






1.假设我们有5个请求,batch1、batch2、batch3、batch4、batch5,如果只有batch2 ack
failed,1、3、4、5都保存了,而实际上batch2已经落盘了,只是在ack那一刻网络出现了
问题那么根据底层的retry机制batch2将会随下次batch重发而造成数据重复落盘
2.为了解决retry带来的数据重复落盘的问题,kafka加入了幂等性机制
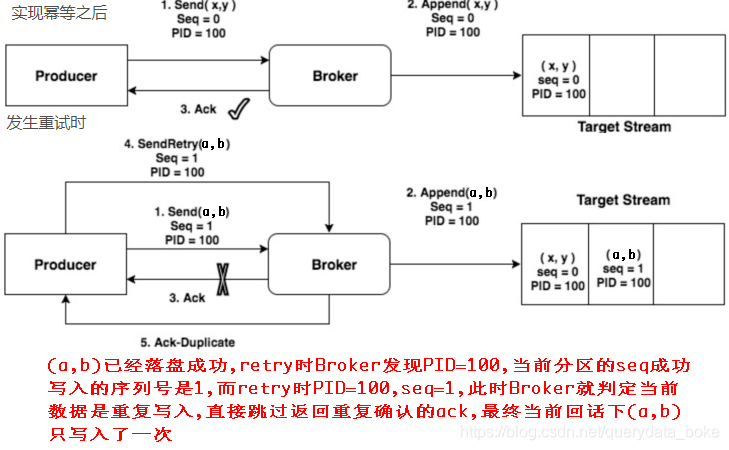
3.为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number
PID:每个新的Producer在初始化的时候会被分配一个唯一的PID,对用户是不可见的
Sequence Numbler:对于每个PID,该Producer发送数据的每个<Topic,Partition>都对应
一个从0开始单调递增的Sequence Number,Broker端在缓存中保存了这seq number,对于
接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃,这样就
可以实现了消息重复提交了.但是只能保证单个Producer对于同一个<Topic,Partition>
的Exactly Once语义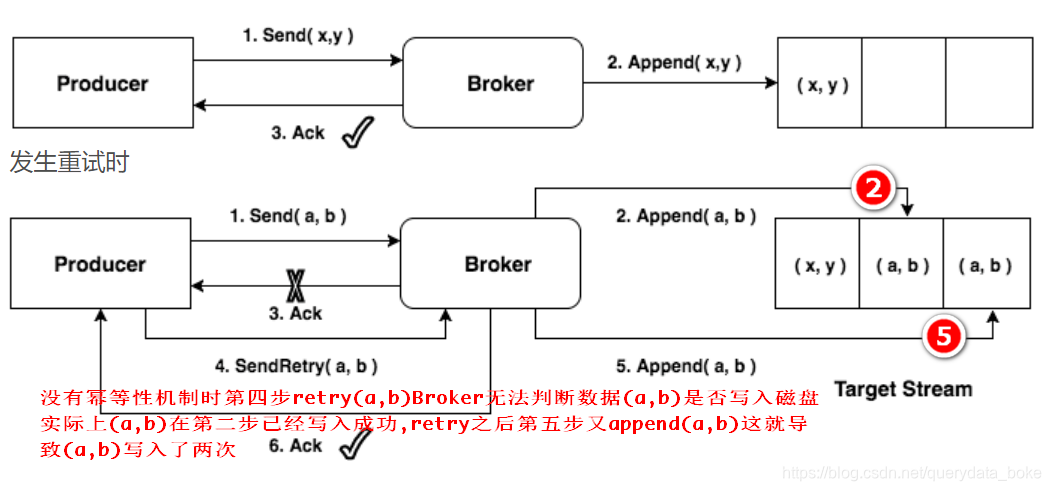
 4.同一PID同一topic不同partition保存的<Topic, Partition,Seq>相互独立
4.同一PID同一topic不同partition保存的<Topic, Partition,Seq>相互独立
5.设置enable.idempotence=true后能够动态调整max.in.flight.requests.
per.connection,正常情况下该参数大于1,当重试请求到来且时,batch会根据seq重新添
加到队列的合适位置,并把max.in.flight.requests.per.connection设为1,这样它前面
的batch序号都比它小,只有前面的batch都发完了,它才能发,这样就解决了数据发送的
乱序问题,但是降低了系统的吞吐量
幂等性实现
Producer使用幂等性的示例非常简单,与正常情况下Producer使用相比变化不大,只需要
把Producer的配置enable.idempotence设置为true即可,如下所示:
Properties props = new Properties();
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
//当enable.idempotence为true时acks默认为 all
// props.put("acks", "all");
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer producer = new KafkaProducer(props);
producer.send(new ProducerRecord(topic, "test");
Prodcuer幂等性对外保留的接口非常简单,其底层的实现对上层应用做了很好的封装,应用
层并不需要去关心具体的实现细节,对用户非常友好

















 2595
2595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









