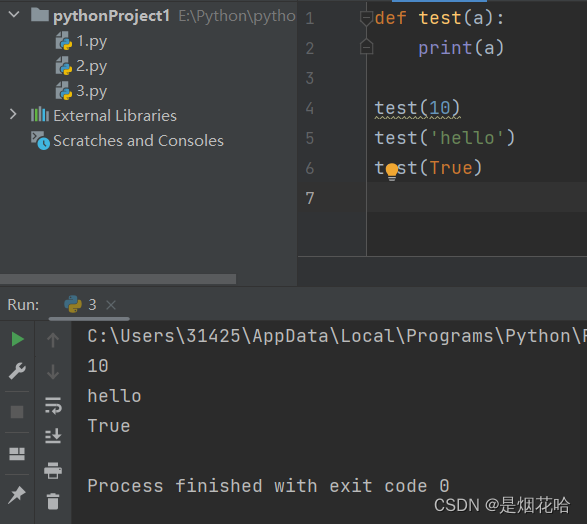
函数返回
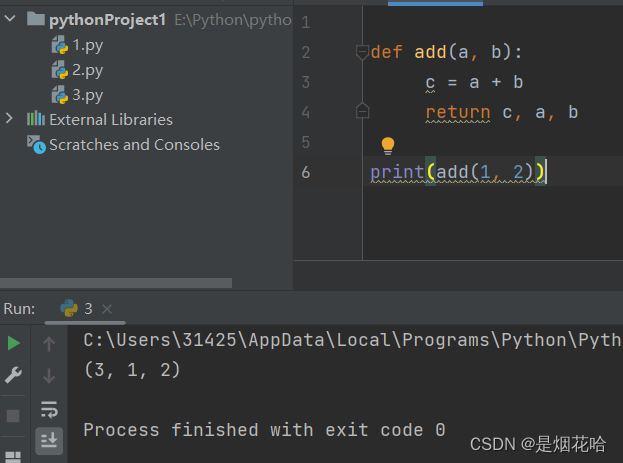
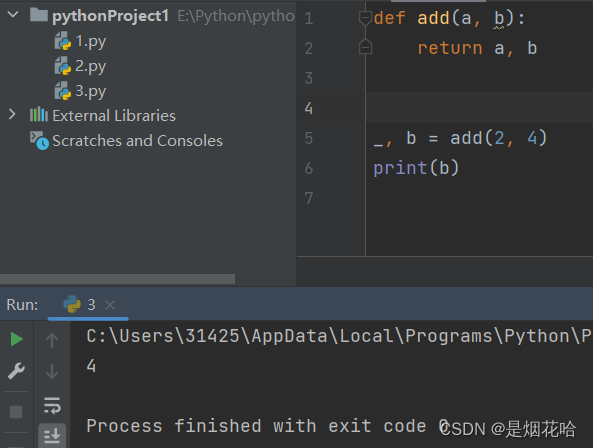
函数变量
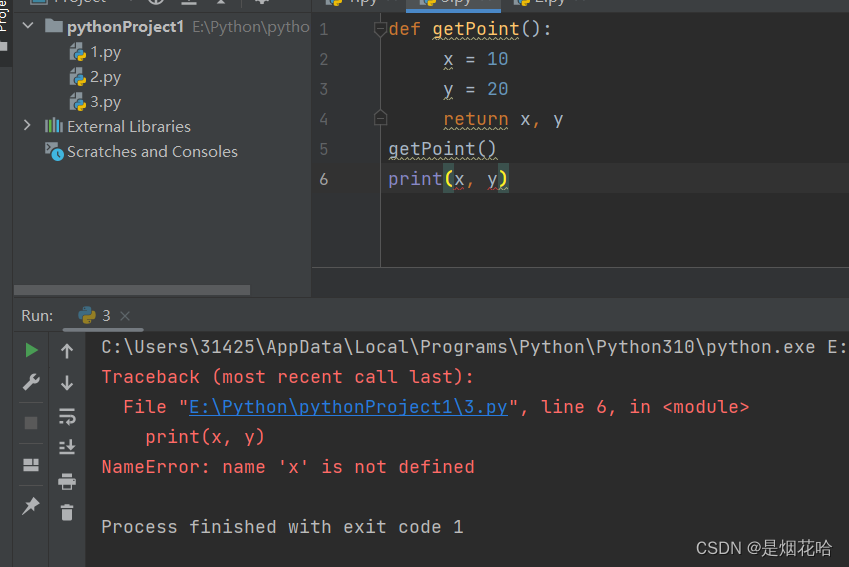
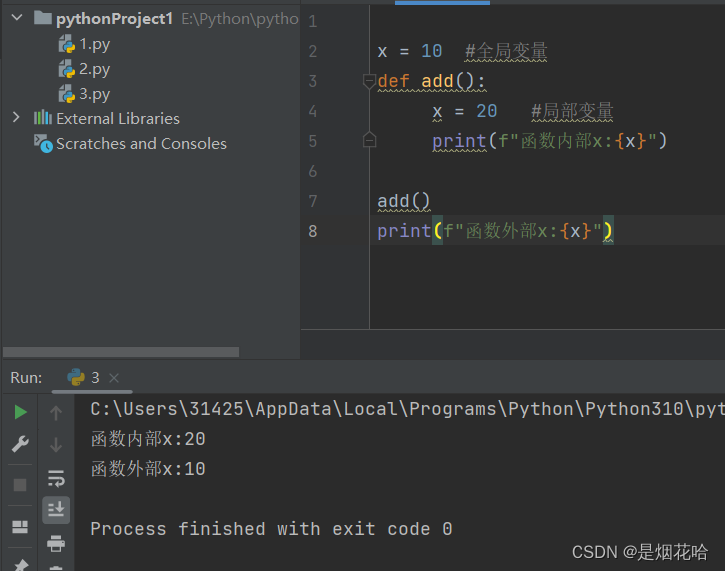
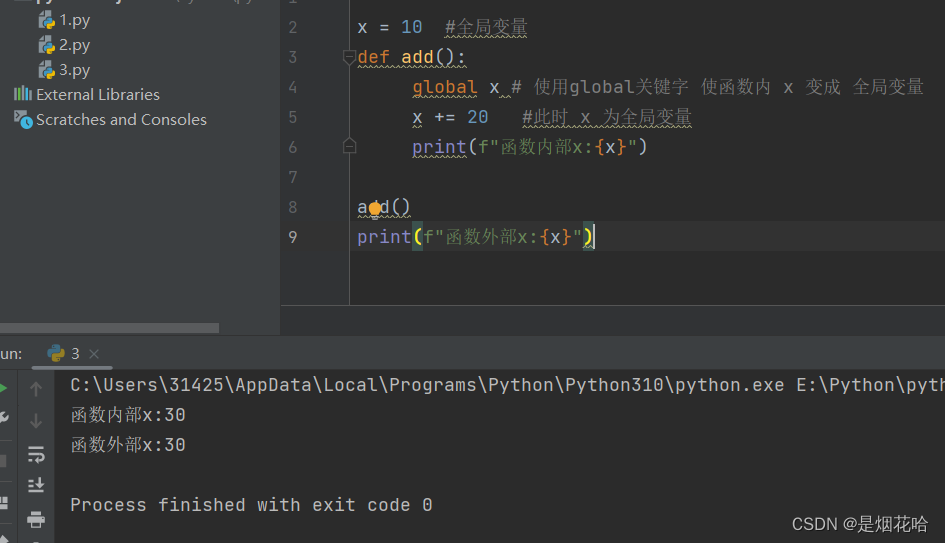
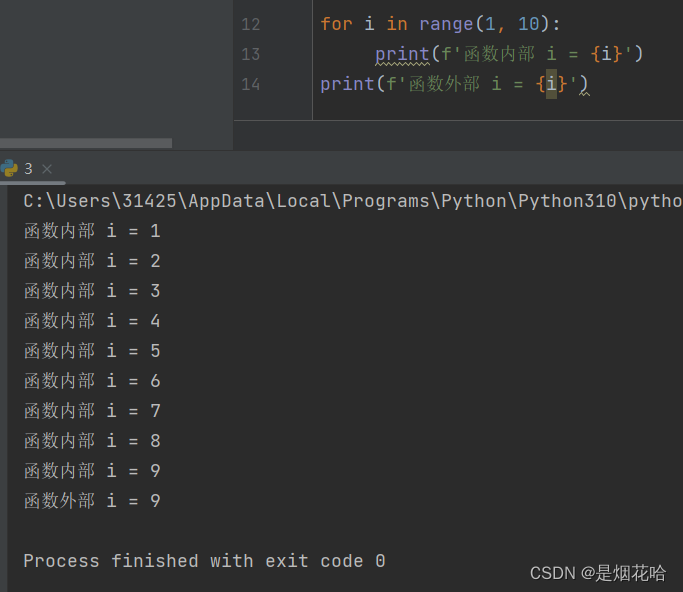
- 在函数内部的变量, 也称为 "局部变量"
- 不在任何函数内部的变量, 也称为 "全局变量"
函数递归
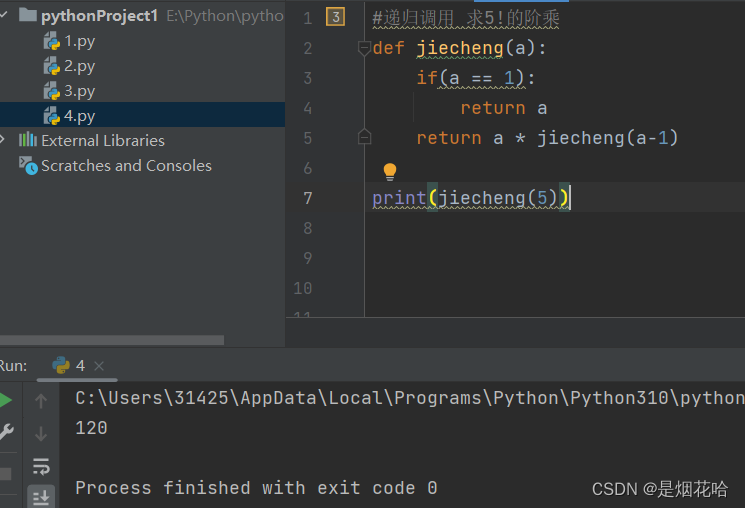
注意:
- 递归代码务必要保证 递归必须要有一个结束条件出口。
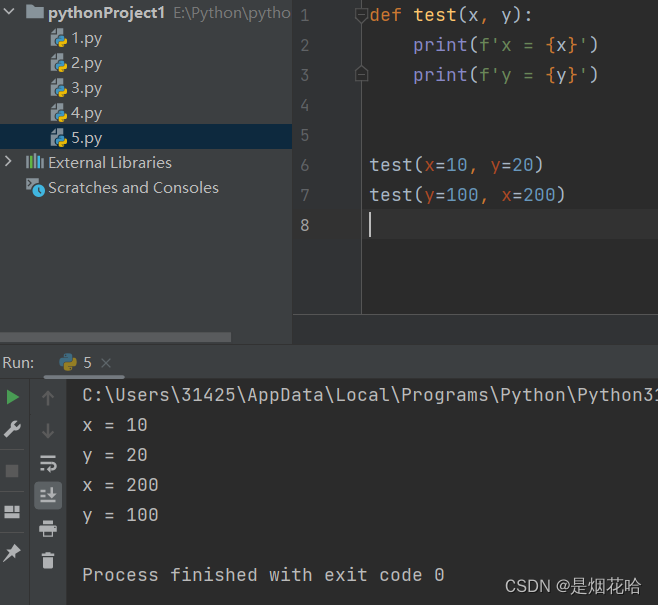
关键字参数

五、列表和元组
Python中的列表可以理解为Java中的数组,是用来存储数据元素的。Python列表里面的元素是可以修改的。
创建列表
list = [1,2,3,4,5,6]
print(list)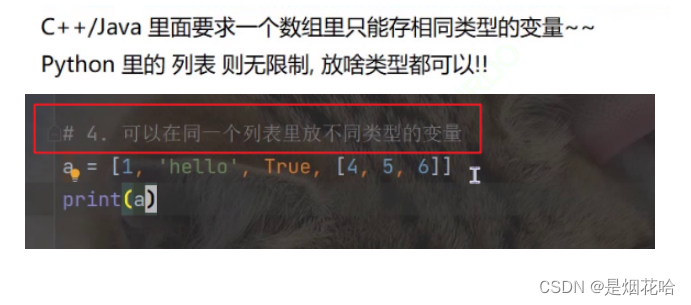
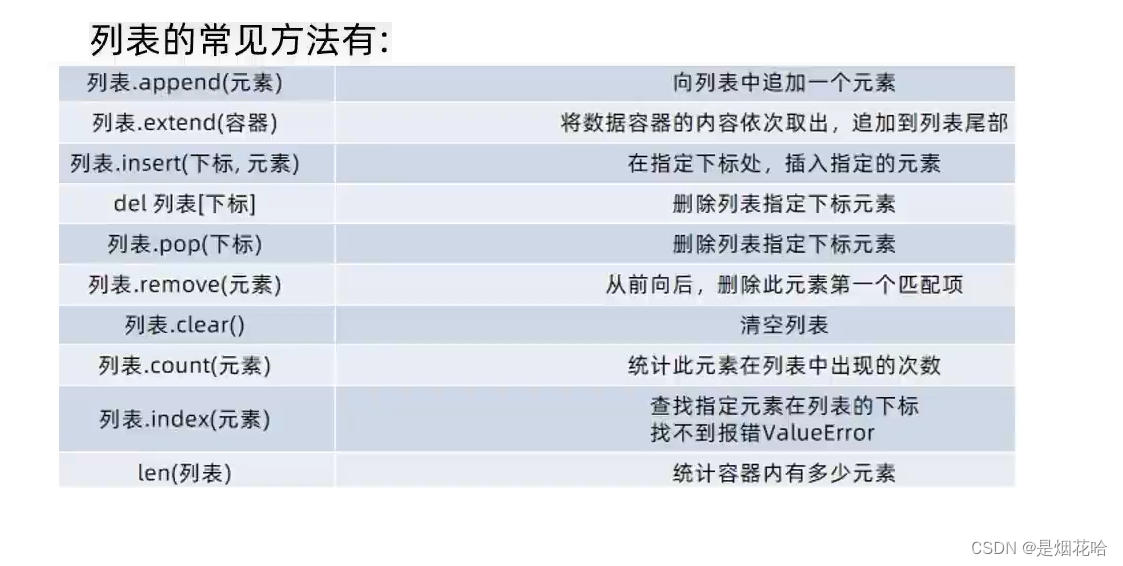
访问下标
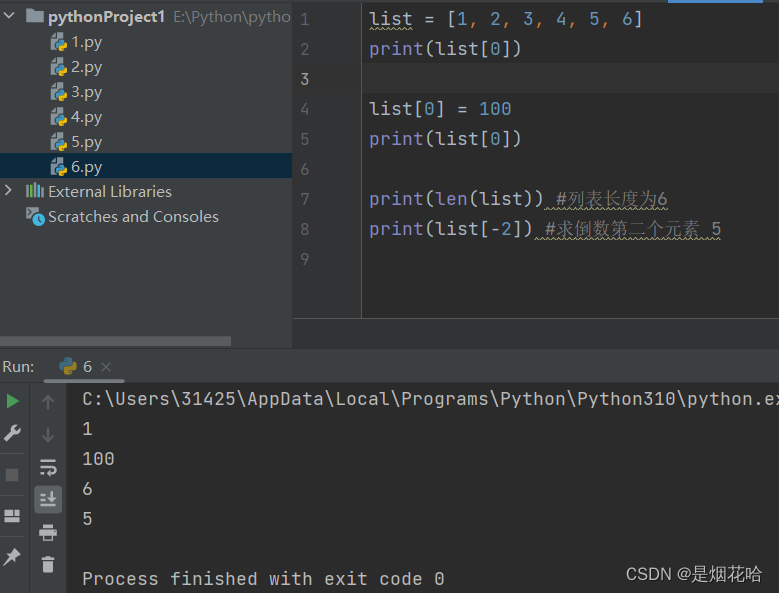
切片操作
切片操作是使用 [ a : b ] 的方式进行切片操作,其中a,b 都是列表的下标。a是开始下标,b是结束下标,切片操作中包含a下标,不包含b下标。(左闭右开)
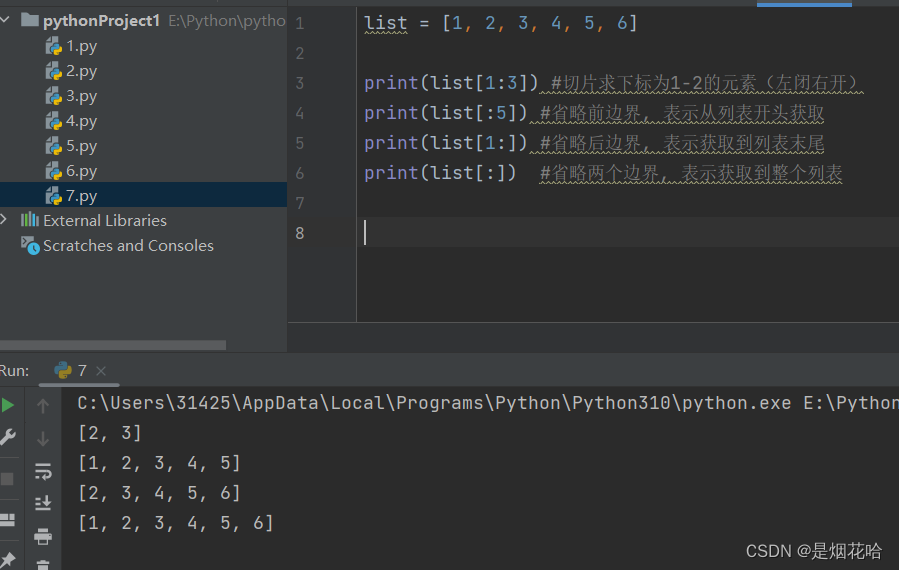
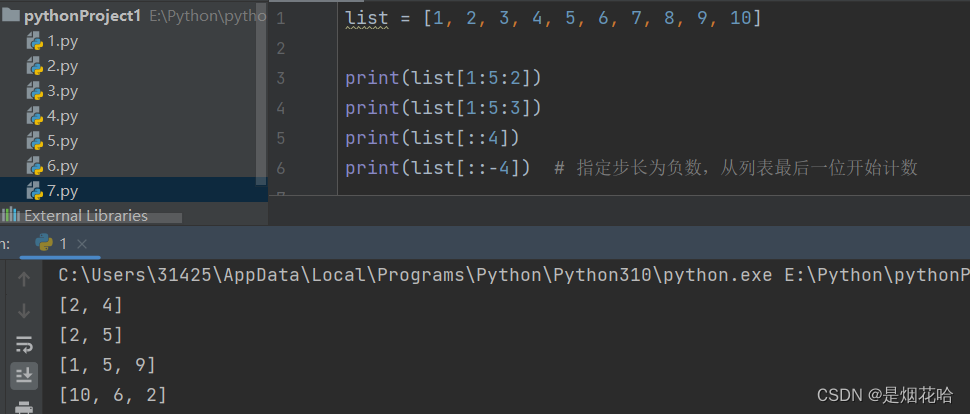
list[ : : -1]等同于将列表序列进行反转
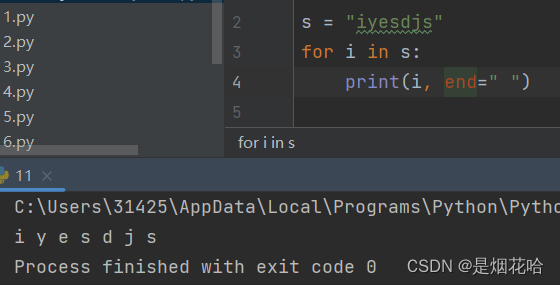
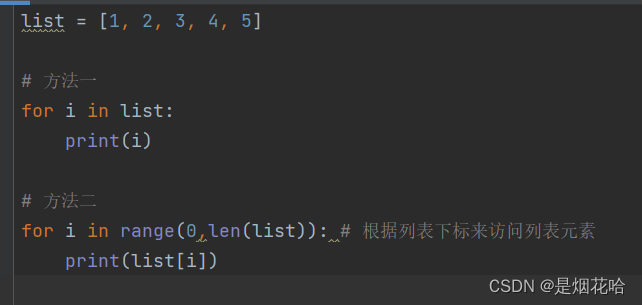
遍历列表元素
遍历列表元素使用for循环,方法有2种:
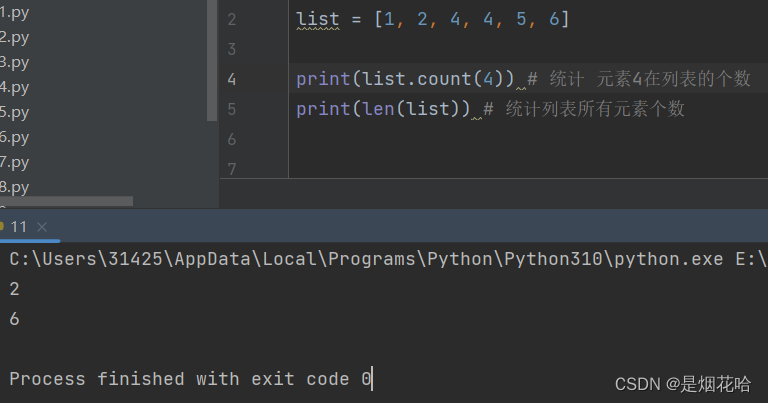
统计列表指定元素个数
使用 count 方法来统计列表中指定元素个数
使用 len 方法来统计列表中所有元素个数
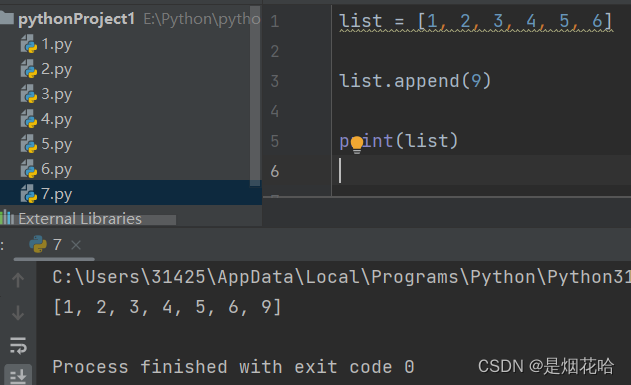
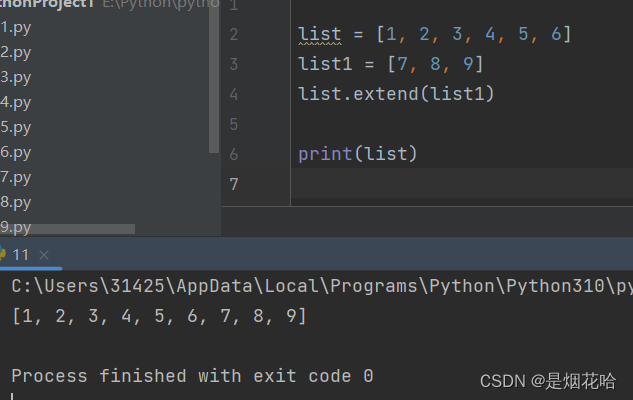
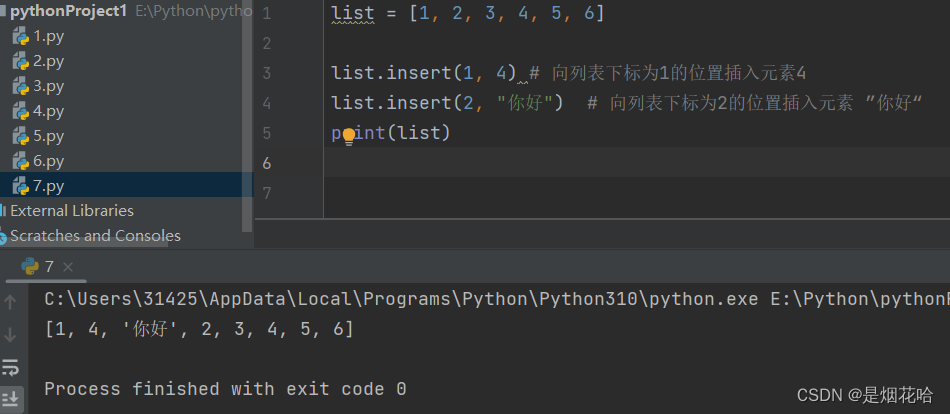
新增元素
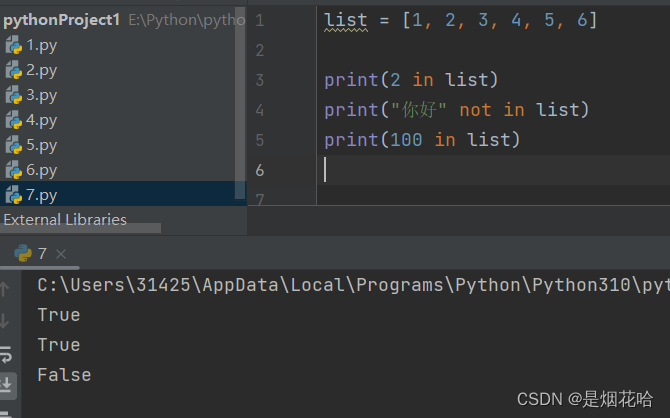
查找元素
使用 in 操作符, 判定元素是否在列表中存在,返回值是布尔类型。
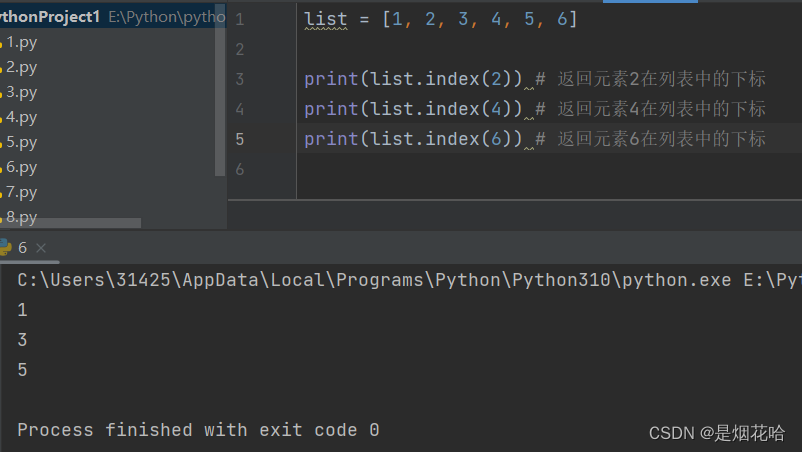
快速判断某个元素是否在列表中并返回它在列表的下标:index
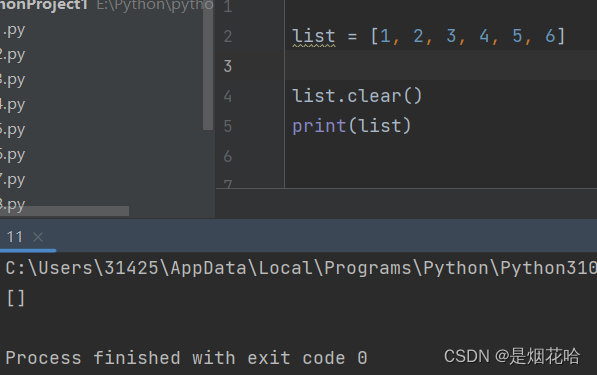
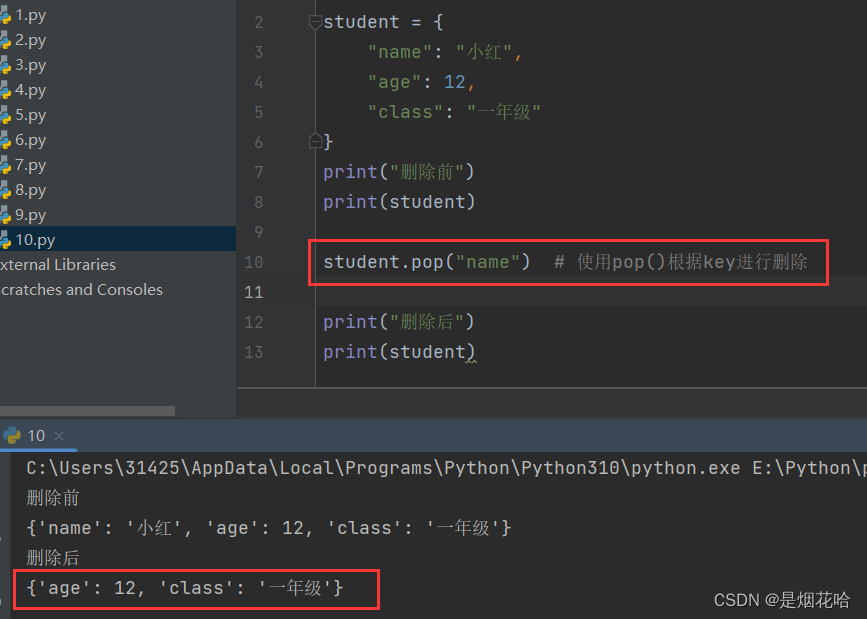
删除元素
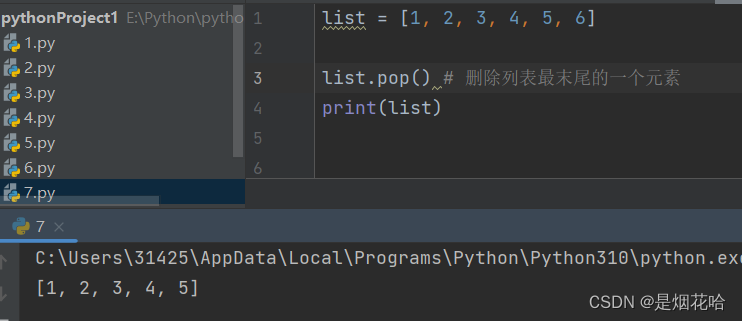
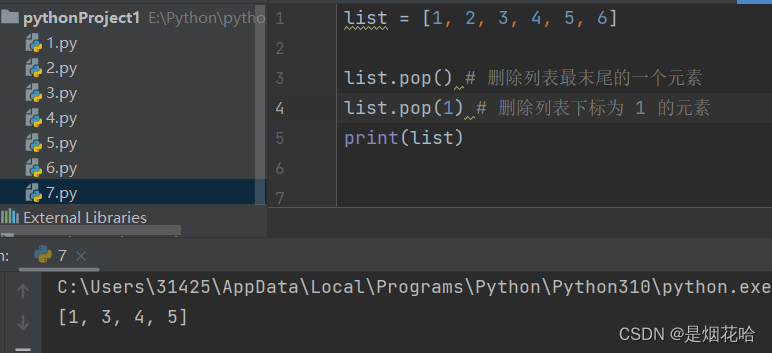
注意点:若列表中有多个指定元素,则使用remove()方法时,按照从左到右顺序删除遇到的第一个指定元素
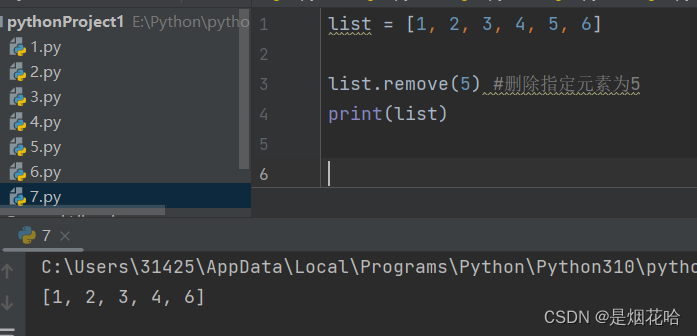
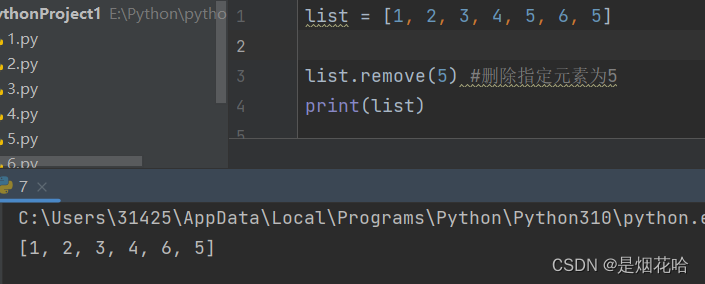
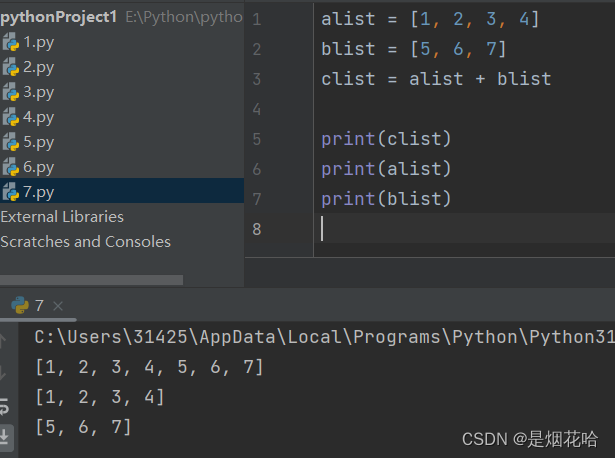
连接列表
1、使用 + 能够把两个列表拼接在一起
此处的 + 结果会生成一个新的列表. 而不会影响到旧列表的内容
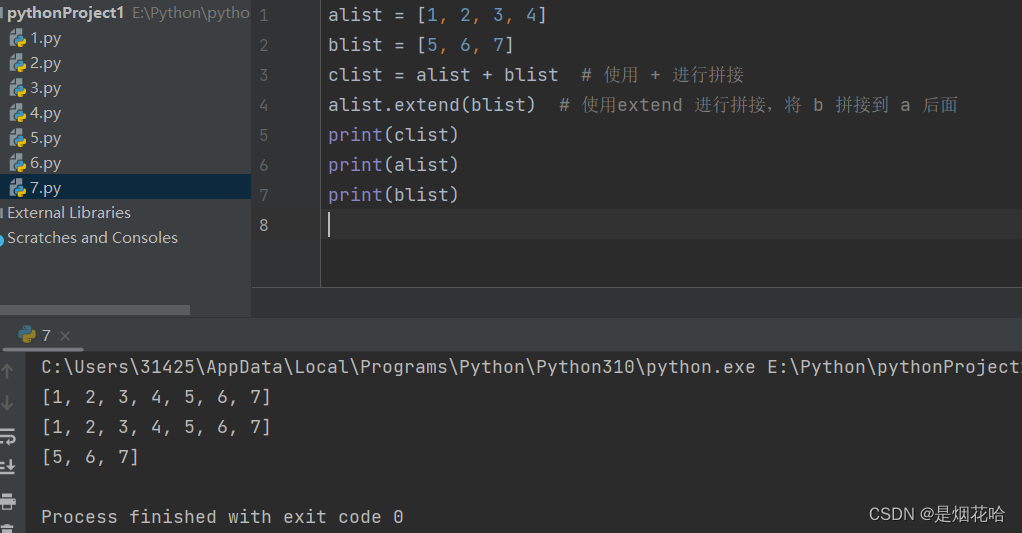
2、使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面。
a.extend(b) , 是把 b 中的内容拼接到 a 的末尾。会修改a的内容,但不会修改 b
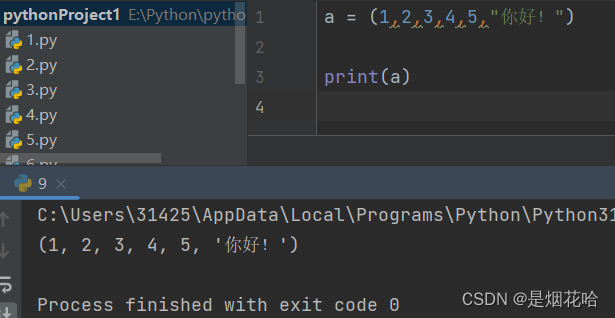
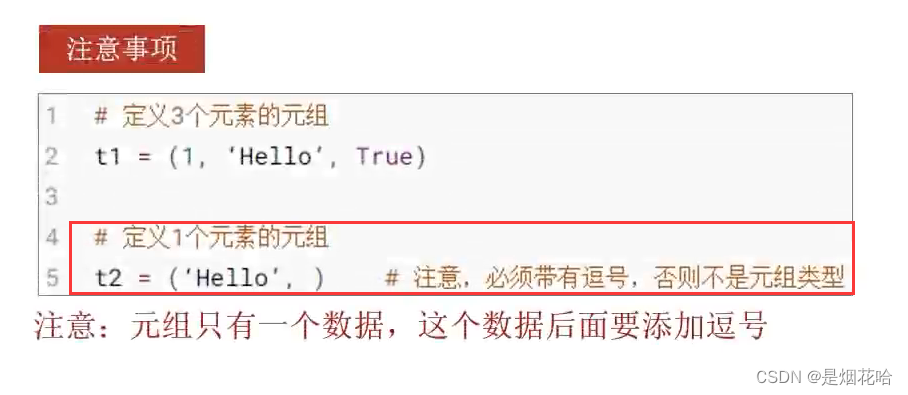
创建元组
() 表示一个空元组
元组操作
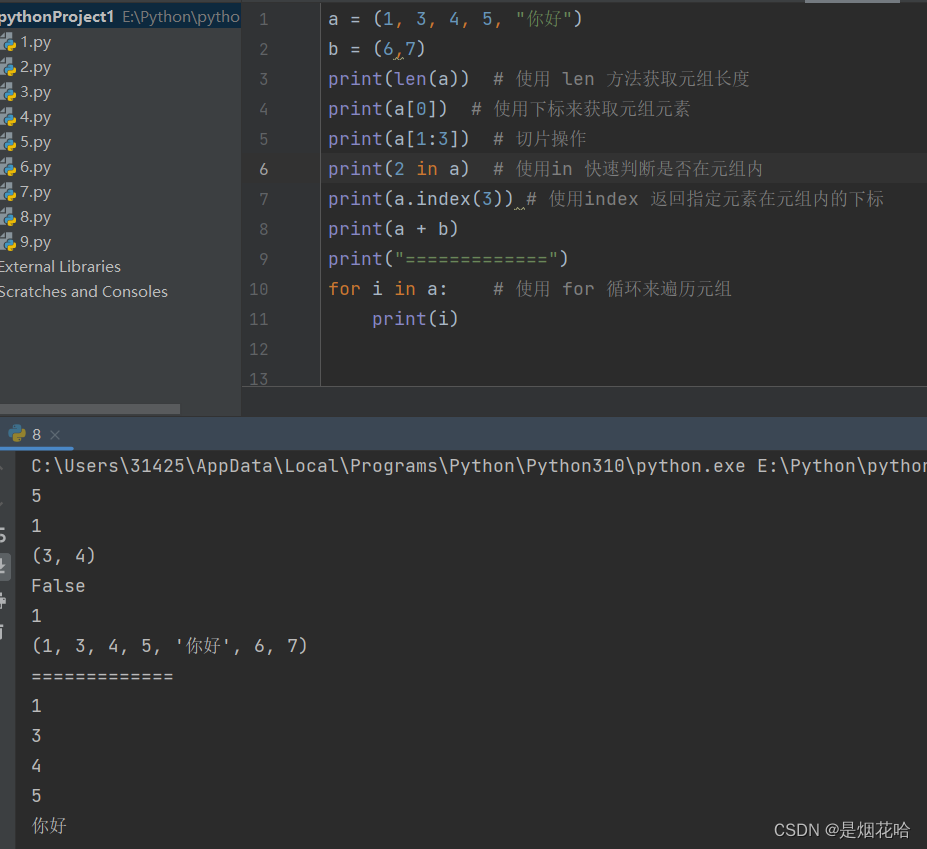
元组内的元素是不能修改的,因此元组的读操作和列表的读操作是一样的,但是写操作就不能实现了。
1、像读操作,比如 访问下标, 切片, 遍历, in, index, + 等, 元组也是一样支持的2、像写操作, 比如 修改元素, 新增元素, 删除元素, extend 等, 元组则不能支持
列表和元组的区别
1、列表是可修改的(可以修改元组内元素),元组是不可修改的(不可以修改元组内元素)
2、列表定义后好,是可以变的,可以进行增加、删除和修改操作
元组定义好后,是不可变的,不能进行增加、删除和修改操作
既然已经有了列表 , 为啥还需要有元组 ?元组相比于列表来说, 优势有两方面:1、你有一个列表, 现在需要调用一个函数进行处理。 但是你有不是特别确认这个函数是否会把你的列表数据弄乱. 那么这时候传一个元组就安全很多.2、字典, 是一个键值对结构. 要求字典的键必须是 "可hash对象" (字典本质上也是一个hash表). 而一个可hash对象的前提就是不可变. 因此元组可以作为字典的键, 但是列表不行。
六、字典
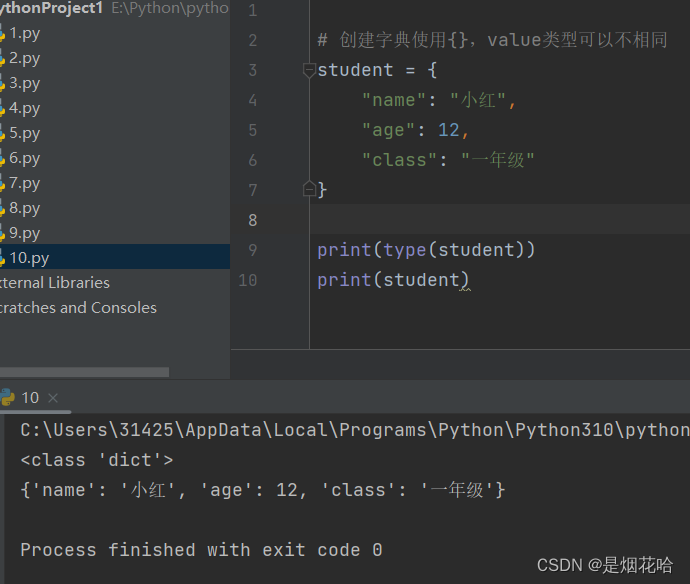
字典是一种存储 键值对 的结构,可以理解为 key :value 结构。字典中的key的类型必须保持一致,而value的类型可以不相同。
创建字典
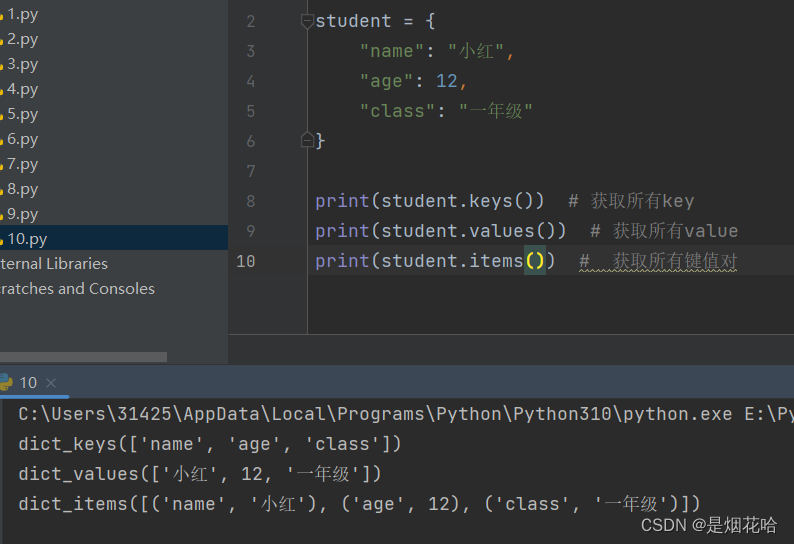
查找 key
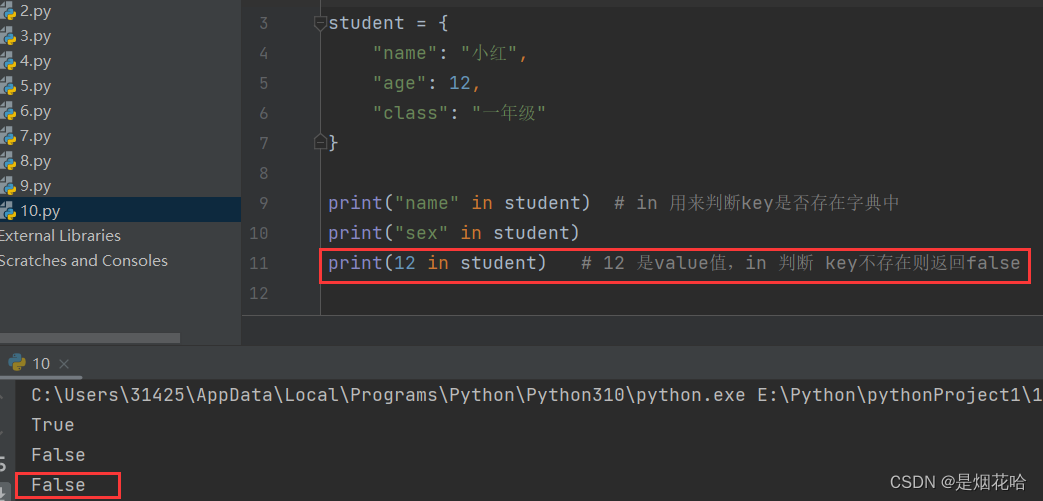
获取value值
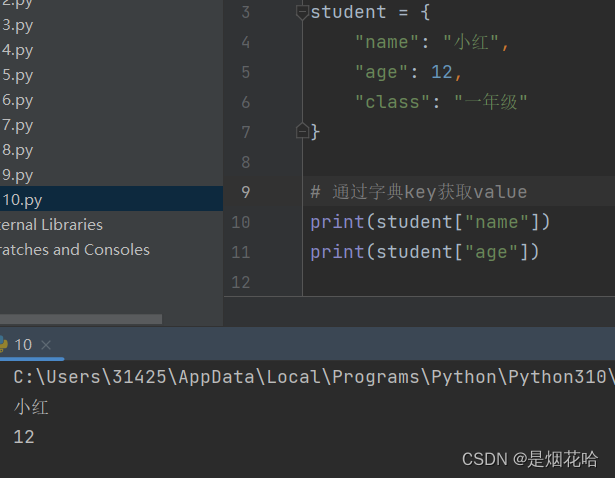
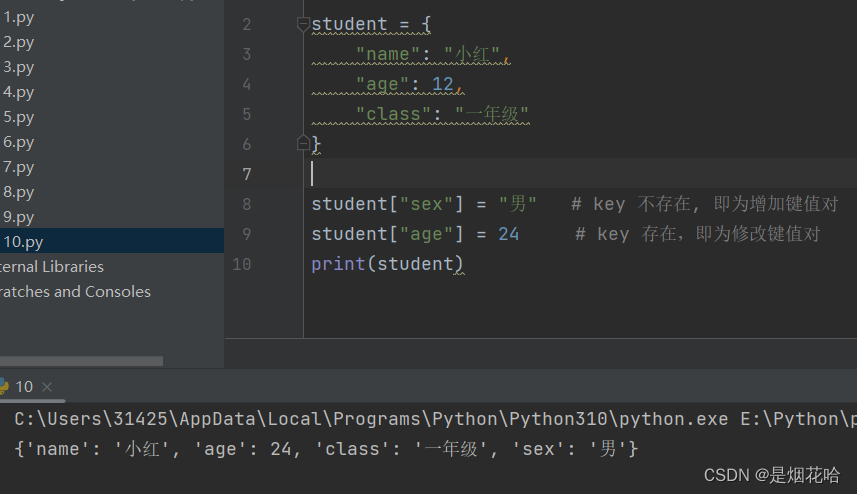
增加/修改元素
增加、修改元素只需要对key对应的value值进行修改即可,若字典中不存在该key就增加该键值对,反之则修改该键值对。
删除元素
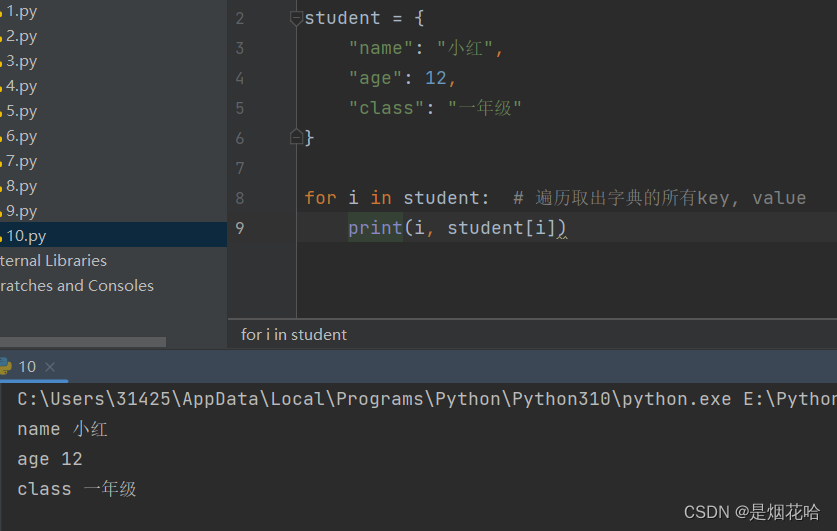
遍历字典
七、字符串
字符串之前已经介绍过,使用" "或者' '包含的为字符串。注意点:字符串是不可变的,不支持修改操作。
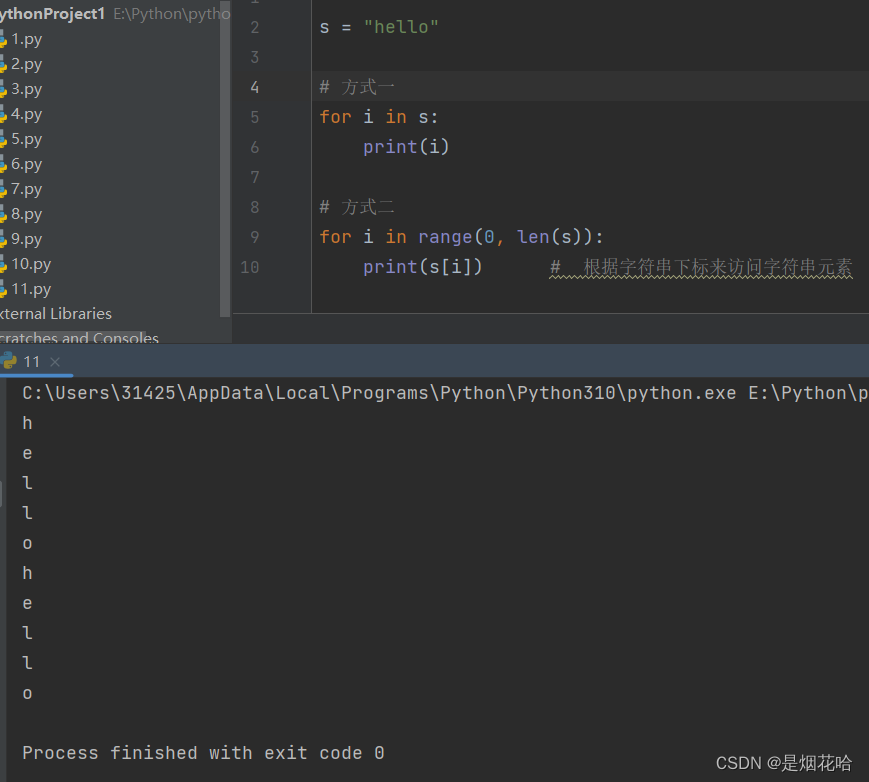
遍历字符串
字符串可以根据下标来访问字符串元素,不可以根据字符串下标来进行修改操作。
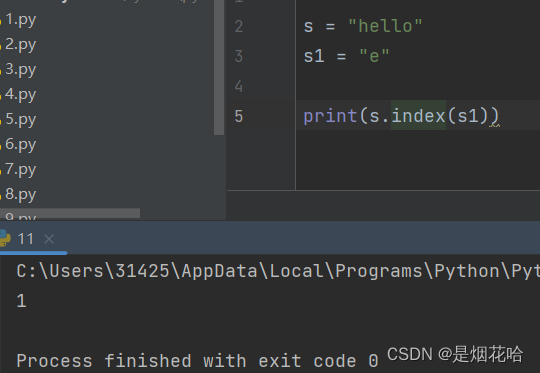
index 方法
字符串可以快速判断子字符串是否在字符串,并返回字符串位置的下标。在Java 中也有类似方法:indexOf()方法
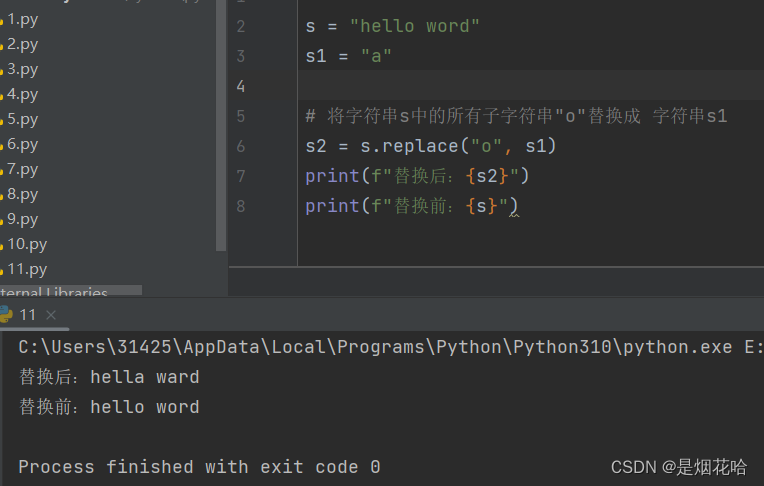
字符串替换replace()
语法: 字符串.replace(字符串1,字符串2)
功能: 将字符串内的全部字符串1,替换为字符串2。注意: 不是修改字符串本身,而是得到了一个新字符串。
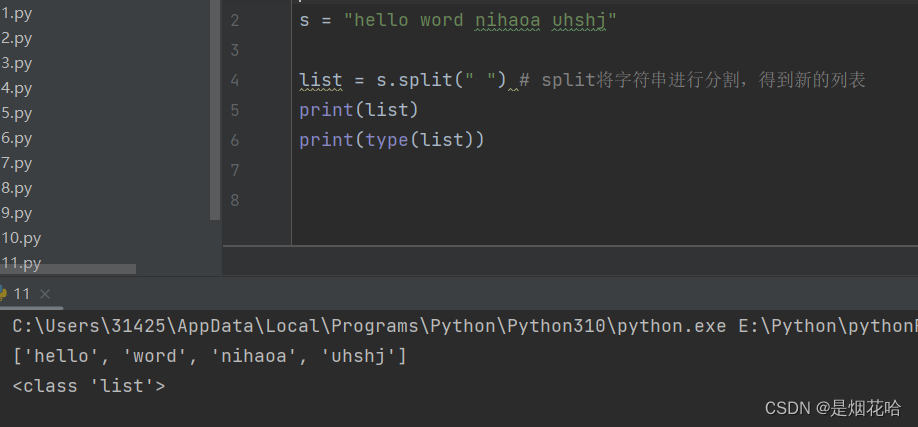
字符串分割split()
使用split()按照指定子字符串将字符串进行分割成多个字符串,并存入列表对象中。
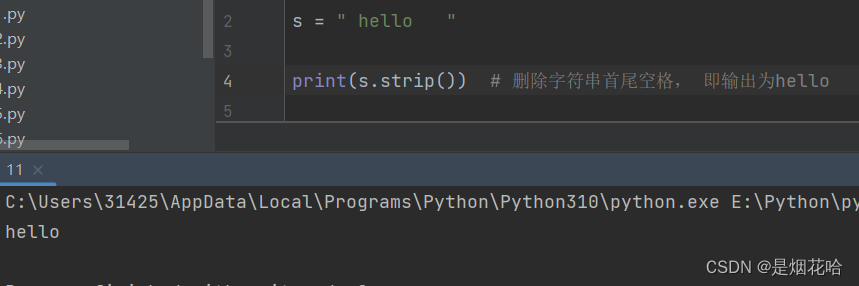
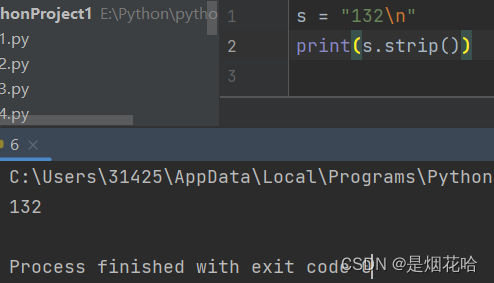
strip()方法
1、不传入参数 默认为 删除字符串前后空格和换行符\n, Java语言里面也有类似方法:trim()
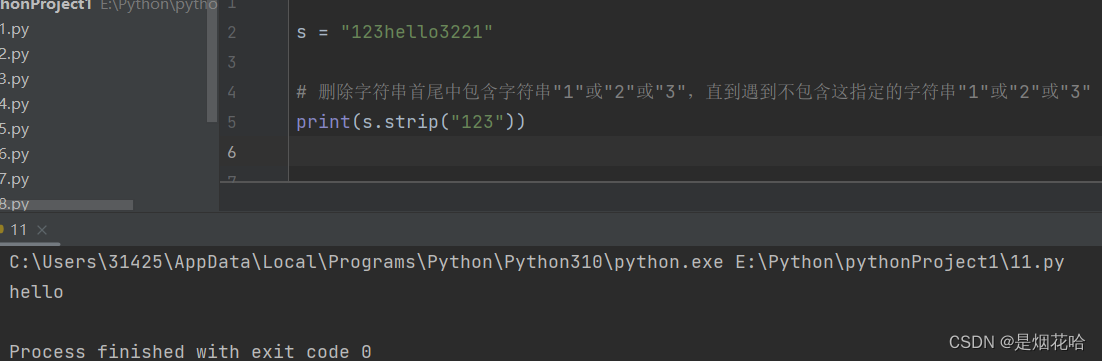
2、传入参数 为 删除字符串前后指定字符串
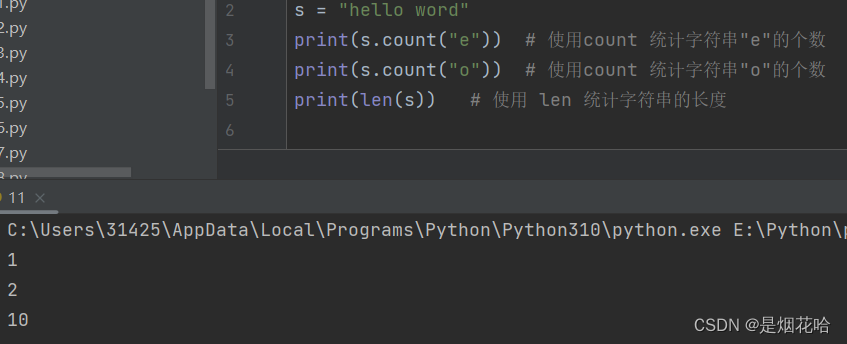
count() 方法
使用 count 方法来统计字符串中指定字符串的个数
使用 len 方法来统计字符串的长度
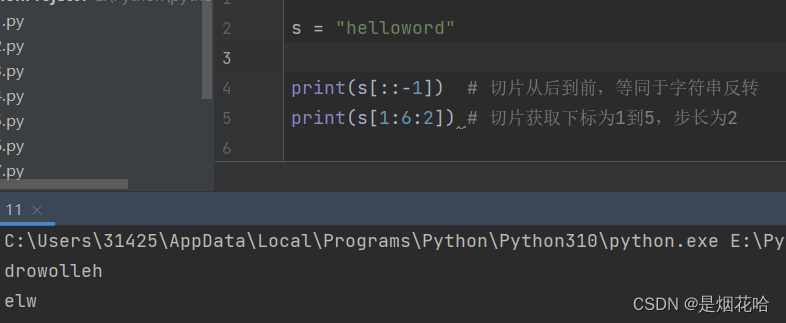
切片操作
s[::-1]可以理解为将字符串反转
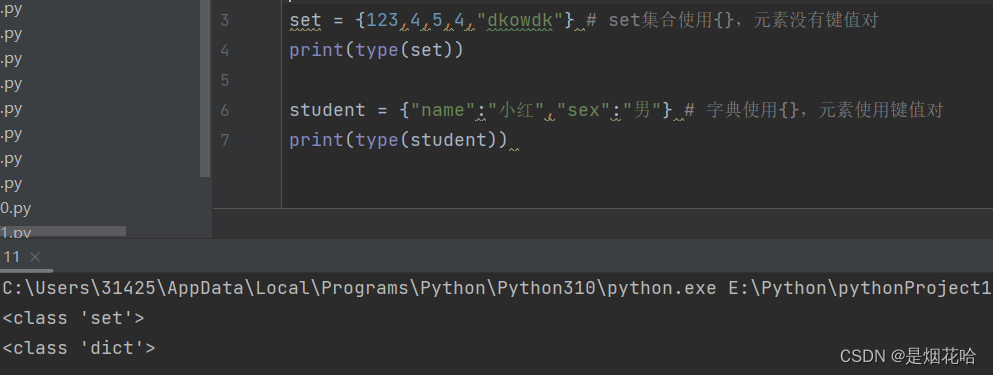
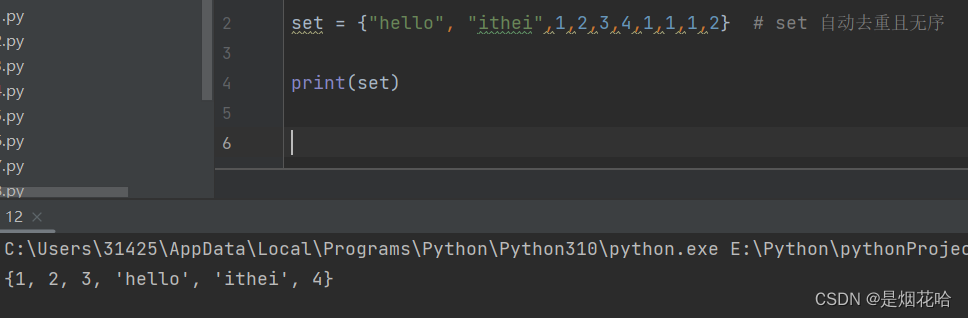
八、set集合
前面已经学习过了列表、元组、字符串和字典,其中 列表可以修改,支持重复元素且有序,元组、字符串不可以修改,支持重复元素且有序。
此次的集合为set集合,支持自动去重且元素是无序的
创建set集合
创建set集合为{a,b,c}
创建一个空set集合为set()
创建字典也是{},只不过字典内元素为key:value键值对,注意区分。
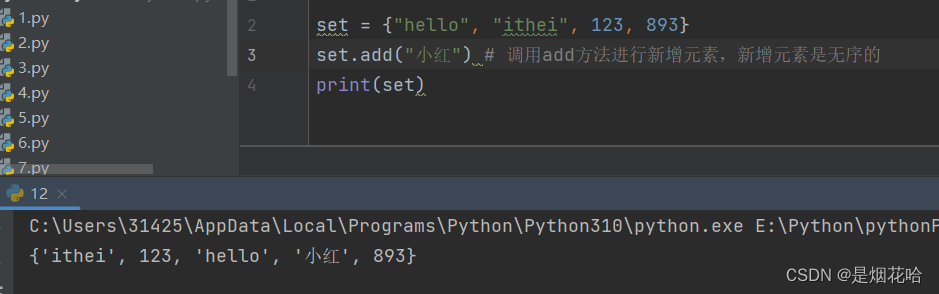
新增元素
set集合使用add() 方法进行增加元素,新增元素是无序的。
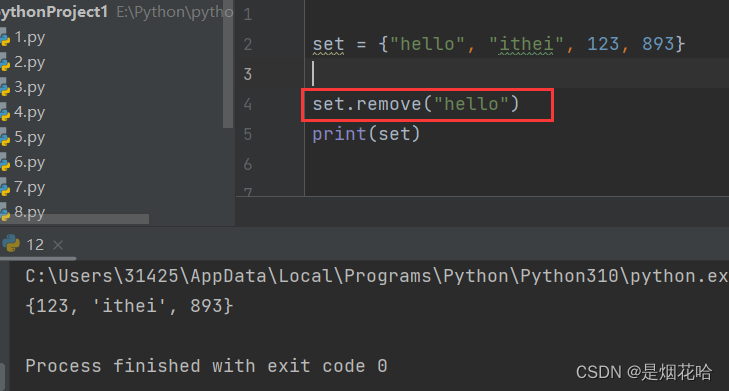
删除元素
set集合删除元素使用remove()方法。
取出2个集合的差集difference()

消除2个集合的差集difference_update()

2个集合合并union()

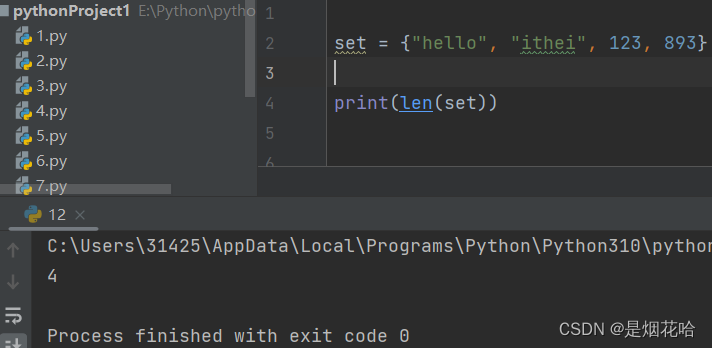
统计集合内元素len()
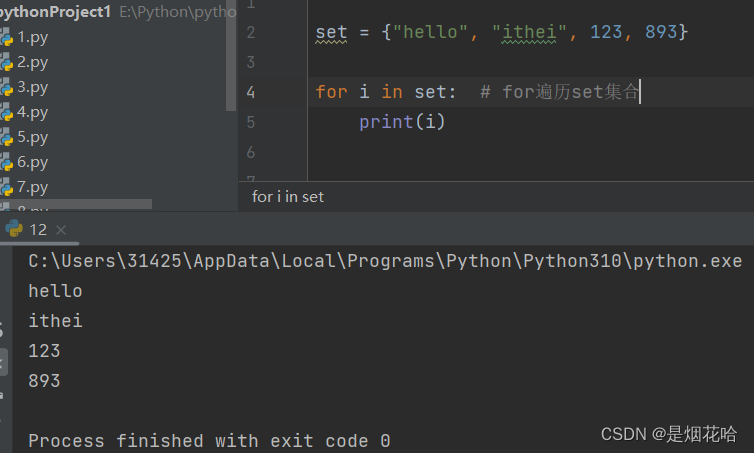
遍历set集合
九、五大数据容器总结
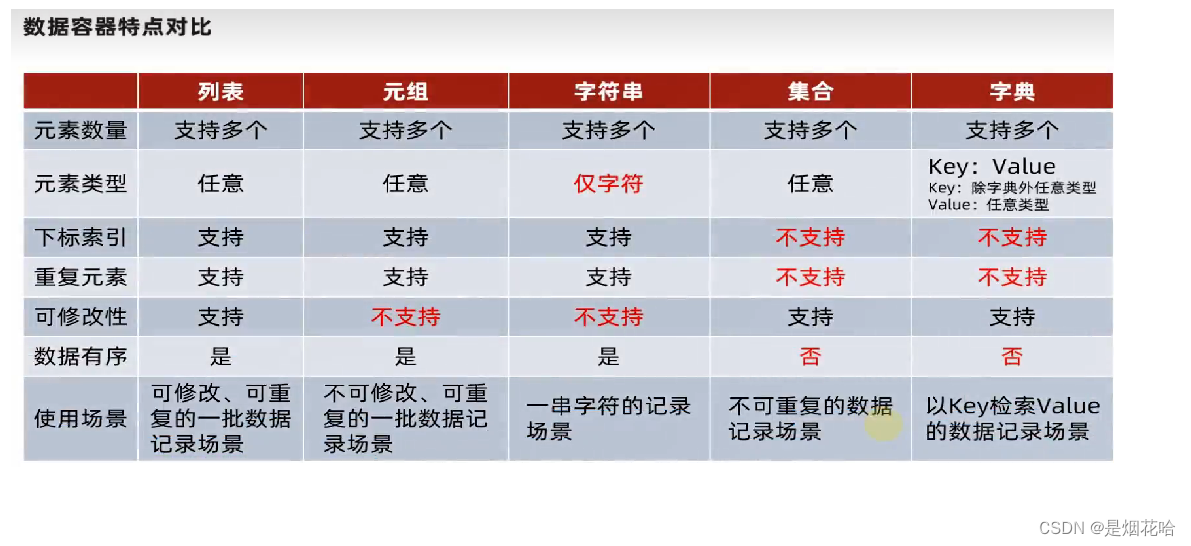
求最大值max、最小值min

容器的通用转换功能

容器通用排序功能
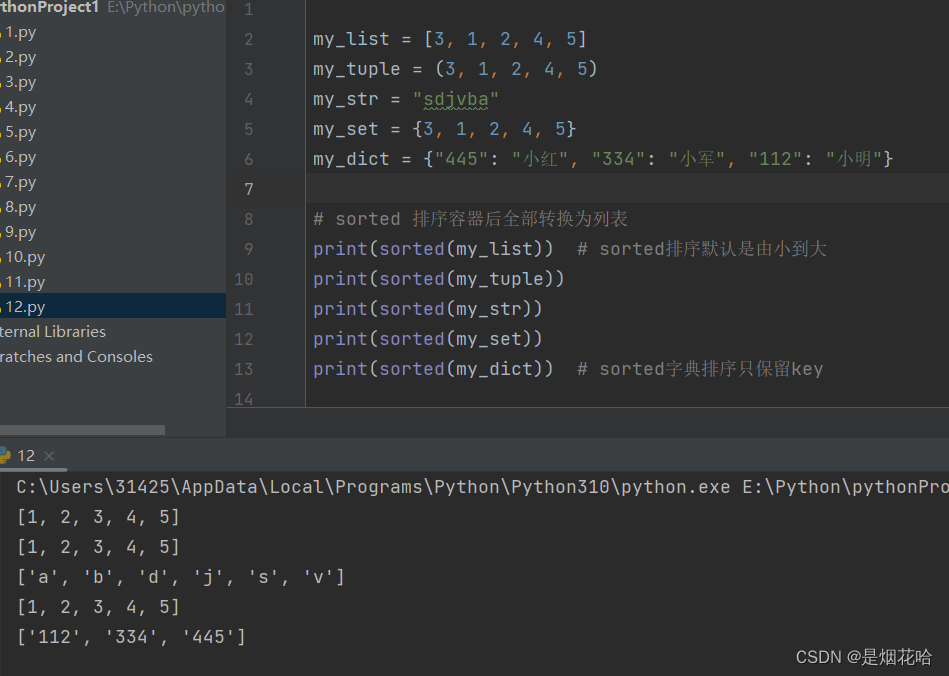
通用排序方法使用sorted()方法,默认是由小到大进行排序,而且排序后的容器全都自动转换为列表。
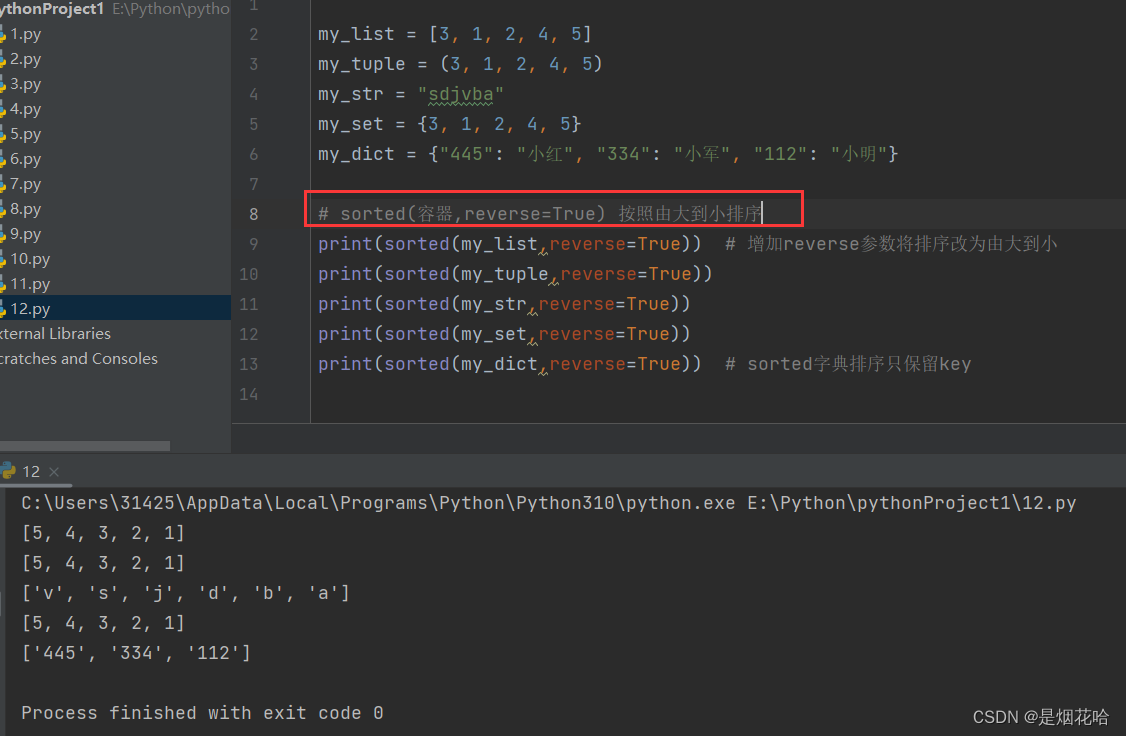
若需要由大到小进行排序,就只需在sorted()方法里面增加一个参数:reverse=True。(reverse代表反转,True代表真)
(Java编程语言中也有类似排序方法:sort(), 比如 Arrays.sort()就是将数组按照由小到大进行排序)
注意:字典排序后转换为列表,只保留key值,value值全部抛弃。
由大到小进行排序:sorted(容器,reverse=True)
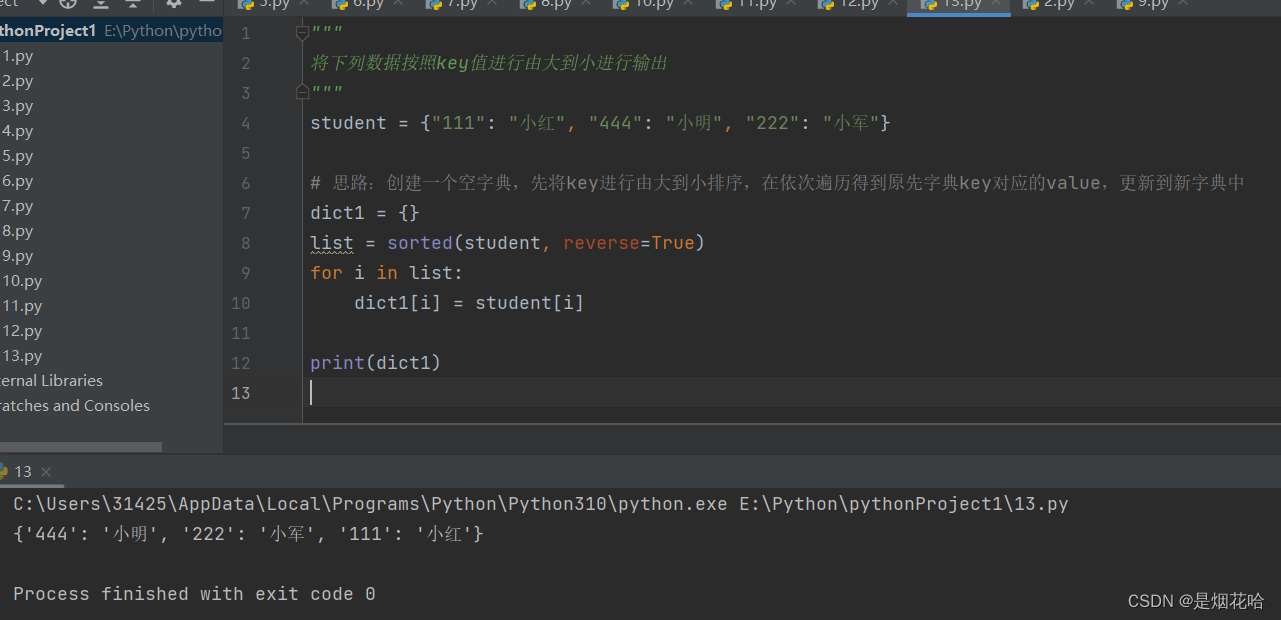
例题:将字典内元素按照key进行由小到大进行排序
十、文件
文件概念
内存中存放的数据在计算机关机后就会消失。要长久保存数据,就要使用硬盘、光盘、U盘等设备。为了便于数据的管理和检索,引入了“文件”的概念。
一篇文章、一段视频、一个可执行程序,都可以被保存为一个文件,并赋予一个文件名。操作系统以文件为单位管理磁盘中的数据。
一般来说,文件可分为文本文件、视频文件、音频文件、图像文件、可执行文件等多种类别。
文件操作
在文件操作中,包含打开文件、读文件、写文件和关闭文件等操作。
1、打开文件
# 打开文件语法
(1) f = open('E:/测试.txt', 'r',encoding="UTF-8")
(2) with open('E:/测试.txt', 'r',encoding="UTF-8") as f:
# 文件操作代码块
此时的 f 是 open 函数的文件对象
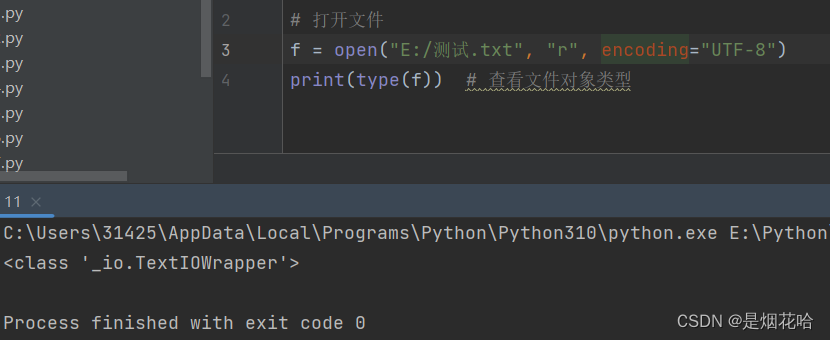
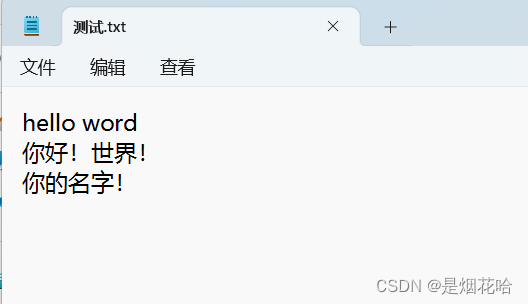
测试.txt文件内容为:
2、读文件
读文件的方法有read() 、 readLines()、readLine() 和 for循环
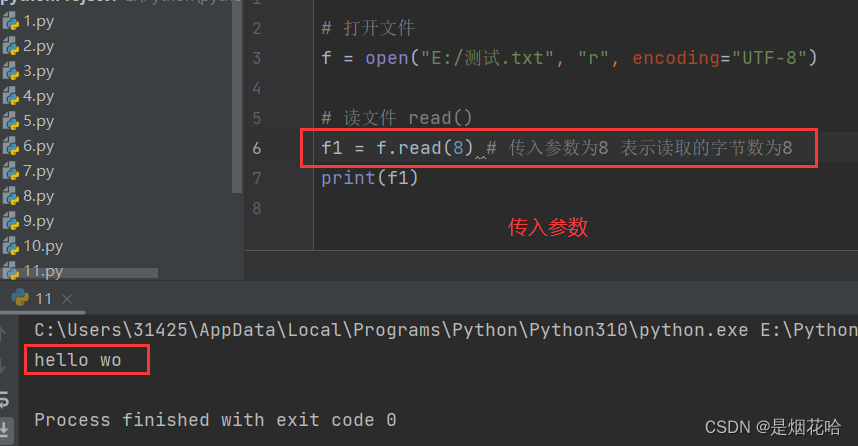
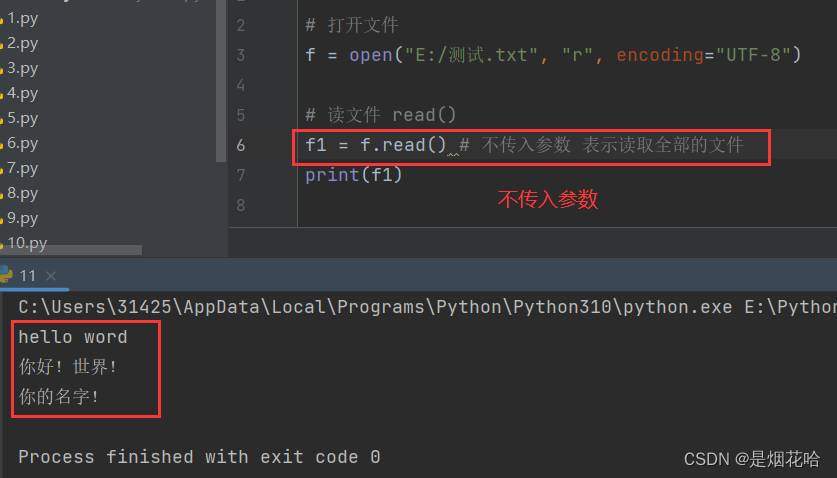
read()语法格式:文件对象.read(num)
num表示要从文件中读取的数据长度(单位是字节),如果没有传入num,那么表示读取文件中的所有数据。
readLines()语法格式:文件对象.readLines()
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据转换为字符串。
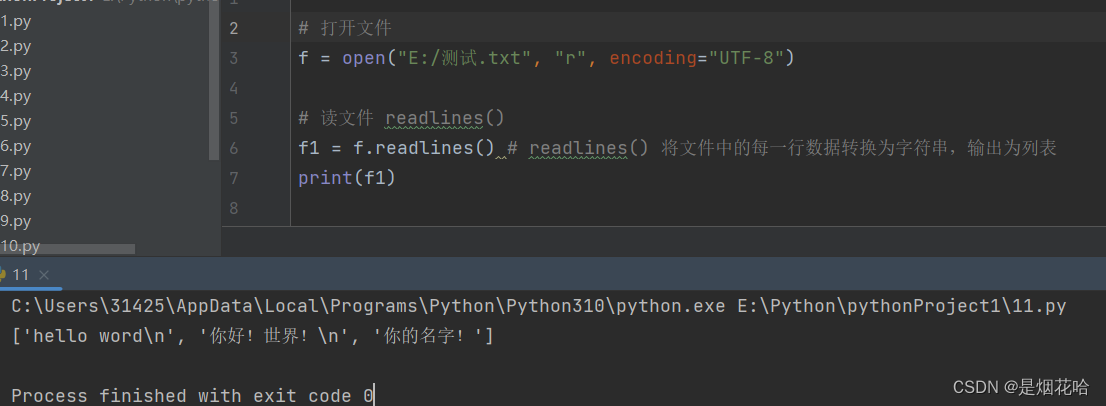
readLine()语法格式:文件对象.readLine()
readLines()方法每次只能读取一行,每调用一次就读取一行,调用两次就读取两行,每一行的数据转换为字符串
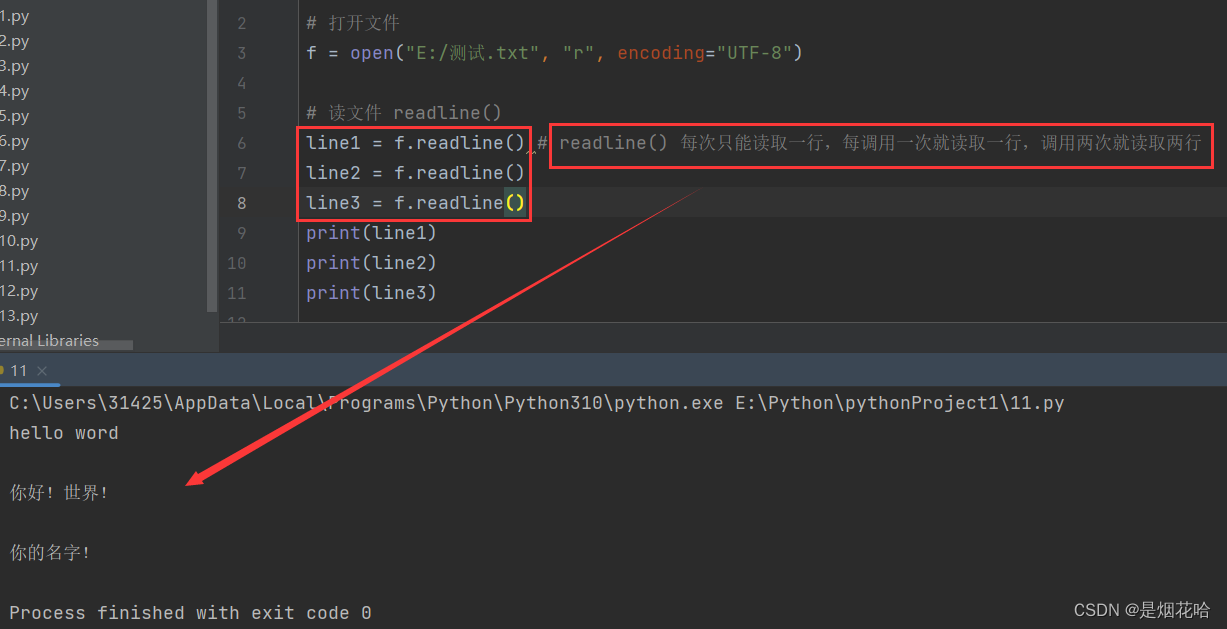
for循环:循环遍历文件的每一行数据
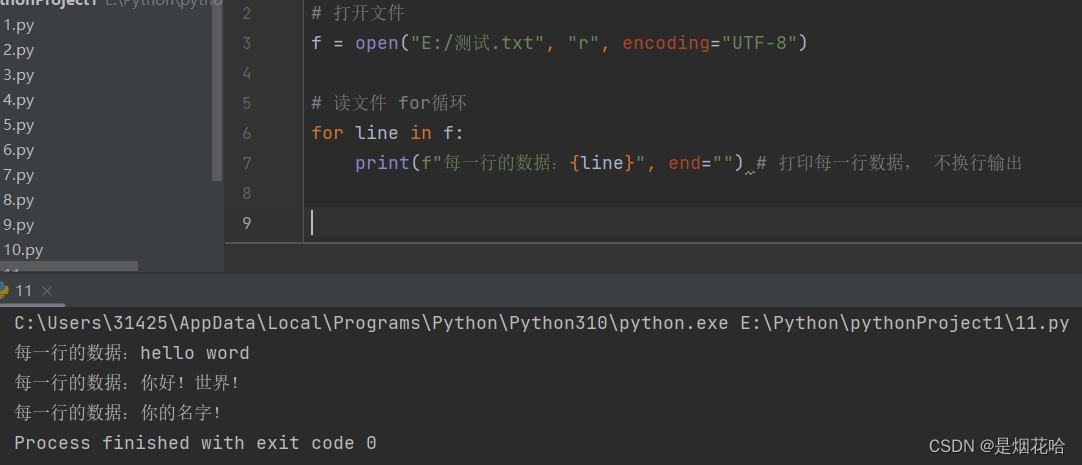
3、写文件
- 写文件, 要使用写方式打开, open 第二个参数设为 "w" 或 "a" (牢记:在写文件操作时,必须修改open方法的第二个参数)
- 使用 write() 方法写入文件
- 使用 'w' 实现"覆盖写入",一旦打开文件成功, 就会清空文件原有的数据。
- 使用 'a' 实现 "追加写入", 此时原有内容不变, 写入的内容会存在于之前文件内容的末尾。
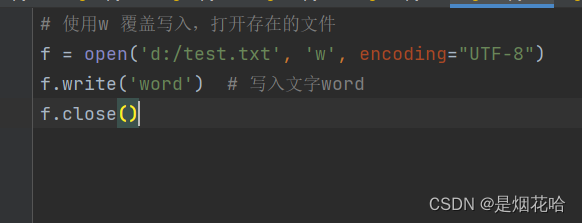
(1)覆盖写入:w
会清空文件内容,重新写到文件中
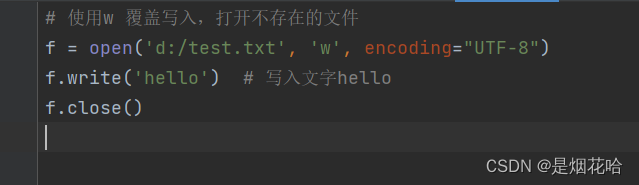
运行以上程序后,查看D盘下test.txt文件内容
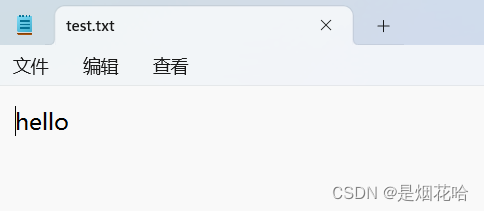
此时仍然使用 w 来进行写入文件,写入文字:word。
之前test.txt文件内容:hello已被清空,重新写入文字:word

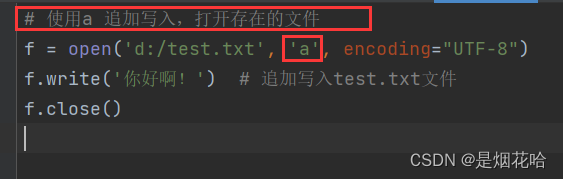
(2)追加写入:a
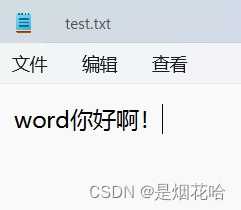
不会清空文件内容,写的内容会追加到文件末尾
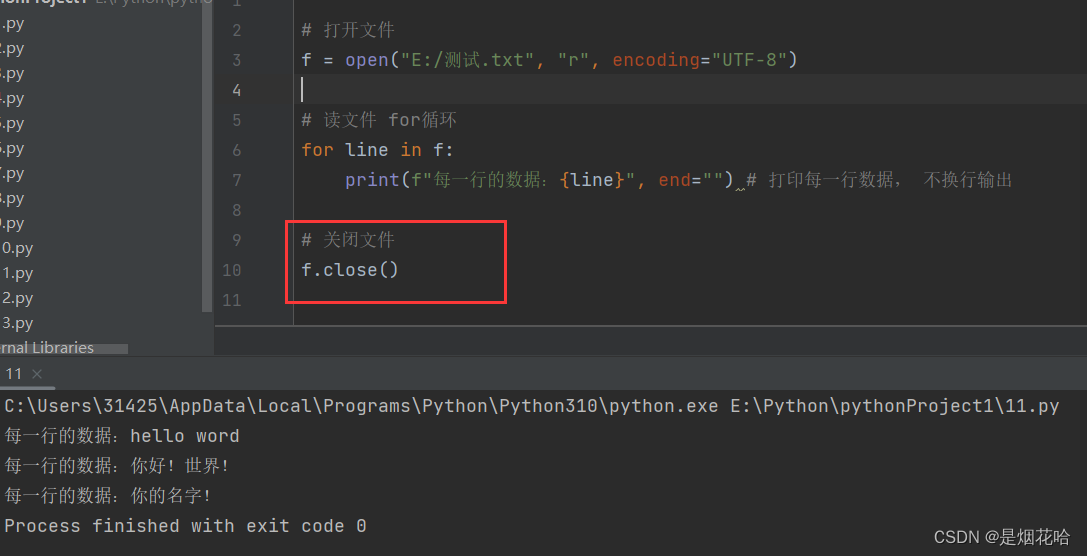
4、关闭文件
文件的关闭方法是close(),文件打开使用完毕后需要将文件进行关闭,此时需要调用close()方法。
例题练习:统计文件中的某个单词出现次数

代码参考:
解题思路采用最简单的read()方法来读取文件,在使用count()方法来统计指定字符串。(推荐使用)
"""
例题练习:统计文件中的"hello"单词出现次数
"""
# 思路:读取文件使用read() 或者 readlines() ,遍历每一个字符串,使用count()统计指定字符串
# 打开存在的文件
f = open('d:/test.txt', 'r', encoding="UTF-8")
# 方式一:使用readlines(),每行数据读取到列表,再遍历列表每一个字符串,使用count()统计指定字符串
list = f.readlines()
count = 0
for i in list:
count += i.count("hello")
print(count)
# 方式二:使用read()全部读取为字符串,使用count()统计指定字符串
s = f.read()
count = s.count("hello")
print(count)
f.close()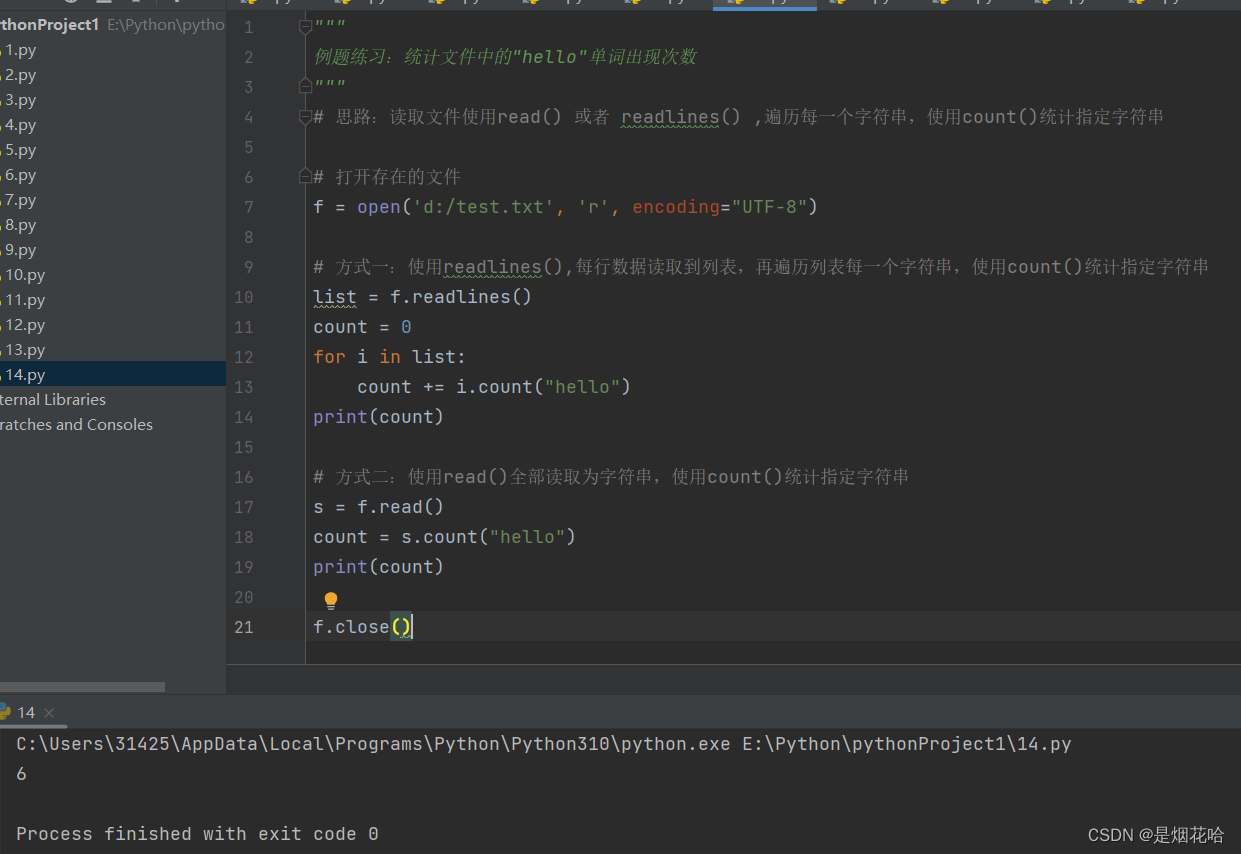
十一、异常
异常就是程序运行的过程中出现了错误
异常捕获
(1) 捕获常规异常
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码示例:当以"r"读的形式打开一个不存在的文件时,此时程序会报错。

(2)捕获指定异常
当出现了我们指定的异常条件时,此时才会取捕获异常。
当出现的异常不是我们指定异常时,此时不会捕获,并且会直接跳出程序异常报错。
基本语法:
# 示例:需要捕获变量名称未定义的异常
try:
print(name)
except NameError as e:
print("变量名称未定义,发生异常")(3)捕获多个异常
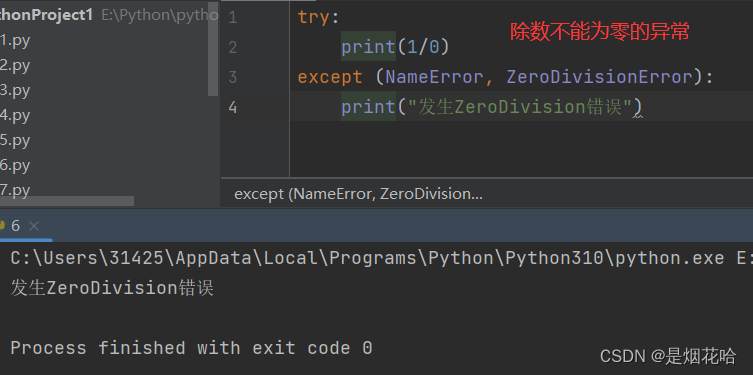
当需要捕获多个异常时,可以把需要捕获的异常类型名字,放到except后,并使用元组的形式进行书写
基本语法:
# 捕获多个不同类型异常,异常类型写在元组内
try:
print(1/0)
except (NameError, ZeroDivisionError):
print("发生ZeroDivision错误")捕获异常执行结果:
(4) 捕获全部异常
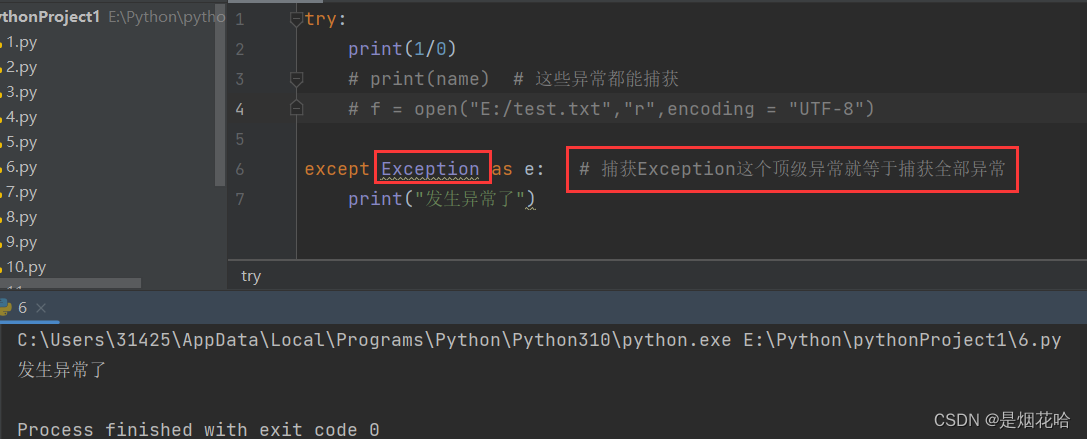
捕获全部异常,使用最开始的捕获常规异常也可以实现捕获全部的异常。
借助捕获 Exception 也可以捕获全部的异常。
基本语法:
try:
print(1/0)
# print(name) # 这些异常都能捕获
# f = open("E:/test.txt","r",encoding = "UTF-8")
except Exception as e: # 捕获Exception这个顶级异常就等于捕获全部异常
print("发生异常了")捕获异常执行结果:
异常else和finally
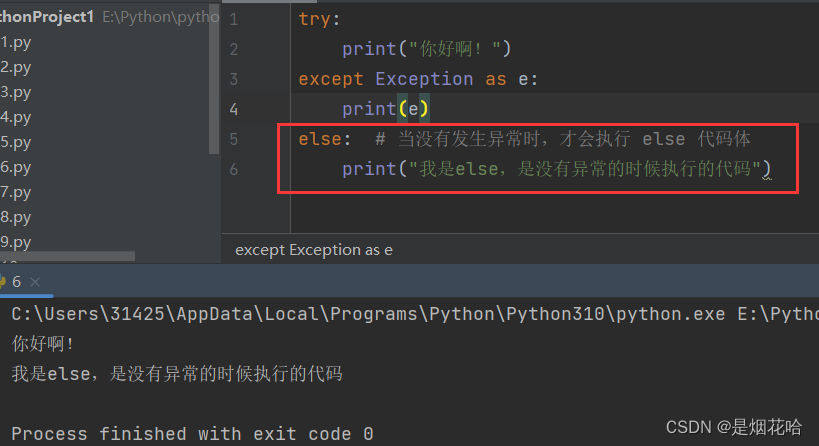
else 表示如果没有发生异常就要执行的代码,else 代码体可写,也可不写。
基本语法:
try:
print("你好啊!")
except Exception as e:
print(e)
else: # 当没有发生异常时,才会执行 else 代码体
print("我是else,是没有异常的时候执行的代码")捕获异常执行结果:
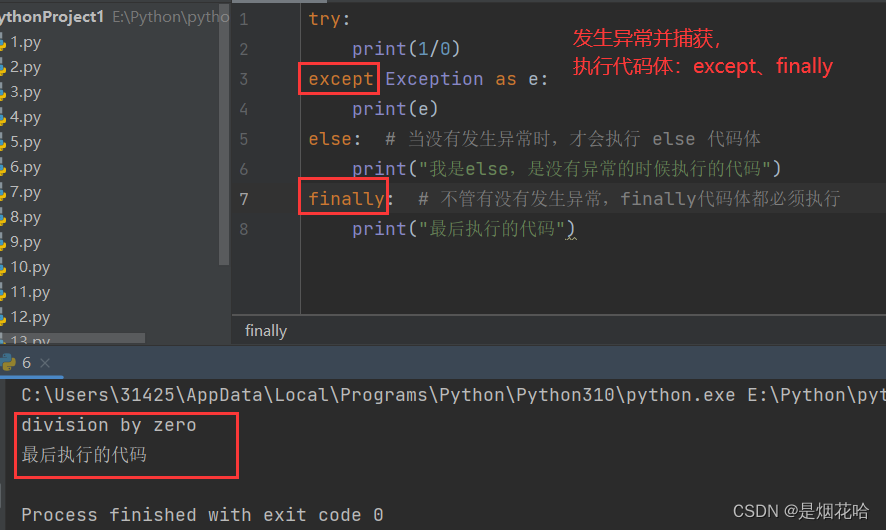
finally 表示的是无论是否发生异常,最后都要执行的代码,finaly 代码体可写,也可以不写(例如关闭文件)
基本语法:
try:
print("你好啊!")
except Exception as e:
print(e)
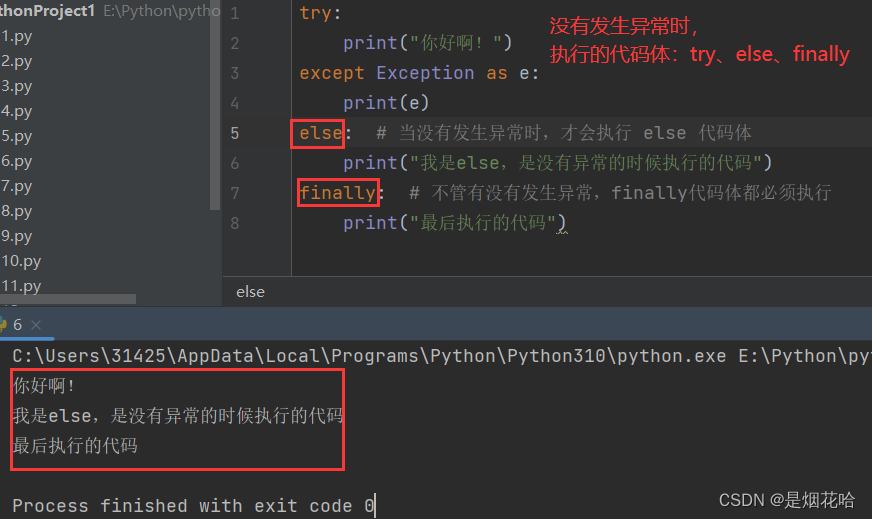
else: # 当没有发生异常时,才会执行 else 代码体
print("我是else,是没有异常的时候执行的代码")
finally: # 不管有没有发生异常,finally代码体都必须执行
print("最后执行的代码")捕获异常执行结果:
异常传递

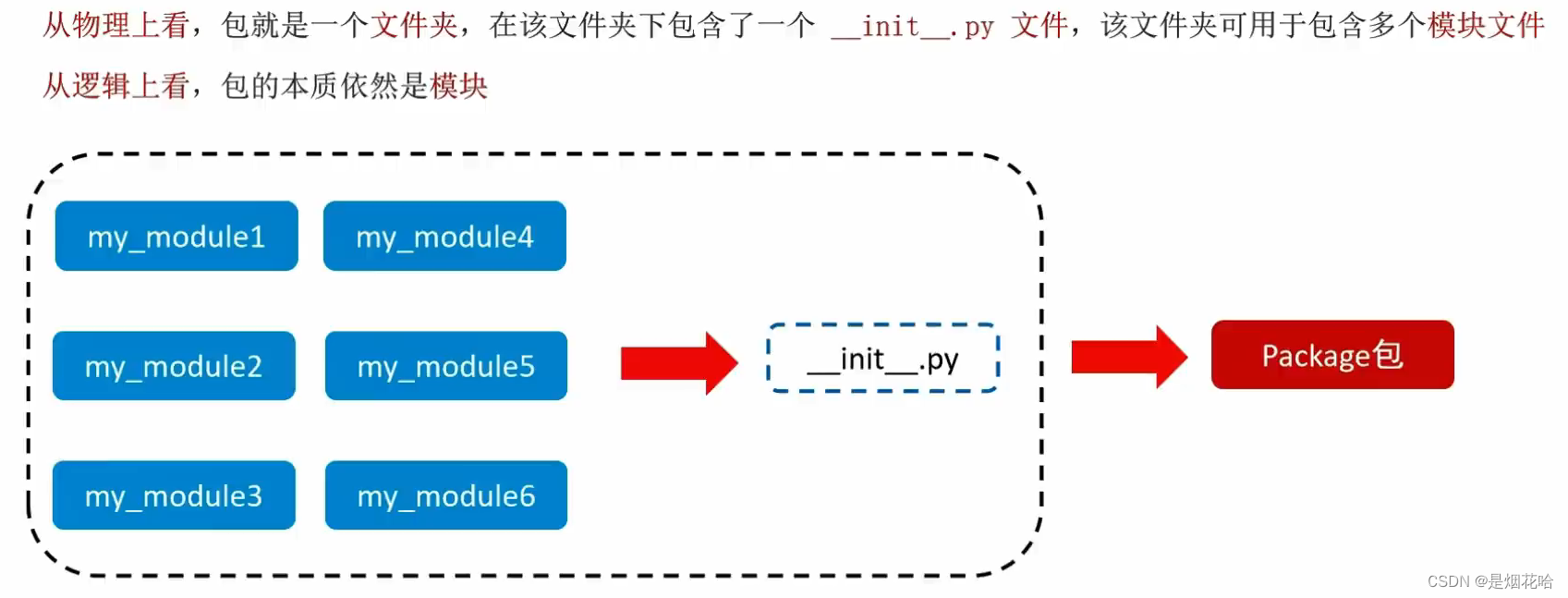
十二、模块、包
模块就是一个Python文件,里面有类、函数、变量等,我们可以拿过来用(导入模块去使用)
模块的导入方式

模块的导入方式最常用的:import 模块名
基本语法:
import 模块名
import 模块名1,模块名2
# 调用模块功能
模块名.功能名()
自定义模块
Python中已经帮我们实现了很多的模块,不过有时候我们需要一些个性化的模块,这里就可以通过自定义模块实现,也就是自己制作一个模块。
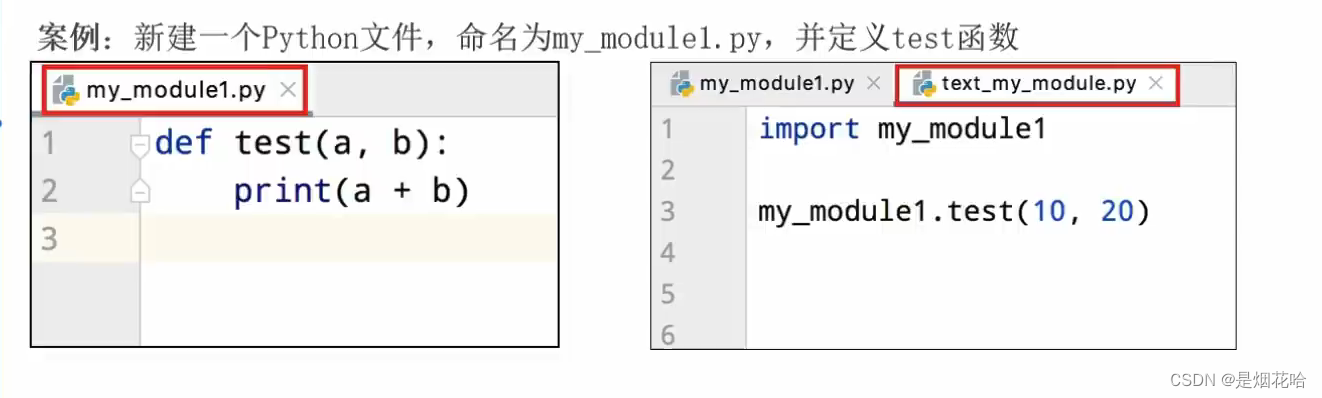
实现方法:
1、自己创建一个Python文件,定义函数。
2、然后在另外一个Python文件中导入该文件,调用方法。
自定义包
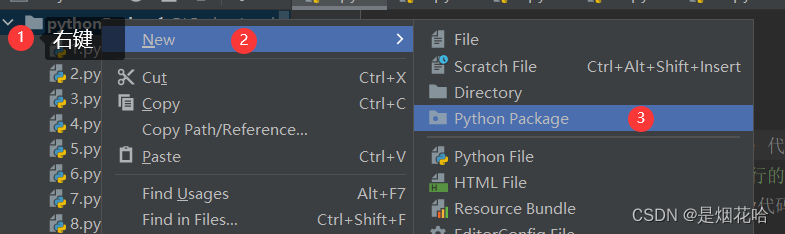
创建包就是点击项目名,鼠标右键创建一个Pyhton.backage。
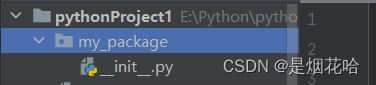
只有包括_init_.py文件的才可以叫做包,反之叫做普通文件夹。
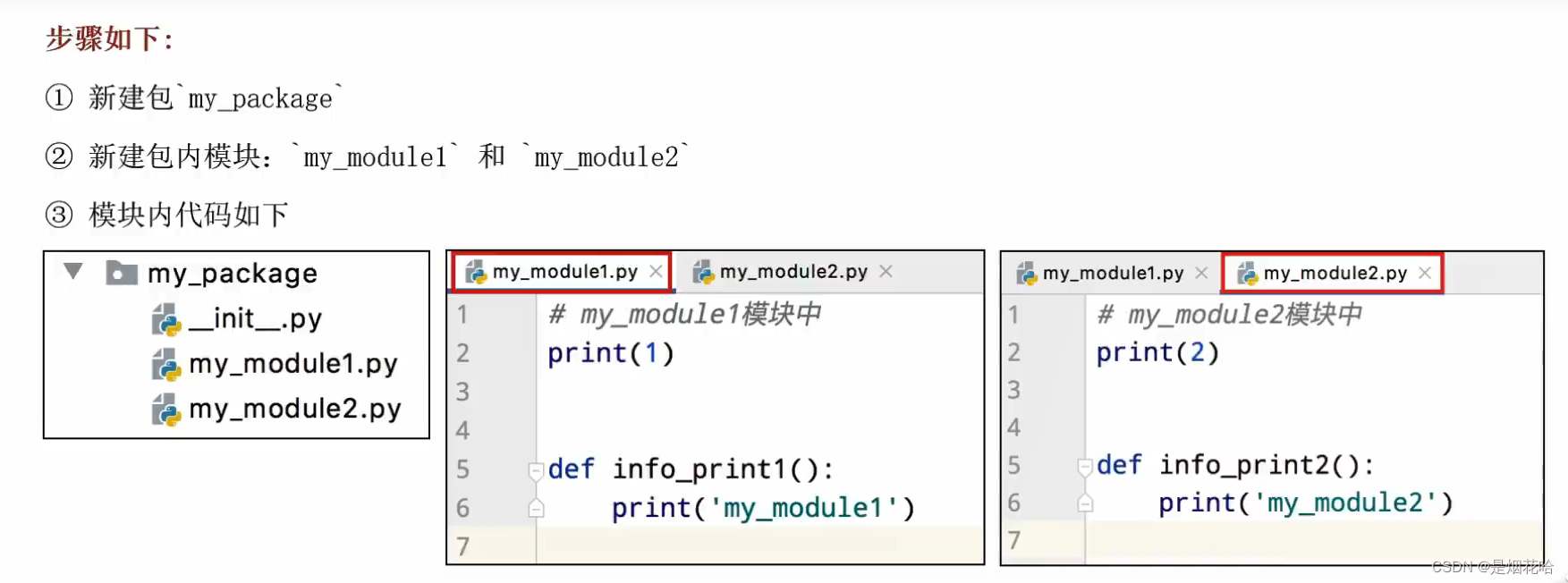
自定义包步骤
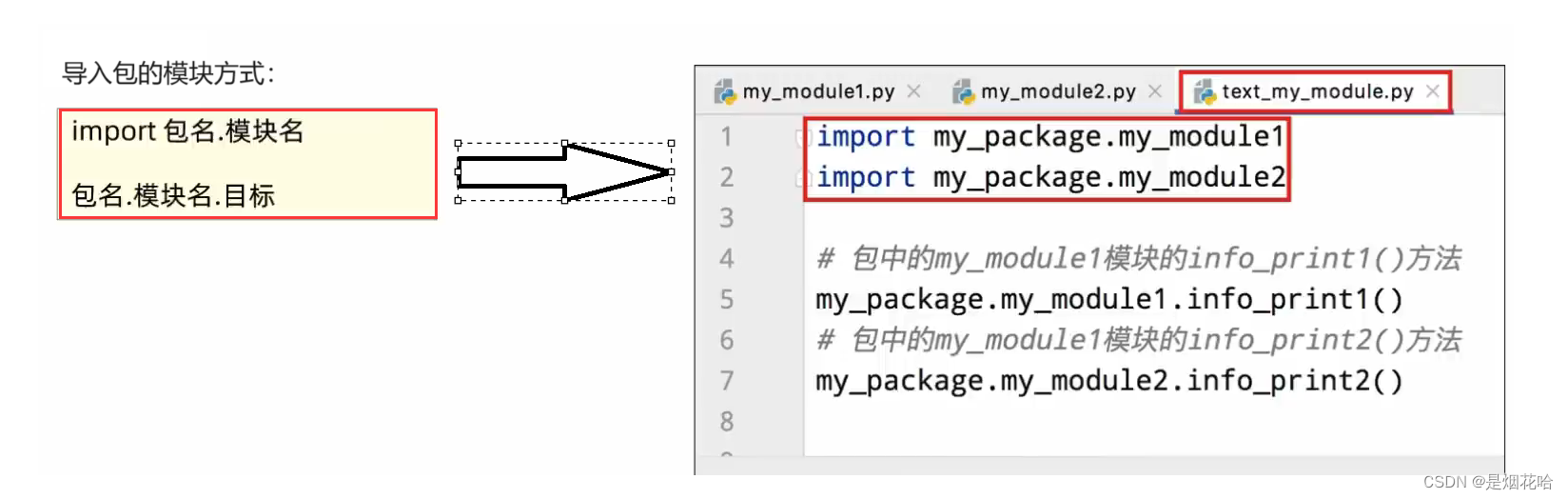
导入第三方包
包可以包含一堆的Python模块,而每个模块又内含许多的功能。可以理解为一个包就是一堆同类型功能的集合体。在Python程序的生态中,有许多非常多的第三方包(非Python官方),可以极大的帮助我们提高开发效率。
导入第三方包可以通过 pip 或者PyCharm 软件工具来进行下载。这里介绍使用PyCharm来进行下载第三方包。
步骤如下:
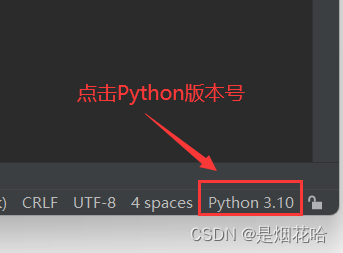
1、点击PyCharm 右下角Python版本
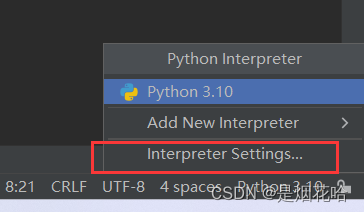
2、在弹出界面选择Interpreter Settings
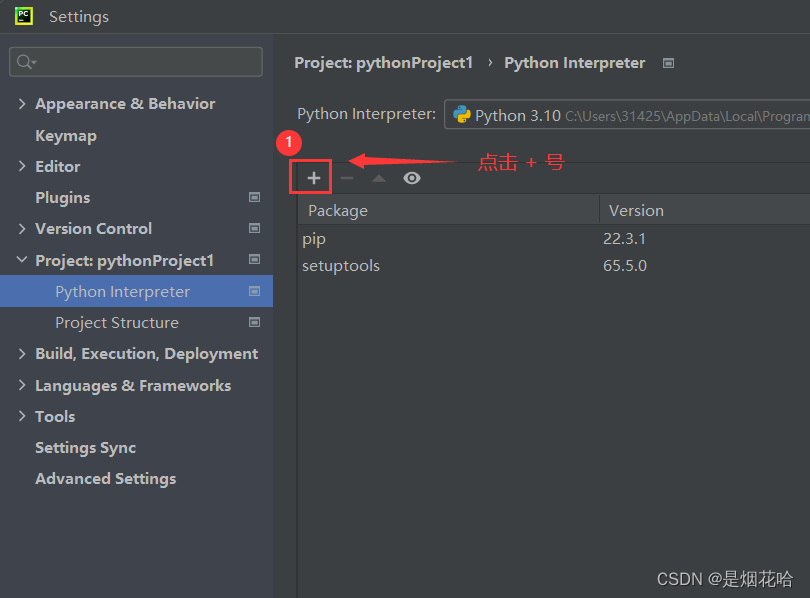
3、点击 + 号进入到第三方包搜索界面,输入需要下载的第三包。
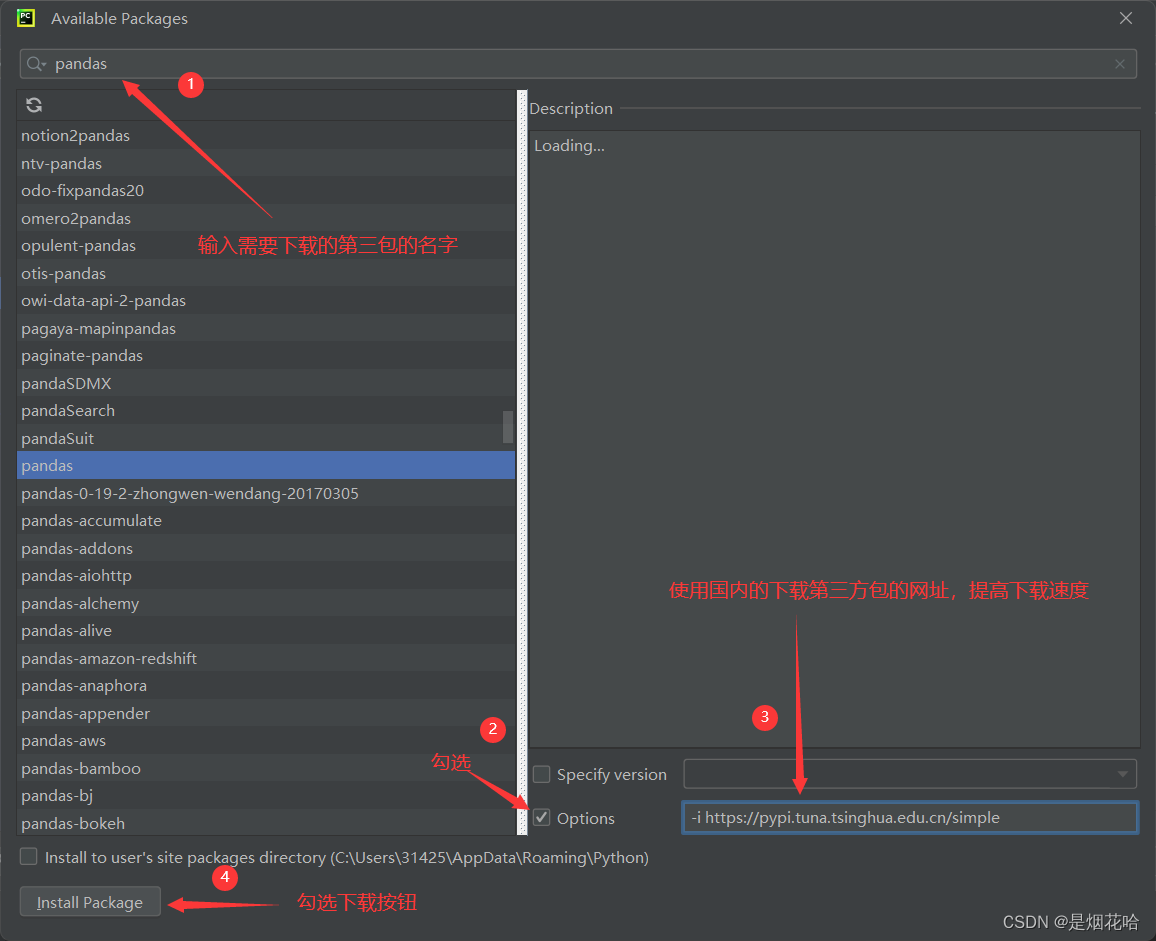
国内的下载第三方包的网址为:-i https://pypi.tuna.tsinghua.edu.cn/simple
-i https://pypi.tuna.tsinghua.edu.cn/simple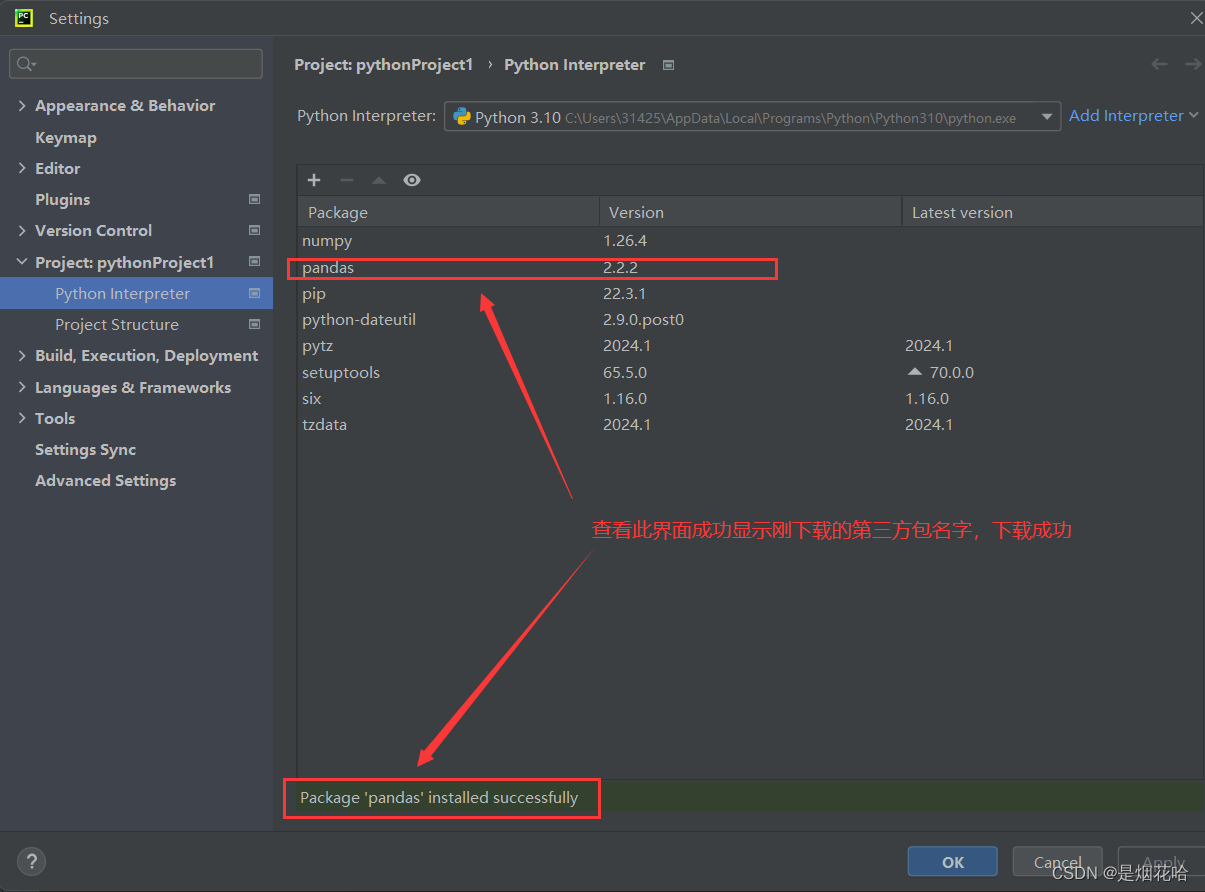
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









