







一、认识Hadoop框架

Hadoop是一个提供分布式存储和计算的开源软件框架,使用Java语言编写,具有高扩展性、高容错性、无共享和高可用(HA)等特点,非常适合处理海量数据。它基于Google发布的MapReduce论文实现,并且应用了函数式编程的思想。
Hadoop框架主要包括HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce、YARN(Yet Another Resource Negotiator,另一种资源协调者)等模块。其中,HDFS是Hadoop集群中最根本的文件系统,提供了高扩展、高容错、机架感知数据存储等特性,可以非常方便的部署在机器上面。MapReduce是Hadoop的分布式计算框架,它将数据处理分成两个阶段,即Map阶段和Reduce阶段。在Map阶段,数据会被分成多个小的数据块,然后由不同的Map任务并行处理;在Reduce阶段,中间结果会被分组,并且由不同的Reduce任务并行处理,生成最终的输出结果。YARN则负责为Hadoop作业分配和管理资源。
Hadoop的工作原理主要依赖HDFS和MapReduce。HDFS将大文件分割成多个块,并存储在不同的计算节点上,以提高数据的可靠性和容错性。MapReduce则将数据处理分成Map阶段和Reduce阶段,通过并行处理来加快数据处理的速度。
Hadoop的优点包括:
- 高容错性:数据自动保存多个副本,并通过增加副本的形式提高容错性,当某个副本丢失时,它可以自动恢复。
- 适合处理大数据:能够处理数据规模达到GB、TB、甚至PB级别的数据,以及百万规模以上的文件数量。
- 可构建在廉价机器上:通过多副本机制提高可靠性。
然而,Hadoop也存在一些缺点,例如不适合低延时数据访问,无法高效地对大量小文件进行存储等。
总的来说,Hadoop是一个功能强大的分布式计算和存储框架,可以应用于各种大数据处理场景,如数据分析、数据挖掘、机器学习等。
二、了解Hadoop的核心组件
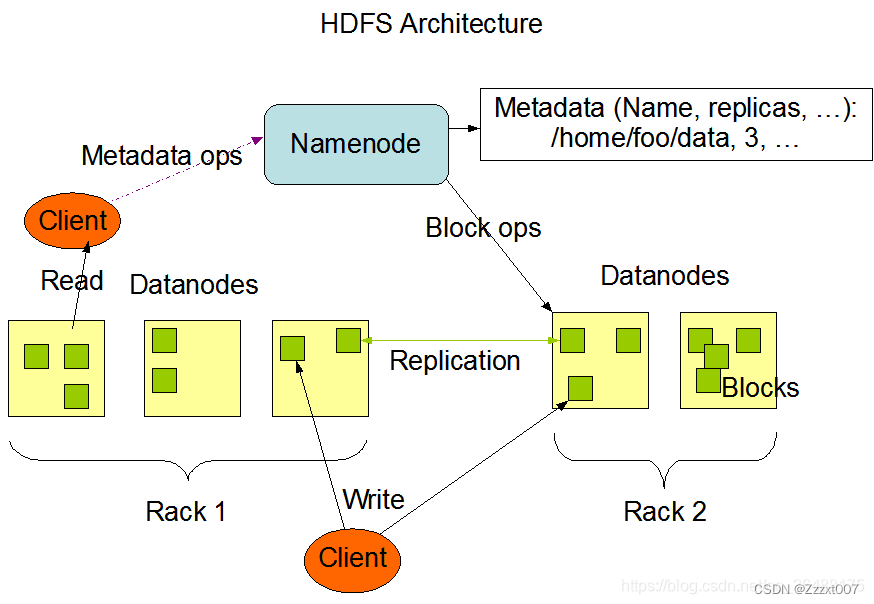
Hadoop的核心组件主要包括Hadoop Common、HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce以及YARN(Yet Another Resource Negotiator,另一种资源协调者)。
Hadoop的核心组件主要包括Hadoop Common、HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)、MapReduce以及YARN(Yet Another Resource Negotiator,另一种资源协调者)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 9768
9768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









