







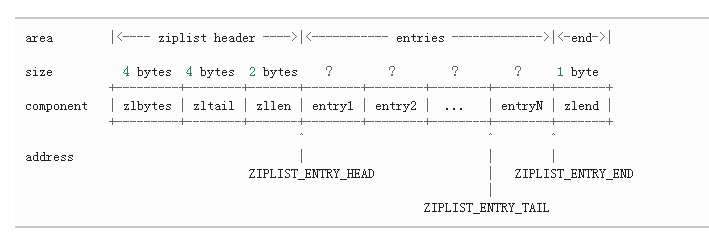
压缩列表的结构可以表示为以下:

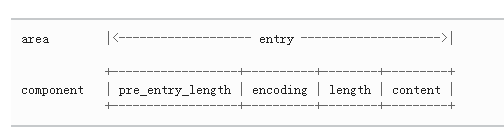
每个节点的构成:
上面的两个数据结构就可以实现整个压缩链表,其实他就是一个连续内存占用的双向链表,只不过没有以固定的节点大小来表示每个节点,而是以各个节点内部的长度标识了节点的额大小,这样可以更加剩内存,
在实现的过程中,使用了如下的技巧来保证压缩列表的性质:
1,根据编码方式的不同, pre_entry_length 域可能占用 1 字节或者 5 字节:
1 字节:如果前一节点的长度小于 254 字节,便使用一个字节保存它的值。
5 字节:如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。
2,encoding 和 length 两部分一起决定了 content 部分所保存的数据的类型(以及长度)。
其中, encoding 域的长度为两个 bit , 它的值可以是 00 、 01 、 10 和 11 :
00 、 01 和 10 表示 content 部分保存着字符数组。
11 表示 content 部分保存着整数。
以 00 、 01 和 10 开头的字符数组的编码方式如下:
| 编码 | 编码长度 | content 部分保存的值 |
| 00bbbbbb | 1 byte | 长度小于等于 63 字节的字符数组。 |
| 01bbbbbb xxxxxxxx | 2 byte | 长度小于等于 16383 字节的字符数组。 |
| 10____ aaaaaaaa bbbbbbbb cccccccc dddddddd | 5 byte | 长度小于等于 4294967295 的字符数组。 |
表格中的下划线 _ 表示留空,而变量 b 、 x 等则代表实际的二进制数据。为了方便阅读,多个字节之间用空格隔开。
11 开头的整数编码如下:
| 编码 | 编码长度 | content 部分保存的值 |
| 11000000 | 1 byte | int16_t 类型的整数 |
| 11010000 | 1 byte | int32_t 类型的整数 |
| 11100000 | 1 byte | int64_t 类型的整数 |
| 11110000 | 1 byte | 24 bit 有符号整数 |
| 11111110 | 1 byte | 8 bit 有符号整数 |
| 1111xxxx | 1 byte | 4 bit 无符号整数,介于 0 至 12 之间 |
可以看出,由于压缩列表的性质,在有些情况下会造成连锁更新的情况,比如,你将一个原本很小的节点进行了update操作,就有可能使这个节点的encoding 和 length字段重新编码,导致长度发生变化,这时对于他后面的节点,就需要更新他的pre_entry_length字段,同样,由于pre_entry_length字段的长度可以用一个字节,也可以用五个字节,所以长度也发生了变化,以此类推,导致后面的节点都需要更新,这就是压缩列表的连锁更新,但是这种更新的机会并不会特别多。















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









