






最近在做爬虫作业,心血来潮决定认真爬一下猫耳的弹幕,毕竟之前没学的时候都是F12完cltr+f的笨方法找字幕,如果用了爬虫想必以后自己做二创也能轻松一点吧()
主要思路是先找出字幕组工作人员的id,然后再打印出疑似工作人员id发送的所有弹幕,以完成筛选。
比起爬虫更多的是在做数据清洗和筛选工作。
使用猫耳的免费剧集,虚拟偶像团综丨《名利场》作为例子(其实就是我自己要用)由于本文章撰写时间跨度较大,出现了截图中前后使用的音频不同的情况,不过问题应该不大。
进入想要爬取的音频/视频页面。F12打开开发者模式,在【网络-Fetch/XHR-getdm?soundid=[ID]-预览】下面可以看见弹幕列表预览
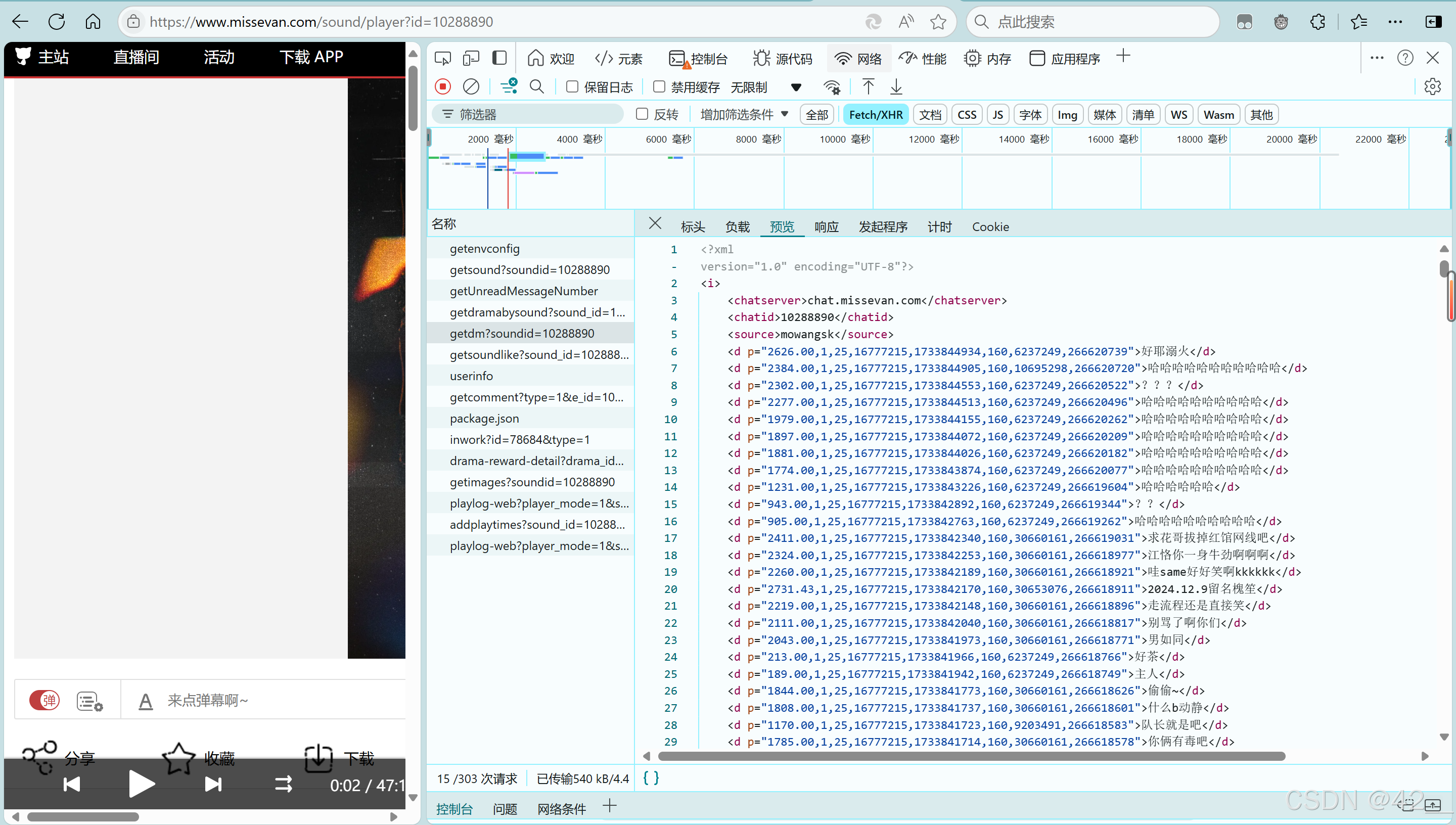
这里的[ID]就是音频(视频?)的ID,相当于b站的bv号,在视频所在网址的末端可以看到,猫耳的音频格式均为
https://www.missevan.com/sound/player?id= [ID]
虽然不是很懂,但是这个【Fetch/XHR】好像是两个数据请求方法,大概意思可能是我们在这里看到的只是当前网站在向另一个网站请求信息?而我们所需要的弹幕信息就存储在 【标头-请求URL】后面的网址里:
https://www.missevan.com/sound/getdm?soundid=[ID]

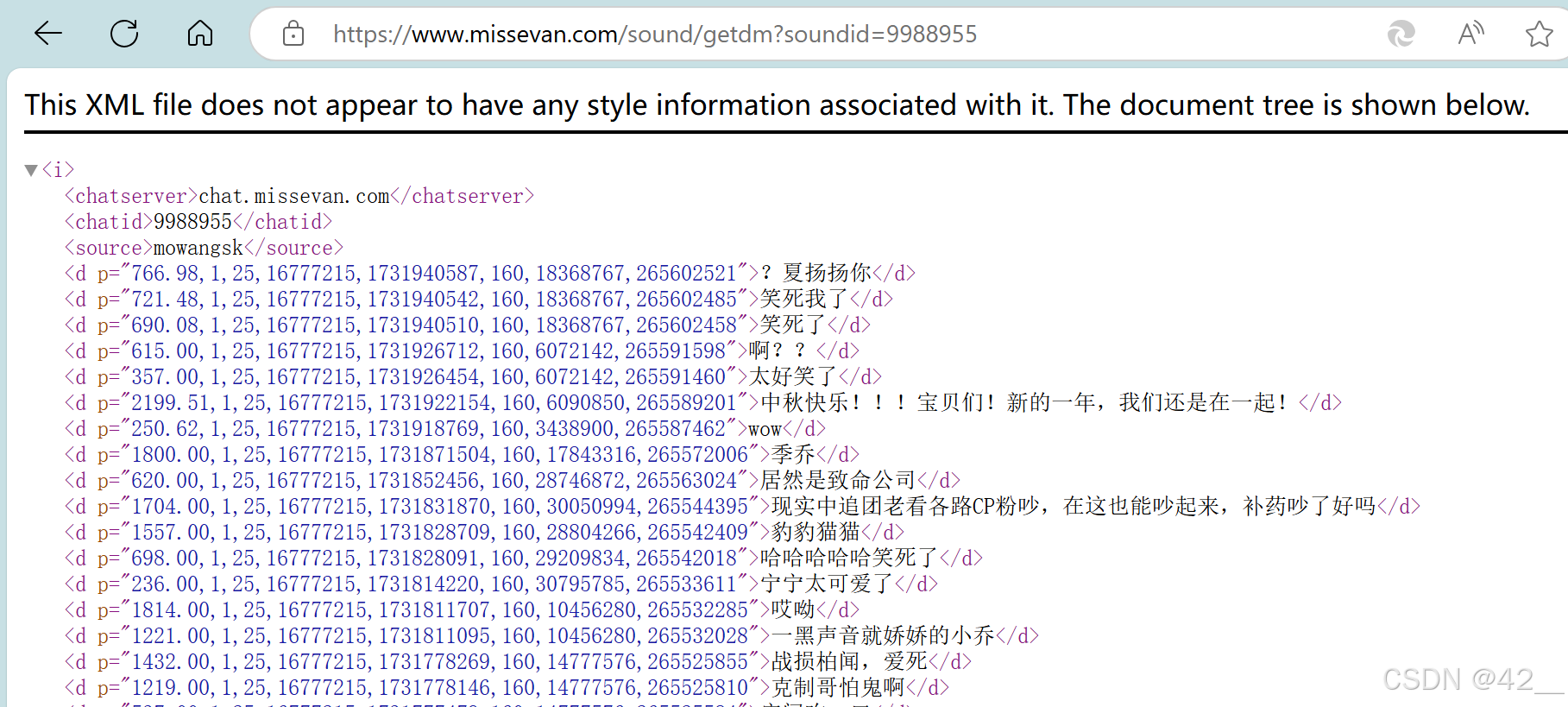
于是我们直接爬取这个网址的信息,代码如下:
import requests
# 确认网页地址
url = "https://www.missevan.com/sound/getdm?soundid=10288890"
# 获取网页内容
response = requests.get(url)
print(response.text)输出结果:
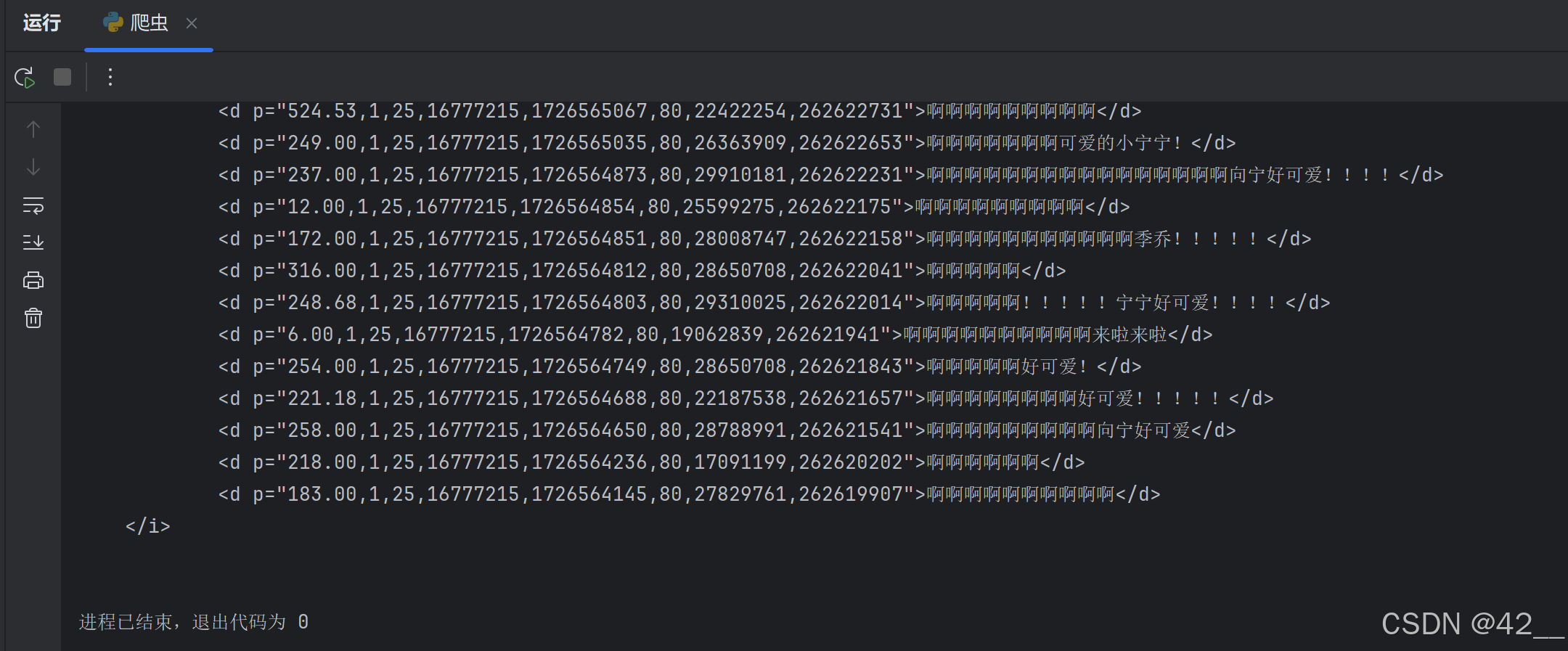
我们观察这长长的一串弹幕信息,以上图中最后一条弹幕为例,第一个数字“183.00”代表弹幕发送时间(以秒为单位),第四个数字“1677215”代表是弹幕的颜色信息(hex颜色代码的十进制)【1677215这个大家都在用的颜色转换成16进制是ffffff,默认白色】,倒数第二个数字“27829761”则是代表发送的用户ID。以我本人账号为例,这个ID会显示在个人主页的网址最后:
我摸索出来的弹幕信息就这些,不过这也已经足够。
为了便于筛选弹幕,我们把从网站中提取的弹幕信息存储至一个列表当中。再从该列表提取关键信息并格式化存入新列表,返回。
#将弹幕信息存入list
def get_list(xml_content):
# 解析XML
root = ET.fromstring(xml_content)
list1 = [ET.tostring(d, encoding='unicode') for d in root.findall('d')]
# 遍历每个弹幕元素
for danmaku in list1:
# 提取 p 属性中的值
p_value = re.search(r'p="([^"]+)"', danmaku)
if p_value:
# 将 p 属性值按逗号分隔并提取所需的信息
p_parts = p_value.group(1).split(',')
# 获取发送时间、发送id和颜色信息
time = p_parts[0] # 发送时间
times.append(time)
id = p_parts[6] # 发送id
ids.append(id)
color = p_parts[3] # 颜色信息
colors.append(color)
# 提取弹幕内容(标签内的文本部分)
content = re.search(r'>(.*?)</d>', danmaku).group(1)
contents.append(content)
danmaku_list = list(zip(times,ids,colors,contents))
return danmaku_list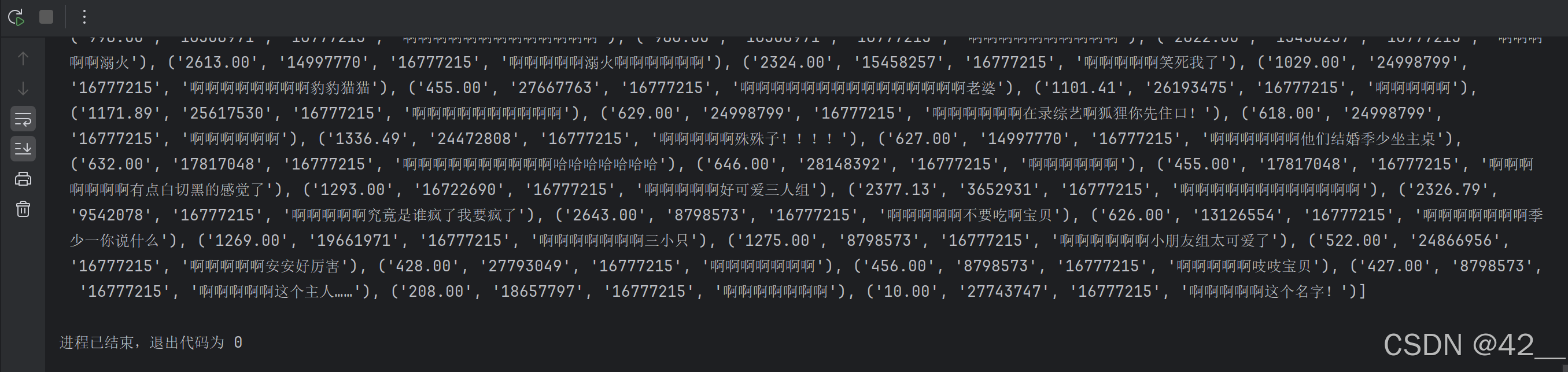
如何从普通用户发送的吐槽弹幕和字幕中区分出我们需要的字幕呢?
(本来是想可以按弹幕数量进行筛选的,但是过程中发现普通听众发送弹幕的数量也很感人……这太恐怖了……)
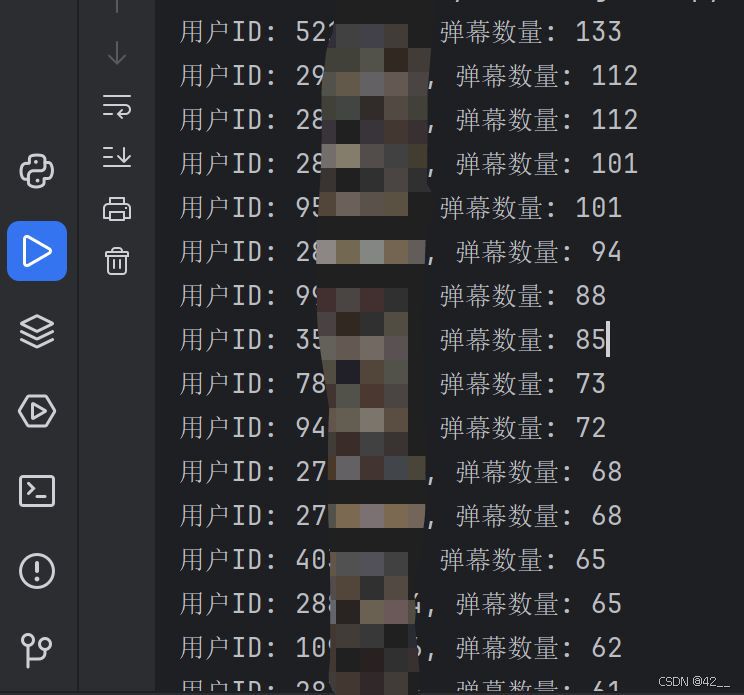
好吧,换一套标准来。对字幕组人员的新识别标准为发送疑似字幕超过十条,疑似字幕:1:格式为“人名”+“:”+“(其他内容)”,2:颜色号码不为'16777215'(默认白)
当然这一套标准不一定适用于所有剧的字幕,事实上扫一眼数据集基本上也能够直接看出来哪些是字幕,可以直接找到id的
因为镭塔的人名很多,写了一个列表存储。(才发现没写新团人的名字,但是,那又怎样?)
函数搜寻返回疑似字幕组成员id号列表ids:
def search_workers(danmaku_list, names):
# 用于存储每个ID符合条件的弹幕数量
counts = defaultdict(int)
names = ['顾子尧', '夏予扬', '乔殊', '林致', '柏闻', '季少一', '江恪', '许向安', '许向宁']
# 遍历弹幕列表
for danmaku in danmaku_list:
time, user_id, color, content = danmaku
# 判断颜色是否为'16777215',如果是则跳过
if color == '16777215':
continue
# 判断内容格式是否符合“人名:内容”模式
match = re.match(r"([^\x00-\xff]+):(.*)", content)
if match:
person_name = match.group(1)
# 判断人名是否在预设的names列表中
if person_name in names:
counts[user_id] += 1
# 筛选出发送超过10条符合条件弹幕的id
result_ids = [user_id for user_id, count in counts.items() if count > 10]
return result_ids
根据id在弹幕列表中找到所有对应弹幕,并按照时间顺序排序,就可以得到一个完整的台词表了:
def get_lines(danmaku_list, ids):
# 筛选出指定 id 的弹幕
danmakus = [danmaku for danmaku in danmaku_list if danmaku[1] in ids]
# 按时间升序排序
danmakus.sort(key=lambda x: float(x[0])) # 根据时间排序
# 格式化输出时间为 "分-秒" 格式,并提取弹幕内容
result = [(format_time(float(danmaku[0])), danmaku[3],danmaku[2]) for danmaku in danmakus]
return result
def format_time(seconds):
# 计算分钟和秒数
minutes = int(seconds // 60)
seconds = int(seconds % 60)
return f"{minutes:02d}:{seconds:02d}"输出:

dlc(?):根据字幕颜色寻找同一人物的所有台词。
思路是由于部分台词内容有如下特征格式:人名+":"+说话内容,可以匹配得出该人物的台词对应部分弹幕,已知同一人物弹幕颜色相同且唯一,由于人物的台词不一定会带有特征格式,可根据弹幕颜色确定所有台词。
函数实现:
def find_character(result, character_name):
#查找该人物的第一条弹幕,获取其颜色
color = None
first_line = None
for time, line, c in result:
if line.startswith(f"{character_name}:"):
first_line = (time, line, c)
color = c
break
#根据该颜色筛选所有同颜色的弹幕
filtered_lines = [(time, line) for time, line, c in result if c == color]
#格式化输出所有同颜色的弹幕
print(f"查询人物:{character_name}\n")
for time, line in filtered_lines:
print(f"{time} - {line}")
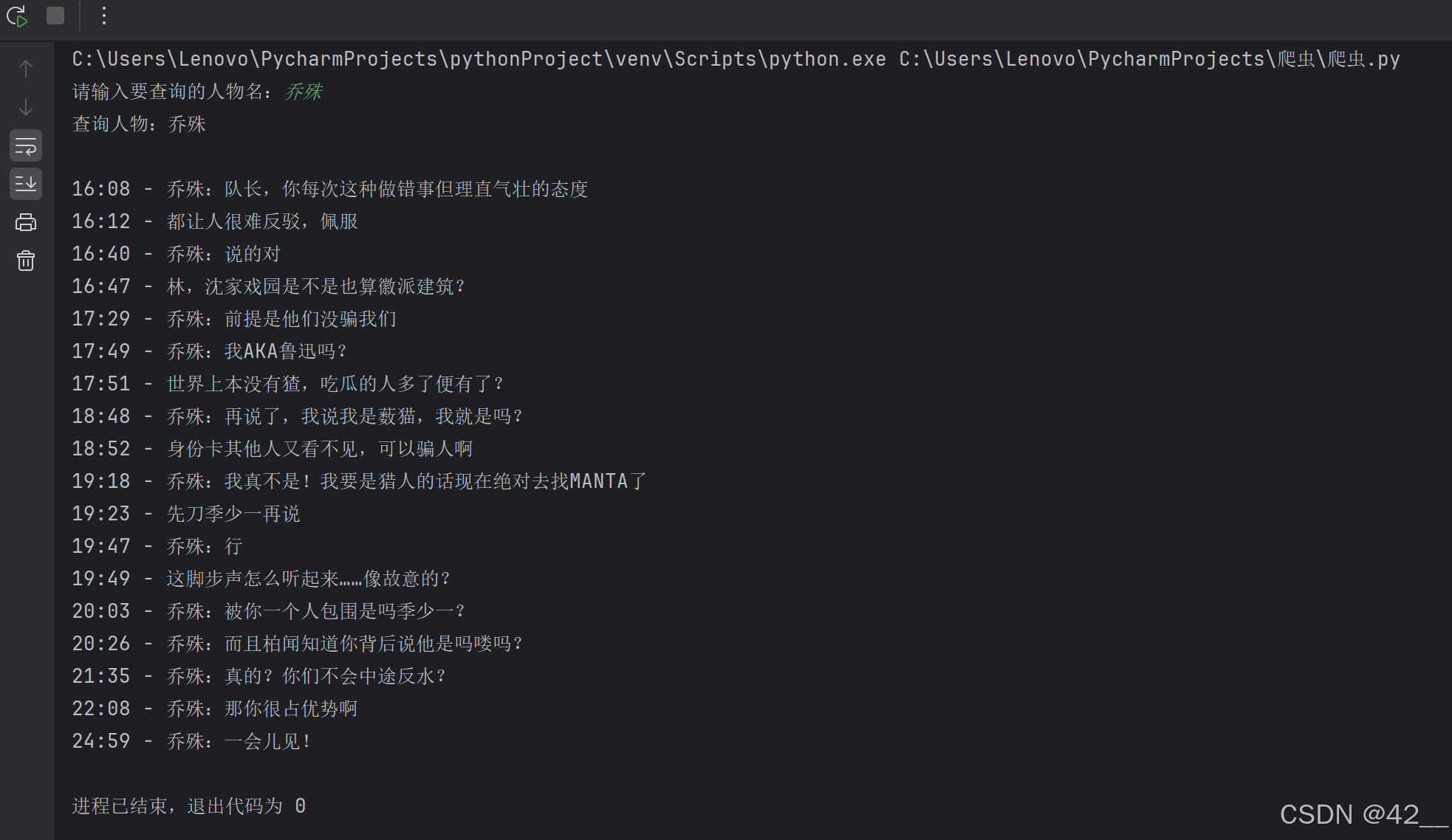
本来有想过既然每条弹幕自带颜色是否可以根据颜色代码在输出时根据对应颜色打印的,可是搜索发现python不能识别hex颜色代码,只好作罢。
完整代码:
import requests
import re
from bs4 import BeautifulSoup
import xml.etree.ElementTree as ET
from collections import defaultdict
from colorama import init, Fore, Back, Style
data = []
contents = []
times = []
colors = []
ids = []
def get_page(url):
# 假设网页地址
page = requests.get(url)
# 获取网页内容
response = requests.get(url)
#print(response.text)
xml_content = response.text
return xml_content
#将弹幕信息存入list
def get_list(xml_content):
# 解析XML
root = ET.fromstring(xml_content)
list1 = [ET.tostring(d, encoding='unicode') for d in root.findall('d')]
# 遍历每个弹幕元素
for danmaku in list1:
# 提取 p 属性中的值
p_value = re.search(r'p="([^"]+)"', danmaku)
if p_value:
# 将 p 属性值按逗号分隔并提取所需的信息
p_parts = p_value.group(1).split(',')
# 获取发送时间、发送id和颜色信息
time = p_parts[0] # 发送时间
times.append(time)
id = p_parts[6] # 发送id
ids.append(id)
color = p_parts[3] # 颜色信息
colors.append(color)
# 提取弹幕内容(标签内的文本部分)
content = re.search(r'>(.*?)</d>', danmaku).group(1)
contents.append(content)
danmaku_list = list(zip(times,ids,colors,contents))
return danmaku_list
def search_workers(danmaku_list):
# 用于存储每个ID符合条件的弹幕数量
counts = defaultdict(int)
names = ['顾子尧', '夏予扬', '乔殊', '林致', '柏闻', '季少一', '江恪', '许向安', '许向宁']
# 遍历弹幕列表
for danmaku in danmaku_list:
time, user_id, color, content = danmaku
# 判断颜色是否为'16777215',如果是则跳过
if color == '16777215':
continue
# 判断内容格式是否符合“人名:内容”模式
match = re.match(r"([^\x00-\xff]+):(.*)", content)
if match:
person_name = match.group(1)
# 判断人名是否在预设的names列表中
if person_name in names:
counts[user_id] += 1
# 筛选出发送超过10条符合条件弹幕的id
result_ids = [user_id for user_id, count in counts.items() if count > 10]
return result_ids
def get_lines(danmaku_list, ids):
# 筛选出指定 id 的弹幕
danmakus = [danmaku for danmaku in danmaku_list if danmaku[1] in ids]
# 按时间升序排序
danmakus.sort(key=lambda x: float(x[0])) # 根据时间排序
# 格式化输出时间为 "分-秒" 格式,并提取弹幕内容
result = [(format_time(float(danmaku[0])), danmaku[3],danmaku[2]) for danmaku in danmakus]
return result
def format_time(seconds):
# 计算分钟和秒数
minutes = int(seconds // 60)
seconds = int(seconds % 60)
return f"{minutes:02d}:{seconds:02d}"
def find_character(result, character_name):
#查找该人物的第一条弹幕,获取其颜色
color = None
first_line = None
for time, line, c in result:
if line.startswith(f"{character_name}:"):
first_line = (time, line, c)
color = c
break
#根据该颜色筛选所有同颜色的弹幕
filtered_lines = [(time, line) for time, line, c in result if c == color]
#格式化输出所有同颜色的弹幕
print(f"查询人物:{character_name}\n")
for time, line in filtered_lines:
print(f"{time} - {line}")
if __name__ == '__main__':
url = "https://www.missevan.com/sound/getdm?soundid=10288890"
xml_content = get_page(url)
danmaku_list = get_list(xml_content)
ids = search_workers(danmaku_list)
result = get_lines(danmaku_list, ids)
for time, content,color in result:
print(f"{time} - {content}")
#character = input("请输入要查询的人物名:")
#find_character(result, character)
好啦,现在你可以一键自动化提取广播剧的字幕啦!虽然写到这里我还在怀疑是否有人需要这个写得稀碎的教程()突然又想到再加一个爬取剧集网址列表的函数就可以输入第n集直接爬了,甚至不用打开网址找id……不过我懒得实现了,有时间可能会修改本文补上这个功能吧。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









