










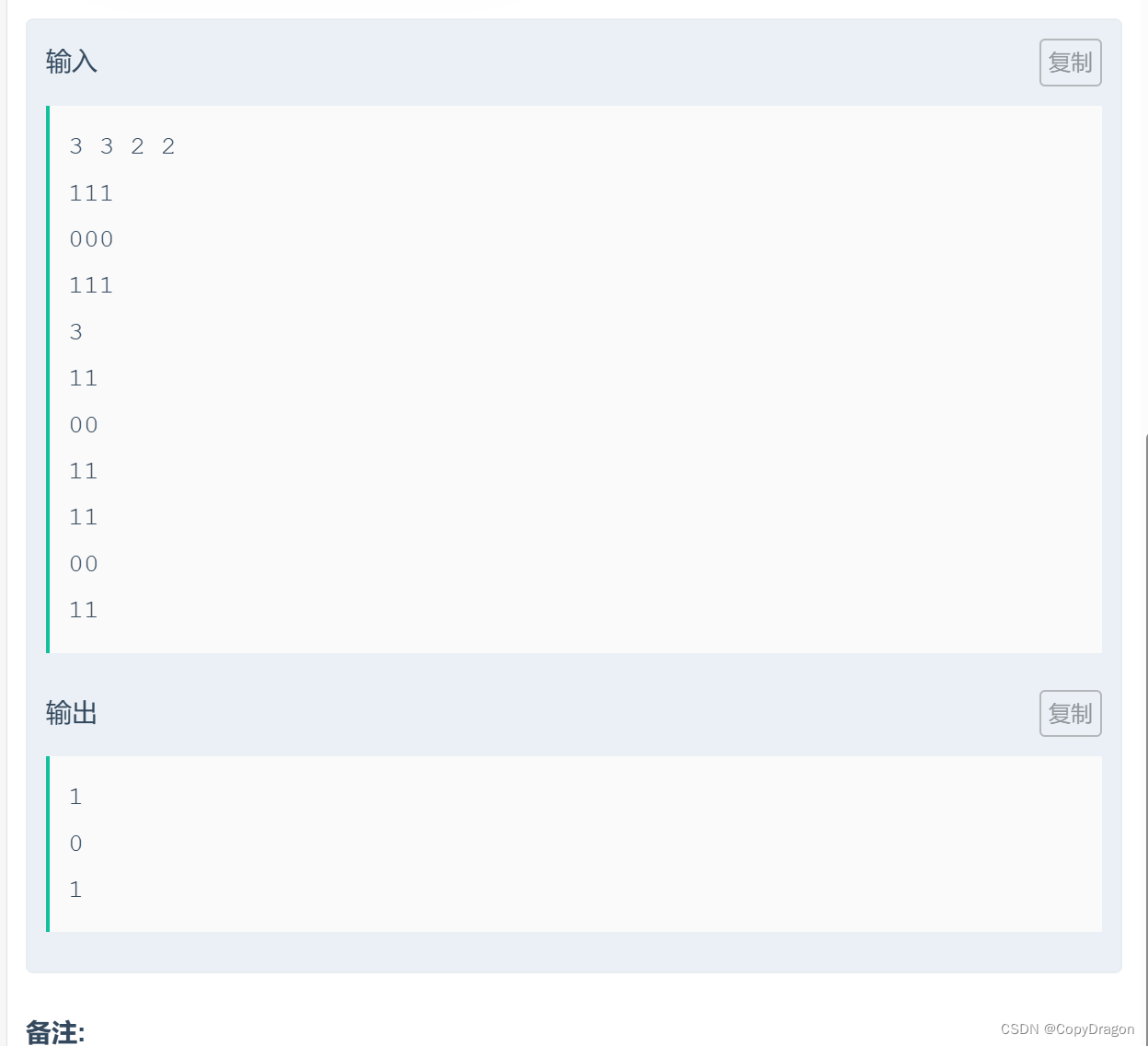
二维Hash的板子题,我们先对每行的前缀维护一下Hash值,最对每列维护每行前缀的前缀值
void get_hash(int n,int m,int type)
{
for (int i=1; i<=n; i++)
for (int j=1; j<=m; j++)
if (type) hashs[i][j]=hashs[i][j-1]*base1+s[i][j];
else sub_hash[i][j]=sub_hash[i][j-1]*base1+s[i][j];
for (int j=1; j<=m; j++)
for (int i=1; i<=n; i++)
if (type) hashs[i][j]=hashs[i-1][j]*base2+hashs[i][j];
else sub_hash[i][j]=sub_hash[i-1][j]*base2+sub_hash[i][j];
}为什么可以分别计算行和列的前缀和?
-
行哈希计算:首先,对于每一行,我们计算从第一个字符到当前字符的前缀和(使用
base1作为基数)。这相当于将每一行看作一个独立的字符串,并计算其哈希值。这样,hashs[i][j]就存储了从第i行第1个字符到第i行第j个字符的哈希值。 -
列哈希计算:接着,我们利用已经计算好的行哈希值,进一步计算跨越多行的列哈希值。对于每一列,我们将每一行的哈希值作为新的“字符”,并使用
base2作为基数来计算列的前缀和。这样,hashs[i][j]就存储了从第1行第j个字符到第i行第j个字符的哈希值(跨越了所有行)。
为什么直接通过矩阵的前缀和计算得到的答案是有问题的?
如果我们尝试直接计算整个矩阵的前缀和来作为哈希值,那么我们实际上是将矩阵看作一个长字符串,并且没有区分行和列的信息。这样的哈希值无法反映出矩阵中字符的二维排列,因此无法准确地表示子矩阵的哈希值。
具体来说,如果我们直接计算矩阵的前缀和,那么对于任意子矩阵,我们无法简单地通过前缀和运算来得到它的哈希值,因为子矩阵的哈希值需要同时考虑行和列的信息。
通过分别计算行和列的前缀和,我们可以将二维矩阵的哈希值分解为一维字符串的哈希值的组合。这种方法保留了字符在矩阵中的二维排列信息,使得我们可以高效地计算任意子矩阵的哈希值,并通过比较哈希值来判断子矩阵是否出现在原始矩阵中。直接计算整个矩阵的前缀和则无法达到这个目的。
使用pw1[b]和pw2[a]的原因如下:
-
列哈希的“右移”:对于每一行的哈希值,我们需要使用
pw1[b]来确保当我们将哈希值累加到hashs[i][j]时,之前行的哈希值不会与当前行的哈希值重叠。通过将之前行的哈希值乘以base1的b次幂,我们可以将它们“右移”到足够远的位置,以便新的字符哈希值可以安全地加到它们后面。 -
行哈希的“下移”:对于每一列的哈希值,我们使用
pw2[a]来确保当我们计算跨越多行的列哈希值时,之前列的哈希值不会与当前列的哈希值重叠。通过将之前列的哈希值乘以base2的a次幂,我们可以将它们“下移”到足够低的位置,以便新的行哈希值可以安全地加到它们下面。
通过结合使用这两个幂,我们能够确保在构建最终的哈希值时,每个部分都被放置在了正确的位置,从而正确地反映了子矩阵中字符的二维排列。
这里是一个简化的例子来说明这个概念:
假设我们有一个2x2的子矩阵,我们想要计算它的哈希值。我们首先将每一行看作一个独立的字符串,并计算它们的哈希值。然后,我们将这些行哈希值看作“字符”,并使用base2来计算列哈希值。
如果我们不使用幂来移动哈希值,那么行哈希值会直接相加,导致它们重叠在一起,无法区分出原始的二维结构。通过使用pw1[b]和pw2[a],我们确保每个哈希值都被放置在了它应该在的位置,从而保留了原始矩阵的结构信息。
这种方法的关键在于哈希函数的线性性质,它允许我们将复杂的结构(如二维矩阵)分解为简单的部分(如行和列),并单独计算它们的哈希值,最后再通过加法运算组合起来。
将模板矩阵的每个A行B列的子矩阵的Hash值算出来,这里有点类似于前缀和的:
for (int i=a; i<=n; i++)
for (int j=b; j<=m; j++) {
ull sb=hashs[i][j]-hashs[i-a][j]*pw2[a]-hashs[i][j-b]*pw1[b]+hashs[i-a][j-b]*pw2[a]*pw1[b];
mos[++cnt]=sb;
}
AC:
#include <bits/stdc++.h>
using namespace std;
const int mac=1e3+10;
const int base1=131,base2=137;
typedef unsigned long long ull;
char s[mac][mac];
ull hashs[mac][mac],mos[mac*mac],sub_hash[120][mac];
ull pw1[mac],pw2[mac];
void get_hash(int n,int m,int type)
{
for (int i=1; i<=n; i++)
for (int j=1; j<=m; j++)
if (type) hashs[i][j]=hashs[i][j-1]*base1+s[i][j];
else sub_hash[i][j]=sub_hash[i][j-1]*base1+s[i][j];
for (int j=1; j<=m; j++)
for (int i=1; i<=n; i++)
if (type) hashs[i][j]=hashs[i-1][j]*base2+hashs[i][j];
else sub_hash[i][j]=sub_hash[i-1][j]*base2+sub_hash[i][j];
}
int main()
{
int n,m,a,b;
scanf ("%d%d%d%d",&n,&m,&a,&b);
for (int i=1; i<=n; i++)
scanf ("%s",s[i]+1);
get_hash(n,m,1);
int cnt=0;
pw1[0]=pw2[0]=1;
for (int i=1; i<=max(n,m); i++) pw1[i]=pw1[i-1]*base1,pw2[i]=pw2[i-1]*base2;
for (int i=a; i<=n; i++){
for (int j=b; j<=m; j++){
ull sb=hashs[i][j]-hashs[i-a][j]*pw2[a]-hashs[i][j-b]*pw1[b]+hashs[i-a][j-b]*pw2[a]*pw1[b];
mos[++cnt]=sb;
}
}
sort(mos+1,mos+cnt+1);
int q;
scanf ("%d",&q);
while (q--){
for (int i=1; i<=a; i++)
scanf ("%s",s[i]+1);
get_hash(a,b,0);
int flag=0;
int pos=lower_bound(mos+1,mos+1+cnt,sub_hash[a][b])-mos-1;
if (pos<cnt && mos[pos+1]==sub_hash[a][b]) flag=1;
if (flag) printf("1\n");
else printf("0\n");
}
return 0;
}
#include<iostream>
#include<cstdio>
#include<unordered_set>
#include<vector>
using namespace std;
const int N=1010,M=110,P=131;
typedef unsigned long long ULL;
vector<ULL> que;
ULL h[N][N],p[M*N];
char st[N],op[N];
unordered_set<ULL> s;
ULL has(ULL h[],int l,int r)
{
return h[r]-h[l-1]*p[r-l+1];
}
int main(void)
{
int n,m,a,b;
scanf("%d%d%d%d",&n,&m,&a,&b);
p[0]=1;
for(int i=1;i<=M*N;i++)
{
p[i]=p[i-1]*P;
}
for(int i=1;i<=n;i++)
{
scanf("%s",st+1);
//cin>>st+1;
for(int j=1;j<=m;j++)
{
h[i][j]=h[i][j-1]*P+st[j]-'0';
}
}
int q;
scanf("%d",&q);
while(q--)
{
ULL ans=0;
for(int i=1;i<=a;i++)
{
scanf("%s",op+1);
for(int j=1;j<=b;j++)
{
ans=ans*P+op[j]-'0';
}
}
s.insert(ans);
que.push_back(ans);
}
for(int i=b;i<=m;i++)
{
int l=i-b+1,r=i;
ULL res=0;
for(int j=1;j<=n;j++)
{
res=res*p[b]+has(h[j],l,r);
if(j>a)
res-=has(h[j-a],l,r)*p[a*b];
if(j>=a)
s.erase(res);
}
}
for(int i=0;i<que.size();i++)
{
if(s.count(que[i]))
printf("0\n");
else
printf("1\n");
}
return 0;
}-
预处理和变量定义:
- 定义了一些常量
N,M,P以及类型别名ULL(无符号长长整型)。 - 定义了一些全局变量,如
que(存储查询的数字串),h(哈希值数组),p(幂次数组用于哈希计算),st(存储输入字符串的数组)等。 - 定义了一个函数
has用于计算哈希值。
- 定义了一些常量
-
输入处理:
- 输入
n,m,a,b分别表示矩阵的行数、每行字符串的长度、需要出现的子串的个数和子串的长度。 - 计算幂次数组
p,用于哈希计算。 - 读取
n个长度为m的字符串,并计算它们的哈希值。
- 输入
-
查询处理:
- 输入查询的个数
q。 - 对于每个查询,读取一个长度为
b的数字串,计算其哈希值,并将其加入s(一个无序集合)和que(一个向量)中。
- 输入查询的个数
-
查找子串:
- 遍历每一列(即每个长度为
m的字符串),并计算其哈希值。 - 使用滑动窗口(大小为
b)在矩阵的每一行中查找子串,并计算当前窗口内所有行的哈希值的组合。 - 如果当前窗口内的组合哈希值已经在
s中(意味着这个子串已经在之前的a个字符串中出现过),则从s中删除它。
- 遍历每一列(即每个长度为
-
输出结果:
- 遍历
que中的每个查询,如果它仍在s中,输出0(表示该子串没有作为子串出现在至少a个长度为m的字符串中),否则输出1。
- 遍历















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









