










使用springboot+vw-crawler轻松抓取CSDN的文章
有关VW-Cralwer的介绍可以看这里,简单轻便开源的一款Java爬虫框架。
下面结合比较流行的框架SpringBoot抓取CSDN的数据(有关的Spingboot的使用可以参考这里)
配置POM
使用Springboot做架构,redis做数据存储,vw-crawler做爬虫模块,最终的pom如下
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.3.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<vw-crawler.version>0.0.4</vw-crawler.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<!--这里不需要web服务,只需要Application即可-->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.github.vector4wang</groupId>
<artifactId>vw-crawler</artifactId>
<version>0.0.5</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-redis</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.7</version>
</dependency>
</dependencies>redis相关配置
因为已经添加了redis的相关依赖,只需要在application.properties里配置redis的链接参数即可,如下
# Redis数据库索引(默认为0)
spring.redis.database=1
# Redis服务器地址
spring.redis.host=localhost
# Redis服务器连接端口
spring.redis.port=6379
# Redis服务器连接密码(默认为空)
spring.redis.password=
# 连接池最大连接数(使用负值表示没有限制)
spring.redis.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.pool.max-wait=-1
# 连接池中的最大空闲连接
spring.redis.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.pool.min-idle=0
# 连接超时时间(毫秒)
spring.redis.timeout=0代码里的使用
@Component
public class DataCache {
@Autowired
private StringRedisTemplate redisTemplate;
public void save(Blog blog) {
redisTemplate.opsForValue().set(blog.getUrlMd5(), JSON.toJSONString(blog));
}
public Blog get(String url) {
String md5Url = Md5Util.getMD5(url.getBytes());
String blogStr = redisTemplate.opsForValue().get(md5Url);
if (StringUtils.isEmpty(blogStr)) {
return new Blog();
}
return JSON.parseObject(blogStr, Blog.class);
}
}比较简单,一个保存一个获取即可,这里使用StringRedisTemplate时为了更直观的在redis客户端中查看内容。
爬虫
页面数据model
使用流行的注解方式来填充数据
@CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-title-box > h1", resultType = SelectType.TEXT)
private String title;
@CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-info-box > div > span.time", dateFormat = "yyyy年MM月dd日 HH:mm:ss")
private Date publishDate;
@CssSelector(selector = "#mainBox > main > div.blog-content-box > div.article-info-box > div > div > span", resultType = SelectType.TEXT)
private String readCountStr;
private int readCount;
@CssSelector(selector = "#article_content",resultType = SelectType.TEXT)
private String content;
@CssSelector(selector = "body > div.tool-box > ul > li:nth-child(1) > button > p",resultType = SelectType.TEXT)
private int likeCount;
/**
* 暂时不支持自动解析列表的功能,所以加个中间变量,需要二次解析下
*/
@CssSelector(selector = "#mainBox > main > div.comment-box > div.comment-list-container > div.comment-list-box",resultType = SelectType.HTML)
private String comentTmp;
private String url;
private String urlMd5;
private List<String> comment;使用选择器来精确定位数据,使用chrome浏览器的可以这样快速获取
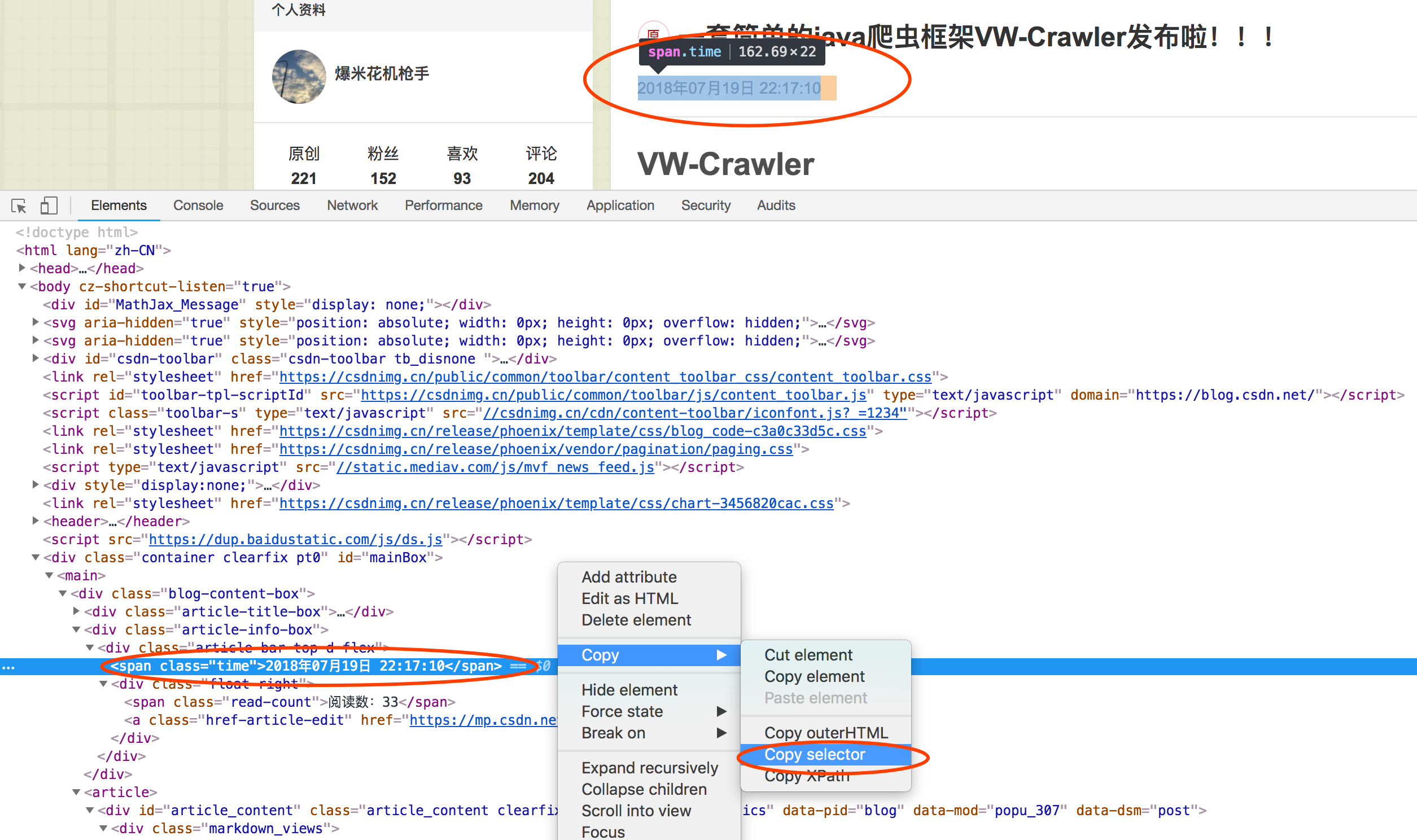
如图,也支持xpath的快捷选择(vw-crawler后续会支持xpath定位元素),当然了,有些元素如”阅读数:xxx”,是不能自动转化为整型,所以还需要第二次解析处理
爬虫配置
这里需要配置请求头如“User-Agent”,目标页URL的正则表达式,列表页URL的正则,还有爬虫的线程数和超时等等,如下
new VWCrawler.Builder().setUrl("https://blog.csdn.net/qqhjqs").setHeader("User-Agent",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36")
.setTargetUrlRex("https://blog.csdn.net/qqhjqs/article/details/[0-9]+").setThreadCount(5)
.setTimeOut(5000).setPageParser(new CrawlerService<Blog>() {
@Override
public void parsePage(Document doc, Blog pageObj) {
pageObj.setReadCount(Integer.parseInt(pageObj.getReadCountStr().replace("阅读数:", "")));
pageObj.setUrl(doc.baseUri());
pageObj.setUrlMd5(Md5Util.getMD5(pageObj.getUrl().getBytes()));
}
@Override
public void save(Blog pageObj) {
dataCache.save(pageObj);
}
}).build().start();需要实现CrawlerService,看下源码
public boolean isExist(String url){
return false;
}
public boolean isContinue(Document document){
if (document == null) {
return false;
}
return true;
}
public abstract void parsePage(Document doc, T pageObj);
public abstract void save(T pageObj);可以看到parsePage可以处理数据的二次解析,save则负责保存数据,isExist和isContinue是处理爬取过程中的一些判断逻辑
- isExist 是url的二次判重,你可以通过查找数据库来判断即将要抓取的URL是否存在数据库中,存在则返回true,不存则正常抓取即返回false;
- isContinue 是在解析页面数据前判断一下该页面是否有WAF(Web Application Firewal),如果有则返回false,没有则正常进行解析即返回true;
要在springboot全部初始化完毕之后再去启动爬虫, 所有需要这样配置
@Component
@Order
public class Crawler implements CommandLineRunner {
@Autowired
private DataCache dataCache;
@Override
public void run(String... strings) {
// 爬虫配置
}
}启动
直接右键执行CrawlerApplication即可
最终抓取如图
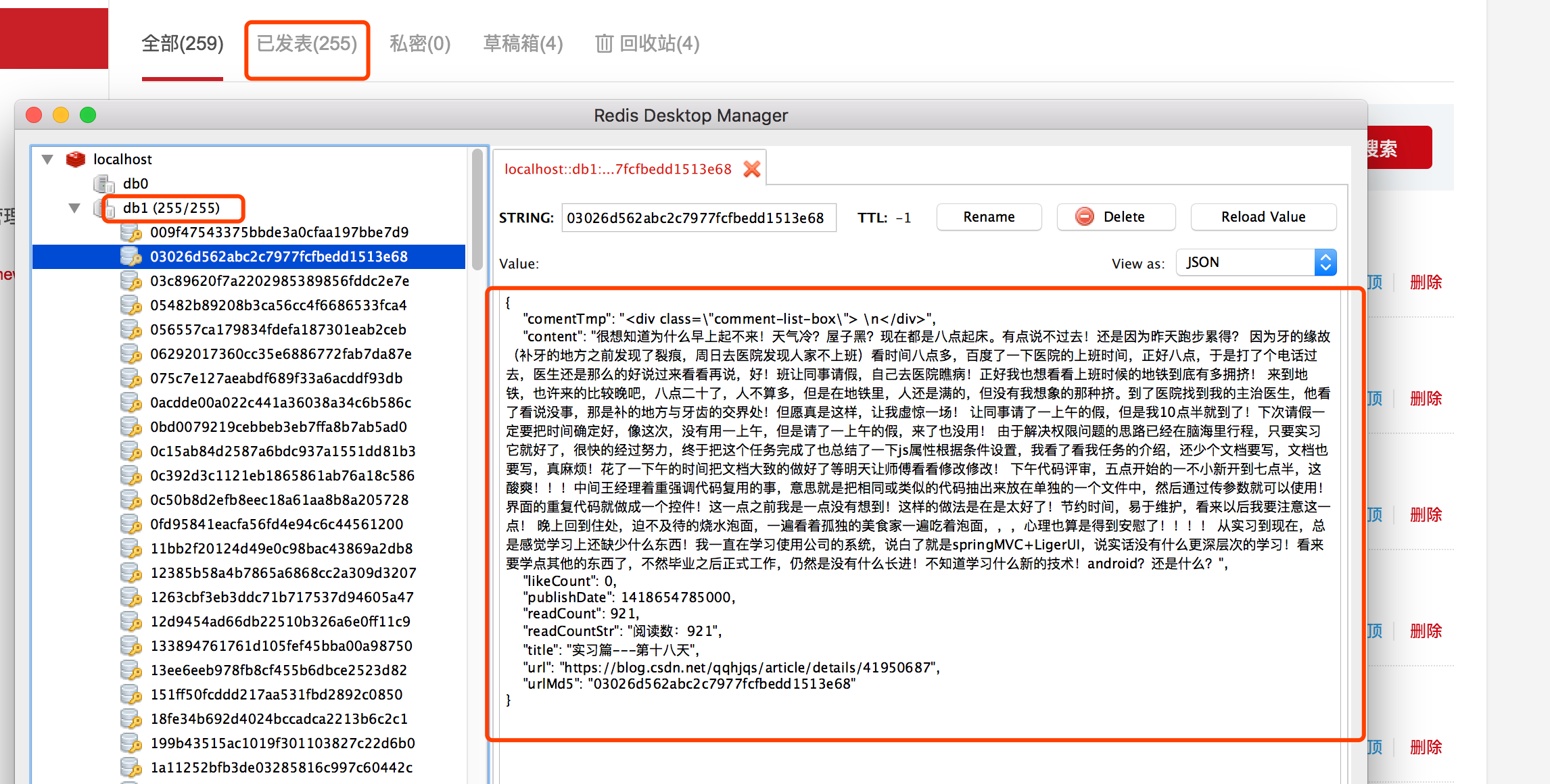
相关链接
该爬虫地址:传送门
![]()
![]()
![]()
![]()
![]()















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









