










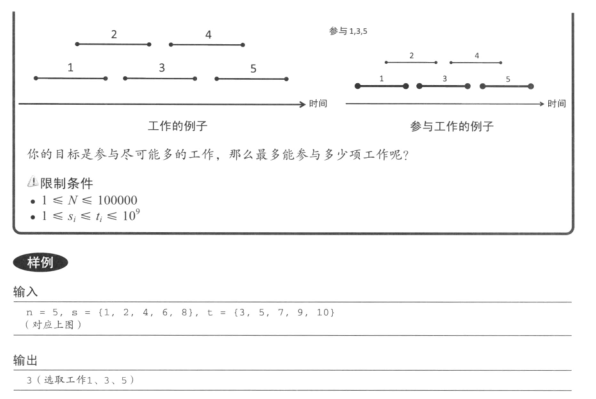
分析:
拿到这道题目,首先要看清楚最终的题目要求,它的要求是参与尽可能多的工作,并不是说工作总时间最长。
对于这题我们其实可以使用贪心算法,就是不断选取当前最优策略
我们不断选取工作,其实可以有以下几种思路进行选取,并进行聚反例来排除这种思路:
1.在可选的工作中,选取开始时间最早的.
反例:
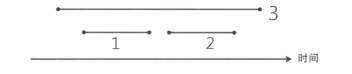
这种情况下先根据开始最早原则选取3号工作,这样剩下的1,2工作都不能被选取,而我们明显可以看到如果1,2工作,其工作数量是只比选取1号工作多的------不可取
2.在可选的工作中,选取用时最短的的:
反例:

这种情况下按照用时最短的原则选取,先选3,那么剩下的1,2都无法选取,和第一种情况是一样的,还不如选取1,2工作更满足题意------不可取
3.在可选的工作中选取与其他可选工作重叠最少的工作:
反例:

先选取5号工作,之后依次选取1和4,明显不对,我们有一种更符合的情况,那就是1,2,3,4-------不可取
4.在可选的工作中,选取结束时间最早的工作:
最终我们用的就是这种情况,并没有反例,我也确实找了好久没有找到。对于这种思路,大家可以想想,结束的时间越早,那么剩余的供选择的时间范围也就更广。
源代码:
#include<iostream>
#include<algorithm>
#include<cstdlib>
using namespace std;
#define Max_N 100000
//int start[Max_N];
//int end[Max_N];
int n;
pair<int,int> p[Max_N];
int main()
{
cin>>n;
for(int i=0;i<n;i++)
{
int start,end;
cin>>start>>end;
p[i]=make_pair(end,start);
} //输入数据,并组成pair对保存在数组中
sort(p,p+n); //按照pair中第一个关键词进行升序排序
int last=0,ans=0;
cout<<"选择的工作的起始时间有:"<<endl;
for(int i=0;i<n;i++)
{
if(p[i].second>last) //现在寻找的下一个工作的开始时间大于上一次工作的结束时间,则选择该次工作
{
last=p[i].first;
ans++;
cout<<p[i].second<<"--"<<p[i].first<<endl;
}
}
cout<<"共选择了 "<<ans<<" 个工作";
return 0;
}PS:这次选择了使用截图的方式,直接将题目用截图的方式展示出来,省去了之前手敲题目的繁杂,也可以让我将更多的精力放在代码研究和思路探索与方案分析上,以后本系列的博文也会采取这种方式~














 626
626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









