







第七章 文件
打开文件
f=open(file, mode='r', buffering=-1, encoding=None)file:必需,文件路径
mode:可选,文件打开模式
buffering:设置缓冲
encoding:编码方式,若没有指定该参数,则默认用GBK、utf-8
| 打开模式 | 说明 |
| t | 文本模式 |
| b | 二进制模式 |
| + | 打开一个文件进行更新 |
| r | 以只读形式打开文件用于只读。文件指针将会放在文件的开头 |
关闭文件
f.close()【例】打开文件test.txt并读取其中的数据显示到屏幕上
f=open("test.txt", "r")
print(f.read())
f.close()Pthon还可以引入with语句来管理资源,自动调用close()方法:
with open('test.txt', 'r') as f:
print(f.read())
print(f.read()) #程序报错第一个print语句可以正确执行,执行完成之后自动调用了close方法,第二个print语句由于文件对象f已经被关闭,所以程序报错。
文件定位操作
f.tell():查看文件指针位置
f.seek(0):把文件指针移动到文件开始位置
目录操作
os.walk:遍历目录的整个结构
os.listdir:遍历目录中的子目录和文件,但子目录中的文件不会被遍历
import os
path=os.getcwd()#获得当前Python脚本工作的目录路径
print(path)
print(os.listdir(path))#查找当前目录下的所有文件和目录名
for root,dirs,files in os.walk(r'D:\Jupyter notebook',topdown=False):#遍历一个目录内各个子目录和子文件
for name in files:
print(os.path.join(root,name))#目录拼接
for name in dirs:
print(os.path.join(root,name))import os
for root,dirs,files in os.walk(r"D:\Huawei Share",topdown=False):
count=1
for name in files:
if os.path.splitext(name)[1]=='.bmp':#分离拓展名
newname=str(count)+'.jpg'
os.rename(os.path.join(root,name),os.path.join(root,newname))
count+=1topdown=False:从最底层到顶层
topdown=True:自上而下
实验思考题
1、读文件并打印
with open(r"D:\Cfiles\Python\test.txt","r") as f:
print(f.read())
f.seek(0)
print(f.readlines())运行结果:
hello world!
this is a test
python
['hello world!\n', 'this is a test\n', 'python\n']read()会读取整个文件的内容,并将读取的游标留在文件的末尾,
如果没有f.seek(0)来移动游标在文件中的位置,则print(f.readlines())读取结果只有一个[]。
2、读取文件,在每一行前面标上序号,并存储为新的文件
def print_to_file(fname):
num = 1
with open(fname+"_OK.txt", "w") as output_file:
with open(fname,'r') as input_file:
for line in input_file:
output_file.write('%03d%s' % (num, line))
num += 1
fname = r"D:\Cfiles\Python\hello.txt"
print_to_file(fname)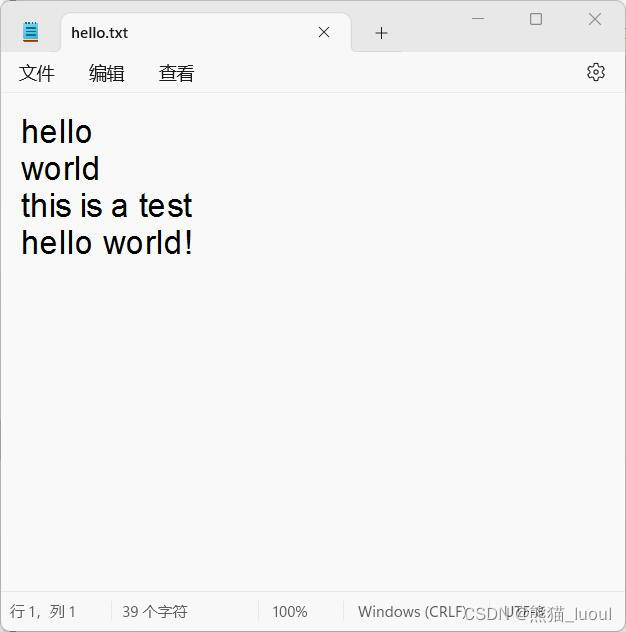
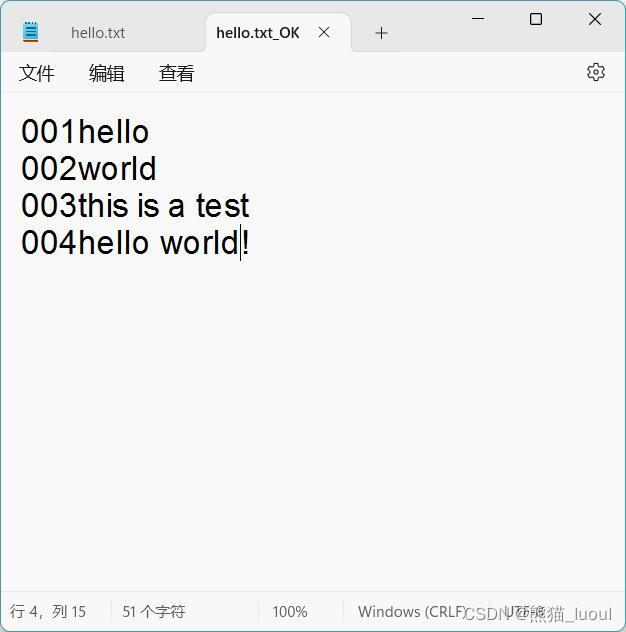
3、查找一个根目录中是否存在所找的文件
import os
path= r"D:\Cfiles\\"
filename="hello.txt"
for root,dirs,files in os.walk(path):
for name in files:
if filename==name:
print(os.path.join(root,name))4、替换文件中指定的字符串
def alter(file,old_str,new_str):
file_data=''
with open(file,"r",encoding="utf-8") as f:
for line in f:
if old_str in line:
line=line.replace(old_str,new_str)
file_data+=line
with open(file,"w",encoding="utf-8") as f:
f.write(file_data)
file=r"D:\Cfiles\Python\hello.txt"
alter(file,'hello','你好')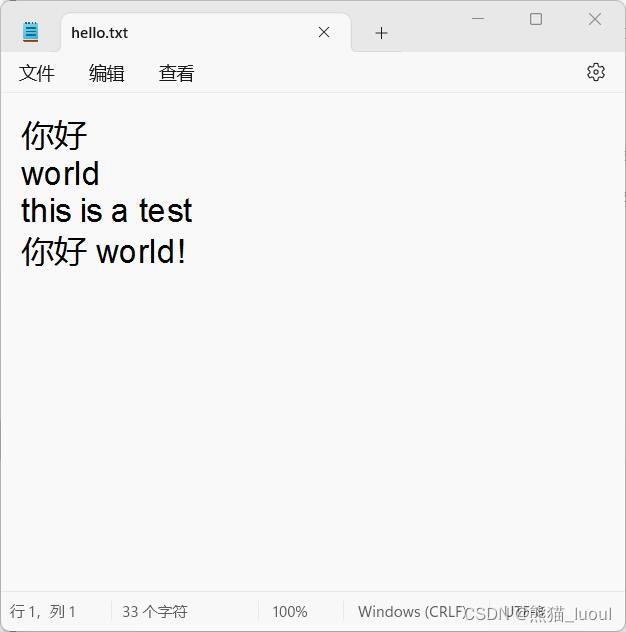
5、统计文本文件中最长行和该行的内容
def find_longest_line(file_path):
max_length = 0
longest_line = ''
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
for line in lines:
line_length=len(line)
if line_length > max_length:
max_length = line_length
longest_line = line
return max_length, longest_line
# 指定文本文件路径
file_path = r"D:\Cfiles\Python\hello.txt"
# 调用函数获取最长行和内容
max_length, longest_line = find_longest_line(file_path)
print(f"最长行长度:{max_length}")
print(f"最长行内容:{longest_line}")运行结果:
最长行长度:15
最长行内容:this is a test6、以行为单位列出两个文本文件中重复的内容
file_path1 = r"D:\Cfiles\Python\hello.txt"
file_path2 = r"D:\Cfiles\Python\test.txt"
with open(file_path1, 'r', encoding='utf-8') as file1:
lines1 = file1.readlines()
with open(file_path2, 'r', encoding='utf-8') as file2:
lines2 = file2.readlines()
for line2 in lines2:
if line2 in lines1:
print(line2)运行结果:
this is a test7、通过jieba库对文本文件进行分词,并用wordcloud库绘制词云图
import jieba as jb
import wordcloud as wc
import matplotlib.pyplot as plt
with open(r"D:\Cfiles\Python\a.txt",'r',encoding='utf-8') as f:
text=f.read()
seg_list=jb.cut(text,cut_all=True)
liststr=" ".join(seg_list)
print("原文:",text)
print("分词:",liststr)
wc1=wc.WordCloud(font_path=r'C:\Windows\Fonts\simfang.ttf')
wc1.generate(liststr)
plt.imshow(wc1)
原文: 《明日方舟》是由上海鹰角网络科技有限公司自主开发运营的一款策略向即时战略塔防游戏,iOS和Android服务器分别于2019年4月30日和5月1日开启公测 ,该游戏适龄级别为12+。在游戏中,玩家将作为罗德岛的领导者“博士”,带领罗德岛的一众干员救助受难人群、处理矿石争端以及对抗诸如整合运动等其他势力。在错综复杂的势力博弈之中,寻找治愈矿石病的方法。
分词: 《 明日 日方 方舟 》 是 由 上海 海鹰 角 网络 网络科技 科技 有限 有限公司 公司 自主 开发 发运 运营 的 一款 策略 向 即时 即时战略 战略 塔 防 游戏 , iOS 和 Android 服务 服务器 务器 分别 于 2019 年 4 月 30 日 和 5 月 1 日 开启 公测 , 该游戏 游戏 适龄 龄级 级别 为 12 + 。 在 游戏 中 , 玩家 将 作为 罗德岛 德岛 的 领导 领导者 “ 博士 ”, 带领 罗德岛 德岛 的 一 众 干员 救助 受难 人群 、 处理 矿石 争端 以及 对抗 诸如 整合 合运动 运动 等 其他 势力 。 在 错综 错综复杂 复杂 的 势力 博弈 之中 , 寻找 治愈 矿石 病 的 方法 。

8、读取账单的文本文件,统计总花销
data = []
with open(r"D:\Cfiles\Python\a.txt", 'r', encoding='utf-8') as f:
for line in f:
parts = line.split()
name = parts[0]
price = int(parts[1])
amount = int(parts[2])
item = {"name": name, "price": price, "amount": amount}
data.append(item)
total_price = sum(item["price"] * item["amount"] for item in data)
print(data)
print(total_price)[{'name': 'apple', 'price': 10, 'amount': 3}, {'name': 'tesla', 'price': 100000, 'amount': 1}, {'name': 'mac', 'price': 3000, 'amount': 2}, {'name': 'lenovo', 'price': 30000, 'amount': 3}, {'name': 'chicken', 'price': 10, 'amount': 3}]
1960609、读取成绩单文本文件,统计每门学科的平均分和方差,并输出每位同学的总分
import statistics
data={}
def file_read(filename):
with open(filename,'r') as f:
number=0
grades=[]
for line in f:
parts=line.split()
name=parts[0]
grade=int(parts[1])
number+=1
if name in data:
data[name]+=grade
else:
data[name]=grade
grades.append(grade)
sum_score=sum(grades)
average_score=sum_score/number
variance=statistics.variance(grades)
return sum_score,average_score,variance
def print_info(filename):
print("数据来源:",filename)
s,a,v=file_read(filename)
print("该学科的总分为{},平均分为{},方差为{}。".format(s,a,v))
f1=r"D:\Cfiles\Python\语文.txt"
f2=r"D:\Cfiles\Python\数学.txt"
f3=r"D:\Cfiles\Python\英语.txt"
fn=[f1,f2,f3]
for file in fn:
print_info(file)
for name,grade in data.items():
print("姓名:{:<8}总分:{}".format(name,grade))运行结果:
数据来源: D:\Cfiles\Python\语文.txt
该学科的总分为380,平均分为95.0,方差为31.333333333333332。
数据来源: D:\Cfiles\Python\数学.txt
该学科的总分为394,平均分为98.5,方差为1.6666666666666667。
数据来源: D:\Cfiles\Python\英语.txt
该学科的总分为443,平均分为88.6,方差为56.3。
姓名:abc 总分:283
姓名:bcd 总分:287
姓名:cde 总分:264
姓名:amiya 总分:100
姓名:def 总分:184
姓名:logos 总分:99















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









