






1.pom包
<dependency>
<groupId>com.deepoove</groupId>
<artifactId>poi-tl</artifactId>
<version>1.8.1</version>
</dependency>2.合并word工具类
package cn.com.fesco.hpe.config;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xwpf.usermodel.BreakType;
import org.apache.poi.xwpf.usermodel.Document;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFPictureData;
import org.apache.xmlbeans.XmlOptions;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTBody;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.OutputStream;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 参数1:需要合并的word的文件对象list
* 参数2:合并之后word存储的全路径file对象
*/
public class MergeDocUtils {
public static void mergeDoc(List<File> fileList, File newFile) throws Exception {
OutputStream dest = new FileOutputStream(newFile);
ArrayList<XWPFDocument> documentList = new ArrayList<XWPFDocument>();
XWPFDocument doc = null;
for (int i = 0; i < fileList.size(); i++) {
FileInputStream in = new FileInputStream(fileList.get(i).getPath());
OPCPackage open = OPCPackage.open(in);
XWPFDocument document = new XWPFDocument(open);
documentList.add(document);
}
for (int i = 0; i < documentList.size(); i++) {
doc = documentList.get(0);
if (i != 0) {
//documentList.get(i).createParagraph().setPageBreak(true);//实现了分页效果。//但是会出现在首行为空的情况
documentList.get(i).createParagraph().createRun().addBreak(BreakType.PAGE);//现了分页效果。使用这种方式不会出现留白的情况
appendBody(doc, documentList.get(i));
}
}
doc.write(dest);//输出合并之后的文件
}
public static void appendBody(XWPFDocument src, XWPFDocument append) throws Exception {
CTBody src1Body = src.getDocument().getBody();
CTBody src2Body = append.getDocument().getBody();
List<XWPFPictureData> allPictures = append.getAllPictures();
// 记录图片合并前及合并后的ID
Map<String, String> map = new HashMap();
for (XWPFPictureData picture : allPictures) {
String before = append.getRelationId(picture);
//将原文档中的图片加入到目标文档中
String after = src.addPictureData(picture.getData(), Document.PICTURE_TYPE_PNG);
map.put(before, after);
}
appendBody(src1Body, src2Body, map);
}
private static void appendBody(CTBody src, CTBody append, Map<String, String> map) throws Exception {
XmlOptions optionsOuter = new XmlOptions();
optionsOuter.setSaveOuter();
String appendString = append.xmlText(optionsOuter);
//去掉追加word内容中的 w:sectPr 标签,确保合成的word中只有一个 w:sectPr 标签对
//避免合成的word文档打开之后会提示有些内容读不出来,导致文件损坏
String rgex = "<[\\s]*?w:sectPr[^>]*?>[\\s\\S]*?<[\\s]*?\\/[\\s]*?w:sectPr[\\s]*?>";
appendString = appendString.replaceAll(rgex, "");
String srcString = src.xmlText();
String regex = regex(srcString, "w:sectPr");
System.out.println(regex);
String prefix = srcString.substring(0, srcString.indexOf(">") + 1);
String mainPart = srcString.substring(srcString.indexOf(">") + 1, srcString.lastIndexOf("<"));
String sufix = srcString.substring(srcString.lastIndexOf("<"));
String addPart = appendString.substring(appendString.indexOf(">") + 1, appendString.lastIndexOf("<"));
if (map != null && !map.isEmpty()) {
//对xml字符串中图片ID进行替换
for (Map.Entry<String, String> set : map.entrySet()) {
addPart = addPart.replace(set.getKey(), set.getValue());
}
}
//将两个文档的xml内容进行拼接
CTBody makeBody = CTBody.Factory.parse(prefix + mainPart + addPart + sufix);
src.set(makeBody);
}
/**
* 获取指定标签中的内容
*
* @param xml
* @param label
* @return
*/
public static String regex(String xml, String label) {
String context = "";
// 正则表达式
String rgex = "<" + label + "[^>]*>((?:(?!<\\/" + label + ">)[\\s\\S])*)<\\/" + label + ">";
Pattern pattern = Pattern.compile(rgex);// 匹配的模式
Matcher m = pattern.matcher(xml);
// 匹配的有多个
List<String> list = new ArrayList<String>();
while (m.find()) {
int i = 1;
list.add(m.group(i));
i++;
}
if (list.size() > 0) {
// 输出内容自己定义
context = String.valueOf(list.size());
}
return context;
}
}
3.代码实例
//new一个list 模拟要合并的word对象集合
List<File>docFileList = new ArrayList<>();
docFileList.add(new File("D:/pdfData/2022-06-23-2c3d300450884b19bb58585d2c4ae518.docx"));
docFileList.add(new File("D:/pdfData/2022-06-23-4a899305225e4fd8abc7ae154841124c.docx"));
//合并之后doc存储路径 此处读的配置文件的存储路径 D:/pdfData/
String docPath = fileUploadConfig.getDocPath();
//当前日期+UUID作为文件名防止重复
String fileName = LocalDate.now() + "-" + UUID.randomUUID().toString().replaceAll("-", "");
//合并之后doc存储路径
String mergeDocUrl = docPath+fileName+".docx";
//转成file对象
File mergeDocFile = new File(mergeDocUrl);
//合并doc
MergeDocUtils.mergeDoc(docFileList,mergeDocFile);
System.out.println("合并word成功");4.分页问题,我直接读的word模板,填充的数据,下边动态生成的表格
word填充模板,动态生成表格可以看这条poi填充word,动态生成表格+LibreOffice转成pdf_ytqucheng的博客-CSDN博客_poi 动态生成word表格
直接在word模板上需要分页的地方添加分页标识符,
我这里直接在最后一行加的分页标识
下面上图片
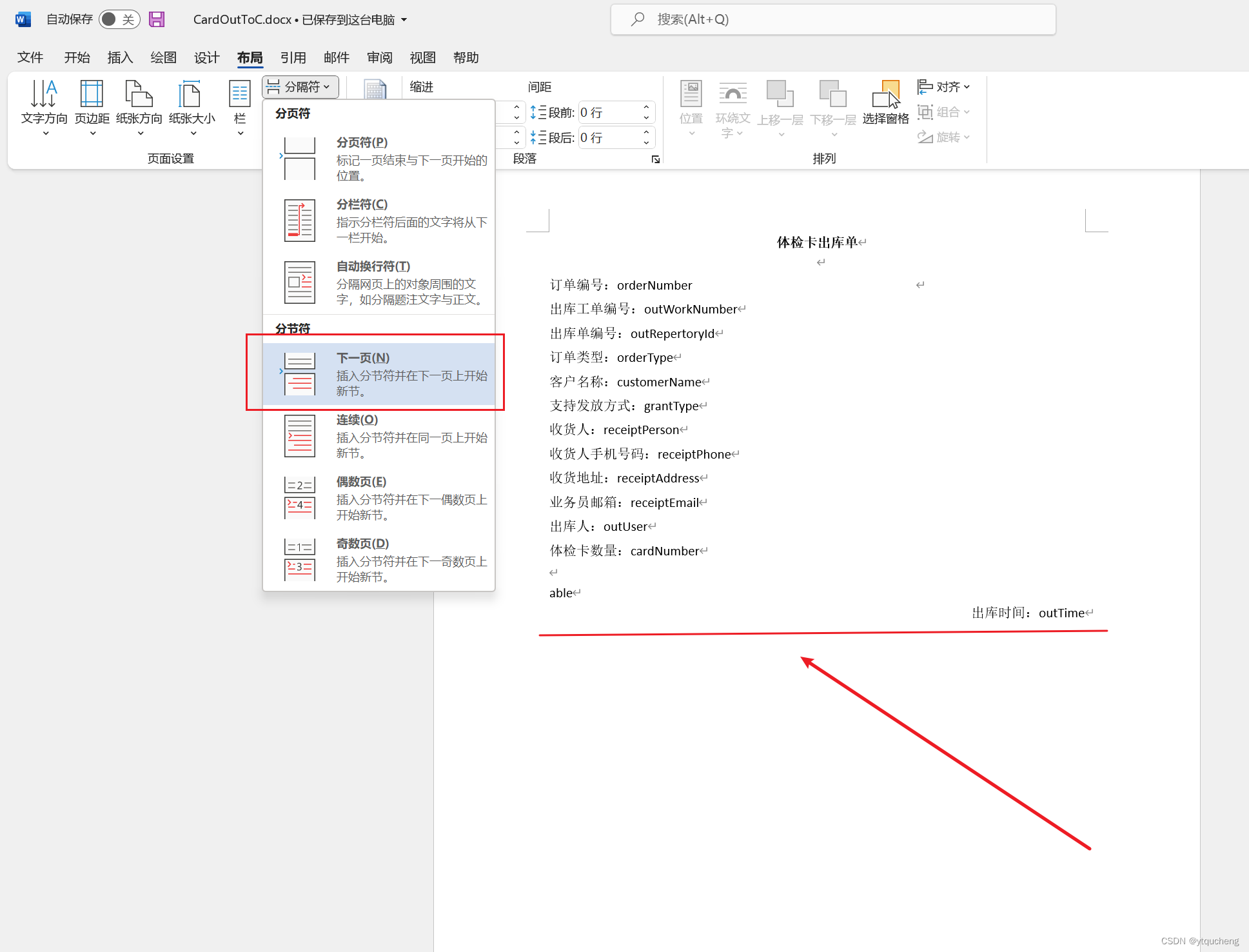
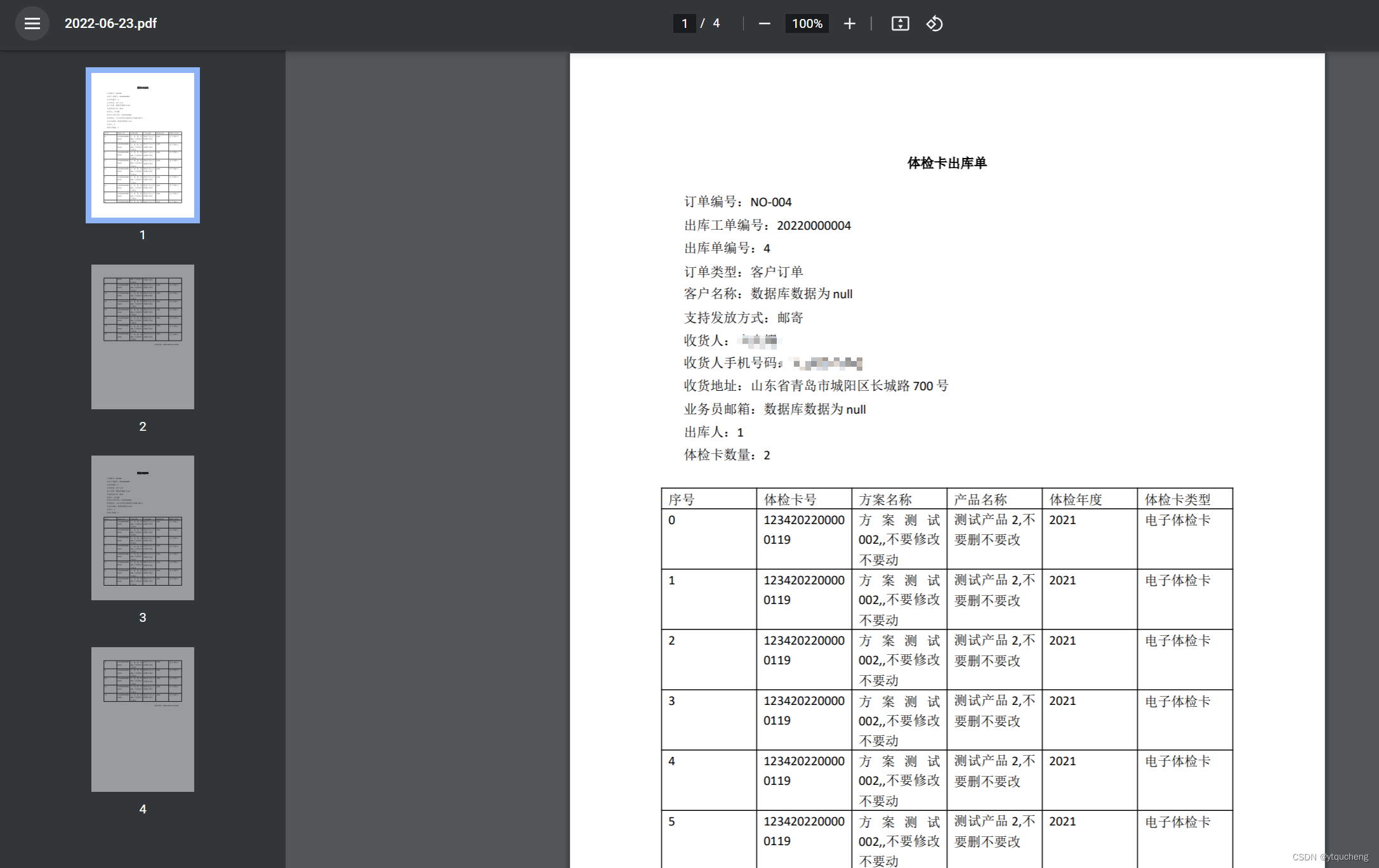
5.效果图


















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









