






基于中羽在线评论实现的羽毛球拍智能推荐系统
目录
3.1 badmintoncn 数据获取----Scrapy爬虫框架 - 6 -
1背景介绍
羽毛球作为一项广受欢迎的运动,拥有庞大的参与者群体。无论是休闲爱好者还是专业运动员,选择一把合适的羽毛球拍对于提升运动体验、增加训练效果至关重要。然而,市场上的羽毛球拍种类繁多,不同品牌、型号、材质、重量、硬度等因素都可能影响使用体验。对于大多数消费者来说,面对这些多样化的选择,很难确定哪一款羽毛球拍最适合自己。
在此背景下,建立一个智能羽毛球拍推荐系统显得尤为重要。通过个性化推荐,可以根据用户的运动水平、偏好、身体特征以及使用需求,帮助用户筛选出最适合的羽毛球拍,从而提高他们的运动表现和舒适度。同时,智能推荐系统还可以帮助用户节省时间,避免不必要的选择困扰,提升购物体验。
2思路及解决方案
2.1 数据收集与准备
数据是推荐系统的核心,首先需要收集并准备相关的数据,包括用户的基本信息、羽毛球拍的产品特征、用户的反馈数据等。
数据源:中羽在线 - 超人气羽毛球社区 是一个汇集中国羽毛球爱好者与专业运动员的平台,里面收集了大量的球拍数据,用户对球拍的评论,具有很大的价值
**采集方式:**Scrapy 是一个用于网页抓取的 Python 框架,提供高效的爬虫开发工具。它支持并发请求,使用 XPath 或 CSS 选择器提取数据,并能将数据输出到多种格式(如 JSON、CSV)。Scrapy 内置强大的中间件和管道机制,方便处理数据清洗、去重、存储等操作,适用于大规模的网页抓取和数据提取任务。
**数据介绍:**通过scrapy采集数据,在经过一晚上的采集,大约采集了11w条评论数据,评论包含,羽毛球拍eid,评论人名字,评论内容,评论星级,羽毛球拍评分(为了方便就放在这里面了,本来应该放在羽毛球拍信息中的)这五个字段,900条羽毛球拍的信息,由于器材的时效性与主流原因,只收集了这么多,更多的球拍信息不足,或者用的人稀少并没有什么参考价值,就没有进行收集了。以上收集的信息,评论信息存储在comment_data.csv中,羽毛球拍信息存储在info_data.csv中
2.2 数据的预处理
数据预处理是保证推荐系统准确性的关键步骤,涉及以下几个方面:
-
数据清洗:
处理重复存在的数据,人工填补空缺的数据
2.3 推荐算法的设计
1.基于内容的过滤
用户选择重量,品牌,价格都是硬性条件,所以直接从数据中筛出符合条件的数据即可
-
基于内容的近似
我设计了15个标签,分别是“入门,高端,性价比,暴力,进攻,杀球,控制,头重,连贯,速度,中杆硬,中杆软,糖水,颜值,拉吊”,每个羽毛球拍都会由其评论数据得到所对应的标签值是多少,用户输入对这些标签的需求与权重,通过计算推荐加权欧式距离最小的十个数据作为推荐球拍。
**羽毛球标签值的确定:**这个地方采用深度学习的模型来实现羽毛球评论多标签分类的过程
BERT(Bidirectional Encoder Representations from Transformers)是一种深度学习模型,能够在上下文中理解文本的含义。通过预训练,BERT能够捕捉丰富的语言特征和语义信息。在这个代码中,我使用了 BERT 的中文预训练模型 (bert-base-chinese) 来进行文本分类任务。
模型架构如下:
基于中文BERT预训练模型:
我使用了 bert-base-chinese 作为预训练模型。BERT 是一个 Transformer-based 的模型,能够从大量文本中学习语言表示,适用于各种自然语言处理任务。在这个模型中,BERT 的输出主要是一个包含每个输入词汇向量的编码和整个句子的表示(pooled_output)。
添加了线性分类层:
在 BERT 的输出上添加了一个全连接层(Linear),将 BERT 的隐藏状态(通常是 pooled_output,即最后一个层的句子级别的表示)映射到标签空间。每个标签都有一个独立的神经元,输出维度为标签的数量。
使用 Sigmoid 激活函数:
对于每个标签,输出的结果经过 Sigmoid 激活函数转化为概率值。Sigmoid 会将每个标签的输出映射到 [0, 1] 之间,表示该标签属于当前评论的概率。
使用二元交叉熵损失函数:
由于这是一个多标签分类问题,每个标签是一个独立的二分类问题。因此,采用 Binary Cross-Entropy Loss(二元交叉熵损失函数)来计算损失。该损失函数衡量了每个标签的预测概率与真实标签之间的误差。
训练数据为另外爬取的1500条数据,使用人工的标注的方式来对1500条评论设置标签值是多少。
模型训练完毕后,通过模型来预测每条评论所对应的15个标签值,预测完成后,根据eid为分组,统计每个标签值之和/评论个数作为该羽毛球拍的所有标签值。考虑到较少的评论并不具有代表性可能会造成数据异常,故而使用sigmod函数对羽毛球拍标签计算后乘一个权重,设置beta值为50,使得50条评论以上的时候,才能代表羽毛球拍的标签得分。
公式表示如下:
BadmintonRacketscore=Sum(commentscore)/Sum(comment)/(1+0.1∗exp(x−50))
其中x表示评论数量
在计算完后,发现得分值大多都比较低,此时使用了一个归一化操作,避免再后续计算欧氏距离的时候,不同项造成的影响不一样。
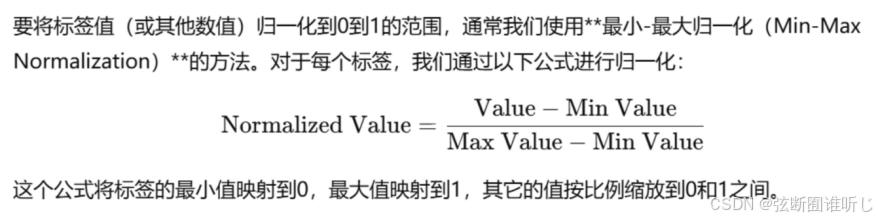
归一化完成后,通过计算输入与羽毛球特征空间的欧氏距离,得到最小的10个值就是推荐的羽毛球拍。
3实现及代码介绍
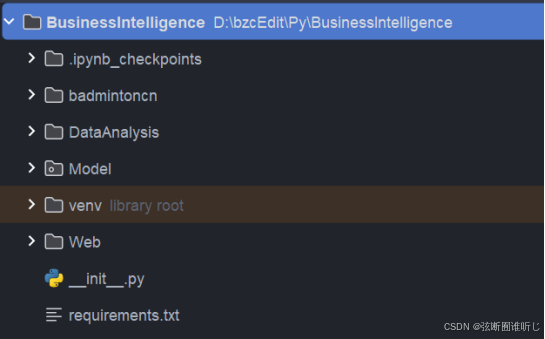
项目结构如下,badmintoncn是用于爬取数据,DataAnalysis用于实现数据价值的挖掘,做了数据的可视化,Model则是构建并训练评论文本多标签分类模型,Web是做了一个简单的功能展示,下面我将分别介绍这些功能及代码。
3.1 badmintoncn 数据获取----Scrapy爬虫框架
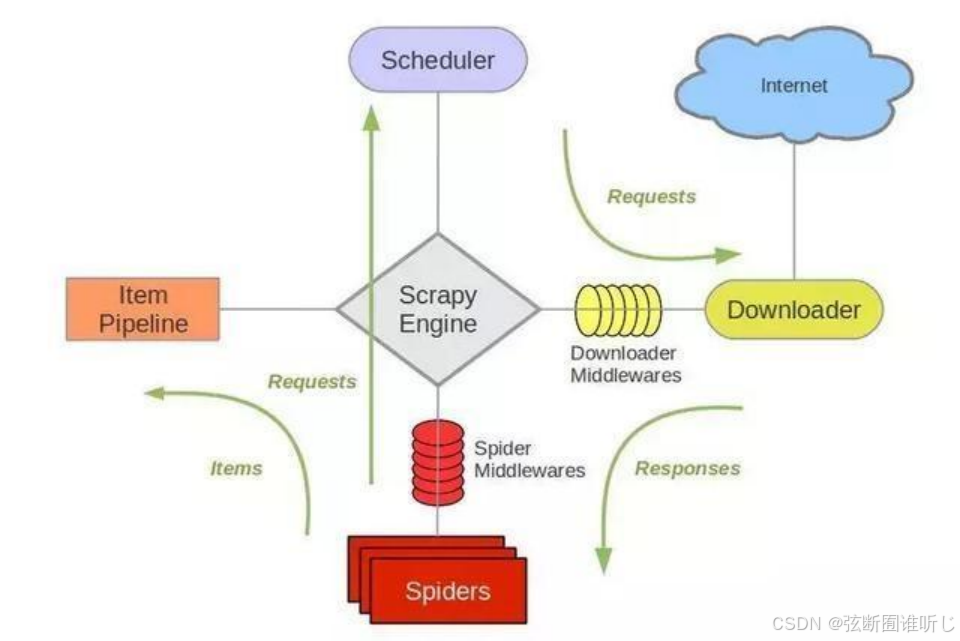
上图是Scrapy官方给出的架构,主要由五大组件组成,它们分别是调度器(Scheduler)、下载器(Downloader)、爬虫(Spider)和实体管道(Item Pipeline)、Scrapy引擎(Scrapy Engine)。
爬虫部分的文件展示如下:
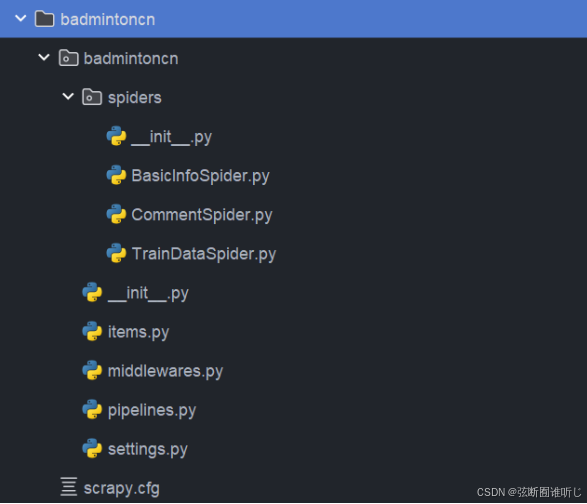
BasicInfoSpider.py是用于羽毛球拍基本信息的获取,CommentSpider.py是评论数据的获取,TrainDataSpider.py是用于训练数据的获取
该网站爬取的难度并不大,仅仅是一个简单的request发送请求,xpath解析数据就没了,此处不予赘述。
在pipline.py中,定义了一个XlsxExportPipeline类,用于数据的导出(本来是想保存到xlxs中的,后来发现csv格式更常见),实现即把item加入到类成员列表里面,当爬虫关闭的时候,调用close_spider根据爬虫的名字spider.name知道是哪一个爬虫,保存到对应的csv文件中。
在items.py中定义了数据的格式应该是怎样的
在middlewares.py中定义了两个类,RandomProxyMiddleware,
CustomRetryMiddleware(RetryMiddleware),其中第一个类适用于切换代理ip避免请求频率过高被封ip,花9块钱买了3000个代理,5分钟更新一次代理池。第二个类用于重新发起请求,由于网站的封控机制,可能会出现403的错误,为了数据尽可能的完善,当错误码是403时再次延迟几秒更换再次发送请求,实现数据的再爬取。
此外,在settings.py里设置中间件的优先级等,设置下载延迟为2s,避免过快被封ip,设置请求头防止检测为机器人,设置cookie实现免登录。
3.2 DataAnalysis 数据的可视化
文件结构如下,data目录是用于存放数据的地方
对文件的一些介绍:
comment_data.csv:爬取到的评论数据
commment_data_with_tags.csv:使用模型对评论进行预测打上标签值后的数据
data.csv:最终用到的数据,包含羽毛球拍基本信息和标签值
info_data.csv:爬取到的球拍信息,不含标签信息
sum_data.csv:为了方便将info_data和comment_data内连接的数据,可有可无
train_data.csv:爬取到的训练数据,再经过人工标注。
show.ipyb:用于做数据的可视化,生成了词云信息查看羽毛球爱好者通常怎样描述球拍获得更具有特色的标签,可视化成饼状图查看羽毛球拍评论的分布,生成竖状图查看价格大致分布。最后在预测完后查看,第一个推荐的羽毛球拍的词云,确实是符合标签的。
3.3 Model 评论多标签分类的具体实现
Model文件夹展示如下,models用于存储训练好的模型,plots保存了训练过程中的损失变化,model定义了模型和训练过程。
下面是对model.py的详细介绍:
BadmintonDataset 通过继承自 PyTorch 的 Dataset 类,使得文本数据能够被 DataLoader 以批次形式处理,它的作用是将原始文本和标签转换为 BERT 模型所需要的 input_ids 和 attention_mask,并提供对应的标签用于训练或评估。
Tools类将预测功能导出使用,在构造函数指定了模型,避免每次使用都重新加载模型,预测调用成员函数即可实现预测
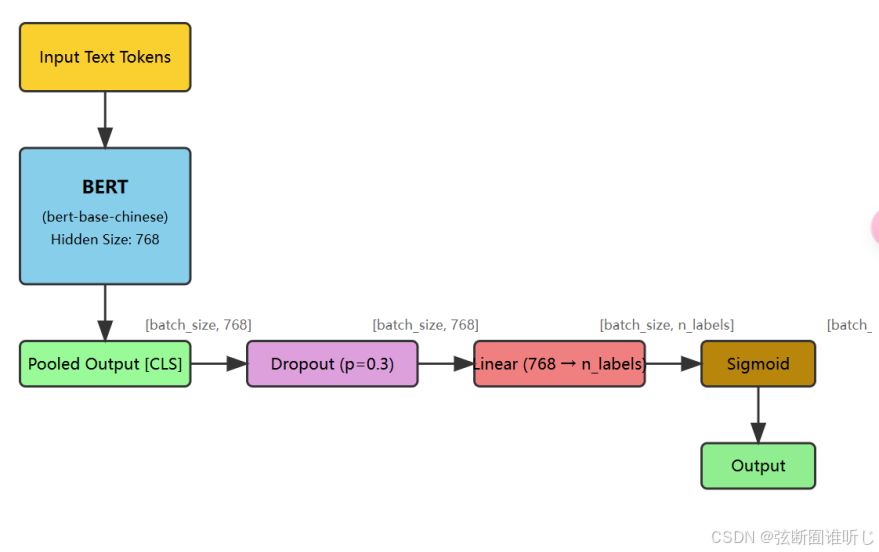
BadmintonBertClassifier 是一个基于 BERT 模型的自定义神经网络,专门用于多标签分类任务。在构造函数里,使用的是中文 bert-base-chinese,BertModel.from_pretrained(‘bert-base-chinese’) 会加载预训练模型的权重,这样可以使用 BERT 模型已经学到的语言知识进行下游任务的学习。此外,定义了一个 Dropout 层,nn.Dropout(0.3)。0.3 表示每次前向传播时有 30% 的神经元将被随机丢弃,用于防止过拟合。
self.classifier是一个全连接层(nn.Linear),将 BERT 输出的向量(大小为 bert.config.hidden_size,对于 bert-base-chinese 是 768)映射到 n_labels 个输出标签,
全连接层会将 BERT 的输出进一步映射为与分类任务相关的标签数量。
self.sigmoid是一个 Sigmoid 激活函数,用于多标签分类任务。Sigmoid 将每个输出值映射到 (0, 1) 之间,用于表示标签是否存在。对于多标签分类,每个标签都有一个单独的 Sigmoid 输出,用于预测标签的概率(不是互斥的)。
网络架构展示如下
train_model定义了模型是如何训练的,并保存了模型和损失曲线,在main函数中,开始训练设置batch_size=16,训练批次,定义优化器为AdamW优化器并设置学习率为2e-5,损失函数nn.BCEloss()设置为二元交叉熵损失,适用于多标签分类,并设置训练15次。训练过程的,损失曲线如下图所示:
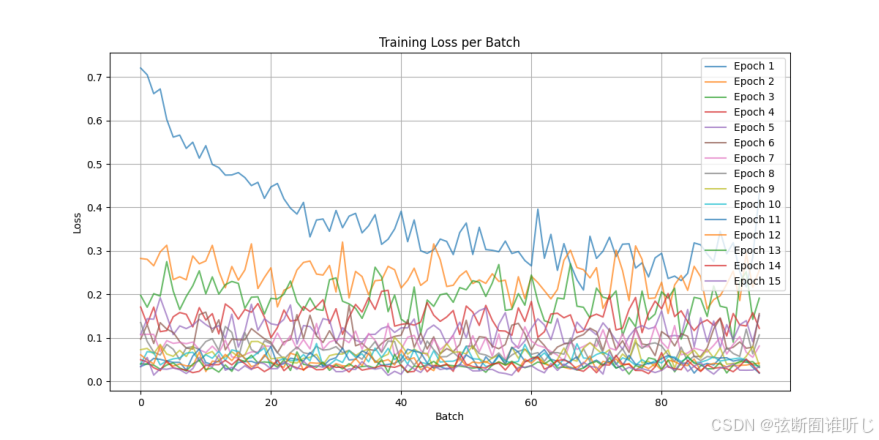
(约epoch 10之后)的曲线基本稳定在较低水平,曲线之间的重叠增多,说明模型逐渐达到收敛状态
3.4 Web 功能的可视化展示
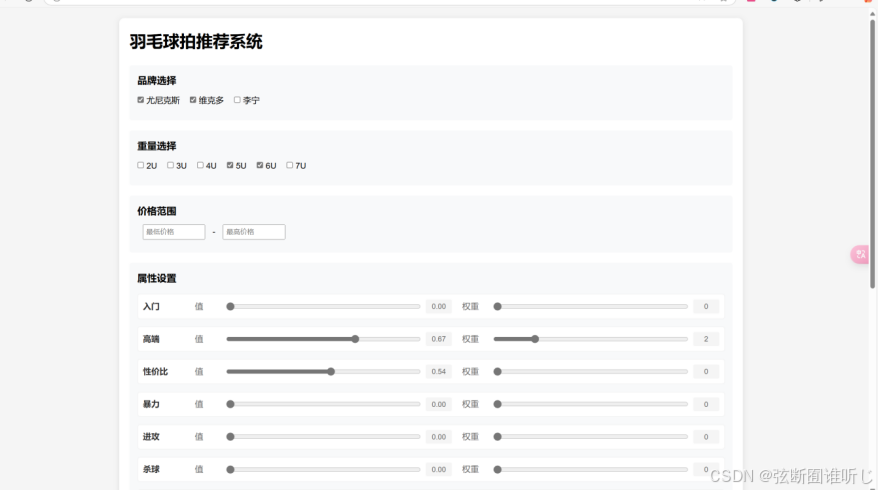
文件目录结构如下:这个是基于flask框架实现的,典型的结构,index.html是主页,可以选择品牌,重量,价格,以及15个标签的需求,当然这些也都可以不选,可选可不选,系统会根据表单数据做出推荐。展示如下:
recommenddations.html在接受后端的数据后,以可视化的方式展现推荐的10个羽毛球拍,给出了一些大致的参数,也给了直达中羽在线的链接,方便用户的使用,展示如下: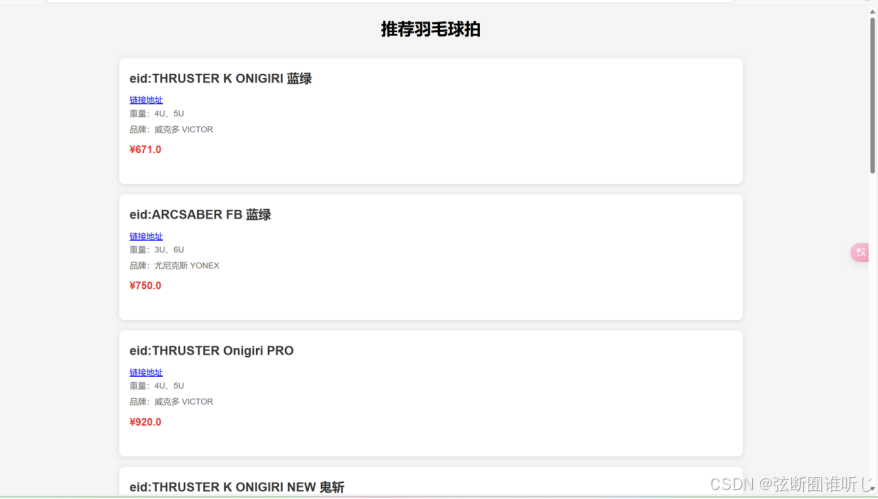
API.py则是具体推荐算法的实现,首先数据会从data.csv读取到data中,先复制一份数据以免后续操作破坏原数据
def filters(data_all, brand=None, weight=None, price_start=0, price_end=1000000):
Filters函数先根据品牌,重量,价格等信息过滤出符合要求的数据。
在得到过滤后的数据filtered_data后判断是否有标签需求,如果没有直接返回前10条数据,如果有,则根据要求标签值和权重值进行加权欧氏距离计算,注意,此处未选择的标签是不会参与计算的,既提高了精度又避免了冗余计算,最后返回distance最小的前10条数据。
4总结与展望
测试结果,输入300-700区间,指定品牌为李宁,重量为3U-4U,杀球,进攻,暴力拉满
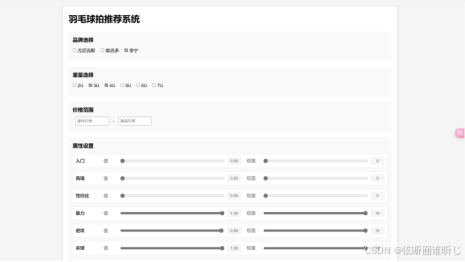
查看预测结构
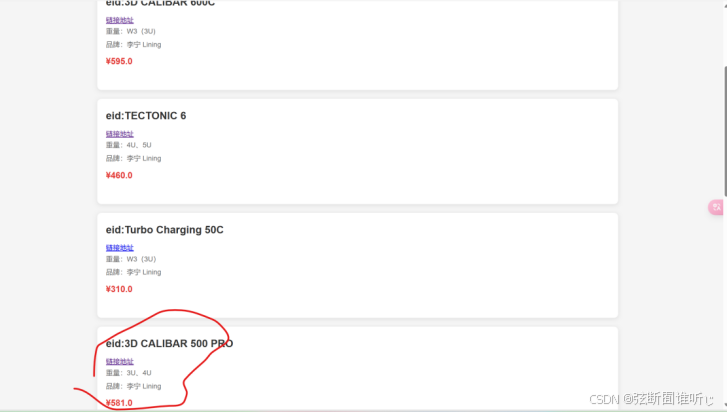
这是本人用的风刃500pro确实很符合,故而该羽毛球推荐系统大致实现了需求。
展望:
-
随着数据采集技术的进步,推荐系统将能更加精准地根据用户的个人需求、打球习惯和技术水平提供定制化的羽毛球拍推荐。例如,结合用户的身体特征(如手腕力量、握力等)和运动表现(如击球速度、控制力等),系统可以实现更为细致的个性化建议
-
随着社交平台的兴起,未来的羽毛球拍推荐系统可能会与社交平台进行深度融合,基于用户在社交网络上的互动数据(如分享、评论、点赞等)进行推荐优化。通过与各大运动品牌和羽毛球社群的合作,用户还可以分享自己的装备使用经验、技巧和训练视频,从而形成更加互动和多元的社交网络。
-
未来,可以利用深度学习算法进一步优化推荐系统的准确性,结合用户在不同环境、场地条件下的打球反馈数据,实现实时更新与精准预测。此外,系统可通过实时反馈机制(如羽毛球拍的使用寿命、适配性调整等)帮助用户随时调整运动装备,提升运动体验。
使用说明:位于代码文件夹下的README.md中
- 7 -


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









