










 本文提出了Multi-gateMixture-of-Experts(MMoE)模型,用于在多任务学习中建模任务关系。MMoE通过门控网络和专家网络,自动调整共享信息和任务特定信息的建模,有效处理任务相关性较低的情况。在合成数据和真实数据集上的实验表明,MMoE在任务相关性低时表现出优越的性能,且训练稳定性更高。此外,MMoE在大规模内容推荐系统的在线实验中也显示出改善的性能。
本文提出了Multi-gateMixture-of-Experts(MMoE)模型,用于在多任务学习中建模任务关系。MMoE通过门控网络和专家网络,自动调整共享信息和任务特定信息的建模,有效处理任务相关性较低的情况。在合成数据和真实数据集上的实验表明,MMoE在任务相关性低时表现出优越的性能,且训练稳定性更高。此外,MMoE在大规模内容推荐系统的在线实验中也显示出改善的性能。
发于2018年,论文地址:KDD 2018 | Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts
Abstract
基于神经网络的多任务学习已经成功的应用于诸如推荐系统等许多现实世界的大规模场景中。例如电影推荐,不仅要推荐用户倾向于购买或观看的电影,还要推荐他们喜欢的(下文提到是为了提高用户粘性,提高用户下次过来的可能性。也就是要同时预测用户的购买和对电影的评分)。通过多任务学习,期待用一个模型同时学习多个目标和任务。目前在用的多任务模型,通常对任务之间的相关性敏感。研究能权衡特定任务以及任务之间关系的模型是很有必要的。(It is therefore important to study the modeling tradeoffs between task-specific objectives and inter-task relationships.)
文中提出的Multi-gate Mixture-of-Experts (MMoE) 方法,可以明确地学习从数据中建模任务间关系。通过在所有任务中共享专家子网络,同时训练门控网络来优化每个任务,从而使混合专家Mixture-of-Experts(MoE)结构适应多任务学习。为了验证方法在不同任务相关性的数据集上的表现,首先将模型应用于可以人为控制任务相关性的人工生成的数据集上。发现当任务不太相关时,MMOE的表现优于基准。还发现MMOE在训练时的另一个优势,这取决于训练数据和模型初始化中不同级别的随机性。此外,展示了 MMoE 在实际任务上的性能提升,包括二分类基准和谷歌的大规模内容推荐系统。
Introduction
有研究说,多任务学习模型可以通过利用正则化和迁移学习来改进对所有任务的预测 。然而现实中,多任务学习模型并不总是在所有任务上都优于单任务模型。很多基于DNN的多任务学习模型对诸如任务之间的关系、数据分布的差异比较敏感。任务差异带来的固有冲突实际上可能会影响部分任务的预测,尤其是当模型参数在所有任务之间广泛共享时( The inherent conflicts from task differences can actually harm the predictions of at least some of the tasks, particularly when model parameters are extensively shared among all tasks.)。
先前有研究通过为每个任务假设特定的数据生成过程,根据假设测量任务差异,然后根据任务的差异程度提出建议。但是,实际应用通常具有更复杂的数据模式,因此很难衡量任务差异并利用这些先前工作的建议方法。
最近有研究提出了新的建模技术来处理多任务学习中的任务差异,而不是依赖于明确的任务差异程度的测量。然而,这些技术通常为每个任务添加更多模型参数以适应任务差异。由于大规模推荐系统可能包含数百万或数十亿个参数,我们很难对这些额外的参数进行很好的约束(those additional parameters are often under-constrained),这可能会损害模型精度。由于服务资源有限,这些参数的额外计算成本在实际生产环境中也常常令人望而却步。
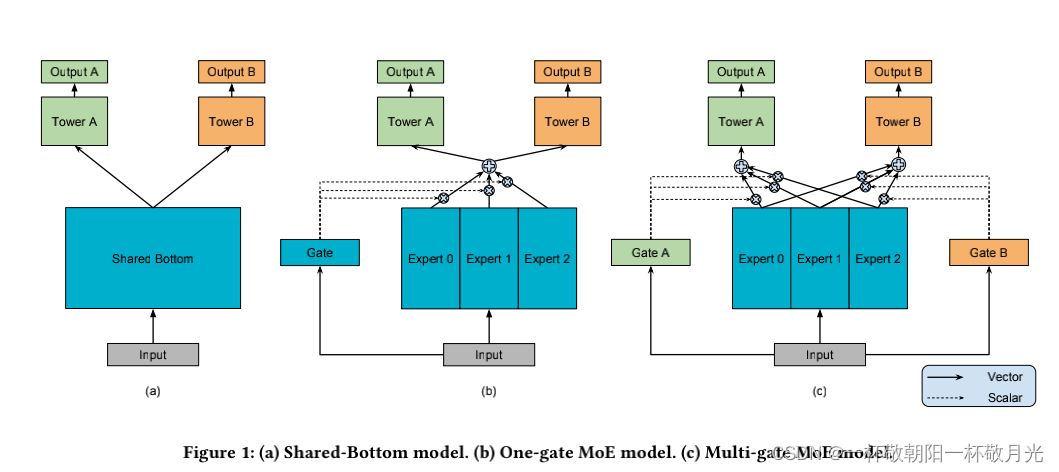
MMoE能利用共享信息建模任务之间的关系、以及每个特定任务的函数。在避免加入更多参数的情况下,允许自动分配参数来捕获共享的任务信息或者某个任务自己的信息。(MMoE explicitly models the task relationships and learns task-specific functionalities to leverage shared representations. It allows parameters to be automatically allocated to capture either shared task information or task-specific information, avoiding the need of adding many new parameters per task.)
MMoE 的主干建立在最常用的 Shared-Bottom 多任务 DNN 结构之上。 Shared-Bottom 模型结构如图 1(a) 所示,其中输入层之后的几个bottom layers在所有任务之间共享,然后每个任务在底部表示之上都有一个单独的网络“塔”。MMoE(如图 1(c))用一组bottom networks(每一个bottom network被称之为专家expert)替代了(a)的所有任务共享的一个bottom network。文中,每个专家都是一个前馈网络。然后为每个任务引入一个门控网络。input features同时输入给专家网络和门控网络,其中门控网络采用softmax激活函数,与专家网络的输出相乘,通过门控网络给专家网络的输出赋予不同的权重,使得每个任务可以以不同的方式利用专家网络。专家网络的输出以不同的权重方式组合后的结果,送入到各自任务的塔中。通过这种方式,不同任务的门控网络可以学习不同专家的组合模式,从而捕获任务关系(the gating networks for different tasks can learn different mixture patterns of experts assembling, and thus capture the task relationships.)。
MMoE结构:
- 输入层
- 专家网络、门控网络;门控网络的个数对应于任务的个数,门控网络的输出维度对应于专家网络的数量
- 各任务自己的task tower
- 各任务的输出
为了了解 MMoE 如何针对不同级别的任务相关性学习其专家和门控网络,在人工生成的数据集上进行了试验,在该数据集上可以通过它们的 Pearson 相关性来测量和控制任务相关性。与[24]类似,使用两个合成回归任务并使用正弦函数作为数据生成机制来引入非线性。在这种设置下,MMOE优于基准,尤其是在任务相关性较低的情况下。在这组实验中,还发现 MMoE 更容易训练并且在多次运行期间收敛到更低的损失。这与最近研究一致,即调制和门控机制可以提高训练非凸深度神经网络的可训练性(This relates to recent discoveries that modulation and gating mechanisms can improve the trainability in training non-convex deep neural networks)。
通过多任务问题设置进一步评估了 MMoE 在 UCI 人口普查收入数据集(UCI Census-income dataset)上的性能。与几种最先进的多任务模型进行比较,这些模型通过软参数共享对任务关系进行建模,并观察我们方法的改进。
最后,在真实的大规模内容推荐系统上测试 MMoE,在向用户推荐items时,同时学习两个分类任务。用数千亿个训练样本训练 MMoE 模型,并将其与shared-bottom生产模型进行比较。离线指标如AUC有明显的提升。此外,MMoE 模型在实时实验中不断改进在线指标。
本文的贡献有三方面:首先,提出了一种新颖的MMoE模型,该模型明确地对任务关系进行建模。通过调制和门控网络,模型自动调整建模共享信息和建模任务特定信息(First, we propose a novel Multi-gate Mixture-of-Experts model which explicitly models task relationships.Through modulation and gating networks, our model automatically adjusts parameterization between modeling shared information and modeling task-specific information.)。其次,对合成数据进行实验。报告了任务相关性如何影响多任务学习中的训练动态以及 MMoE 如何提高模型表达能力和可训练性。最后,在真实的数据、具有数亿用户和iitem的大规模生产推荐系统上进行了实验。实验验证了MMoE在现实环境中的效率和有效性。
2 RELATED WORK
2.1 Multi-task Learning in DNNs
多任务模型可以学习不同任务之间的共性和差异。这样做可以提高每个任务的效率和模型质量。目前广泛使用的多任务学习模型是由Caruana提出的,该模型具有共享的底部模型结构(shared-bottom model),所有任务之间共享shared-bottom。这种结构大大降低了过拟合的风险,但可能会遇到由任务差异引起的优化冲突,因为所有任务在shared-bottom网络中有相同的参数。
为了理解任务相关性是如何影响模型质量的,以前的工作使用人工数据生成和并人为控制不同类型的任务相关性,以评估多任务模型的有效性。
最近的一些方法不是在任务之间共享隐藏层和相同的模型参数,而是在特定任务的参数上添加不同类型的约束。例如,对于两个任务,Duong等人在两组参数之间添加了L2约束。十字绣网络允许模型通过学习前面层的输出的线性组合来确定如何使特定任务的网络利用其它任务的知识。Yang等人使用张量因子分解模型为每个任务生成隐藏层参数。与shared-bottom相比,这些方法具有更多任务特定的参数,当在更新共享参数的时候,由于任务差异引起冲突,这些方法能有更优的表现。 然而,大量特定任务的参数需要更多的训练数据来拟合,并且在大规模模型中可能效率不高。
2.2 Ensemble of Subnets & Mixture of Experts
应用了深度学习中的一些最新发现,用参数调制(parameter modulation)和集成方法(ensemble method)来建模多任务学习中的任务关系。在深度神经网络中,集成模型、对子网络的集成已被证明能够提高模型性能。
Eigen等人[16]和Shazeer等人[31]将专家混合模型(mixture-of-experts model)变成基本的构建块(MoE layer),并将它们堆叠在DNN中。MoE层根据该层在训练和服务时都是依据输入选择子网(专家)。因此,该模型不仅在建模方面更强,而且通过在gating networks中引入稀疏性来降低计算成本。类似地,PathNet【17】是为人工通用智能设计的,用于处理不同的任务,它是一个庞大的神经网络,有多层,每层中的多个子模块。在为一项任务进行训练时,随机选择多条路径,由不同的workers并行进行培训。确定最佳路径的参数,并选择新路径来训练新任务。我们从这些工作中获得了灵感,通过使用一组子网(专家)来实现迁移学习,同时节省计算量( using an ensemble of subnets (experts) to achieve transfer learning while saving computation)。
2.3 Multi-task Learning Applications
由于分布式机器学习系统[13]的发展,许多大规模的应用程序都采用了基于DNN的多任务学习算法,并取得实质性的提升。
在多语言机器翻译任务中,在共享模型参数下,通过与具有大量训练数据[22]的任务联合学习,可以改进训练数据有限的翻译任务。对于构建推荐系统,多任务学习有助于提供上下文感知的推荐(For building recommendation systems, multi-task learning is found helpful for providing context-aware recommendations)。在[3]中,通过共享特征和较低级别的隐藏层来改进文本推荐任务。在[11]中,使用共享底模型来学习视频推荐的排序算法。与这些之前的工作类似,我们在一个现实世界的大规模推荐系统上评估了我们的建模方法。证明我们的方法确实是可扩展的,并且与其他最先进的建模方法相比具有良好的性能。
3 PRELIMINARY
3.1 Shared-bottom Multi-task Model
我们首先在图1(a)中介绍共享底部多任务模型(Shared-bottom Multi-task Model),它是由RichCaruana[8]提出的框架,该框架被多任务学习广泛采用。因此,我们将其视为多任务建模中的一种具有代表性的基线方法。
给定K个任务,模型由(1)shared-bottom network用函数f表示;(2)K个tower networks用表示,其中
是每个任务独有的。shared-bottom network紧随输入层之后,tower networks的输入是shared-bottom network的输出。每个任务自己的输出
各自的task-specific tower输出的。(Given K tasks, the model consists of a shared-bottom network,represented as function
, and K tower networks
, where k = 1, 2, ...,K for each task respectively. The shared-bottom network follows the input layer, and the tower networks are built upon the output of the shared-bottom. Then individual output
for each task follows the corresponding task-specific tower.)对于任务k,其模型用公式表示如下:
3.2 Synthetic Data Generation
先前的研究表明,多任务学习模型的性能在很大程度上取决于数据中固有的任务相关性。然而,很难直接研究任务相关性如何影响实际应用中的多任务模型,因为在实际中,我们无法轻易改变任务之间的相关性并观察其效果。因此,为了建立这种关系的实证研究,我们首先使用合成数据,这样我们可以轻松地测量和控制任务相关性。
受Kang等人[24]的启发,我们生成了两个回归任务,并使用这两个任务标签的Pearson相关性作为任务关系的定量指标。由于我们关注DNN模型,而不是[24]中使用的线性函数,因此我们将回归模型设置为[33]中使用的正弦函数的组合。具体而言,我们生成的合成数据如下所示。
1)给定向量维度d,生成两个正交的单位向量
2)给定一个常量标量和一个相关性分数
,产生两个权重向量
。
3)从标准正态分布中随意采样一个点
4)为两个回归任务生成两个标签
其中是控制正弦函数形状的参数,
(5)重复(3)和(4)直到产生足够的数据。
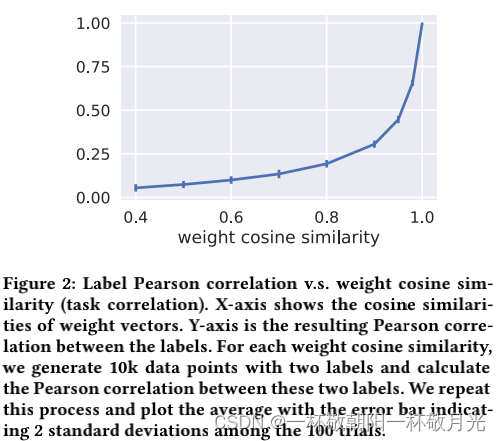
由于非线性数据生成过程,生成具有给定标签Pearson相关性的任务并非易事。相反,我们操纵公式2中权重向量的余弦相似性,即,然后测量得到的标签Pearson相关性。注意,在线性情况下,标签
的Pearson相关系数就是
非线性情况下,公式(3)和(4)标签也是正相关的。在本文的其余部分,为了简单起见,我们将权重向量的余弦相似性称为“任务相关性”。
3.3 Impact of Task Relatedness
为了验证低任务相关性会会影响基线多任务模型的质量,我们对合成数据进行了如下控制实验 :
(1) 给定任务相关性得分列表,为其中的每个得分生成一个合成数据集;
(2) 在每个数据集上分别训练一个Shared-Bottom multi-task model,同时控制所有模型超参数保持不变;
(3) 使用独立生成的数据集重复步骤(1)和(2)数百次,但控制任务相关性得分列表和相同的超参数;
(4) 计算每个任务相关性得分模型的平均性能。
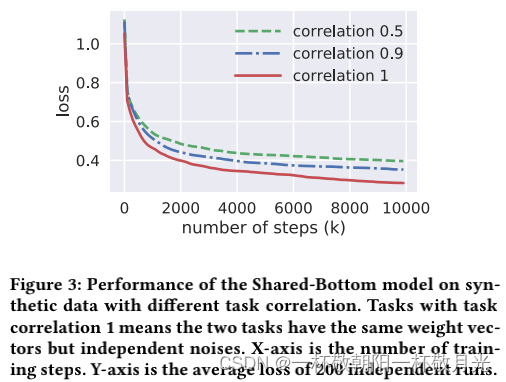
图3显示了不同任务相关性的损失曲线。正如预期的那样,随着任务相关性的降低,模型的性能呈下降趋势。这种趋势在许多不同的超参数设置中是普遍存在的。这里,图3仅显示一组控制实验结果。在本例中,每个塔网络是一个具有8个隐藏单元的单层神经网络,共享底部网络是一个大小为16的单层网络。该模型使用TensorFlow实现,并使用默认设置的Adam 优化器进行训练。请注意,这两个回归任务是对称的,因此报告一个任务的结果就足够了。这一现象验证了我们的假设,即传统的多任务模型对任务关系敏感。
4 MODELING APPROACHES
4.1 Mixture-of-Experts
最初的专家混合模型Original Mixture-of-Experts (MoE) Model可表述为:
其中,
是
的第i个输出,表示专家网络
的概率。
表示n个专家网络,
表示用来组合专家网络输出结果的门控网络。更具体地说,选通网络g根据输入在n个专家上产生分布,最终输出是所有专家输出的加权和。
MoE层:虽然MoE最初是作为多个单独模型的集成方法开发的,但Eigen等人【16】和Shazeer等人【31】将其转化为基本构建块(MoE层),并将其堆叠在DNN中。MoE层的结构与MoE模型相同,区别是其接受前一层的输出作为输入,MoE的输出也会给到后续层。然后以端到端的方式对整个模型进行训练。
Eigen等人【16】和Shazeer等人【31】提出的MoE层结构的主要目标是实现条件计算【7,12】,对于每个示例仅有部分网络处于活动状态。对于每个输入示例,该模型只能通过给定输入的的选通网络选择专家子集。(to achieve conditional computation [7, 12], where only parts of a network are active on a per-example basis. For each input example, the model is able to select only a subset of experts by the gating network conditioned on the input.)
4.2 Multi-gate Mixture-of-Experts
我们提出了一个新的MoE模型,与共享底部多任务模型相比,该模型旨在无需添加更多的参数就可以捕获任务差异。新模型被称为Multi-gate Mixture-of-Experts(MMoE)模型,其中的关键思想是用公式5中的MoE层替换公式1中的共享底部网络f。更重要的是,我们为每个任务k添加一个单独的选通网络。结构见图1(c)任务k的输出用公式表示如下:
我们的实现由具有ReLU激活的相同多层感知器组成。选通网络是输入的线性变换再套一个softmax层:
其中是可训练的,n是专家网络的数目,d是特征的维度。
每个选通网络可以根据输入示例学习“选择”要使用的专家子集。这对于多任务学习情况下的灵活参数共享是可取的。作为一种特殊情况,如果只选择了一个门得分最高的专家,则每个门网络实际上将输入空间线性划分为n个区域,每个区域对应一个专家。MMoE以复杂的方式建模任务关系,通过确定不同门导致的分离如何相互重叠(As a special case, if only one expert with the highest gate score is selected, each gating network actually linearly separates the input space into n regions with each region corresponding to an expert.The MMoE is able to model the task relationships in a sophisticated way by deciding how the separations resulted by different gates overlap with each other)。如果任务相关性较小,则共享专家将受到惩罚,这些相关性小的任务的门控网络将学习使用不同的专家。与共享底部模型相比,MMoE只有几个额外的选通网络,并且选通网络中的模型参数数量可以忽略不计。因此,整个模型在多任务学习中仍然尽可能地享受知识转移(knowledge transfer)的好处。
为了理解为每个任务引入单独的门控网络是如何帮助模型学习任务特定信息,我们与所有任务共享一个门的模型结构进行了比较。我们称之为单门专家混合模型One-gate Mixture-of-Experts(OMoE)模型。这是 MoE 层对 Shared-Bottom 多任务模型的直接适应。有关模型结构的说明,请参见图 1 (b)。
5 MMOE ON SYNTHETIC DATA
在本节中,我们想了解 MMoE 模型是否确实可以更好地处理任务相关性较低的情况。 与第 3.3 节类似,我们对合成数据进行控制实验来研究这个问题。 我们改变合成数据的任务相关性,并观察不同模型的行为如何变化。 我们还进行了可训练性分析,并表明与 Shared-Bottom 模型相比,基于 MoE 的模型可以更容易地训练。
5.1 Performance on Data with Different Task Correlations
我们用MMoE模型和两个基线模型(Shared-Bottom 模型和OMoE模型)重复第3.3节中的实验。
模型结构:输入维度是100,两个基于 MoE 的模型都有 8 个专家,每个专家实现为一个单层网络。专家网络中隐藏层的大小为 16。塔式网络仍然是大小为 8 的单层网络。 我们注意到共享专家和塔中模型参数的总数为 100 × 16 × 8 + 16 × 8 × 2 = 13056。对于基线 Shared-Bottom 模型,我们仍然将塔网络设置为单层 大小为 8 的网络。 我们设置大小为 13056/(100 + 8 × 2) ≈ 113 的单层共享底层网络。
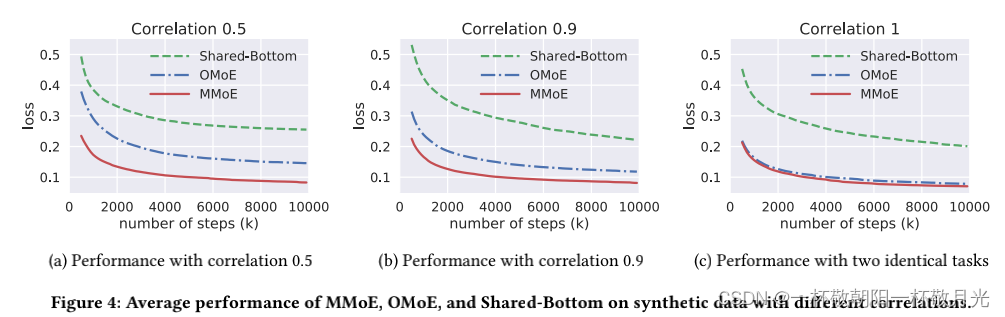
结果:所有模型都使用 Adam 优化器进行训练,学习率从 [0.0001, 0.001, 0.01] 进行网格搜索。对于每个模型相关对设置,我们运行200次具有独立的随机数据生成和模型初始化。平均结果如图 4 所示。 观察结果概述如下:
(1) 对于所有模型,在相关性较高的数据上的表现优于在相关性较低的数据上的表现。
(2) MMoE模型在不同相关性数据上的性能差距远小于OMoE模型和Shared-Bottom模型。这种趋势在我们比较 MMoE 模型和 OMoE 模型时尤为明显:在两个任务相同的极端情况下,MMoE 模型和 OMoE 模型的性能几乎没有差异;然而,当任务之间的相关性降低时,OMoE 模型的性能有明显的退化,而对 MMoE 模型的影响很小。因此,在低相关性情况下,使用特定于任务的门来模拟任务差异至关重要。
(3) 两种 MoE 模型在所有场景中的平均性能都优于 Shared-Bottom 模型。这表明 MoE 结构本身带来了额外的好处。根据这一观察,我们在下一小节中展示了 MoE 模型比 SharedBottom 模型具有更好的可训练性。
5.2 Trainability
对于大型神经网络模型,我们非常关心它们的可训练性,即模型在超参数设置和模型初始化范围内的鲁棒性。
最近,Collins 等人 [10] 发现一些我们认为比普通 RNN 表现更好的门控 RNN 模型(如 LSTM 和 GRU)更容易训练,而不是具有更好的模型容量。虽然我们已经证明 MMoE 可以更好地处理任务相关性较低的情况,但我们还希望更深入地了解它在可训练性方面的表现。
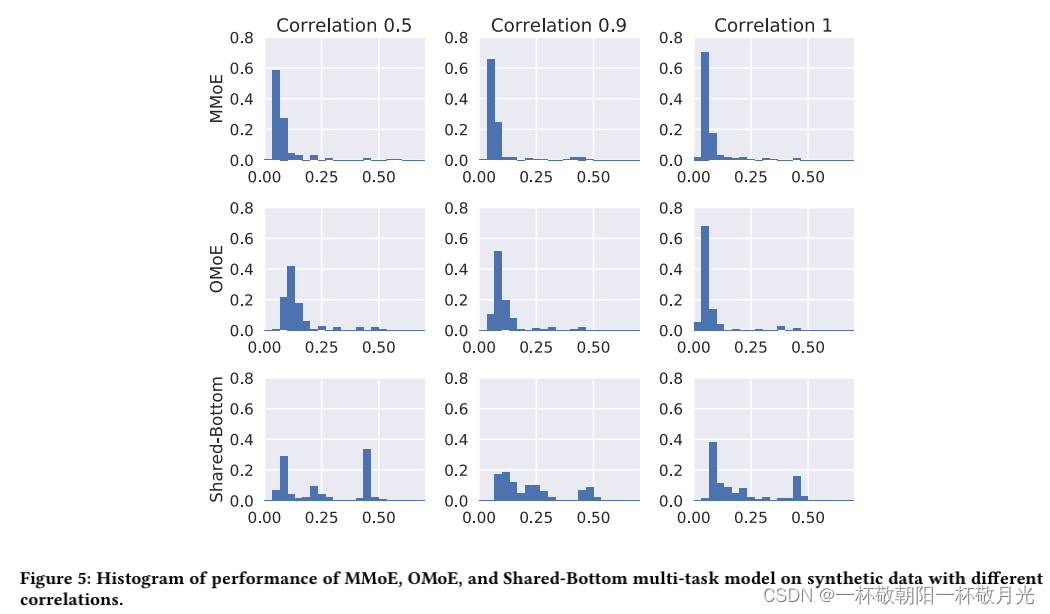
使用我们的合成数据,我们可以自然地研究我们的模型对数据和模型初始化随机性的鲁棒性。我们在每个设置下多次重复实验。每次数据都是从相同的分布但不同的随机种子生成的,模型的初始化也不同。图 5 是重复运行的最终损失值的直方图。
直方图中有三个有趣的观察结果。首先,在所有任务相关设置中,Shared-Bottom 模型的性能差异远大于基于 MoE 的模型的性能差异。这意味着 Shared-Bottom 模型通常比基于 MoE 的模型具有更差的局部最小值。其次,虽然当任务相关性为 1 时,OMoE 模型的性能方差与 MMoE 模型的性能方差相似,但当任务相关性降低到 0.5 时,OMoE 的稳健性有明显下降。请注意,MMoE 和 OMoE 之间的唯一区别是是否存在multi-gate结构。这验证了多门结构在解决由任务差异引起的冲突引起的不良局部最小值方面的有用性。最后,值得一提的是,所有三个模型的最低损失都具有可比性。这并不奇怪,因为神经网络在理论上是通用逼近器。有了足够的模型容量,应该存在一个“正确”的 Shared-Bottom 模型,可以很好地学习这两个任务。但是,请注意,这是 200 次独立实验的分布。并且我们怀疑对于更大更复杂的模型(例如,当共享底层网络是循环神经网络时),获得任务关系“正确”模型的机会会更低。因此,对任务关系进行显式建模仍然是可取的。
6 REAL DATA EXPERIMENTS
在本节中,我们在真实数据集上进行实验以验证我们方法的有效性。
6.1 Baseline Methods
除了 Shared-Bottom 多任务模型之外,我们还将我们的方法与几种试图从数据中学习任务关系的最先进的多任务深度神经网络模型进行比较。
L2-Constrained :该方法是为具有两个任务的跨语言问题而设计的。 在这种方法中,用于不同任务的参数由 L2 约束软共享。
给定作为任务
的真实标签,任务
的预测表示如下:
其中是模型参数。
该方法的目标函数为:
其中是任务 1 和任务 2 的真实标签,
是超参数。该方法用
的大小对任务相关性进行建模。
Cross-Stitch:该方法通过引入“Cross-Stitch”单元来共享两个任务之间的信息。 Cross-Stitch 单元的输入是从任务 1 和任务 2 中获取分离的隐藏层和
,其输出
和
表示如下:
其中是可训练的参数,表示从任务
到任务
的交叉转换(representing the cross transfer from task k to task j.)。
和
分别被送到任务 1 和任务 2 的后续层。
Tensor-Factorization:在这种方法中,来自多个任务的权重被建模为张量,并且张量分解方法用于跨任务的参数共享。 为了进行比较,我们实施了 Tucker 分解来学习多任务模型,据报道它提供了最可靠的结果 [34]。 例如,给定输入隐藏层大小、输出隐藏层大小
和任务编号
,权重
是一个
张量,由以下公式导出:
其中大小为的张量
,大小为
的矩阵
,大小为
的矩阵
,大小为
的
矩阵均是可训练的。所有这些都通过标准反向传播一起训练。
和
是超参数。
6.2 Hyper-Parameter Tuning
我们采用在最近的深度学习框架 [10] 中使用的超参数调优器,在真实数据集的实验中为所有模型搜索最佳超参数。 调整算法是一个类似于 [14, 32] 中介绍的 Spearmint 的高斯过程模型。
为了使比较公平,我们通过为每层隐藏单元的数量设置相同的上限(2048)来限制所有方法的模型大小。对于 MMoE,它是“专家数量”ד每个专家的隐藏层单元数”。 我们的方法和所有基线方法都是使用 TensorFlow [1] 实现的。
我们调整所有方法的学习率和训练步骤的数量。 我们还调整了一些特定于方法的超参数:
- MMOE:专家数量,每位专家的隐藏单元数量。
- L2-Constrained:隐藏层大小。 L2 约束的权重 α。
- Cross-Stitch:隐藏层大小、Cross-Stitch 层大小。
- Tensor-Factorization:
用于Tuck 分解,隐藏层大小。
6.3 Census-income Data
在本小节中,我们报告和讨论了人口普查收入数据(Census-income Data)的实验结果。
6.3.1 数据集描述
UCI 人口普查收入数据集 [2] 是从 1994 年人口普查数据库中提取的。 它包含 299,285 个美国成年人的人口统计信息实例。 共有 40 个特征。 我们通过将一些特征设置为预测目标并计算超过 10,000 个随机样本的任务标签的 Pearson 相关性的绝对值,从该数据集构建了两个多任务学习问题:
(1)
任务1:预测收入是否超过$50K;任务 2:预测此人的婚姻状况是否从未结过婚。皮尔逊相关系数绝对值:0.1768。
(2)
任务1:预测教育水平是否至少为大学;任务 2:预测此人的婚姻状况是否从未结过婚。皮尔逊相关系数绝对值:0.2373。
在数据集中,有 199,523 个训练样例和 99,762 个测试样例。我们进一步以 1:1 的比例将测试示例随机分为验证数据集和测试数据集。
请注意,我们从输入特征中删除了教育和婚姻状况,因为它们在这些设置中被视为标签。我们将 MMoE 与上述基线方法进行比较。由于两组任务都是二元分类问题,我们使用 AUC 分数作为评估指标。在两组中,我们将婚姻状况任务作为辅助任务,将第一组的收入任务和第二组的教育任务作为主要任务。对于超参数调整,我们使用验证集上主要任务的 AUC 作为目标。对于每种方法,我们使用超参数调优器进行数千次实验以找到最佳超参数设置。在超参数调优器为每种方法找到最佳超参数后,我们在训练数据集上使用随机参数初始化对每种方法进行 400 次训练,并在测试数据集上报告结果。
6.3.2 结果
对于这两个组,我们报告了 400 次运行的平均 AUC,以及获得最佳主要任务性能的运行的 AUC。 表 1 和表 2 显示了两组任务的结果。 我们还通过为每个任务训练一个单独的模型并报告它们的结果。
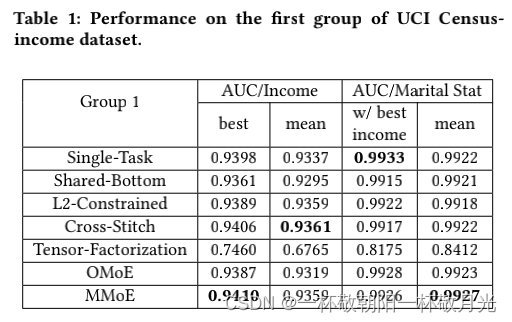
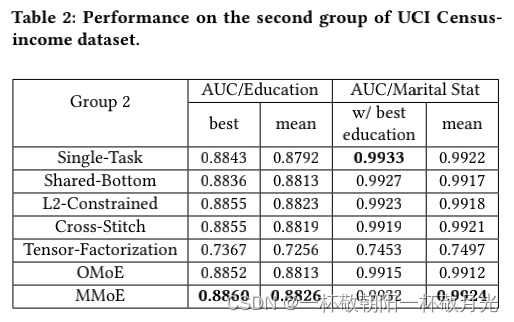
鉴于任务相关性(通过 Pearson 相关性粗略衡量)在任一组中都不是很强,Shared-Bottom 模型几乎总是多任务模型中最差的(除了 Tensor-Factorization)。 L2-Constrained 和 Cross-Stitch 对每个任务都有单独的模型参数,并添加了对这些参数添加了约束,因此比 Shared-Bottom 表现更好。然而,对模型参数学习的约束在很大程度上依赖于任务关系假设,这不如 MMoE 使用的参数调制机制(parameter modulation mechanism)灵活。因此 MMoE 在第 2 组中在所有方面都优于其他多任务模型,其中任务相关性甚至小于第 1 组。
Tensor-Factorization 方法在两组中都是最差的。这是因为它倾向于将所有任务的隐藏层权重推广到低秩张量和矩阵中(This is because it tends to generalize the hidden-layer weights for all of the tasks in lower rank tensor and matrices)。这种方法可能对任务相关性非常敏感,因为当任务不太相关时,它往往会过度泛化,需要更多的数据和更长的训练时间。
多任务模型没有针对验证集上的辅助任务婚姻状况任务进行调整,但是单任务模型是调优过的。所以单任务模型在辅助任务上获得最佳性能是合理的。
6.4 Large-scale Content Recommendation
在本小节中,我们在 Google Inc. 的大规模内容推荐系统上进行实验,其中推荐是从数十亿用户的数亿个独特item中生成的。具体来说,给定用户当前消费商品的行为,该推荐系统旨在向用户显示接下来可能消费的相关商品列表。
我们的推荐系统采用了与一些现有内容推荐框架 [11] 中提出的相似的框架,它有一个候选item生成器,然后是一个深度排序模型。我们设置中的深度排序模型经过训练以优化两种类型的排名目标:(1)优化参与相关的目标,例如点击率和参与时间; (2)针对满意度相关的目标进行优化,例如喜欢率。我们的训练数据包括数千亿的用户隐式反馈,例如点击和喜欢。如果单独训练,每个任务的模型需要学习数十亿个参数。因此,与单独学习多个目标相比,Shared-Bottom 架构具有模型尺寸更小的优势。事实上,这种 Shared-Bottom 模型已经在生产中使用了。
6.4.1 实验设置
我们通过为深度排序模型创建两个二分类任务来评估多任务模型:(1)预测用户参与相关的行为; (2)预测与用户满意度相关的行为。我们将这两个任务命名为参与子任务和满意度子任务(engagement subtask and satisfaction subtask)。
我们的推荐系统对稀疏特征使用嵌入,并将所有稠密特征归一化 [0, 1] 。对于 SharedBottom 模型,我们将共享底部网络实现为一个前馈神经网络,其中包含多个具有 ReLU 激活的全连接层。在共享底层网络之上为每个任务各自构建全连接层用作塔式网络。对于 MMoE,我们只需将共享底层网络的顶层更改为 MMoE 层,并保持输出隐藏单元具有相同的维度。因此,我们不会在模型训练和服务中增加额外且显著的计算成本。我们还实现了基线方法,例如 L2-Constrained 和 Cross-Stitch。由于它们的模型架构,与 Shared-Bottom 模型相比,它们的参数数量大约增加了一倍。我们不与 Tensor-Factorization 进行比较,因为如果没有大量的效率工程,Tucker product的计算无法扩展到十亿级。所有模型都使用批量大小为 1024 的小批量随机梯度下降 (SGD) 进行优化。
6.4.2 离线评估结果
对于离线评估,我们在固定的 300 亿用户隐式反馈集上训练模型,并在 100 万个保留数据集上进行评估。鉴于满意度子任务的标签比参与子任务稀疏得多,因此离线结果具有非常高的噪声水平。我们只在表 3 中显示了参与子任务的 AUC 分数和 R-Squared 分数。
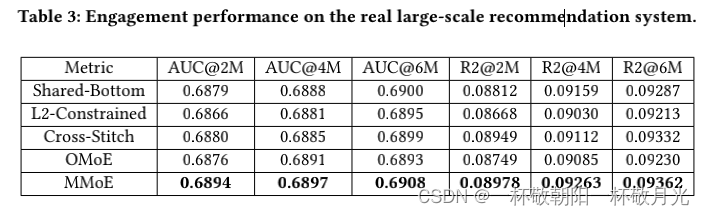
我们展示了训练 200 万步(100 亿个示例,批量大小为 1024)、400 万步和 600 万步后的结果。 MMoE 在这两个指标方面都优于其他模型。 L2-Constrained 和 Cross-Stitch 比 Shared-Bottom 模型差。这可能是因为这两个模型建立在两个单独的单任务模型上,并且模型参数太多而无法很好地约束。
为了更好地理解门是如何工作的,我们在图 6 中展示了每个任务的 softmax 门的分布。我们可以看到 MMoE 学习这两个任务之间的差异并自动平衡共享和非共享参数。由于满意度子任务的标签比参与子任务的标签更稀疏,因此满意度子任务的门更侧重于单个专家。

6.4.3 线上实验结果
最后,我们在内容推荐系统上对我们的 MMoE 模型进行了 线上实验。我们不会对 L2 约束和Cross-Stitch方法进行线上实验,因为这两种模型都通过引入更多参数使服务时间加倍。
我们进行了两组实验。第一个实验是比较 Shared-Bottom 模型和 Single-Task 模型。 Shared-Bottom 模型针对参与子任务和满意度子任务进行训练。单任务模型仅针对参与子任务进行训练。请注意,虽然没有针对满意度子任务进行训练,但 Single-Task 模型在测试时用作排序模型,因此我们还可以计算其满意度指标。第二个实验是将我们的 MMoE 模型与第一个实验中的 Shared-Bottom 模型进行比较。这两个实验都是使用相同量的实时流量完成的。
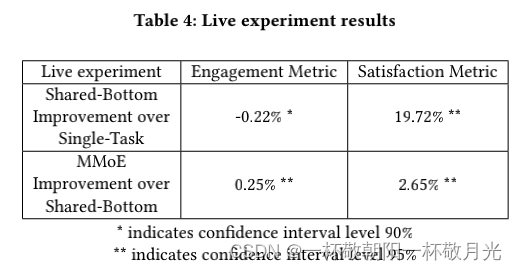
表 4 显示了这些线上实验的结果。首先,通过使用 Shared-Bottom 模型,我们看到满意度指标的巨大提升 19.72%,而参与度指标略有下降 -0.22%。其次,通过使用 MMoE,与 Shared-Bottom 模型相比,我们改进了这两个指标。在这个推荐系统中,参与度度量具有比满意度度量更大的原始值,并且希望在提高满意度度量的同时没有参与度度量损失甚至增加。
7 CONCLUSION
我们提出了一种新颖的多任务学习方法,即Multi-gate MoE(MMoE),它明确地学习从数据中建模任务关系。我们通过对合成数据的控制实验表明,所提出的方法可以更好地处理任务不太相关的场景。我们还表明,与基线方法相比,MMoE 更容易训练。通过在基准数据集和真正的大规模推荐系统上的实验,我们证明了所提出的方法在几个最先进的基线多任务学习模型上的成功。
除了上述好处之外,真实机器学习生产系统中的另一个主要设计考虑因素是计算效率。这也是 Shared-Bottom 多任务模型被广泛使用的最重要原因之一。模型的共享部分在服务时节省了大量计算 [18, 29]。所有三个最先进的基线模型(参见第 6.1 节)都在失去这种计算优势的情况下学习任务关系。然而,MMoE 模型在很大程度上保留了计算优势,因为门控网络通常是轻量级的,并且专家网络在所有任务中共享。此外,该模型有可能通过将门控网络作为稀疏 top-k 门 [31] 来实现更好的计算效率。我们希望这项工作能激励其他研究人员使用这些方法进一步研究多任务建模。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









