







目录
177. 第N高的薪水

题解
一:dense_rank函数。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
RETURN (
# Write your MySQL query statement below.
select distinct Salary from
(select Salary, dense_rank() over (order by Salary desc) as cnt
from Employee)a where cnt = N
);
END二:这边mark一下一位大神的题解,转自力扣,
排名是数据库中的一个经典题目,实际上又根据排名的具体细节可分为3种场景:
- 连续排名,例如薪水3000、2000、2000、1000排名结果为1-2-3-4,体现同薪不同名,排名类似于编号
- 同薪同名但总排名不连续,例如同样的薪水分布,排名结果为1-2-2-4
- 同薪同名且总排名连续,同样的薪水排名结果为1-2-2-3
不同的应用场景可能需要不同的排名结果,也意味着不同的查询策略。本题的目标是实现第三种排名方式下的第N个结果,且是全局排名,不存在分组的问题,实际上还要相对简单一些。
值得一提的是:在Oracle等数据库中有窗口函数,可非常容易实现这些需求,而MySQL直到8.0版本也引入相关函数。当前MySQL OJ系统为5.7版本(可通过编码区——语言选择按钮——左侧的"i"查看环境信息),所以不能直接应用。
至此,可以总结MySQL查询的一般性思路是:
- 能用单表优先用单表,即便是需要用group by、order by、limit等,效率一般也比多表高
- 不能用单表时优先用连接,连接是SQL中非常强大的用法,小表驱动大表+建立合适索引+合理运用连接条件,基本上连接可以解决绝大部分问题。但join级数不宜过多,毕竟是一个接近指数级增长的关联效果
- 能不用子查询、笛卡尔积尽量不用,虽然很多情况下MySQL优化器会将其优化成连接方式的执行过程,但效率仍然难以保证
- 自定义变量在复杂SQL实现中会很有用,例如LeetCode中困难级别的数据库题目很多都需要借助自定义变量实现
- 如果MySQL版本允许,某些带聚合功能的查询需求应用窗口函数是一个最优选择。除了经典的获取3种排名信息,还有聚合函数、向前向后取值、百分位等,具体可参考官方指南。以下是官方给出的几个窗口函数的介绍:
最后的最后再补充一点,本题将查询语句封装成一个自定义函数并给出了模板,实际上是降低了对函数语法的书写要求和难度,而且提供的函数写法也较为精简。然而,自定义函数更一般化和常用的写法应该是分三步:
- 定义变量接收返回值
- 执行查询条件,并赋值给相应变量
- 返回结果
由于本题不存在分组排序,只需返回全局第N高的一个,所以自然想到的想法是用order by排序加limit限制得到。需要注意两个细节:
- 同薪同名且不跳级的问题,解决办法是用group by按薪水分组后再order by
- 排名第N高意味着要跳过N-1个薪水,由于无法直接用limit N-1,所以需先在函数开头处理N为N=N-1。
注:这里不能直接用limit N-1是因为limit和offset字段后面只接受正整数(意味着0、负数、小数都不行)或者单一变量(意味着不能用表达式),也就是说想取一条,limit 2-1、limit 1.1这类的写法都是报错的。
注:这种解法形式最为简洁直观,但仅适用于查询全局排名问题,如果要求各分组的每个第N名,则该方法不适用;而且也不能处理存在重复值的情况。
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT
BEGIN
SET N := N-1;
RETURN (
# Write your MySQL query statement below.
select Salary from Employee group by Salary
order by Salary desc limit N,1
);
END618. 学生地理信息报告🔒
一所美国大学有来自亚洲、欧洲和美洲的学生,他们的地理信息存放在如下 student 表中。

写一个查询语句实现对大洲(continent)列的 透视表 操作,使得每个学生按照姓名的字母顺序依次排列在对应的大洲下面。输出的标题应依次为美洲(America)、亚洲(Asia)和欧洲(Europe)。数据保证来自美洲的学生不少于来自亚洲或者欧洲的学生。对于样例输入,它的对应输出是:

进阶:如果不能确定哪个大洲的学生数最多,你可以写出一个查询去生成上述学生报告吗?
题解:
一:不考虑进阶版,即默认美洲学生数最多。转自力扣, 使用 "session 变量" 和
join。思路:为每个大洲分配一个单独的行自增 id,然后将它们连接。算法:使用 session 变量为每个大洲分配单独的行自增 id。例如下面语句为美洲的学生分配行自增 id。SELECT row_id, America FROM (SELECT @am:=0) t, (SELECT @am:=@am + 1 AS row_id, name AS America FROM student WHERE continent = 'America' ORDER BY America) AS t2
select America, Asia, Europe from (select @am_id:=0, @as_id:=0, @eu_id := 0)t, (select @am_id := @am_id + 1 as am_id, case when continent = 'America' then name else null end America from student where continent = 'America' order by name)t1 left join (select @as_id := @as_id + 1 as as_id, case when continent = 'Asia' then name else null end Asia from student where continent = 'Asia' order by name)t2 on am_id = as_id left join (select @eu_id := @eu_id + 1 as eu_id, case when continent = 'Europe' then name else null end Europe from student where continent = 'Europe' order by name)t3 on am_id = eu_id用row_number函数产出id
from student where continent = 'America' order by name)t1 left join (select row_number() over() as as_id, case when continent = 'Asia' then name else null end Asia from student where continent = 'Asia' order by name)t2 on am_id = as_id left join (select row_number() over() as eu_id, case when continent = 'Europe' then name else null end Europe from student where continent = 'Europe' order by name)t3 on am_id = eu_id二:转自力扣, 进阶的解法:使用case when ...(参考其他大神的解法)。思路:同样先是根据洲名分组,对同一洲名的学生进行组内排序编号;然后分别判断这些学生的所属洲:如果是美洲,则将该学生的名字赋值给美洲,否则置null;如果是亚洲,则将该学生的名字赋值给亚洲,否则置null;如果是欧洲,则将该学生的名字赋值给欧洲,否则置null;到这一步,就已经实现了列转行。下面需要将列转行的结果根据编号整合一下。最后将这些记录根据排序的编号分组,分别取美洲、亚洲、欧洲栏位的最大值,这样就可以将同一编号的学生放在一起。同一编号没有学生的洲就为NULL。
select name, continent ,case when continent='America' then name else null end as America ,case when continent='Asia' then name else null end as Asia ,case when continent='Europe' then name else null end as Europe from student
select row_number() over(partition by continent order by name) as cnt ,name, continent from student
select id, case when continent="America" then name else null end America, case when continent="Asia" then name else null end Asia, case when continent="Europe" then name else null end Europe from (select row_number() over(partition by continent order by name) as id, name, continent from student)t
select id, max(case when continent="America" then name else null end) America, max(case when continent="Asia" then name else null end) Asia, max(case when continent="Europe" then name else null end) Europe from (select row_number() over(partition by continent order by name) as id, name, continent from student)t group by id
select max(case when continent="America" then name else null end) America, max(case when continent="Asia" then name else null end) Asia, max(case when continent="Europe" then name else null end) Europe from (select row_number() over(partition by continent order by name) as id, name, continent from student)t group by id






569. 员工薪水中位数🔒

请编写SQL查询来查找每个公司的薪水中位数。挑战点:你是否可以在不使用任何内置的SQL函数的情况下解决此问题。

题解
一:借这一题来求解每个公司的工资最高的额三个人。用row_number函数分组排序,由于工资同的人员的rn一样,故这边每个公司返回的人数可能不止三个人。
select Company, Salary, rn from
(select dense_rank() over(partition by Company order by Salary desc) as rn,
Company, Salary from Employee)t where rn <= 3 order by Company, Salary desc
二:方便的窗口函数,
select id, row_number() over(partition by Company order by Salary, id) as rn,
count(1) over(partition by Company) as cnt,
Company, Salary from Employee
select id, Company, Salary from
(select id, row_number() over(partition by Company order by Salary, id) as rn,
count(1) over(partition by Company) as cnt,
Company, Salary from Employee)t
where (mod(cnt, 2)=1 and rn = round(cnt / 2,0))
or (mod(cnt, 2)=0 and (rn = round(cnt / 2,0) or rn = round(cnt / 2,0) + 1))
order by Company, Salary 
262. 行程和用户
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。

Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。

写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
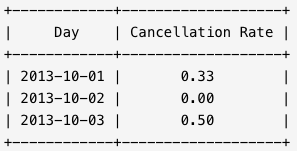
题解
一:无摘要
select Request_at Day,
round(ifnull(count(Status="cancelled_by_driver" or Status="cancelled_by_client" or null) /
count(Status), 0), 2) as 'Cancellation Rate' from
(select Status, Request_at from Trips
left join Users a on a.Users_Id = Client_Id
left join Users b on b.Users_Id = Driver_Id
where a.Banned = 'No' and b.Banned = 'No'
and Request_at >= "2013-10-01" and Request_at <= "2013-10-03")c
group by Day order by Day1205. 每月交易II🔒
Transactions 记录表

id 是这个表的主键。该表包含有关传入事务的信息。状态列是类型为 [approved(已批准)、declined(已拒绝)] 的枚举。
Chargebacks 表

退单包含有关放置在事务表中的某些事务的传入退单的基本信息。trans_id 是 transactions 表的 id 列的外键。每项退单都对应于之前进行的交易,即使未经批准。
编写一个 SQL 查询,以查找每个月和每个国家/地区的已批准交易的数量及其总金额、退单的数量及其总金额。注意:在您的查询中,给定月份和国家,忽略所有为零的行。查询结果格式如下所示:

题解
一:转自力扣,UNION,然后给UNION过来的记录打个标签用来区分就行了。
SELECT
DATE_FORMAT(trans_date, '%Y-%m') `month`,
country,
COUNT(IF(state = 'approved', 1, NULL)) approved_count,
SUM(IF(state = 'approved', amount, 0)) approved_amount,
COUNT(IF(state = 'chargeback', 1, NULL)) chargeback_count,
SUM(IF(state = 'chargeback', amount, 0)) chargeback_amount
FROM
(
SELECT
trans_date, id, country, state, amount
FROM
Transactions
UNION
SELECT
c.trans_date, c.trans_id, t.country, 'chargeback' state, t.amount
FROM
Chargebacks c
LEFT JOIN Transactions t ON c.trans_id = t.id
) t
GROUP BY
1,2
HAVING
approved_count + chargeback_count > 01683. Invalid Tweets
Table: Tweets
+----------------+---------+
| Column Name | Type |
+----------------+---------+
| tweet_id | int |
| content | varchar |
+----------------+---------+
tweet_id is the primary key for this table.This table contains all the tweets in a social media app.
Write an SQL query to find the IDs of the invalid tweets. The tweet is invalid if the number of characters used in the content of the tweet is strictly greater than 15.Return the result table in any order.The query result format is in the following example:
Tweets table:
+----------+----------------------------------+
| tweet_id | content |
+----------+----------------------------------+
| 1 | Vote for Biden |
| 2 | Let us make America great again! |
+----------+----------------------------------+
Result table:
+----------+
| tweet_id |
+----------+
| 2 |
+----------+
Tweet 1 has length = 14. It is a valid tweet.
Tweet 2 has length = 32. It is an invalid tweet.
题解
一:主要是取字符串长度的函数length,该函数会记录空格数,一个空格算一个字符
select tweet_id from Tweets where length(content) > 15185. 部门工资前三高的所有员工
力扣![]() https://leetcode.cn/problems/department-top-three-salaries/
https://leetcode.cn/problems/department-top-three-salaries/
表: Employee
+--------------+---------+
| Column Name | Type |
+--------------+---------+
| id | int |
| name | varchar |
| salary | int |
| departmentId | int |
+--------------+---------+
Id是该表的主键列。
departmentId是Department表中ID的外键。
该表的每一行都表示员工的ID、姓名和工资。它还包含了他们部门的ID。
表: Department
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| name | varchar |
+-------------+---------+
Id是该表的主键列。
该表的每一行表示部门ID和部门名。
公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。
编写一个SQL查询,找出每个部门中 收入高的员工 。
以 任意顺序 返回结果表。
查询结果格式如下所示。
示例 1:
输入:
Employee 表:
+----+-------+--------+--------------+
| id | name | salary | departmentId |
+----+-------+--------+--------------+
| 1 | Joe | 85000 | 1 |
| 2 | Henry | 80000 | 2 |
| 3 | Sam | 60000 | 2 |
| 4 | Max | 90000 | 1 |
| 5 | Janet | 69000 | 1 |
| 6 | Randy | 85000 | 1 |
| 7 | Will | 70000 | 1 |
+----+-------+--------+--------------+
Department 表:
+----+-------+
| id | name |
+----+-------+
| 1 | IT |
| 2 | Sales |
+----+-------+
输出:
+------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| IT | Joe | 85000 |
| IT | Randy | 85000 |
| IT | Will | 70000 |
| Sales | Henry | 80000 |
| Sales | Sam | 60000 |
+------------+----------+--------+
解释:
在IT部门:
- Max的工资最高
- 兰迪和乔都赚取第二高的独特的薪水
- 威尔的薪水是第三高的
在销售部:
- 亨利的工资最高
- 山姆的薪水第二高
- 没有第三高的工资,因为只有两名员工
select b.name Department, Employee, Salary from
(select name as Employee, Salary, departmentId,
dense_rank() over(partition by departmentId order by salary desc) as r
from Employee)a
left join Department b
on departmentId = id
where a.r <= 3













 416
416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









