









一、五种基本数据结构
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)
| 结构类型 | 结构可存储值 | 结构读写能力 | 使用命令 | 底层数据结构 |
|---|---|---|---|---|
| String | 字符串、整数或浮点数 | 对字符串或字符串的一部分进行操作,对整数或浮点数进行自增或自减 | get、set、del | SDS |
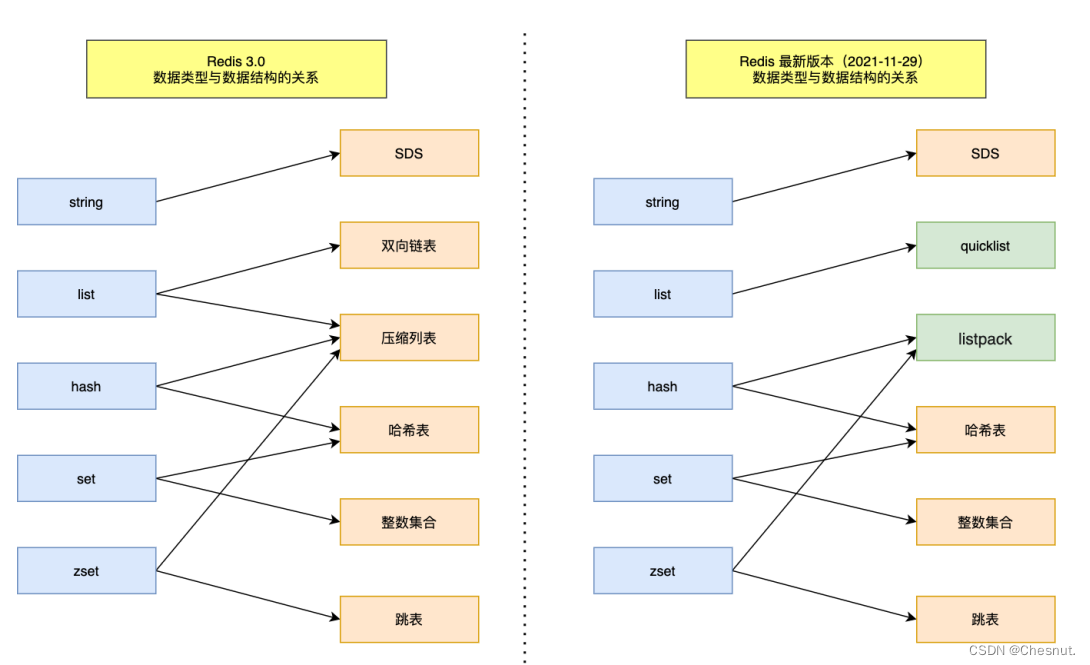
| List | 链表,链表上每个节点包含一个字符串 | 对链表两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素 | lpush、lrange、index、lpop | 双向链表/压缩列表 |
| Set | 字符串的无序集合 | 是否存在、添加、获取、删除字符串;计算交集、并集、差集等 | sadd、smember、sismember、srem | 哈希表/整数集合 |
| Hash | 包含键值对的无序散列表 | 添加、获取、删除单个元素 | hset、hget、hgetall、hdel | 压缩列表/哈希表 |
| Zset | 和Hash一样存储键值对 | 字符串成员与浮点分数之间的有序映射、元素的排列顺序由分数的大小决定;包含方法由添加、获取、删除单个元素及根据分值范围或成员获取元素 | zadd、zrange、zrangebyscore、zrem | 压缩列表/跳表 |
Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
二、四种新增数据结构
BitMap(2.2 版新增)
bit 是计算机中最小的单位,使用它进行储存将非常节省空间,特别适合⼀些数据量大且使用二值统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
HyperLogLog(2.8 版新增)
HyperLogLog用于基数统计,统计规则是基于概率完成的,不准确,标准误算率是 0.81%。优点是,在输入元素的数量或者体积非常大时,所需的内存空间总是固定的、并且很小。可用于海量数据基数统计的场景,比如百万级网页 UV 计数等;
GEO(3.2 版新增)
存储地理位置信息的场景,并对存储的信息进⾏操作。底层是由Zset实现的,使用GeoHash编码方法实现了经纬度到Zset中元素权重分数的转换,这其中的两个关键机制就是「对⼆维地图做区间划分」和「对区间进⾏编码」。 ⼀组经纬度落在某个区间后,就⽤区间的编码值来表示,并把编码值作为Zset元素的权重分数比如滴滴叫车;
Stream(5.0 版新增)
消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
三、底层数据结构实现
1. 简单动态字符串(Simple Dynamic String,SDS)

- SDS可以存储字符串,还可以存储二进制数据,包括空字符。这使得SDS在处理二进制数据时更为灵活,不受空字符的限制。
- 缓存长度信息:SDS在头部保存了字符串的长度信息,因此可以在0(1)的时间复杂度内获取字符串的长度。这样,不需要遍历整个字符串来计算长度,提高了获取长度的效率。
- 动态扩容:SDS可以根据实际存储的数据动态扩容。当字符串长度变长时,SDS会自动进行内存的扩展,而不需要像C语言中的传统字符串那样手动管理内存。
2. 双向链表
双端链表的链表节点可以保存不同类型的值,支持在两端进行元素的快速插入和删除,并且链表结构提供了表头指针和表尾指针,获取链表的表头节点和表尾节点的时间复杂度只需O(1);获取链表数量的时间复杂度也只需O(1);
缺点:
- 链表每个节点之间的内存都是不连续的,意味着无法很好利用 CPU 缓存;
- 保存一个链表节点的值都需要一个链表节点结构头的分配,内存开销较大。
3. 压缩列表
压缩列表是一种紧凑的、可变长度,由连续内存块组成的顺序型数据结构,类似于数组,被用于存储列表和哈希表的数据。压缩列表在内存使用效率上相对较高,它可以根据数据大小进行灵活的扩容和收缩。
缺点:
- 空间扩展操作也就是重新分配内存,因此连锁更新一旦发生,就会导致压缩列表占用的内存空间要多次重新分配,直接影响到压缩列表的访问性能。
- 如果保存的元素数量增加了,或是元素变大了,会导致内存重新分配,会有连锁更新的问题。
- 压缩列表只会用于保存的节点数量不多的场景,只要节点数量足够小,即使发生连锁更新也能接受。
4. 哈希表
哈希表是一种保存键值对(key-value)的数据结构。优点在于能以O(1)的复杂度快速查询数据。Redis 采用了拉链法来解决哈希冲突,在不扩容哈希表的前提下,将具有相同哈希值的数据串起来,形成链接。
5. 整数集合
整数集合是一种专门用于存储整数值的数据结构,通过紧凑的二进制表示,提高了整数存储的效率。
6. 跳表
跳跃表是一种在链表基础上改进过来的,实现了一种多层的有序链表,当数据量很大时,跳表的查找复杂度就是O(logN)。用于实现有序集合(Sortedset)。
跳表的查找过程?
查找一个跳表节点的过程时,跳表会从头节点的最高层开始,逐一遍历每一层。在遍历某一层的跳表节点时,会用跳表节点中的 SDS 类型的元素和元素的权重来进行判断:
- 如果当前节点的权重小于要查找的权重时,跳表就会访问该层上的下一个节点。
- 如果当前节点的权重等于要查找的权重时,并且当前节点的 SDS 类型数据小于要查找的数据时,跳表就会访问该层上的下一个节点。
如果上面两个条件都不满足,或者下一个节点为空时,跳表就会使用目前遍历到的节点的level 数组里的下一层指针,然后沿着下一层指针继续查找。
举个🌰:
从头节点的顶层开始,查到第一个大于指定元素的节点时,退回上一节点,在下一层继续查找。比如我们要查找16:
- 从头节点的最顶层开始,先到节点7。
- 7的下一个节点是39,大于16,因此我们退回到7
- 从7开始,在下一层继续查找,就可以找到16。

为了避免插入操作的时间复杂度是O(N),跳表每层的数量不会严格按照2:1的比例,而是对每个要插入的元素随机一个层数。随机层数的计算过程如下:每个节点都有第一层,那么它有第二层的概率是p,有第三层的概率是p*p,不能超过最大的层数。


7. quicklist
quicklist 就是双向链表+压缩列表组合,quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表。quicklist 通过控制每个链表节点中的压缩列表的大小或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越小,连锁更新带来的影响就越小,从而提供了更好的访问性能。
8. listpack
listpack 没有压缩列表中记录前一个节点长度的字段,listpack 只记录当前节点的长度,当我们向 listpack加入一个新元素的时候,不会影响其他节点的长度字段的变化,从而避免了压缩列表的连锁更新问题。















 1452
1452











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









