






一、数据结构与线程安全
1. ConcurrentHashMap(JDK 1.8+)
- 底层结构:数组 + 链表/红黑树
- 默认初始容量为16,负载因子0.75
- 当链表长度 ≥8 且数组长度 ≥64 时,链表转为红黑树(查询效率从O(n)优化为O(logn))
- 线程安全:
- 采用 CAS(无锁算法) + synchronized 锁桶头节点,粒度更细
- 支持多线程协同扩容(其他线程插入时可协助迁移数据)
2. HashMap
- 底层结构:数组 + 链表/红黑树(JDK 1.8+)
- 默认初始容量16,负载因子0.75
- 非线程安全,多线程操作可能导致数据错乱或死循环(JDK 1.7头插法问题)
- 哈希优化:
- 扰动函数(
(h = key.hashCode()) ^ (h >>> 16))减少哈希冲突
- 扰动函数(
3. Hashtable
- 底层结构:数组 + 单向链表(无红黑树)
- 默认初始容量11,扩容后为
2n + 1
- 默认初始容量11,扩容后为
- 线程安全:
- 全表锁(所有方法用
synchronized修饰),并发性能差
- 全表锁(所有方法用
二、扩容机制对比
1. ConcurrentHashMap(JDK 1.8+)
- 触发条件:元素数量 ≥ 容量 × 负载因子(默认0.75)
- 扩容步骤:
- 创建新数组(容量翻倍,保持2的幂次方)
- 多线程分块迁移数据,每个线程负责部分桶的迁移
- 迁移时通过
ForwardingNode标记已处理的桶,避免重复操作 - 迁移完成后替换旧数组,更新阈值
2. HashMap
- 触发条件:元素数量 > 容量 × 负载因子(默认0.75)
- 扩容步骤:
- 创建新数组(容量翻倍,保持2的幂次方)
- 重新计算哈希,通过高位掩码(
(n-1) & hash)确定元素位置(无需全量重哈希) - 链表拆分:若旧链表元素在新数组中分布在不同位置,拆分为两条链表
3. Hashtable
- 触发条件:元素数量 ≥ 容量 × 负载因子(默认0.75)
- 扩容步骤:
- 创建新数组(容量翻倍 +1)
- 全表锁定,单线程重新哈希所有元素
三、核心差异总结
| 特性 | ConcurrentHashMap | HashMap | Hashtable |
|---|---|---|---|
| 线程安全 | ✔️(CAS + 桶锁) | ❌ | ✔️(全表锁,低效) |
| 数据结构 | 数组 + 链表/红黑树(JDK8+) | 数组 + 链表/红黑树(JDK8+) | 数组 + 单向链表 |
| 扩容方式 | 多线程协同迁移 | 单线程重哈希 | 单线程重哈希 |
| 锁粒度 | 桶级锁(JDK8+) | 无锁 | 全表锁 |
| Null支持 | ❌(键/值均不可为null) | ✔️(允许null键值) | ❌(键/值均不可为null) |
| 性能 | 高并发下最优 | 单线程最快 | 低效(全表锁竞争) |
| 哈希冲突处理 | 链表 → 红黑树(JDK8+) | 链表 → 红黑树(JDK8+) | 仅链表 |
| 初始容量 | 16(默认) | 16(默认) | 11(默认) |
| 负载因子 | 0.75(默认) | 0.75(默认) | 0.75(默认) |
四、设计哲学与演进
-
ConcurrentHashMap 的优化方向:
- JDK1.7:分段锁(每个
Segment独立锁) - JDK1.8:摒弃分段锁,改用 CAS + synchronized 锁桶头节点,减少锁竞争
- 扩容优化:多线程协同迁移数据,避免长时间阻塞
- JDK1.7:分段锁(每个
-
HashMap 的演进:
- JDK1.7:头插法导致死循环(多线程扩容时)
- JDK1.8:尾插法 + 红黑树,解决并发问题并优化查询效率
-
Hashtable 的局限性:
- 全局锁导致并发性能差,已被
ConcurrentHashMap取代
- 全局锁导致并发性能差,已被
五、适用场景
- ConcurrentHashMap:高并发环境(如缓存、计数器)
- HashMap:单线程或读多写少场景(性能最优)
- Hashtable:已淘汰,仅用于兼容旧代码
通过上述对比可见,ConcurrentHashMap 通过细粒度锁和CAS机制在并发场景下实现高性能,而 HashMap 和 Hashtable 分别适用于单线程和遗留系统场景。
六、补充CAS
CAS(Compare-And-Swap)操作在并发插入场景中通过以下机制避免线程安全问题:
1. 原子性操作的本质
CAS 是硬件级别的原子指令(如 x86 的 cmpxchg),其核心逻辑为:
- 比较内存值:检查目标内存位置的值是否等于预期值(旧值);
- 条件更新:若相等,则将新值写入该内存位置;否则不操作;
- 返回结果:返回操作是否成功
线程安全原理:
由于这一系列操作在硬件层面不可分割,即使多线程并发调用,同一时刻只有一个线程能成功修改内存值,其他线程的 CAS 操作会失败并重试,从而避免了数据覆盖或不一致。
2. 在 ConcurrentHashMap 插入场景中的具体应用
以 JDK 1.8 的 ConcurrentHashMap 为例,插入新节点的流程如下:
(1) 空桶插入(无锁操作)
当线程发现目标桶为空时,会直接通过 CAS 尝试插入新节点:
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break;
}- 关键点:
- 原子性保证:
casTabAt()方法底层调用sun.misc.Unsafe的 CAS 方法,确保只有一个线程能成功将null替换为新节点 - 失败处理:若 CAS 失败(其他线程已插入),线程会重新检查桶状态,转而走锁冲突处理流程。
- 原子性保证:
(2) 非空桶处理(锁细化)
当桶已有节点时,线程会使用 synchronized 锁住头节点,再遍历链表或红黑树处理冲突:
synchronized (f) {
if (tabAt(tab, i) == f) {
// 遍历链表/红黑树并插入
}
}- 协同机制:
- CAS 仅在初始化阶段或空桶插入时使用,冲突处理通过锁保证原子性
- 锁粒度细化到单个桶的头节点,减少竞争范围。
3. 无锁化设计的优势
(1) 避免阻塞与上下文切换
- 无锁竞争:CAS 操作无需线程挂起,失败线程仅需自旋重试,减少上下文切换开销(当线程因竞争锁而失败时,传统锁机制(如
synchronized或ReentrantLock)会通过操作系统将线程挂起(Blocking),使其进入阻塞状态。) - 高并发性能:在低冲突场景(如空桶插入)中,CAS 效率远高于传统锁机制。
(2) 内存可见性保障
- Volatile 变量:
ConcurrentHashMap的数组引用和节点值均用volatile(Volatile 变量是 Java 中用于多线程环境下保证共享变量可见性和禁止指令重排序的关键字。)修饰,确保线程能立即感知到其他线程的修改 - CAS 与 Volatile 协同:CAS 操作的原子性与
volatile的可见性结合,防止脏读或过期数据问题。
4. 应对 ABA 问题
虽然 CAS 存在 ABA 问题(即值从 A→B→A,但线程误判未变化),但在 ConcurrentHashMap 中:
- 节点不可变:链表节点一旦创建,其
hash、key和next指针不可变,仅value可修改(通过volatile保证可见性) - 场景规避:插入操作依赖哈希值定位桶,即使旧节点被移除后重建,新节点的哈希定位可能不同,避免误判。
总结
CAS 通过硬件级原子性、无锁化设计、内存可见性保障,结合 ConcurrentHashMap 的细粒度锁策略,实现了高效的线程安全插入。其核心在于:
- 空桶插入无锁化:CAS 直接竞争内存位置,失败重试。
- 冲突处理精细化:仅锁住冲突桶,不影响其他线程操作。
- 内存模型协同:Volatile 变量与 CAS 共同维护数据一致性
这一机制在高并发场景下显著提升了性能,同时避免了传统锁的瓶颈问题。
六、补充HashMap JDK1.7:头插法导致死循环
HashMap 在扩容时迁移链表的主要原因是为了将旧数组(桶)中的键值对重新分配到新的、容量更大的数组中,确保数据分布均匀并减少哈希冲突。
1. 线程独立的新数组与共享的旧链表节点
- 新数组独立:每个线程扩容时会创建自己的新数组(如线程 1 的
newTable1和线程 2 的newTable2),新数组不共享。 - 旧链表节点共享:线程迁移操作基于同一个旧数组中的链表节点,这些节点的
next指针是 共享内存。任何线程修改节点的next指针,都会直接影响其他线程的后续操作。
2. 保存节点的本质
在扩容时,每个线程通过以下两个局部变量临时保存链表节点:
- **
Entry<K,V> e**:表示当前正在处理的节点; - **
Entry<K,V> next**:表示当前节点的下一个节点。
这两个变量仅在 线程栈内存 中生效,用于在遍历旧链表时临时记录节点间的引用关系
3. 线程 2 的迁移如何影响线程 1
以旧链表 A → B → null 为例,具体流程如下:
背景:线程1和线程2同时扩容,但是线程2先执行,线程1由于某种原因落后于线程2,也就是说线程1创建了新数组,但是还没有执行到赋值e和next,而线程2已经执行完链表反转,此时旧数组中 A → B → null已经变为了 B → A → null,此时线程 1执行 保存局部变量:e = B(当前节点),next = A(下一节点)
步骤 1:线程 1 挂起前的状态
- 此时旧链表的实际状态已被线程 2 修改为
B → A → null(头插法反转) - 线程 1 保存局部变量:
e = B(当前节点),next = A(下一节点)
步骤 2:线程 1 恢复执行
- 线程 1 继续处理
e = B和next = A:- 将
B插入新数组的头部,此时B.next = newTable1[i](初始为空,因此B.next = null); - 更新
e = next = A; - 处理
A时,发现A.next = null(线程 2 修改后的结果),将A插入新数组头部,此时A.next = B;
- 将
- 最终新链表变为
A → B → A,形成环形链表
上述为腾讯元宝给出有些模糊下面为源码加画图形式讲解产生原因
do {
Entry<K,V> next = e.next; // 步骤1:保存当前节点的下一个节点
int i = indexFor(e.hash, newCapacity); // 步骤2:计算新索引
e.next = newTable[i]; // 步骤3:头插法修改指针
newTable[i] = e; // 步骤4:更新新数组头节点
e = next; // 步骤5:移动到下一个节点
} while (e != null);扩容前
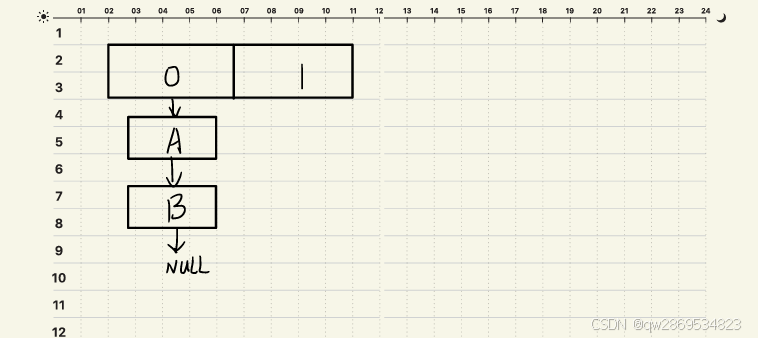
线程1和2同时触发扩容
线程1开始扩容
首先创建新的数组为2n
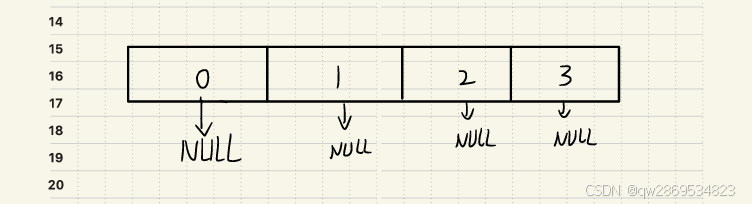
线程2开始扩容
首先创建新的数组为2n
线程1和线程2同时执行此步骤
Entry<K,V> next = e.next; // 步骤1:保存当前节点的下一个节点e(当前节点)= A , next(下一个节点) = B
int i = indexFor(e.hash, newCapacity); // 步骤2:计算新索引这里假设重新计算的索引刚好都与源索引相同
e.next = newTable[i]; // 步骤3:头插法修改指针
newTable[i] = e; // 步骤4:更新新数组头节点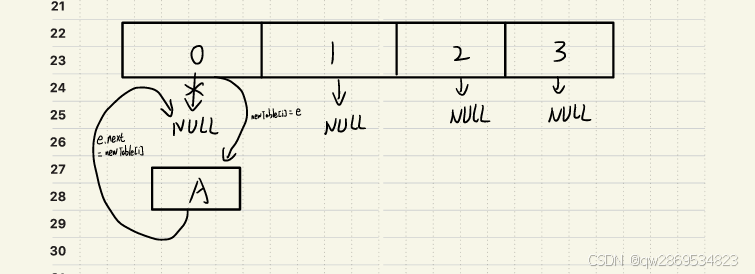
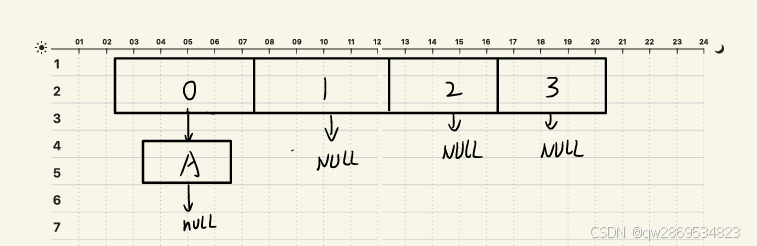
e = next; // 步骤5:移动到下一个节点此时由于某种原因线程1被挂起或落后于线程2
线程2开始继续执行步骤5
e(当前节点)= B
Entry<K,V> next = e.next; // 步骤1:保存当前节点的下一个节点e(当前节点)= B, next(下一个节点) = null
int i = indexFor(e.hash, newCapacity); // 步骤2:计算新索引这里假设重新计算的索引刚好都与源索引相同
e.next = newTable[i]; // 步骤3:头插法修改指针
newTable[i] = e; // 步骤4:更新新数组头节点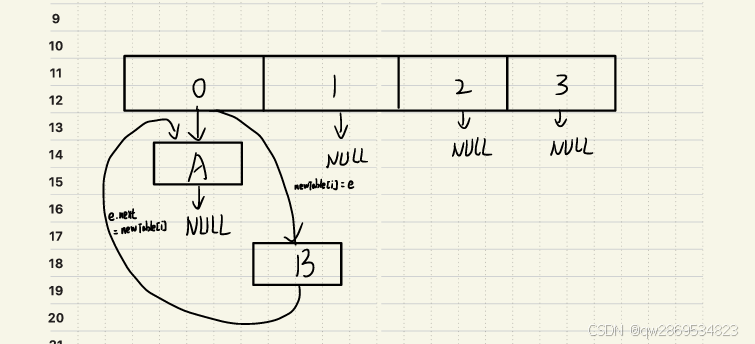
e = next; // 步骤5:移动到下一个节点e(当前节点)= null
此时线程1恢复执行继续执行步骤5
e(当前节点)= B
Entry<K,V> next = e.next; // 步骤1:保存当前节点的下一个节点e(当前节点)= B, next(下一个节点) = A (在线程2执行完后链表已经从B->null变为B->A所以导致next不是null而是A)
int i = indexFor(e.hash, newCapacity); // 步骤2:计算新索引这里假设重新计算的索引刚好都与源索引相同
e.next = newTable[i]; // 步骤3:头插法修改指针
newTable[i] = e; // 步骤4:更新新数组头节点
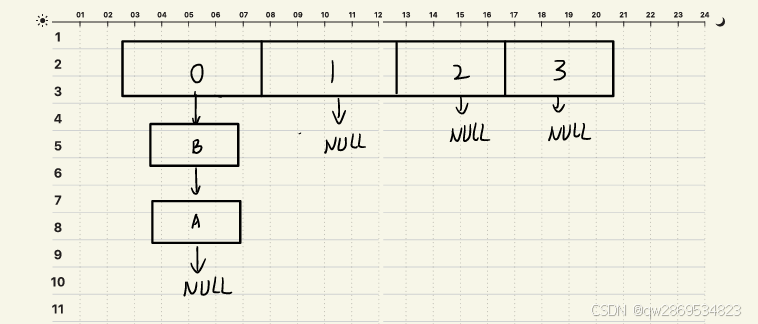
e = next; // 步骤5:移动到下一个节点e(当前节点)= A(就在此处产生环)
Entry<K,V> next = e.next; // 步骤1:保存当前节点的下一个节点e(当前节点)= A, next(下一个节点) = null
int i = indexFor(e.hash, newCapacity); // 步骤2:计算新索引这里假设重新计算的索引刚好都与源索引相同
e.next = newTable[i]; // 步骤3:头插法修改指针
newTable[i] = e; // 步骤4:更新新数组头节点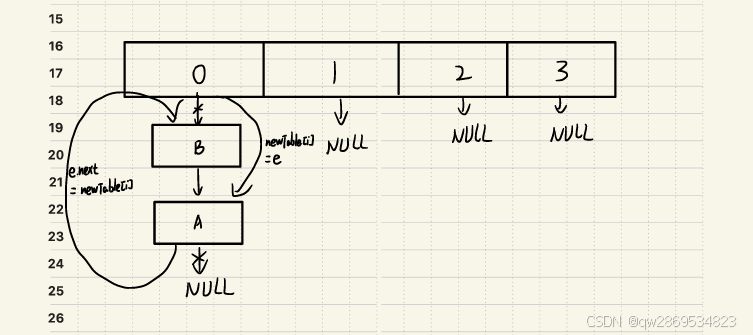
此时链形成
六、补充HashMap JDK1.8 的问题
JDK 1.8 通过以下三个核心机制解决了 HashMap 在多线程扩容时可能产生的环形链表问题,这些改进均围绕数据迁移和结构优化展开
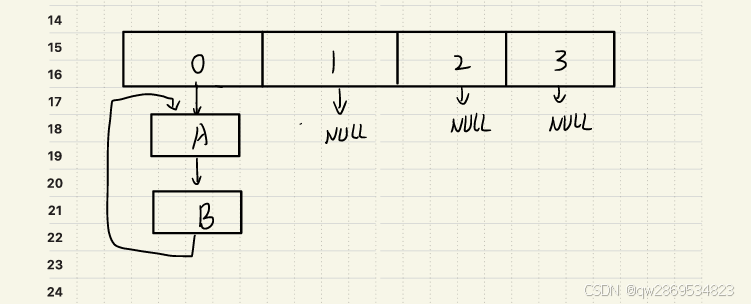
1. 尾插法替代头插法
JDK 1.7 的链表迁移采用头插法,导致链表顺序反转。例如,原链表 A → B → C 迁移后变为 C → B → A。在多线程并发操作时,若两个线程同时反转链表,可能因 next 指针的并发修改形成环形链表(如 A → B → A)。
JDK 1.8 改用尾插法:
- 保持链表顺序:新节点始终追加到链表末尾,迁移后的链表仍为
A → B → C,避免顺序反转带来的指针冲突 - 消除反转操作:头插法的反转逻辑被移除,从根源上杜绝环形链表的形成
2. 高低位链表拆分
JDK 1.8 在扩容时通过位运算拆分链表,将原链表分为低位链表(索引不变)和高位链表(索引 = 原索引 + 旧容量),并独立迁移到新数组:
if ((e.hash & oldCap) == 0) { // 低位链表
loTail.next = e;
} else { // 高位链表
hiTail.next = e;
}- 原子性迁移:每条链表独立处理,无需共享指针,降低并发操作冲突风险
- 无需链表遍历反转:拆分后的链表直接整体迁移,避免头插法的顺序反转
3. 红黑树优化
当链表长度超过阈值(默认 8)且数组长度 ≥64 时,JDK 1.8 将链表转换为红黑树:
- 减少链表长度:红黑树的查询时间复杂度为 O(logN),避免长链表遍历时因并发修改导致指针错乱
- 树化与退化机制:
- 树化条件:链表长度 ≥8 且数组长度 ≥64。
- 退化条件:红黑树节点 ≤6 时退化为链表,平衡性能与空间效率
总结对比
| 特性 | JDK 1.7 | JDK 1.8 |
|---|---|---|
| 链表迁移方式 | 头插法(反转顺序) | 尾插法(保持顺序) |
| 扩容冲突处理 | 可能形成环形链表 | 高低位拆分 + 尾插法 |
| 数据结构 | 数组+链表 | 数组+链表+红黑树 |
| 线程安全性 | 不安全(死循环、数据丢失) | 仍非线程安全,但解决死循环问题 |
实际效果:
JDK 1.8 的优化使得 HashMap 在高并发扩容场景下避免了死循环,但仍存在数据覆盖等线程安全问题。因此,多线程环境仍需使用 ConcurrentHashMap
扩展说明:
- 扰动函数优化:JDK 1.8 简化了哈希计算(仅一次高位异或),降低哈希碰撞概率,间接减少链表长度和冲突风险
- 扩容索引计算:通过
(e.hash & oldCap) == 0判断新索引位置,避免重新计算哈希值,提升效率
HashMap并发操作时仍然会出现错误
HashMap 的非线程安全性
HashMap 的设计初衷是追求单线程下的高性能,因此在 JDK 1.8 中依然未内置锁或其他线程安全机制。以下是其非线程安全的典型表现:
- 数据覆盖:多线程同时调用
put()方法时,若计算出的索引位置相同,后写入的线程可能覆盖前者的数据 - 扩容不一致性:多线程同时触发扩容时,可能导致链表节点丢失或重复迁移,最终引发数据错乱
- 迭代器快速失败:迭代过程中若其他线程修改结构(如增删元素),会抛出
ConcurrentModificationException
import java.util.HashMap;
import java.util.Map;
public class SchoolSpringApplication {
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
// 线程1:插入数据
new Thread(() -> {
for (int i = 0; i < 10000; i++) {
map.put(i, "Value-" + i);
System.out.println("Value-" + i);
}
System.out.println("Thread1 finished!"); // 新增日志
}).start();
// 线程2:触发扩容并遍历
new Thread(() -> {
try {
while (true) {
// 写操作可能引发并发异常(若 map 非线程安全)
map.put(100, "Trigger");
// 读操作可能因并发修改抛出异常
System.out.println(map.size());
// 遍历 map 时捕获并发修改异常
try {
int actualSize = 0;
for (Integer key : map.keySet()) {
actualSize++;
}
System.out.println("Actual keys: " + actualSize);
} catch (Exception e) {
System.out.println("遍历时发生异常: " + e.getClass().getSimpleName());
e.printStackTrace();
}
}
} catch (Exception e) { // 捕获其他可能的异常(如 NullPointerException)
System.out.println("主循环发生异常: " + e.getClass().getSimpleName());
e.printStackTrace();
}
}).start();
}
}
迭代器快速失败

扩容不一致性
线程 A 和线程 B 同时操作同一个链表:若两个线程同时遍历链表并拆分,可能各自生成独立的低位和高位链表副本
节点重复迁移:拆分后的链表会被复制到新数组的不同位置,但并发操作可能导致同一节点被不同线程迁移到多个位置,形成重复


















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









