








Spark BroadCast
Broadcast 简单来说就是将数据从一个节点复制到其他各个节点,常见用于数据复制到节点本地用于计算,在前面一章中讨论过Storage模块中BlockManager,Block既可以保存在内存中,也可以保存在磁盘中,当Executor节点本地没有数据,通过Driver去获取数据
Spark的官方描述:
A broadcast variable. Broadcast variables allow the programmer to keep a read-only variable
* cached on each machine rather than shipping a copy of it with tasks. They can be used, for
* example, to give every node a copy of a large input dataset in an efficient manner. Spark also
* attempts to distribute broadcast variables using efficient broadcast algorithms to reduce
* communication cost.在Broadcast中,Spark只是传递只读变量的内容,通常如果一个变量更新会涉及到多个节点的该变量的数据同步更新,为了保证数据一致性,Spark在broadcast 中只传递不可修改的数据。
Broadcast 只是细粒度化到executor? 在storage前面的文章中讨论过BlockID 是以executor和实际的block块组合的,executor 是执行submit的任务的子worker进程,随着任务的结束而结束,对executor里执行的子任务是同一进程运行,数据可以进程内直接共享(内存),所以BroadCast只需要细粒度化到executor就足够了
TorrentBroadCast
Spark在老的版本1.2中有HttpBroadCast,但在2.1版本中就移除了,HttpBroadCast 中实现的原理是每个executor都是通过Driver来获取Data数据,这样很明显的加大了Driver的网络负载和压力,无法解决Driver的单点性能问题。
为了解决Driver的单点问题,Spark使用了Block Torrent的方式。
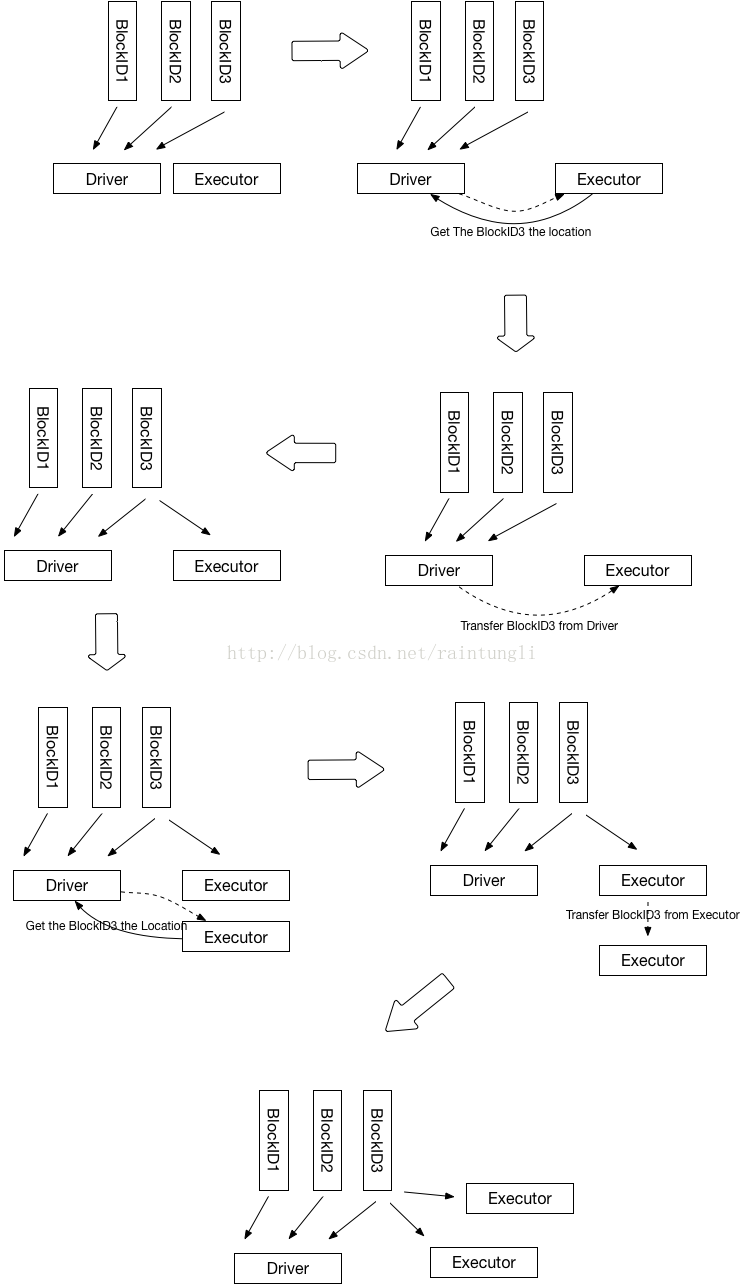
1. Driver 初始化的时候,会知道有几个executor,以及多少个Block, 最后在Driver端会生成block所对应的节点位置,初始化的时候因为executor没有数据,所有块的location都是Driver
2. Executor 进行运算的时候,从BlockManager里的获取本地数据,如果本地数据不存在,然后从driver获取数据的位置
bm.getLocalBytes(pieceId) match {
case Some(block) =>
blocks(pid) = block
releaseLock(pieceId)
case None =>
bm.getRemoteBytes(pieceId) match {
case Some(b) =>
if (checksumEnabled) {
val sum = calcChecksum(b.chunks(0))
if (sum != checksums(pid)) {
throw new SparkException(s"corrupt remote block $pieceId of $broadcastId:" +
s" $sum != ${checksums(pid)}")
}
}
// We found the block from remote executors/driver's BlockManager, so put the block
// in this executor's BlockManager.
if (!bm.putBytes(pieceId, b, StorageLevel.MEMORY_AND_DISK_SER, tellMaster = true)) {
throw new SparkException(
s"Failed to store $pieceId of $broadcastId in local BlockManager")
}
blocks(pid) = b
case None =>
throw new SparkException(s"Failed to get $pieceId of $broadcastId")
} 3. Driver里保存的块的位置只有Driver自己有,所以返回executer的位置列表只有driver
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
if (blockLocations.containsKey(blockId)) blockLocations.get(blockId).toSeq else Seq.empty
}4. 通过块的传输通道从Driver里获取到数据
blockTransferService.fetchBlockSync(
loc.host, loc.port, loc.executorId, blockId.toString).nioByteBuffer()5. 获取数据后,使用BlockManager.putBytes ->最后使用doPutBytes保存数据
private def doPutBytes[T](
blockId: BlockId,
bytes: ChunkedByteBuffer,
level: StorageLevel,
classTag: ClassTag[T],
tellMaster: Boolean = true,
keepReadLock: Boolean = false): Boolean = {
.....
val putBlockStatus = getCurrentBlockStatus(blockId, info)
val blockWasSuccessfullyStored = putBlockStatus.storageLevel.isValid
if (blockWasSuccessfullyStored) {
// Now that the block is in either the memory or disk store,
// tell the master about it.
info.size = size
if (tellMaster && info.tellMaster) {
reportBlockStatus(blockId, putBlockStatus)
}
addUpdatedBlockStatusToTaskMetrics(blockId, putBlockStatus)
}
logDebug("Put block %s locally took %s".format(blockId, Utils.getUsedTimeMs(startTimeMs)))
if (level.replication > 1) {
// Wait for asynchronous replication to finish
try {
Await.ready(replicationFuture, Duration.Inf)
} catch {
case NonFatal(t) =>
throw new Exception("Error occurred while waiting for replication to finish", t)
}
}
if (blockWasSuccessfullyStored) {
None
} else {
Some(bytes)
}
}.isEmpty
}6. 在保存数据后同时汇报该Block的状态到Driver
7. Driver跟新executor 的BlockManager的状态,并且把Executor的地址加入到该BlockID的地址集合中
private def updateBlockInfo(
blockManagerId: BlockManagerId,
blockId: BlockId,
storageLevel: StorageLevel,
memSize: Long,
diskSize: Long): Boolean = {
if (!blockManagerInfo.contains(blockManagerId)) {
if (blockManagerId.isDriver && !isLocal) {
// We intentionally do not register the master (except in local mode),
// so we should not indicate failure.
return true
} else {
return false
}
}
if (blockId == null) {
blockManagerInfo(blockManagerId).updateLastSeenMs()
return true
}
blockManagerInfo(blockManagerId).updateBlockInfo(blockId, storageLevel, memSize, diskSize)
var locations: mutable.HashSet[BlockManagerId] = null
if (blockLocations.containsKey(blockId)) {
locations = blockLocations.get(blockId)
} else {
locations = new mutable.HashSet[BlockManagerId]
blockLocations.put(blockId, locations)
}
if (storageLevel.isValid) {
locations.add(blockManagerId)
} else {
locations.remove(blockManagerId)
}
// Remove the block from master tracking if it has been removed on all slaves.
if (locations.size == 0) {
blockLocations.remove(blockId)
}
true
}如何实现Torrent?
1. 为了避免Driver的单点问题,在上面的分析中每个executor如果本地不存在数据的时候,通过Driver获取了该BlockId的位置的集合,executor获取到BlockId的地址集合随机化后,优先找同主机的地址(这样可以走回环),然后从随机的地址集合按顺序取地址一个一个尝试去获取数据,因为随机化了地址,那么executor不只会从Driver去获取数据
/**
* Return a list of locations for the given block, prioritizing the local machine since
* multiple block managers can share the same host.
*/
private def getLocations(blockId: BlockId): Seq[BlockManagerId] = {
val locs = Random.shuffle(master.getLocations(blockId))
val (preferredLocs, otherLocs) = locs.partition { loc => blockManagerId.host == loc.host }
preferredLocs ++ otherLocs
}2. BlockID 的随机化
通常数据会被分为多个BlockID,取决于你设置的每个Block的大小
| spark.broadcast.blockSize=10M |
在获取完整的BlockID块的时候,在Torrent的算法中,随机化了BlockID
for (pid <- Random.shuffle(Seq.range(0, numBlocks))) {
......
}在任务启动的时候,新启的executor都会同时从driver去获取数据,大家如果都是以相同的Block的顺序,基本上的每个Block数据对executor还是会从Driver去获取, 而BlockID的简单随机化就可以保证每个executor从driver获取到不同的块,当不同的executor在取获取其他块的时候就有机会从其他的executor上获取到,从而分散了对Driver的负载压力。















 2914
2914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









