






1,DeepSeek
DeepSeek手机版本和Deepseek使用技巧介绍,有一些技巧可以帮助用户更好地利用该工具。首先,利用高级搜索功能,可以通过设置特定的过滤条件,缩小搜索范围,从而提高找到相关内容的概率。其次,定期更新应用版本,确保使用最新的功能和修复,保持良好的使用体验。此外,合理利用书签功能,可以将常用的搜索结果保存,方便日后快速访问。最后,用户可以通过参与社区讨论,获取其他用户的使用心得和技巧,进一步提升搜索效率。
提示词:
链接:https://pan.quark.cn/s/205e13243653
2,剪映pojie
通过剪映手机版,获取一堆必须VIP才能用的功能和素材,下载剪映特殊版本,链接地址如下:
链接:https://pan.quark.cn/s/5478bf16982e
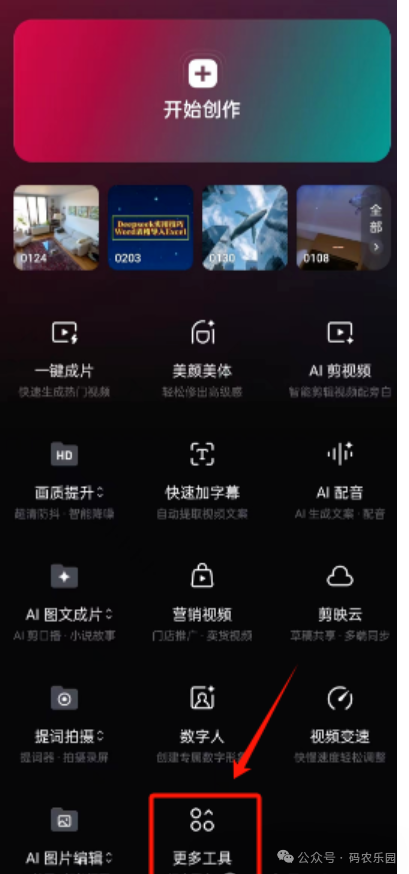
1),首先,打开剪映首页“更多工具” 如下图所示:
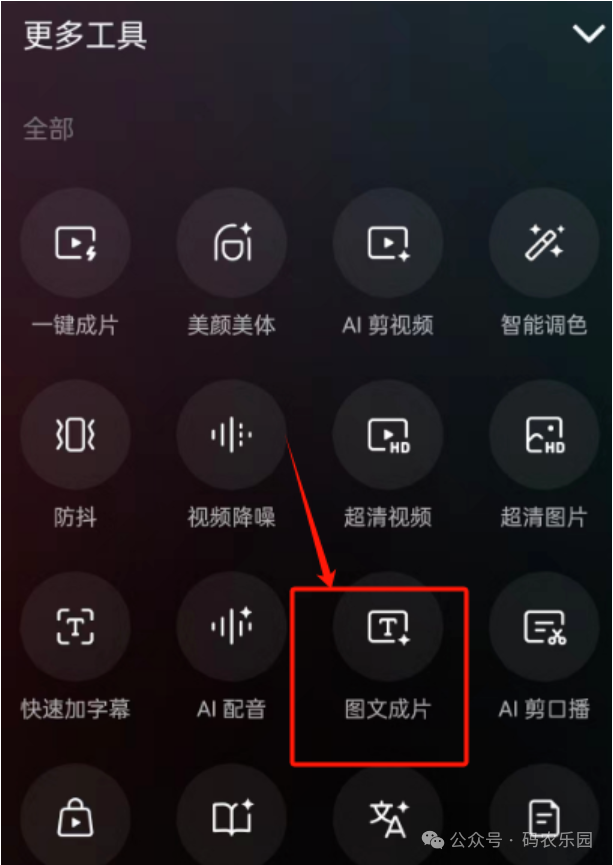
2),然后在选择“图文成片”这个选项
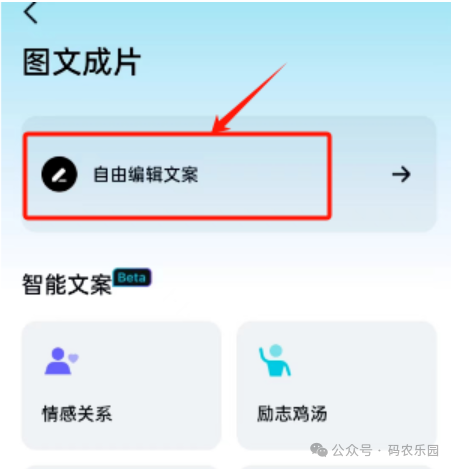
3)第三步 在选择图文成片
生成图文可以使用Deepseek生成

4),最后生成点应用生成视频即可;

生成视频有水印,可以通过视频去水印工具“HitPaw Watermark Remover,一键视频去水印神器”
去水印》》》
链接:https://pan.quark.cn/s/f4d4f390ae87
3,豆包插件
豆包插件,
可对页面内容进行总结,文章改写、AI翻译等等。
使用步骤:
第一步:打开谷歌浏览器,并访问扩展程序页面 chrome://extensions
第二步:开启页面右上角的「开发者模式」

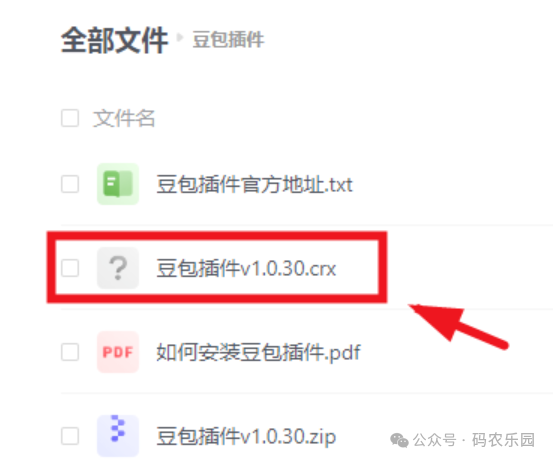
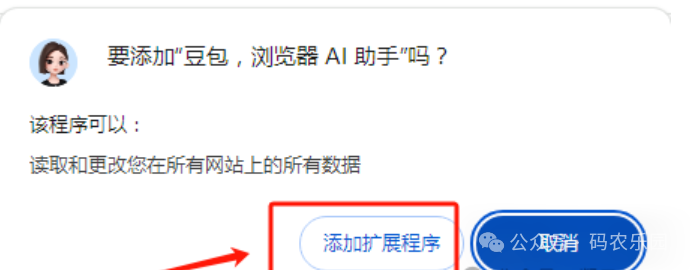
链接:https://pan.quark.cn/s/1ec0056d9335
大幅提升工作效率,告别加班熬夜。
轻松应对海量信息,快速找到关键内容。
做出更明智的决策,把握每一个机会。
还在等什么?赶紧收藏这篇文章,开始你的 DeepSeek 逆袭之旅吧!
关注我们,获取更多 DeepSeek 使用技巧和效率提升秘籍!
#DeepSeek #效率工具 #逆袭 #职场 #学习
网盘资源分享:
https://kdocs.cn/l/cior4AhTyOpG



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











