







文章目录
概述
作为Halcon和Hdevlop的菜鸟选手,bottle.hdev 算是我踏上这条路的第一次实践。
开始学习Halcon后,零零散散地阅读了些资料,并无感,于是决定从示例程序再下手。基于前阵子读了些Blob内容,便在示例程序目录树 [方法 -> Blob分析] 分支下,希望能找到一个足够简单和实用的例子来研习,最终锁定名为 bottle.hdev(完成分割和读取啤酒瓶上保质期)的程序文件。尽管它可能不是最简单并适合入门的示例程序,但我就是一眼相中了它。在阅读该示例程序前,我已简单了解Halcon的数据类型、基本语法等知识。
示例程序bottle.hdev源码
* bottle.hdev: Segment and read numbers on a beer bottle
本程序的主要功能是,分割和读取啤酒瓶上标识的保质期。后续代码注释中的 “best before” date 含义为保质期/最佳饮用日期/最佳食用日期。该程序利用已经训练好的OCR模型,识别啤酒瓶上的 “最佳饮用日期”,将图片字符转换为日期数字。
Step 0: Preparations
* Step 0: Preparations
* Specify the name of the font to use for reading the date on the bottle.
* It is easiest to use the pre-trained font Universal_0-9_NoRej. If you
* have run the program bottlet.hdev in this directory, you can activate
* the second line to use the font trained with this program.
FontName := 'Universal_0-9_NoRej'
* FontName := 'bottle'
Preparations是准备工作。其中指定了用于读取瓶子上日期的字体的名称。如果您运行了目录中的 bottlet.hdev 程序,可以取消注释第二行以使用该程序训练的字体。可以看到 bottlet.hdev 程序与 bottle.hdev 程序同在 …/examples\hdevelop\Applications\OCR 目录下,前者功能是 Training of the OCR. The font is used in “bottle.hdev”。 根据代码中的注释,建议使用预训练的字体"Universal_0-9_NoRej",该字体可能是经过训练和优化的,以便更好地识别瓶子上的数字字符。
补充,(临时不做深究20240228,后续章节可能添加)
OCR(Optical Character Recognition,光学字符识别)的训练和字体选择是OCR技术中的一部分,其中涉及复杂的算法和模型训练过程。在OCR训练中,通常需要提供大量的标注数据,其中包括图像样本和相应的字符标签。通过将这些样本输入到OCR算法中,可以通过训练来调整OCR模型的参数,使其能够更好地识别出字符。在OCR中,字体(Font)指的是一种特定的字符设计和排列方式。不同的字体具有不同的字形和样式,如字体的大小、粗细、倾斜度等。字体在OCR中起到重要的作用,因为不同的字体可能会对字符的外观和特征产生影响,从而影响OCR的准确性。
Step 1: Segmentation - 读取并显示图片
*
* Step 1: Segmentation
dev_update_window ('off')
read_image (Bottle, 'bottle2')
get_image_size (Bottle, Width, Height)
dev_close_window ()
dev_open_window (0, 0, 2 * Width, 2 * Height, 'black', WindowID)
set_display_font (WindowID, 16, 'mono', 'true', 'false')
dev_display (Bottle)
disp_continue_message (WindowID, 'black', 'true')
stop ()
该段代码实现了,在一个窗口中显示读取的图像,并等待用户操作。具体的,
1、程序先将窗口更新设置为关闭状态,在不需要实时更新图像时,关闭更新以提升处理速度。
2、从名为’bottle2’的图像文件中读取图像数据,并将其存储在名为Bottle的变量中。
3、获取图像Bottle的宽度和高度,并将它们存储在Width和Height变量中。
4、关闭了之前可能打开的窗口,以便为后面的窗口设置做准备。
5、使用dev_open_window打开一个新的窗口,设置窗口的位置和大小。通过将窗口的宽度和高度设置为原始图像的两倍,可以提供足够的空间来显示分割和识别结果。新打开的窗口如下图,其中,图形窗口的名称 200000 为 WindowID 的值。
6、置窗口的显示字体。它将字体大小设置为16,字体类型设置为’mono’(等宽字体),'true’表示将字体设置为粗体,'false’表示不使用斜体。
7、调用 dev_display (Bottle) 在打开的窗口中显示图像Bottle。
8、disp_continue_message 在窗口中显示一条继续消息。它将消息的颜色设置为黑色,'true’表示以等待用户操作的方式显示消息。在单步调试时,图形窗口右下角可见 “Press Run (F5) to continue”。很显然这是一种调试信息。

9、代码行 stop(),该函数的作用是提供一个交互式的界面,使用户有机会查看并处理窗口中的图像。当程序执行到此行时,程序将暂停,直到用户采取某种操作或关闭窗口为止。用户可以使用键盘的F5,或者是工具栏的运行F5按钮、单步调试按钮等使得程序继续运行。直观的功能是,调试过程中,当使用一次F5时,程序会在一个stop行上停住,在执行上述任意用户操作后方能继续。
Step 1: Segmentation - 创建并设置OCR模型
*
* Create Automatic Text Reader and set some parameters
create_text_model_reader ('auto', FontName, TextModel)
* The printed date has a significantly higher stroke width
set_text_model_param (TextModel, 'min_stroke_width', 6)
* The "best before" date has a particular and known structure
set_text_model_param (TextModel, 'text_line_structure', '2 2 2')
补充,
在Halcon算子帮助文档中,会首先列出函数签名,然后实际的函数声明,以使得读者可以辨别出参数数据类型和输出输出类型。Halcon算子函数的签名,遵循如下格式,

以create_text_model_reader 函数为例,其签名如下,

这个函数没有输入和输出图像数据,只有两个输入控制数据 + 一个输出控制数据。
create_text_model_reader (‘auto’, FontName, TextModel)

该函数创建一个TextModel文本模型,用于描述将要使用find_text进行分割的文本。此行代码是本程序的核心代码,它代表了要查找的内容。通过这个文本模型,可以定义和描述要查找的文本的特征和结构。例如,可以指定要查找的特定字符、字体、大小、颜色等。然后,可以使用这个文本模型在图像中查找符合这些特征和结构的文本。
参数’auto’表示使用自动模式来选择合适的OCR模型和字体。参数FontName,对应形参OCRClassifier,意为分类器,是输入型控制数据,Halcon提供了很多预定义分类器,

set_text_model_param (TextModel, ‘min_stroke_width’, 6)

设置文本模型TextModel的参数,用于指定文本中字符的最小笔画宽度,以像素为单位。这个设置项仅适用于字符,标点符号或分割符的笔画宽度不受其限制。示例中,其用于处理印刷日期,因为这些字符通常具有较大的笔画宽度。
set_text_model_param (TextModel, ‘text_line_structure’, ‘2 2 2’)

指定文本行的结构(每行字符的数量和结构)。示例中,‘2 2 2’ 表示 “best before” 日期的结构为3个字符段,每段包含2个字符。
Step 1: Segmentation - 文本分割与识别
*
* Read the "best before" date
find_text (Bottle, TextModel, TextResultID)
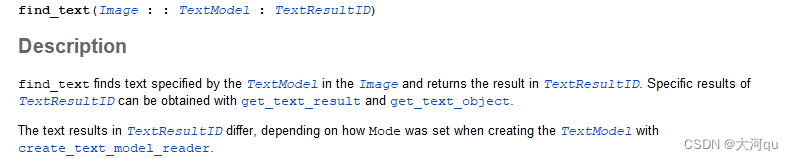
在Image图像中,函数find_text,会查找由TextModel指定的文本,并将结果存返回存储到TextResultID中。TextResultID所包含的具体的(Specific)结果可以使用get_text_result和get_text_object获取。TextResultID中的文本结果会根据使用create_text_model_reader创建TextModel时设置的Mode而有所不同。
计算结果显示
*
* Display the segmentation results
get_text_object (Characters, TextResultID, 'all_lines')
dev_display (Bottle)
dev_display (Characters)
stop ()
* Display the reading results
get_text_result (TextResultID, 'class', Classes)
area_center (Characters, Area, Row, Column)
disp_message (WindowID, Classes, 'image', 80, Column - 3, 'green', 'false')

get_text_object 函数获取了find_text函数的具体输出数据,可以通过ResultName参数指定获取全部字符,一行字符、或者指定序号的一个字符等。执行结果如下,

有点意外的是,代码执行到上述位置,图像变量Charactors被赋值后,在执行dev_display之前,Charactors会在图形窗口中叠加显示,当执行到下一行代码时,Charactors又被从图形窗口中清除。dev_display (Bottle)、dev_display (Characters) 会再次重新显示图像变量。

不同于get_text_object,函数get_text_result输出的是控制数据 ResultValue,即变量Classes对应的字符串数组,具体执行结果,

字符串数组(string array)Classes 存储了每个字符的识别类别。进行文本识别时,每个字符都被分类到不同的类别中。这些类别可以表示不同的字符、数字、符号等。例如,类别可以是字母A、数字1、标点符号!等等。具体的,这里水太深,暂不深究。
内存释放
*
* Free memory
clear_text_result (TextResultID)
clear_text_model (TextModel)
在Halcon中,文本结果和文本模型存储着大量的信息,包括字符识别结果、模型参数等。为了有效地管理这些数据,并确保在需要时可以释放内存,Halcon将这些数据分配在堆上。
导出为C++代码
Halcon提供了各种导出选项,例如C++, C#, Visual Basic等,以及与OpenCV等其他常用机器视觉库的集成。导出为其他语言可以让开发人员更方便地将Halcon的功能嵌入到自己的应用程序中,并与其他库和工具进行集成。这种灵活性使得Halcon成为一个强大的机器视觉开发平台,可以适应不同的应用需求和开发环境
导出为C++代码
在文件菜单中选择导出,打开如下导出界面,暂保持默认配置,
本地函数是在当前程序文件中定义的函数,它们通常用于封装和组织代码,并在程序中多次使用。外部函数是在其他Halcon程序文件中定义的函数,它们可能是标准的Halcon函数库函数或自定义的函数。按照上述配置,成功导出 bottle.cpp文件,其中主要函数实现如下,
// Main procedure
void action()
{
// Local iconic variables
HObject ho_Bottle, ho_Characters;
// Local control variables
HTuple hv_FontName, hv_Width, hv_Height, hv_WindowID;
HTuple hv_TextModel, hv_TextResultID, hv_Classes, hv_Area;
HTuple hv_Row, hv_Column;
//
//bottle.hdev: Segment and read numbers on a beer bottle
//
//Step 0: Preparations
//Specify the name of the font to use for reading the date on the bottle.
//It is easiest to use the pre-trained font Universal_0-9_NoRej. If you
//have run the program bottlet.hdev in this directory, you can activate
//the second line to use the font trained with this program.
hv_FontName = "Universal_0-9_NoRej";
//FontName := 'bottle'
//
//Step 1: Segmentation
// dev_update_window(...); only in hdevelop
ReadImage(&ho_Bottle, "bottle2");
GetImageSize(ho_Bottle, &hv_Width, &hv_Height);
if (HDevWindowStack::IsOpen())
CloseWindow(HDevWindowStack::Pop());
SetWindowAttr("background_color","black");
OpenWindow(0,0,2*hv_Width,2*hv_Height,0,"visible","",&hv_WindowID);
HDevWindowStack::Push(hv_WindowID);
set_display_font(hv_WindowID, 16, "mono", "true", "false");
if (HDevWindowStack::IsOpen())
DispObj(ho_Bottle, HDevWindowStack::GetActive());
disp_continue_message(hv_WindowID, "black", "true");
// stop(...); only in hdevelop
//
//Create Automatic Text Reader and set some parameters
CreateTextModelReader("auto", hv_FontName, &hv_TextModel);
//The printed date has a significantly higher stroke width
SetTextModelParam(hv_TextModel, "min_stroke_width", 6);
//The "best before" date has a particular and known structure
SetTextModelParam(hv_TextModel, "text_line_structure", "2 2 2");
//
//Read the "best before" date
FindText(ho_Bottle, hv_TextModel, &hv_TextResultID);
//
//Display the segmentation results
GetTextObject(&ho_Characters, hv_TextResultID, "all_lines");
if (HDevWindowStack::IsOpen())
DispObj(ho_Bottle, HDevWindowStack::GetActive());
if (HDevWindowStack::IsOpen())
DispObj(ho_Characters, HDevWindowStack::GetActive());
// stop(...); only in hdevelop
//Display the reading results
GetTextResult(hv_TextResultID, "class", &hv_Classes);
AreaCenter(ho_Characters, &hv_Area, &hv_Row, &hv_Column);
disp_message(hv_WindowID, hv_Classes, "image", 80, hv_Column-3, "green", "false");
//
//Free memory
ClearTextResult(hv_TextResultID);
ClearTextModel(hv_TextModel);
}
对应着原来的hdev程序,上述C++代码很好理解,基本上就是换了一个函数名字而已,由于初学,也不再做太深入的研究。在VS中新建空项目,添加HDevelop导出生成的bottle.cpp文件。此时是无法通过编译的,因为尚未配置 IDE …
配置 VS + Halcon 环境
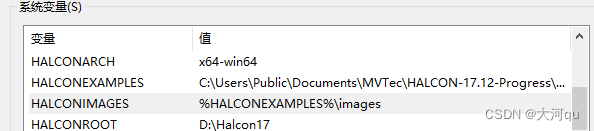
关于集成开发环境的配置,是老生常谈,需要配置哪些方面的内容,可参见《》,此处仅简单描述,建议使用相对路径配置,本机系统环境变量如下,
以Debug + x64平台为例进行配置如下,
项目属性 -> C/C++ -> 常规 -> 附加包含目录,
$(HALCONROOT)\include;$(HALCONROOT)\include\halconcpp
项目属性 -> 连接器 -> 常规 -> 附加库目录,
$(HALCONROOT)\lib\$(HALCONARCH)
项目属性 -> 连接器 -> 输入 -> 附加依赖项,
halconcpp.lib
VS程序执行结果
注意在main函数中加上 system(“pause”); 语句,否则窗口将一闪而过。
HTuple hv_Classes 转 std::string
将结果转换为自己熟悉的C++字符串,心里踏实了许多。这里成功测试了两种方法,但可能不是最简单的方法。
#if 0
HString hstring = hv_Classes.ToString();
std::string std_string = hstring.Text();
std::cout << "hv_Classes to std_string, Len:" << hstring.Length()
<< ", Content: " << std_string
<< std::endl;
//print
//hv_Classes to std_string, Len:30, Content : ["0", "1", "0", "8", "9", "4"]
#else
std::string std_string;
for (int i = 0; i < hv_Classes.Length(); i++) {
HString str = hv_Classes[i].S();
char* code = const_cast<char*>(str.Text());
std_string += code;
}
std::cout << "hv_Classes to std_string, Content: " << std_string << std::endl;
//print
//hv_Classes to std_string, Content: 010894
#endif // 0
OCR训练/字体文件(bottlet.hdev)
学习整理完成 bottle.hdev后,直观的感受是,在Halcon和HDevelop的加持下,实现一个光学字符识别功能真的是挺方便的。前边遗留了OCR训练的过程和概念没搞明白,一转眼过去10多天了,倒回头来再深入下。下文将试图理解,什么是OCR训练,如何训练,什么是文本模型,它的内容是什么? etc.
Step2 - 生成OCR样本数据
* Step2: Training file generation
TrainingNames := ['0','1','0','8','9','4']
TrainingFileName := FontName + '.trf'
sort_region (FinalNumbers, SortedRegions, 'first_point', 'true', 'column')
shape_trans (SortedRegions, RegionTrans, 'rectangle1')
area_center (RegionTrans, Area, Row, Column)
MeanRow := mean(Row)
dev_set_check ('~give_error')
delete_file (TrainingFileName)
dev_set_check ('give_error')
for I := 0 to |TrainingNames| - 1 by 1
select_obj (SortedRegions, CharaterRegions, I + 1)
append_ocr_trainf (CharaterRegions, Bottle, TrainingNames[I], TrainingFileName)
disp_message (WindowID, TrainingNames[I], 'image', MeanRow - 40, Column[I] - 6, 'yellow', 'false')
endfor
我们先跳跃着来看看与bottle.hdev最直接相关的部分。如下代码进行了OCR训练文件的存储,

具体的,

select_obj 函数的功能比较好理解,它使用(I+1)索引值,从对象数组SortedRegions中获取单个对象。如I==2时,CharaterRegions对应的Region图如下,
有了单字符图像数据后,并不是直接简单地与实际字符进行映射关系存储就万事大吉了,尽管确实涉及了写文件操作,

TrainingFileName == ‘bottle.trf’ 即 bottle.hdev 中可以选择使用的字体文件。
如上,append_ocr_trainf 函数的功能实际上是在设置OCR训练所直接需要的数据,它为后续的 trainf_ocr_class_mlp 训练过程做准备。它将表示字符的regin区域(包括区域和像素的灰度值)以及相应的类别名称(TrainingNames[I],字符值)写入文件中。一个图像中可以支持任意(arbitrary)数量的字符区域。对于signature_Character中的每个字符(regin区域),必须在signature_Class中指定相应的class name类别名称。灰度值通过Image参数传递。与write_ocr_trainf操作不同的是,它使用相同的训练文件格式,将字符追加到现有文件中。如果文件不存在,将生成一个新文件。(这里可得知,append_ocr_trainf 确实也是写文件操作的)。
Step3: 执行OCR训练
* Step3: Training
* 将训练样本的名称列表进行sort排序并uniq去重,得到一个包含所有不同标签的列表
CharNames := uniq(sort(TrainingNames))
* 创建一个基于多层感知器(MLP)的OCR分类器,并设置参数。并将其保存在 OCRHandle 变量中
create_ocr_class_mlp (8, 10, 'constant', 'default', CharNames, 10, 'none', 10, 42, OCRHandle)
* 使用训练文件 TrainingFileName 中的样本数据对 OCRHandle 中的OCR分类器进行训练。训练次数为200次,学习率为0.01
trainf_ocr_class_mlp (OCRHandle, TrainingFileName, 200, 1, 0.01, Error, ErrorLog)
* 将训练得到的OCR分类器以 FontName 的名称保存起来,以便后续使用,即在bottle.hdev中使用的字体名称
write_ocr_class_mlp (OCRHandle, FontName)
* 清除 OCRHandle 中的OCR分类器,释放相关的内存资源。
clear_ocr_class_mlp (OCRHandle)
不再对上述代码具体展开,只重点关注下 trainf_ocr_class_mlp 函数,
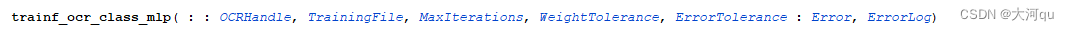
trainf_ocr_class_mlp trains the OCR classifier OCRHandle with the training characters stored in the OCR training files given by TrainingFile.
函数 trainf_ocr_class_mlp 使用存储在OCR训练文件(TrainingFile == ‘bottle.trf’)中的训练字符,来训练OCR分类器。在执行这个训练过程前,训练文件必须已经是存在的,前边也已经说了,append_ocr_trainf 如果检测到文件不存在,会自动创建。函数的参数挺多的,大体来看一下,以便理解,
trainf_ocr_class_mlp (OCRHandle, TrainingFileName, 200, 1, 0.01, Error, ErrorLog)
该行代码用于训练基于多层感知器(MLP)的OCR分类器的操作,该操作详细说明如下,
OCR分类器的句柄 [OCRHandle]:即先前使用create_ocr_class_mlp操作创建的分类器。
训练文件名称 [TrainingFileName]:其中包含用于训练的样本数据。该文件应该符合与append_ocr_trainf操作相同的训练文件格式。
训练迭代次数 [200]:。在每次迭代中,分类器根据样本数据进行参数更新和优化。迭代次数越多,训练效果可能会更好,但可能导致训练时间较长。
批处理大小 [1]:批处理是指一次性将多个样本数据一起输入到分类器进行训练。设置批处理大小可以控制每次迭代中使用的样本数量。在此情况下,每次迭代中使用一个批次。
学习率 [0.01]:学习率决定了在每次迭代中更新参数时所应用的步长。较高的学习率可以加快训练速度,但可能导致不稳定的收敛。较低的学习率可以提高收敛的稳定性,但可能需要更多的迭代次数才能达到较好的训练效果。
误差值 [Error]:用于存储训练过程中的误差值。通过该参数可以获取每次迭代后分类器的训练误差。
误差日志 [ErrorLog]:用于存储训练过程中的误差日志。通过该参数可以获取每次迭代后的详细误差信息。
Step1 - 提取到感兴趣区域
通过前文的学习和分析,我们已经大体知道了什么是OCR训练文件、训练的样本数据、基本的训练参数、OCR分类器等基本概念,大约明白了 bottle.hdev 使用的 ‘字体’ 到底是怎么搞出来的,算是基本将两个halcon程序的功能对接上了。接下来我们将简单地看看最初的样本数据是怎么计算分析出来的…
* Step 1: Segmentation
dev_update_window ('off')
read_image (Bottle, 'bottle2')
get_image_size (Bottle, Width, Height)
dev_close_window ()
dev_open_window (0, 0, 2 * Width, 2 * Height, 'black', WindowID)
set_display_font (WindowID, 27, 'mono', 'true', 'false')
* 使用阈值化操作将图像Bottle分割成二值图像,将像素值在0到95之间的像素设为前景,其他像素设为背景
threshold (Bottle, RawSegmentation, 0, 95)
* 对RawSegmentation中连通域面积1到5个像素之间的区域进行填充,用于去除图像中的噪点或细小的非感兴趣区域
fill_up_shape (RawSegmentation, RemovedNoise, 'area', 1, 5)
* 使用半径为2.5的圆形结构元素,对RemovedNoise进行圆形开运算,通过先腐蚀再膨胀的操作,去除小的细节并保留较大的结构
opening_circle (RemovedNoise, ThickStructures, 2.5)
* 对ThickStructures进行形状填充操作,填充孔洞,形成实心的连通区域,并将结果保存在Solid中
fill_up (ThickStructures, Solid)
* 使用宽度为1高度为7的矩形结构元素,对Solid进行矩形开运算,去除细小的细节并保留较大的结构,将结果保存在Cut中
opening_rectangle1 (Solid, Cut, 1, 7)
* 对Cut进行连通性分析,将具有相同连通性的像素标记为同一对象,并将结果保存在ConnectedPatterns中
connection (Cut, ConnectedPatterns)
* 计算ConnectedPatterns和ThickStructures之间的交集,得到候选对象NumberCandidates
intersection (ConnectedPatterns, ThickStructures, NumberCandidates)
* 根据面积的大小选择形状,保留面积在300到9999(个像素)之间的对象,并将结果保存在Numbers中
select_shape (NumberCandidates, Numbers, 'area', 'and', 300, 9999)
* 根据区域的首点坐标进行排序,按列的顺序对Numbers中的区域进行排序,并将结果保存在FinalNumbers中
sort_region (Numbers, FinalNumbers, 'first_point', 'true', 'column')
* 显示原始图
dev_display (Bottle)
* 设置图形窗口中绘图颜色为绿色
dev_set_color ('green')
* 设置图形窗口中绘图线宽为2像素
dev_set_line_width (2)
* 设置图形窗口中绘图形状为矩形
dev_set_shape ('rectangle1')
* 设置图形窗口中绘图绘制方式为边缘margin模式
dev_set_draw ('margin')
* 按照上述绘制参数绘制并显示FinalNumbers中的图像区域,具体如下图所示
dev_display (FinalNumbers)

总结
?真的要在这条路上走下去吗 …















 3414
3414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









