







这一部分主要是关于教师端。
在项目任务书中,关于教师端部分的需求(部分)如下:
智能批改,评阅
OCR识别
多模态输入
多层次批改:错别字识别与纠正,病句/语法错误识别与纠正,标点误用识别与纠正
直接批改并生成评语
- 智能识别 :识别比喻/拟人/排比等常见修辞,同时提供高阶修辞识别(通感、反讽、层递)
- 智能作文训练命题:教师+AI自定义题目,发布后供学生进行针对性场景写作训练。
需要注意的是,教师端与学生端是可交互的,其基本业务流程应该为:
学生进行作文训练->作文交给老师批改->老师可使用上述功能点辅助批改
这一业务流程目前已经基本完成,以下各部分的详细介绍:
一、(模拟考场)作文训练与提交:
首先是ai生成三个可供选择的题目这一功能,使用deepseekAPI生成三个题目并不难,重点在于编辑prompt格式要求并按照相关字段对生成的三个题目进行准确裁取划分:
# 从开始标识之后的内容开始查找题目
content_after_start = full_result[start_index + len("作文题如下:"):]
first_index = content_after_start.find("一、")
second_index = content_after_start.find("二、")
third_index = content_after_start.find("三、")
if first_index == -1 or second_index == -1 or third_index == -1:
raise ValueError("未找到完整的题目标识")
result1 = content_after_start[first_index + len("一、"):second_index].strip()
result2 = content_after_start[second_index + len("二、"):third_index].strip()
result3 = content_after_start[third_index + len("三、"):].strip()
同时模拟考场还需要定时功能。倒计时机制:借助 setInterval 以每秒(1000 毫秒)为间隔来减少剩余时间(this.remainingTime)。终止条件:一旦剩余时间变为 0,就会清除计时器,并且更新状态变量。倒计时结束后将不能再输入,实现如下:
remainingTime: 3600, // 初始化为一小时(单位:秒)
isTimeUp: false,
startCountdown() {
this.countdownInterval = setInterval(() => {
if (this.remainingTime > 0) {
this.remainingTime--;
} else {
clearInterval(this.countdownInterval);
this.isTimeUp = true;
}
}, 1000);
},
formatTime(seconds) {
const minutes = Math.floor(seconds / 60);
const remainingSeconds = seconds % 60;
return
`${String(minutes).padStart(2, '0')}:${String(remainingSeconds).padStart(2, '0')}`;
},
相应地还需要能够提交保存作文,对应的数据库表字段为(record_id,student_id,teacher_id,essay_topic,essay_text),相应的后端方法逻辑较为简单,故不再给出。
前端部分相关界面:
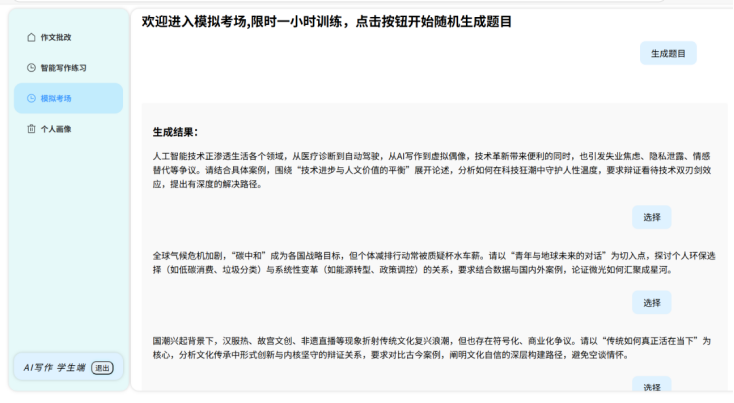
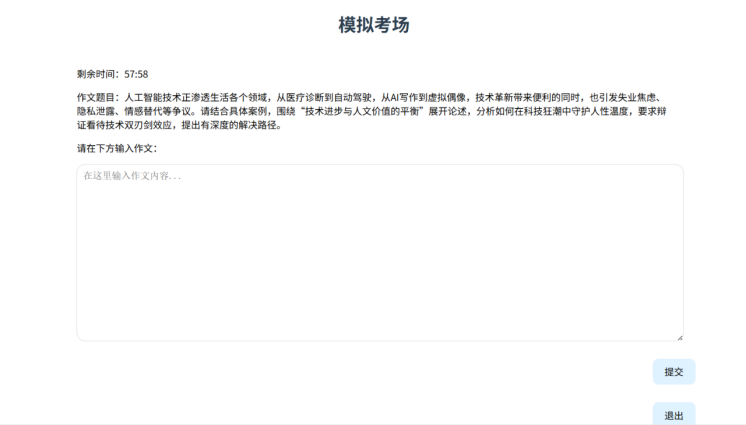

二、 多模态输入:OCR与pdf的上传与识别。
目前python主流的OCR库有三种,我们选择使用使用pytesseract以及tesseract来实现(后端)。
从 GitHub 下载并安装 Tesseract OCR 引擎,在安装是选择中文支持。
调用其方法即可完成识别:
# 使用Tesseract进行OCR识别
img = Image.open(filepath)
img = img.convert('L').point(lambda x: 255 if x > 180 else 0) #这一句是为了提高识别率,也有其他方法。
text = pytesseract.image_to_string(img, lang='chi_sim')
print(text) #测试用
目前测试发现正确率90%左右,所以这是一个可能的后续测试与优化点。
Pdf的识别(后端):使用pdfplumber库即可。
# 提取PDF文本
text = ""
with pdfplumber.open(filepath) as pdf:
for page in pdf.pages:
text += page.extract_text() + "\n"
可以把pdf内容识别为完整的文字。
前端部分:
调用接口:
const response = await axios.post('http://localhost:5000/api/ocr', formData, {
headers: {
'Content-Type': 'multipart/form-data'
}
});
const response = await axios.post('http://localhost:5000/api/pdf', formData, {
headers: {
'Content-Type': 'multipart/form-data'
}
});目前,我们暂定的实现方案为prompt+deepseekAPI来实现。
所以这部分的主要工作为写合适的prompt:
后端Api方法将多层次(三个)批改功能和为一体,前端通过不同的参数即可实现不同的批改类型。
方法大概如下:
@app.route('/api/recognize', methods=['POST'])
def recognize_text():
# 此方法需要传入的参数:
# 1.文本 2.一个int变量function_id
# 文本就是作文,id用于选择不同的功能
# id=1:识别修辞手法
# id=2:识别错别字与标点符号错误,并提供改正建议
# id=3:识别语法错误与病句并提供修改建议
根据不同的_id,我们选择不同的prompt与user_context:
一个例子如下:
elif function_id == 2:
prompt = "你是一位专业的语文老师,你的任务是检查以下作文中的错别字与标点符号误用,并提供详细的改正建议。"
"请注意以下几点:\n"
"1. 识别作文中的书写错误与标点符号的不恰当使用。\n"
"2. 提供每个错误的改正建议。\n"
"3. 在必要时,简要解释错误的原因。\n"
"4. 保持对作文整体内容的理解,确保建议符合语境。"
"5. 无需给出你的思考过程"
user_context = "请帮我检测这篇作文中的错别字与标点符号误用的情况。"
前端部分:
调用接口:
const response = await axios.post('http://localhost:5000/api/recognize', {
text: essayDetails.value.essay_text,
function_id: functionId
});
apiResult.value = response.data.result;相关界面:
(此界面数据通过传入 teacher_id查询数据库essay_rate为null的record记录获得,由于实现逻辑较简单所以不再阐述)
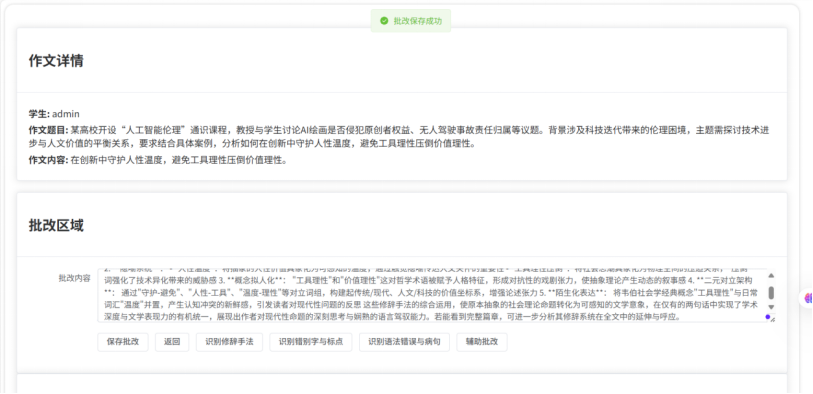
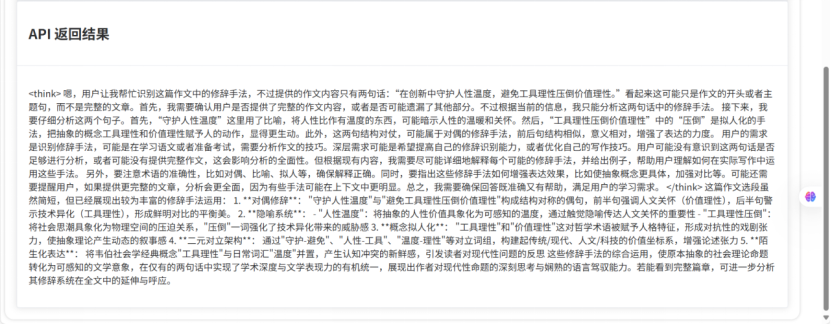 至此,本项目已大致完成任务书中教师端部分,学生->教师的业务链也大致构造完成(还需要完善学生端和教师端对于考试作文以及批改记录的各类筛选查询功能)。
至此,本项目已大致完成任务书中教师端部分,学生->教师的业务链也大致构造完成(还需要完善学生端和教师端对于考试作文以及批改记录的各类筛选查询功能)。
三、 学生端与教师端的互通
设计了 student 和 teacher 数据库表,以实现学生与教师的多对一关系。以下是 student 表的 SQL 设计:
CREATE TABLE `student` (
`student_id` int NOT NULL AUTO_INCREMENT,
`username` varchar(255) NOT NULL,
`password` varchar(255) NOT NULL,
`email` varchar(255) DEFAULT NULL,
`teacher_id` int DEFAULT NULL,
PRIMARY KEY (`student_id`),
KEY `teacher_id` (`teacher_id`),
CONSTRAINT `student_ibfk_1` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`teacher_id`)
);目前的功能逻辑为学生端在注册账号时绑定教师,相关的学生注册接口代码如下:
@auth_bp.route('/register-student', methods=['POST'])
def student_register():
data = request.get_json()
username = data.get('username')
password = data.get('password')
email = data.get('email')
teacher_id = data.get('teacher_id')
if not username or not password:
return jsonify({'status': 'error', 'message': '用户名和密码不能为空'}), 400
try:
cursor = mysql.connection.cursor(MySQLdb.cursors.DictCursor)
# 检查用户名是否已存在
cursor.execute('SELECT student_id FROM student WHERE username = %s', (username,))
existing_account = cursor.fetchone()
if existing_account:
cursor.close()
return jsonify({'status': 'error', 'message': '用户名已存在,请选择其他用户名'}), 409
# 插入新学生信息
cursor.execute(
'INSERT INTO student (username, password, email, teacher_id) VALUES (%s, %s, %s, %s)',
(username, password, email, teacher_id)
)
mysql.connection.commit()
new_student_id = cursor.lastrowid
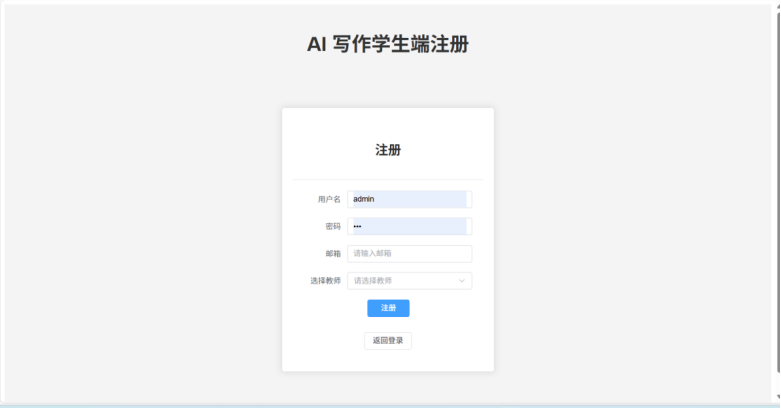
cursor.close()前端界面如下:
设计了 test_record 数据库表用于存储作文相关信息。test_record与teacher、student为多对一关系。test_record 表的 SQL 设计如下:
CREATE TABLE `test_record` (
`record_id` int NOT NULL AUTO_INCREMENT,
`essay_topic` varchar(666) NOT NULL,
`essay_text` longtext NOT NULL,
`essay_rate` longtext,
`teacher_id` int DEFAULT NULL,
`student_id` int DEFAULT NULL,
`rate_time` datetime DEFAULT NULL,
PRIMARY KEY (`record_id`),
KEY `teacher_id` (`teacher_id`),
KEY `student_id` (`student_id`),
CONSTRAINT `test_record_ibfk_1` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`teacher_id`),
CONSTRAINT `test_record_ibfk_2` FOREIGN KEY (`student_id`) REFERENCES `student` (`student_id`)
);目前阶段根据以上数据库表设计以及相关的查询逻辑实现教师端与学生端的互通。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









