







一、前提
(1)环境:Ubuntu 16.04
(2)需要软件:JDK 1.8 和 Hadoop-2.8.0
二、安装JDK
安装的详细过程参见博文:博文链接
三、安装Hadoop
下载地址:http://hadoop.apache.org/releases.html
我选的是hadoop 2.8.0,选择binary版本。(source是源码,如果在工作中需要修改源码之后再运行,则可以选择source),如下图:

下载完毕之后,
(1)解压:直接使用解压命令
S1:首先使用cd命令切换到hadoop-2.8.0.tar.gz目录地址。
S2:使用解压命令:
tar zxf hadoop-2.8.0.tar.gz解压之后我这边hadoop文件的目录地址为:/opt/Hadoop/hadoop-2.8.0
(2)设置JAVA_HOME环境变量:
在之前安装JDK时已经在~/.bashrc中设置过,所以这里不需要再次设置。
(3)设置Hadoop安装目录(即HADOOP_INSTALL)的环境变量:
在~/.bashrc中设置:
S1:打开~/.bashrc文件,使用命令:
sudo gedit ~/.bashrcS2:在打开的文件末尾加上:
export HADOOP_INSTALL=/opt/Hadoop/hadoop-2.8.0(注释:/opt/Hadoop/hadoop-2.8.0是Hadoop解压过后的路径)
export PATH=.:$HADOOP_INSTALL/bin:$HADOOP_INSTALL/sbin:$JAVA_HOME/bin:$PATHS3:使用下列命令使配置立即生效:
source ~/.bashrc(4)判断Hadoop是否正常工作,使用命令:
hadoop version若执行命令之后,输出hadoop的版本信息等,则说明hadoop安装正确。
四、伪分布模式配置
(一)配置xml文件
利用hadoop搭建伪分布式环境需要配置5个xml文件,这5个xml文件都在/opt/Hadoop/hadoop-2.8.0/ect/hadoop文件夹中。
(1)修改hadoop-env.sh配置文件
| 配置hadoop-env.sh过程 |
|---|
S1:打开hadoop-env.sh文件,将当前位置切换了/opt/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo gedit hadoop-env.sh,命令执行后hadoop-env.sh文件被打开。 |
S2:在hadoop-env.sh文件中修改JAVA_HOME环境变量,将export JAVA_HOME=${JAVA_HOME}(虽然之前的代码也能获取到JAVA_HOME的值,但是有时候会失效)修改为export JAVA_HOME=/opt/Java/Jdk/jdk1.8 |
(2)修改core-site.xml配置文件
| 配置core-site.xml过程 |
|---|
S1:打开core-site.xml文件,将当前位置切换了/opt/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo gedit core-site.xml,命令执行后core-site.xml文件被打开。 |
| S2:在core-site.xml文件末尾添加上如下代码: |
代码如下(和标签原来就有):
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/Hadoop/hadoop-2.8.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:8080</value>
</property>
</configuration>注意:hadoop.tmp.dir文件不是一个临时文件,是存放所有hadoop中数据的文件,其目录地址为:/opt/Hadoop/hadoop-2.8.0/tmp。
(3)修改hdfs-site.xml配置文件
| 配置hdfs-site.xml过程 |
|---|
S1:打开hdfs-site.xml文件,将当前位置切换了/opt/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo gedit hdfs-site.xml,命令执行后hdfs-site.xml文件被打开。 |
| S2:在hdfs-site.xml文件末尾添加上如下代码: |
代码如下(和标签原来就有):
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>注意:1是指备份1份(总共1份)。在hadoop中默认有3份文件(含备份),现在伪分布模式是单机,因此变成1。若是总共想要存放2份文件,则改为2。
(4)修改mapred-site.xml配置文件
| 配置mapred-site.xml过程 |
|---|
S1:打开mapred-site.xml文件(你会发现在/opt/Hadoop/hadoop-2.8.0/etc/hadoop没有mapred-site.xml文件,只有一个mapred-site.xml.template文件。这是因为mapreduce比较特殊,它可以配置也可以不配置,而其他例如core-site.xml存在因为其必须配置。这里只需要将mapred-site.xml.template复制一下,并且将文件名改为mapred-site.xml进行修改即可),将当前位置切换了/opt/Hadoop/hadoop-2.8.0/ect/hadoop中,使用命令sudo gedit mapred-site.xml,命令执行后mapred-site.xml文件被打开。 |
| S2:在mapred-site.xml文件末尾添加上如下代码: |
代码如下(和标签原来就有):
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost</value>
</property>
</configuration>
(5)修改yarn-site.xml配置文件
| 配置yarn-site.xml过程 |
|---|
S1:打开yarn-site.xml文件,将当前位置切换了/opt/Hadoop/hadoop-2.8.0/etc/hadoop中,使用命令sudo gedit yarn-site.xml,命令执行后yarn-site.xml文件被打开。 |
| S2:在yarn-site.xml文件末尾添加上如下代码: |
代码如下(和标签原来就有):
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>注意:你会发现在/opt/Hadoop/hadoop-2.8.0/etc/hadoop目录下,除了上面需要修改的文件之外,每一个文件有相应的default文件。例如,core-site.xml存在,同时在/opt/Hadoop/hadoop-2.8.0下面的其他文件中也存在core-default.xml文件(其他3个xml文件也有对应的default文件,在我们没有进行配置修改之前,系统调用default文件,修改之后边调用我们修改之后的文件)。
(二)配置SSH
若这样直接启动hdfs和yarn进程,则需要多次输入密码。因此这里配置SSH实现免密码登录。
命令如下:
sudo apt-get install ssh
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys使用命令ssh localhost进行测试,如果配置成功,则无需输入密码。
(三)格式化HDFS文件
使用cd命令将当前位置切换到/opt/Hadoop/hadoop-2.8.0/bin目录下(bin目录下面有一个hdfs),执行命令:
./hdfs namenode -format(四)启动进程并检测是否正确配置
使用cd命令将当前位置切换到/opt/Hadoop/hadoop-2.8.0/sbin目录下:
(1)启动dfs进程,使用命令start-dfs.sh,输入此命令后会有相应的进程开启,使用jps查看已有进程,如下图:
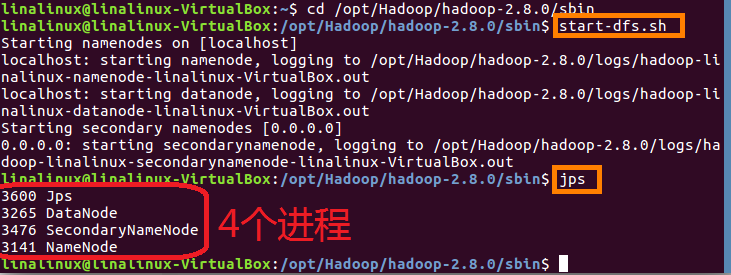
隔段时间使用一次jps查看已有进程,这还不够,验证的时候最好访问web地址:http://localhost:50070(50070是访问dfs的端口号)。
若能正常访问,则会出现下图所示界面:

(2)启动yarn进程,使用命令start-yarn.sh,输入此命令后会有相应的进程开启,使用jps查看已有进程,如下图:
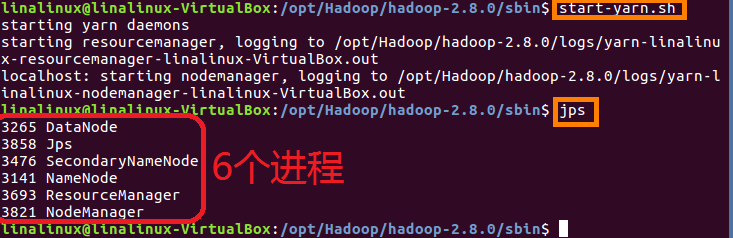
隔段时间使用一次jps查看已有进程,这还不够,验证的时候最好访问web地址:http://localhost:8088(8088是访问yarn的端口号)。
若能正常访问,则会出现下图所示界面:

(五)终止进程
(1)终止dfs进程使用命令:stop-dfs.sh
(2)终止yarn进程使用命令:stop-yarn.sh
五、可能出现的问题
1、
问题:使用start-dfs.sh启动dfs时,datanode启动不了
原因:多次格式化namenode
解决方案:将/opt/Hadoop/hadoop-2.8.0/tmp/dfs/data文件夹下的文件全部删除,再次格式化namenode(问是否重新格式化,选Yes),重新启动dfs即可
2、
问题:算是一个比较奇怪的问题,直接找到mapred-site.xml通过右击的方式可以看到mapred-site.xml中的内容,但是在相应的目录下使用sudo gedit mapred-site.xml找不到这个文件(即打开之后的文件内容为空)
原因:在/opt/Hadoop/hadoop-2.8.0/etc/hadoop文件夹下没有mapred-site.xml文件,我们需要复制mapred-site.xml.template并将其命名为mapred-site.xml,我之前是使用手动复制重命名的方式,所以出现了这个问题
解决方案:使用cp命令复制这个文件,cp mapred-site.xml.template mapred-site.xml,并将其内容改成上面的配置命令。
Eclipse中使用Hadoop单机模式开发配置及简单程序示例详见博客:Eclipse中使用Hadoop单机模式开发配置及简单程序示例















 644
644

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









