







数据清洗的目的与重要性
在AI辅助学习APP的开发中,数据清洗(Data Cleaning) 是数据预处理的核心环节,其目的是提升数据质量,确保模型训练的准确性和可靠性。
1. 数据清洗的目的
去除噪声:删除或修正错误、重复、不完整的数据(如缺失值、异常值)。
标准化格式:统一数据格式(如日期、单位、编码),便于后续处理。
纠正偏差:修正标注错误或逻辑矛盾(如“小学生”年龄为30岁的异常记录)。
增强一致性:确保同类数据表达一致(如“数学”和“数学科”应统一为“数学”)。
提高可用性:使数据符合模型输入要求(如文本分词、图像尺寸归一化)。
2. 为什么数据经过爬取后需要清洗?
爬取的数据通常存在以下问题:
脏数据:网页中的广告、无关内容、HTML标签混入文本。
缺失值:部分字段为空(如学生答题记录缺少“用时”字段)。
格式混乱:日期可能是“2023/01/01”或“01-Jan-2023”。
重复数据:同一题目被不同网页重复收录。
逻辑错误:如“答对次数”大于“总答题次数”。
如果不清洗,直接使用原始数据会导致:
模型性能下降
噪声数据干扰模型学习,降低准确率(如错误标签导致AI推荐错误知识点)。
泛化能力变差
不一致的数据(如“math”和“数学”混用)会让模型难以识别同类实体。
计算资源浪费
重复数据增加训练时间,但无助于模型优化。
业务逻辑错误
未处理的缺失值可能导致统计错误(如平均答题时间计算失真)。
伦理与合规风险
未脱敏的个人信息(如学生姓名)可能违反隐私法规(如GDPR)。
3. 典型场景示例
题目数据清洗:
问题:爬取的数学题含无关字符(如“【答案】选A”)。
清洗:去除广告文本,提取纯题目和选项。
行为日志清洗:
问题:用户答题记录中有重复提交(同一题记录多次)。
清洗:去重并保留最后一次有效记录。
文本问答清洗:
问题:师生问答数据含错别字(如“如何解方程?”→“如何解方成?”)。
清洗:拼写纠正或使用NLP工具标准化。
4. 清洗方法(技术层面)
结构化数据:用Pandas处理缺失值(fillna())、去重(drop_duplicates())。
文本数据:正则表达式去噪、NLP工具(如NLTK)分词纠错。
自动化工具:OpenRefine、Trifacta等可视化清洗工具。
我们已经完成了基础爬虫功能的编写,接下来要将爬取的数据以.xlsx的形式导出:
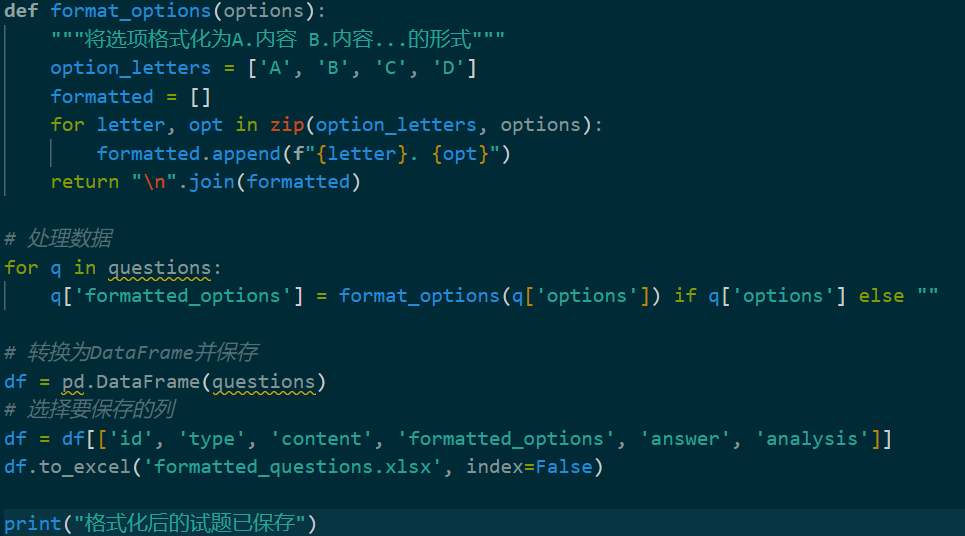
接下来便可进行数据的爬取工作,对中国组卷网语文部分学科的试题进行爬取并导出保存,结果如下:

但数据整体杂乱且重复度高,不便于直接用于训练ai,故需要进行数据清洗和规范:
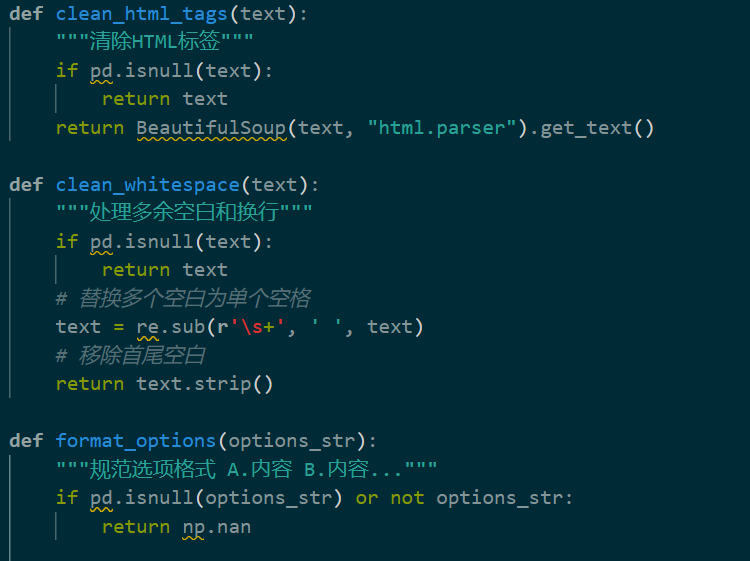
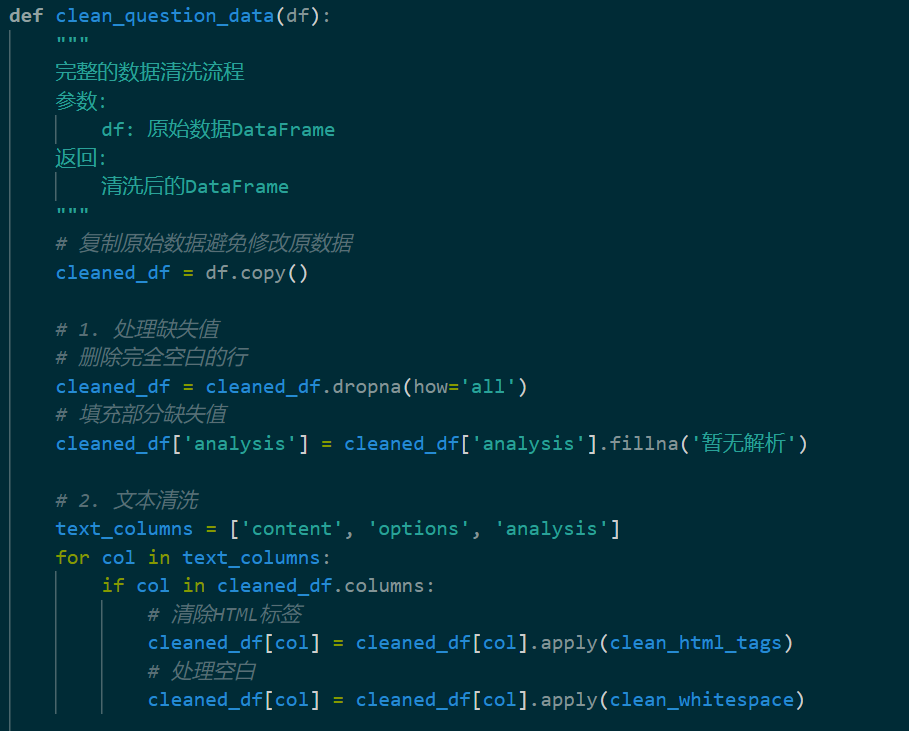
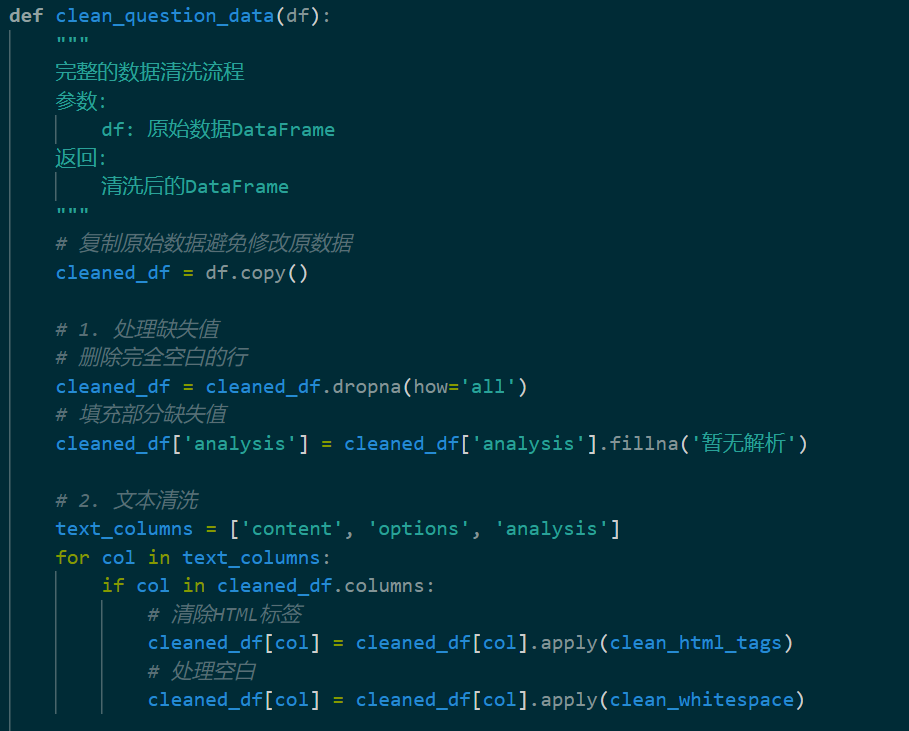
通过数据的清洗和规范以及人工检查后,导出的数据如下:

更加清晰,便于使用和查看,通过过反复爬取后得到了一至六年级的语文习题数据集(10w+题),经人工整理和检查筛选后,数据集大致如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









