







R的数据类型与相应运算
(学习资料参考北京大学李东风老师《R语言教程》)
6 字符型数据及其处理
6.1 字符型向量
字符型向量是元素为字符串的向量。 如:
s1 <- c('abc', '', 'a cat', NA, '李明')
结果会在右上角的环境中如下显示:

注意,空字符串并不能自动认为是缺失值, 字符型的缺失值仍用NA表示。
6.2 paste()函数
针对字符型数据最常用的R函数是 paste() 函数。
paste()用来连接两个字符型向量, 元素一一对应连接, 默认用空格连接。
如输入 paste(c("ab", "cd"), c("ef", "gh")) ,输出结果如下:

相当于 c("ab ef", "cd gh") 。
paste()在连接两个字符型向量时采用R的一般向量间运算规则, 而且可以自动把数值型向量转换为字符型向量。 可以作一对多连接,.
如输入 paste("x", 1:3) ,输出结果如下:

相当于 c("x 1", "x 2", "x 3")。
- 用
sep=指定分隔符, 如paste("x", 1:3, sep="")结果相当于c("x1", "x2", "x3")。 - 使用
collapse=参数可以把字符型向量的各个元素连接成一个单一的字符串, 如paste(c("a", "b", "c"), collapse="")结果相当于"abc"。
6.3 转换大小写
toupper() 函数把字符型向量内容转为大写,tolower() 函数转为小写。
如:
toupper('aB cd')
输出结果如下:

再如:
tolower(c('aB', 'cd'))
输出结果如下:
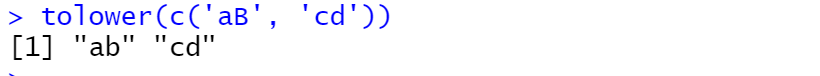
ps. 这两个函数可以用于不区分大小写的比较, 比如,不论x的值是’JAN’, ‘Jan’还是’jan’, toupper(x)=='JAN'的结果都为TRUE。
6.4 字符串长度
用 nchar(x, type='bytes') 计算字符型向量 x 中每个字符串的以字节为单位的长度,这一点对中英文是有差别的, 中文通常一个汉字占两个字节,英文字母、数字、标点占一个字节。
用 nchar(x, type='chars') 计算字符型向量 x 中每个字符串的以字符个数为单位的长度,这时一个汉字算一个单位。
在画图时可以用 strwidth() 函数计算某个字符串或表达式占用的空间大小。
6.5 取子串
substr(x, start, stop)从字符串 x 中取出从第start个到第stop个的子串, 如:
substr('JAN07', 1, 3)
输出结果如下:

- 如果
x是一个字符型向量,substr将对每个元素取子串。如:
substr(c('JAN07', 'MAR66'), 1, 3)
输出结果如下:

- 用
substring(x, start)可以从字符串 x 中取出从第start个到末尾的子串。如:
substring(c('JAN07', 'MAR66'), 4)
输出结果如下:
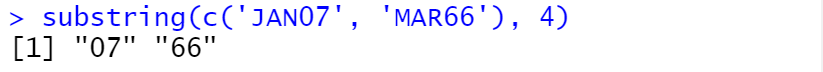
6.6 类型转换
- 用
as.numeric()把内容是数字的字符型值转换为数值。as.numeric()是向量化的, 可以转换一个向量的每个元素为数值型。
先看第一个:
substr('JAN07', 4, 5)
输出结果如下:

意思是取字符串中第4、5个,得到结果是07字符串
再看第二个
substr('JAN07', 4, 5) + 2000
输出结果如下:

因为得到的07是字符串,不能和2000相加,所以出现报错,如果想要他们相加做如下处理:
as.numeric(substr('JAN07', 4, 5)) + 2000
输出结果如下:

此时将第一个字符串变成数值07,就可以和2000相加。
再如:
as.numeric(substr(c('JAN07', 'MAR66'), 4, 5))
输出结果如下:

- 用
as.character()函数把数值型转换为字符型,如:
as.character((1:5)*5)
输出结果如下:

- 为了用指定的格式数值型转换成字符型, 可以使用
sprintf()函数, 其用法与C语言的sprintf()函数相似, 只不过是向量化的。例如:
sprintf('file%03d.txt', c(1, 99, 100))
输出结果如下:

没太看懂??
6.7 字符串拆分
用 strsplit() 函数可以把一个字符串按照某种分隔符拆分开,例如:
x <- '10,8,7'
strsplit(x, ',', fixed=TRUE)[[1]]
输出结果如下:

如果想把 x中各数值求和,可用以下函数:
sum(as.numeric(strsplit(x, ',', fixed=TRUE)[[1]]))
输出结果如下:

6.8 字符串替换功能
用 gsub() 可以替换字符串中的子串, 这样的功能经常用在数据清理中。 比如,把数据中的中文标点改为英文标点, 去掉空格,等等。 如:
x <- '1, 3; 5'
gsub(';', ',', x, fixed=TRUE)
输出结果如下:

这里 gsub 函数,把原来x中的分号换成了逗号输出。
再举个例子:
strsplit(gsub(';', ',', x, fixed=TRUE), ',')[[1]]
输出结果如下:

以上是先将x中的分号换成逗号,再按分隔符拆开
6.9 正则表达式
正则表达式 (regular expression) 是一种匹配某种字符串模式的方法。 用这样的方法,可以从字符串中查找某种模式的出现位置, 替换某种模式,等等。 这样的技术可以用于文本数据的预处理, 比如用网络爬虫下载的大量网页文本数据。 R中支持perl语言格式的正则表达式, grep() 和 grepl() 函数从字符串中查询某个模式, sub() 和 gsub() 替换某模式。 比如, 下面的程序把多于一个空格替换成一个空格:
gsub('[[:space:]]+', ' ', 'a cat in a box', perl=TRUE)
输出结果如下:
















 6115
6115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









