






一、form表单以get方式提交。
数据直接在URL上拼接,以key-values形式,间隔以&,除了“a~z”,"A~Z","0~9",",","*","-","_","*"等字符外,其他都是不安全字符。需要进行编码。空格编码成"+"。
当出现不安全字符时,在发送到服务器时,浏览器会对这些字符进行编码。通常会是以utf-8进行编码。字符会转换成一个或多个字节(中文以二个字节)。然后每个字节会被表示成"%xy"格式的由三个字符组成的字符串。xy是字节的2位十六进制数表示(一个字节8位二进制数)。
也可以用javascript对数据进行encodeURIComponent(url);(没用过)
现在的URL就成了ASCII范围内的字符了。然后以iso-8859-1的编码方式转换成二进制随着请求头一起发送出去。对于get方式来说,没有请求实体,含有数据的url都在请求头里面。
注意:这里进行了两次编码。第一次是使用UTF-8第二次是使用iso-8859-1编码成能在网上传输的二进制。
现有问题来到了服务器端。每种服务器默认的编码方式都可能不同,比如tomcat默认编码就是iso-8859-1, 而resin默认编是utf-8。
按道理服务器端也会做两次的解码动作,第一次是对二进制内容的iso-8859-1的解码,第二次是使用服务器默认的编码对数据进行解码。
因此我们使用request.getParameter(“name”)得到的数据是经过两次解码的.
当tomcat使用iso-8859-1对数据进行第二次解码时,因为对应客户端编码是utf-8
因此我们使用request.getParameter(“name”)就肯定乱码.
如果我们不去改变tomcat的默认编码,可以使用
new String(request.getParameter(“name”).getBytes(“iso-8859-1″), “utf-8″);手工重新解
码.request.setCharacterEncoding(“utf-8″)这种方式对于get方式提交数据是无效的,
但是对post方式提交数据却是有效的.因为get没有request body.
通常的做法还是修改tomcat的默认编码:
在server.xml中的connector加上URIEncoding=”UTF-8″即可
<%@ page language="java" contentType="text/html; charset=GB18030"
pageEncoding="GB18030"%>
<%
//request.setCharacterEncoding("iso-8859-1");
String name=request.getParameter("name");
if(name!=null && !name.equals("")){
System.out.println(new String(request.getParameter("name").getBytes("iso-8859-1"), "gbk"));(第一次编码取决于 charset 是GBK这里就是GBK 是UTF8这里就是UTF-8底下有实验1)。
}
%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=GB18030">
<title>Insert title here</title>
</head>
<body>
<form action="Get.jsp" method=get">
姓名:<input type="text" name="name" ><br>
<input type="submit" value="上交">
</form>
</body>
</html>
输入中文输出的结果就不会乱码。
实验1

输入:阮行诗 链接的地址是:http://localhost:8080/CharacterOrEncoding/NewFile.jsp?name=%C8%EE%D0%D0%CA%AB

输入:阮行诗 链接的地址:http://localhost:8080/CharacterOrEncoding/NewFile1.jsp?name=%E9%98%AE%E8%A1%8C%E8%AF%97
利用javascript 里的 var str=encodeURIComponent("阮行诗")
alert(str);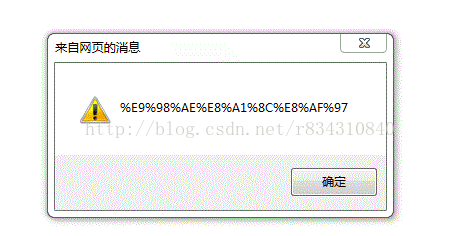
图一和图二的链接地址不一样说他们的第一次编码使用的格式并不一样。
对于第一个用 String(request.getParameter("name").getBytes("iso-8859-1"), "gbk"));可以重新得到字符串"阮行诗"说明第一次是用GBK格式编码的。
对于第二个用 String(request.getParameter("name").getBytes("iso-8859-1"), "UTF-8")可以重新得到字符串"阮行诗"说明第一次是用UTF-8编码的。
综上不难发现他们的第一次编码使用的格式取决于jsp页面参数 charset的值 。
对于post方式只要相应的改不request.setCharacterEncoding("GBK")或request.setCharacterEncoding("UTF-8");
二、form表单以post方式提交。
post方式提交的数据也是必须进行编码的.
如果form所在html文件指定了编码,就使用那个编码进行url编码.
从上面的实验可以看出,其实get也是这样的。
对于该链接的http://wenku.baidu.com/view/7effb4d676a20029bd642d87.html提到的关于get提交的不安全字符第一次编码使用的是GBK还是UTF-8这是浏览器的事情,不同的浏览器有不同的作法并不认可。
补充:
1.String下的getBytes(String CharsetName) 使用指定的字符集将此String 解码为字节序列,并将结果存储到一个新的字节数组中。
String 构选函数String(byte[] bytes, String charsetName) 构造一个新的String,方法是使用指定的字符集解码指定的字节数组。
resp.setContentType("text/html;charset=utf-8");是用来告诉浏览器页面的编码方式的,resp.setCharacterEncoding("utf-8");是用来告诉服务器请求的编码方式的。
对于这两个如同时出现,第二个会覆盖第一个的作用















 5322
5322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









