






版本说明:
1.VMware:VMware Workstation 17pro
2.虚拟机操作系统:CentOS-6.7-x86_64
3.JDK:jdk-8u202-linux-x64
4.Hadoop:hadoop-2.7.4
资源已附上,请按需下载。
一、虚拟机及文件准备
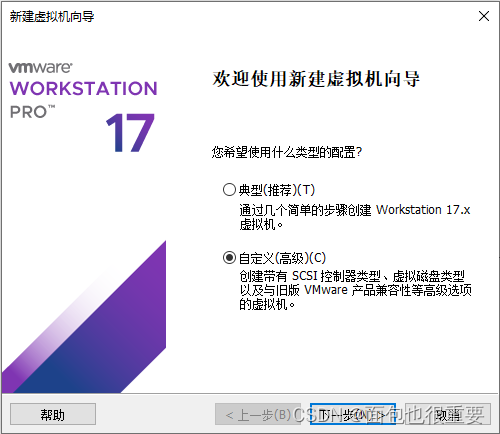
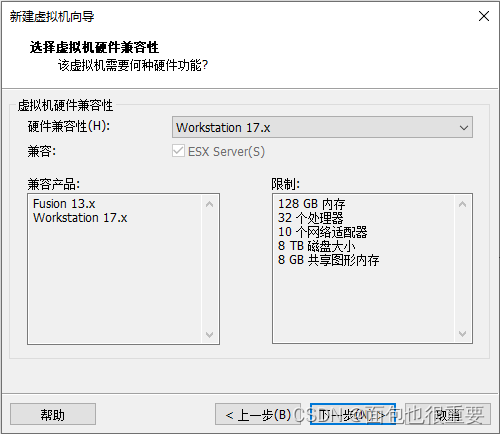
(一)创建虚拟机
1.选择新建虚拟机
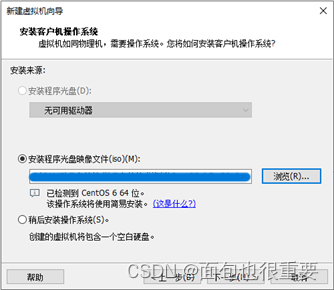
2.选择镜像文件:
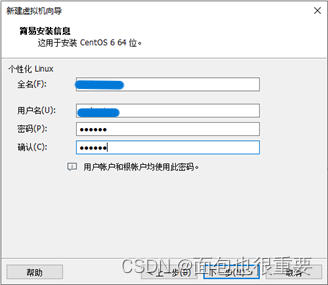
3.编辑用户名和密码:
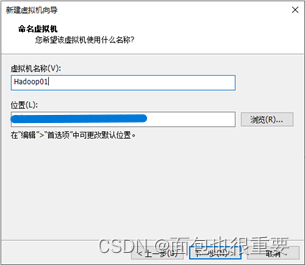
4.编辑虚拟机名称机虚拟机存储路径:
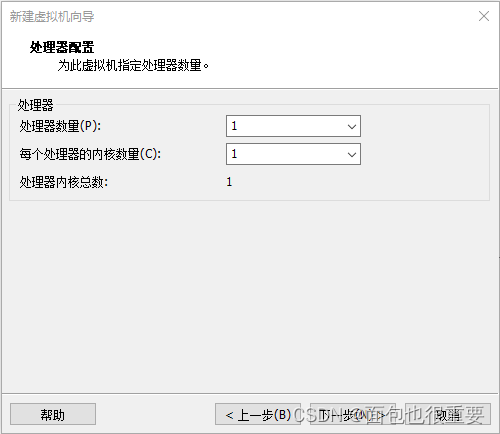
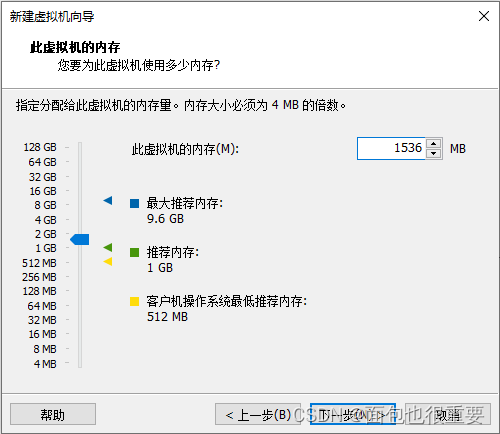
5.选择虚拟机配置:
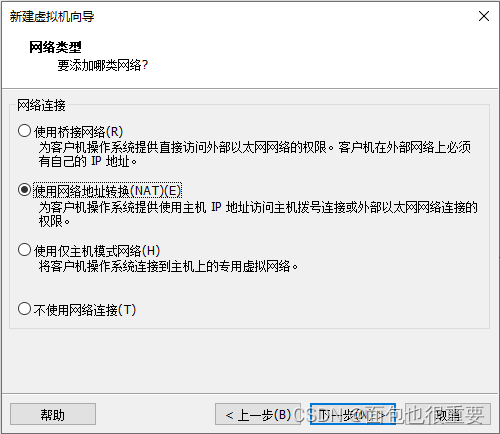
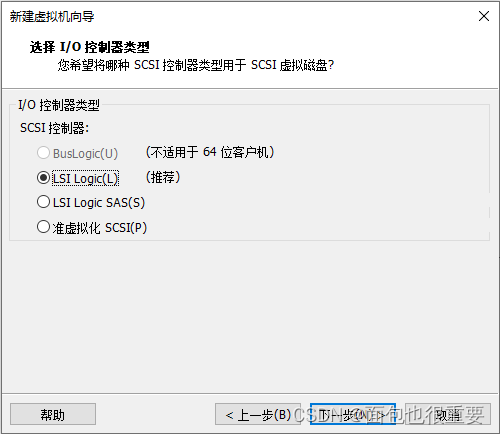
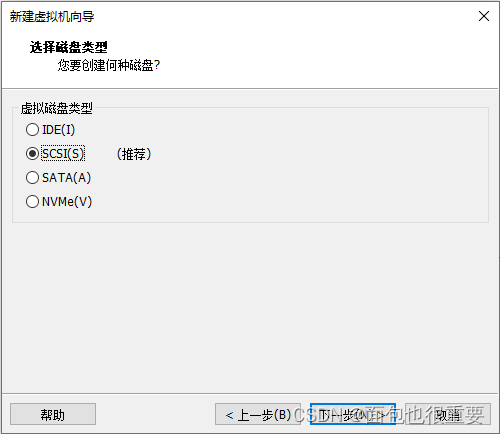
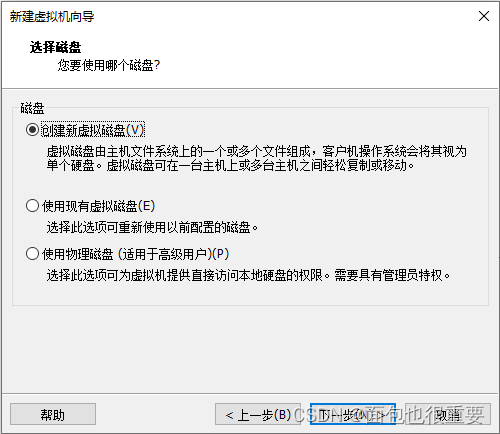
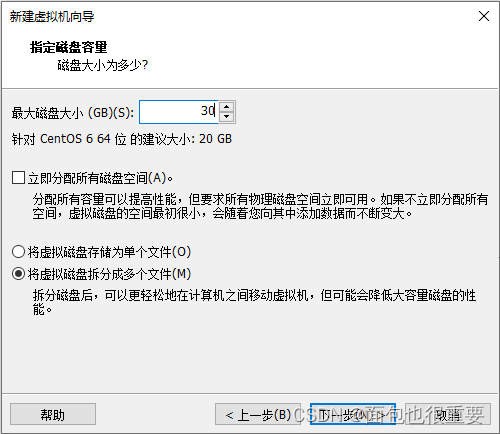
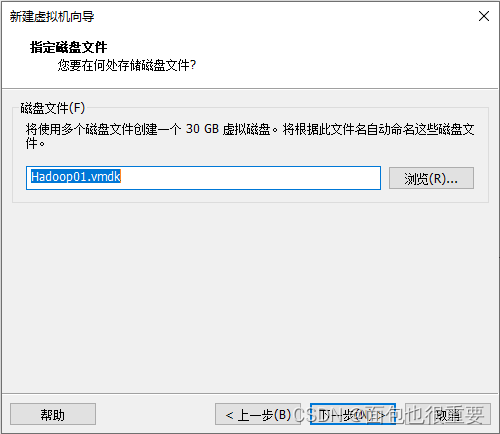
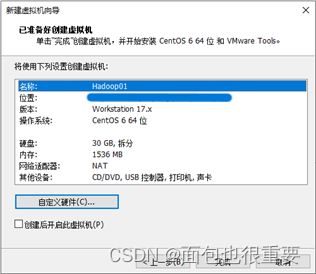
6.开启虚拟机,等待自动安装:
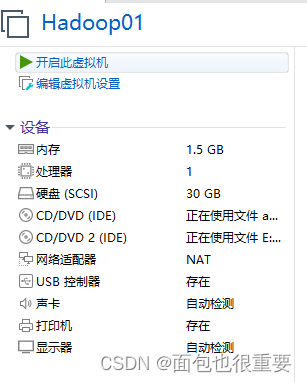
7.登录
选择other输入用户名root,密码123456进入CentOS
(二)文件准备
1.在根目录下创建文件夹:export,在该文件夹下创建两个文件夹:software和servers
2.将准备好的文件拷贝到software文件夹下
(三)参照(一)、(二)步骤再创建两台同样配置的虚拟机(Hadoop02,Hadoop03)
二、连接虚拟机及虚拟机间免密登录
(一)连接虚拟机(ping通)
1.分别查询三个虚拟机的ip地址
输入指令查询:ifconfig
2.配置IP地址
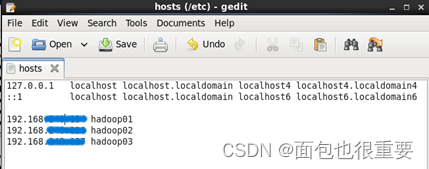
分别在三个虚拟机中打开/etc/hosts,在最后添加以下代码并保存:
192.168.xxx.xxx hadoop01
192.168.xxx.xxx hadoop02
192.168.xxx.xxx hadoop03
2.改主机名
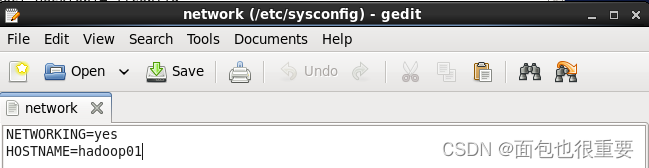
打开并编辑文件: /etc/sysconfig/network ,将其中的HOSTNAME=后的代码改为hadoop01(2号虚拟机和3号虚拟机分别对应hadoop02,hadoop03)
3.重启3台虚拟机,查看主机名
4.连接虚拟机
通过代码:ping hadoop01 , ping hadoop02 , ping hadoop03 分别测试各虚拟机之间的连接。

(二)实现各主机间免密登录(该步骤三台Hadoop主机上均需要执行)
1.在终端输入 cd /root/.ssh ,然后输入 ls -a 查看文件
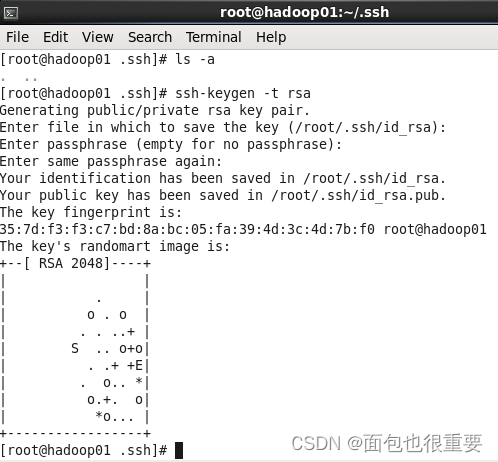
2.终端输入: ssh-keygen -t rsa ,然后连续回车
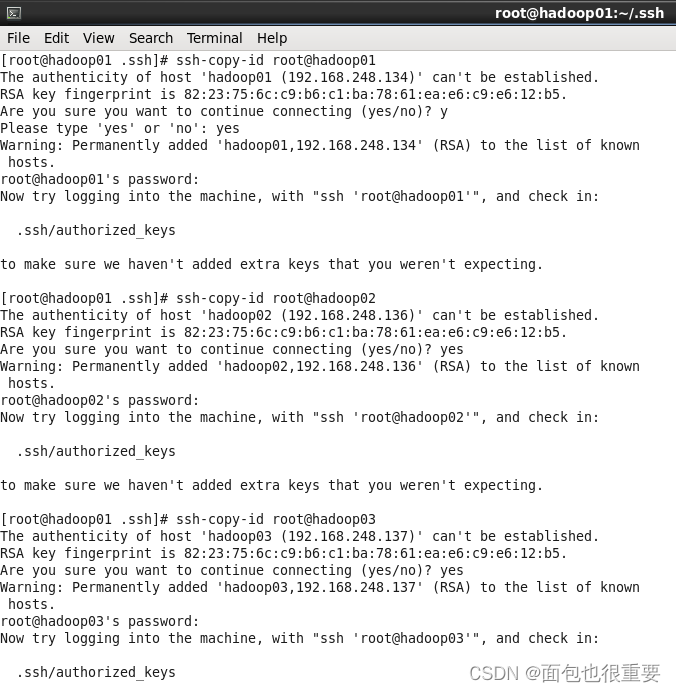
3.终端输入: ssh-copy-id root@hadoop01 , ssh-copy-id root@hadoop02 , ssh-copy-id root@hadoop03 这三条指令,每条指令输完都要输入yes和相应主机的密码,该指令是将密钥分发到其他主机
三、安装配置JDK(该工作三台虚拟机均需要执行)
1.解压jdk
tar -zxvf /export/software/jdk-8u202-linux-x64.tar.gz -C /export/servers/

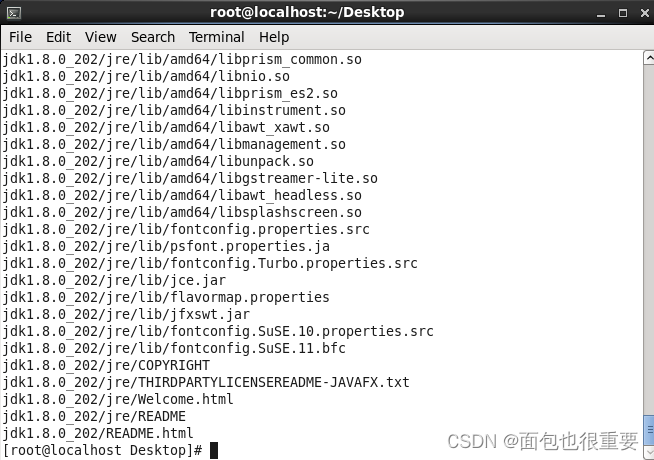
2.修改解压后的文件名
mv /export/servers/jdk1.8.0_202/ /export/servers/jdk
![]()
3.编辑配置文件
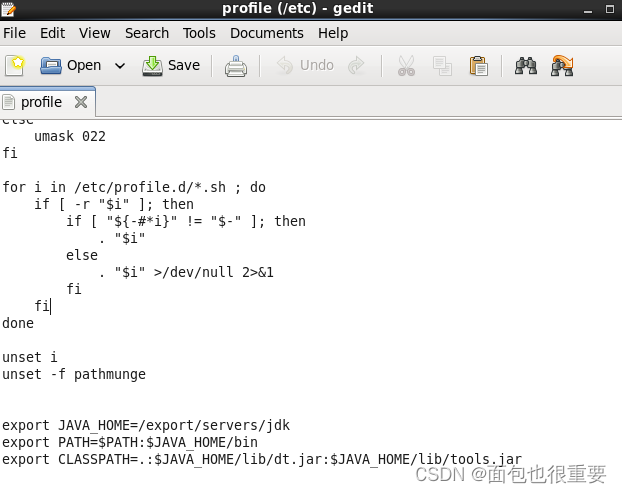
打开编辑 /etc 下的profile文件,在最后插入如下代码并保存:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
4.重启配置文件
source /etc/profile
![]()
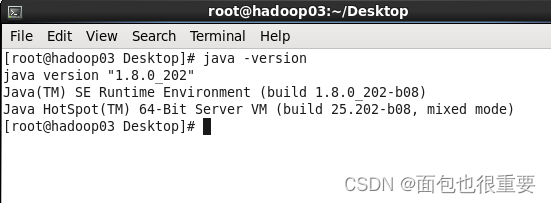
5.测试jdk
java -version
四、配置并启动Hadoop
(一)配置Hadoop
1.tar -zxvf /export/software/hadoop-2.7.4.tar.gz -C /export/servers/
2.打开 /export/servers/hadoop-2.7.4/etc/hadoop/ ,将以下7个文件替换进去:
1)core-site.xml(更改属性,允许运行)
2)hadoop-env.sh
3)hdfs-site.xml(更改属性,允许运行)
4)mapred-site.xml(更改属性,允许运行)
5)slaves
6)yarn-env.sh
7)yarn-site.xml(更改属性,允许运行)

3.打开 /etc/profile ,在最后插入以下代码并保存:
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.在终端输入:source /etc/profile
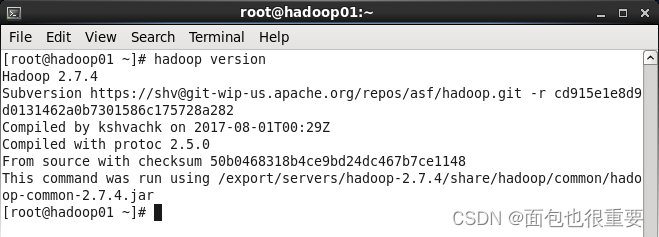
3.在终端输入:hadoop version,查看Hadoop服务启动情况
(二)启动Hadoop服务
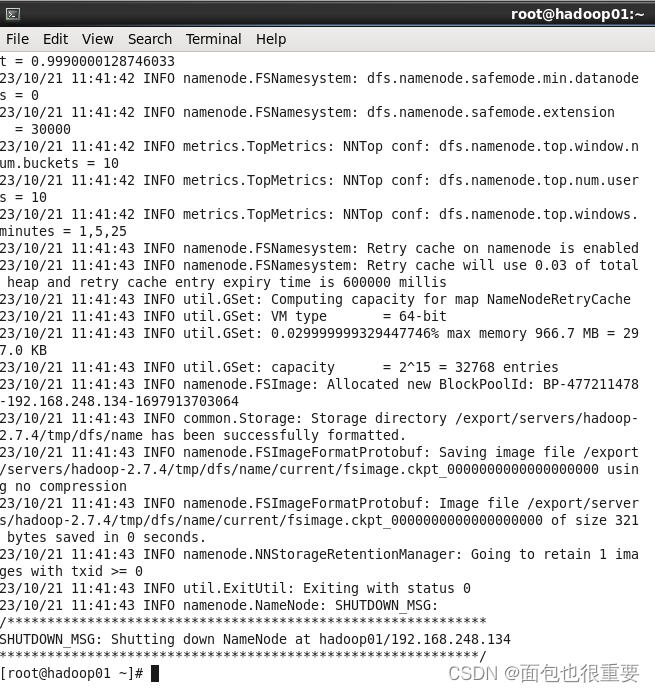
1.hadoop01中,在终端输入:hdfs namenode -format,格式化
2.hadoop01、02、03中,在终端输入:start-dfs.sh

3.hadoop01、02、03中,在终端输入:start-yarn.sh

4.关闭三台虚拟机的防火墙
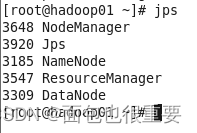
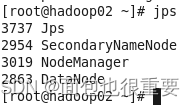
5.在三台虚拟机的中的分别输入:jps,三台虚拟机因分别显示5个,4个和3个服务。
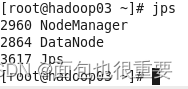
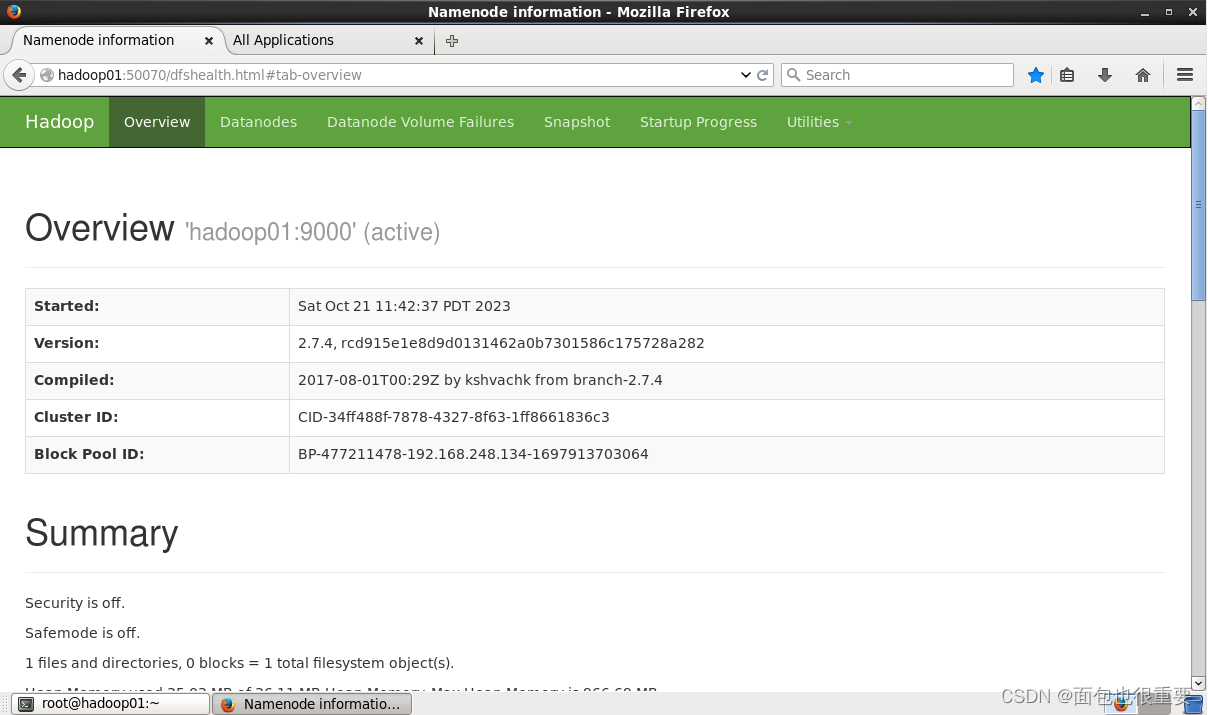
6.三台虚拟机在火狐(或google)浏览器中,访问两个网址:
hadoop01:50070
hadoop01:8088 注:在hadoop01:8088中检查节点是应为3个

2023.10.23更新:
五、安装mysql(只需在Hadoop01中执行)
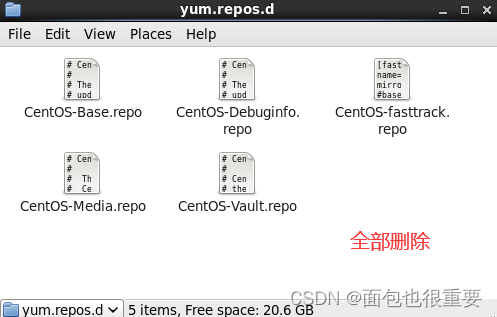
1.在hadoop01中打开: /etc/yum.repos.d 将里面的文件删除,将准备好的镜像文件复制进去

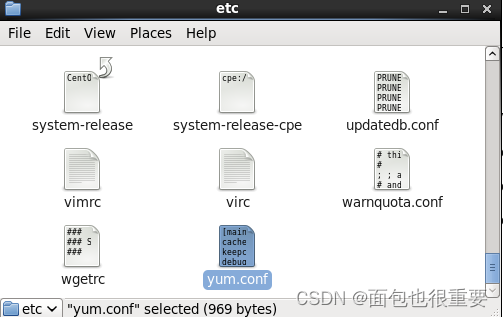
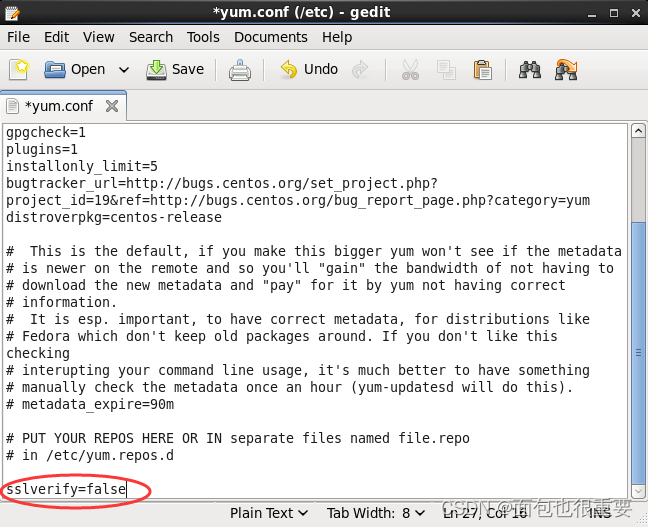
2.编辑一下 /etc/yum.conf 这个文件,我们在最下面加上以下代码并保存:
sslverify=false
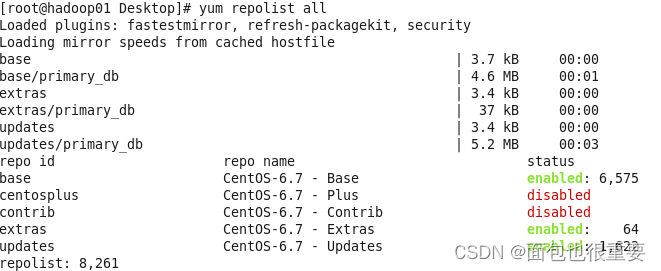
3.在虚拟机Hadoop01中,依次执行如下命令:
yum repolist all
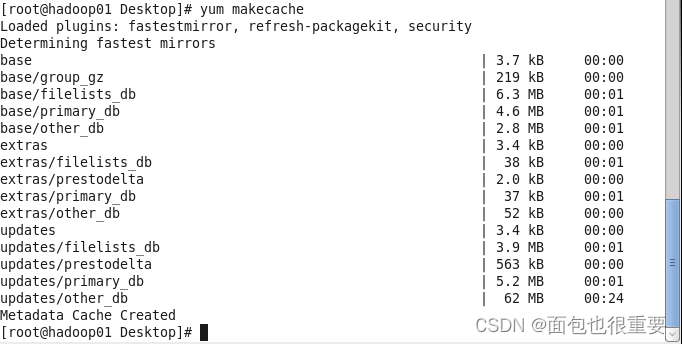
yum clean all
yum makecache

4.在虚拟机的命令行下,执行这条命令,安装MySQL
yum install mysql mysql-server mysql-devel -y
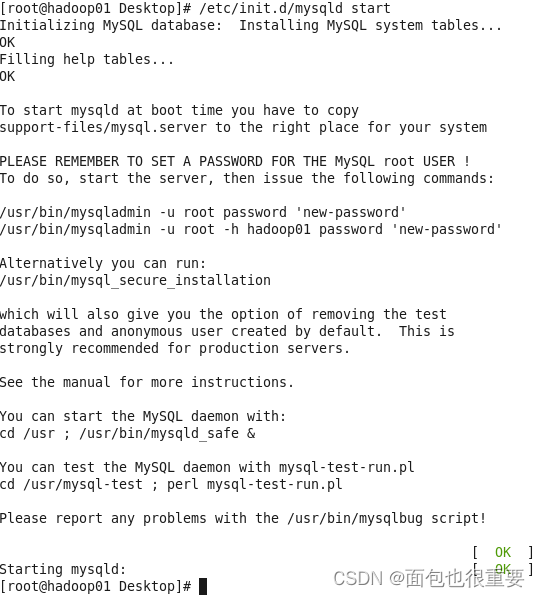
5.输入以下指令启动MySQL服务:
/etc/init.d/mysqld start
6. MySQL安装成功后,我们需要对MySQL进行相关配置。
(1)进入MySQL:
mysql

(2)选择数据库服务器中的mysql数据库,为当前数据库:
USE mysql;

(3)设置root用户的密码为:123456:
UPDATE user SET Password=PASSWORD('123456') WHERE user='root';

(4)允许root用户,从远程进行登录:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;

(5)刷新权限,使刚刚设置的权限,生效:
FLUSH PRIVILEGES;

(6)退出重新登录,验证配置,完毕后退出
Exit
mysql -u root -p (输入密码:123456)
Exit

六、hive(只需要在hadoop01上执行)
1.解压hive:tar -zxvf /export/software/apache-hive-1.2.1-bin.tar.gz -C /export/servers/

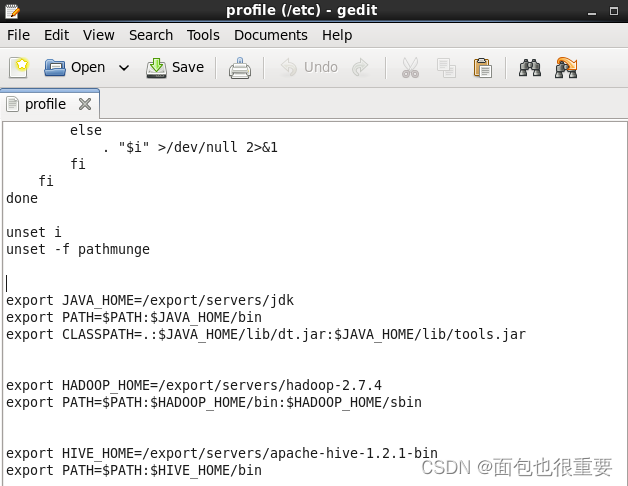
2./etc/profile文件最下方添加以下代码并保存后重载(source /etc/profile):
export HIVE_HOME=/export/servers/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin
![]()
3.复制以下两个文件到hive的conf文件夹下(目录:/export/servers/ apache-hive-1.2.1-bin/conf ,属性改为可执行)

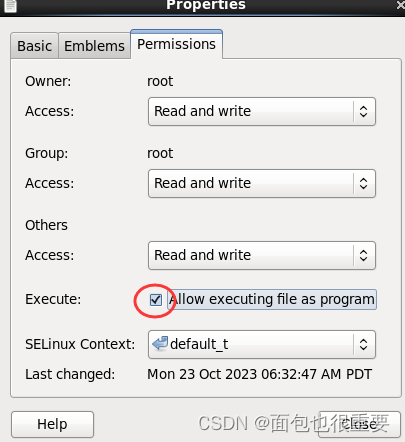
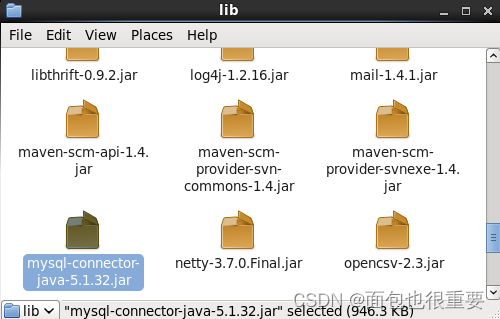
4.将mysql-connector-java-5.1.32.jar文件放到hive的lib文件夹下(目录:/export/servers/ apache-hive-1.2.1-bin/lib)

5.终端进入hive的bin文件夹下执行./hive(或者在终端直接执行hive)

看见hive> 即表示成功了
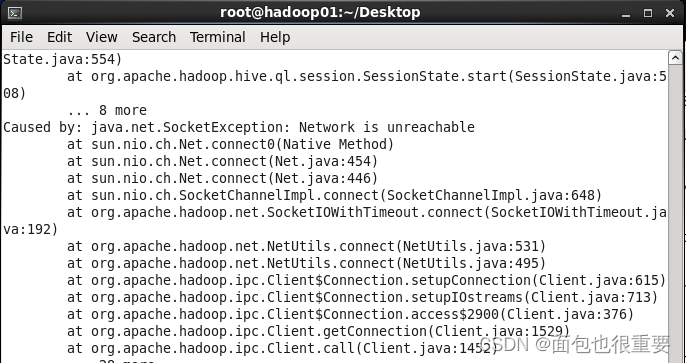
6如果hive执行时弹出一堆代码,则要检查数据库有服务没有打开,若没打开需要重新打开MySQL,并多启动几次hive:
service mysqld status
七、sqoop的安装与应用
1.解压sqoop :
tar -zxvf /export/software/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /export/servers/
2.改名:(先进入servers文件夹下:cd /export/servers)
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop-1.4.6

3.复制sqoop-env.sh文件到conf(目录:/export/servers/ sqoop-1.4.6 /conf ,改为可执行),

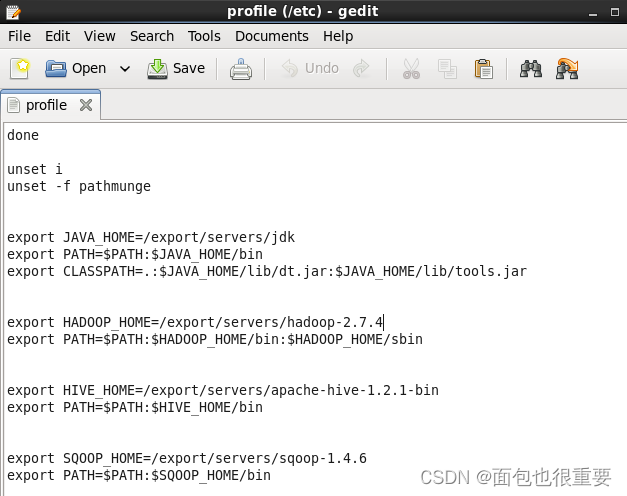
4. /etc/profile文件最下方添加以下代码并保存后重载(source /etc/profile):
export SQOOP_HOME=/export/servers/sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
![]()
5.复制接口工具,把:mysql-connector-java-5.1.32.jar,这个文件,拷贝到这里:/export/servers/sqoop-1.4.6/lib/
6.启动验证sqoop服务开启
在虚拟机命令行下,执行:
sqoop list-databases -connect jdbc:mysql://localhost:3306/ --username root --password 123456
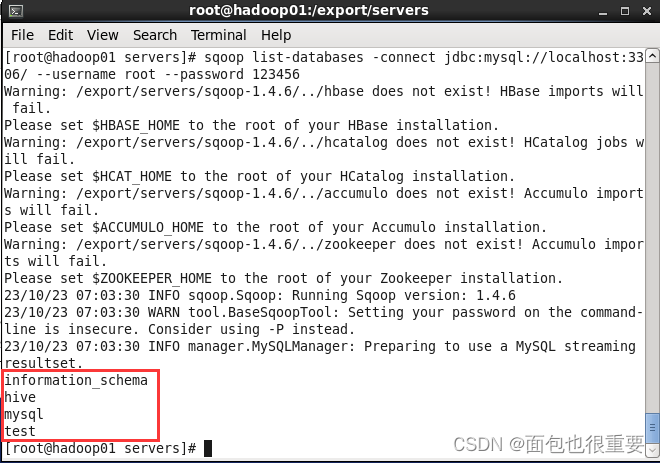
如上图所示即为成功。
2023.11.1
八、部署服务(编写简单的程序在Hadoop上运行并产生结果)
(一)单词计数程序
1.使用IDEA编写简单的jar
(1)使用IDEA新建项目
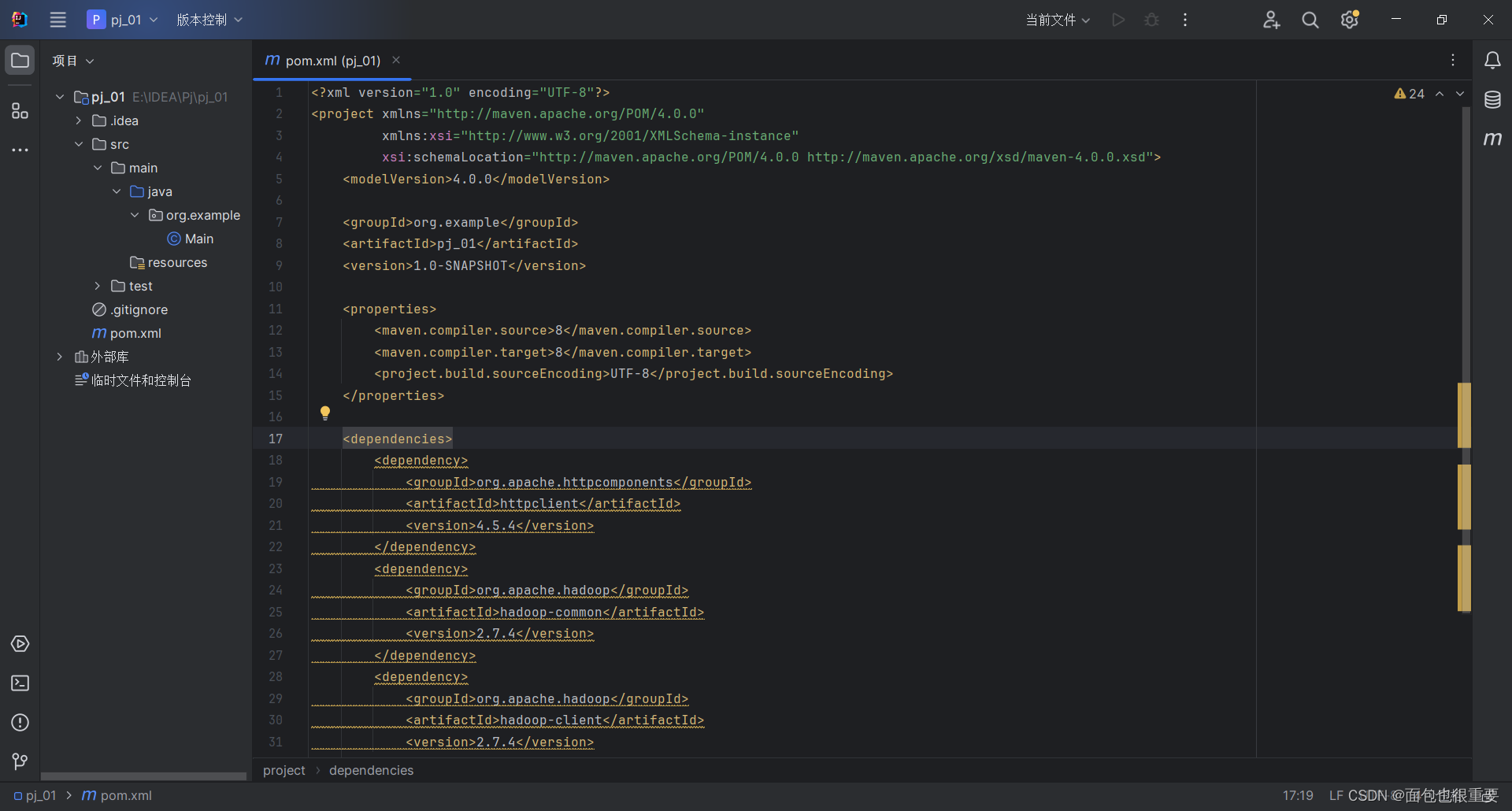
(2)对pom.xml文件进行修改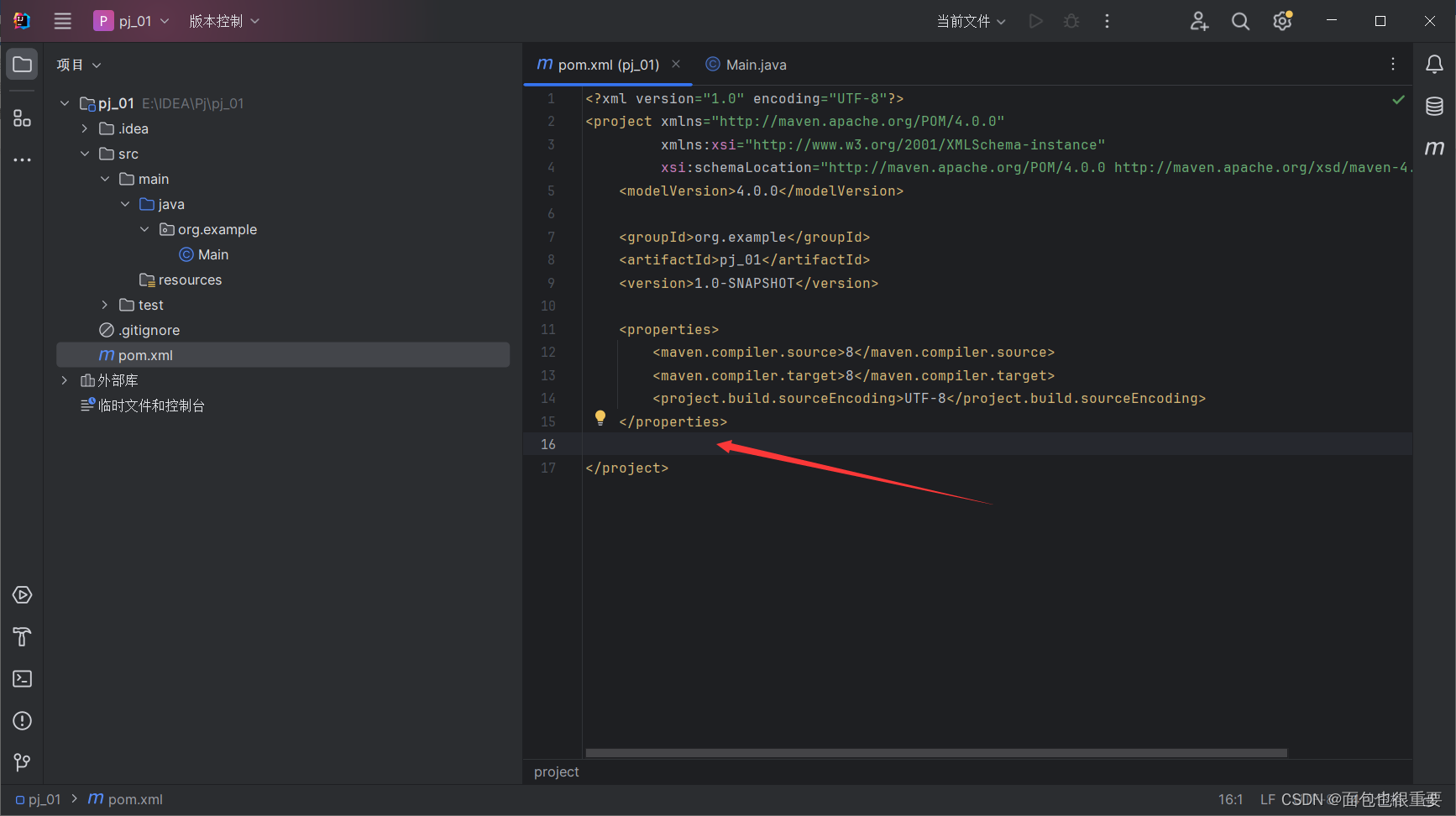
在这里插入代码
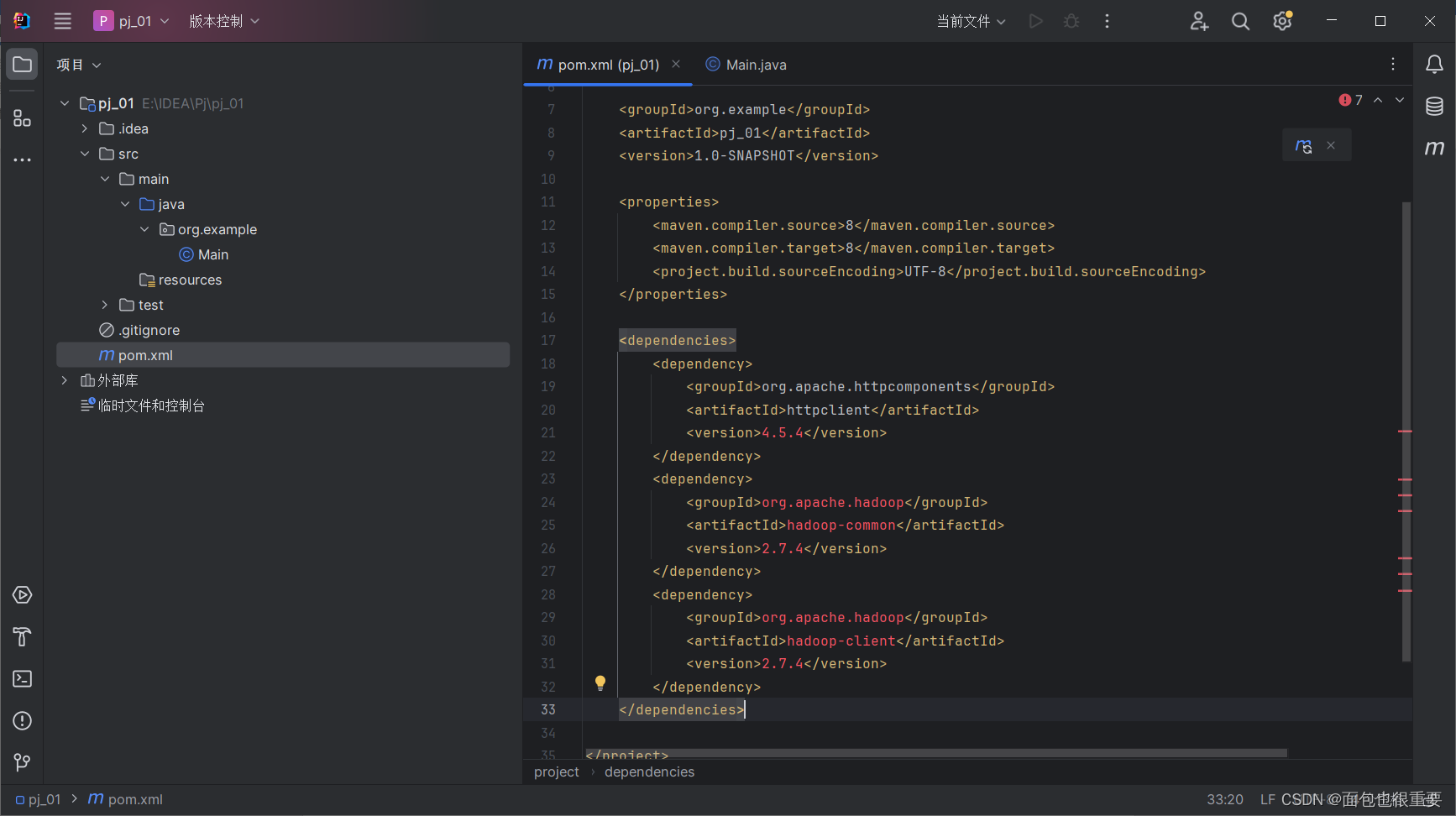
点击这里,开始解析依赖,这里需要等待一段时间
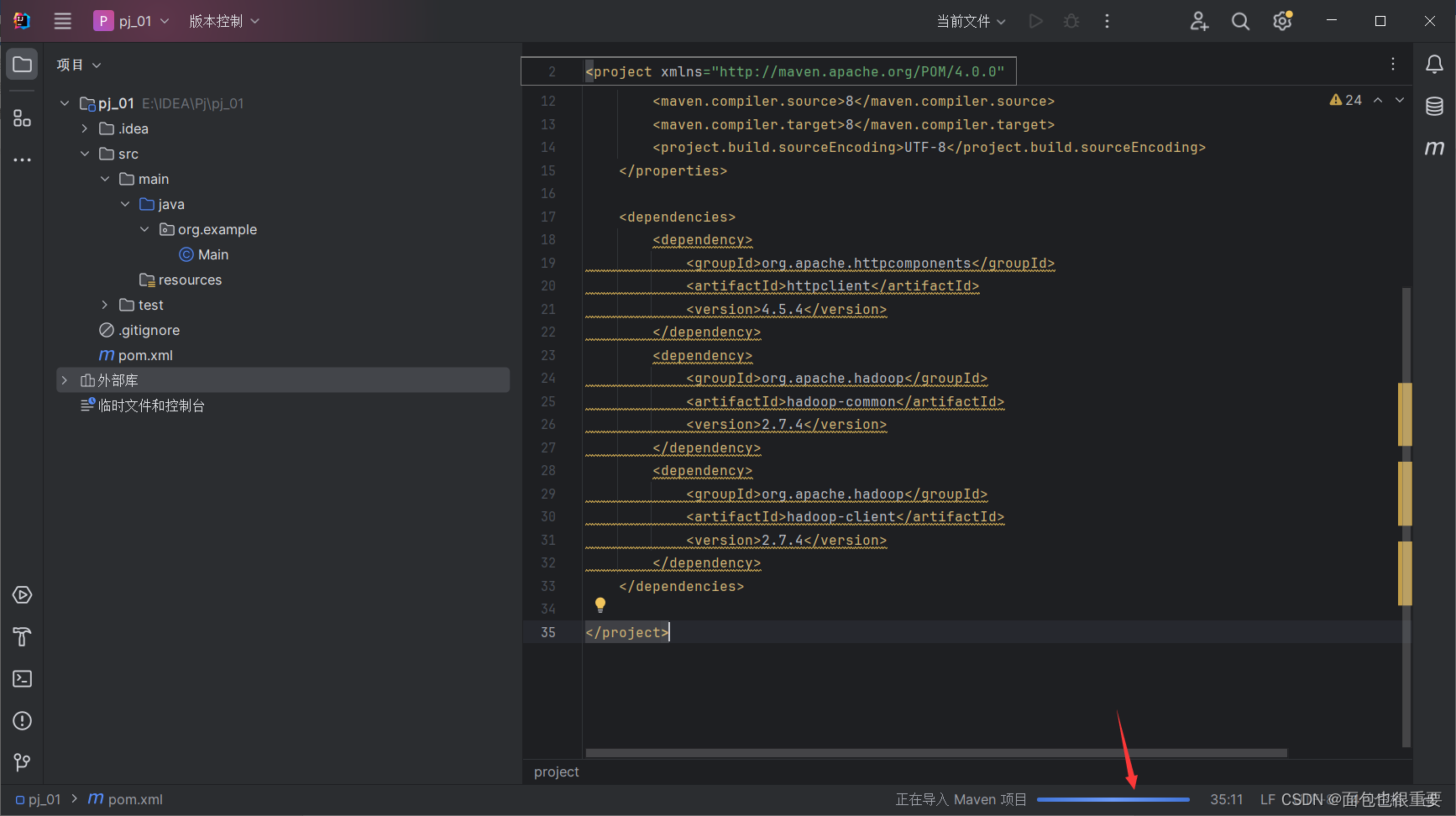
(3)新建class文件,编写程序
输入代码(源文件可在资源中获取)
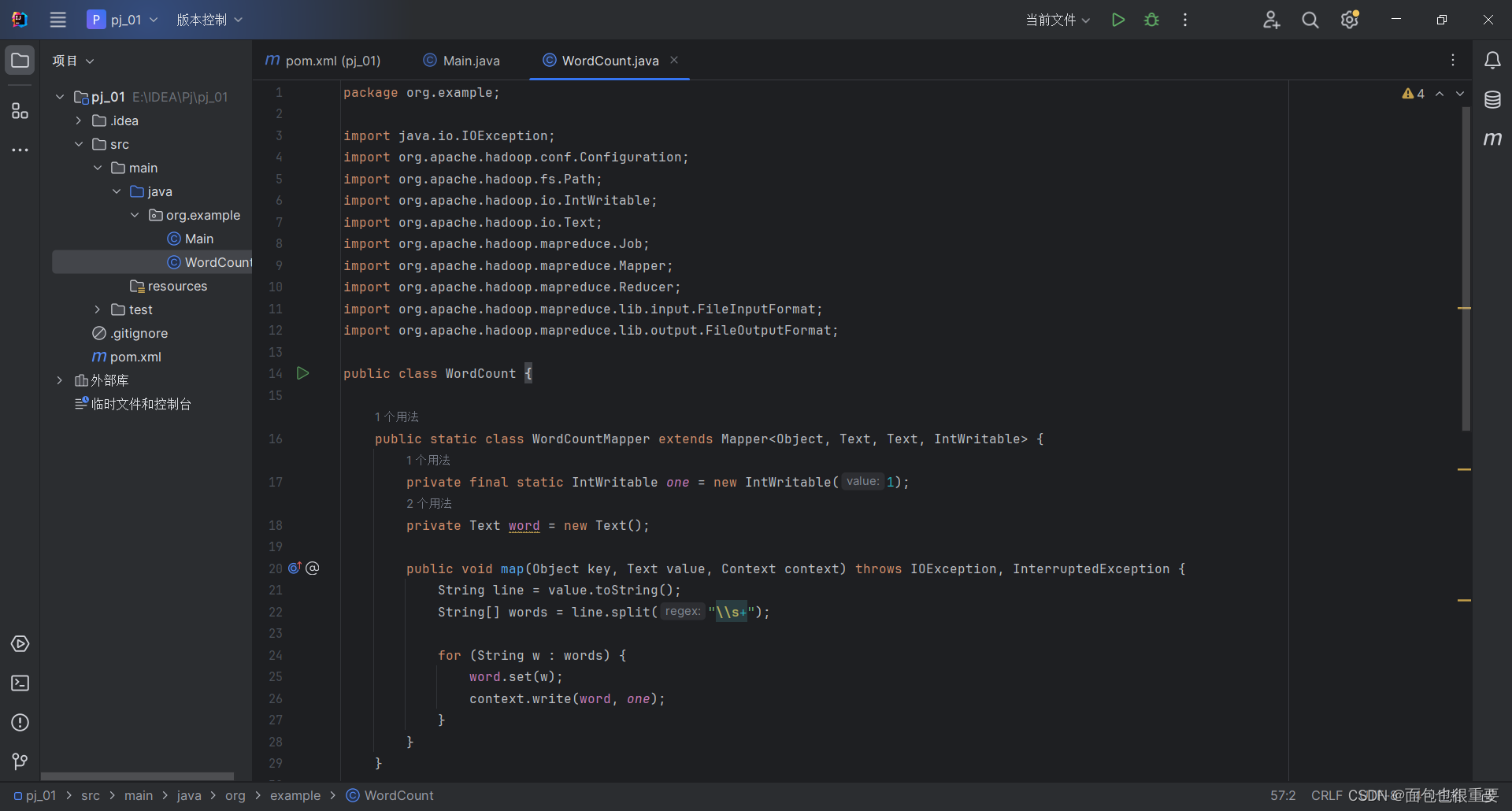
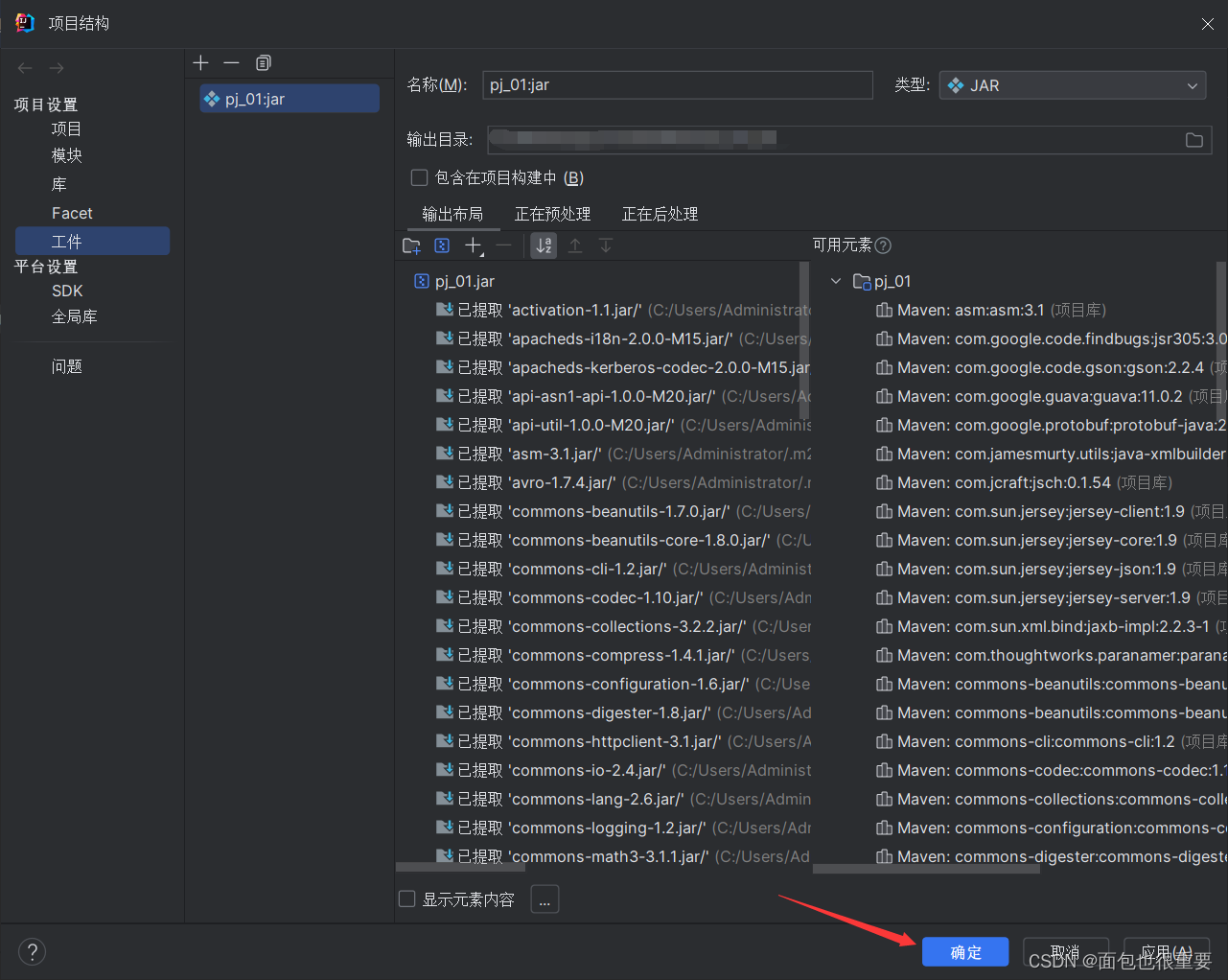
(4)在项目结构中添加工件
依次点击
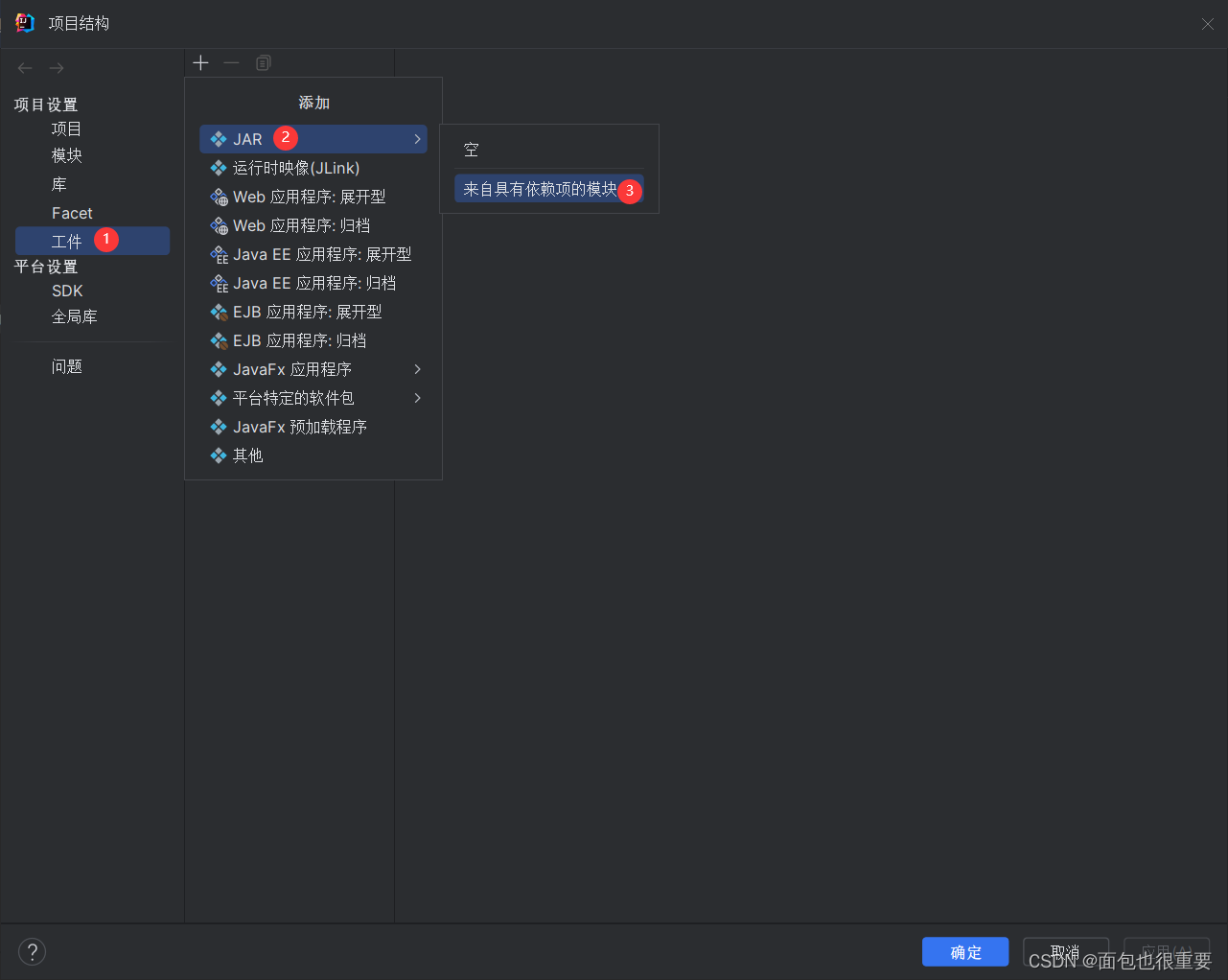
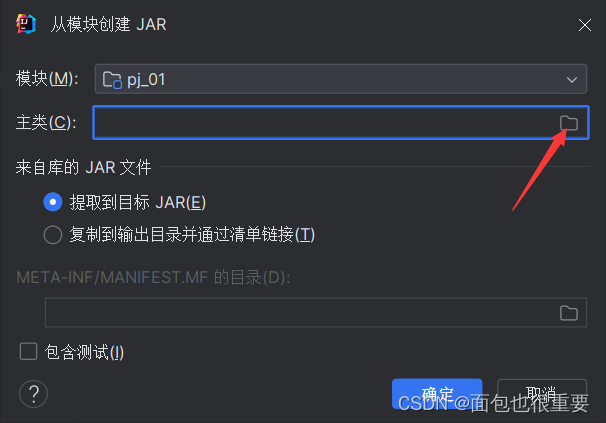
添加主类
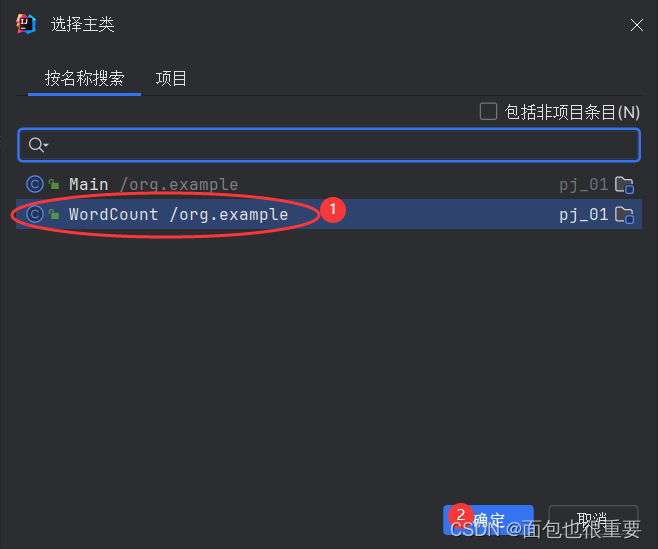
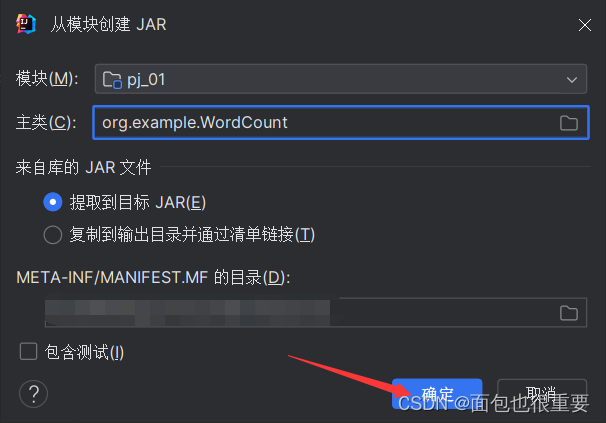
(5)构建工件,输出jar包
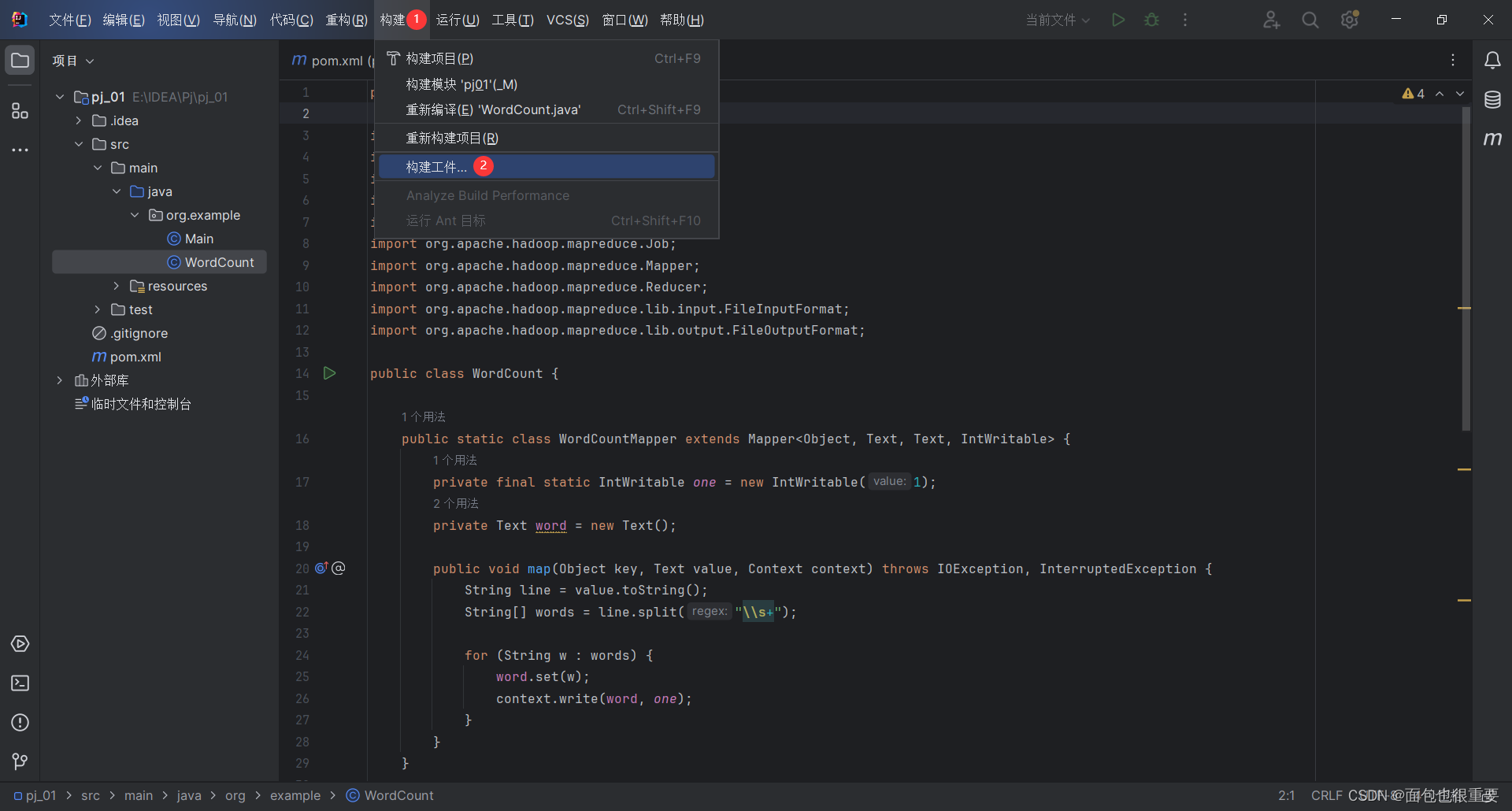

在文件夹中找到jar包
2.将程序部署到Hadoop上
(1)将jar包(pj_01.jar)拷贝到虚拟机Hadoop01中(创建目录:/export/my_jar)

(2)在同级目录下创建input.txt文件。
在其中任意编写内容并保存,要有一些重复的单词用来测试:
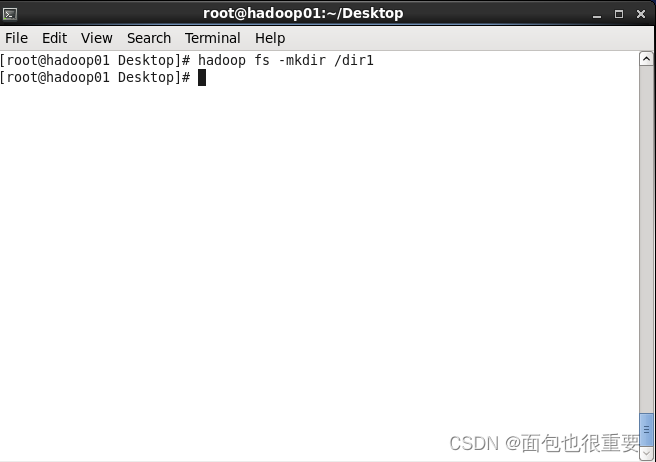
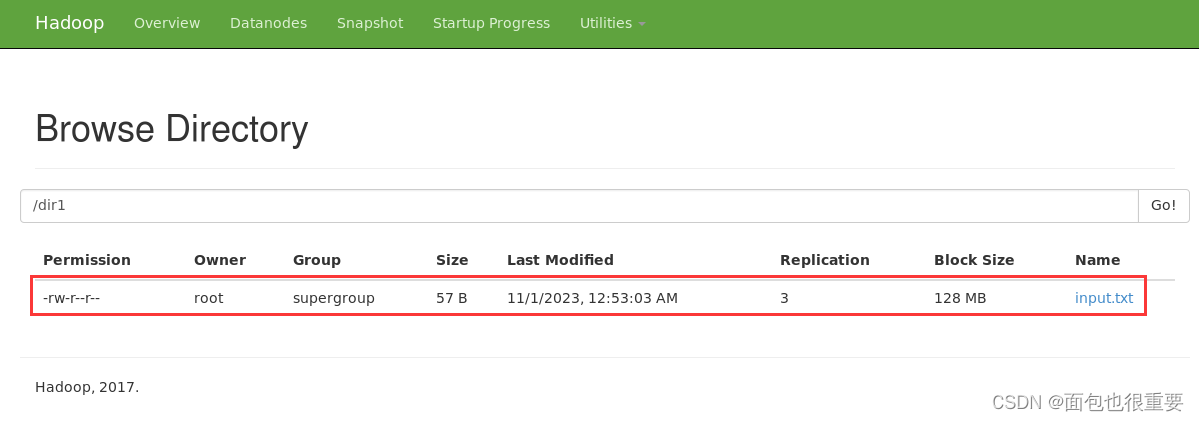
(3)在部署的Hadoop上创建名为dir1的文件夹
终端输入:hadoop fs -mkdir /dir1
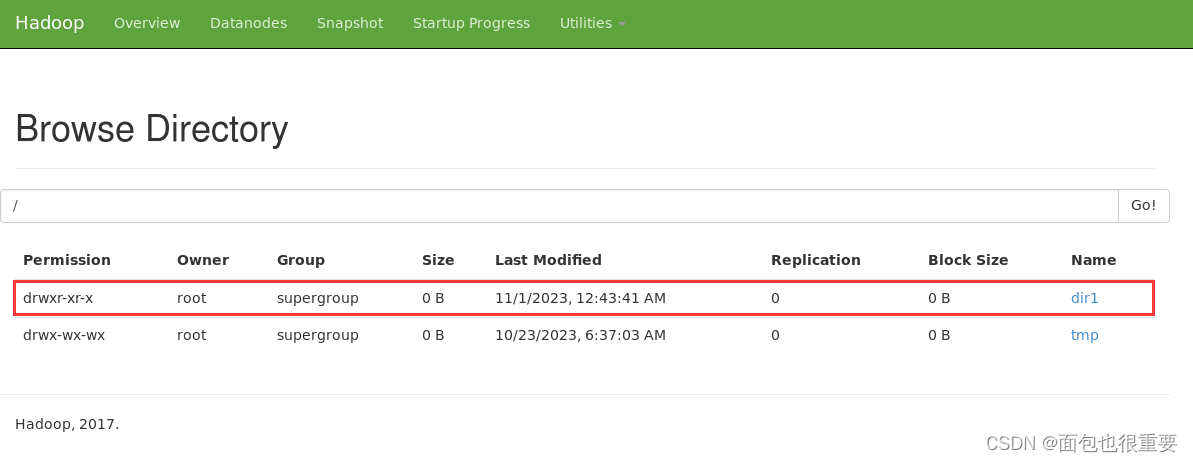
进入50070端口查看文件
(4)将input.txt上传至dir1文件夹中
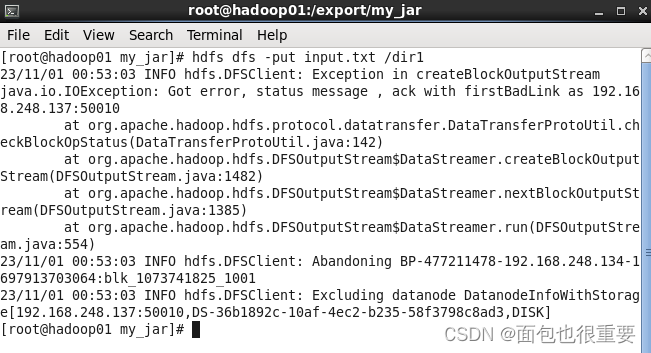
终端输入:hdfs dfs -put input.txt /dir1(注:在本地my_jar文件夹下打开终端)
(5)用pj_01.jar对input.txt进行处理,并将结果输出至output文件中
终端输入:hadoop jar pj_01.jar /dir1/input.txt output01(注:在本地my_jar文件夹下打开终端)

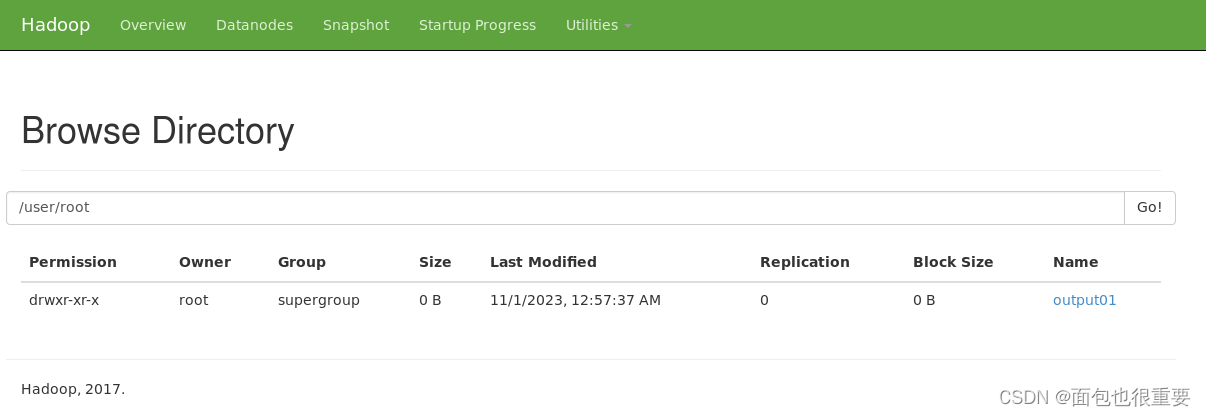
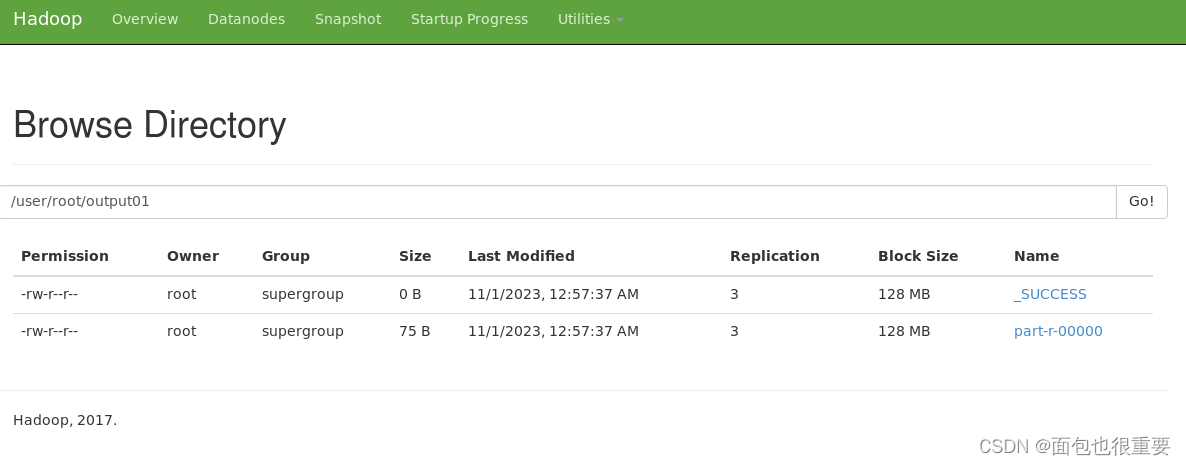
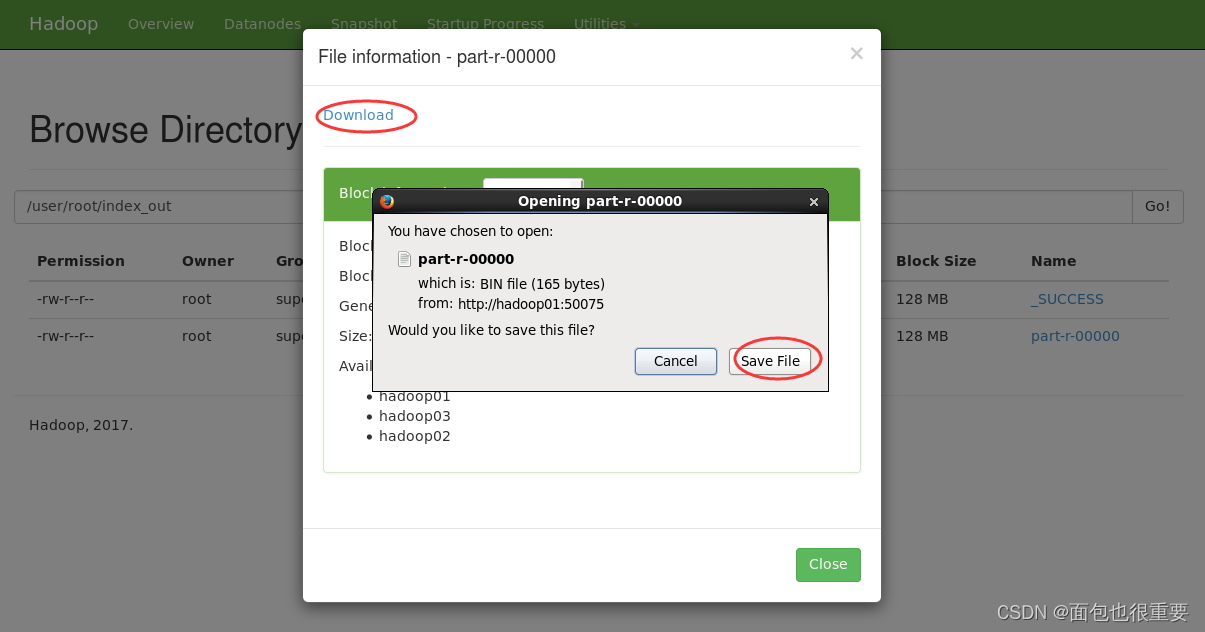
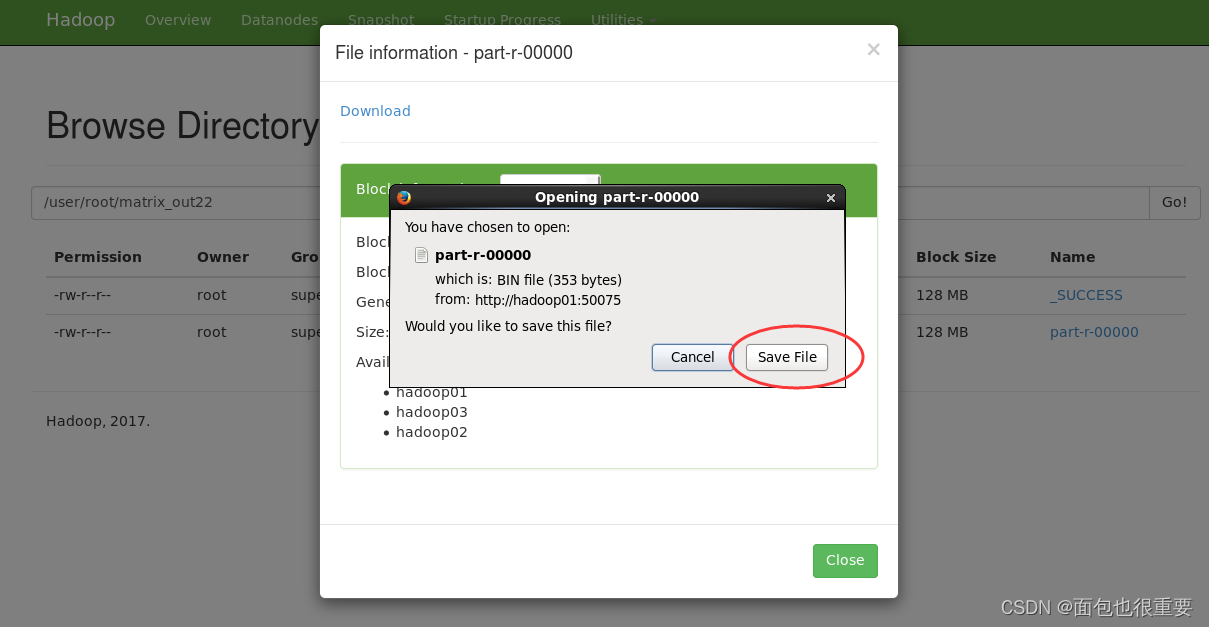
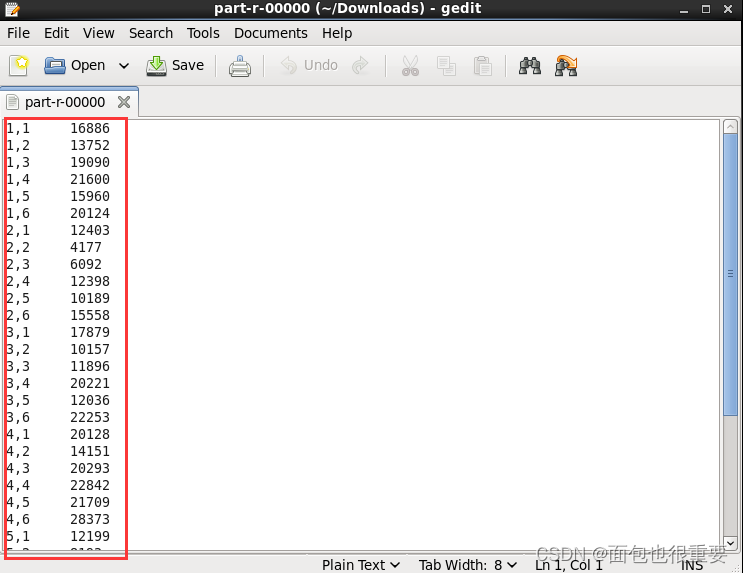
下载输出的文件检验结果
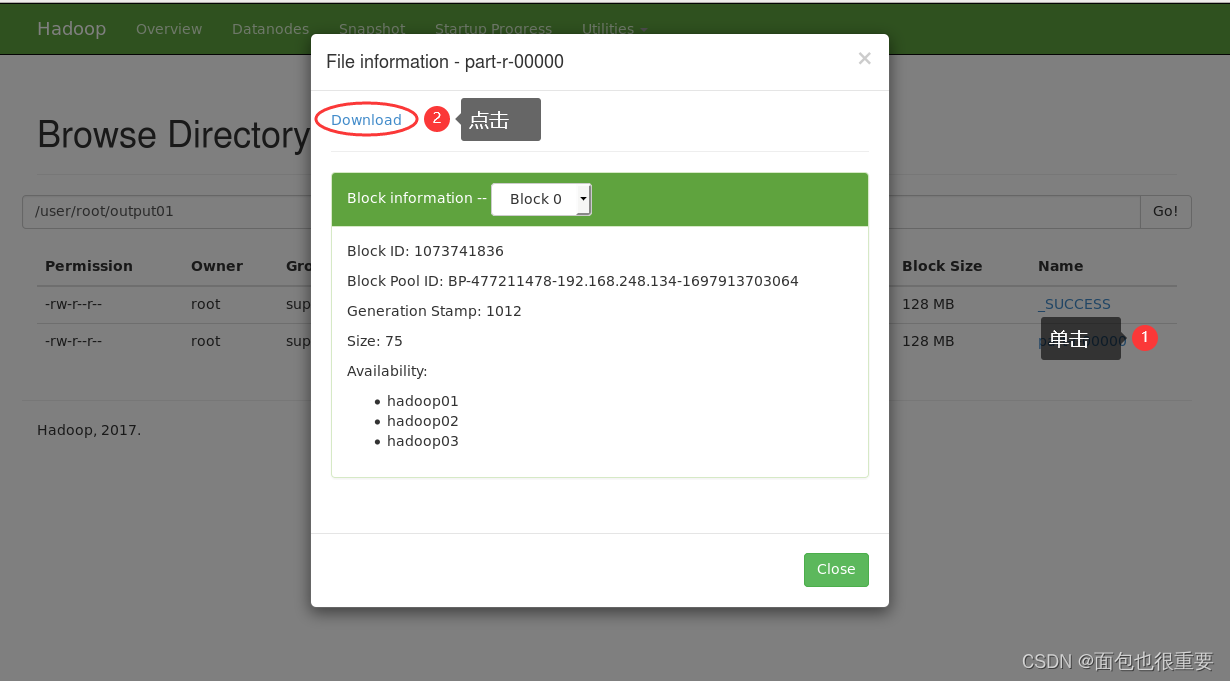
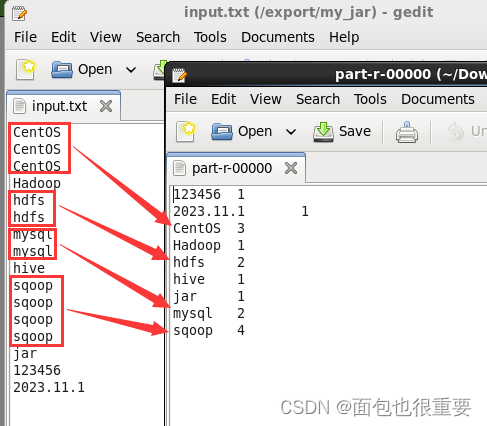
我们可以看到程序成功对文件进行了单词计数
(二)索引
1.使用IDEA编写简单的jar
(1)使用IDEA新建项目
(2)对pom.xml文件进行修改,解析依赖
(3)新建class文件,编写程序
输入代码(源文件可在资源中获取)
(4)在项目结构中添加工件
添加主类
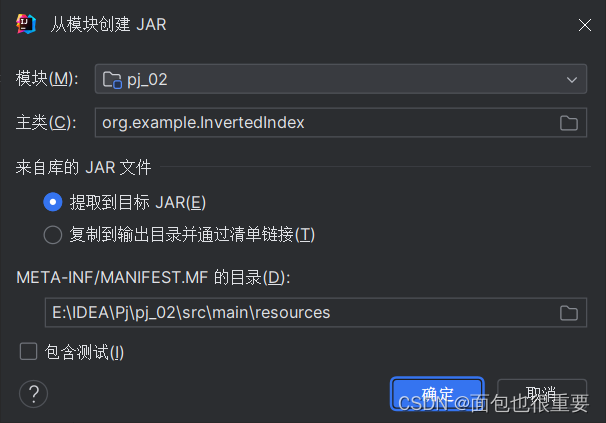
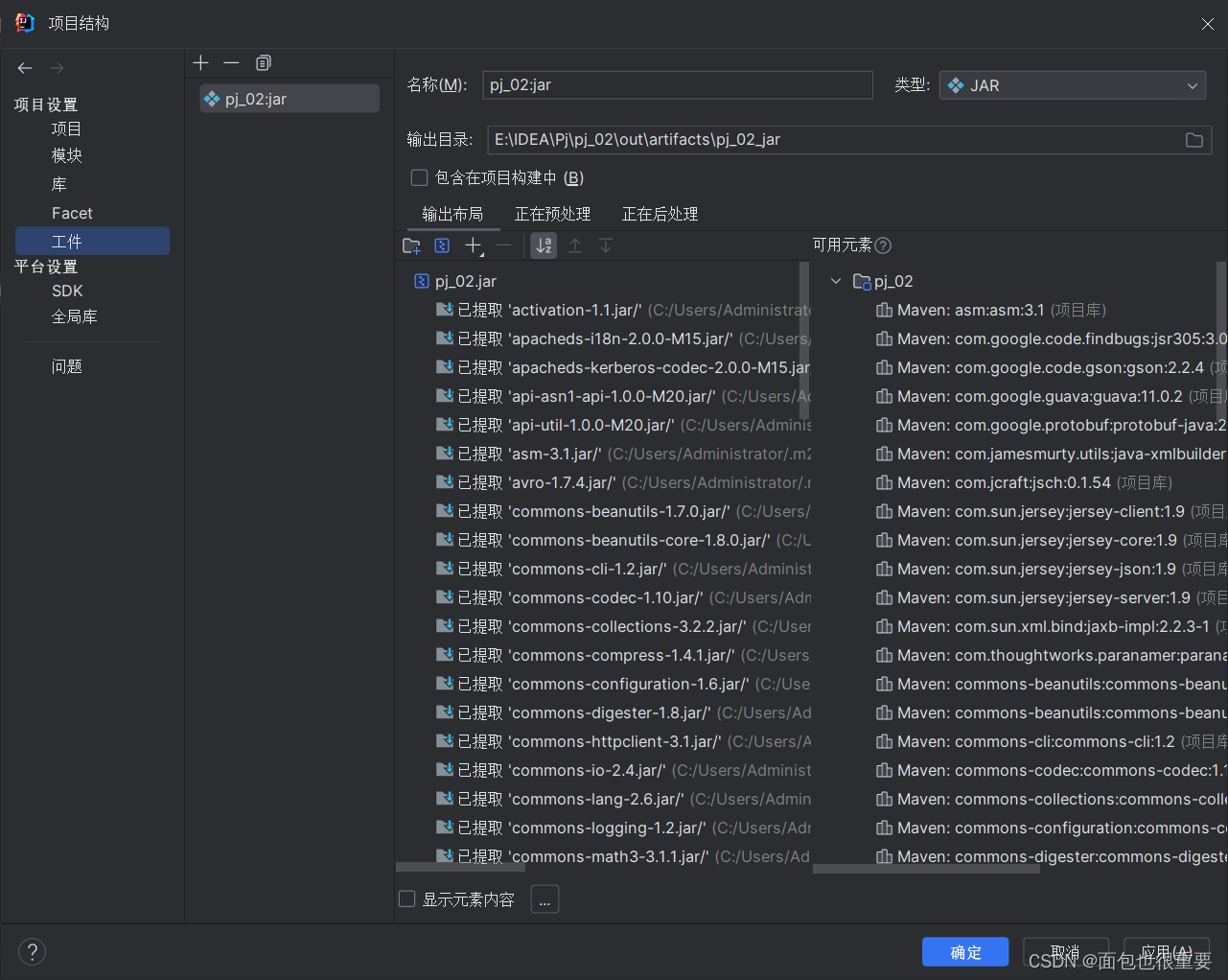
(5)构建工件,输出jar包
在文件夹中找到jar包
2.将程序部署到Hadoop上
(1)将jar包(pj_02.jar)拷贝到虚拟机Hadoop01中(目录:/export/my_jar)

(2)在同级目录下创建三个txt文件(file1.txt, file2.txt, file3.txt)。
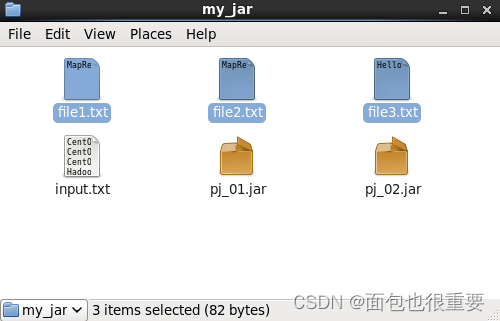

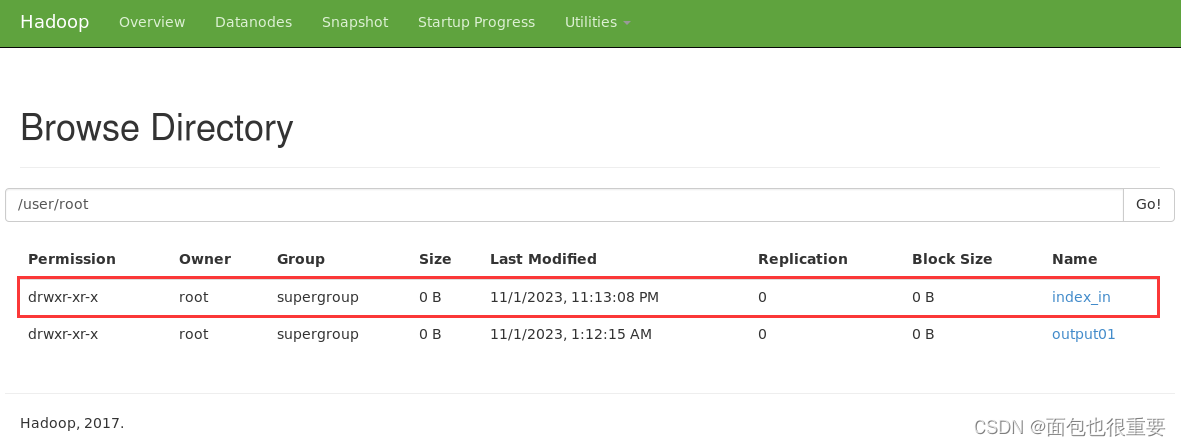
(3)在部署的Hadoop上创建名为index_in的文件夹(地址:/user/root/index_in)
终端输入:hadoop fs -mkdir /user/root/index_in
进入50070端口查看文件:
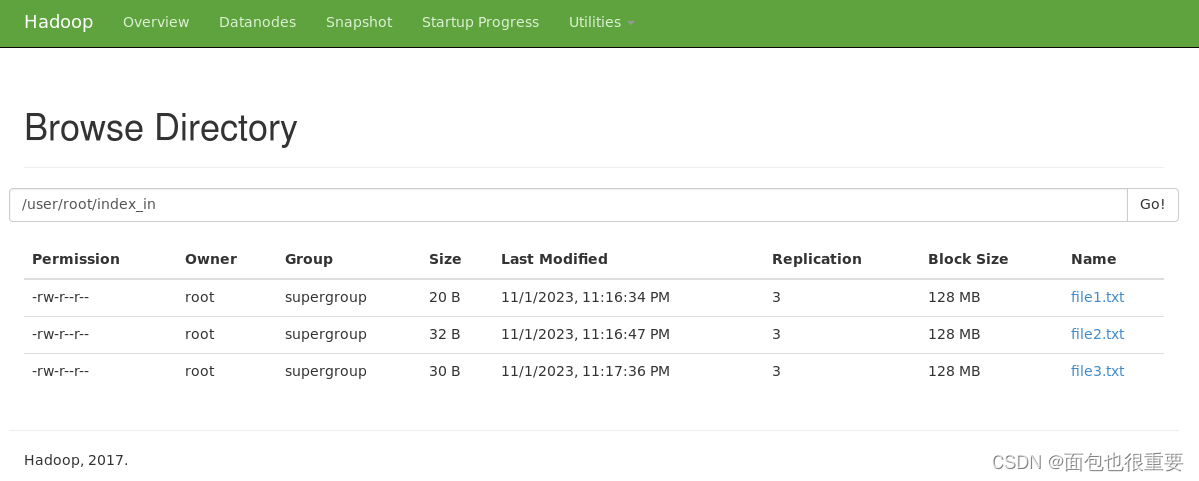
(4)将三个txt文件上传至index_in文件夹中
终端输入:
hdfs dfs -put file1.txt /user/root/index_in
hdfs dfs -put file2.txt /user/root/index_in
hdfs dfs -put file3.txt /user/root/index_in
(注:在本地my_jar文件夹下打开终端)
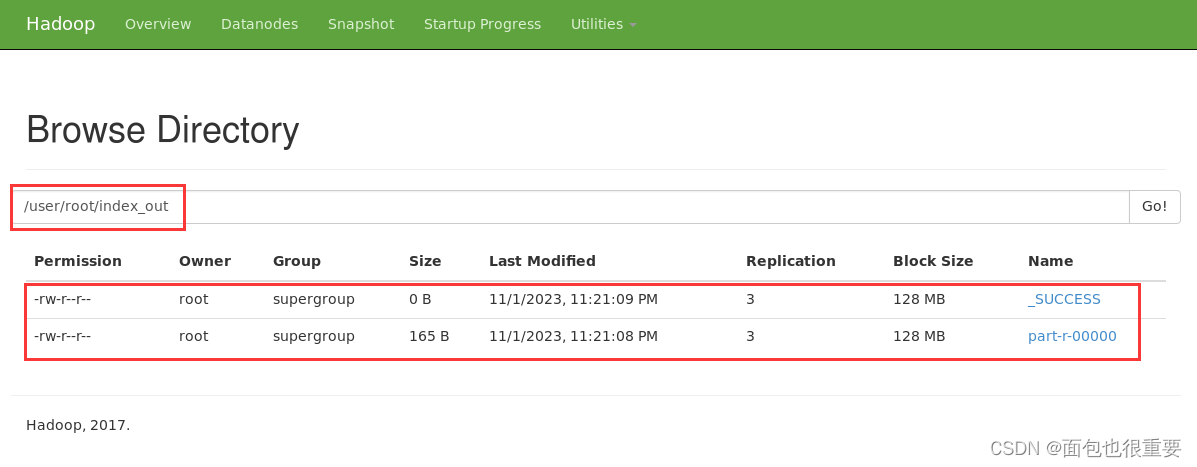
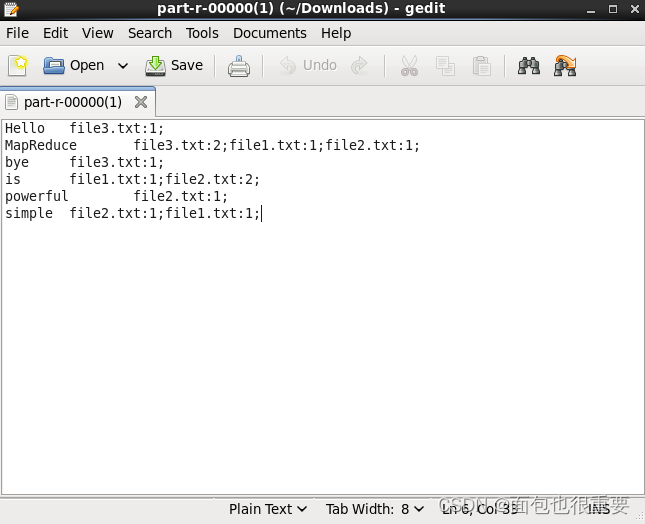
(5)用pj_02.jar对三个txt文件进行处理,并将结果输出
终端输入:hadoop jar pj_02.jar(注:在本地my_jar文件夹下打开终端)
(三)矩阵运算
1.使用IDEA编写简单的jar
(1)使用IDEA新建项目
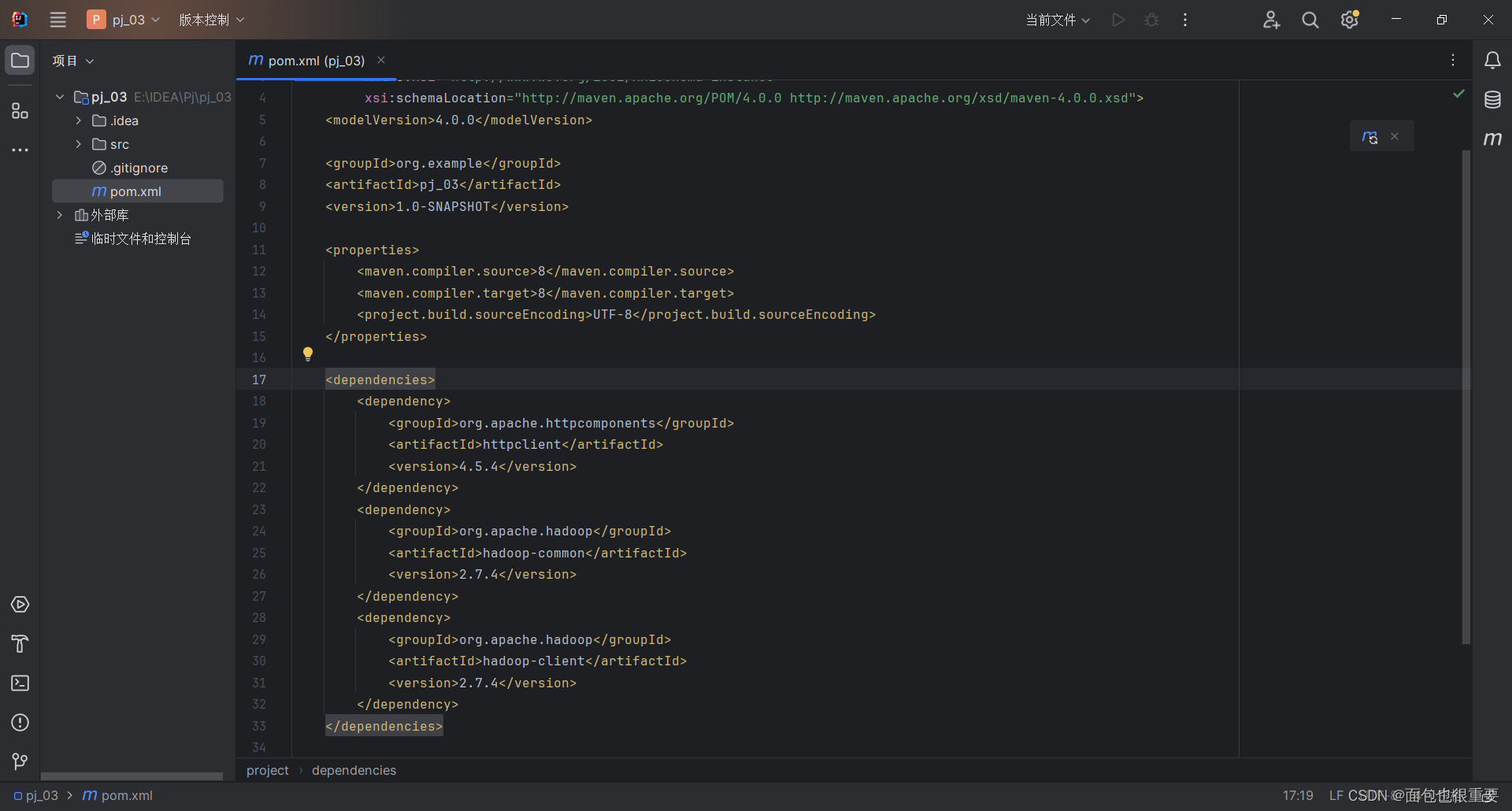
(2)对pom.xml文件进行修改,解析依赖
(3)新建class文件,编写程序
输入代码(源文件可在资源中获取)
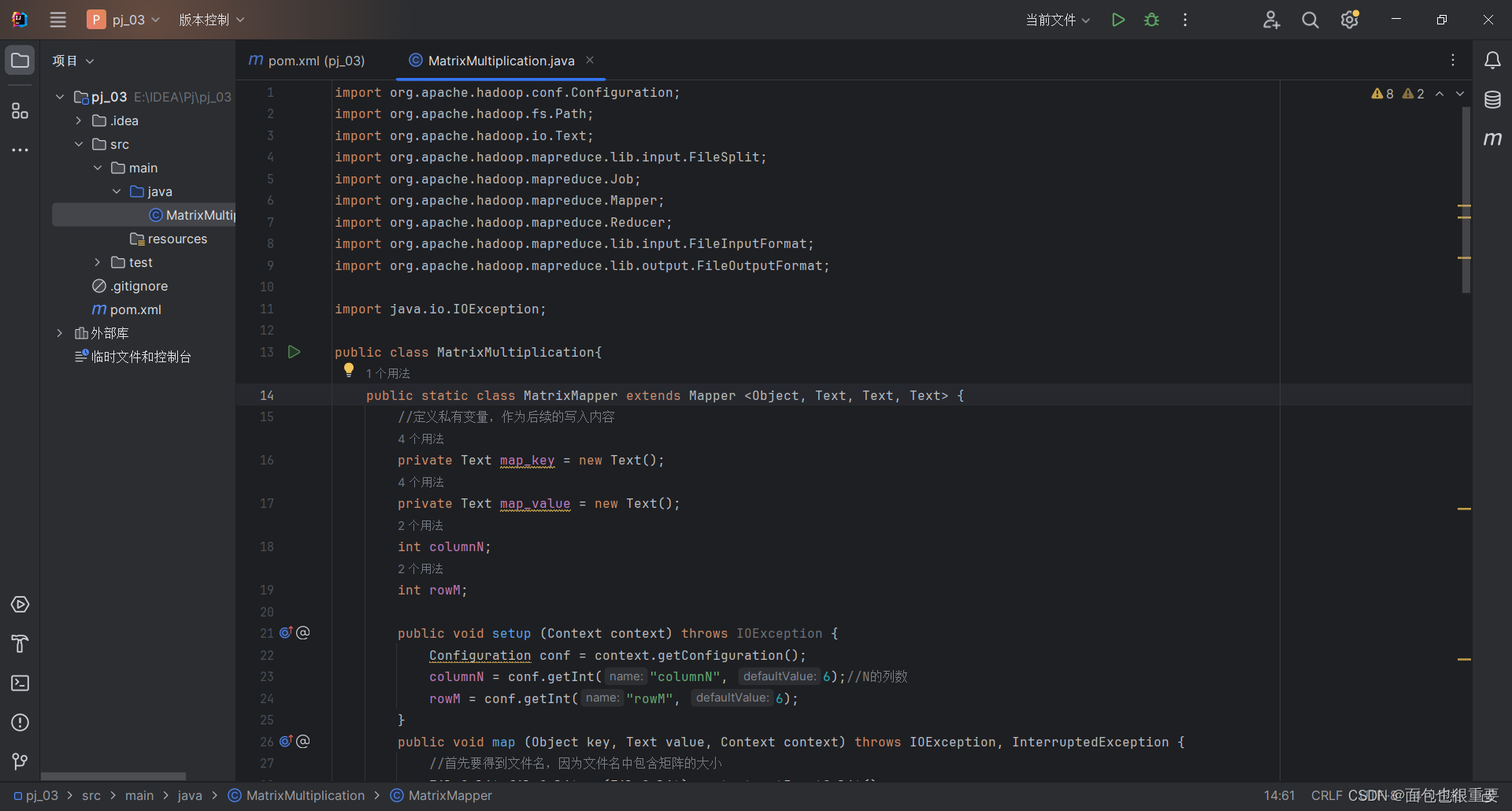
(4)在项目结构中添加工件
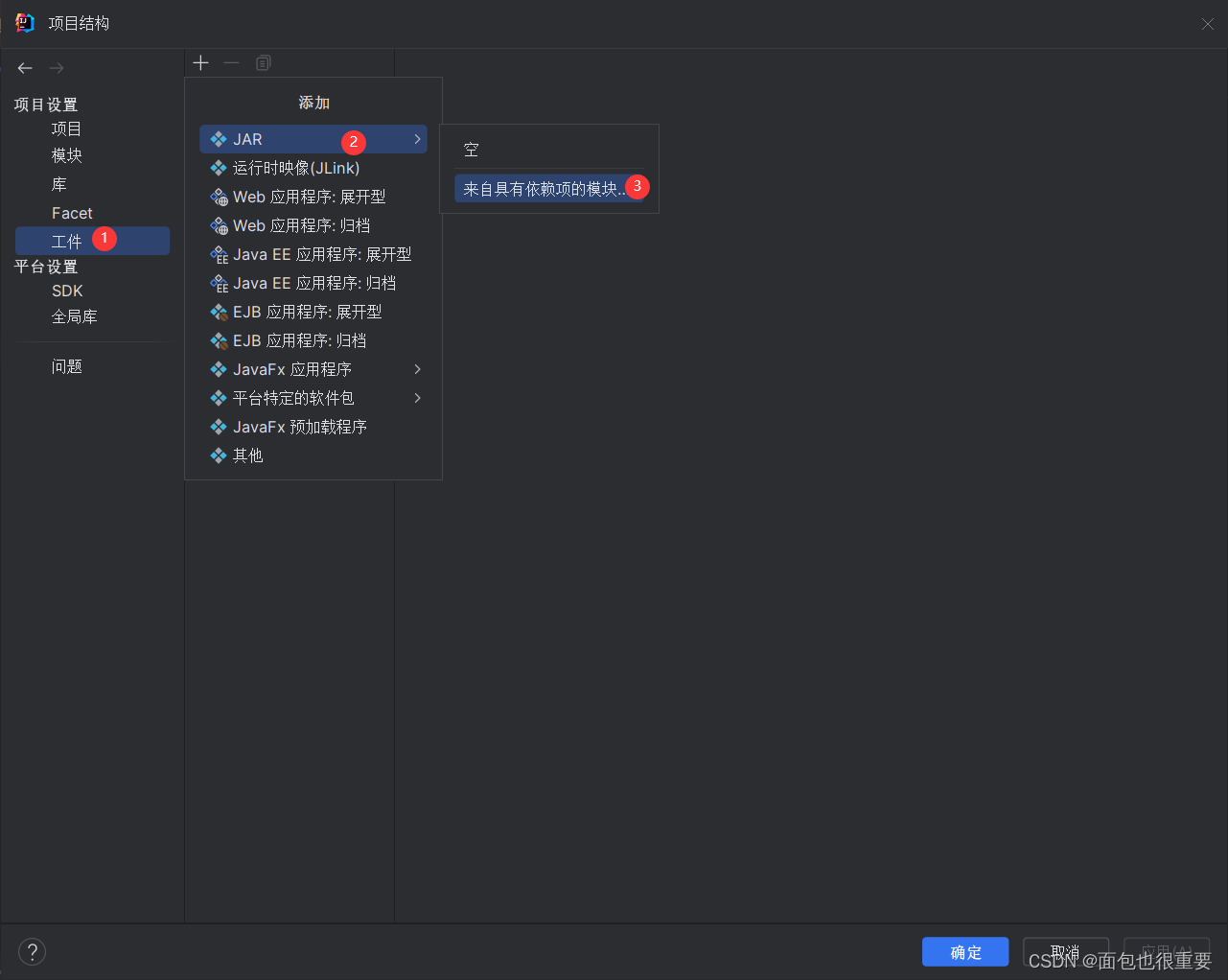
添加主类
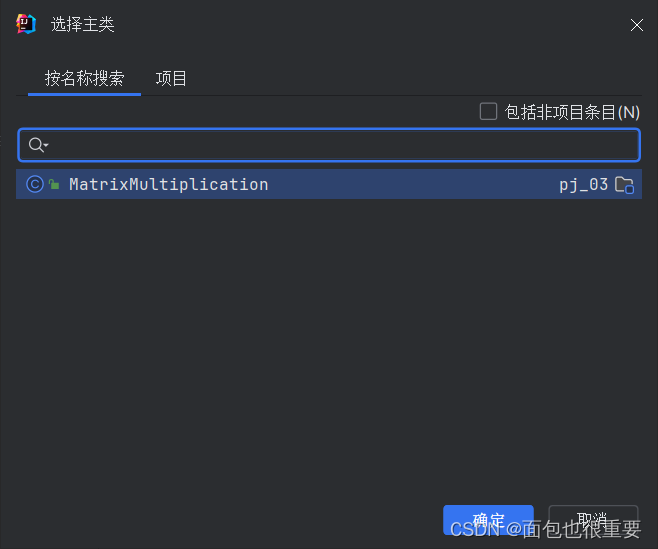

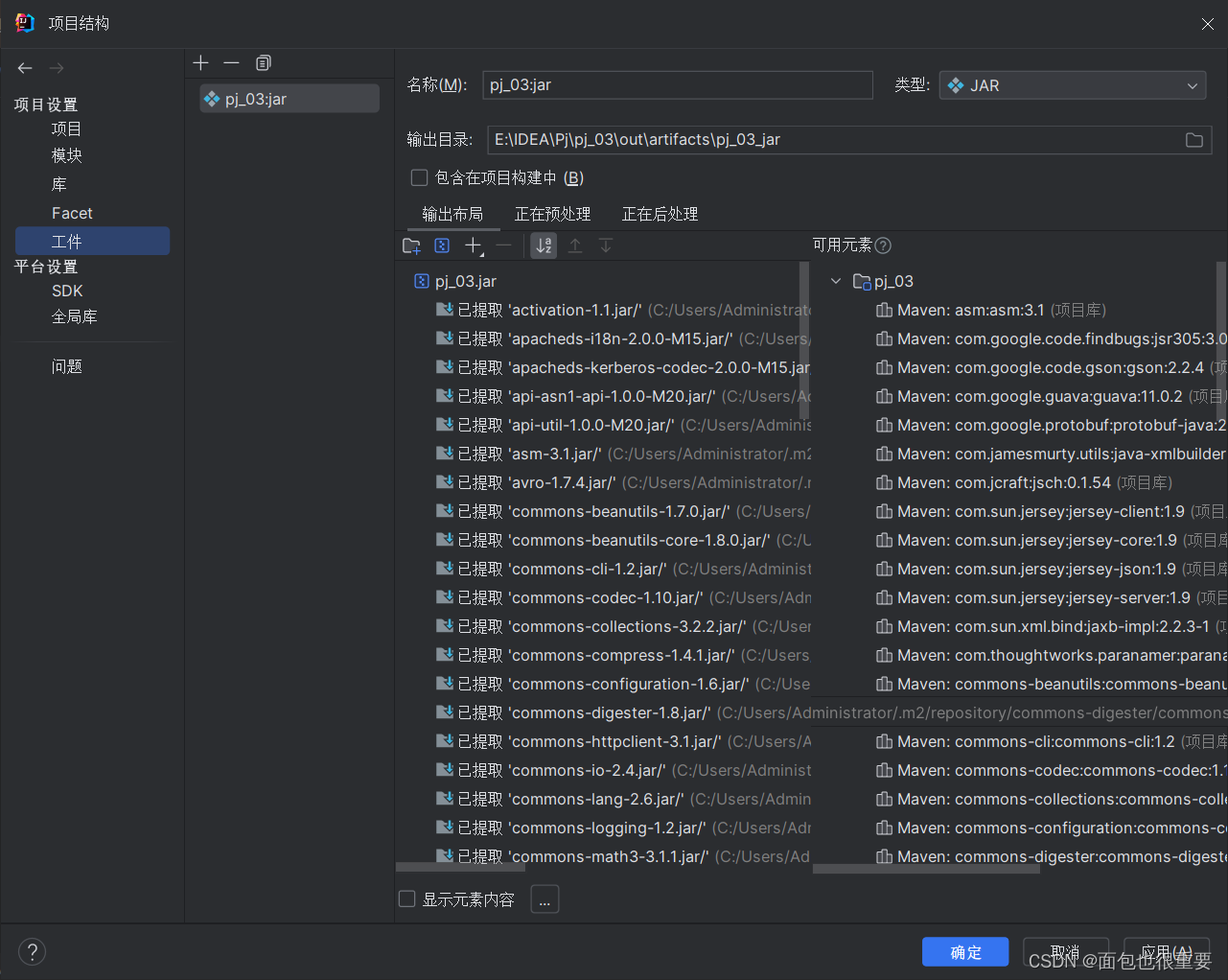
(5)构建工件,输出jar包

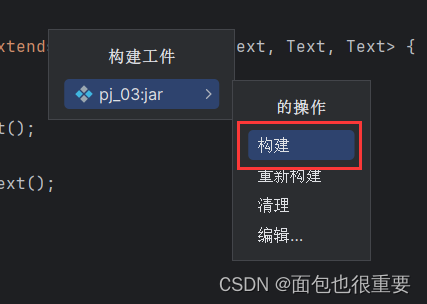

在文件夹中找到jar包
2.将程序部署到Hadoop上
(1)将jar包(pj_02.jar)拷贝到虚拟机Hadoop01中(目录:/export/my_jar/pj_03)
(2)在同级目录下拷贝shell文件(bat01.sh)
(3)在同级目录执行sh文件(属性改为可执行)
在该目录下(/export/my_jar/pj_03)运行终端输入:./bat02.sh 6 7 6
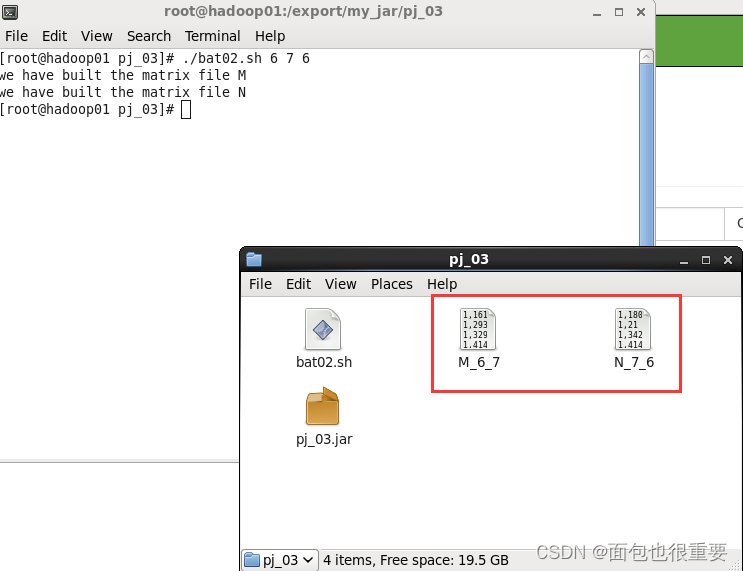
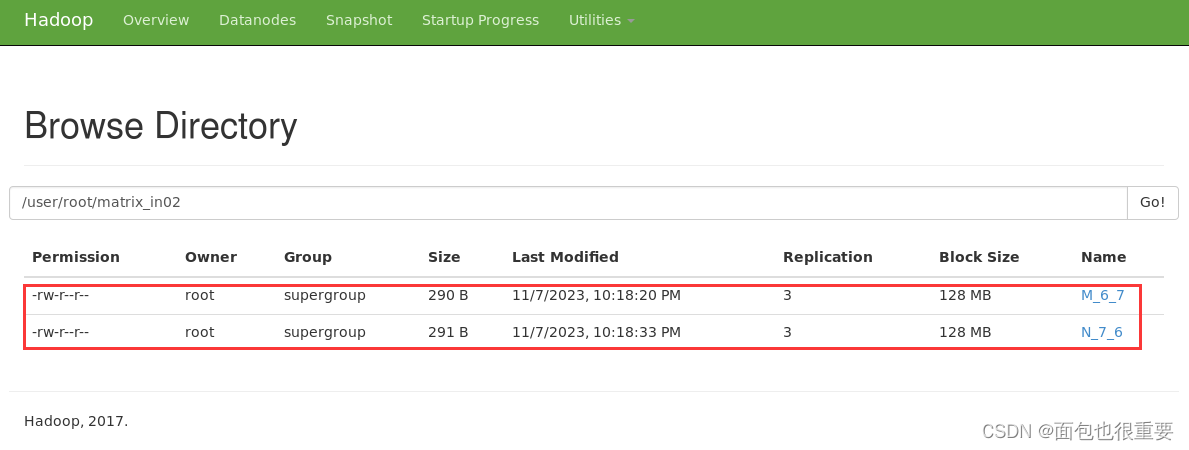
(4)将生成的两个文件上传至Hadoop中的/user/root/matrix_in02文件夹中
终端输入:(注:在本地/export/my_jar/pj_03文件夹下打开终端)
hadoop fs -mkdir /user/root/matrix_in02
hdfs dfs -put M_6_7 /user/root/matrix_in02
hdfs dfs -put N_7_6 /user/root/matrix_in02
(5)用pj_03.jar对两个文件进行处理,并将结果输出
终端输入: hadoop jar pj_03.jar MatrixMultiplication
(注:在本地 /export/my_jar/pj_03 文件夹下打开终端)
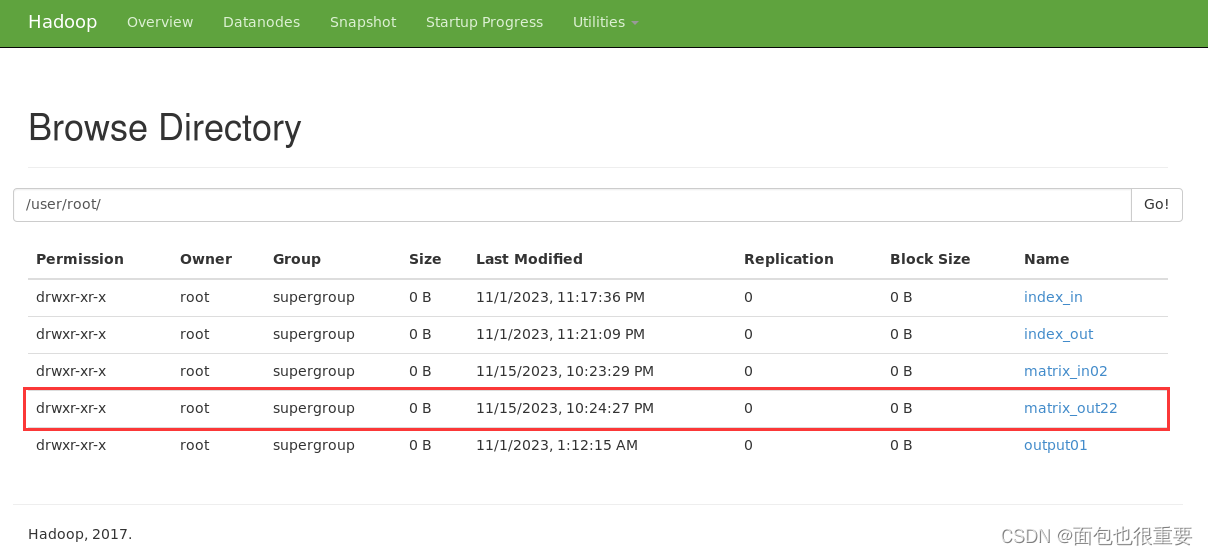
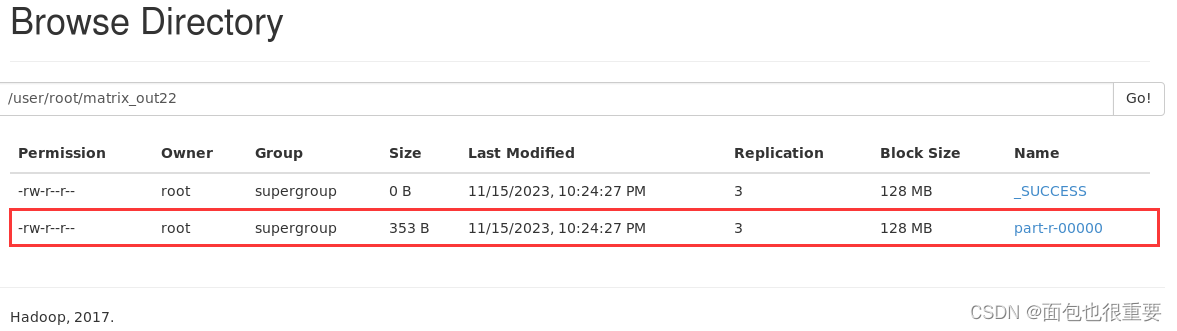
(6)若不成功,可删除文件重试
hadoop fs -rmr /user/root/matrix_in02
hadoop fs -rmr /user/root/matrix_out22
九、hive实验
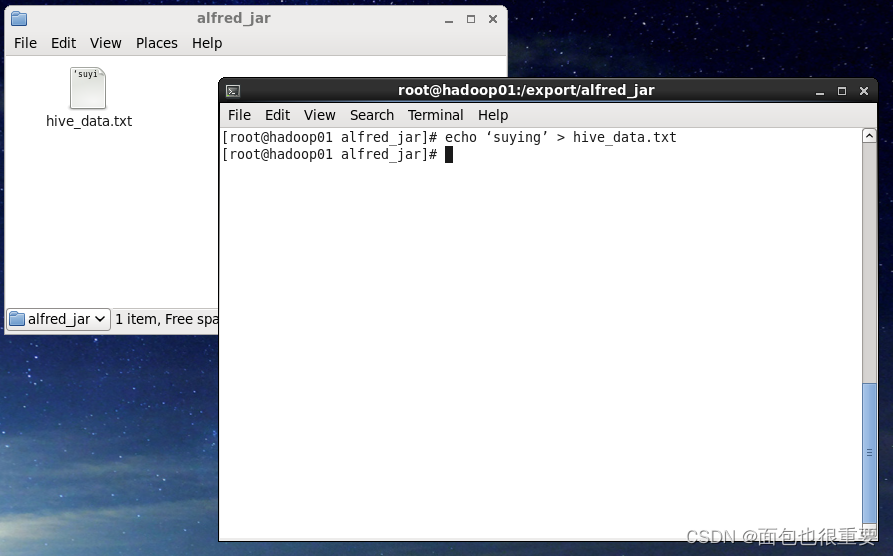
(一)在创建目录:/export/alfred_jar ,并在该目录下运行终端,终端输入:echo ‘suying’ > hive_data.txt ,创建一个名为 hive_data.txt的文本文件
(二)运行hive,创建一个名为my_db2的数据库,查看数据库
hive
hive>show databases;
hive>create database my_db2;
hive>show databases;

(三)选定使用my_db2数据库,创建一个名为my_test的表
hive>use my_db2;
hive>create table my_test(value string);
hive>show tables;
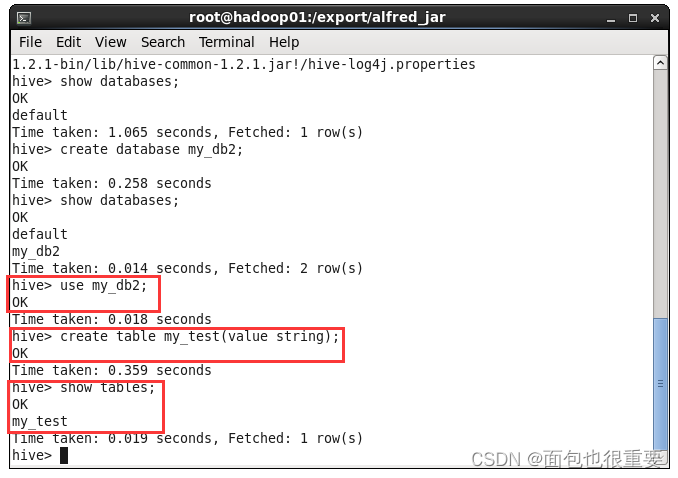
(四)将之前创建的文本文件导入到表中
hive> load data local inpath 'hive_data.txt' overwrite into table my_test;

(五)查询表中内容
hive> select * from my_test;
















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









