






Ajax技术
AJAX = Asynchronous JavaScript and XML(异步的 JavaScript 和 XML)。
Ajax并不是新的编程语言,而是一种使用现有标准的新方法,当然也不是很新了,在97年左右,微软就发明了ajax的关键技术,但是并没有推广;随着Google eath、google suggest和gmail的广泛应用,ajax才开始流行起来。
ajax最大的优点是在不重新加载整个页面的情况下,可以与服务器交换数据并更新网页的部分内容。
ajax不需要任何浏览器插件,但是需要用户允许javascript的执行。
Ajax的应用
运用XHTML+CSS来表达资讯;
运用JavaScript操作DOM(Document Object Model)来执行动态效果;
运用XML和XSLT操作资料;
运用XMLHttpRequest或新的Fetch API与网页服务器进行异步资料交换;
注意:AJAX与Flash、Silverlight和Java Applet等RIA技术是有区分的。
目前有很多使用ajax的应用案例,比如新浪微博,google地图,今日头条等。
今天我们借助今日头条见一下ajax内容的解析,如何爬取这类网站的内容。
今日头条的搜索功能
前几天一直登不上今日头条,估计网络监管太严,很多咨询类服务商都down掉了。。。
今天终于能打开了,赶紧来讲一下ajax的内容。
【插入图片,今日头条的搜索功能】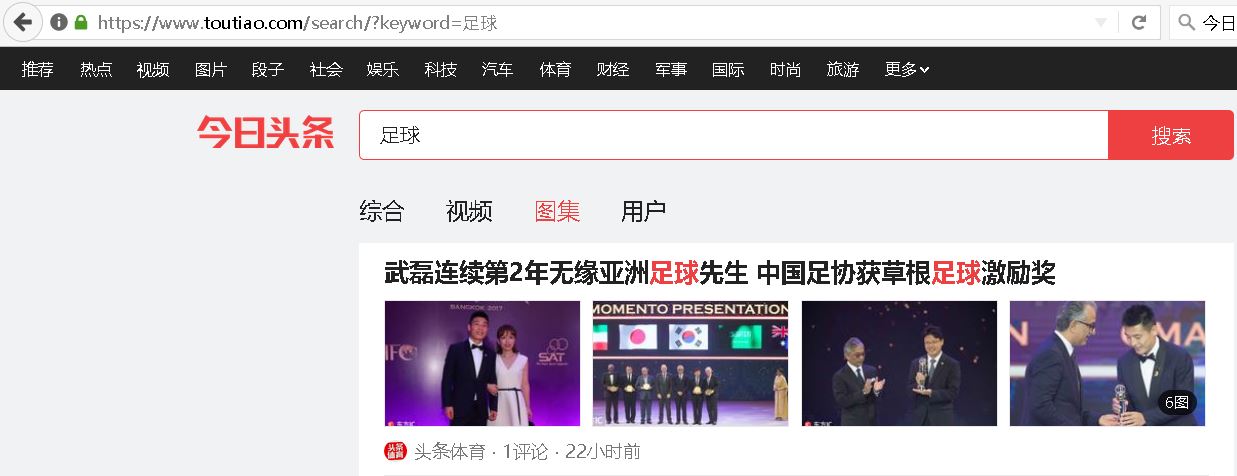
上面图片中可以看出利用今日头条搜索一些关键字,可以返回很多内容,请看四个标签,综合、视频、图集和用户,我们今天讲一下图集。也就是标签选项卡设置为图集,如何设置后面会讲清楚。
Index页的源代码
假设我们搜索足球关键字(哈哈,不搜索美女了。。。),我们看一下网页的源代码是什么情况。
【插入图片,index源代码】
源代码中除了一些基本的html标签,就是各种js了,没有我们想要的一些url内容或者图集的信息。
上面说过了,今日头条采用了ajax技术来加载内容,那么根据ajax技术的特点,肯定有一部分数据会从服务器发送到我们的浏览器上来,否则网页不会显示出这些图集的内容。
那么这些数据在哪里呢?
Ajax加载的数据在哪?
打开浏览器的调试,请选择网络标签,选择XHR内容,看下面出现的几个文件。
【插入图片,如何打开ajax加载的内容】
我们看这几个文件的类型,都是json格式的。
再看search_content的类容,除了offset的值改变止呕,其他都是一样的。因为我们滚动过页面了,每页正好显示20项内容,想必读者一下子就能明白这个offset的内容,就是用来加载多个页面的控制器。
我们看一个search_content的消息头:
【插入图片,json的消息头】
这时一个get请求,我们可以用requests库的get方法直接来请求到json文件。但是url的内容是啥呢?
大家看一下上图中的几个参数,尤其是最后的cur_tab设置为3,因为3才表示的选择的是图集,1的话是综合,2是视频,上面提到过。
我们只要改变其中的offset参数,就能够得到多个页面,每页20个内容。
我们再来看一下响应内容:
【插入图片,json的响应信息】
因为是json格式的内容,里面都是一些key:value格式的内容,我们主要关注data下面的20个内容,每个内容中都包含article_url关键字信息,这个信息就是打开每个图集的url,我们通过这个url就能访问具体的图集了。
关于网站解析的内容今天就讲到这里,我们再来看一下代码,如何获取这些每个图集的url。
1、获取index页面的json内容
import requests
from urllib.parser import urlencode
def get_page_index(offset):
#cur_tab标签一定要写正确,3才代表图集,很重要
data={
'offset':offset,
'format':'json',
'keyword':'足球',
'autoload':'true',
'count':'20',
'cur_tab':'3'
}
url='https://www.toutiao.com/search_content/?'+urlencode(data)
try:
response = requests.get(url)
if response.status_code==200:
#print(response.text)
return response.text
else:
return None
except Exception:
print('请求索引页出错!')
return None我们设置了一个offset参数,这样就能控制获取哪一个页面,也就是实现自动向下滑动的功能。
data是我们在get请求时url的参数内容,我们用一个字典来表示,使用urlencode来编码。
这个访问还是很顺利的,并没有再提交额外的header参数。
2、对json内容进行解析
import json
def parse_page_index(html):
data=json.loads(html)
result=[]
if data and 'data' in data.keys():
for item in data.get('data'):
article_url=item.get('article_url')
if article_url and ('group' in article_url):
result.append(article_url)
return result因为要解析json内容,所以导入了json库。
我们要获取的是json内容里面,data标签下各项里面的article_url信息,所以设置了一些筛选,data信息中一定要包含'data'关键字才做解析。
由于我们想要图集,虽然设置了cur_tab为3,但是返回的一些url还是不太规范,我们在url中设置一定要包含group字符串,才能视作图集。
然后将每个url都添加到result列表中。
3、开启多进程运行
from multiprocessing import Pool
def main(offset):
html=get_page_index(offset)
for url in parse_page_index(html):
print(url)
if __name__=='__main__':
p=Pool()
p.map(main,[i*20 for i in range(3)])我们先打开3个页面尝试一下,采用多进程可以快一些,虽然现在代码少,但是理念要掌握。
【插入图片,url结果】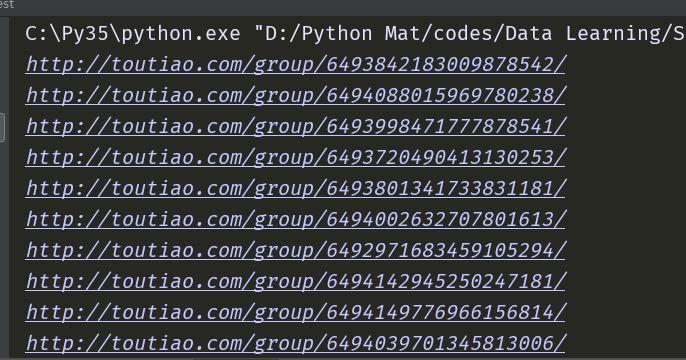
OK,今天就先到这里,明天再继续讲一下如何在这些url中获取图片。
















 105
105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









