









1. 性能测试结果分析
1. 指标分析
(一) 以Linux+Java架构系统为例, 当得到性能测试结果, 拿到数据之后, 如何分析性能瓶颈在哪里呢?一般指标分析思路如下:
- 判断业务指标(响应时间, 成功率, TPS)是否满足目标?
- 若不满足, 则先排除施压机和外围依赖系统是否有瓶颈?
- 若没有, 则关注网络, DB性能以及连接数是否存在性能问题?
- 若不存在, 则检查应用系统如下指标是否正常:
4.1. 硬件: 磁盘是否写满, 内存是否够用, CPU利用率以及Load值是否正常
4.2. 软件: JVM内存管理及回收是否合理, 应用程序本身代码是否隐藏性能问题
(二) 性能部署结构图如下
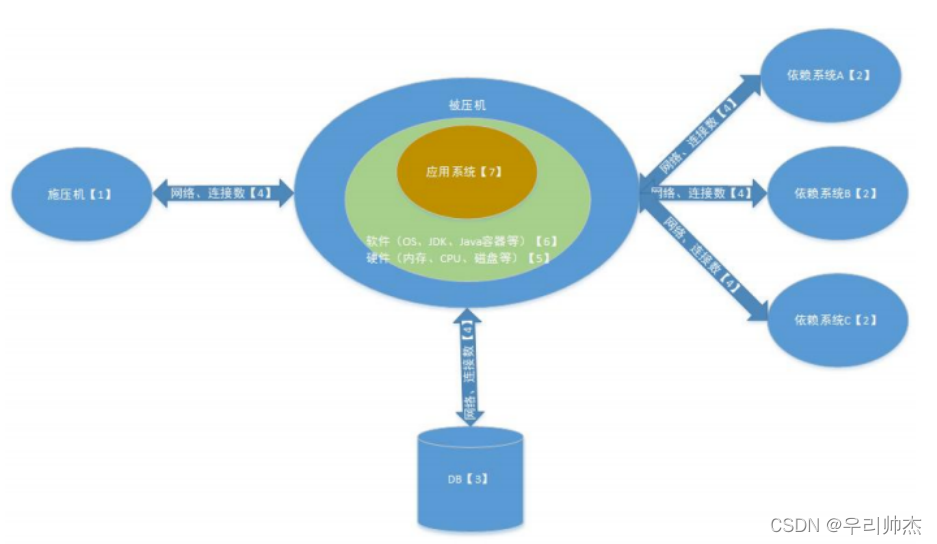
我们在定位的时候, 可以根据标注中的数字: 1, 2, 3, 4, 5, 6, 7依次进行排查, 先排查施压机是否有瓶颈, 接着看后端依赖系统, DB, 网络等, 最后看被压机本身, 列如响应时间逐渐变慢, 一般来说是外围依赖的系统出现的瓶颈导致整体响应变慢.
1.1. 系统瓶颈分析
服务器负载瓶颈经常表现为, 服务器受到的并发压力比较低的情况下, 服务器的资源利用率比预期要高, 甚至高很多. 导致服务器处理能力严重下降, 最终有可能导致服务器宕机, 实际性能测试工作中, 经常会用到以下三种类型资源指标判定是否存在服务器负载瓶颈: CPU利用率, 内存使用率, Load.
一般CPU使用率应低于50%, 如果过高有可能程序算法消耗太多CPU, 或者某些代码块进行不合理的使用, Load值尽量小于CPU核心数, 其中CPU和Load一般与并发数成正比
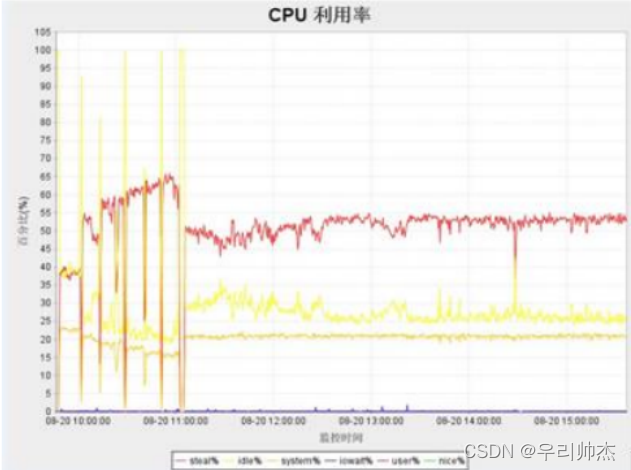
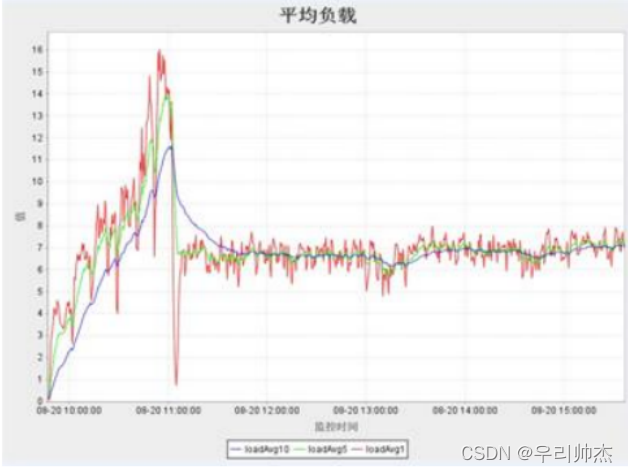
内存可以通过两种方式来看:
1. 当vmstat命令输出的si和so值显示为非0值, 则表示剩余可以支配的屋里内存已经严重不足, 需要通过与磁盘交换内容来保持系统稳定; 由于磁盘处理的速度远远小于内存, 此时就会出现严重的性能下降, si和so的值越大, 表示性能瓶颈越严重
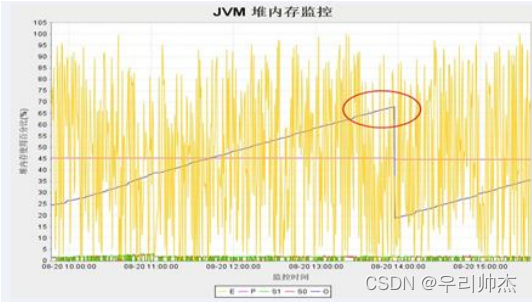
2. 用工具监控内存使用情况, 如果出现如下图的增长趋势, (used曲线呈线性增长), 有可能系统内存沾满的情况;

如果出现内存占用一直上升的趋势, 有可能系统一直在创建新的线程, 旧的线程还未销毁, 或者应用申请了堆外内存, 一直没有回收导致内存一直增长
1.2. JVM瓶颈分析
对于Java应用来说, 过高的GC频率也会在很大程度上降低应用的性能, 即使采用了并发收集的策略, GC产生非停顿时间积累起来也是不可忽略的, 特别是出现了cmsGC失败, 导致fullGC的场景
①CMSGC频率过高
当在一段较短的时间区间内, cmsGC值超出预料的大, 那么说明该JAVA应用在处理对象策略上存在一些问题, 即过多过快的创建了长寿命周期的对象. 或者old区大小分配或者回收比例设置的不合理, 导致cms频繁触发, 下面看一张gc监控图(蓝色线代表cmsGC)
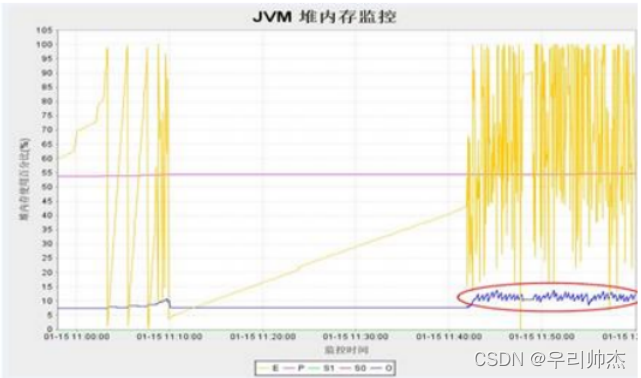
由图可以看出cmsGC非常频繁, 后经分析是因为jvm参数-XX: CMSInitiatingOccupancyFraction设置为15, 比例太小导致cms比较频繁, 这样可以扩大cmsgc占old区比例, 降低cms频率注
调优后的图如下:
②FullGC频繁触发
当采用cms并发回收算法, 当cmsgc回收失败时会导致fullgc

由上图可以看得出fullgc的耗时非常长, 在6-7s左右, 这样会严重影响应用的响应时间,经分析是因为cms比例过大, 回收频率较慢导致, 调优方式: 调小cms回收比例, 尽早触发cmsgc, 避免触发fullgc, 调优后回收情况如下

可以看出cmsgc时间缩短了很多, 优化后可以大大提高, 从上面两个例子可以看出cms比例不是绝对的, 需要根据应用的具体情况来看, 比如应用创建的对象存活周期长, 且对象较大, 可以适当提高cms的回收比例
③内存泄漏
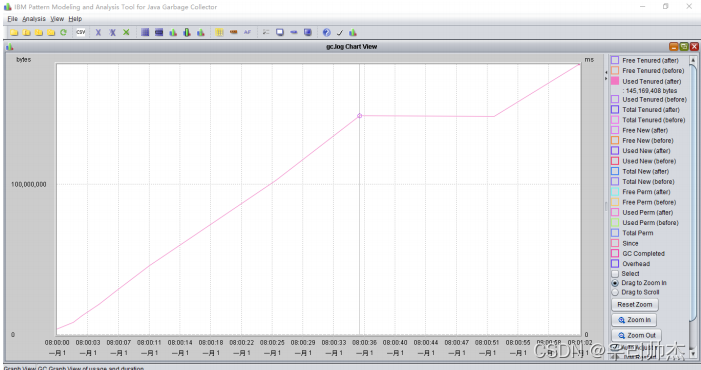
分析: 每次cmsgc没有回收干净, old区呈上升趋势, 疑似内存泄漏, 最终有可能导致OOM, 这种情况就需要dump内存进行分析:
找到oom内存dump文件, 具体的文件配置在jvm参数里,
-XX: HeapDumpPath=/home/admin/logs
-XX: ErrorFile=/home/admin/logs/hs_err_pid%p.log
2. 建模分析
2.1. 理发店模型
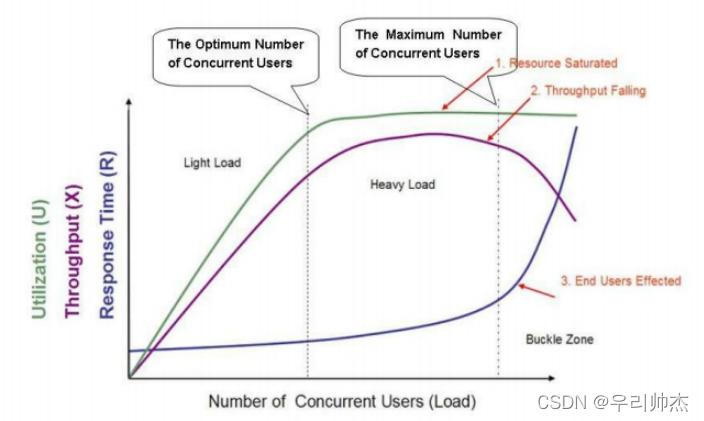
图中展示的是一个标准的软件性能模型, 在图中有三条曲线, 分别表示资源的利用情况, (Utilization, 包括硬件资源和软件资源), 吞吐量(Throughput, 每秒事务数), 以及响应时间(Response Time), 图中横坐标从左到右表示并发用户数不断增长.
当系统负载等于最佳并发用户数时, 系统的整体效率最高, 没有资源浪费, 用户也不需要等待; 当系统负载处于最佳并发用户数和最大用户并发数之间时, 系统可以继续工作, 但是用户的等待时间延长, 满意度开始降低, 并且如果负载一直持续, 将会导致有些用户无法忍受而放弃, , 而当系统负载大于最大用户并发数时, 将会注定导致某些用户无法忍受超长的响应时间而放弃, 所以我们应该保证最佳并发用户数要大于系统的平均负载
2.2. 压力变化模型
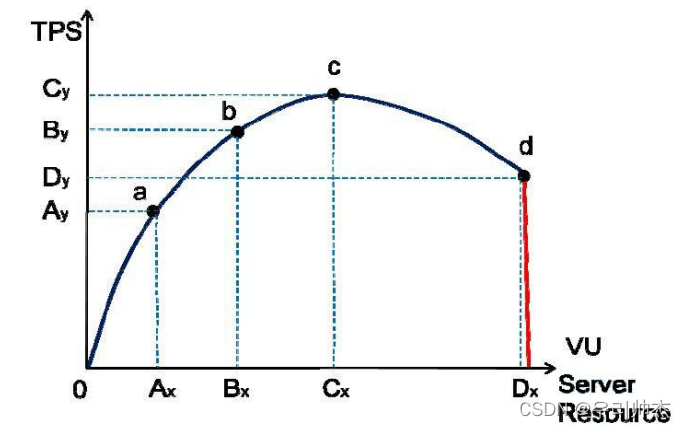
随着单位时间流量的不断增长, 被测系统的压力不断增大, 服务器资源会不断被消耗, TPS值会因为这些因素而发生变化, 而且符合一定规律
a点: 性能期望值
b点: 高于期望, 系统资源处于玲姐点
c点: 高于期望, 拐点
d点: 超过负载, 系统崩溃
2.3. 容量计算模型

以爱吼网性能测试为例:
- 通过分析运营数据, 可知道当前系统每小时处理的PV数
- 通过负载测试, 可以知道当前系统每小时的最大处理的PV数
系统每小时PV处理的剩余量 = 系统每小时最大处理的PV数 - 系统每小时处理的PV数
假设爱吼网用户负载基本成线性增长, 现在有系统用户数为70万, 根据运维推广计划, 1年内爱吼网用户将达到1000万, 即增长了14倍, 即:
系统每小时PV处理增加量 = 当前系统每小时处理的PV数 * 14 - 当前系统每小时处理的PV数
系统每天PV处理的增加量 = 系统每小时处理的PV增加量 * 每天系统负载增加率 * 24
所以,在正常负载条件下:
系统可支持正常运行的天数 = 系统每小时PV处理的剩余量 * 24 / 系统每天PV处理的增加量
假设爱吼网后续部署升级天数已知, 提前升级的天数:
系统可支持正常运行的天数 - 部署天数
3. 性能测试报告
一份好的性能测试报告: 不仅要反馈缺陷问题, 更要对问题进行深入分析, 并提出相应的解决方案, 内容一般包括以下4个方面:
- 测试目标
- 测试结论
- 测试问题&优化建议
- 测试结果&分析
可以根据不同需求对象提供相应有价值的信息, 对测试人员而言, 性能测试需求来自于用户, 开发, 运维的三方面, 用户和开发关注的是与专业业务需求相关的产品指标, 而运维人员关注的是与硬件消耗相关的资源指标
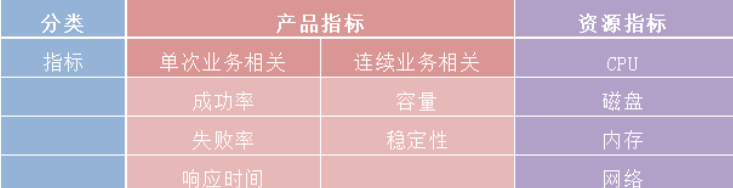
(1)用户角度:
用户关注的是单次业务的相关体验效果, 譬如一次操作的响应快慢, 一次请求是否成功, 一次连接是否失败等, 反应单次业务相关指标包括:
①成功率
②失败率
③响应时间
(2)开发角度:
开发人员更关注的是系统层面的指标
①容量: 系统能够承载的最大用户访问量是多少?
②稳定性: 系统是否支持7*24小时的业务访问
(3)运维角度:
运维人员更关心的是硬件资源系统的消耗情况














 564
564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









