







通过昨天的分析,我们已经能到依次打开多个页面了,接下来就是获取每个页面上宝贝的信息了。
分析页面宝贝信息
【插入图片,宝贝信息各项内容】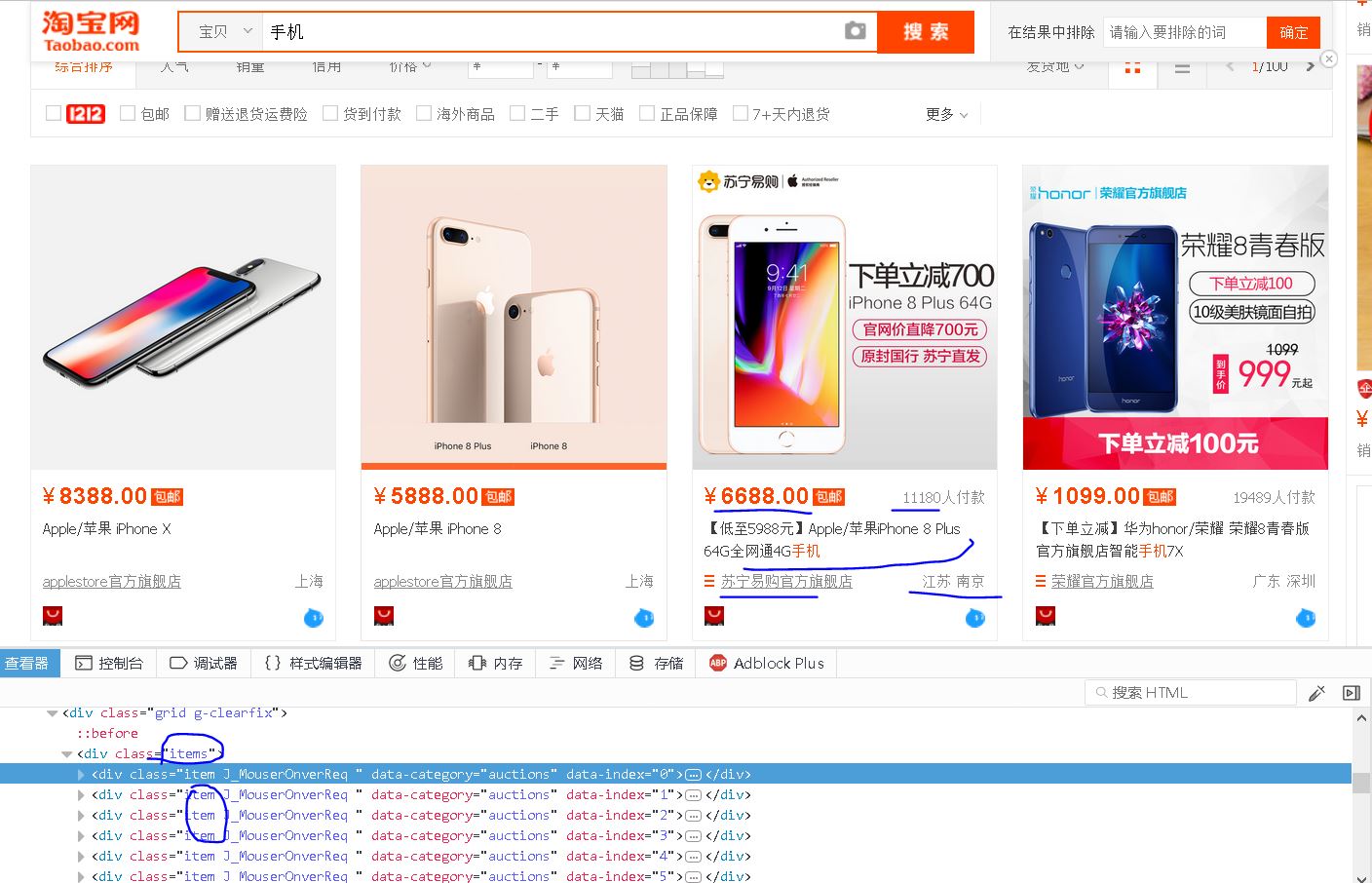
从图片上看,每个宝贝有如下信息;price,title,url,deal amount,shop,location等6个信息,其中url表示宝贝的地址。
我们通过查看器分析,每个宝贝都在一个div里面,这个div的class属性包含item。
而所有的item都在一个div内,这个总的div具有class属性为items,也就是单个页面上包含所有宝贝的一个框架。
因而,只有当这个div已经加载了,才能够断定页面的宝贝信息是可以提取的,所以再提取信息之前,我们要判断这个div的存在。
对于网页源码的解析,这次我们使用Pyquery,轮换着用一下嘛,感觉还是PyQuery比较好用,尤其是pyquery搜索到的对象还能在此进行搜索,很方便。
Pyquery的使用方法请查看我之前的文章,或者看一下API。
下面我们依次来分析一下每项信息应该如何提取。
1、Price
【插入图片,price】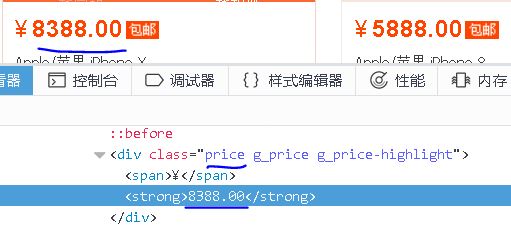
可以看出,price的信息在一个div里面,具有clas属性price,我们如果通过text来获取的话,还会将前面的人民币符号得到,回头切片切掉就好了。
2、Deal Amount
【插入图片,amount】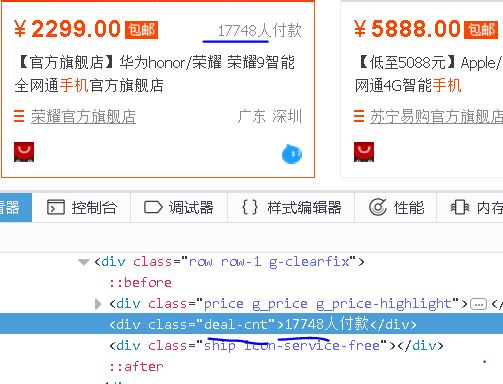
成交量信息再一个class属性为deal-cnt的div标签里面,仍然需要将最后三个字符切掉。
3、Title
【插入图片,title】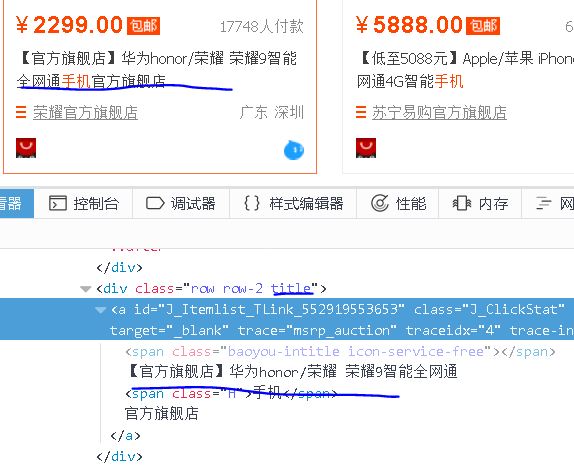
宝贝的标题在一个class属性为title的div标签里面,通过text可以获取。
4、Shop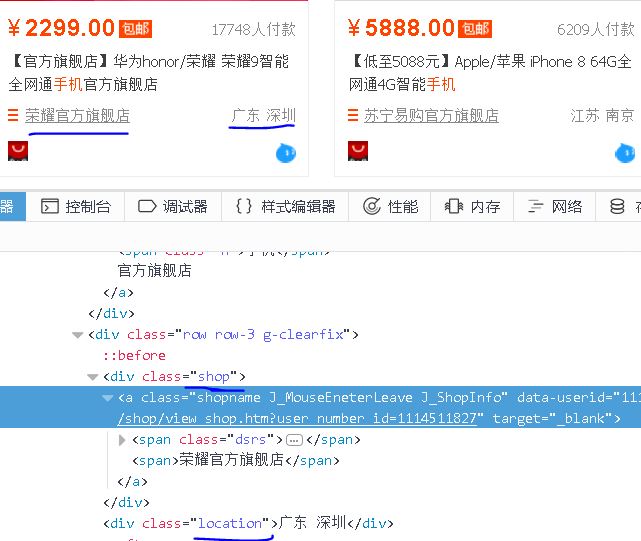
【插入图片,shop和location】
店铺名在一个class属性为shop的div标签呢。
5、Location
同上图,c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









