







1.4.1数的表示
计算机中所有的信息都是由二进制表示,通常情况一个数分为有符号和无符号两种类型。
一个数当做无符号数时,正常处理即可;一个数当作有符号数时,最高位作为符号位,符号位为0,表示为正数,但是符号位为0时,其余位也都为0,表示的是十进制0。0既不是正数也不是负数,所以符号位为0时,既表示十进制正数也表示0。符号位为1,表示为负数。这里符号位为1,其余位都为0,十进制表示为-0,为了避免重复0,所以这里不是0,而是规定为,这也是表示负数的最小值。比如1000,这是4位有符号的二进制数,表示为-8,而1111,表示为-7。
如果是n位无符号二进制数,它能够表示的十进制数的范围是,如果是n位有符号二进制数,它能够表示的十进制数的范围是
。
现在,我们进行公式推导,n位无符号数,用“乘权求和法”将n位无符号数转换为十进制数,其最大值每位都为1,也就是,这个数列是一个等比数列,公比为2。等比数列的求和公式为:
,其中,
是数列的前 n 项和,
是首项,
是公比。在这个数列中,首项
,公比
。将这些值代入公式,可以得到:
,简化后得到:
,所以从2的0次方一直加到2的n次方的和:
,也就是
。所以n位无符号二进制数,其范围为
。
n位有符号的二进制位,符号位为0,表示该数为正数,其最大值每位都为1,比n位无符号的二进制位少了一位,所以是;符号位为1,则表示该数为负数。负数的最小值是除去符号位,其余都为0的时候,比如1000,表示为-8。100,表示为-4。10表示为-2。因此最小值是
。正数的表示范围为0到
,负数的表示范围为-1到
。二者表示范围长度是一样的。所以n位有符号二进制数其范围为
。
1.4.2原码、反码和补码
我们人脑可以很轻松的知道二进制数的第一位是符号位,但对于电路设计来说判别第一位是符号位是非常难和复杂的事情,为了让计算机底层设计更加简单,人们开始探索将符号位参与运算,并且采用只保留加法的方法。这样计算机内部只需要使用加法器电路即可完成加法和减法的运算,大大简化了电路。所以原码、反码和补码就被创造出来了。
正数的原码是其绝对值转换成二进制位然后在高位补0的数,其反码、补码与原码相同。
负数的原码是其绝对值转换成二进制位然后在高位补1的数;反码是将原码的符号位除外,其余位取反,1变为0,0变为1;补码是其反码的最低位加1。
现在进行二进制加减法运算,只需要将其转换为补码并相加,得出的结果再转换为原码即可,这样就不会出现减法,全部都是加法,大大简化了电路。
比如,4-3,转换为-3+4,这样都变为有符号的数了,然后+4转换为有符号的二进制数,-3转换为有符号的二进制数,然后两个的原码全部转换为补码相加,得出的结果为补码,再将补码转换为原码。
4+3,转换为+4+(+3),还是和上面一样的流程。
1.4.3信息编码
在将信息(如文字、图片、声音等)以数据的形式保存到计算机或其他存储介质中时,通常需要将这些信息转换成特定的编码格式。编码是一种将信息转换成计算机可以理解和处理的数字或字符序列的方法。
下面介绍文字以数据形式保存到计算机时的西文字符编码、中文字符编码和Unicode字符集编码。
1.西文字符编码
西文字符编码是将西文字符(如英文字母、数字、各种符号)进行编码。对西文字符最常用的是ASCII字符编码,其采用的是7位二进制编码,可表示即128个字符。具体编码的128个字符见ASCII码字符集。
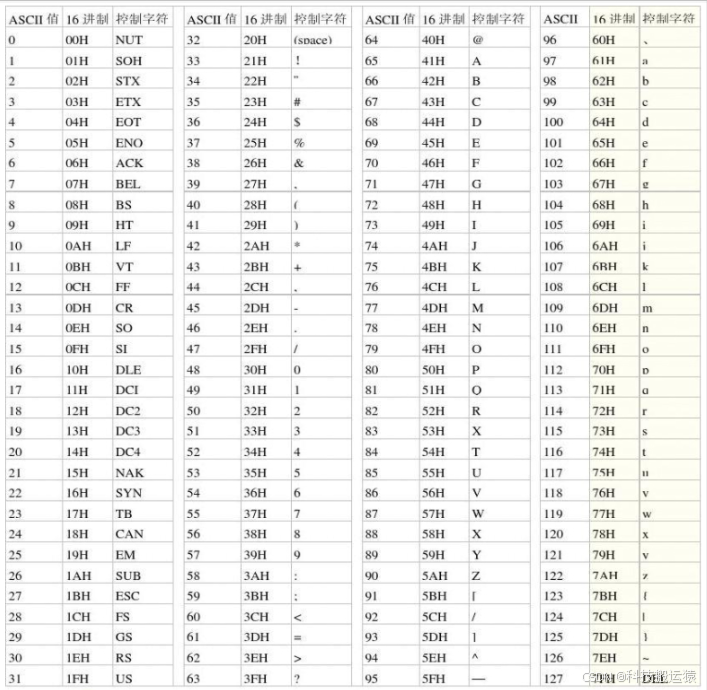
这里对7个二进制位为什么可以表示128种情况进行推导,一位二进制可以表示2种情况,两位二进制可以表示2×2=4种情况,三位二进制可以表示2×2×2=8种情况,这属于数学的知识,最终是。
西文字符除了最常用的ASCII编码外,还有另一种EBCDIC字符编码,这种字符编码主要用在大型机器中。其采用的是8位二进制编码,可以表示即256种西文字符。
一个字符在计算机内实际是用8位二进制数表示的,正常情况下,用ASCII编码后,其最高位为0。在需要奇偶校验时,这一位可用于存放奇偶校验的值,此时称这一位为校验位。所以ASCII字符编码内置有奇偶校验,而EBCDIC字符编码内置没有奇偶校验。
2.中文字符编码
计算机最初的设计主要是为了处理英文文本,所以西文字符编码不需要繁琐的操作。其输入,存储、处理和输出全部都为一个编码即可。
但后来计算机在处理中文字符时,由于中文字符集大,比西文字符编码复杂,并且还不能和西文字符编码重复,其输入、存储、处理和输出中使用的中文字符编码各不同,它们之间要进行相互转换,过程如图所示。 中文字符编码又叫汉字编码。
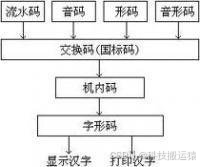
输入码解决了人机交互的问题,国标码保证了计算机内部及网络环境下的数据一致性。机内码负责中文字符在计算机内部的存储和处理,而字形码则关注中文字符的外观呈现。
(1)输入码
输入码是利用键盘输入汉字时对汉字的编码。目前常用的输入码主要分为以下两类:
①音码类。主要以汉字拼音为基础的编码方案,如全拼码。
②形码类。根据汉字字形进行编码,如五笔字型输入法。
当然还有根据音形结合的编码,如自然码等。无论哪种输入法,都是操作者向计算机输入中文的手段。
(2)国标码和区位码
国家标准中文编码(GB2312一80),是中文信息处理的国家标准,也称交换码,简称GB码。国标码中每个汉字用两个字节表示,每个字节最高位为0。国标码把最常用的6763个汉字和682个图形符号进行了编码。
根据国标码编码规定,所有国标中文和符号组成一个94×94的矩阵,每一行称为一个“区”,每一列称为一个“位”,即94个区和94个位,由区号和位号共同构成区位码,将每个区和每个位分别加上20H,就构成了国标码。
区位码的区号和位号范围都是01到94,如果直接将区位码转换为十六进制,区号01到94对应的十六进制是01到5E,位号01到94对应的十六进制是01到5E。这样的编码范围与ASCII码的高位部分有重叠。为了确保GB2312编码的中文不会与ASCII码冲突,并使得汉字编码更加有序,GB2312标准规定将区位码的区号和位号分别加上20H(即32十进制)。这样,区号十六进制01到5E加上20H后变为21到7E,位号十六进制01到5E加上20H后也变为21到7E。这样转换后的国标码范围是A1A1到FEFE(十六进制),完全避开了ASCII码的编码范围。因此,区号和位号各加上20H是为了在编码空间中为中文分配一个不与ASCII码冲突的独立区域,并确保每个汉字都有一个唯一的编码。这就是为什么区位码出来之后,还需要有一个国标码了,就是避免重复,所以在区位码的基础上创造了国标码。
例如,“大”位于第20区83位,其区位码为2083,十六进制区位码表示为1453H,这里是将十进制20转换为了十六进制14,十进制83转换了十六进制53。国标码表示为3473H,这里是14+20,53+20。区位码是一个二维的编码系统,而直接转换成十六进制会将其压缩成一个一维的编码,区位码转换为国标码,也需要对两个维度进行分别处理。
(3)机内码
机内码是指汉字被计算机系统内部处理和存储而使用的编码。一个汉字国标码占两个字节,每个字节最高位为“0”;西文字符的机内代码是7位ASCII码,最高位也为“0”,这样就给计算机内部处理带来困难。
为了区分计算机内部中文编码和ASCII码,将国标的每个字节的最高位由“0”变成“1”,一个字节为8位,最高位由“0”变成1,也就是二进制加1000_0000,即十六进制相加就是80H,国标码有两个字节,即每个字节加80H。如“大”的国标码为3473H,机内码即为B4F3H。
(4)字形码
字形码又称为汉字字模,用于汉字显示输出和打印输出。汉字字形码通常有两种表示方式:点阵和矢量。
用点阵表示字形时,汉字字形指的是这个汉字字形点阵的代码。简易型汉字为16×16点阵,提高型汉字为24×24点阵、32×32点阵等。点阵字模越大,字形越清晰美观,所占存储空间也越大。如一个16×16的点阵字模占32字节,一个32×32的点阵字模占128字节。具体计算可以采用公式:
点阵字模所占字节数=点阵行数×点阵列数÷8
矢量表示方式存储的是描述汉字字形的轮廓特征,当要输出汉字时,通过计算机的计算,由汉字字形描述生成所需大小和形状的汉字。矢量化字形描述与最终汉字显示的大小、分辨率无关,可产生高质量的输出。
3.Unicode字符集编码
Unicode是一个国际编码标准,它为每种语言中的每个字符(包括西文字符和中文字符)设定了唯一的二进制编码,便于统一地表示世界上的主要文字,以满足跨语言、跨平台进行文本转换和处理的要求。这里比较复杂,目前不需要过多了解。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









