







目标
这里带大家用最简单的代码,了解线程池的工作原理
线程池实现原理
- 定义成员变量 包含核心线程数、最大线程数、阻塞队列、拒绝策略、当前线程数
- 当线程数小于核心线程数我们创建新的线程
- 当线程数大于核心线程,填入队列
- 如果队列装入失败,则判断是否达到最大线程数,没有达到就继续创建,否则就执行拒绝策略
开始编码
首先实现jdk底层接口,代表这是一个线程池
public class MyThreadPool implements Executor
//定义几个重要的成员变量
private int coreSize;
private int maxSize;
private BlockingQueue<Runnable> queue;
private RejectPolicy rejectPolicy;
private AtomicInteger totalCount = new AtomicInteger(0);
//仿照ThreadPoolExecutor创建构造方法
public MyThreadPool(int coreSize, int maxSize, BlockingQueue<Runnable> taskQueue, RejectPolicy rejectPolicy) {
this.coreSize = coreSize;
this.maxSize = maxSize;
this.queue = taskQueue;
this.rejectPolicy = rejectPolicy;
}
//这个方法用于创建新线程
private void addWorker(Runnable task) {
int count = totalCount.get();
boolean b = totalCount.compareAndSet(count, count + 1);
if(b){
new Thread(()->{
Runnable newTask = task;
while (newTask!=null || (newTask = getTask())!=null) {
try {
// 执行任务
newTask.run();
} finally {
// 任务执行完成,置为空 这里不置为空会导致任务无限执行
newTask = null;
}
}
},"myzf-threadpool-"+(count+1)).start();
}
}
//这里是从队列中获取任务 使用take()可以阻塞队列
private Runnable getTask(){
try {
return queue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
return null;
}
//核心方法 就是实现java.util.concurrent.Executor的接口方法
@Override
public void execute(Runnable task) {
if(task == null){
throw new NullPointerException("任务不能为空");
}
int i = totalCount.get();
//当前线程数少于核心线程数,执行new Thread()方法
if(i< coreSize){
//创建新的线程
addWorker(task);
}
/**
这里有些不了解线程池原理的人
首次写可能会写成,因为这样比较直观
else if(i<maxSize){
queue.offer(task);
}
道理上这样写可以的,但是有个问题就是,我们是通过totalCount来计算当前实际
线程数的,如果这里执行了入队操作,那么就不好判断出来队列是否满了的情况,
而且当前线程数不好计算了
因为上面private Runnable getTask()方法一直会从队列中取任务,如果任务执行的慢的
话,那么是否创建线程数就无法精准判断了,这样就会导致无法使用设置的最大线程数
这里其实是稍微难理解的地方,可以好好想下
**/
}
//存队列
else {
if(queue.offer(task)){
//入队成功 则说明队列没有满
}else {
//队列满了 判断是否达到最大线程数
if(totalCount.get()<maxSize){
addWorker(task);
}else {
System.out.println("执行拒绝策略");
}
}
}
}
开始测试
测试代码
public static void main(String[] args) {
Executor threadPool = new MyThreadPool("test", 5, 10, new ArrayBlockingQueue<>(15), new RejectPolicy() {
});
AtomicInteger num = new AtomicInteger(0);
for (int i = 0; i < 100; i++) {
threadPool.execute(()->{
try {
Thread.sleep(5000);
System.out.println( Thread.currentThread().getName()+" running: " +System.currentTimeMillis() + ": " + num.incrementAndGet());
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
当执行for循环的时候,这里sleep 5s是为了让当前task占用着任务,不释放线程资源
这样其他的任务来的时候就会执行拒绝策略了
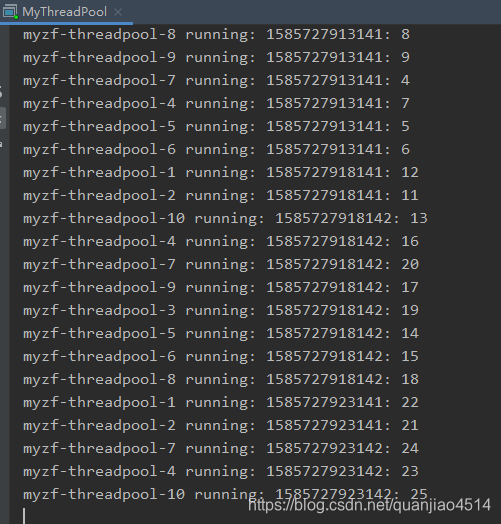
因为我们的最大线程数是10,所以这里可以看到线程id,最大是10,又因为队列容量
是15,所以说一共同时执行的任务就是25个,可以看到计数器只会算到25,说明和
预期的一致,从线程id我们也看出来了,这里我们实现了线程的复用(同一个线程执行了不同任务)
总结
- 线程池复用原理是啥
就是我们定义了一个Runnable的task,因为当执行task.run的时候,就是执行当前的任务
我们把这个任务放在某个线程的whlile循环中,不断从队列中获取任务,获取不到就阻塞
是不是非常的简单了
结尾
这里带大家实现了一个很简单的线程池,其实ThreadPoolExecutor核心原理就是上述代码,它是把线程封装成了一个Worker对象,并且做了其他更规范更严谨的操作,比如使用cas控制队列中获取线程task,每次会从worker队列中获取任务,也就是获取到了thread,当队列为空并且大于核心线程数,小于最大线程数时,会销毁线程,也就是结束某个线程的while循环即可


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









