






如何定位慢查询?


方案2默认是不会打开的,我们需要自己去配置文件中打开
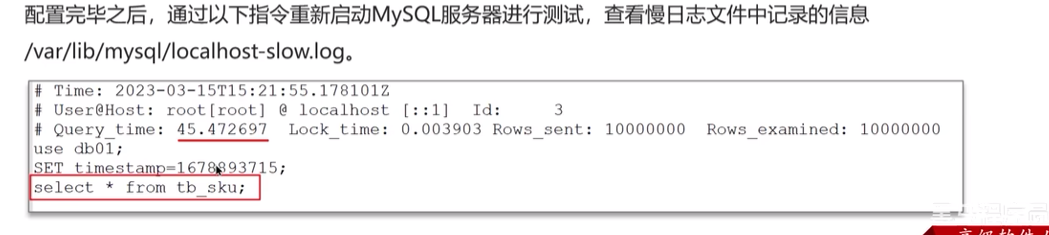
如何分析慢查询






如何优化慢查询
索引
定义:


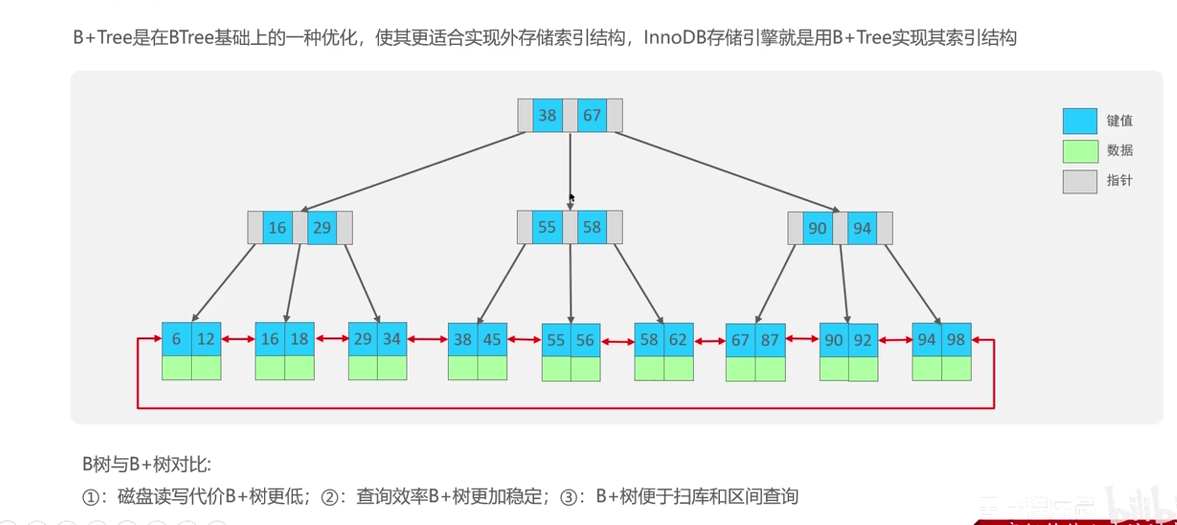
特点:非叶子节点只存指针,只有在叶子节点存取数据,磁盘读写B+树代价低
叶子节点是双向链表,便于扫库和区间查询
阶数更多,路径更短
聚集索引与二级索引


、
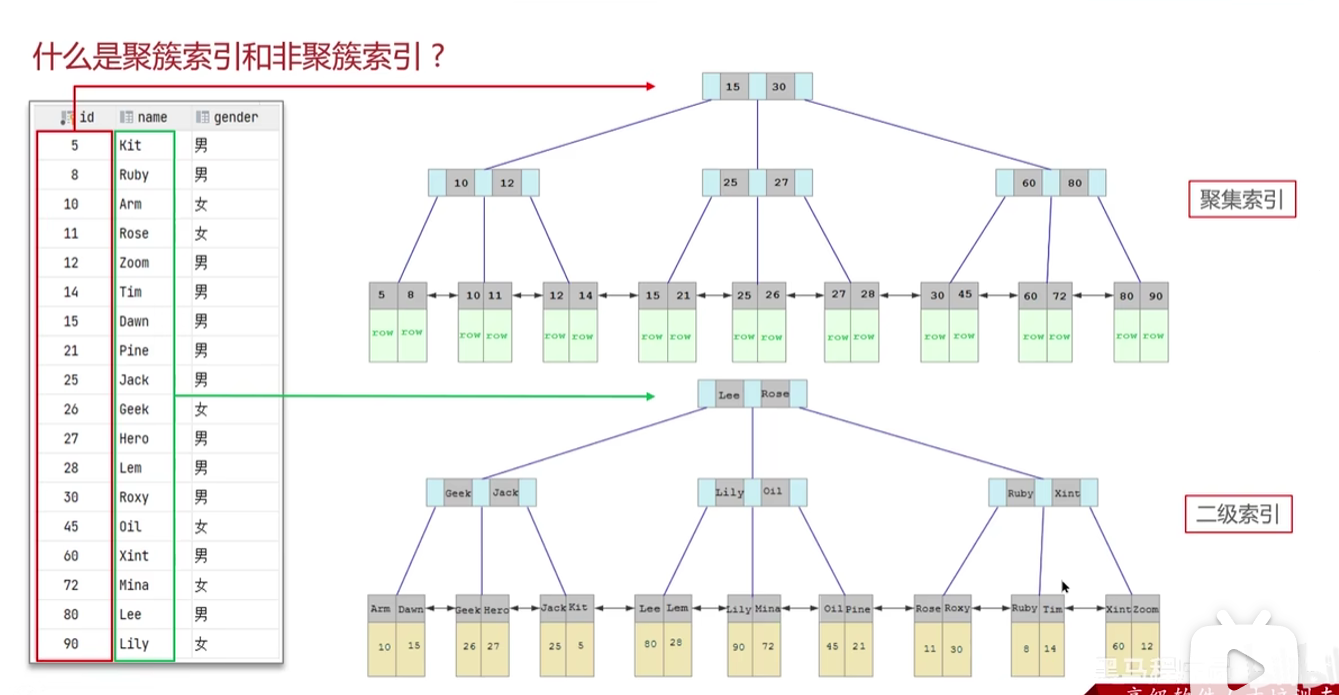
回表查询

参考上图,使用该sql语句查询时,因为我们已经把name设置为二级索引,该查询语句会先走二级索引查询比对,最终获得Arm的主键值为10,然后再根据主键值10走聚簇索引查询最终查到索引为10的所有数据,像这种先查二级索引,然后再查聚集索引查出数据的方式就是回表查询
覆盖索引

以下三个哪个是覆盖索引:
select * from tb user where id =1
select id, name from tb user where name = 'Arm'
select id, name, gender from tb user where name = 'Arm'
回答:
1是,id是主键查询是直接走聚集索引,可以查出所有的数据
2是,name是二级索引,'Arm'查询走二级索引,二级索引可以查出id,再加上'Arm'本身就可以添加到索引中,所有可以可以全部查到name和id
3不是,‘Arm’查询走二级索引可以查出id,再加上自己本身可以查出name,但是无法查出gender,查询出gender需要回表查询,因为二级索引的叶子节点包含的数据只有主键值
面试解答:


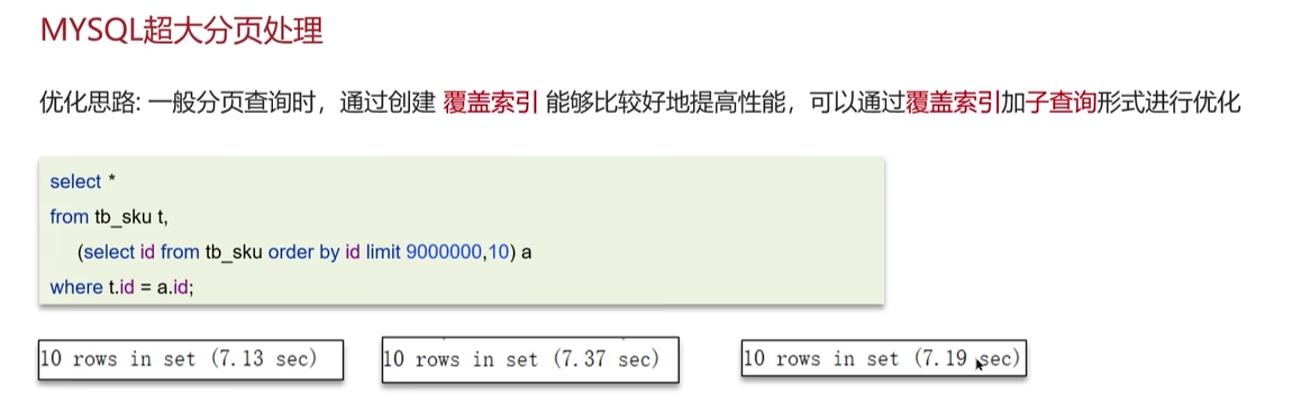
图解:先通过id排序和返回id走的是覆盖索引可以在索引中直接找到,效率很高,然后再跟之前的表做关联做一个等价查询
索引创建原则

索引失效

sql的优化



事务
定义:

事务特性:ACID

MySQL并发事务带来的问题:
![]()

解决方案:对事务进行隔离
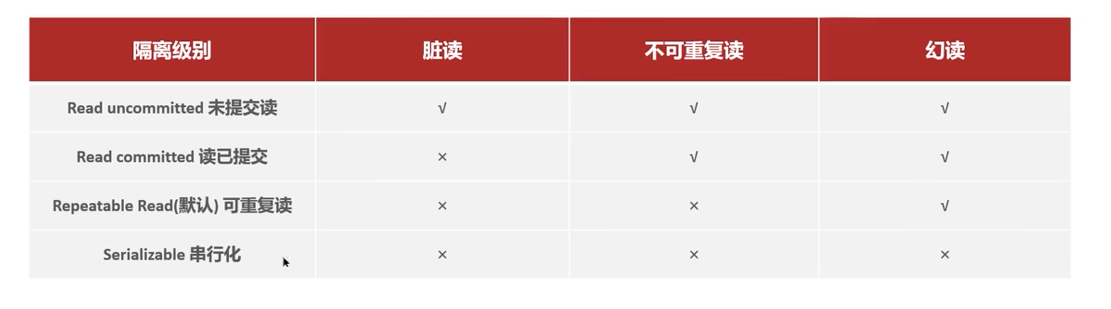
√代表不能解决,×代表可以解决
undo log和redo log的区别
redo log


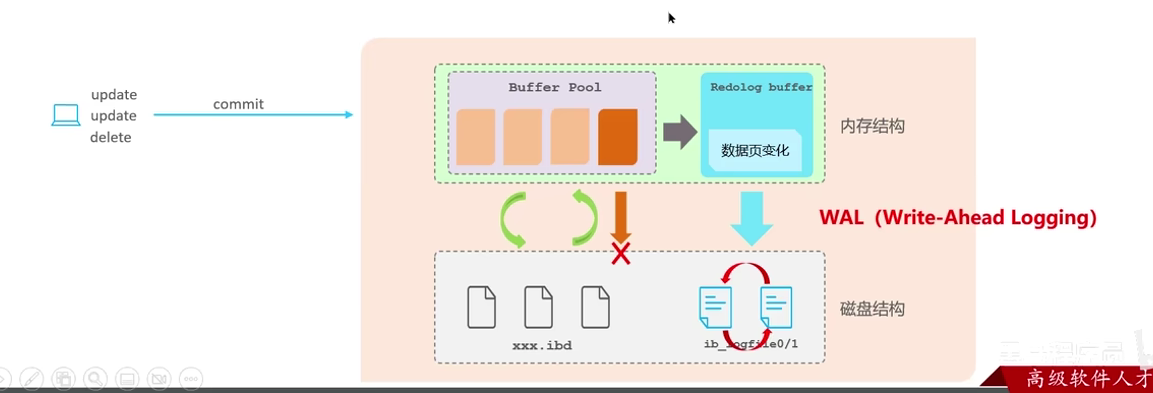
图解:mysql中分为内存结构和磁盘结构,磁盘结构中存在着数据页,而数据页中存储的是行数据,而事务中可能会有很多的update和delete操作事务提交后不会直接操作磁盘结构而是先操作内存结构,若发现操作的数据在内存的缓冲区没有,磁盘会把数据页提交到内存缓冲池中,操作完成后会以一定的频率刷新到磁盘从而减少磁盘IO。但是当内存还没来得及刷新服务器宕机,会导致内存数据丢失,这样违背事务的持久化特性,于是引入redo log,在更新事若缓冲池变化会同步的发送到重做日志缓冲中然后同步的写入磁盘文件的重做日志,当刷新磁盘失败时,磁盘就会根据重做日志文件恢复数据,若刷新磁盘成功磁盘则会把重做日志文件删除。
为什么不直接进行同步?
可以但是有严重的性能问题,直接同步更新时采用的是随机Io, 随机Io是说修改数据页,因为数据页在磁盘位置不是固定的,而通过redo log同步是顺序io 操作,顺序io是说写入redo log是顺序的写入,只要把日志写入到最后一行就可以了
undo log


区别:

事务中隔离性如何保证:
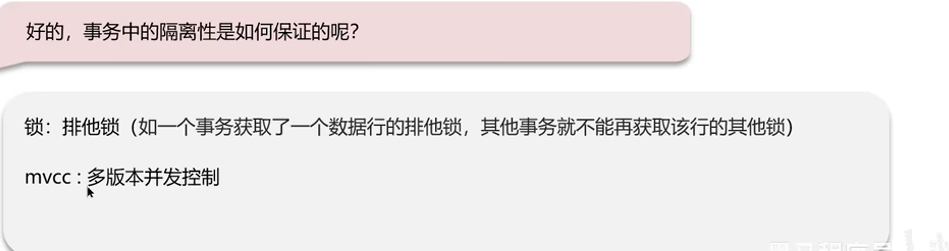
MVCC
定义:
![]()
![]()
隐式字段

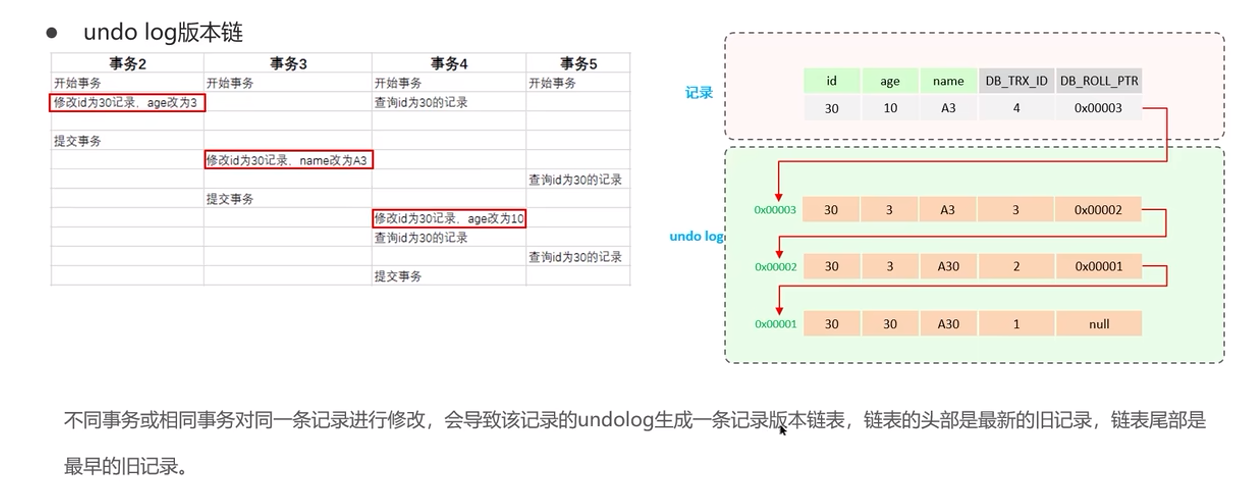
undo log

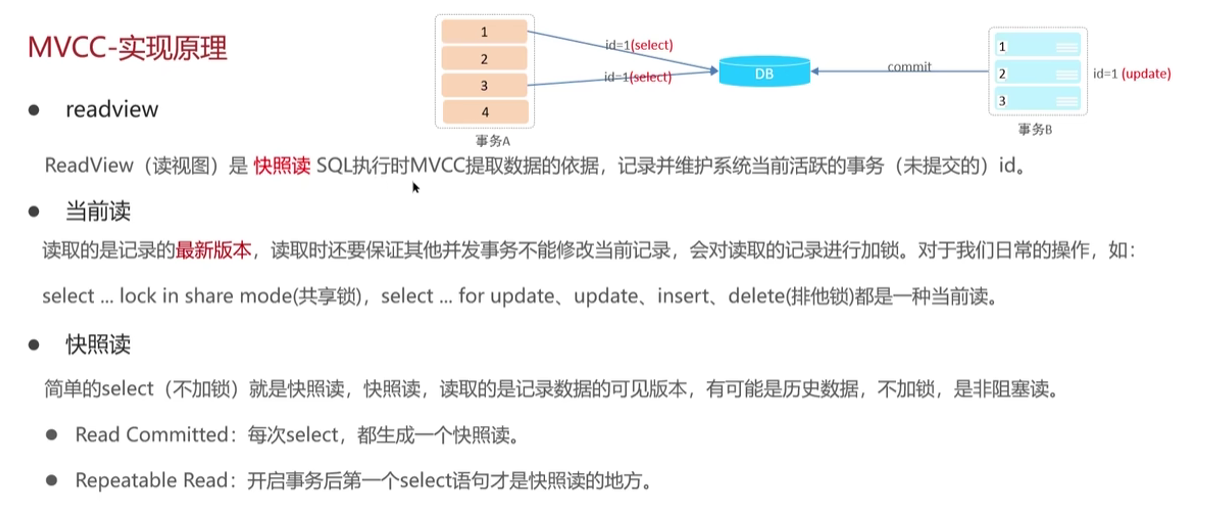
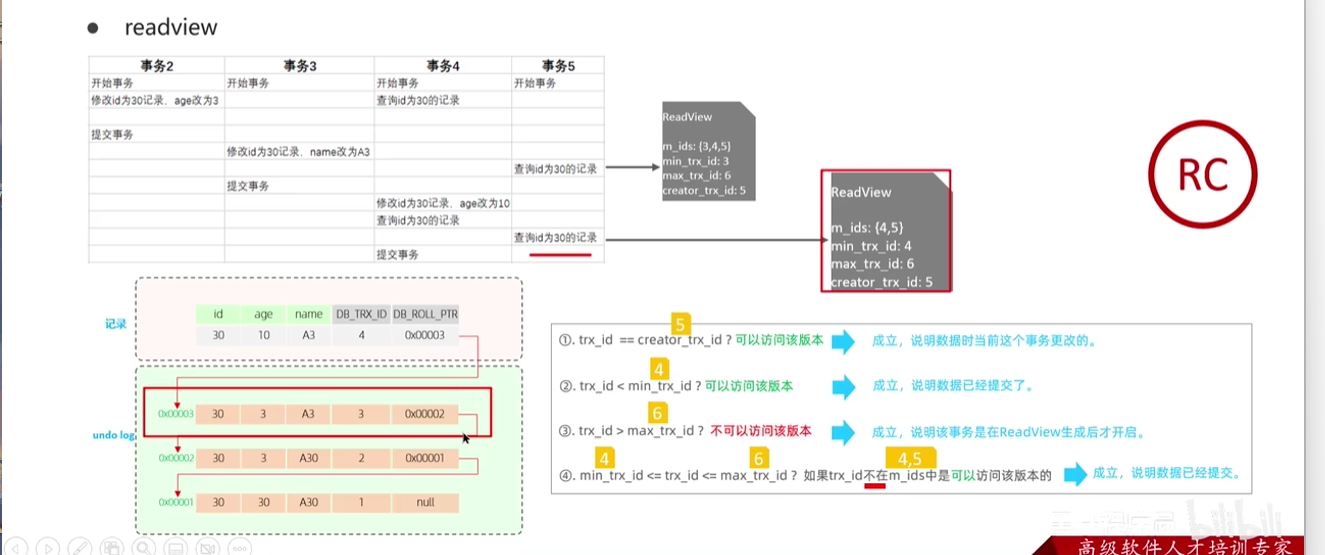
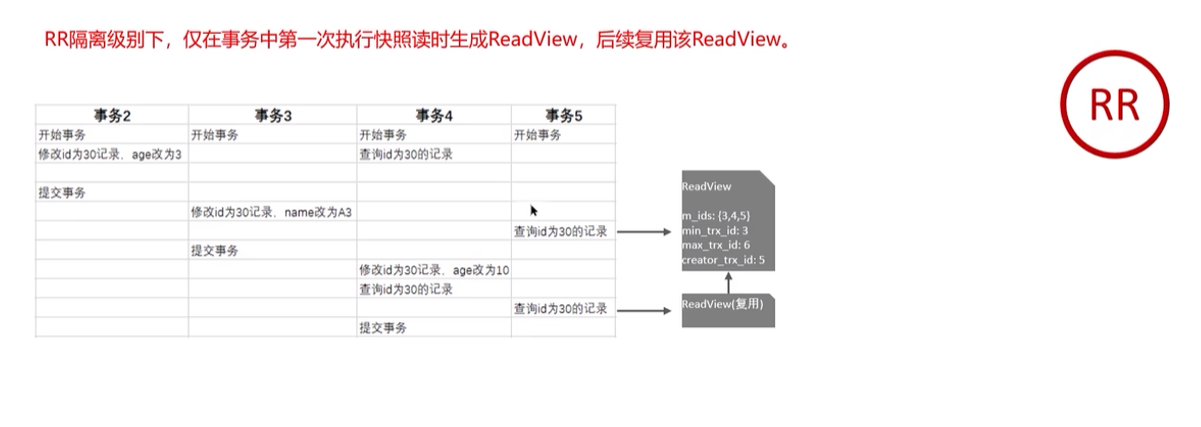
readview



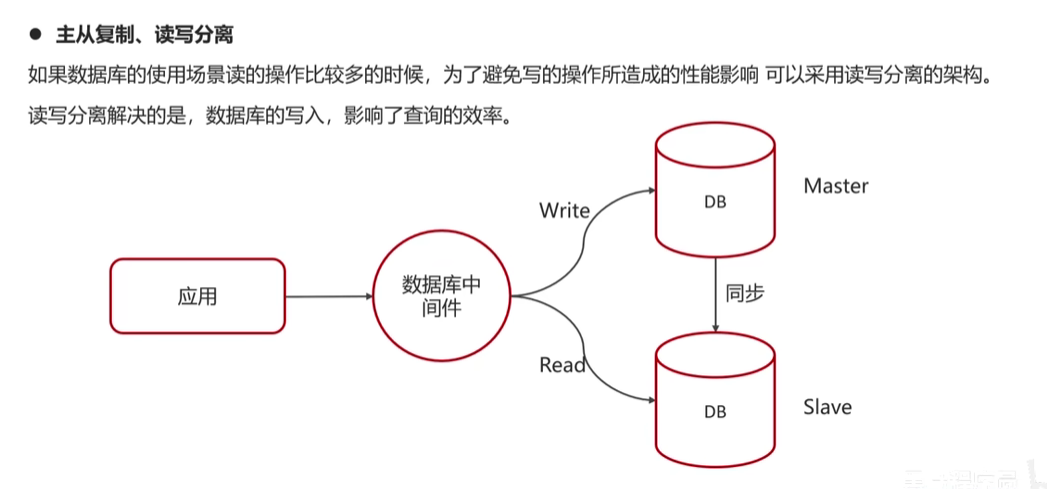
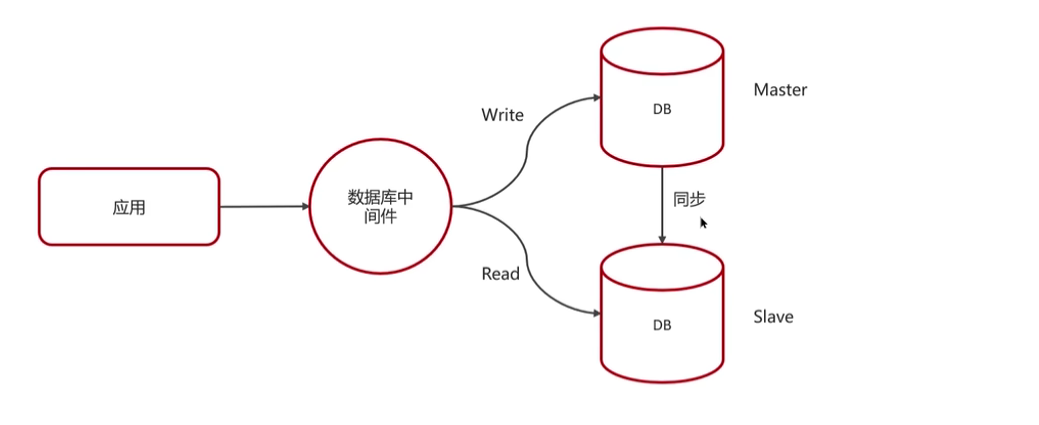
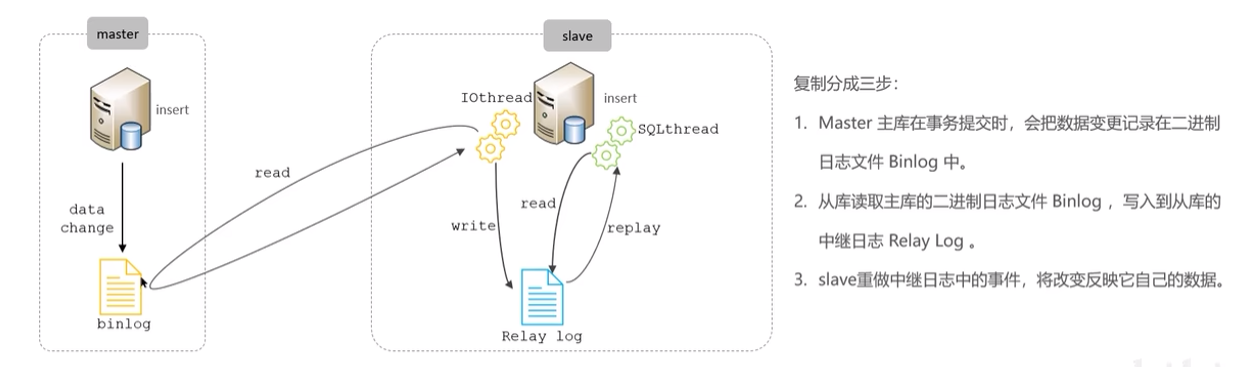
主从同步原理

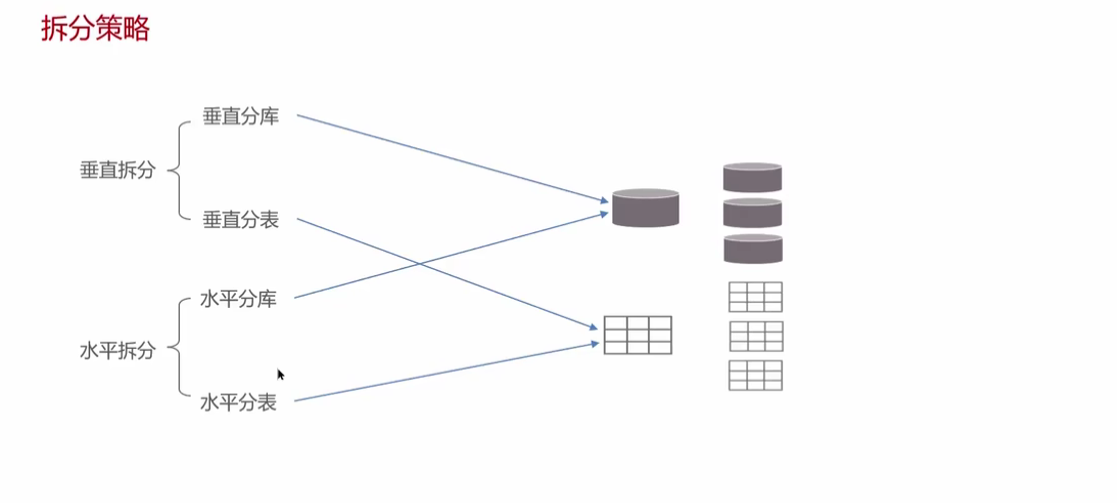
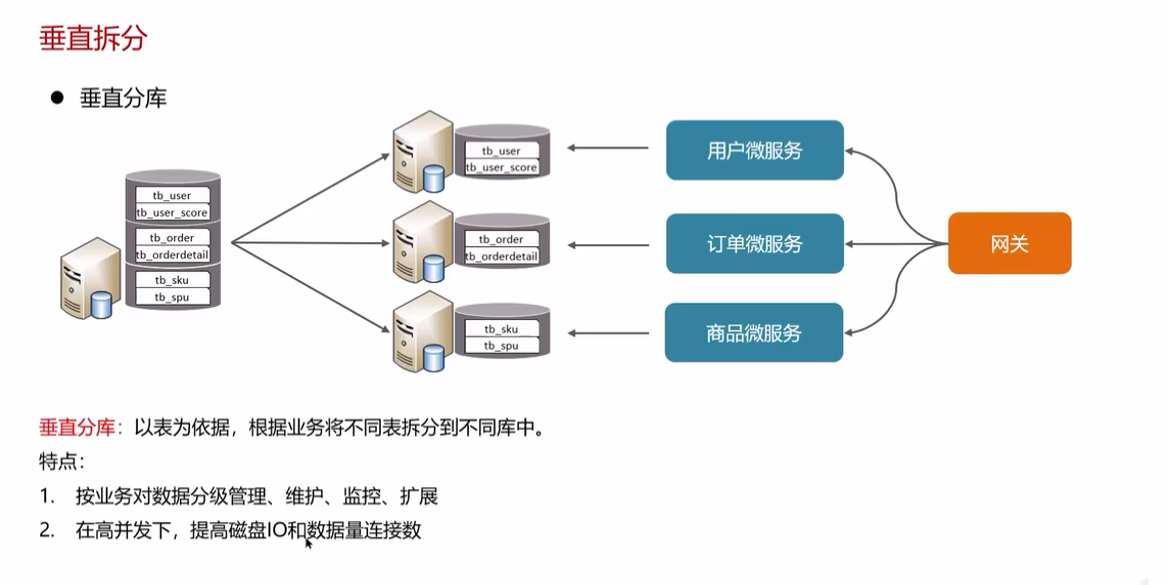
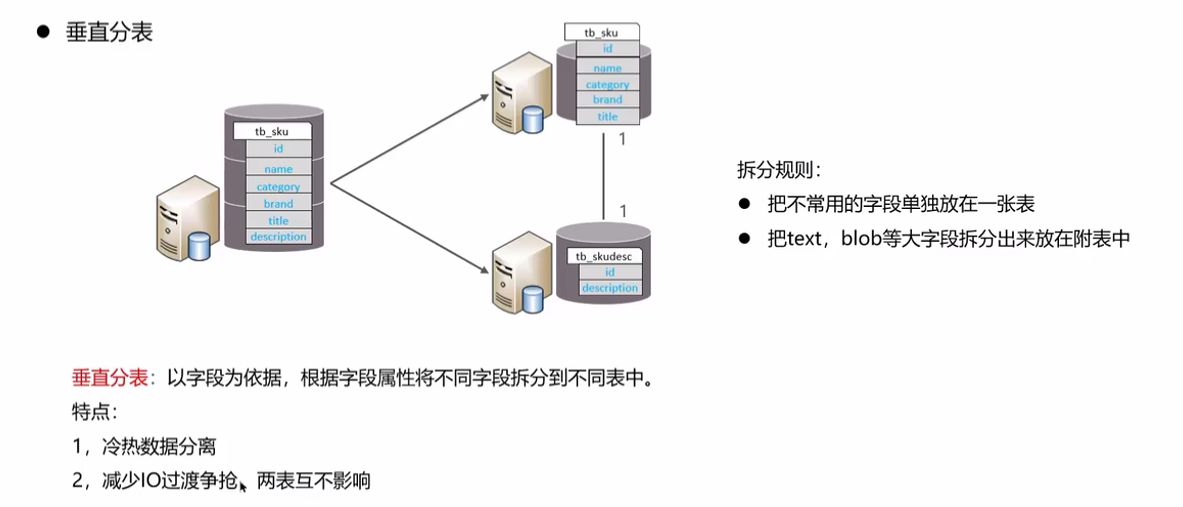
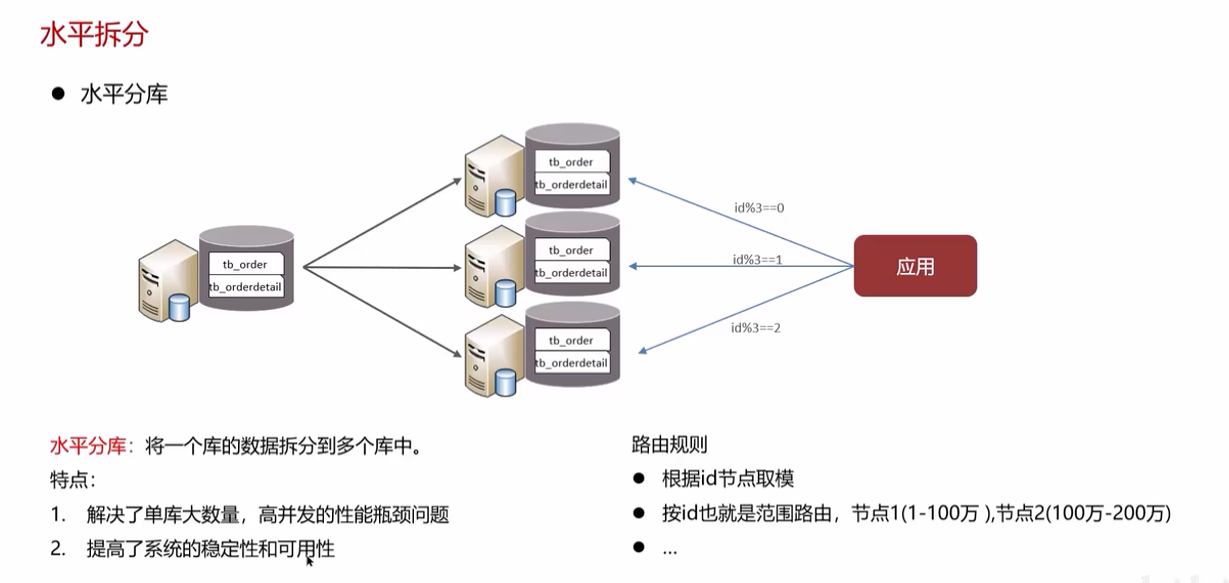
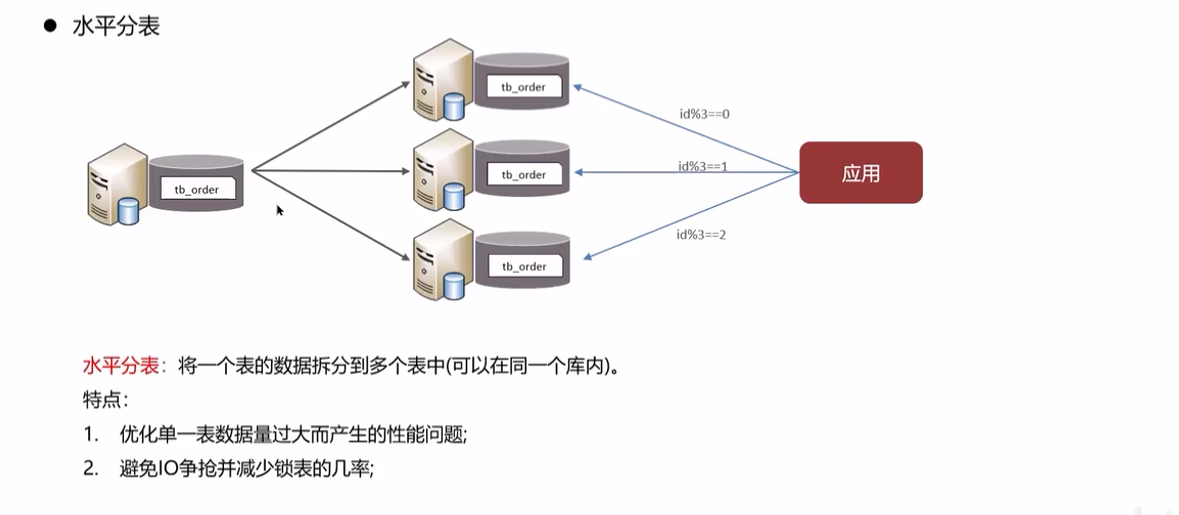
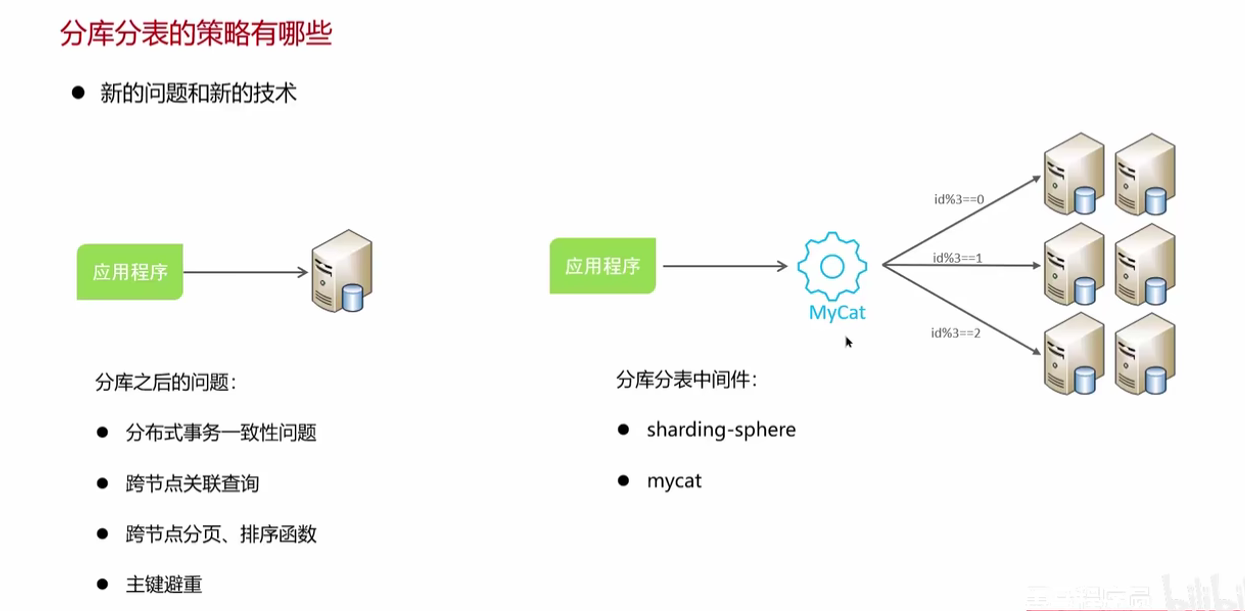
分库分表
















 319
319











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









