







这里写目录标题
指针引用与指针值拷贝的区别
指针值拷贝
值拷贝只是将指针变量所存储的地址拷贝一份给到函数参数指针,这样,在函数内部的指针通过这个地址修改的内容会同步到main
指针引用
指针引用,是对main中实参指针变量的引用,所以,函数指针就是main中的实参指针,他可以通过自己存储的地址修改内容,同步到main
同时,因为是引用,所以,在函数内部修改指针所存储的值,也会同步回去,而指针变量所存储的,就是其所指向的内存的地址号,所以,他还可以实现在函数内部修改指针的指向,这个指向的修改也会同步回mian函数
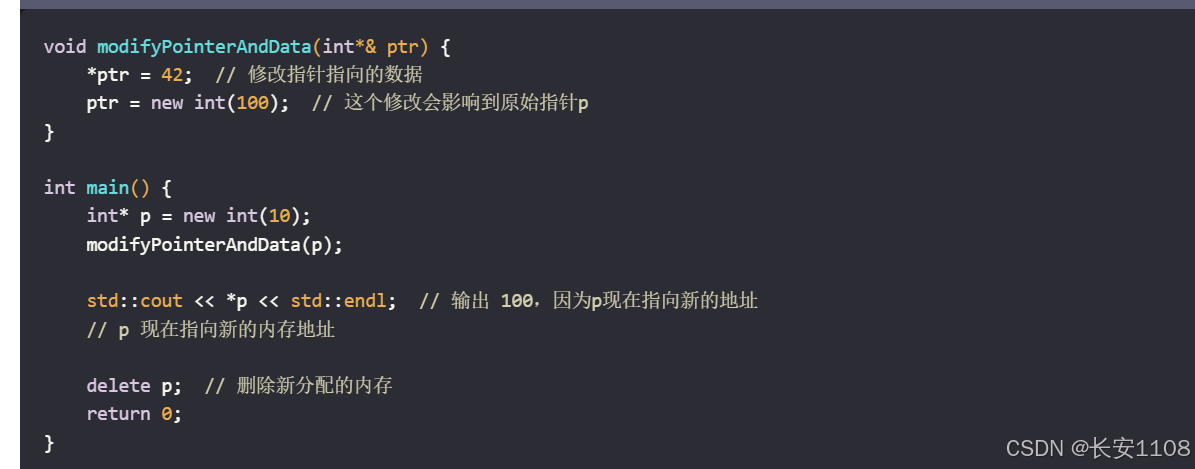
参数定义方法:int* & ptr
(将in* 视为一个类型名整体,在类型名和变量名中间加&,表示引用)
总结

命名空间
简介


命名空间的范围
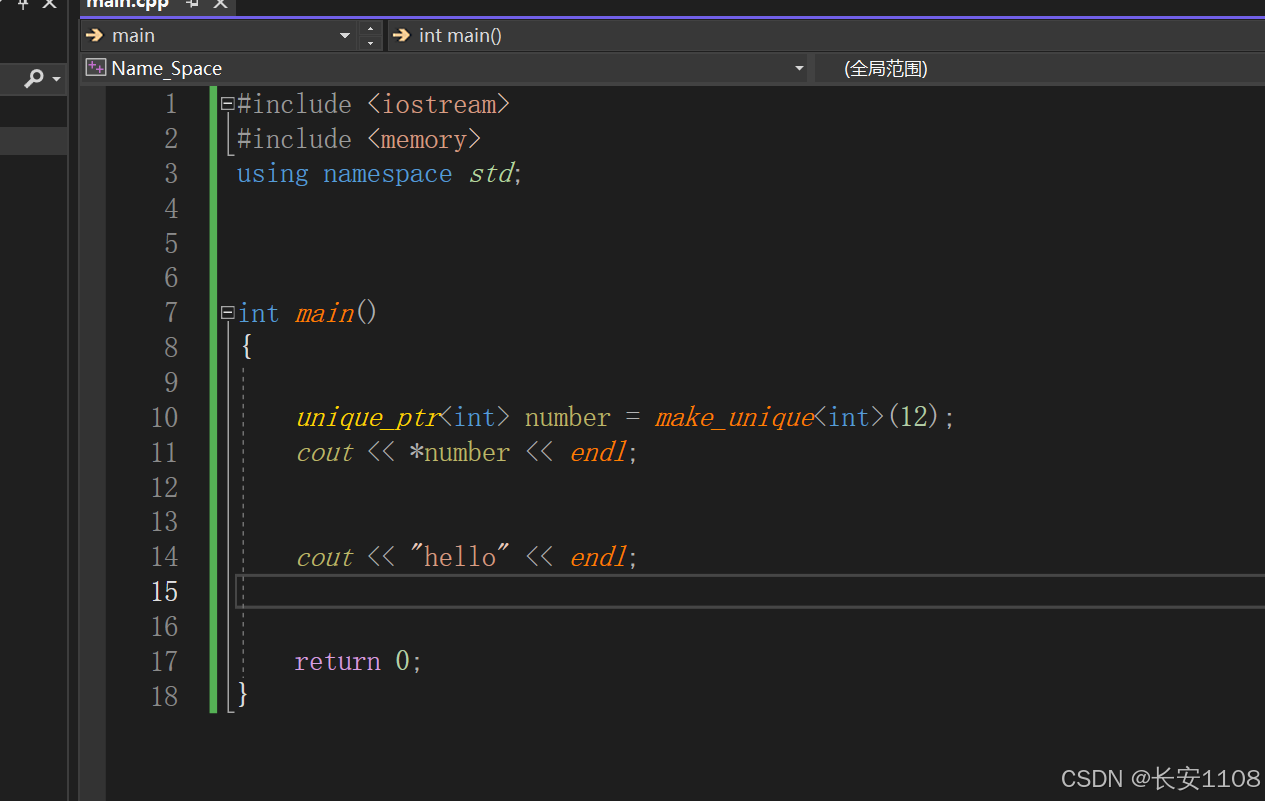
上述包含一个头文件memory,这是智能指针的头文件,之后使用using namespace std,可以看到,在main函数中可以直接使用其模版创建一个智能指针,这个时候对于命名空间的范围可能还没有感觉
接下来,我们将using namespace去除,而是使用std进行指定:
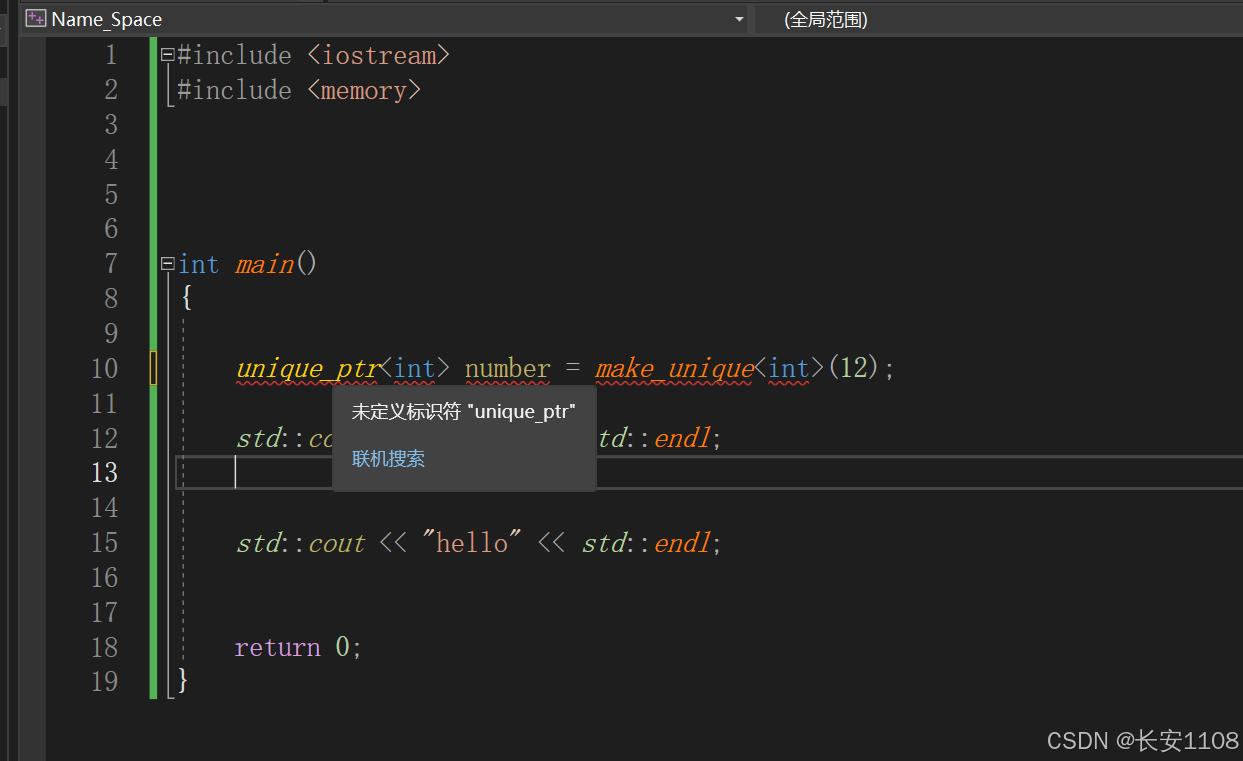
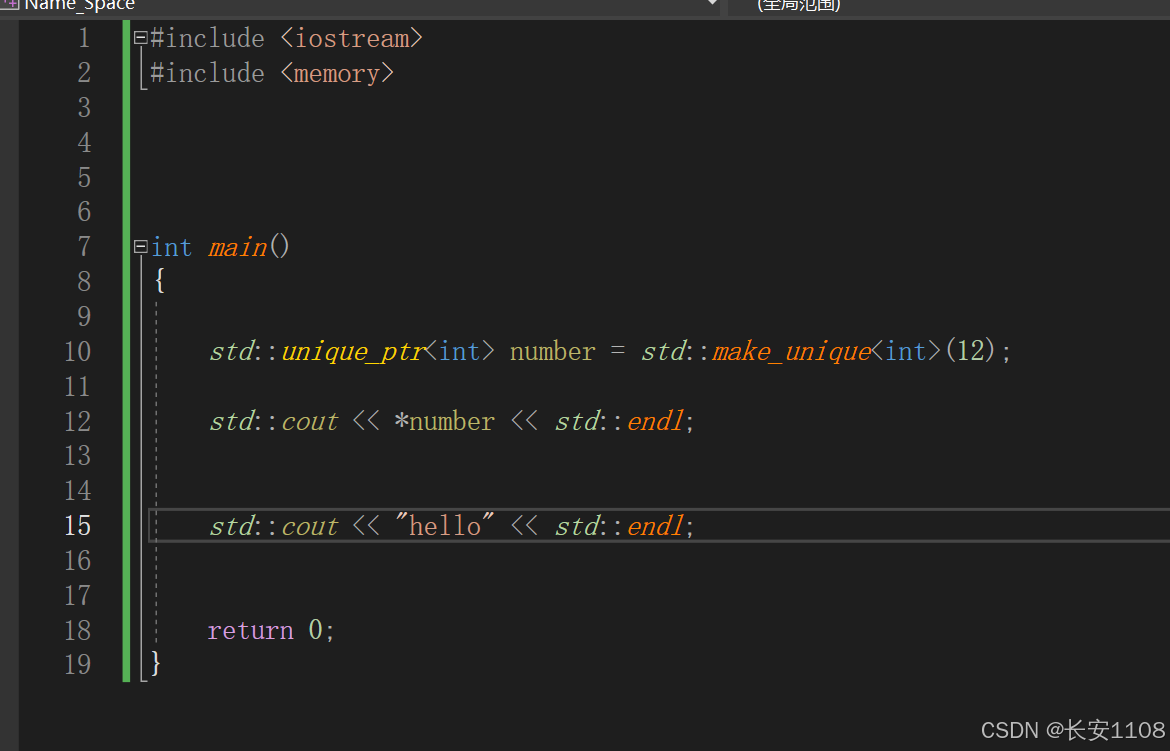
可以看到,不管是iostream中的cout、endl
还是memory中的智能指针
都需要使用std进行限定才能正常使用,所以,这说明,命名空间是一个作用域的定义,他对头文件中可以声明的任何东西(自定义数据类型(类名、结构体名)、变量名(使用extern进行声明)、函数声明)进行一个更大的作用域的限定
一个命名空间,可以包含多个头文件,将多个头文件限定到一起
补充:
using namespace的作用
简介
命名空间一般定义在头文件中,他会框起来一些类型名、变量名、函数名的声明,表示这些自定义数据类型(如类,或者结构体)、变量、函数声明在当前的命名空间内
(ps:变量名一般使用extern声明)
使用using namespace引入命名空间的注意点
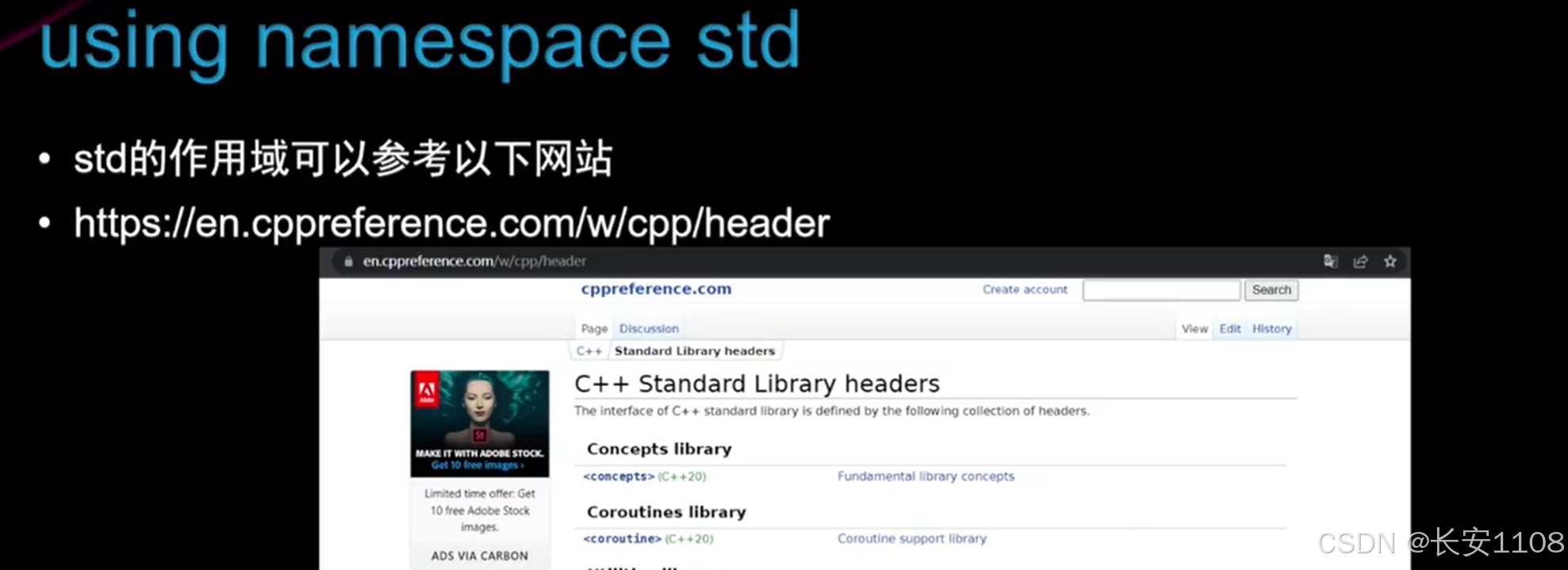
而当我们使用using namespace 直接引入一个命名空间时,他就会将这个命名空间内的声明都引入到当前文件内,那么当前文件内的自定义类型(如类,结构体)的类名,以及变量名、自定义函数的声明,就不能与所引入的命名空间中已经有的类名、变量名、函数声明一样,不然会产生歧义,如下图:
我们直接引入了std,那么当前文件中的类名以及函数声明都被std所“污染”,也就是你接下来所有的自定义类名或者函数声明,不能与std冲突,如上图
可以理解为,命名空间是一个作用域的定义,一旦你引入了某个命名空间,他就会将该命名空间作用域中的声明都放入全局
所以,一般不推荐使用using namespace来引入,而是使用命名空间中的类名、变量名、函数时,使用命名空间来进行限定即可
当然,有时候使用using namespace std还是有好处的,毕竟可以提高编写效率等,视情况而定
空::
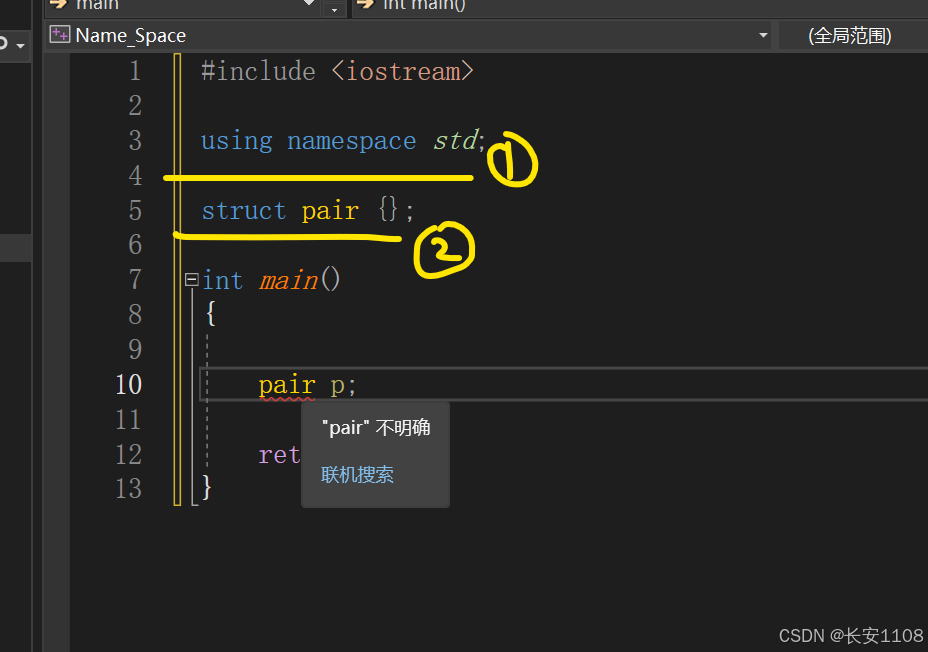
经典使用场景
而如果非要使用using namespace ;来引入,且此时原本的全局作用域中与std中的声明起了冲突,此时在使用时,可以在前面加上一个“::”,双冒号前面什么也不用加,这表示指明使用当前文件原生态的全局作用域下的声明,如上图
另一种使用场景(解决与命名空间名字冲突)
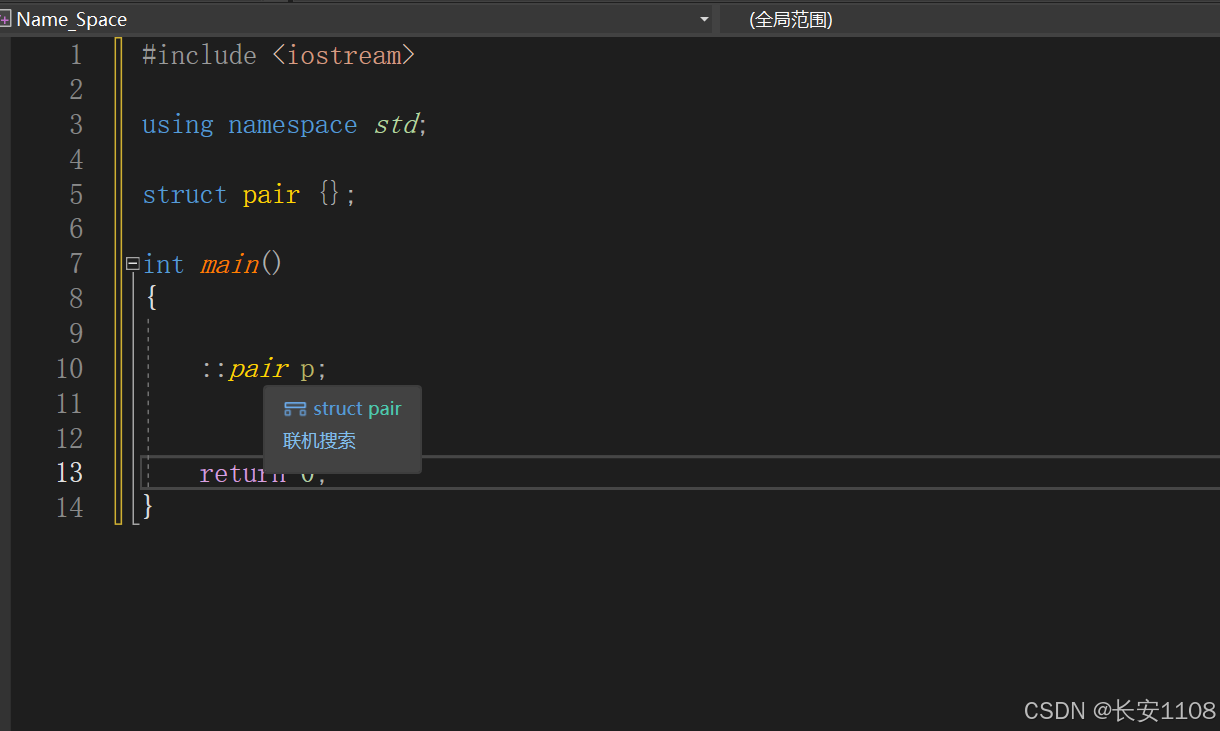
1、
假如我们定义了一个命名空间:AA,在该空间内定义了一个与命名空间名字冲突的类名
此时由于类名std被框在命名空间AA内,且没有使用using namespace全局引入,所以,不会对外面产生影响
2、
而如果没有了命名空间,那么注定会起冲突,且无法解决,除非改变类名
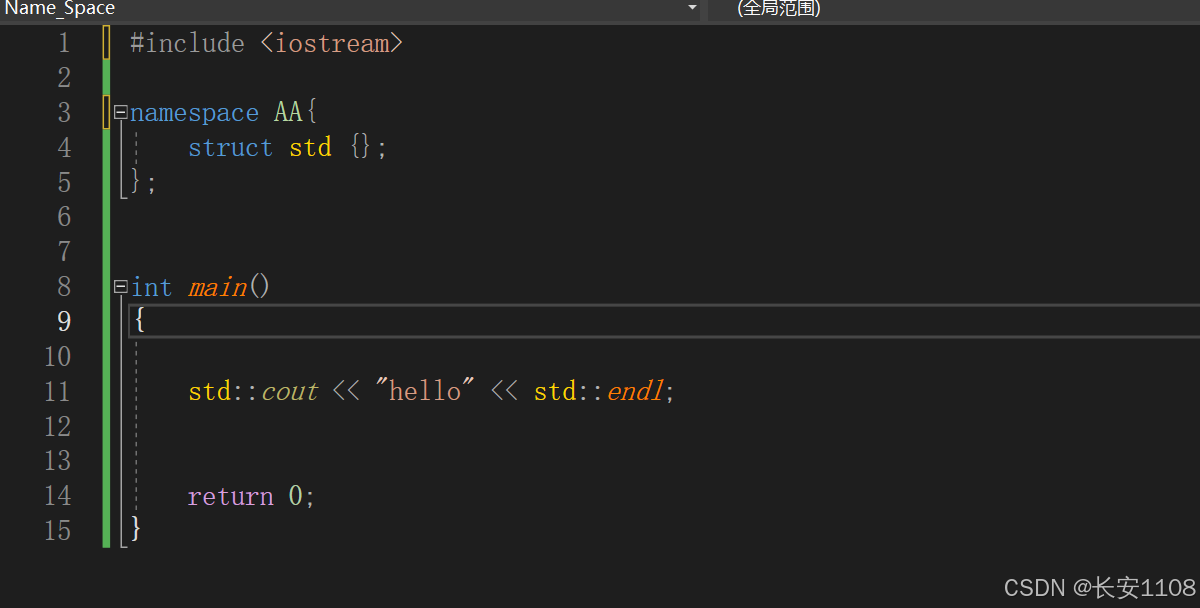
3、而如果此时AA这个命名空间,改为了匿名命名空间:
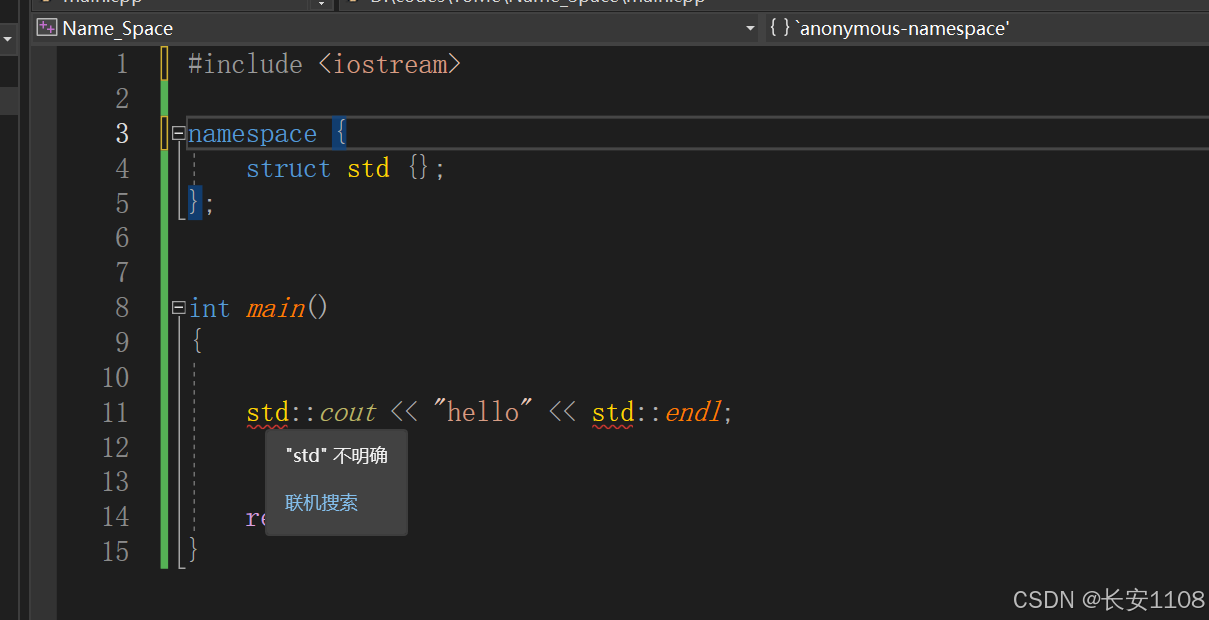
使用匿名命名空间的话,上述场景就会产生冲突,此时,可以使用“空::”来解决
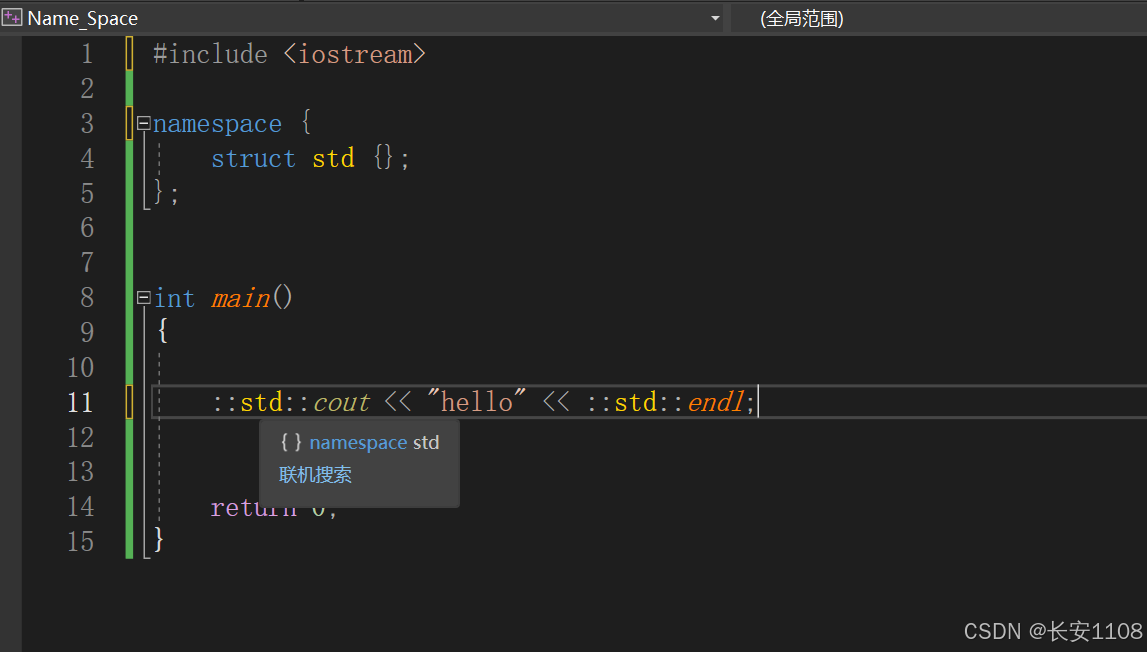
此时使用"空::"就会指明是std是命名空间的名字,而不是某个类名,因为此时std这个命名空间的名字,是在全局下的
创建命名空间
单文件创建命名空间
简介

代码
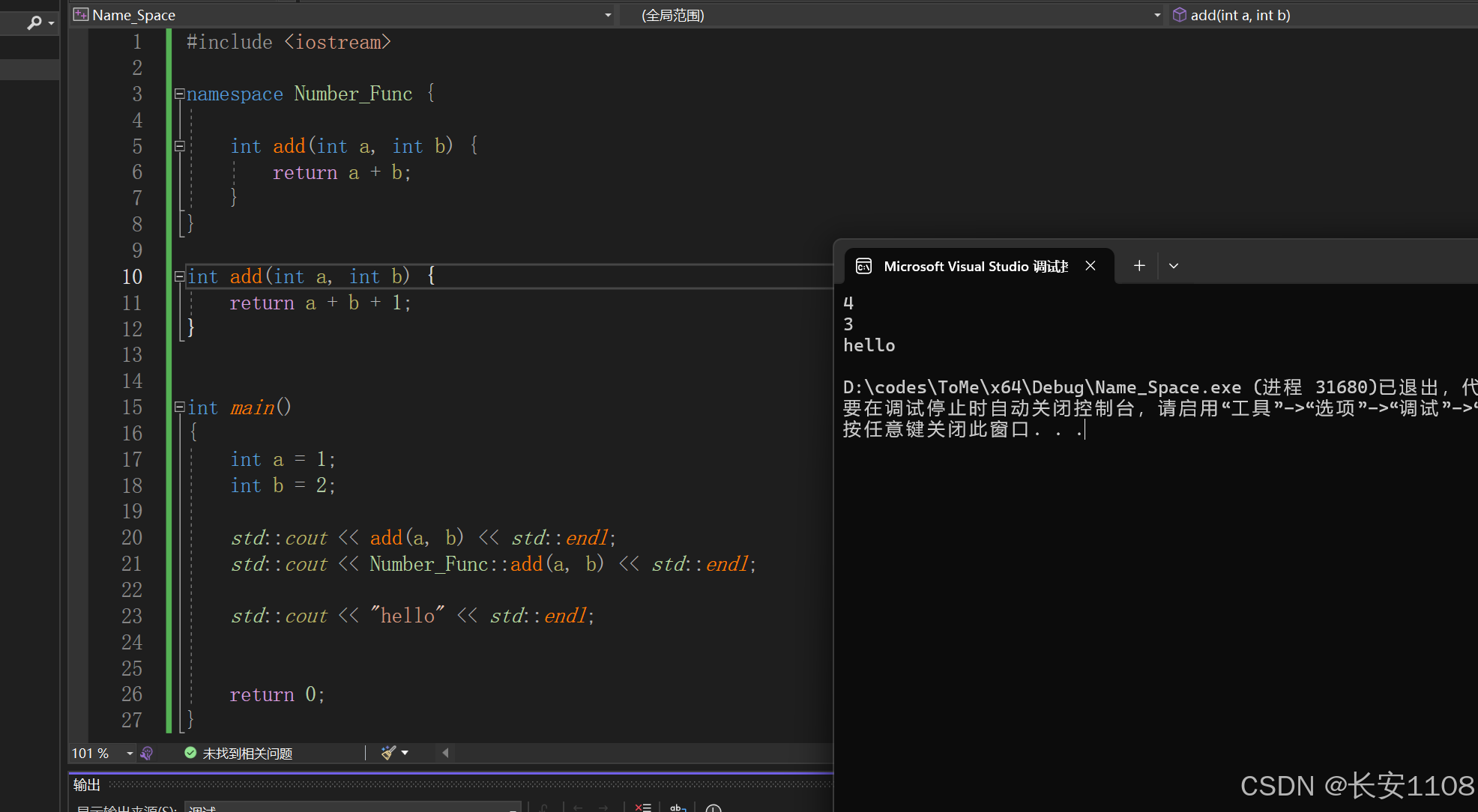
多文件创建命名空间
简介

代码
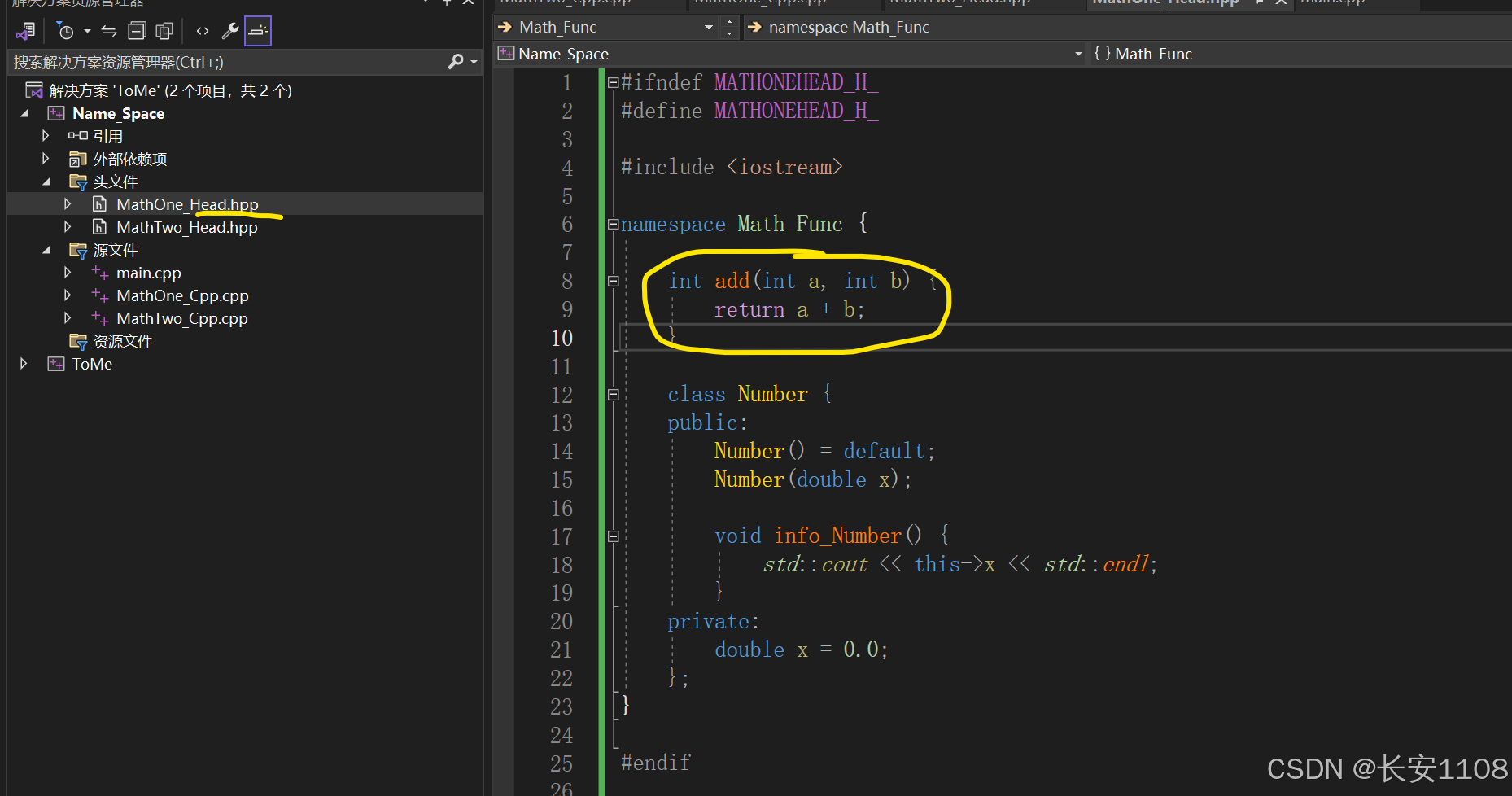
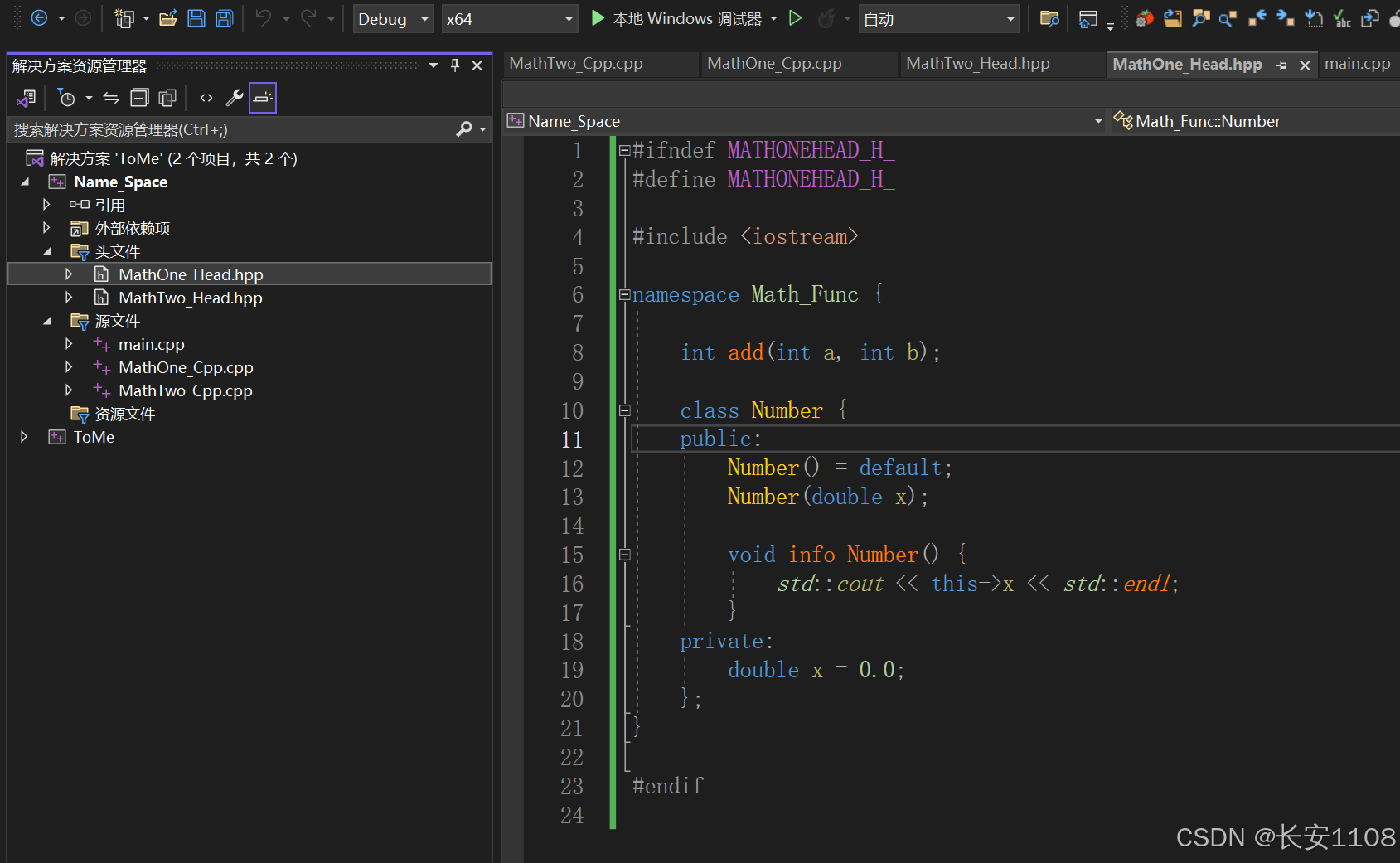
头文件以及实现
第一个头文件:
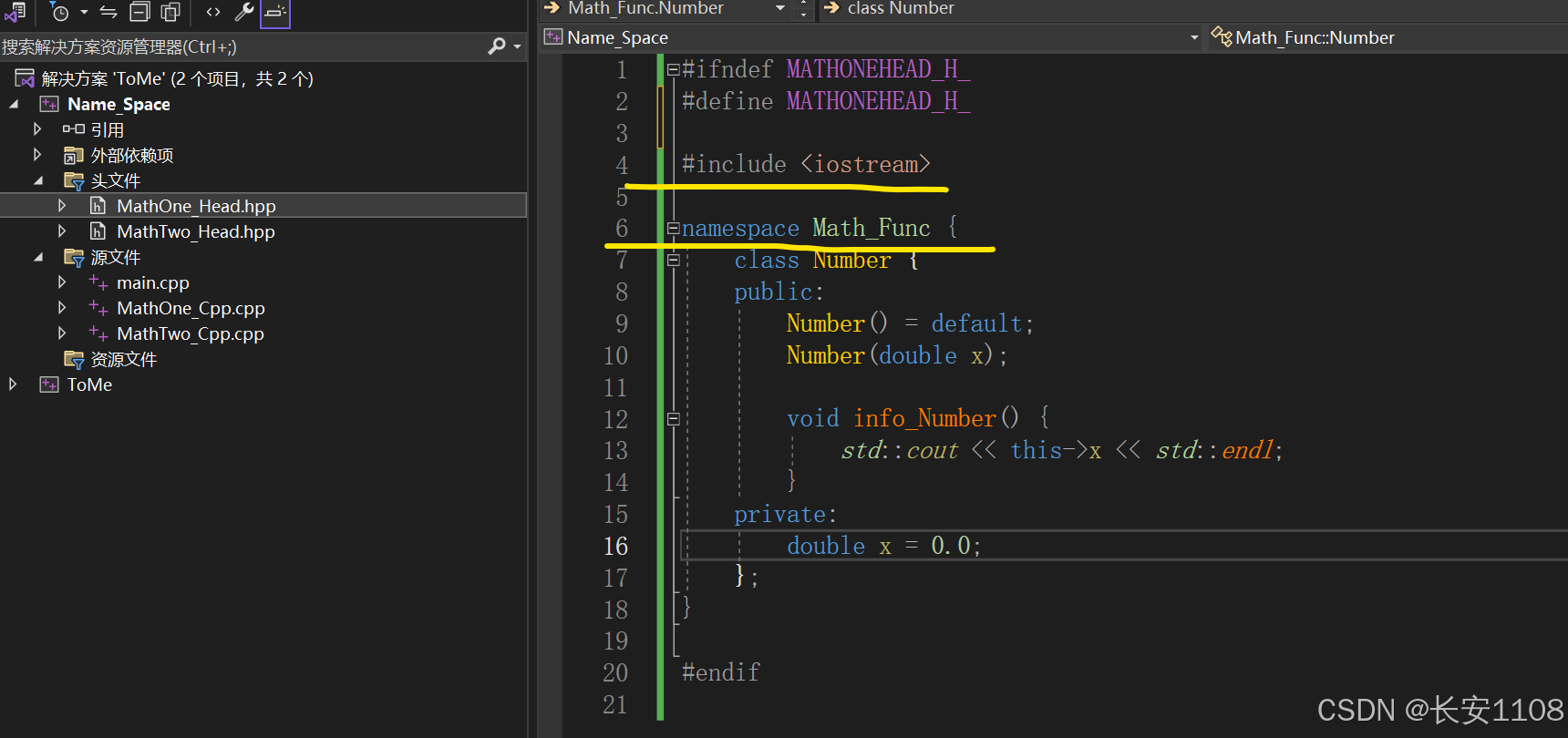
注意点:
1、头文件中如果需要打印,则不要使用using namespace,避免声明污染
2、记得包含当前头文件所要使用的其他头文件(如cout),且不要认为加了std就不用包含头文件了,这是两码事,况且,是std的范围大,iostream的范围小,std中包含了许多的头文件,不包含会报错如下图:
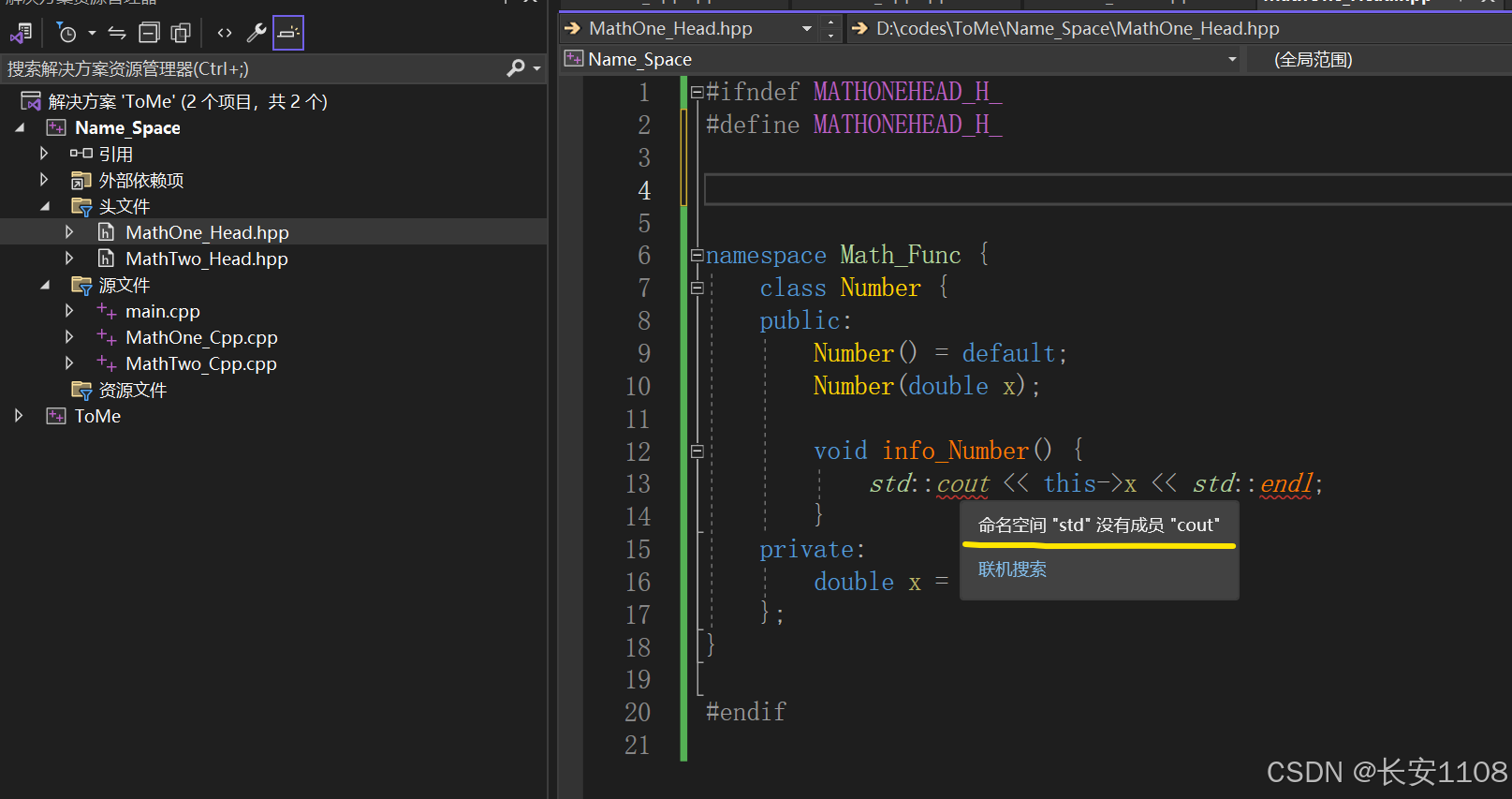
3、头文件定义自定义命名空间,如上图所示
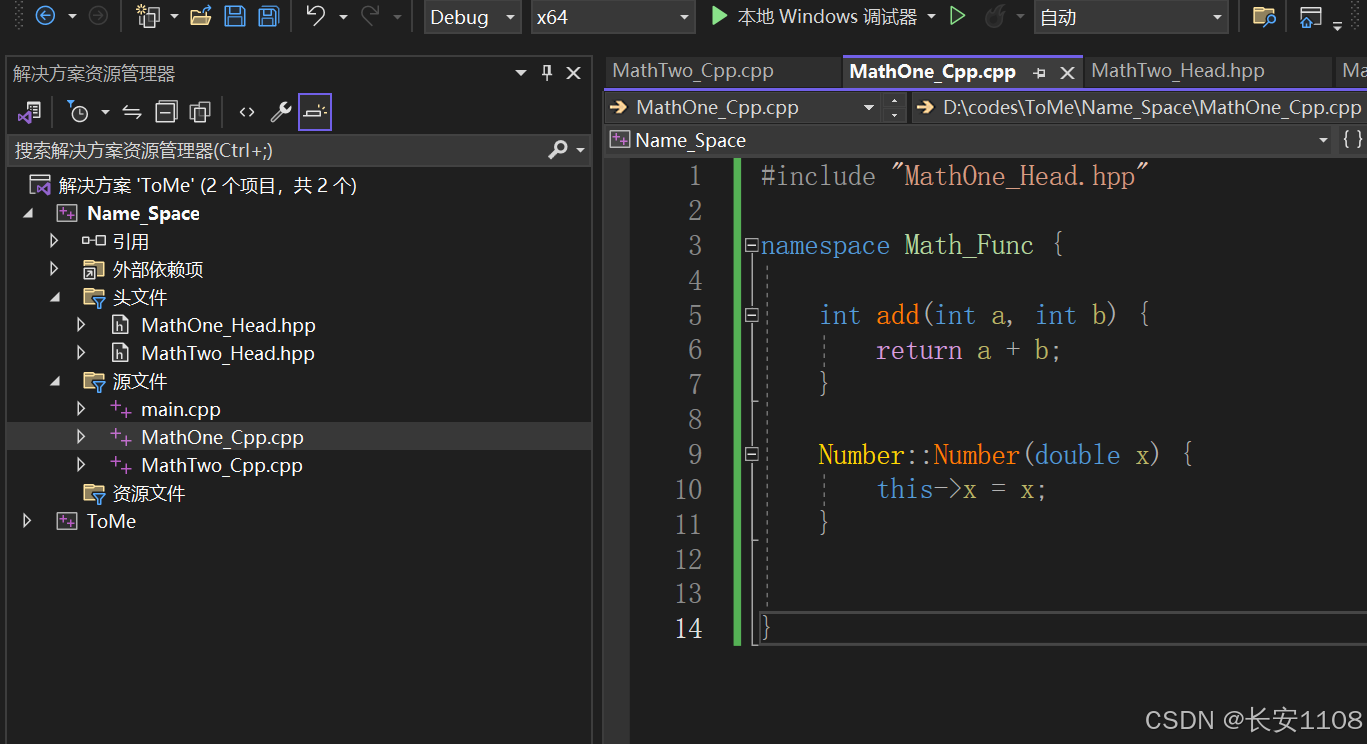
第一个头文件的实现文件:
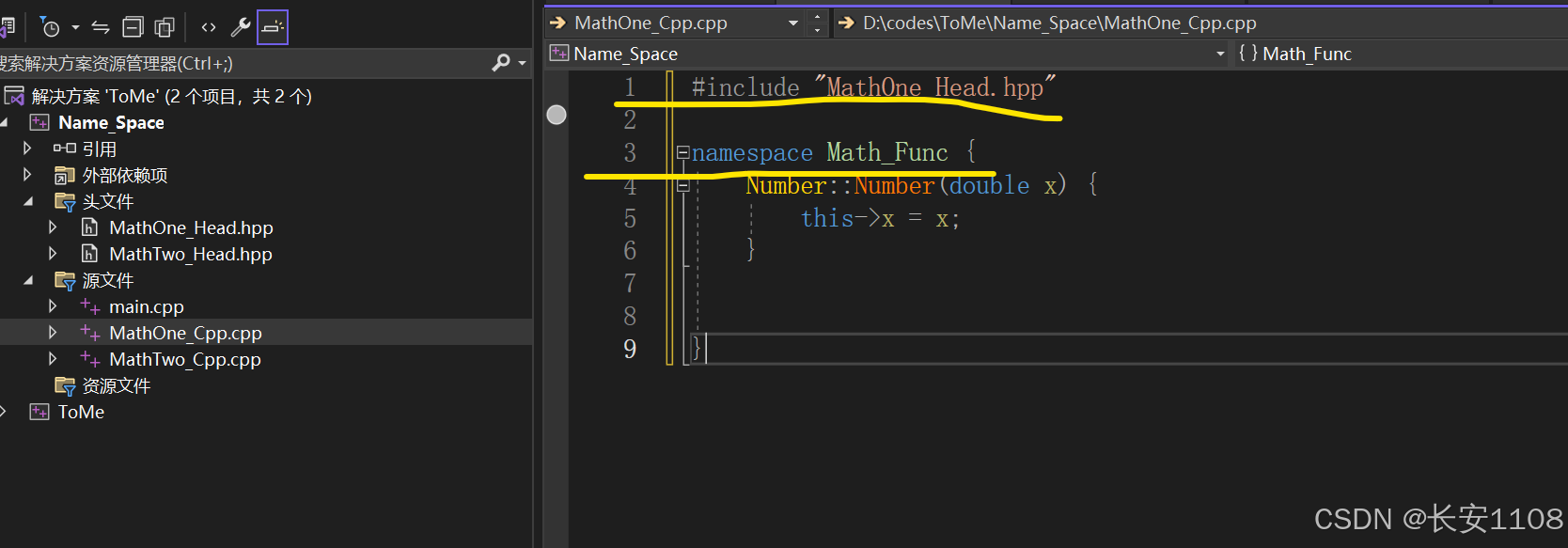
注意点:
1、仍然是要包含对应的头文件
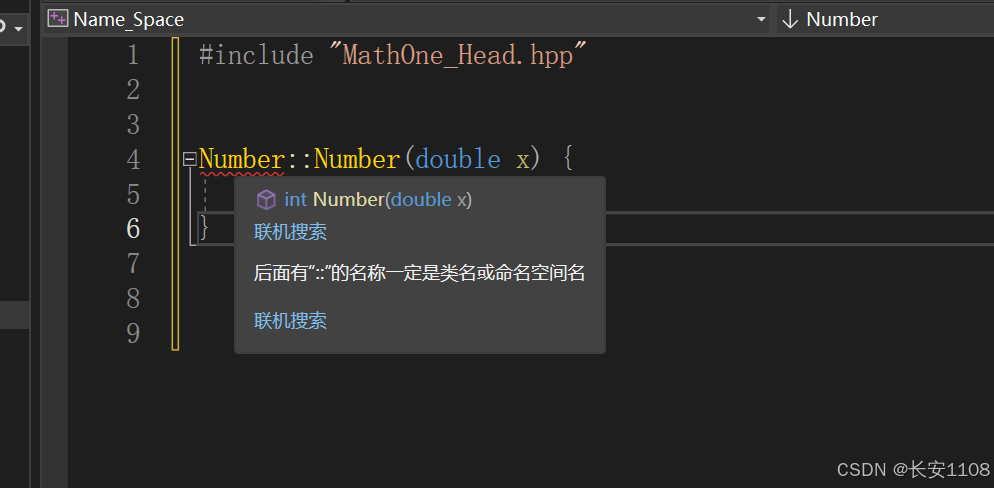
2、在实现头文件的函数时,还需要加上命名空间,如果不加会报错:
第二个头文件和实现文件:
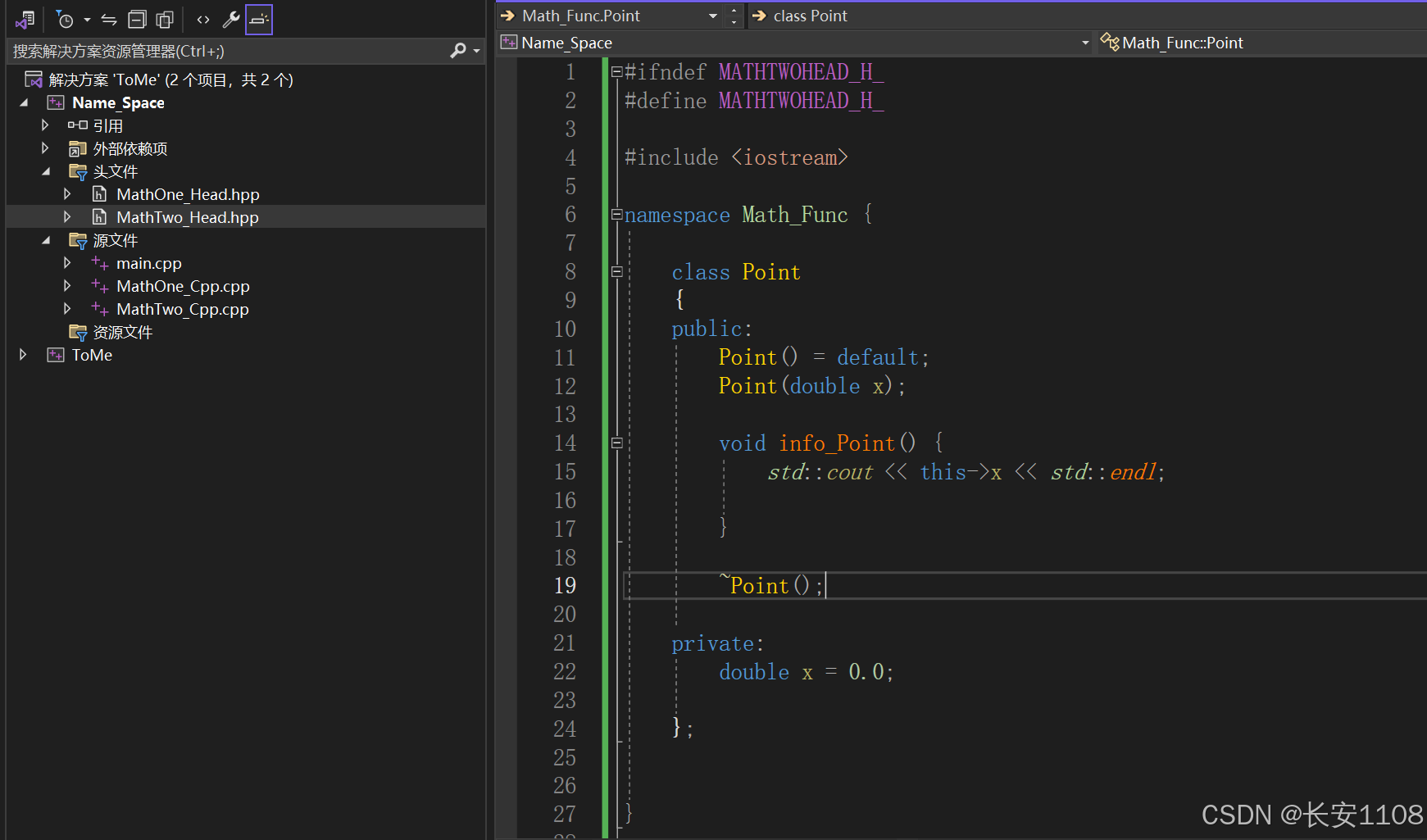
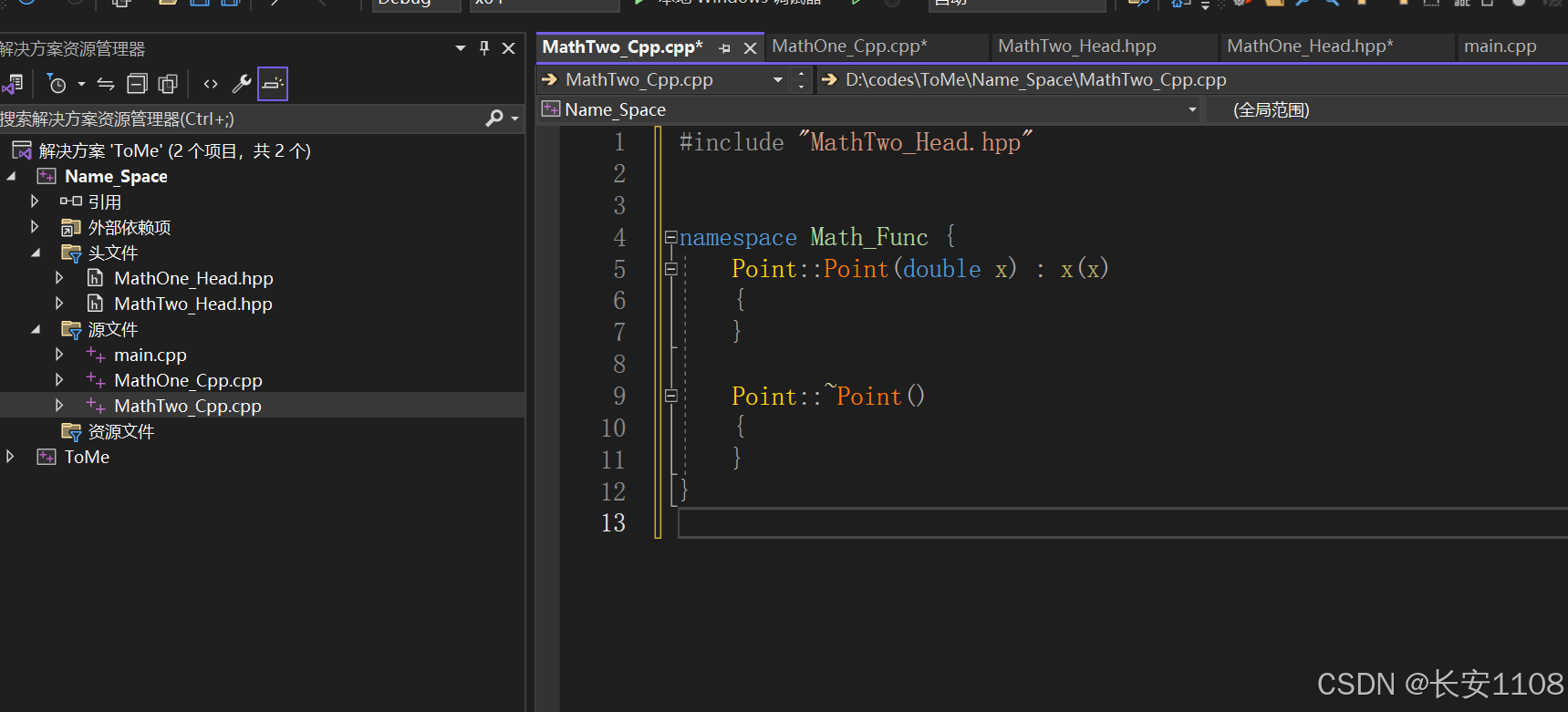
注意点:
1、头文件中的default,表示让编译器生成默认的实现,我们在实现文件中无需再实现,该语法只能对那6种类的默认函数有效
且由于声明了无参构造,所以此时无参构造不会因为有有参构造而消失,(注意该效果不是default实现的,而是由于声明了无参构造)
2、两个头文件,定义了同一个命名空间
main调用
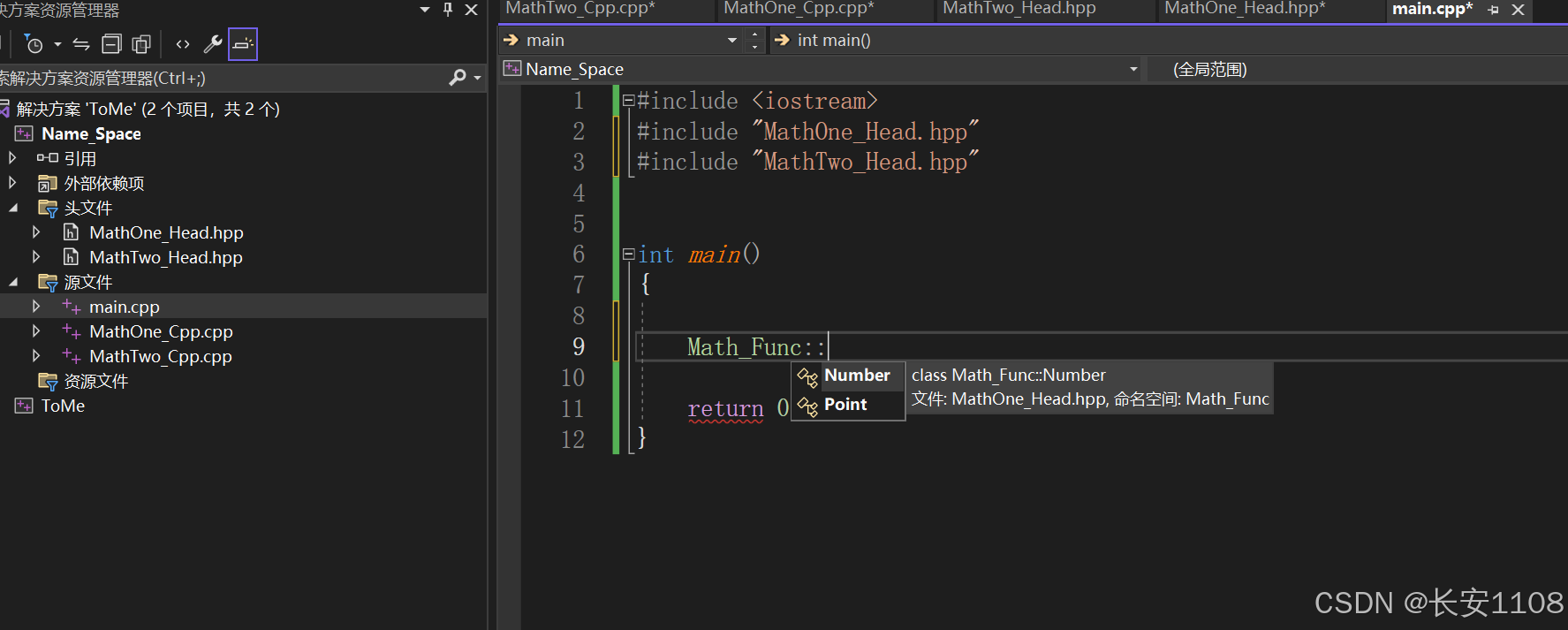
此时可以看到,同一个命名空间下,可以使用两个头文件中的类
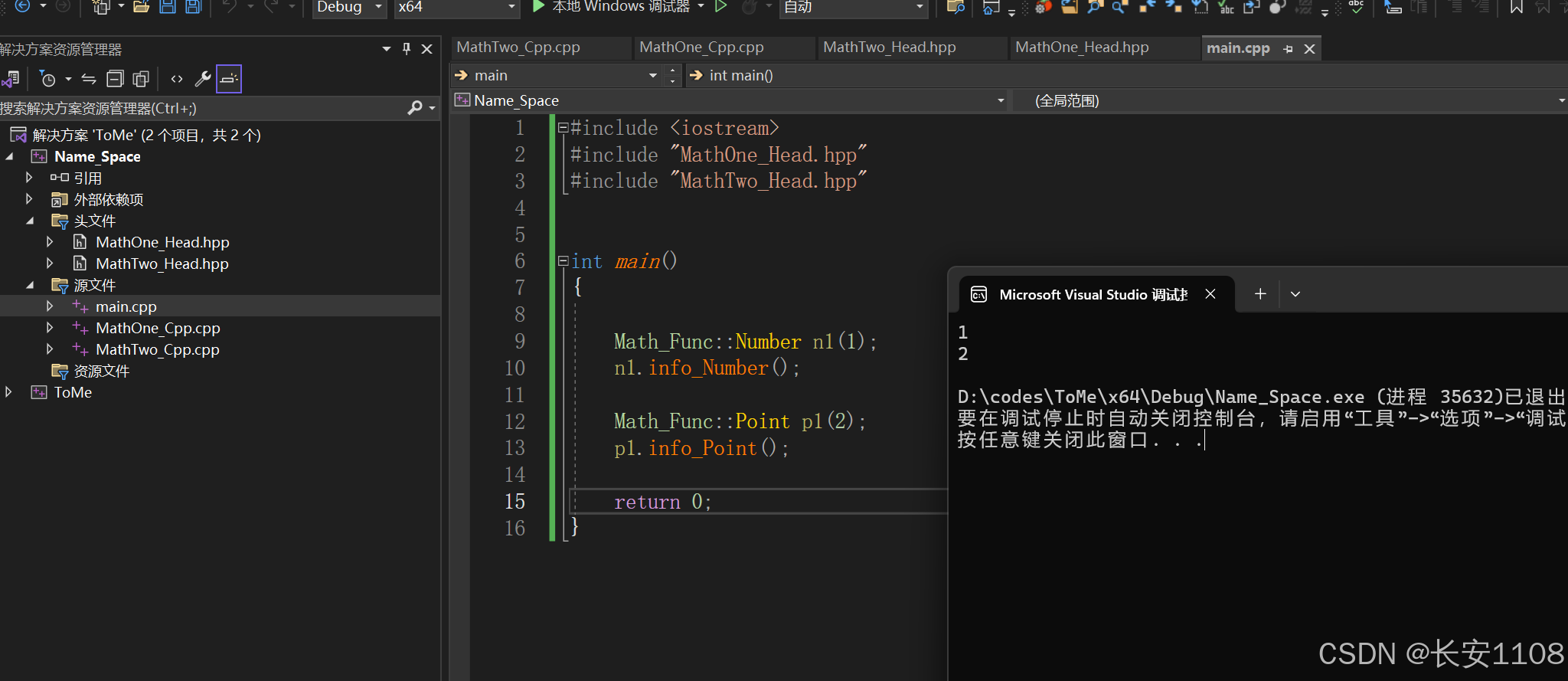
额外注意:命名空间多文件声明函数
如果连声明+定义一起放到hpp命名空间内,这是不允许的,哪怕你是hpp文件
会报错:

此时就需要严格遵循“头文件中声明”、“cpp文件中实现定义”:
使用命名空间调用add函数即可
Default Global Namespace
简介

作用
默认情况下,所有的声明只要不在自定义的命名空间内,就会在默认全局命名空间
代码中使用“空::”来指示
代码
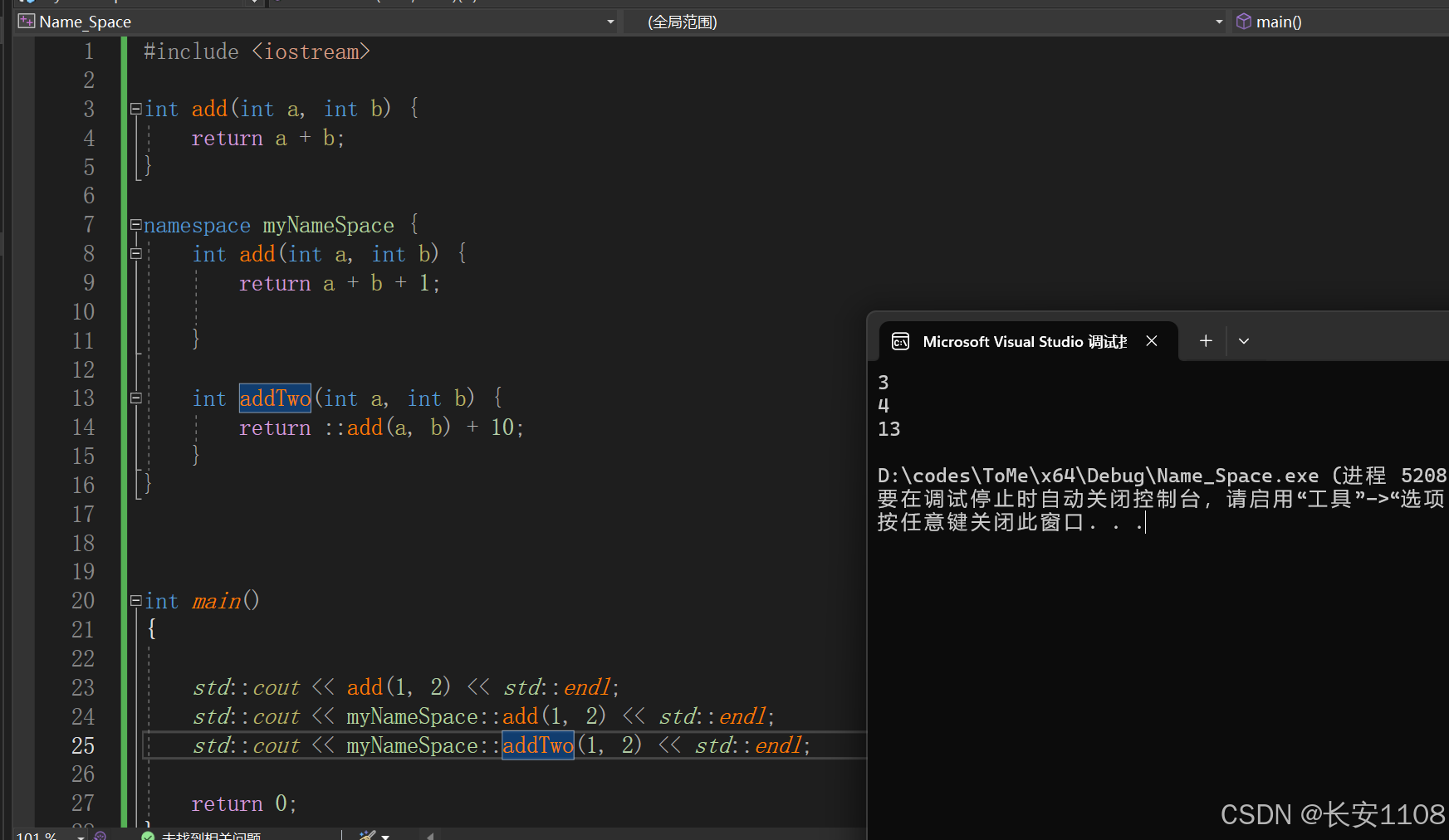
在自定义的命名空间中,使用“空::”来指示全局默认命名空间中的声明
using的用法
引入命名空间
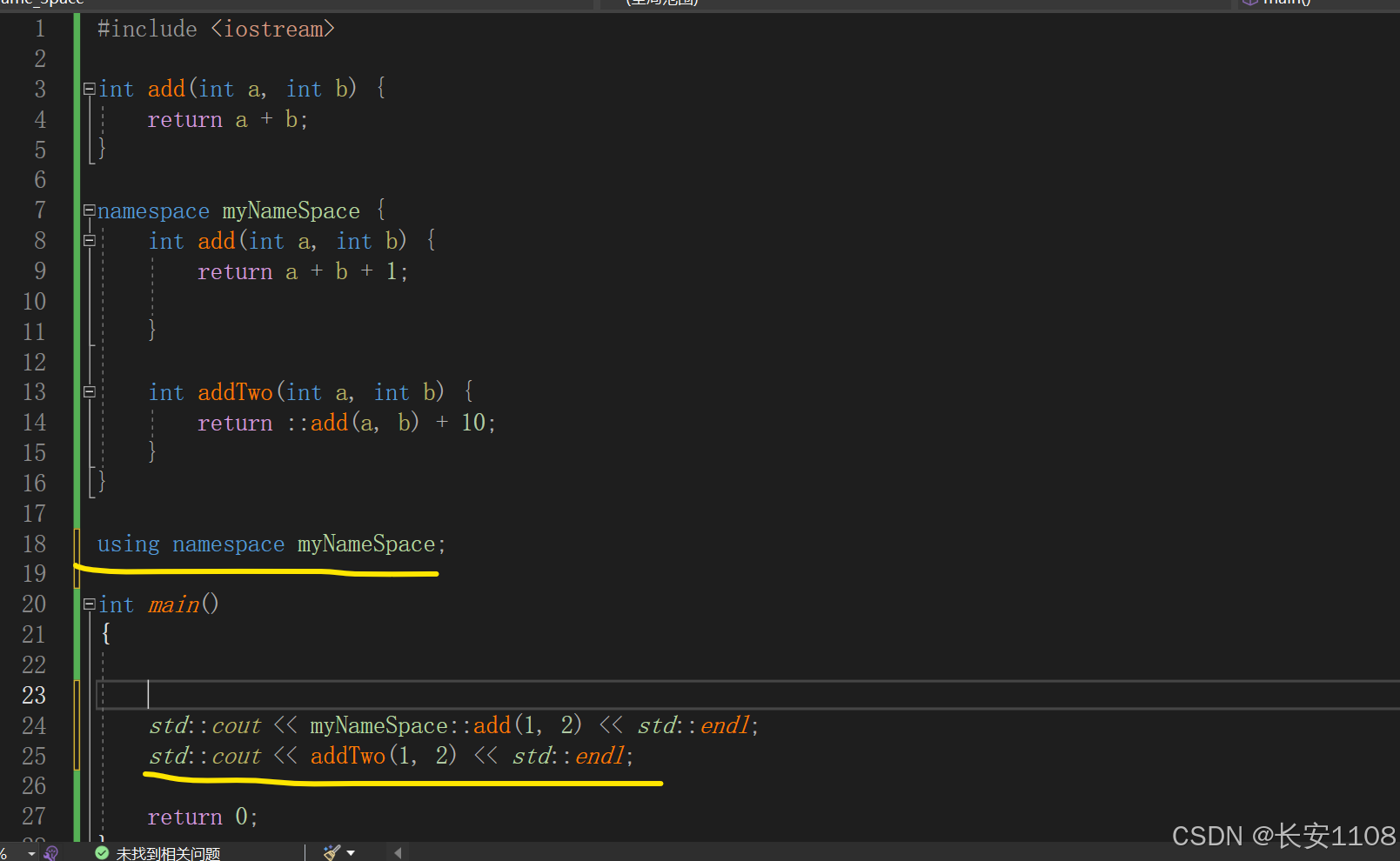
就是我们常使用的using namespace
但是引入后很有可能产生冲突,如上图,myNameSpace中的add与全局下的add产生冲突,这时,我们只能再补上我们想要使用的命名空间
引入某个类名、变量名、函数
1、引入某个命名空间的函数
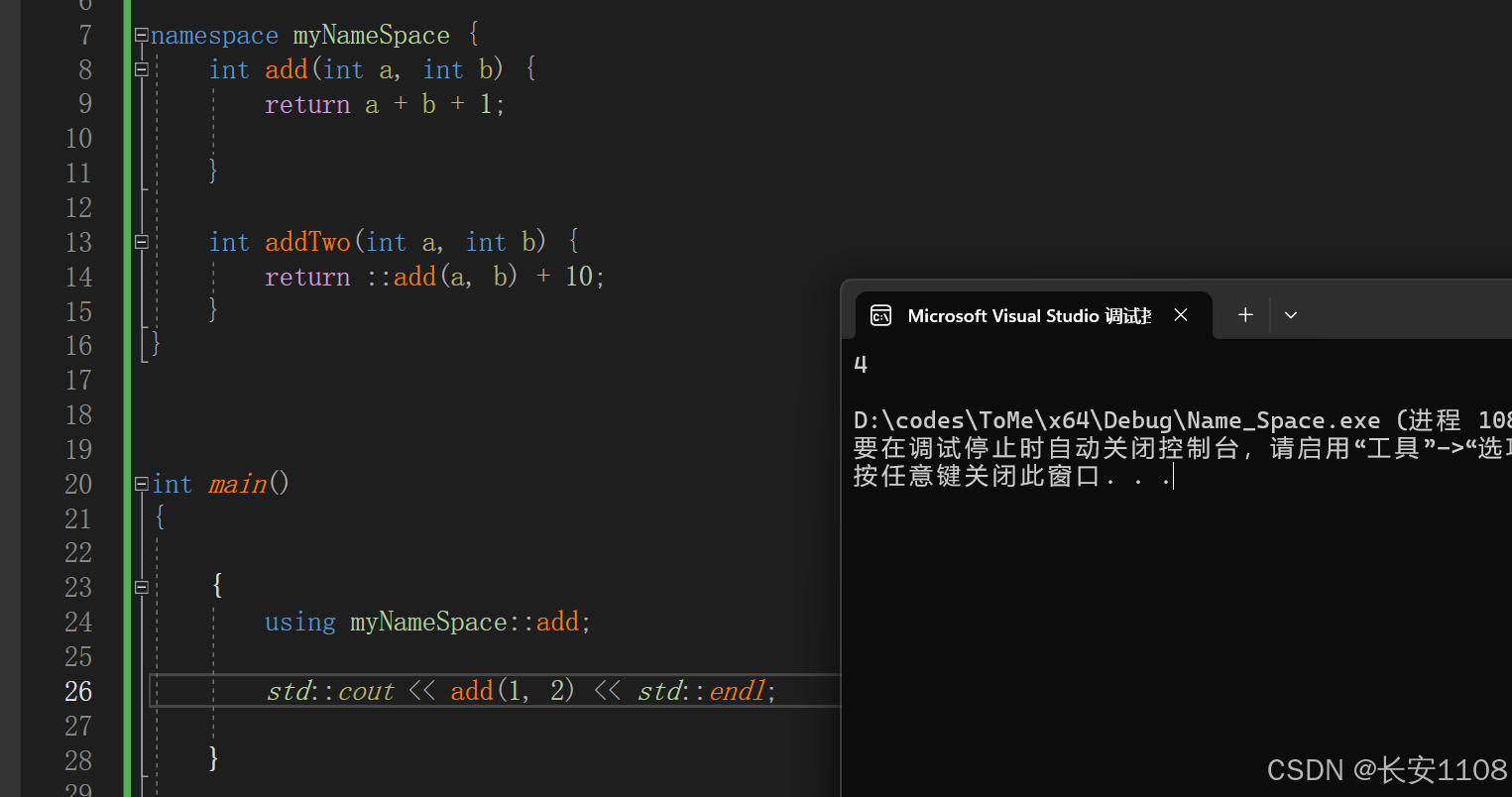
2、引入某个命名空间的类名
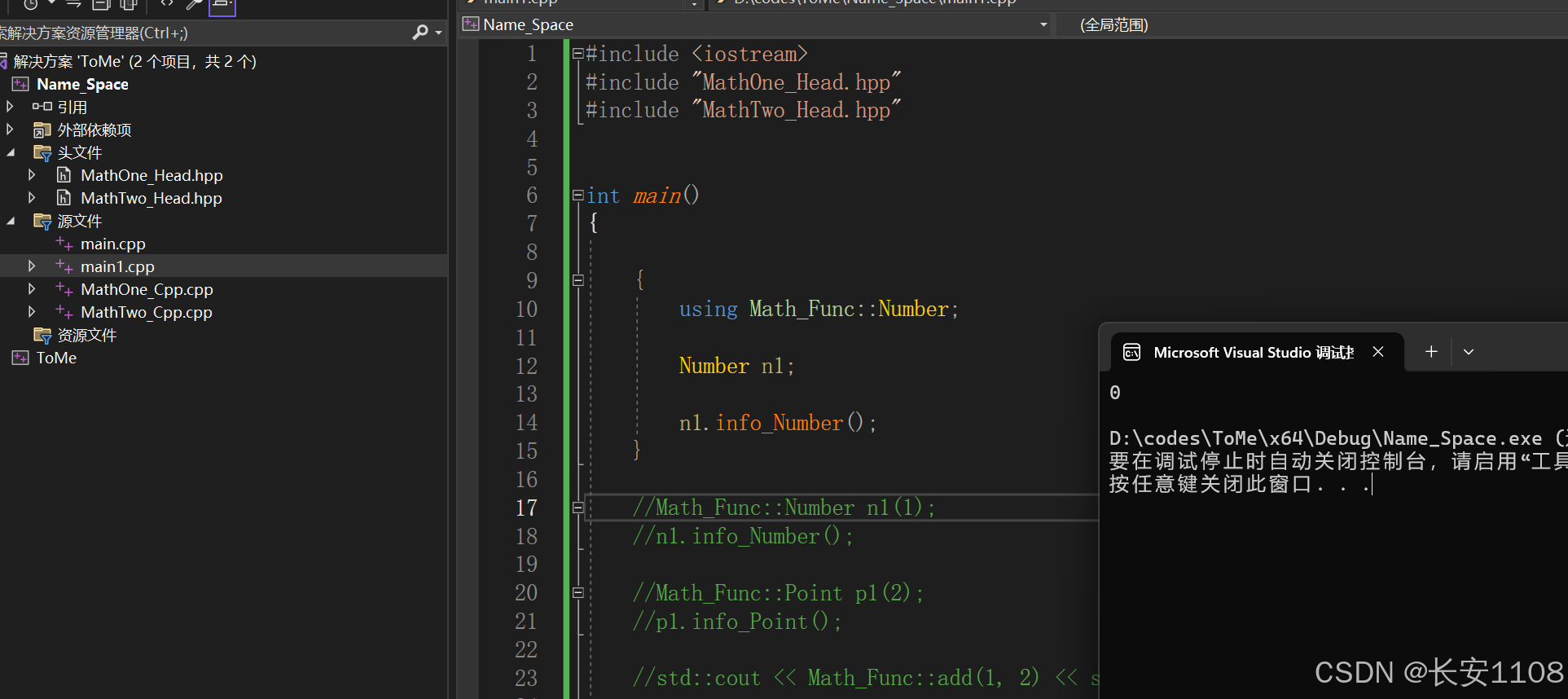
可以看到,一旦这样引入,后续的所有类名、变量名、函数,在使用时如果没有命名空间限定,则是引入的这个
如果此时想调用别的命名空间的同名函数,则加上命名空间即可: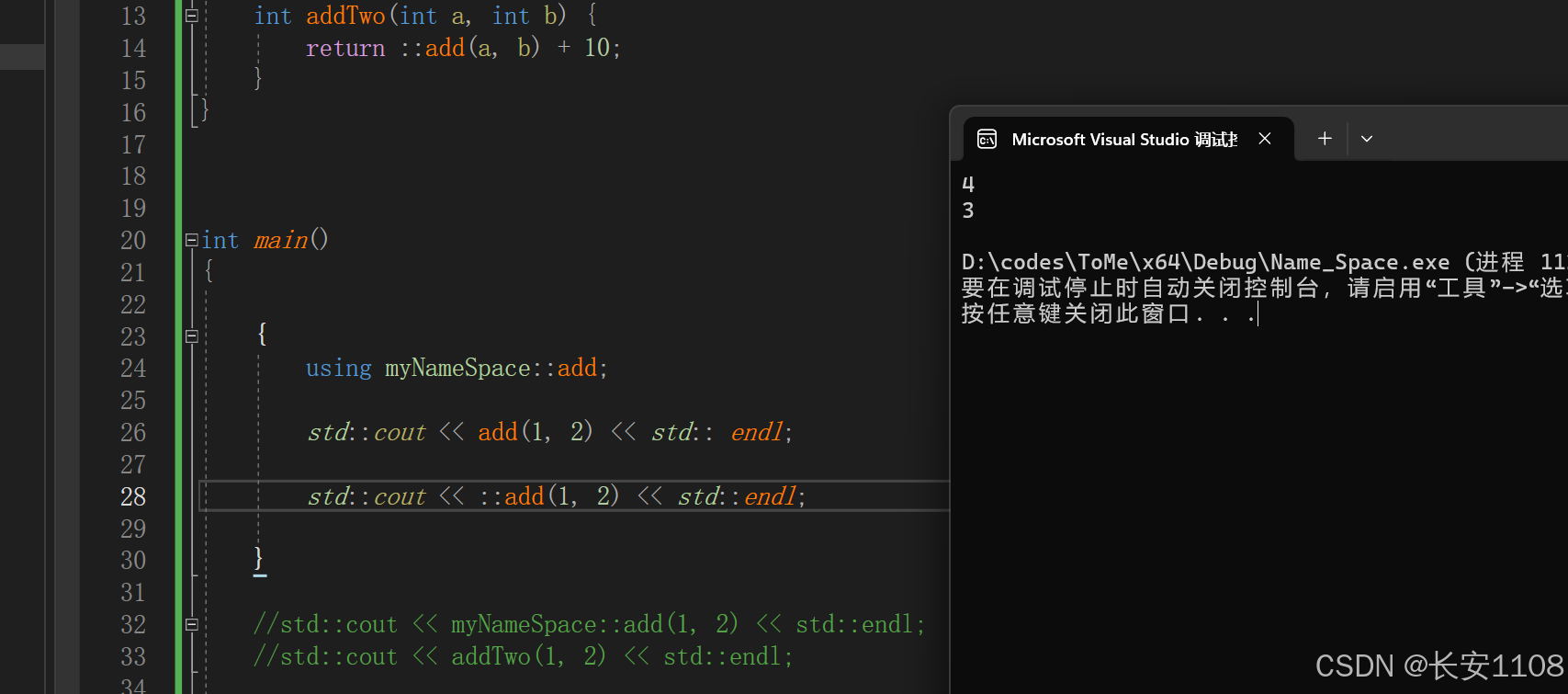
命名空间嵌套与别名
嵌套
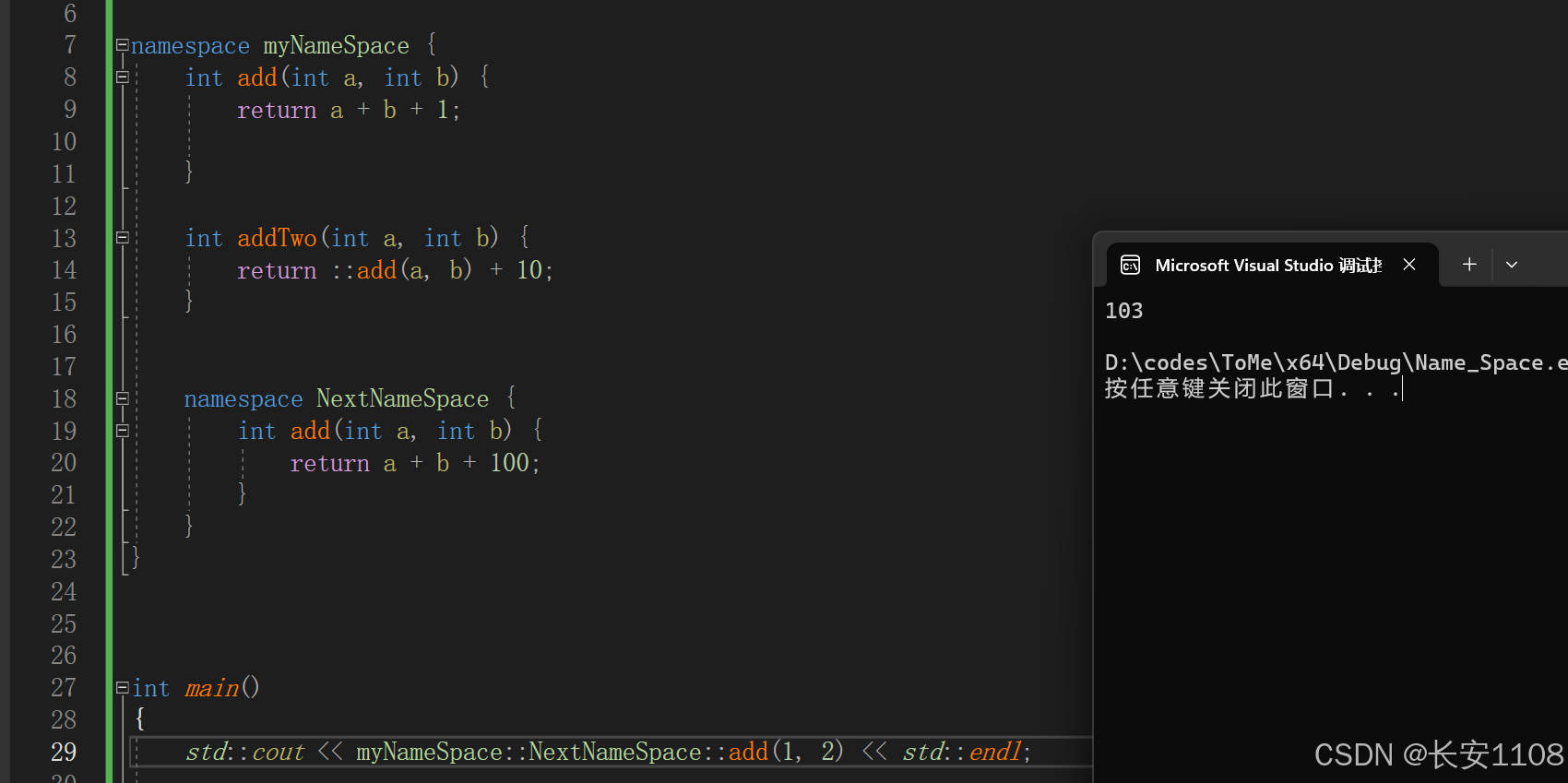
别名

智能指针
简介

智能指针概述



总结:智能指针主要是解决开辟堆区内存时常出现的内存泄漏问题
独占指针
简介以及特点

1、任何时刻,他所指的内存,只能由他来管理,其他智能指针不能同时指向
2、当他超出自己的作用域时,会将内存自动释放
3、该指针不能copy,只能Move
创建方法

使用已有指针创建
首先创建一个Cat类:
1、
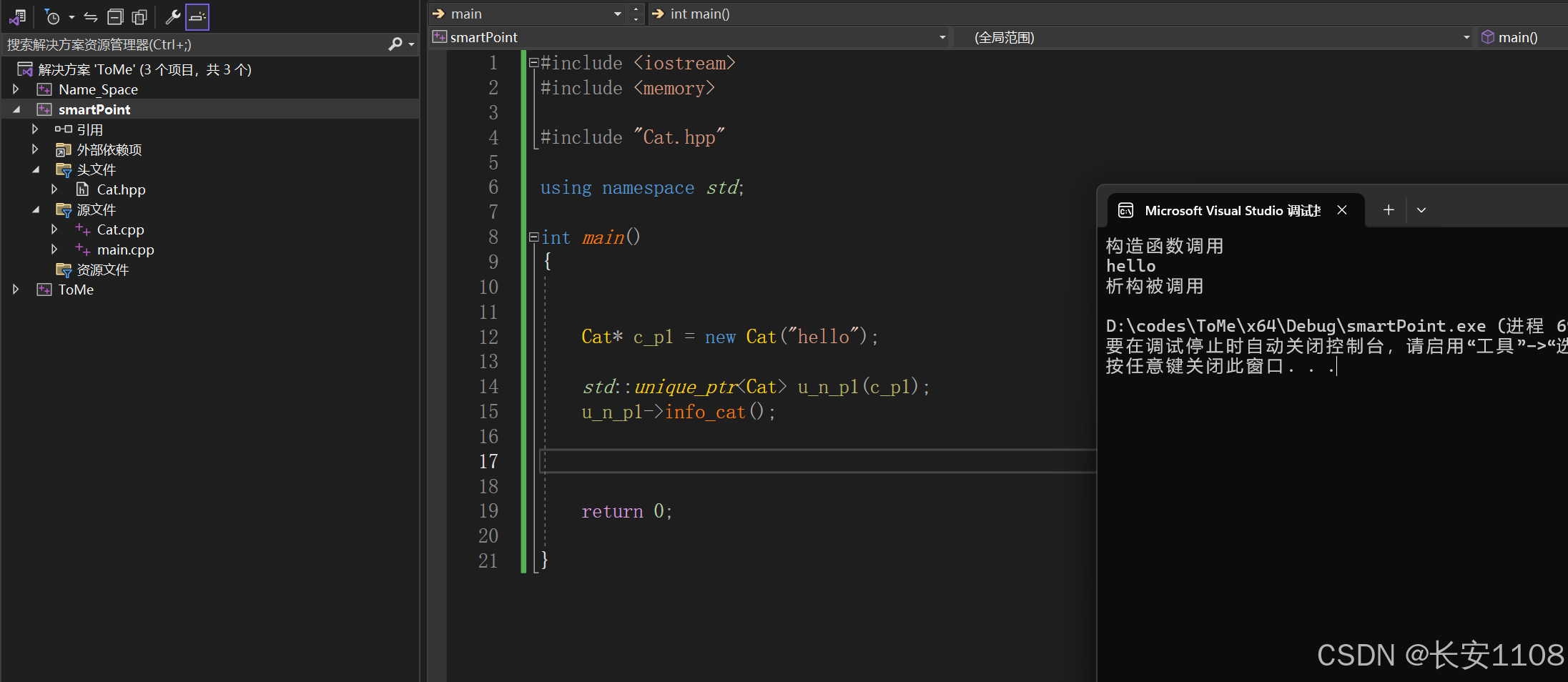
我们首先用一个自己的指针接收一个堆区内存
之后,使用这个指针来构造独占指针
可以看到,独占指针可以调用Cat的方法,并且最后退出main函数作用域后,自动析构Cat对象,释放堆区数据
2、
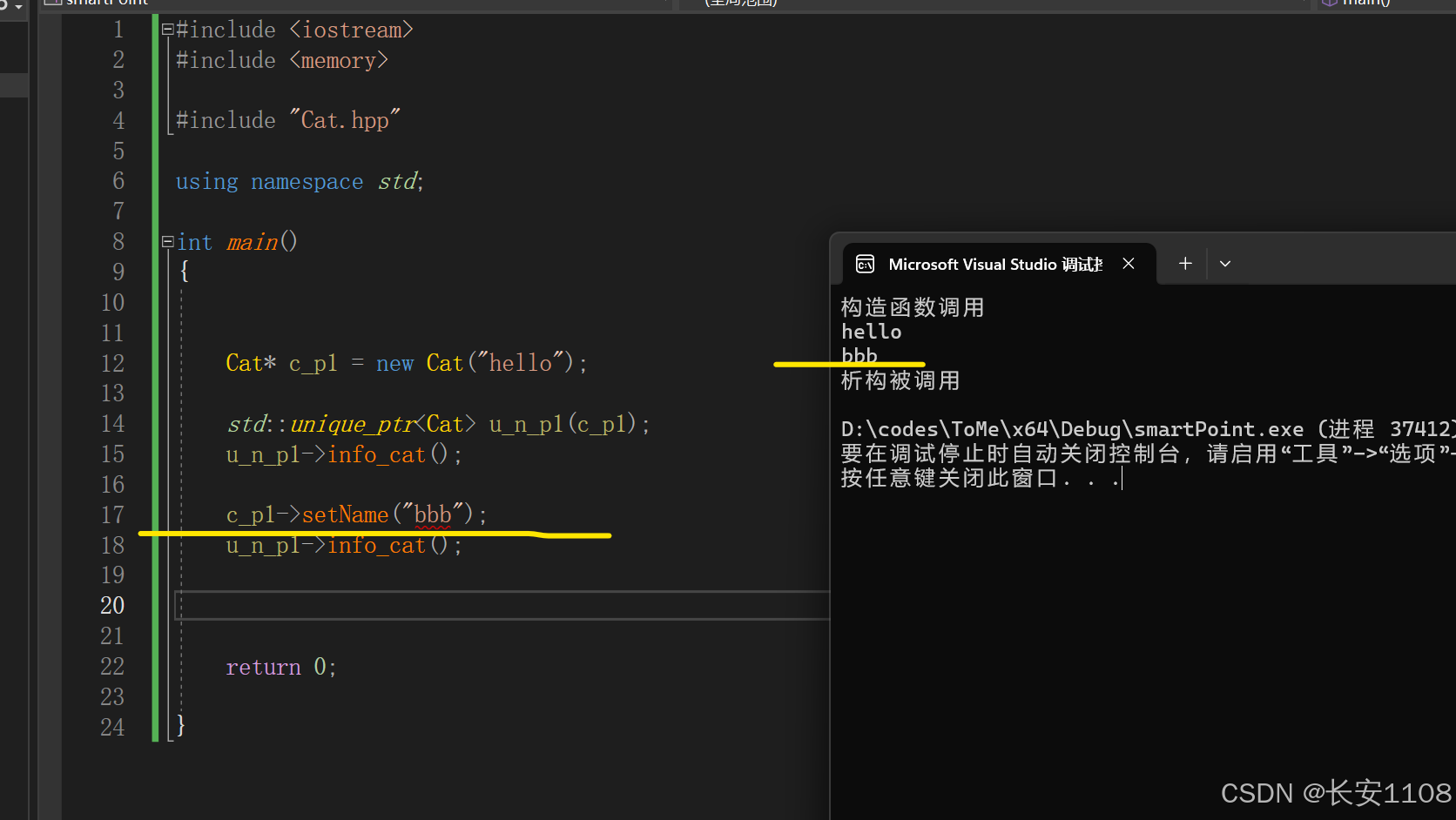
然而,此时那个原始指针仍然指向那块内存,这是因为独占指针只是限制其他的智能指针不能与其共享同一块内存,而不限制原始指针
所以,此时原始指针还是可以操作独占指针所指向的区域的
3、建议原始指针将地址给独占指针后,自己就置空(但是不能delete)
使用new创建
代码:

**小tips:**智能指针必须手动敲出箭头,不然所提示的不是Cat类的成员函数

使用make_unique
类:
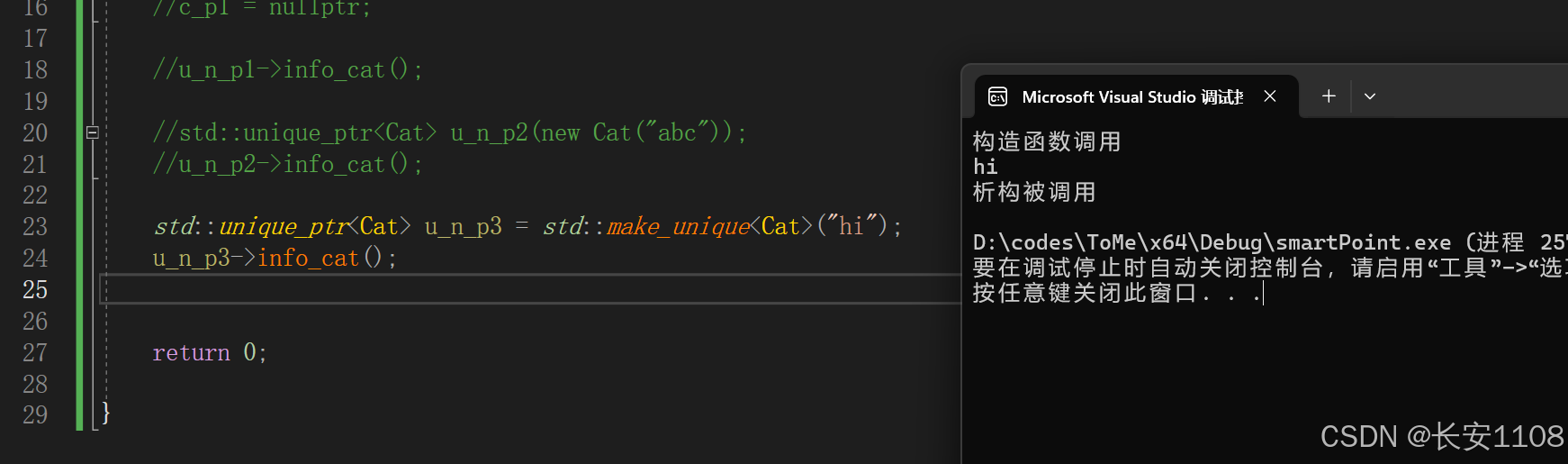
使用make_unique时,也需要填入变量类型,且后面的括号是用来构造Cat对象的
如果想使用无参构造,则也要加括号,使用空括号即可(必须加空括号)
基本数据类型:
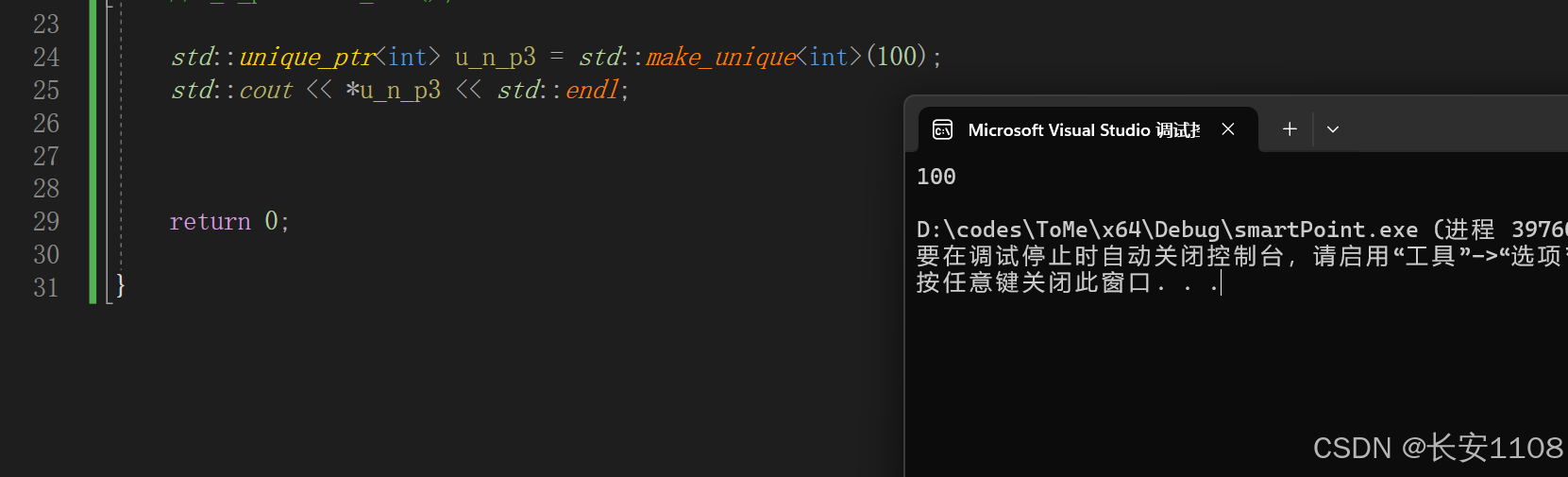
而基本数据类型如果不进行初始化,也必须要加上空括号
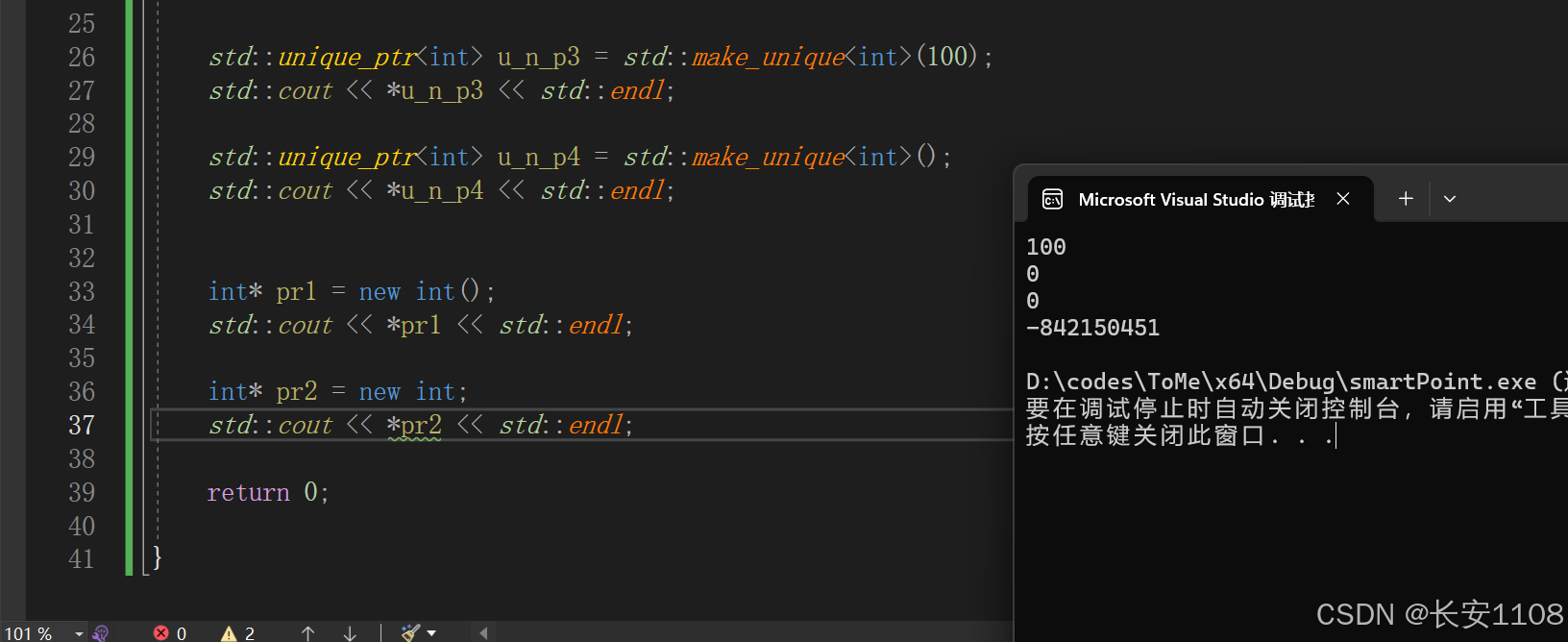
可以看到,智能指针必须要加括号,且会自动初始化为0,这一点与第三块的new是一样的特点
但是new可以不带空括号,那么就会不进行初始化,也不会自动初始化为0,那么解引用出来就是未定义的值
但是对于智能指针来说:不管是基本数据类型还是自定义数据类型,都要加空括号
补充:
对于new来说:
如果是new 一个类,是无参的话,最好也要加上空括号
如果是new一个基本数据类型,如果不进行初始化,那么无需加空括号(加空括号会自动初始化为0)
对于普通栈对象构造:
如果是类,无参的话,可以不加空括号
基本数据类型,不需要加空括号
总结:
对于new和智能指针来说,最好是,不管有参无参,是否初始化,都带上括号,无参或者不进行初始化就使用空括号
get()方法

前面提到,使用智能指针时,要操作内存上的数据,必须手动敲出"->"
这是因为如果使用"点"的话,调用的将会是智能指针自己带有的方法(即他自己的API),比如上图的get()方法
get()方法会返回指针所指向的内存的地址
其他特性以及函数调用
简介

值传递
1、使用常规思路进行值传递
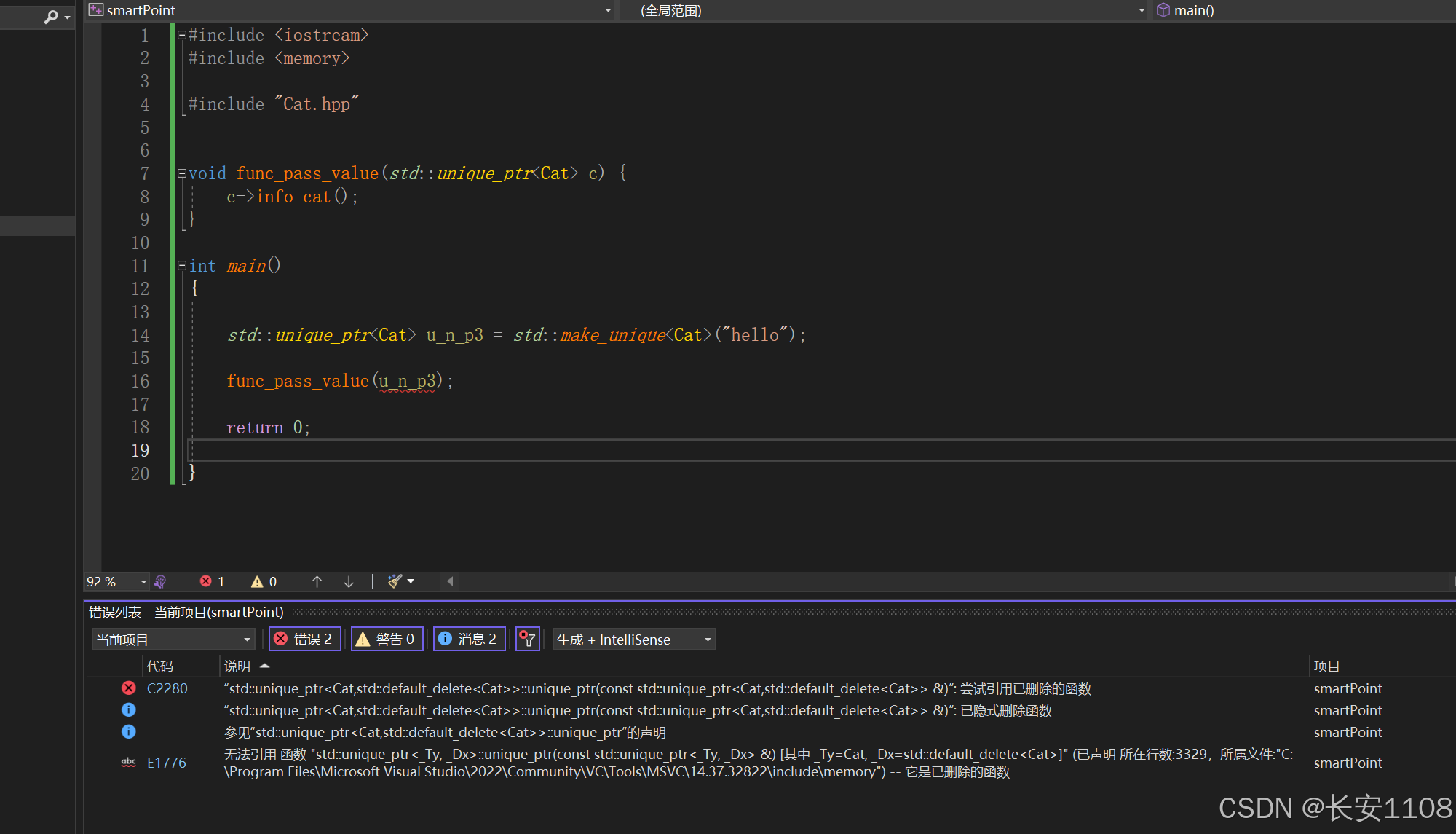
可以看到,会进行如上报错
实际上,上面我们也说到过,独占指针不能被拷贝,只能被Move,这里的常规的值传递就是拷贝,所以是错误的
正解:
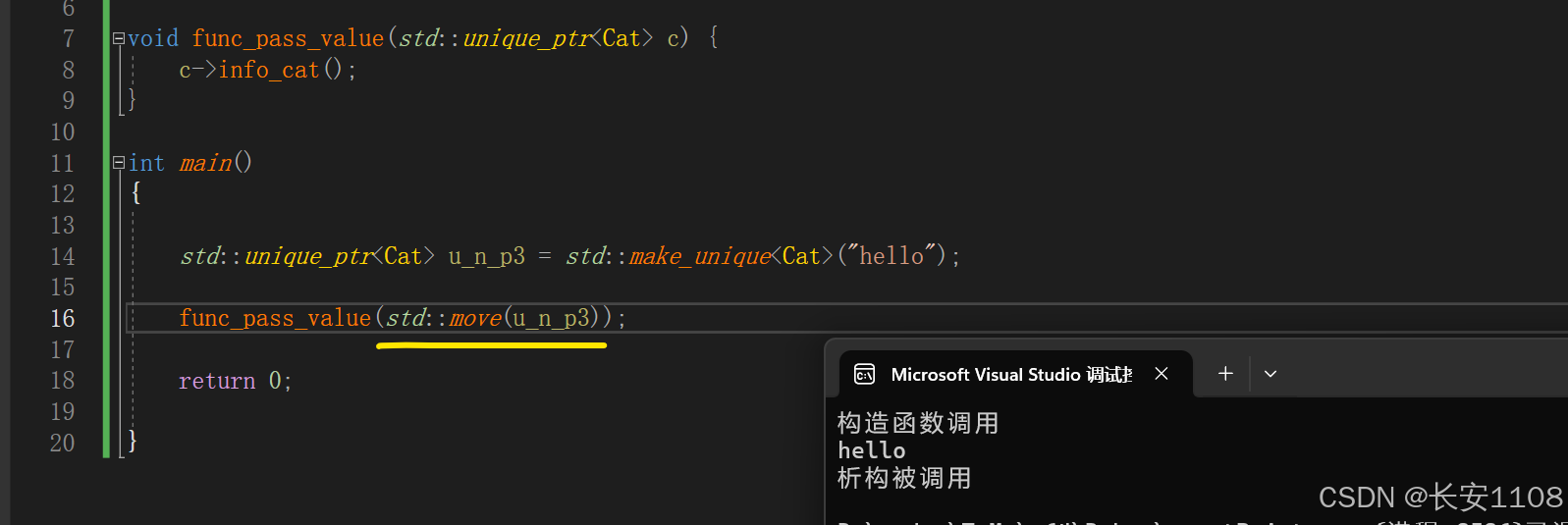
我们知道,智能指针同时有两个身份:
一个是指向一块内存的指针变量(使用->去调用内存数据函数)
另一个是智能指针对象,是一个对象实例,(使用"点"去调用智能指针自己的API)
这里使用u_n_p3的对象身份,将其传入move函数中,将左值转为右值引用之后,允许发送移动语义,将有值引用送到我们的函数中,发生移动语义,调用默认的移动构造或者移动赋值
补充:
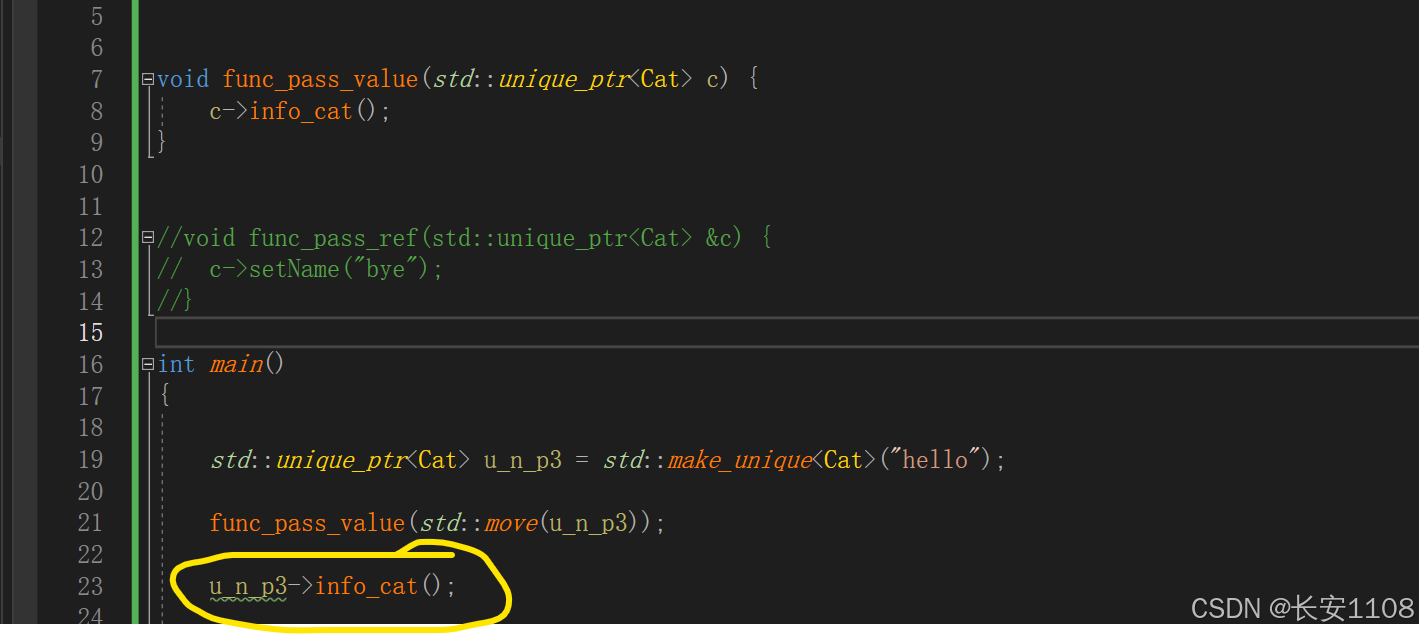
在使用完move进行完函数传递之后,就不能再用外面这个智能指针了,他的资源已经都被转移到函数里面那个智能指针了,控制权转让给了函数里面的那个智能指针
如下图:
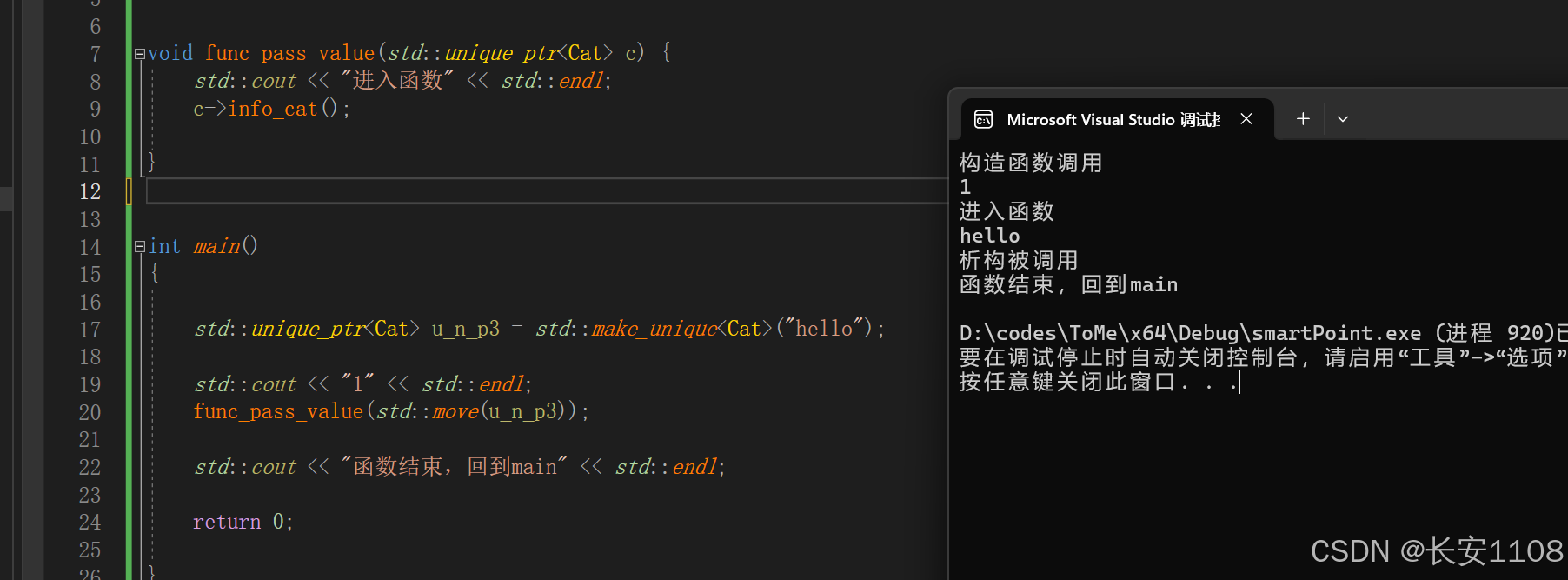
当函数作用域结束时,函数内的智能指针所指向的内存自动释放,析构被调用
引用传递
常规引用
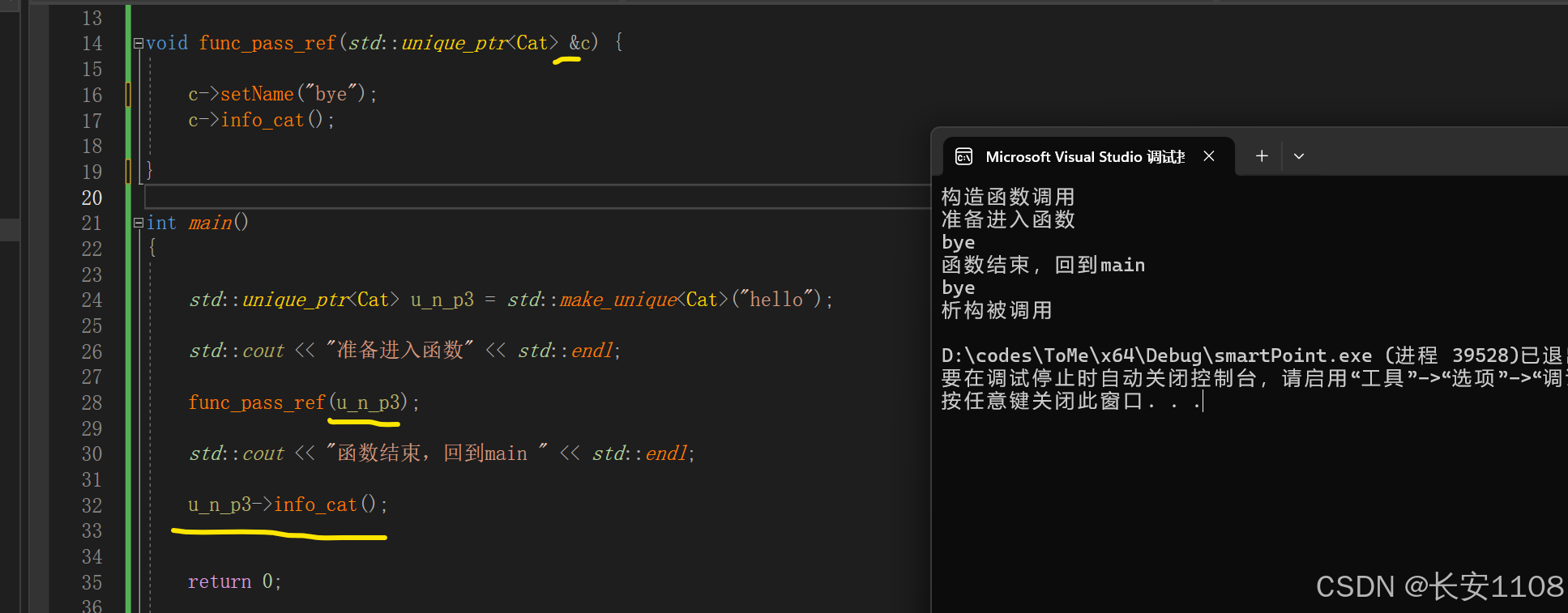
可以看到,引用与值传递的几点不同:
1、引用传递时,无需进行资源转移,所以可直接传入智能指针
2、函数结束后,main中的智能指针还可以继续使用(毕竟全程没有资源转移,都是在操作刚开始的那个智能指针)
ps:此时只有main函数中的u_n_p3走出作用域,才会释放内存
补充:const
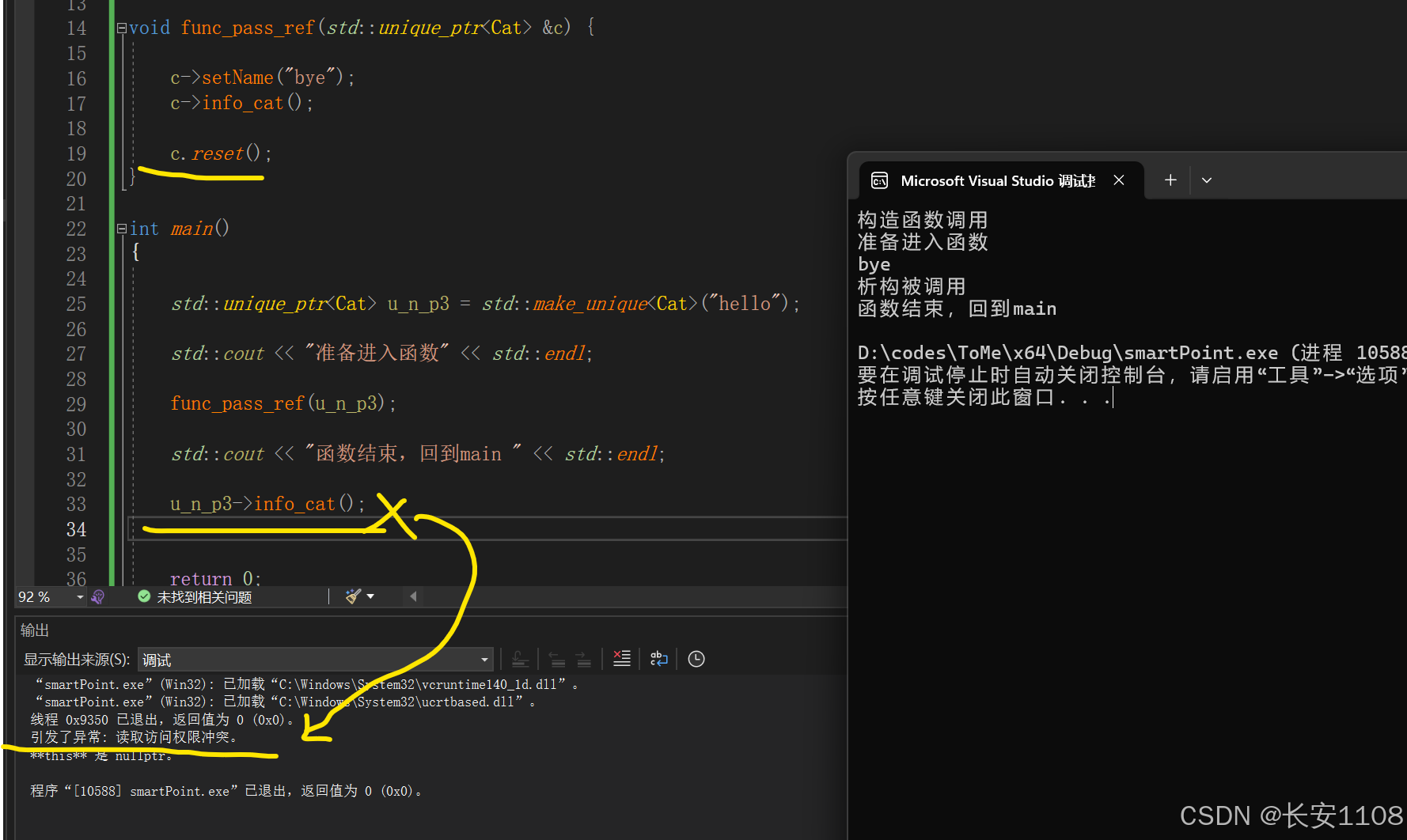
如果在上面的基础上,加上一个"点"调用的reset,这个方法是重置智能指针的指向,所以函数结束之后,main中智能指针的指向被重置,就无法调用内存数据中的函成员函数了,会引发异常
此时,为了避免误调用reset,我们就可以使用const:
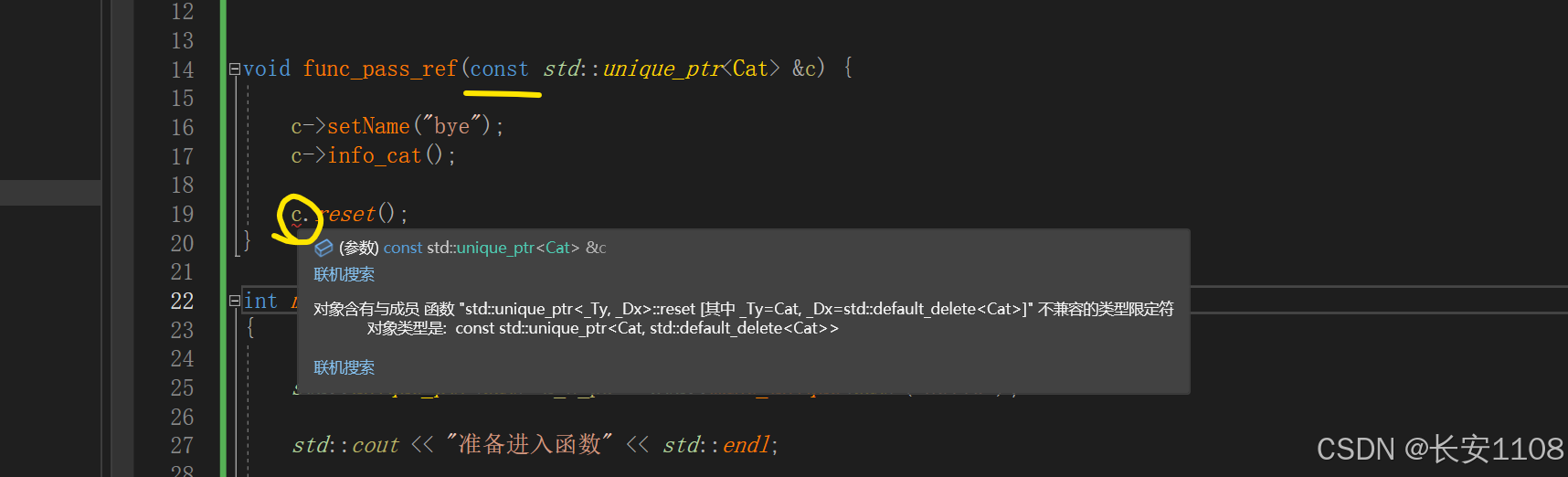
可以看到,加上const限定之后,再想调用reset是会报错的
这是因为const限定了智能指针的指向不能改变(注意这一点与我们平时的const是反着的,const在前,限制了智能指针的顶层指针,其指向不能改变)。所以,无法使用reset重置其指向
返回智能指针
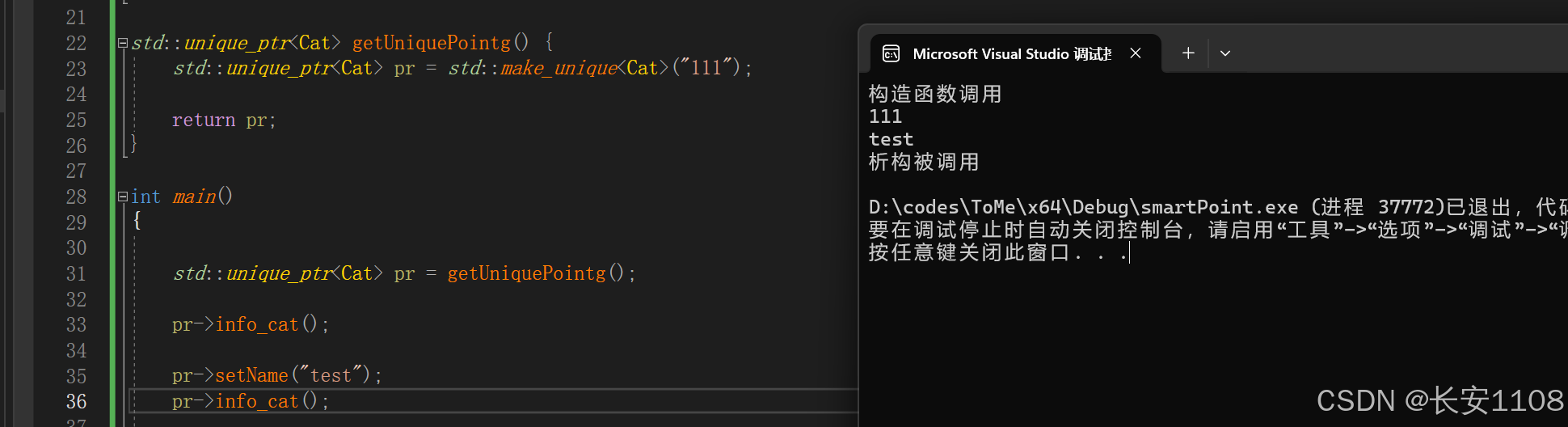
可以直接返回指针变量,并可以在main中使用
所以从这一点可以看出来,独占指针的引用、独占指针的返回,与new一个堆区数据时使用方法是一样的,
可以直接利用形参指针修改值,修改指针指向,并且同步回调用处
可以直接返回指针变量,相当于内存地址号的传递
共享指针
简介以及特点


创建方式以及特性
基本数据类型
定义、查看数据、查看占用数量
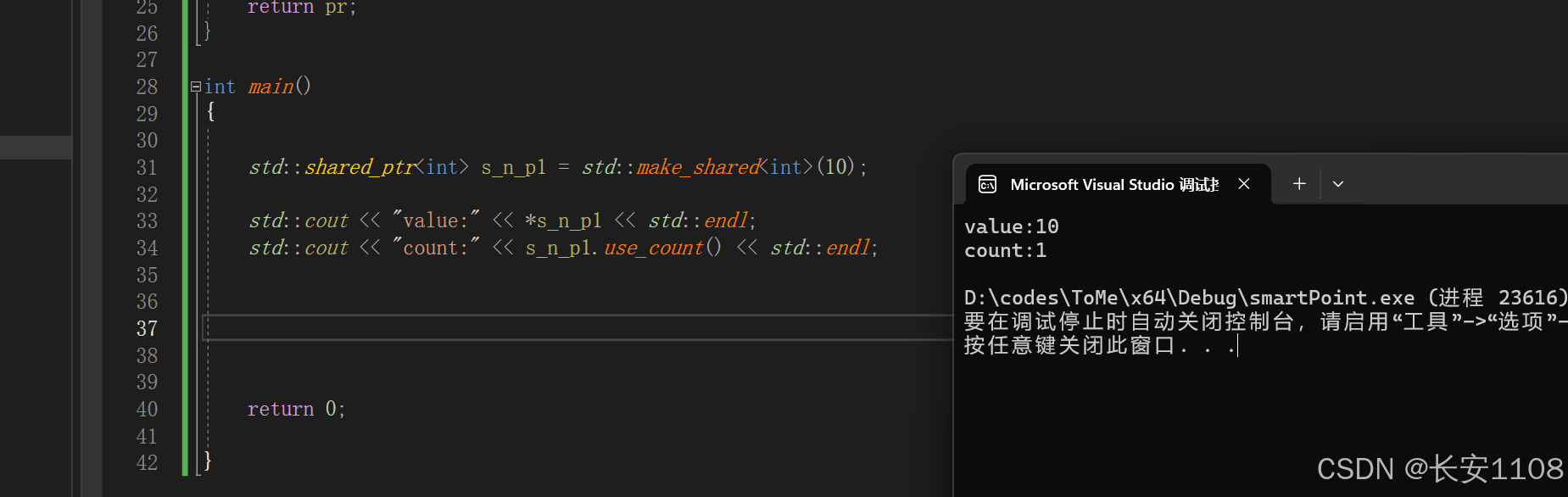
定义就是与上面的unique一样
这里查看基本数据类型的数据,直接解引用即可,因为是基本数据类型
这里可以查看当前共享指针所指向的内存被多少个共享指针共享
共享
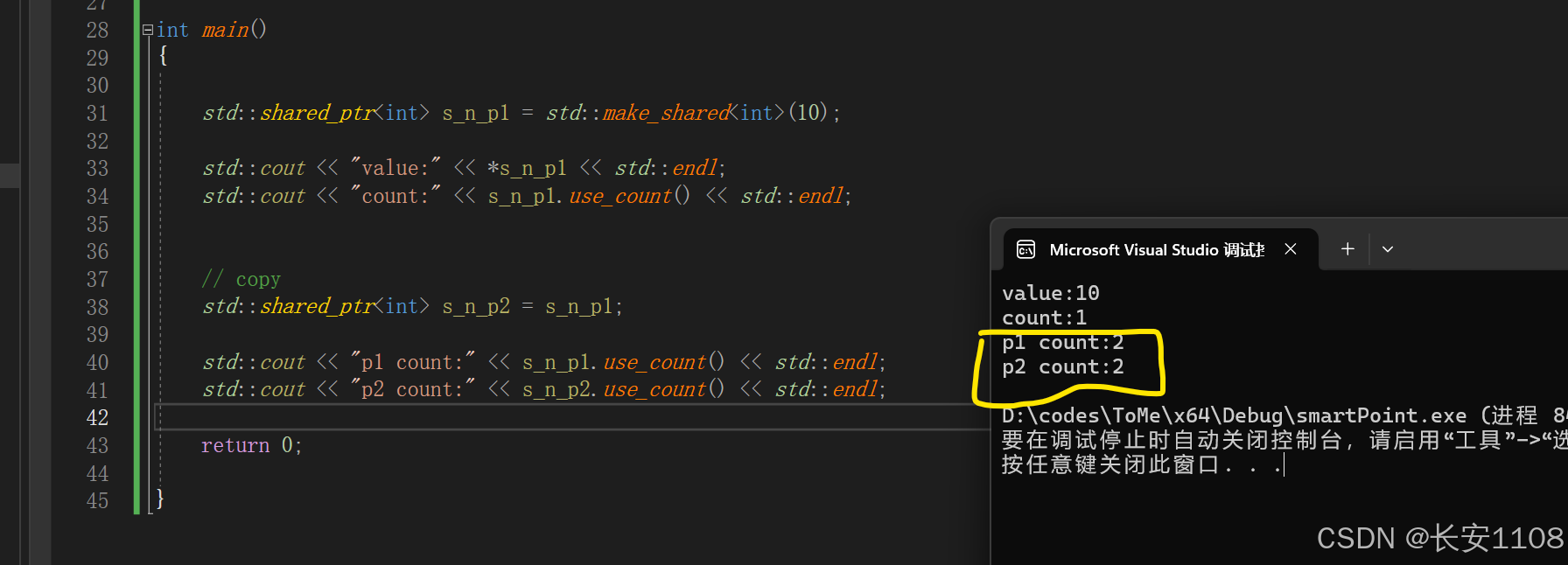
共享指针是可以进行copy的,所以可以共享内存
如上图,p1将内存共享给p2,同时,p1,p2的count都会被更新
同步修改
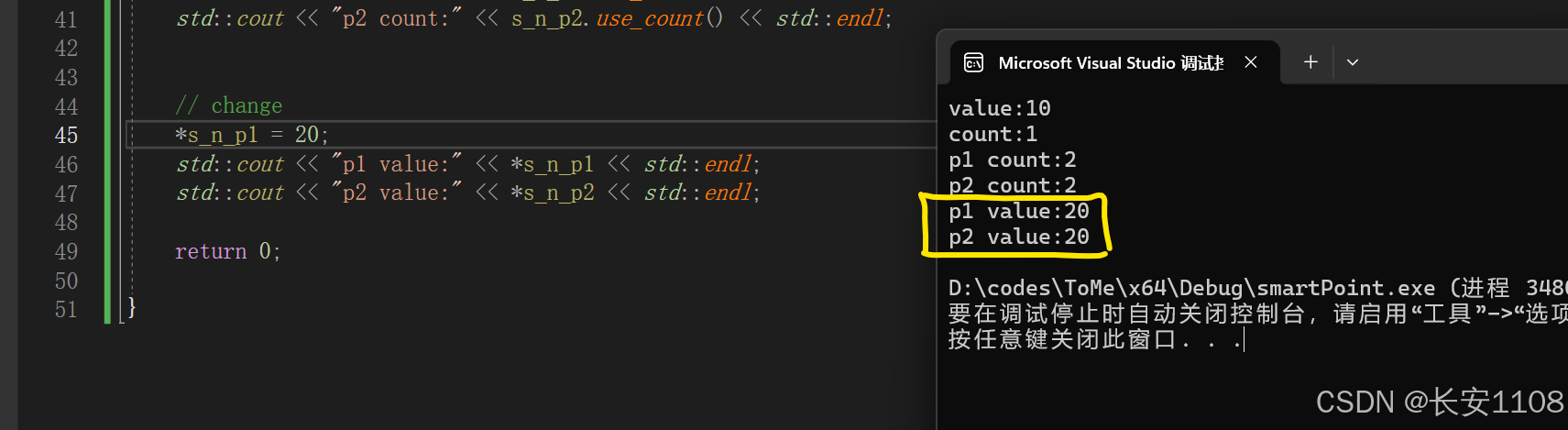
因为是共享内存,使用同一块内存,所以会同步修改
置空
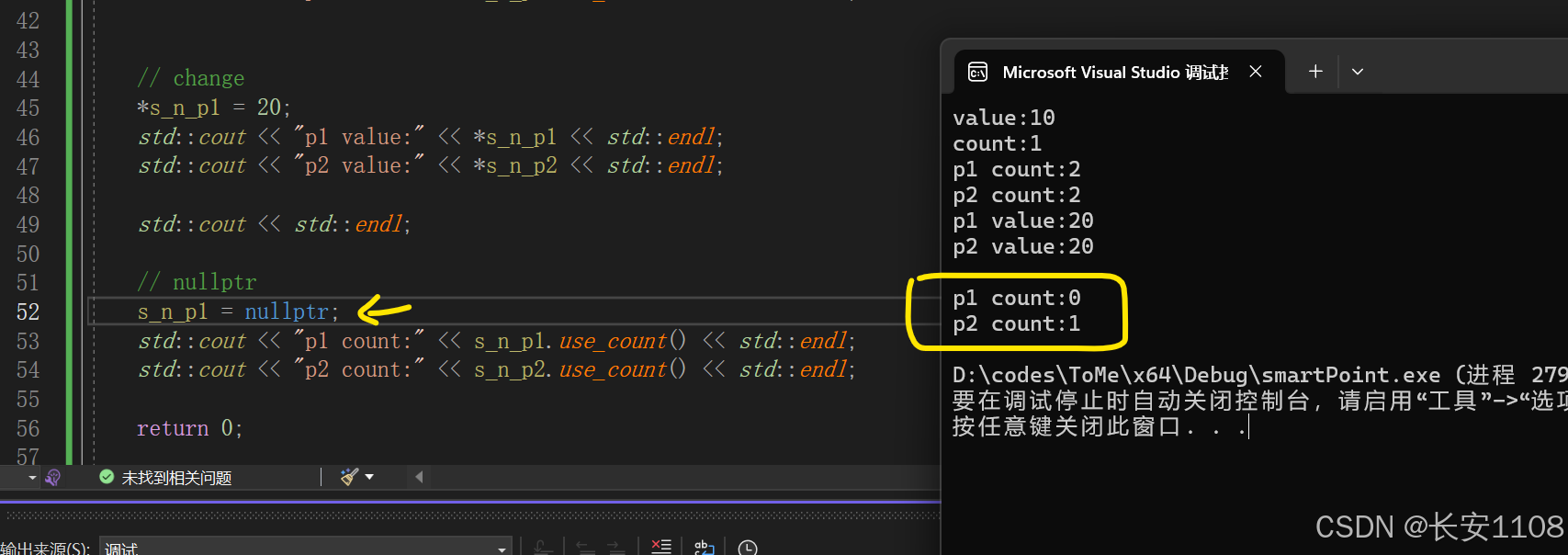
当其中一个置空,表示该共享指针退出共享,所以,他的count会变成0
而另一个没有退出的,他的count会因为p1的退出,而变成1,因为只有他自己了
**补充:**或者可以使用reset来置空:

自定义类类型
定义

就直接这么定义即可,与独占一样
共享
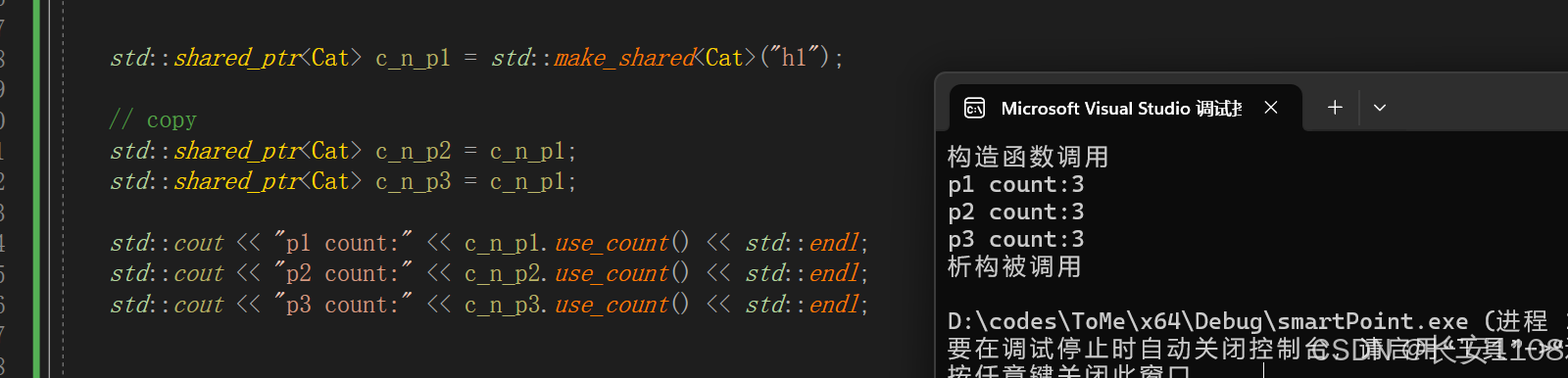
返回其指向的那块内存有几个共享指针共享
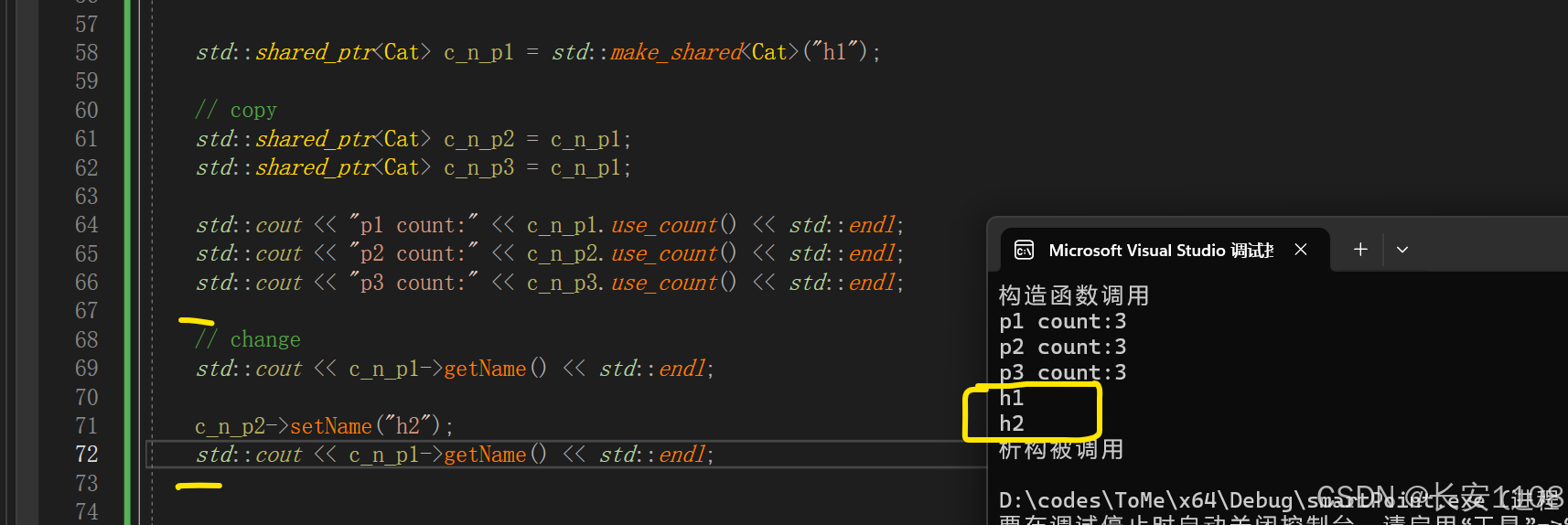
同步修改
置空
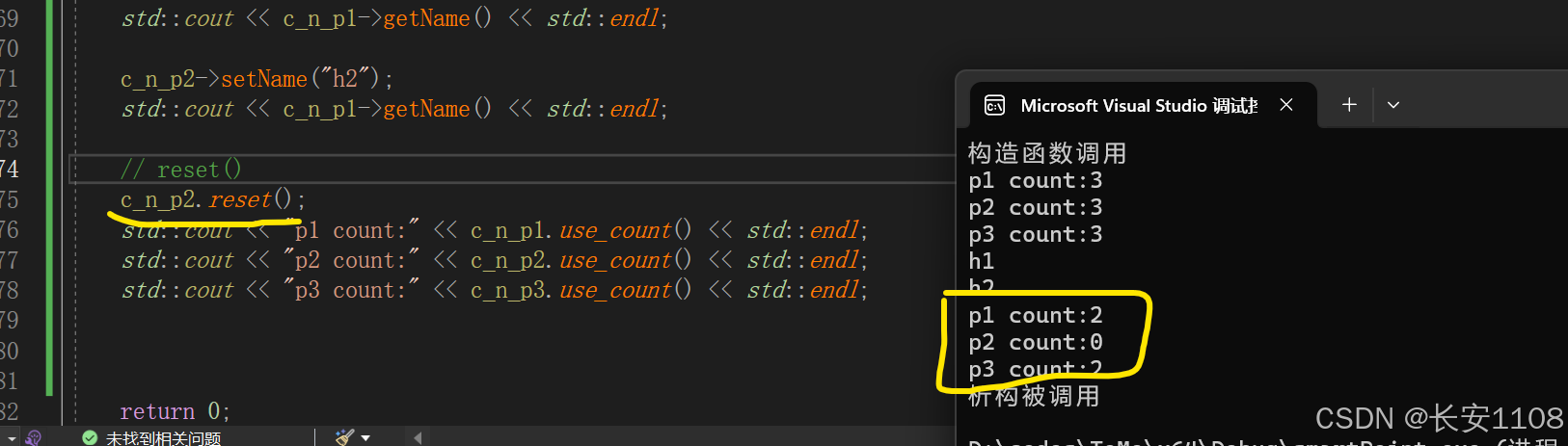
当我们使用reset,将指针置空时,可以看到,p2的所返回的其指向内存上的智能指针数量为0,因为他已经没内存了
而p1,p3都是2,因为p2退出了,只剩下他俩了
补充:
设为nullptr与调用reset是一个效果:
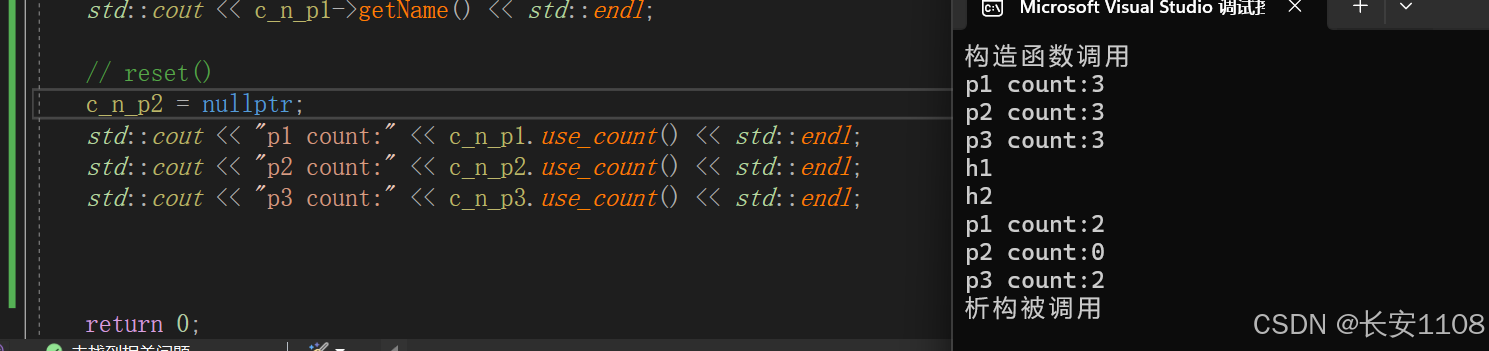
注意:当一块内存的最后一个共享指针超出作用域时,会将该内存释放
函数调用
简介

值传递
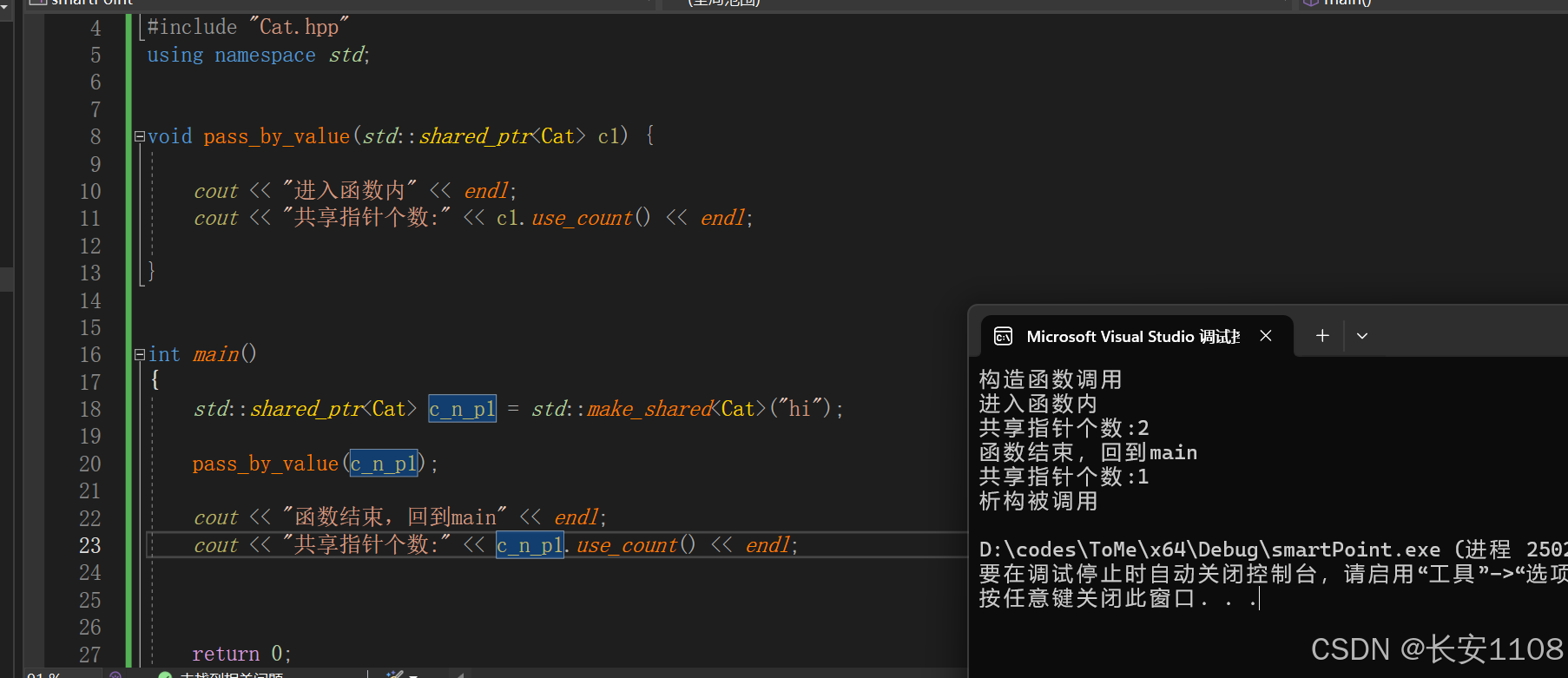
与独占指针不同的是,由于共享指针允许共享内存占用,也就允许cpoy,所以,可以进行正常的值拷贝,像正常指针一样,传入函数,且在函数内,函数形参也会指向内存,从而使得count变为2,函数结束后,形参置空,回到main中,count又变为1
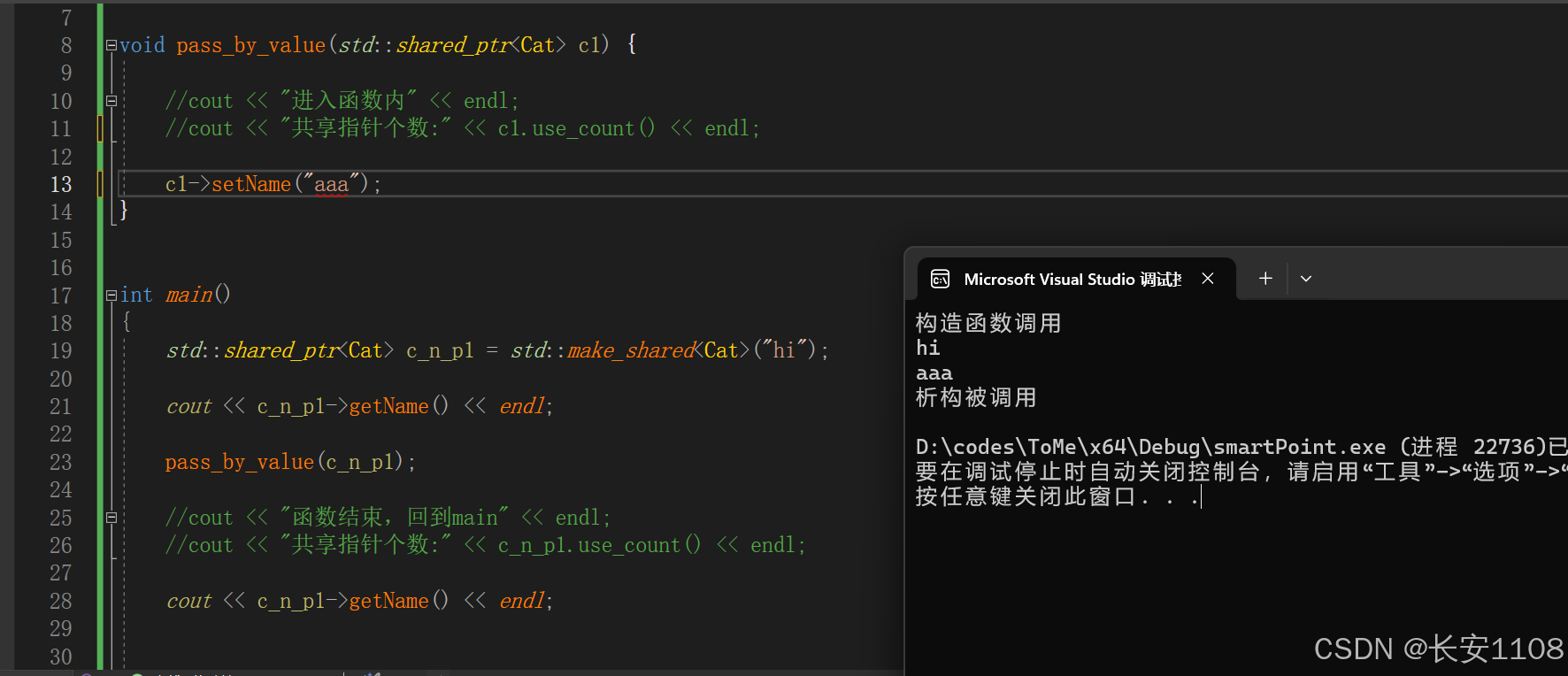
同时,使用形参的箭头函数,就可以对内存的数据进行修改,这也是普通指针的功能,所以,与普通指针的逻辑功能是一致的
引用传递
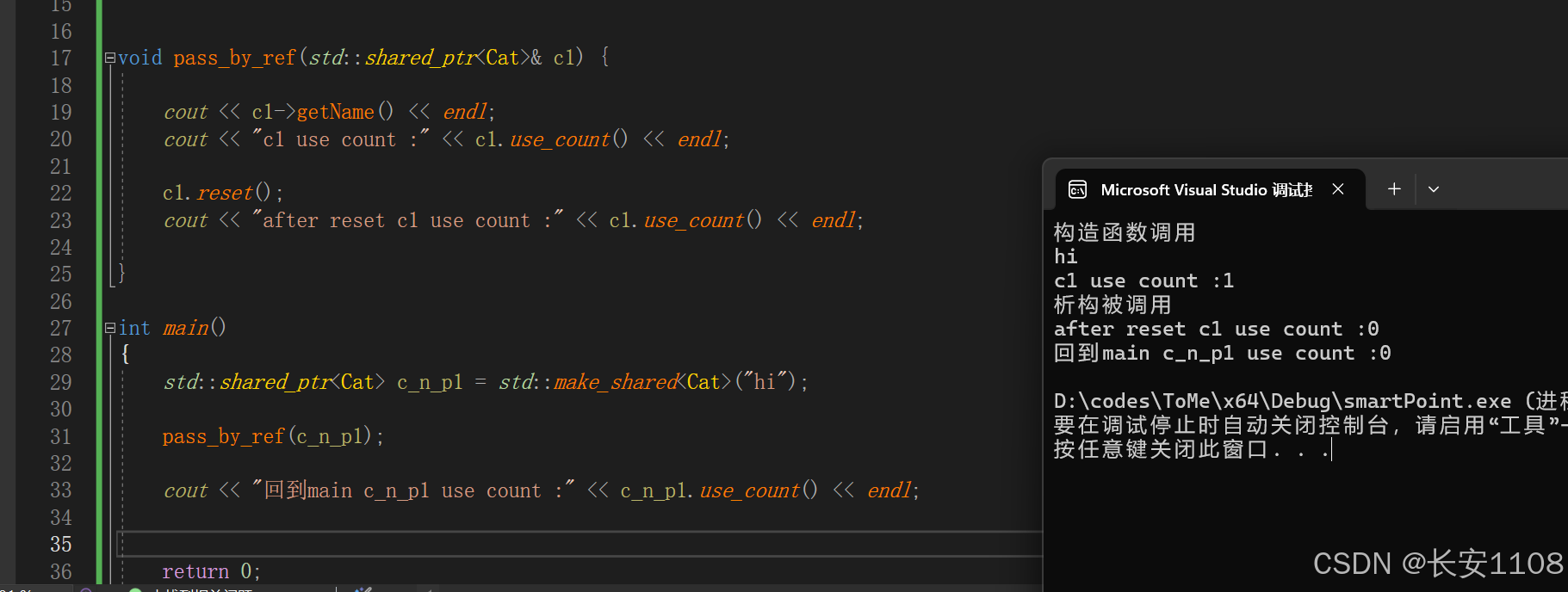
由于是引用传递,所以,函数形参指针就是传入的main函数的实参的别名,所以在函数内操作的本质上还是c_n_p1
由上图可以看到,c1置空之后,内存上的智能指针数为0(析构调用),回到main之后,其也是0,这就说明,引用指针,用的是同一个指针
且,引用指针不仅可以使用箭头函数改变其内存上数据的内容,同步给实参指针,还可以使用“点”函数,修改实参指针指向,这也与普通指针的特性相同
返回智能指针
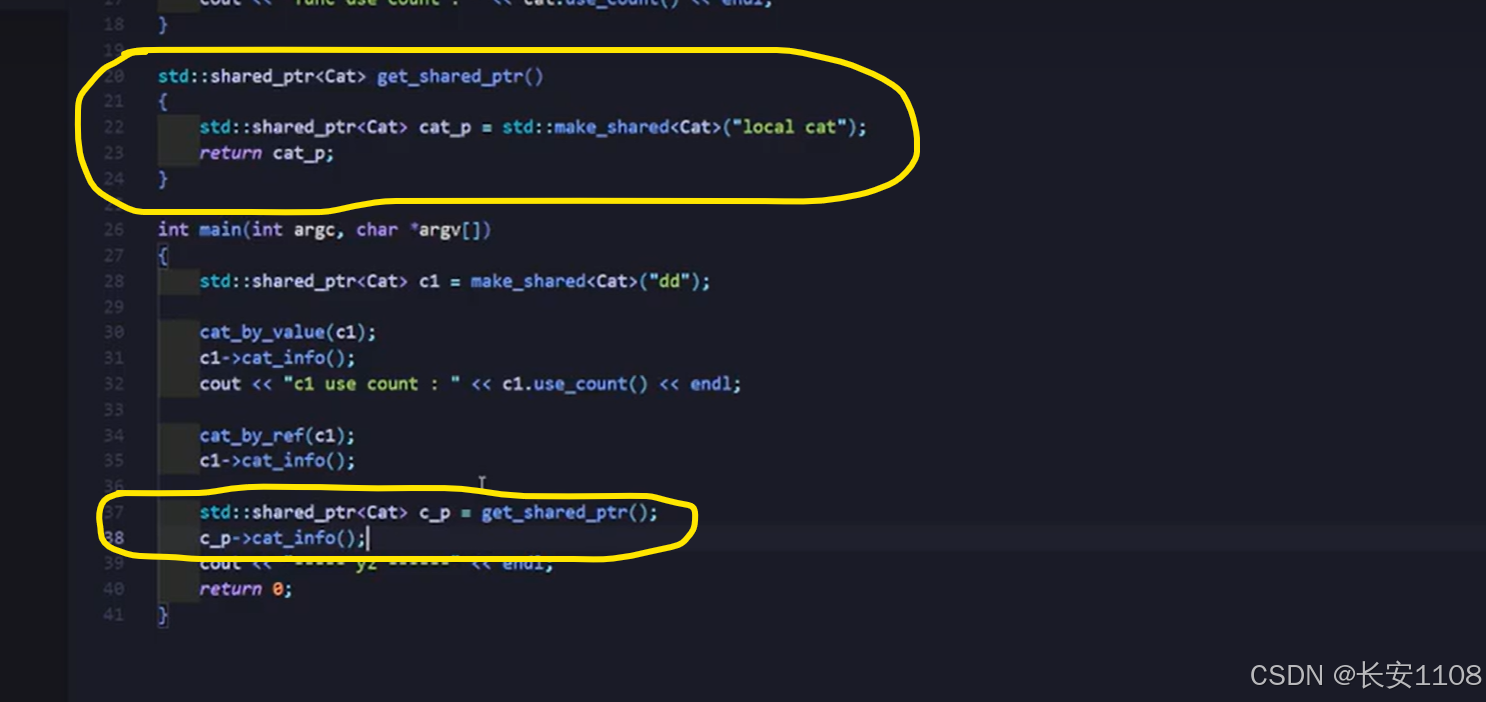
与独占指针相同,且与普通指针特性相同
总结
独占指针的引用传递、返回值都与普通指针特性相同
共享指针的值传递、引用传递、返回值都与普通指针特性相同
独占指针的值传递,由于其无法copy,所以只能使用移动语义进行资源转移
独占指针与共享指针相互转换
简介


代码
显示转换
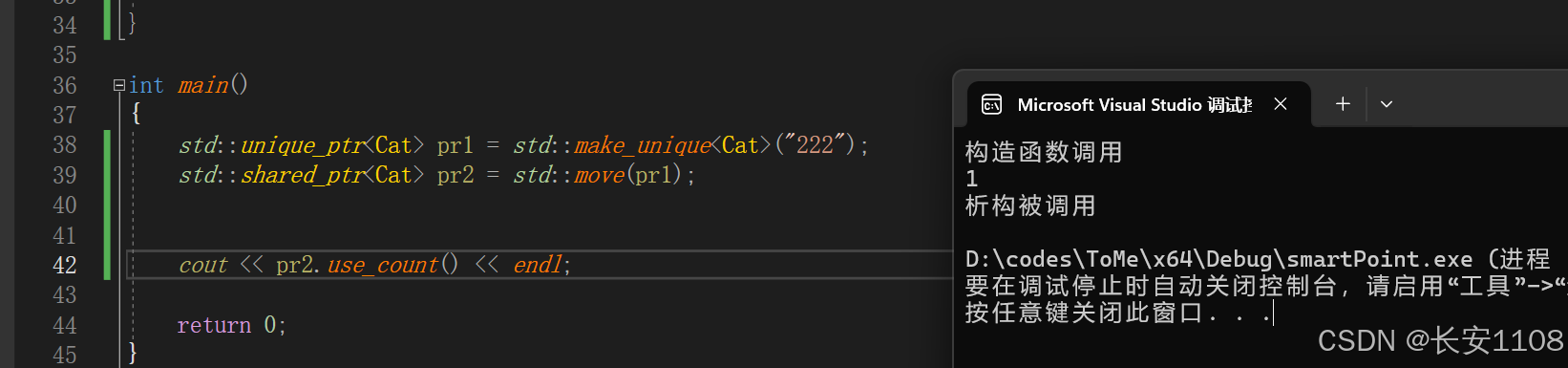
独占指针可以转为共享指针,但是共享指针不能转为独占指针
转换时,使用move,将独占指针传入,进行转换
隐式转换
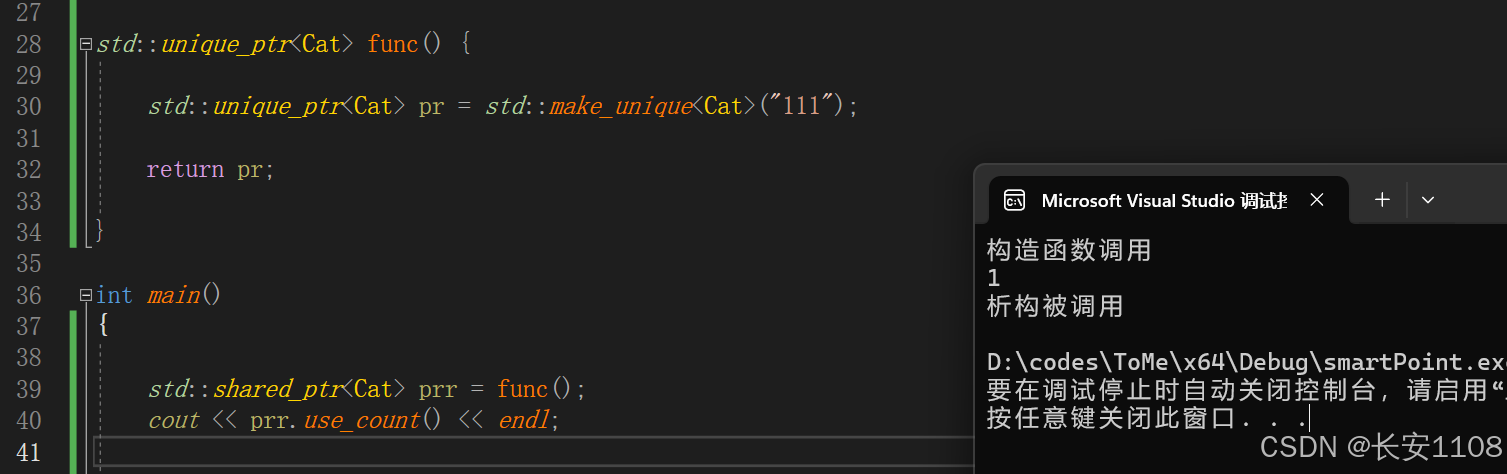
当一个函数的返回值是独占指针时,可以使用共享指针来接收,接收的过程发送隐式转换,可以将独占指针转为共享指针类型
所以,当我们在写类似的函数时,最好都返回独占,这样独占可以丝滑使用共享接收,但是也不一定,视情况而定
弱指针
简介

使用场景

定义
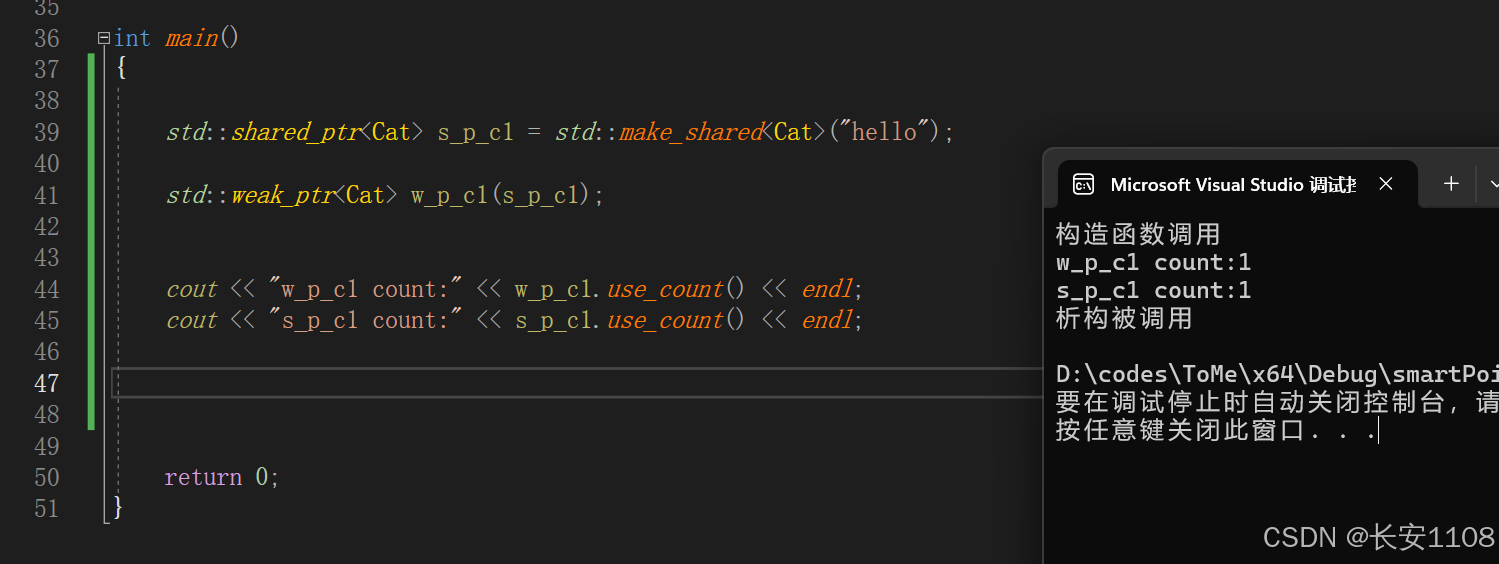
弱指针不能单独创建,因为他没有内存的所有权,需要依赖于共享指针,去创建弱指针
同时注意:弱指针并不占用内存的count数,也是因为他对内存没有所有权,他只是由一个共享指针降级拷贝得到的(强调拷贝,是因为由shared指针降级得到,但shared自己不会受到影响,所以是拷贝的特点,而不是引用的特点)
如上图,弱指针和共享指针的count数是一样的,都是1
提升为share_ptr
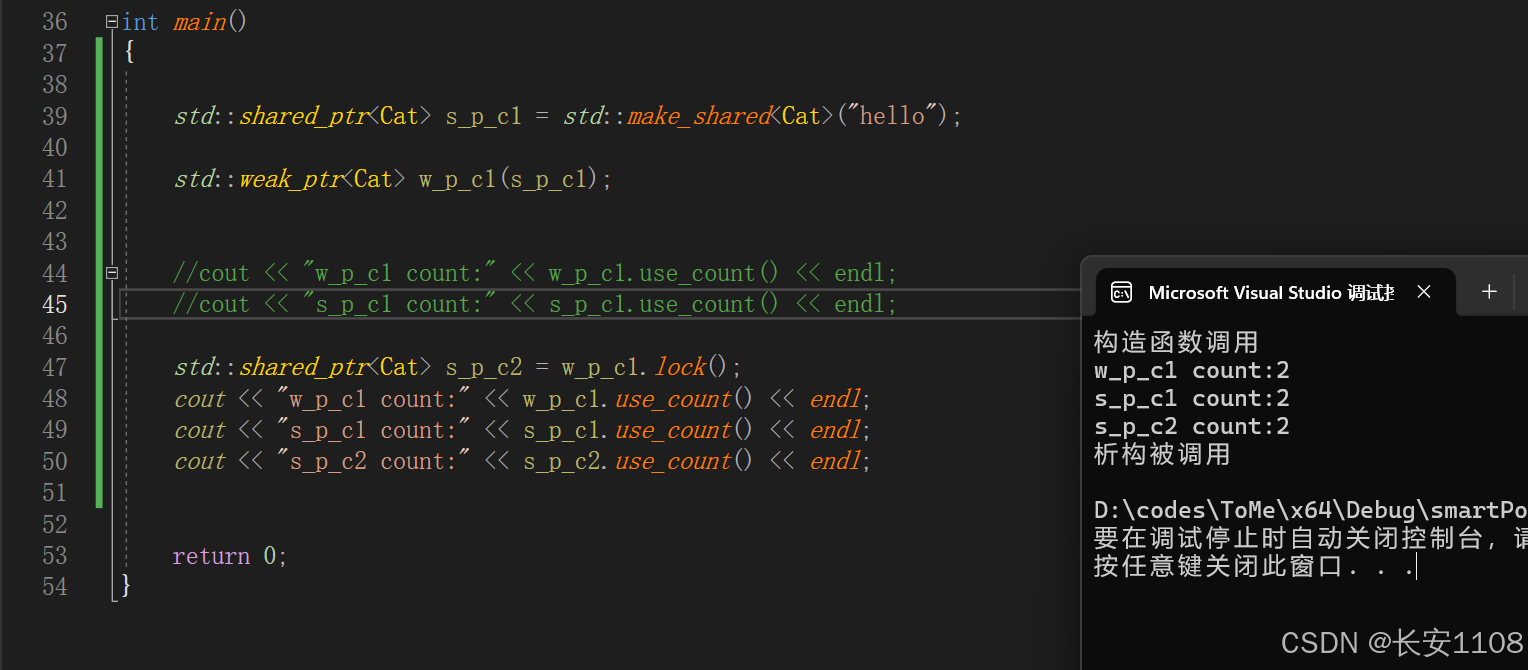
弱指针使用"点"调用lock,可以拷贝提升,生成出一个共享指针
由上面的打印可知,当前这块内存,由3个指针指向,其中,1个弱指针,2个共享指针(由此再次可知,提升也是拷贝出一个新的指针,而不是在原来的指针上做手脚,因为原来的弱指针没变)
注意,弱指针不能使用箭头函数

如上图所示,会报错,那如果一个指针,不能使用箭头函数,那对于这种自定义类型的数据,相当于是废了,因为不能使用箭头函数就不能调用类中的成员
那弱指针有什么用?
见下一节
解决循环依赖
产生循环依赖
对Cat类进行一些拓展:
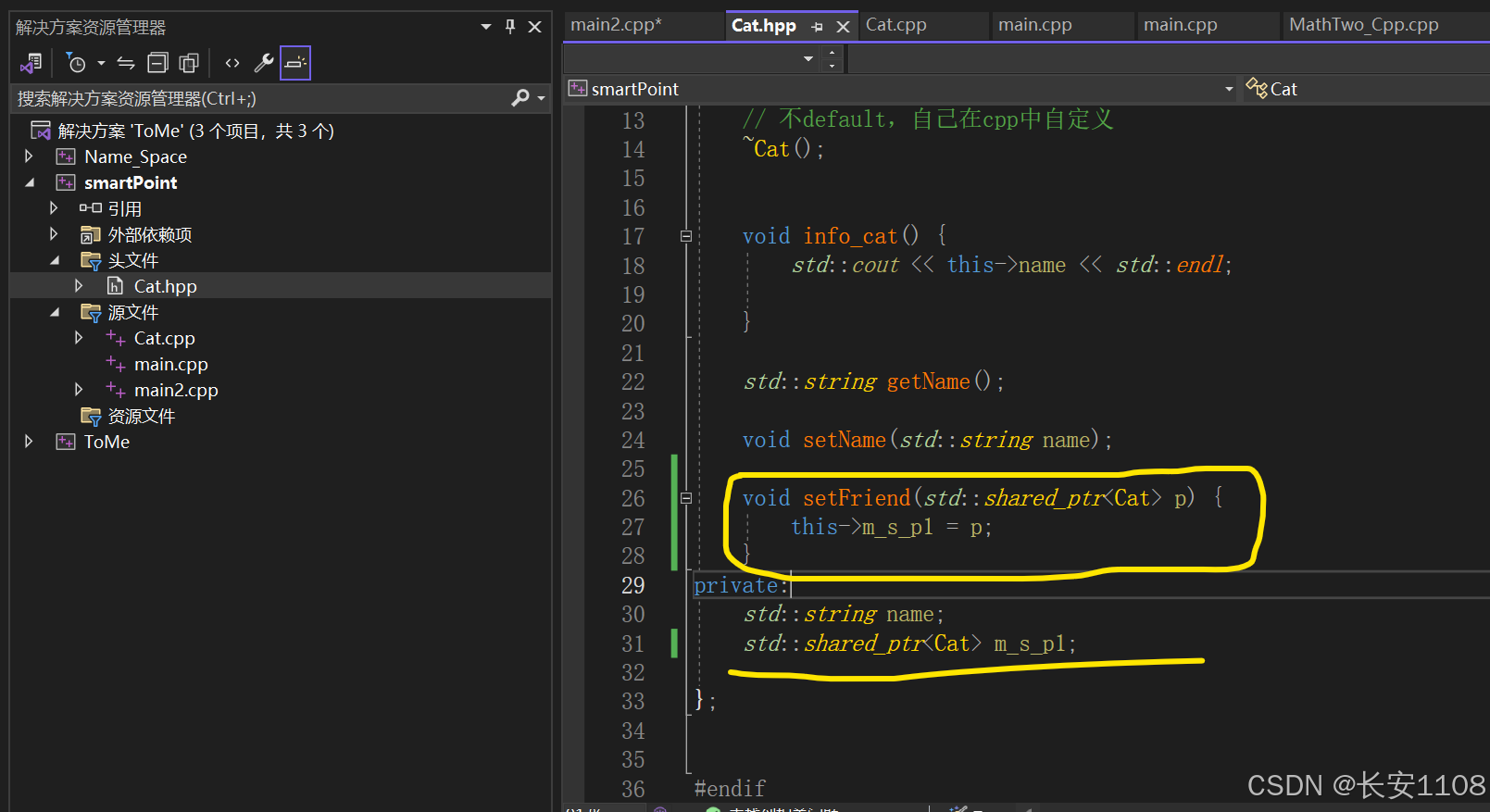
1:加一个类型的共享指针,准备存储当前这个猫的一个朋友,这个朋友也是个猫对象
2:加一个set函数,因为共享指针是私有的
产生循环依赖:

我们创建两个猫对象的共享指针,之后,互相将对方设置为朋友,也就是他们的共享指针成员互相指向对方
这样,在析构时,cat111想要释放cat222,但是释放的过程中,又需要把cat222中的cat111释放完才能释放cat222,所以,就形成了循环
所以最后二者都不会释放,造成内存泄漏
解决依赖
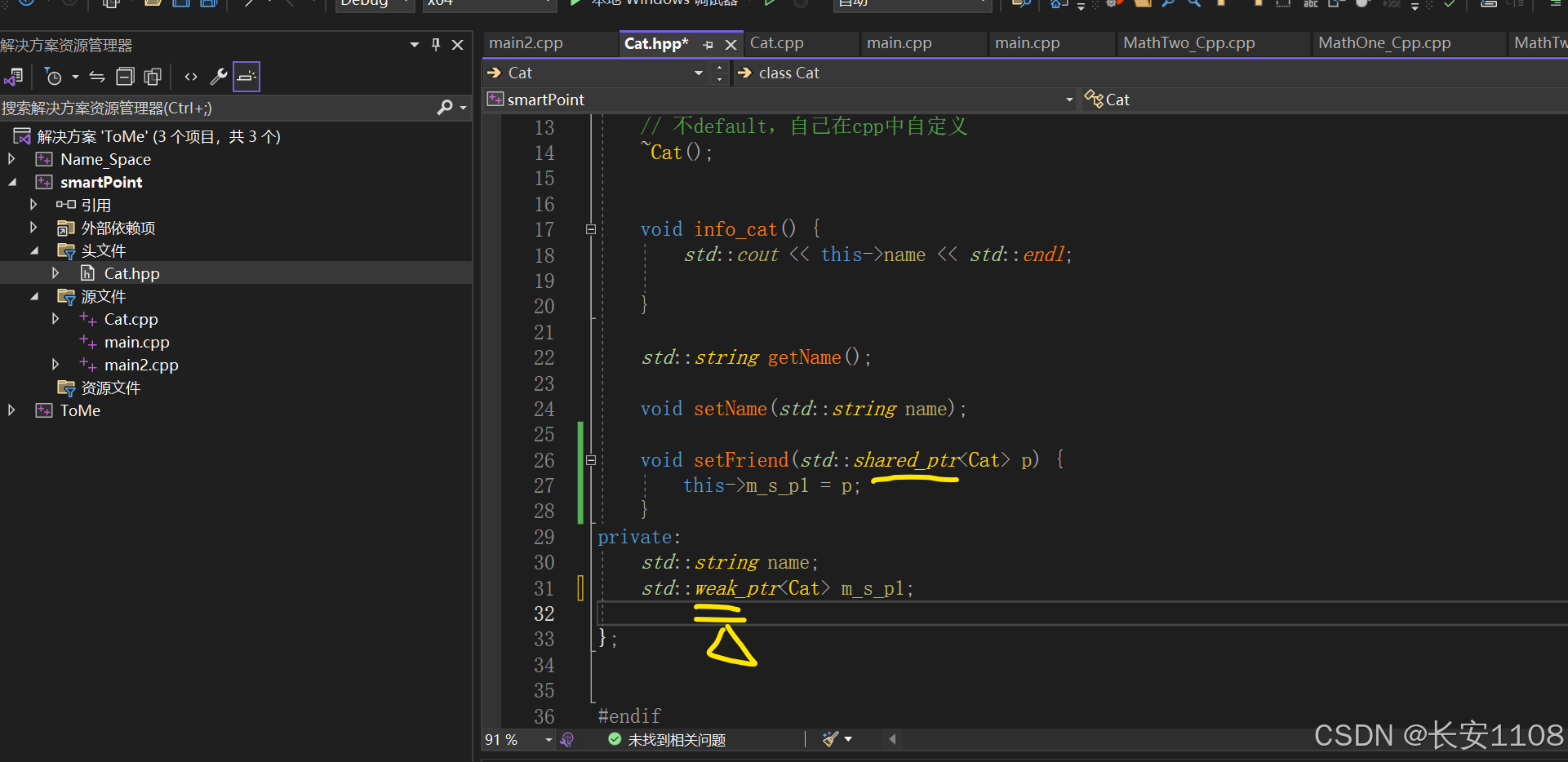
将成员变量改为弱指针即可,且setFriend中的形参都不用改,保持共享指针也可以(因为弱指针就是需要通过共享指针降级来定义的)
效果:
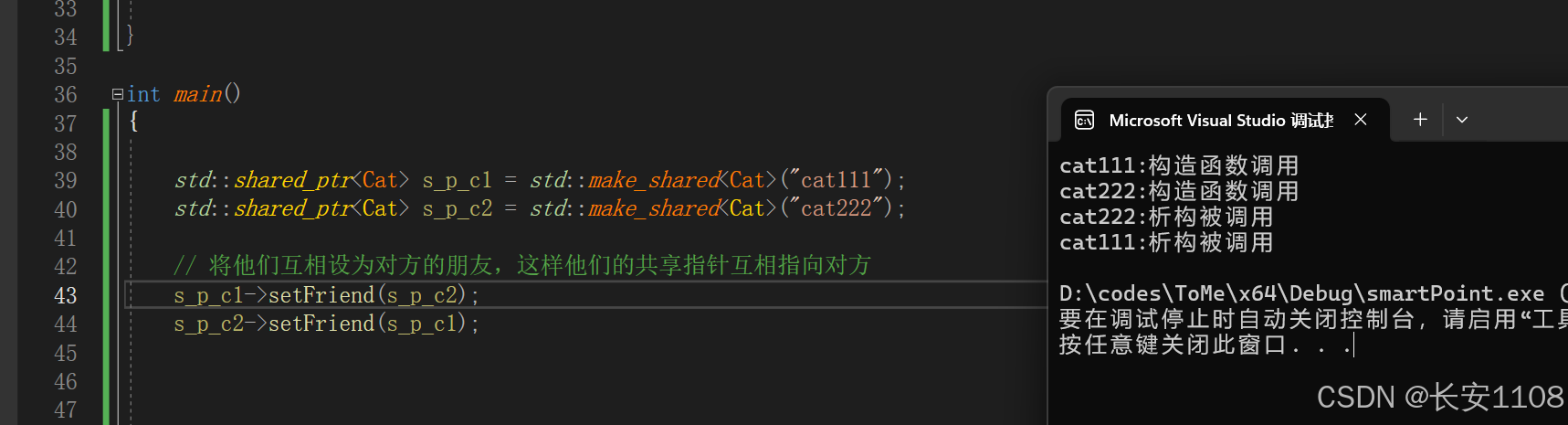
可以看到,两个对象都被正常析构
补充:
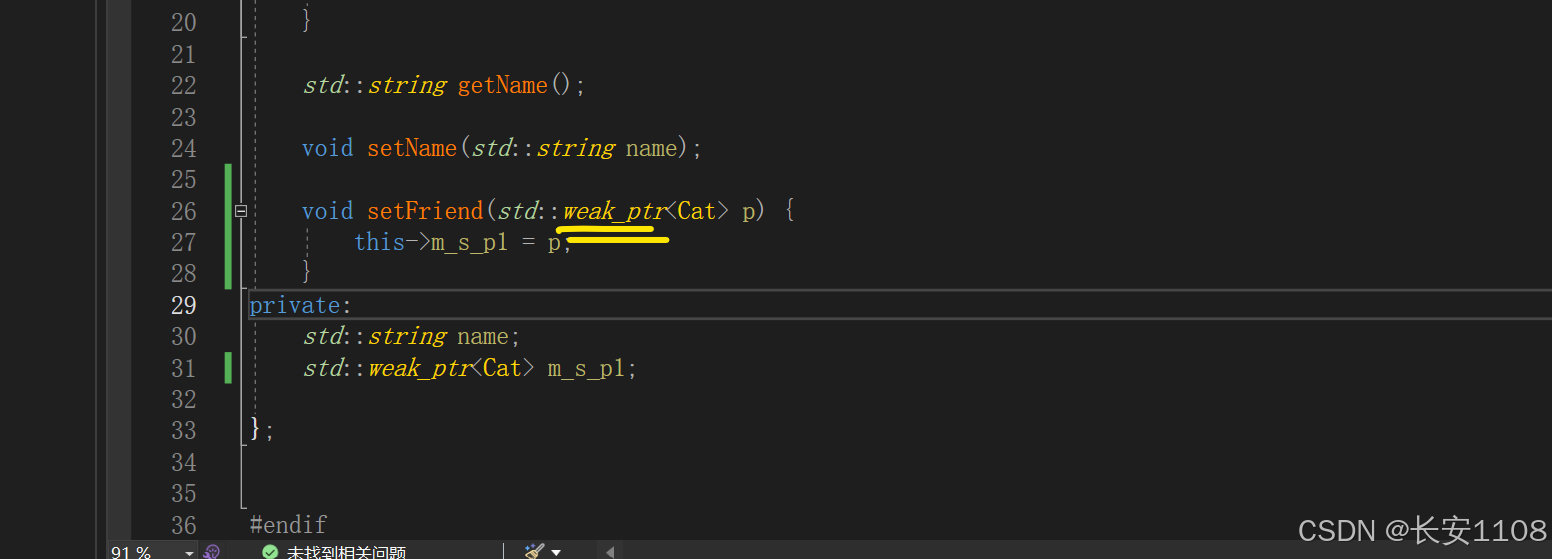
当然这里改成weak也可以,效果一样
为什么在子类构造函数中必须构造父类
因为子类继承了父类之后,父类中的成员变量和成员属性子类都可以使用,或者说都归子类
那么子类自己的构造函数只负责:构造子类对象时,对该对象的子类原本的成员变量进行初始化,但是不负责对继承而来的成员变量进行初始化
所以需要在子类构造中,设置调用父类构造,使得子类对象在调用子类构造初始化原本的成员变量时,通过父类构造将继承而来的变量也初始化,这样才能保证类的完整性,不然子类对象仍然无法使用继承而来的成员变量
而,虽然成员函数不需要初始化,但是可能有些成员函数会用到成员变量,所以,C++为了安全性与完整性,强制要求“在子类构造中,设置调用父类构造”,哪怕你只想使用一下成员函数
移动语义
右值引用
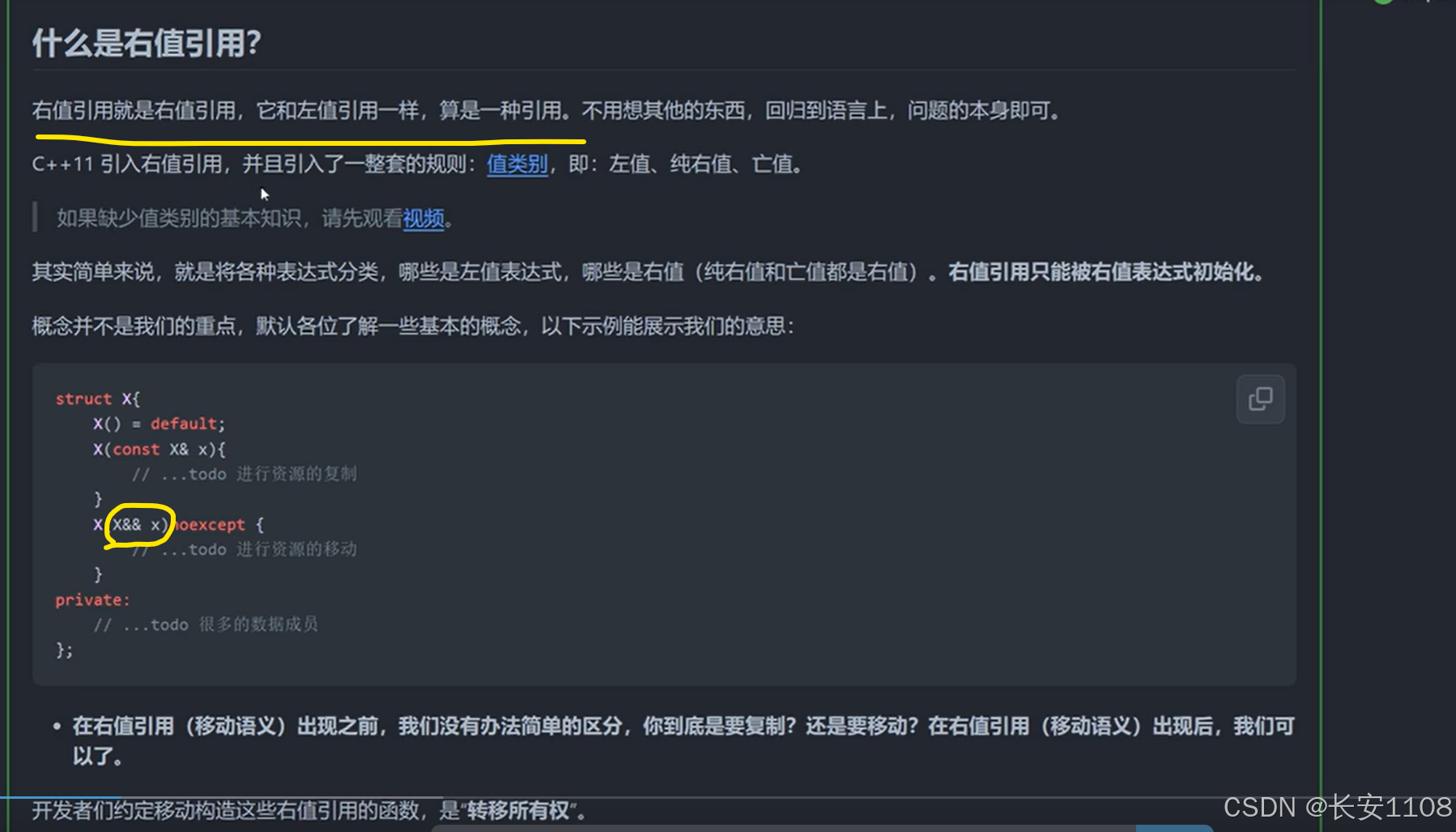
右值引用,把他当成一种类型即可,他就是一种引用,不过是对右值的引用,类型记作X&&
例:
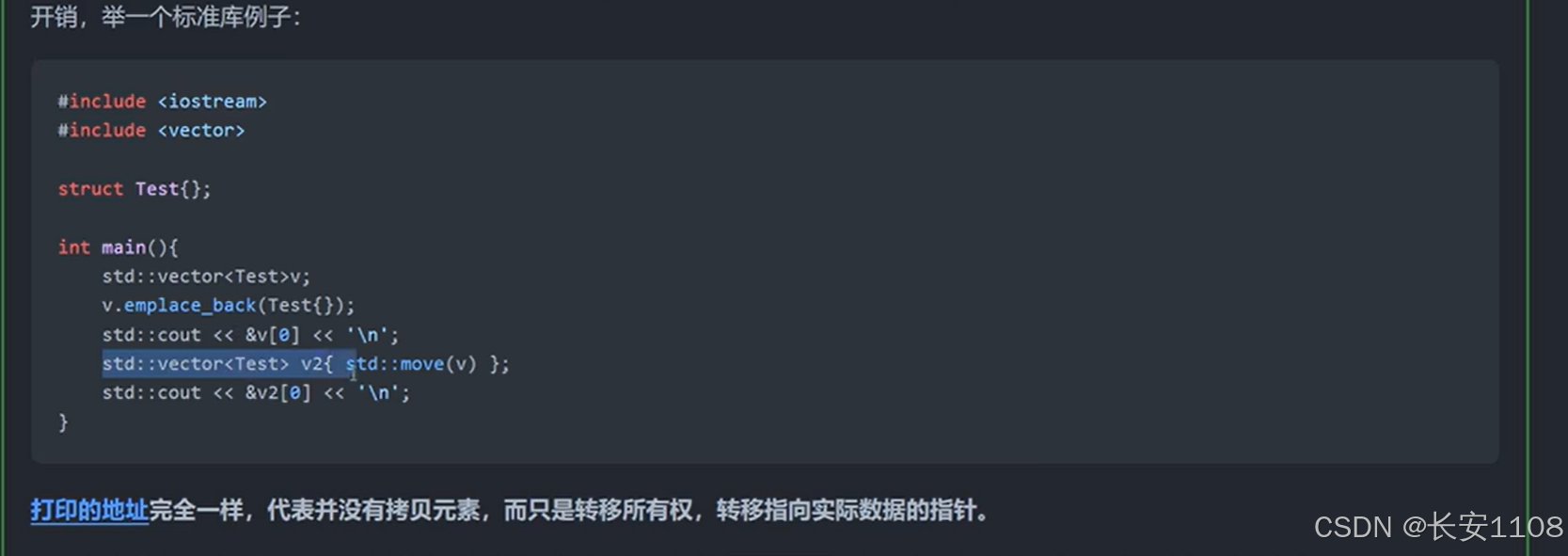
这里先打印v的0号元素地址
之后,使用移动构造,构造出一个v2
打印v2的0号元素地址,发现地址相同
std::move

move,就是将一个左值,转换为右值引用,从而与移动构造和移动赋值等这些需要“右值引用”参数的函数进行匹配,供他们使用,仅此而已
或者说,move就是给移动构造和移动赋值创造实参的,将左值转为右值引用
移动构造和移动赋值
定义
他们是C++提供的默认函数,C++类中会默认实现他们
手动经典实现

使用右值引用构造完新对象的成员变量后,将右值引用的成员变量置空置零

移动赋值则需要多考虑一下,防止发送自我赋值
异常
测试一
测试目的
测试函数在throw异常之后,函数后续的代码是否还会执行
头文件

需要引入头文件
自定义异常类

1、要继承exception类
2、需要一个string成员,存储报错信息
3、构造函数使用有参构造
实际上在后续抛出异常时,就是要手动调用有参构造构造对象
4、重写exception基类的虚函数,注意返回值是char *,所以调用了c_str()方法
测试函数

在一个函数中,模拟定义逻辑:
正常业务进行 -> 出现异常抛出 -> 后续业务继续
用于测试抛出异常后,函数内的业务流程是否会继续
主函数
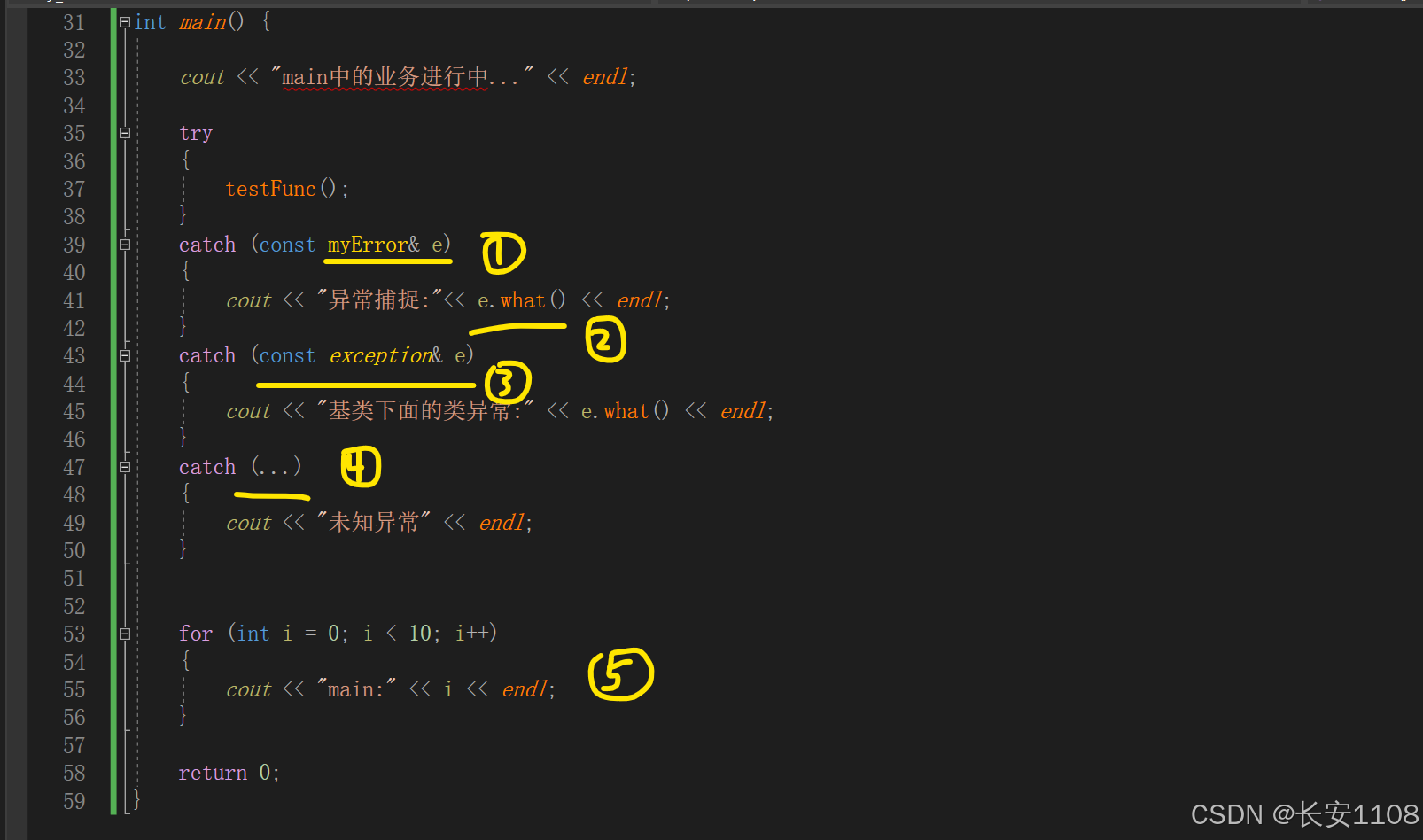
1、try之后,尝试捕捉我们的自定义类异常
捕捉到之后,打印信息,并使用e.what()成员方法,得到报错信息
2、使用e.what()成语方法得到报错信息
3、后续捕捉基类
可以捕捉到继承该基类的所有异常类对象的抛出
4、最后可以加上一个(…)
表示可以捕捉未知异常
5、模拟main函数的后续逻辑
运行结果
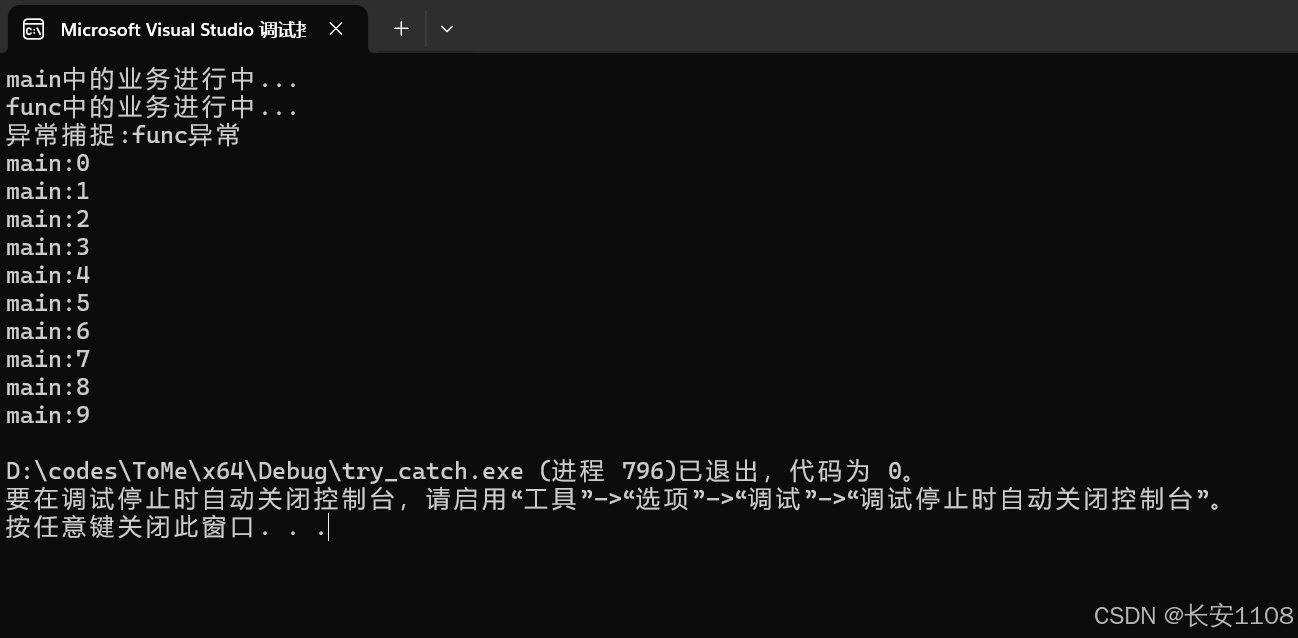
由此得出结论:
1、函数抛出异常之后,throw后面的代码将不会执行
2、外层捕捉到异常之后,外层的程序会继续向下正常运行
测试二
测试目的
测试当外层没有人处理抛出的异常时,会怎么样
代码
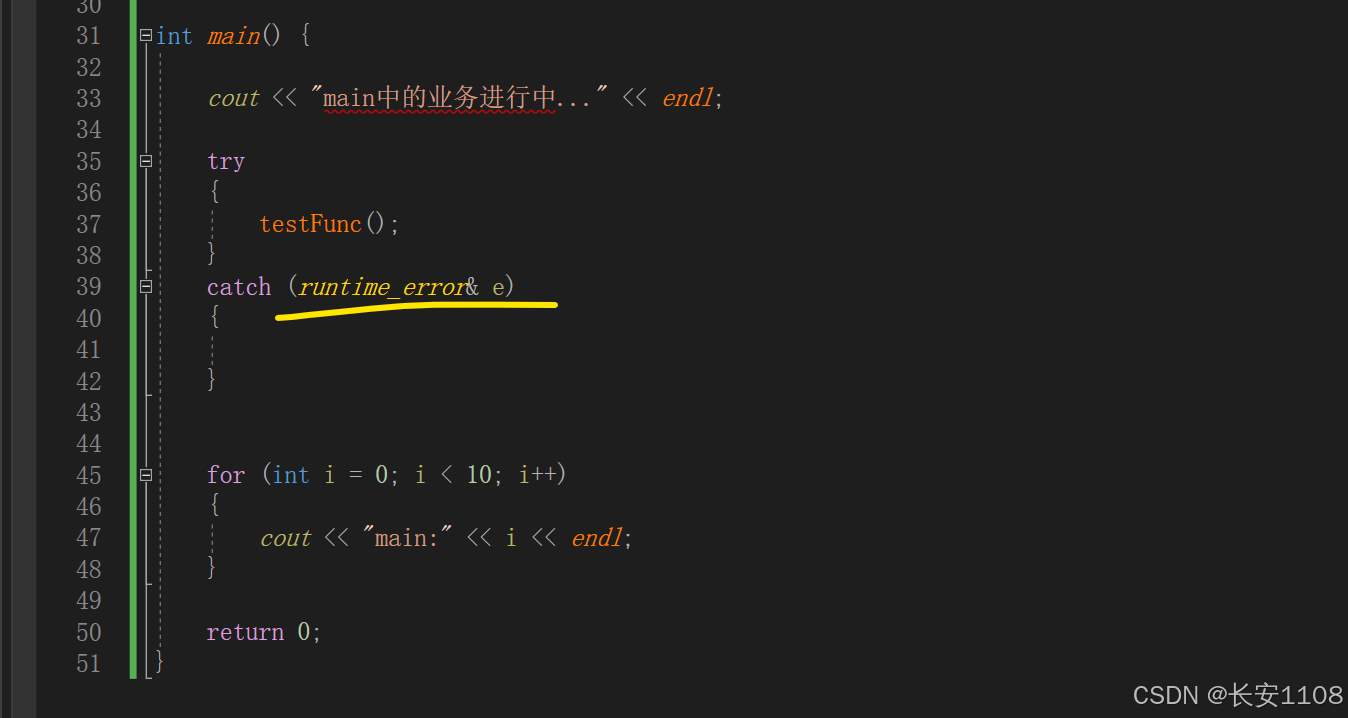
我们仅让去捕捉一个毫不相关的异常
运行结果
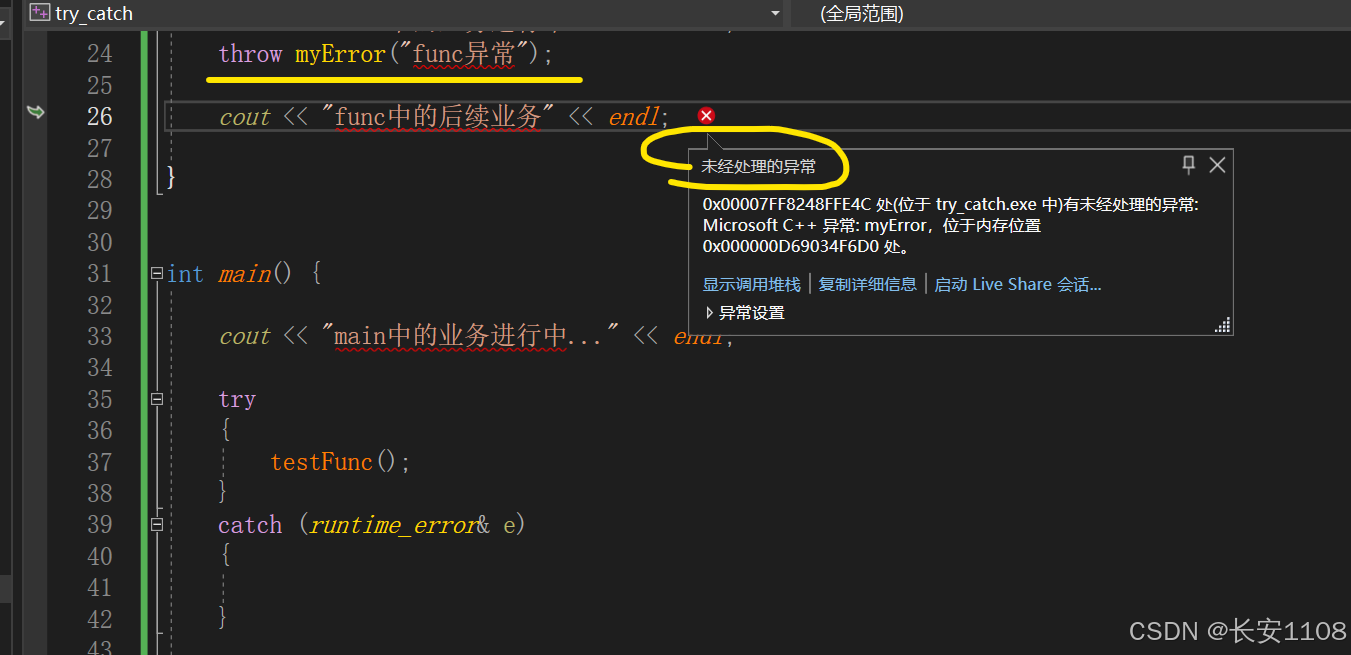
程序会停止运行,并且崩在我们抛出异常的位置
由此得出结论:
如果throw一个异常后,外层没有任何一层去捕捉异常,那么程序会崩溃在throw代码处
测试三
测试目的
看throw的异常,能否跨多层捕捉
代码
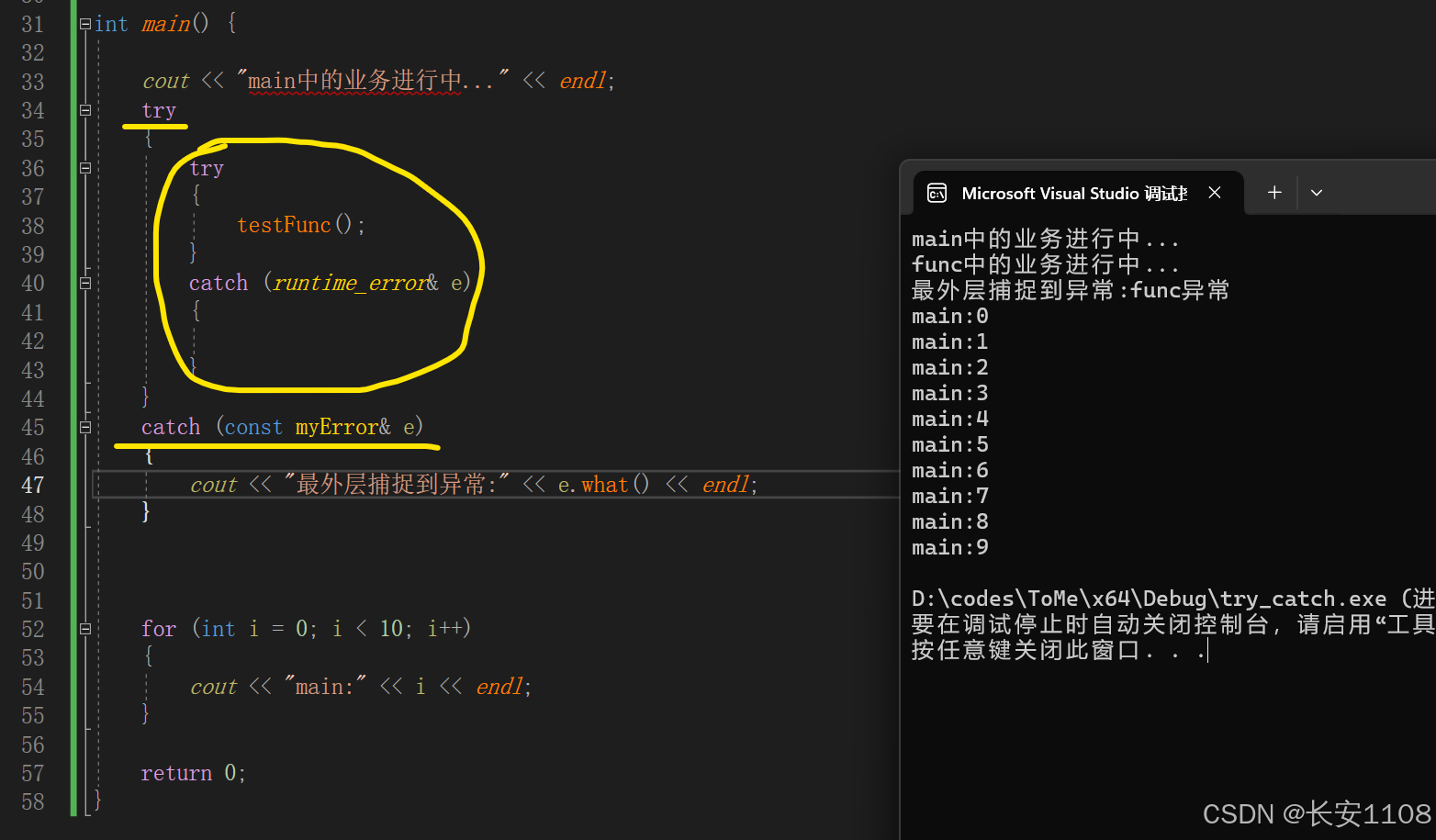
由此得出结论:
抛出后,最近一层没有处理的话,会继续向外层查询看是否捕捉,外层不管几层都可以捕捉到最内层的异常,但是前提是内部每层都没对异常进行捕捉
也就是由内而外看哪层能捕捉到


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









