






 本文详细介绍了Zookeeper的起源、作用、结构、数据模型、集群服务状态、特性和监听机制-Watcher,揭示了它在分布式系统中作为协调者的重要性。Zookeeper作为一个分布式协调服务,解决了一致性问题,广泛应用于Kafka、Dubbo、Spark等开源项目。它通过数据发布/订阅、命名服务、分布式锁等功能,实现了高效的数据管理和分布式协调。
本文详细介绍了Zookeeper的起源、作用、结构、数据模型、集群服务状态、特性和监听机制-Watcher,揭示了它在分布式系统中作为协调者的重要性。Zookeeper作为一个分布式协调服务,解决了一致性问题,广泛应用于Kafka、Dubbo、Spark等开源项目。它通过数据发布/订阅、命名服务、分布式锁等功能,实现了高效的数据管理和分布式协调。
我也是初学zk,整理下资料,希望能对你有帮助!
提起zk我们总会想到,zk可以被用作注册中心、构建zk集群时候节点最好为奇数……
可见我们对zk理解仅仅停在表面。那么zk到底是什么呢 ?
一、什么是zk?
了解zk之前我们首先要知道zk由来,zk能帮助我们做些什么事情?
1.1zk由来
举个例子,小王想找A团队安排点任务,所以小王找了A团队的leader小李,因为小李可以管理团队的成员,知道团队内的大大小小事情。小李协调安排了合适的人帮小王解决了需求。
那么小李,实际上承担了团队里面的协调作用,同样来说分布式系统也相当于一个团队,也需要这么一个协调者。如果小李不存在会出什么问题呢 ?
假设一个团队有三个员工:s1、s2、s3 (一个集群下三个服务)
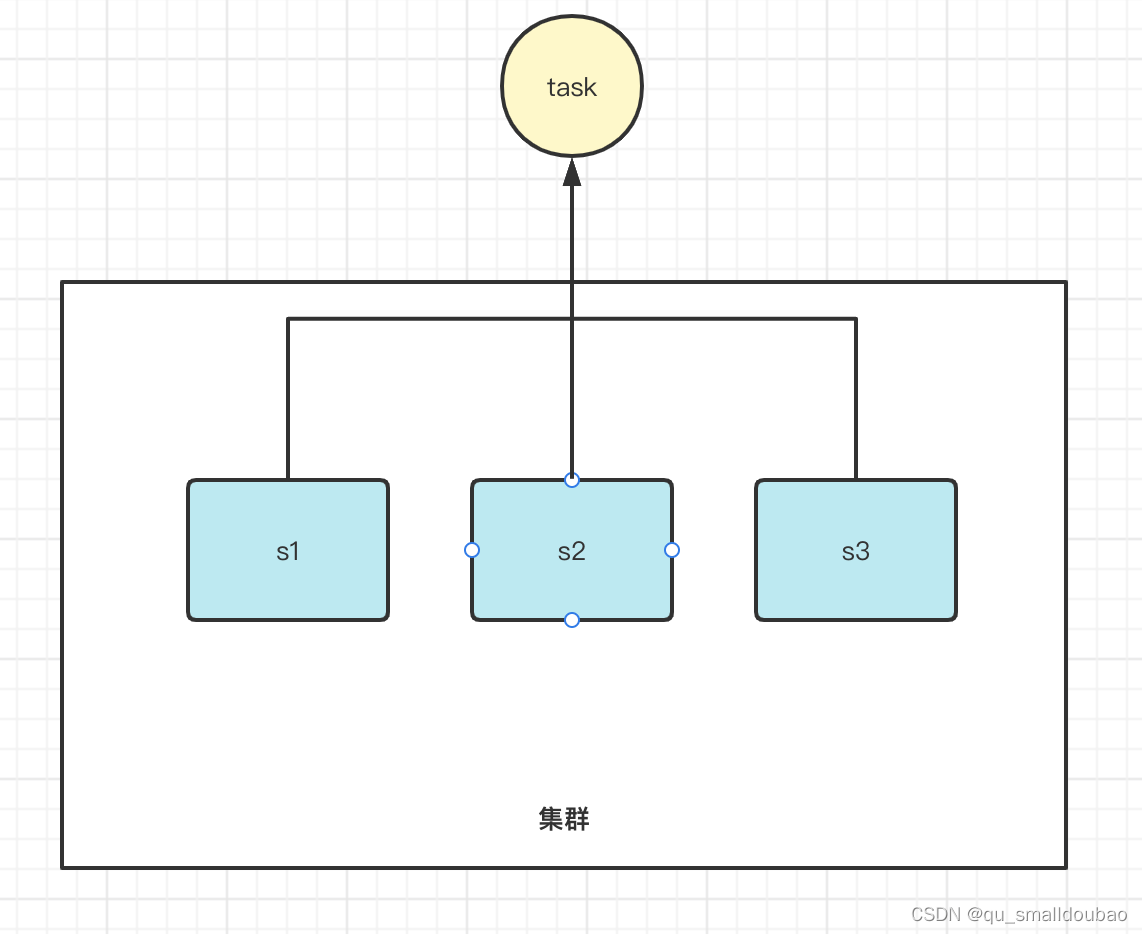
这时候小王提出了几个问题:
1.s1员工换了一个工位(ip),防止其他员工找不到自己,怎么同步给其他员工呢?(每个服务都有一个配置文件,配置文件中信息动态变更,如何保证各节点数据一致性?)
2.来了一个新任务怎么分配给某个员工做?(保证一个任务只在一个service执行)
3.员工s1辞职了,怎么通知其他员工,并把工作交接给别的员工?(某个service挂掉如何通知给其他service并接替它的任务?)
4.三个员工做任务时候都涉及到了一个公共文件,怎么保证这几个员工有序看这个文件并且保证这个文件在看的时候没有被另一个人修改?(保证节点当问共享资源的互斥性和安全性,类似多线程访问同一资源)
这时候就体现了小李承担着分布式协调的工作,我们都知道CAP理论,在选小李这样人才时候不由得思考到底是把CP还是AP放到第一位,选择CP我们就可以在同一时间同步员工信息相同,但是需要容忍一定的同步时间;AP就是需要容忍数据不一致问题,但是确保了员工们都正常给我们做任务。
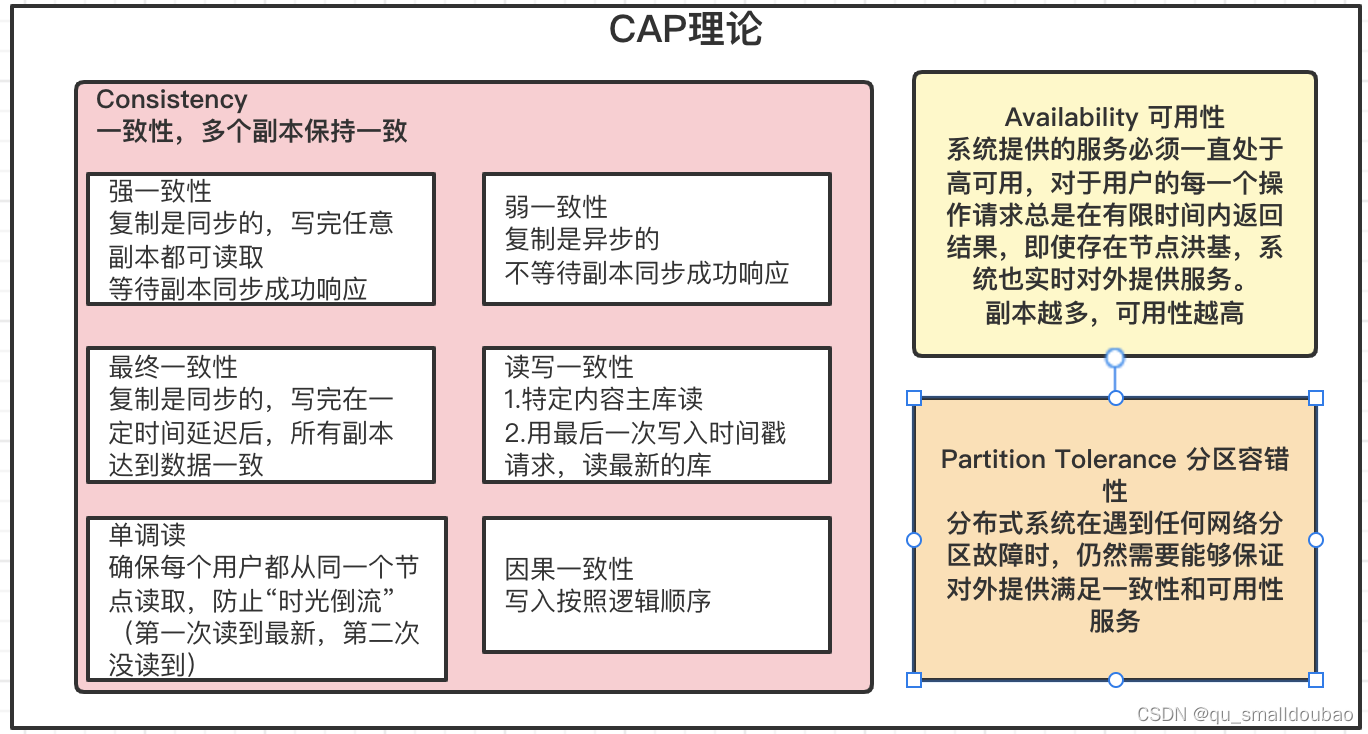
其中zookeeper就是运用cp理论的分布式协调系统佼佼者。
如果把每个节点比喻成各种小动物,那zookeeper就是动物园管理员,这也是zookeeper名字由来

1.2简介
zk设计目标就是作为一个集群提供数据一致的协调服务,在整个及群众负责各个节点数据复制和同步。
zk是一个分布式协调服务,目的解决分布式一致性问题 。底层基于类似于文件系统的目录节点树的方式进行数据存储,同时维护和监控存储数据的状态变化,通过监控这些数据状态变化,从而达到基于数据的集群管理。
让我们看下官网的介绍

1.3应用场景
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master 选举
- 分布式锁
- 分布式队列
许多开源应用都用到了zk,例如Kafka、Dubbo、Spark、Hbase等
上面zk提供的一些核心功能,后续会讲几个核心中的核心~
二、结构
核心:利用自己文件系统,同时这个文件系统可以监控目录变化 (文件系统+通知机制)
2.1 集群架构
宏观结构:
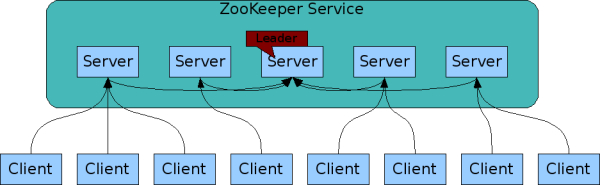
zk集群中的server有3种角色:
leader:选举产生,负责进行投票的发起和决议,更新状态和数据。(不直接处理clieant请求,但是接受由其他follower和observer的请求)
follower:接受client请求并返回结果,在选举过程参与投票。
observer:接受client链接,写操作会转给leader,不参与投票只同步leader状态。
为什么引入observer?
为了扩展系统,提供读取速度。不参与投票因此不影响投票耗时,也不影响集群选举。
运行模式:
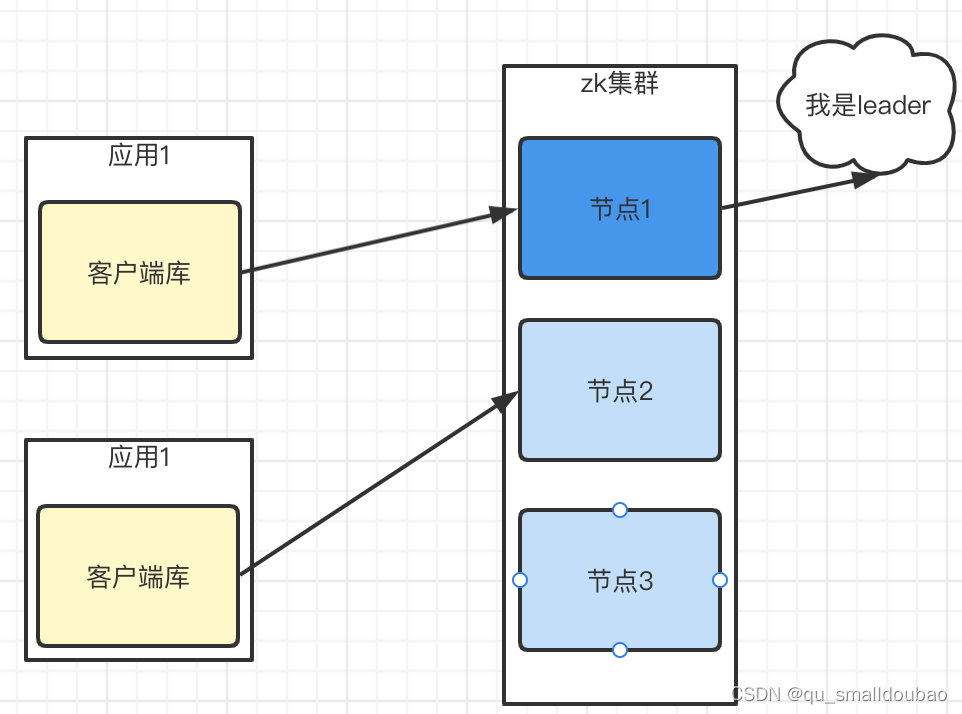
应用使用 zk client库调用zk server,zk client会和集群中某一个节点建立 session, zk client 负责与zk server集群交互。每个client导入客户端库,便可和任何一个zk节点通信。
重连:client也可以主动关闭session,如果zk节点没有在timeout时间内收到session关联的客户端数据的话,zk节点也会关闭session。另外如果client库如果发现链接的zookeeper出错,会自动和其他的zk节点建立连接。
比如:应用1的客户端库和节点1建立session,一段时间后节点1down掉了,该客户端就自动和节点3建立了session链接
session会话
客户端与服务端建立会话后才能通信。客户端所有操作均关联到一个会话上。
当session因为某原因种植时,这个会话期间创建的临时节点将会消失。
session中请求会FIFO顺序执行,,如果客户端拥有多个并发的session,多个会话中FIFO顺序未必能保持。
session有几种生命周期感兴趣的同学可以了解下。
zk集群有两种模式:
- standalone 模式 -- 独立模式 (一个独立运行的节点,zk状态无法复制)
- quorum模式 -- 仲裁模式 (一组zk节点-zk集合,可以进行状态的复制,同时为client提供)
举例一个kafka应用场景:

(此图引用:浅谈我们为什么需要zookeeper?_高世之智的博客-CSDN博客_为什么需要zookeeper)
2.2 数据模型
下图是zk命名空间和标准文件系统的名称空间非常相似
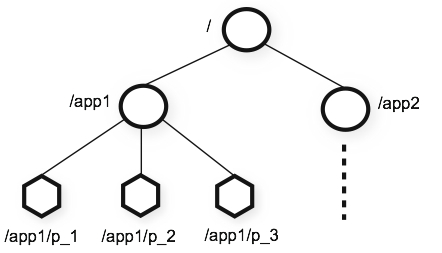
zk会维护一个具有层次关系的数据结构,类似于一个分布式文件系统,zk中每个节点都是一个路径作为唯一标识,节点可以具有关联的数据+子节点,其叫做数据节点znode,znode可以存储1MB数据
如图展示了zk的两个节点:

znode特点:
- 每个子目录项如/hello都被叫做znode(路径唯一标识)
- znode有版本,也就是一个路径可以存储多份数据
- znode可以有子节点目录,也可以存储数据(EPHEMERAL类型不能有子节点目录)
- znode可以是临时节点,删除条件:1.客户端与服务器失去联系2.客户端和服务器采用长连接方式,通过心跳机制保持连接,连接状态称之为session,session失效时候znode会被删除
- znode目录名字可以自动编号,/test1存在就递推/test2
- znode会被监控(watch机制),比如存储数据修改,子节点目录变化,一旦变化就可以通知监控的客户端
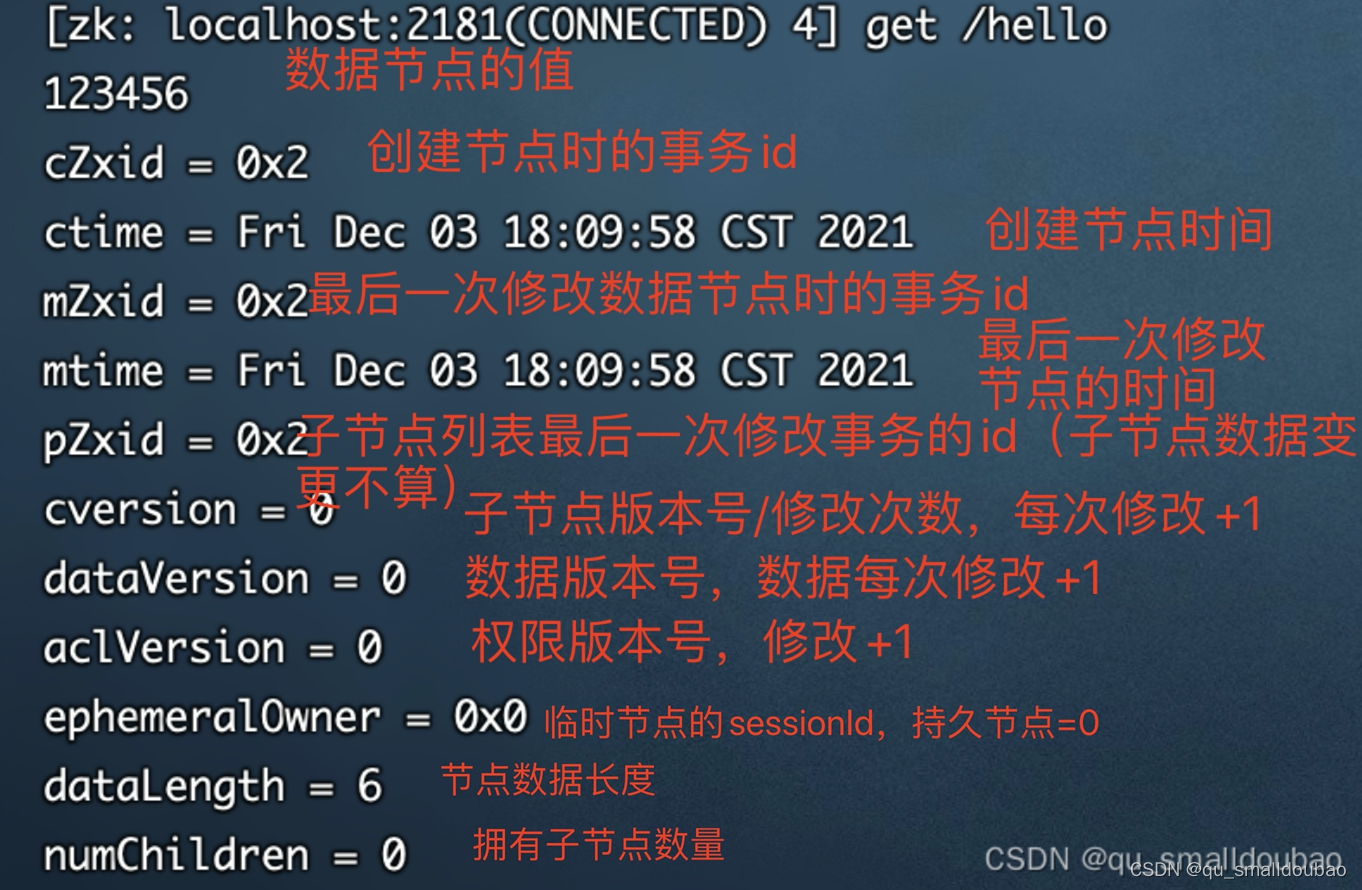
每个znode都维护stat的数据结构,里面存储了该节点的全部状态信息。
stat:
2.3 服务节点类型
- 持久节点:客户端与server断开时候节点也存在,除非手动删除
- 临时节点:1.客户端会话超时或者主动关闭会被自动删除 2.手动删除
- 持久顺序:创建节点时,zk会自动在路径后加上后缀(路径+数字后缀),比如/test_ 会加上/test_1
- 临时顺序节点:临时+顺序
- 容器:表现形式和持久节点是一样的,但是区别是 ZK 服务端启动后,会有一个单独的线程去扫描所有的容器节点,当发现子节点数量为 0 时,会自动删除该节点,除此之外和持久节点没有区别,官方注释给出的使用场景是 Container nodes are special purpose nodes useful for recipes such as leader, lock, etc. 说可以用在 leader 或者锁的场景中。
- TTL:TTL=time to live,该节点分为持久TTL和持久顺序TTL,默认禁用,通过系统配置 zookeeper.extendedTypesEnabled=true 开启(不开启会收到 Unimplemented 的报错),不稳定。该节点在没有子节点情况下,超过指定存活时间就会被删除
2.4集群服务状态
在了解集群服务状态前,我们都了解了一个集群中不同的server都扮演着不同的角色以及分工,
先普及下server接收到的请求类型:
1.事务请求:
会改变服务器状态的请求称为事务请求(创建节点、更新数据、删除节点、创建会话……)2.非事务请求
从zk读取数据但是不对状态进行任何修改的请求称为非事务请求
那么下面来看下各个角色的分工
| 角色 | 工作 |
| leader | 1.事务请求唯一调用者和请求者2.集群内部各个服务器的调用者 |
| follwer | 1.处理非事务请求2.转发事务请求给leader3.参与leader选举4.参与事务请求的proposal投票 |
| observer | 1.观察集群最新状态并同步2.处理非事务请求3.事务请求转发给leader4.不参与事务proposal投票和leader选举投票 |
什么是事务投票?
Proposal又是个啥?为了保证事务的顺序一致性,我们为每个事务都标记了一个事务id ,也就是zxid(每个人的身份证号)
zxid占64位 = 高32位标识epoch(每个leader独有标志) +低32位用递增计数
每个事务请求都需要过半机器投票才能被真正应用到ZK的内存数据库中,这个投票+统计过程被称为
Proposal流程。
有了这几种角色,也就是我们团队里面有了角色的员工,那么当员工状态发生改变会有哪几种情况呢 ?
服务器状态:
- LOCOKING :寻找leader状态,当前集群没有leader,因此进入选举状态 (老大小王跑路了,我们群龙无首啊,内部选个吧那就)
- FOLLOWING:表达当前server是追随者状态 (找来个新leader马云先生,我们很敬佩他,追随他叫他马云爸爸)
- LEDERING:领导者状态
- OBSERVING:观察者状态 (一群吃瓜群众,偶尔也能传传话)
三、特性
- 顺序一致性 同一客户端发起的事务请求,最终会严格的按照顺序被执行。(客户让我们先做A再做B项目,我们就严格执行)
- 可靠性 一旦更改请求被应用,更改结果就会被持久化,直到下一次更改覆盖。(客户说改个数据,所有员工都执行)
- 原子性 所有事务请求处理结果在集群中所有应用情况都是一致的,也就是所有机器都应用了这个事务,要不就没应用。(所有员工有个任务都一起做,要么一起都做完,有一个没做完就返工)
- 最终一致性 客户端无论连接哪个服务器上,看到的数据模型都是一致的
四、监听机制-Watcher
Watcher机制时zk中重要特性
1.监听机制本质是什么?
实现分布式数据发布/订阅功能
发布订阅模型实际上时一对多的订阅关系,多个订阅者订阅一个topic,当topic有新通知会通知订阅者,让订阅者做相应处理。
watcher监听就实现了这个分布式通知功能。
2.监听机制实现
客户端收到集合数据更改的通知,client可以在读取的指定znode时设置watches,(客户端注册表)watches会向注册的client发送关于znode更改的通知(比如监听节点数据变更、节点删除、子节点状态变更等事件)。
例如:这里新增一个子节点就可以观察watcher监听事件的变化
[zk: localhost:2181(CONNECTED) 1] ls /hello watch
[]
[zk: localhost:2181(CONNECTED) 2] create /hello/test abc
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/hello
Created /hello/test
通过这个事件机制,可以基于zl实现分布式锁、集群管理等功能。
当节点变更时,zk产生一个watcher事件并发送到client,但是client只会收到一次通知,也就是后续节点再发生变化就不会再次收到通知。(watcher是一次性的),可以通过循环监听去实现永久监听。比如说我再建立一个子节点,此时就没有触发监听事件
3.监听流程
总体分三个过程:客户端注册watcher、服务器处理watcher、客户端回调watcher客户端
注册watcher的方式:
- getData
- exists
- getChildren
触发事件通知类型:
按通知状态划分有SyncConnected,Disconnected,Expired,AuthFailed等好多种,这里介绍SyncConnected下的几种类型:
None (-1) #客户端链接状态发生变化的时候,会收到 none 的事件
NodeCreated (1) #创建节点的事件。
NodeDeleted (2) #删除节点的事件
NodeDataChanged (3) # 节点数据发生变更
NodeChildrenChanged (4) #子节点被创建、被删除、会发生事件触发
工作流程图:
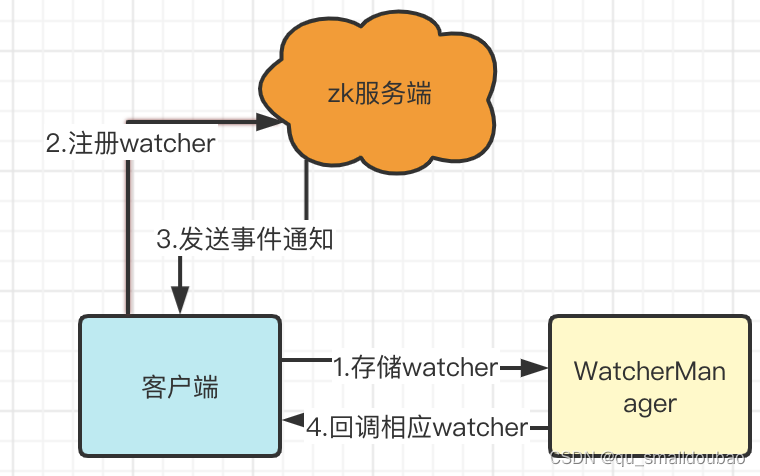
- client会将创建的watcher对象存储在客户端的WatcherManager中,用来管理各种监听器
- client向zk服务器注册监听器,可以监听节点的数据和子节点
- 当服务器处罚watcher事件后会发送事件通知打client
- 把wacher对象发送到WatcherManager中,更新wacher对象中内容。client从WatcherManager再次获取watcher对象,最后进行接收到通知后的逻辑处理
4.特性
- 一次性
- 客户端回调串行执行 (保证执行顺序,客户端本地维护一个接收队列,客户端串行有序回调)
- 客户端需要接受到通知后主动回调才能获取到节点信息变化。 (当监听器监听的事件被触发,服务端会发送通知给客户端,但通知信息中不包括事件的具体内容。以监听ZNode结点数据变化为例,当Znode的数据被改变,客户端会收到事件类型为NodeDataChanged的通知,但该Znode的数据改变成了什么客户端无法从通知中获取,需要客户端在收到通知后手动去获取)
5.总结:
监听机制通过get,exists,getchildren三种方式注册来实现对某个节点的监听,在节点变更时做一次性通知,实现分布式数据的发布/订阅功能。
(监听机制只介绍了大致的流程和概念,后续会讲解具体的实现!)

















 2974
2974

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









