







经过两章的基础知识学习,终于能接触到真正的数据结构了,与其他科目相同,要想学好后面的知识,首先要有良好的基础,而线性表一章则是为整个《算法与数据结构》的学习而打的基础。
一、定义
线性表(Linear List):是指n个(0个或多个)数据元素组成的有限序列。
线性表的定义强调了它的两个性质:
(1)有限(有限性):实际上计算机处理的数据均为有限,无限的一般只会存在于数学方面。
(2)序列(有序性):元素之间是有顺序的,即第一个元素无前驱,最后一个元素无后继,其余每个元素均有且仅有一个前驱和一个后继。
- 前驱、后继:指数据元素在线性表中的相对位置,如序列{A,B}中A为B的前驱,B为A的后继。
两本书均贴心地给出了线性表数学语言的定义如下:
若将线性表记为,则表中
领先于
,
领先于
,称
是
的直接前驱元素,
是
的直接后继元素,当
时,
有且仅有一个后继,当
时,
有且仅有一个前驱。如图所示:
线性表的元素个数定义为线性表的长度,当
时,称为空表。
在非空表中的每一个元素都有一个确定的位置,如是第一个数据元素,
是最后一个数据元素,
是第
个数据元素,称
为数据元素
在线性表中的位序。
但是在生活中,我们通常见到的少有一个数据元素只含一个数据项的线性表,如班级同学的信息名单,它是不是线性表呢?
当然是。在较复杂的线性表中,一个数据元素可以由若干个数据项组成。
二、线性表的抽象数据类型
相对于《大话数据结构》,《数据结构(C语言版)》的抽象数据类型写得过于抽象,以至于还得稍下功夫才能理解,我在文章中将列出《大话数据结构》版本的抽象数据类型。
ADT 线性表(List)
Data
线性表的数据对象集合为{a1,a2,...,an},每个元素的类型均为DataType(自定义),其中,
除第一个元素a1外,每个元素有且仅有一个直接前驱元素,除最后一个元素an外,每个元素有且仅
有一个直接后继元素。数据元素之间的关系是一对一关系
Operation
InitList(*L); 初始化,建立一个空线性表L。
ListEmpty(L); 线性表L存在的前提下,若其为空,返回true,反之返回false。
ClearList(*L); 线性表L存在的前提下,将其清空。
GetElem(L,i,*e); 线性表L存在的前提下,将其中第i个元素返回给元素e。
LocateElem(L,e); 线性表L存在的前提下,在其中查找与给定元素e相等的元素,查找成功返回其序号。
ListInsert(*L,i,e); 线性表L存在的前提下,将元素e插入表中第i个位置。
ListDelete(*L,i,*e); 线性表L存在的前提下,删除其中第i个元素,将其值返回给元素e。
ListLength(L); 返回线性表L的数据元素个数。
endADT相信有不少刚学完一两门编程语言的同学看到这个表就蒙了,它不像我们在学习编程语言时看到的那些完成的程序实现,而是这么一些操作的合集,通俗来讲,ADT框里就是告诉你对这个数据结构你可以实现一些什么操作,而具体的实现代码,就得靠你自己了,不过为了方便初学者理解,我会把ADT框中的代码实现完整写一遍,方便大家理解以及使用。
三、线性表的顺序存储结构
讲了半天线性表的逻辑结构,接下来就要讨论讨论如何将其存放在计算机中了,也就是它的物理结构(存储结构)——顺序存储结构。
1、概念性质
线性表的顺序存储结构:用一段地址连续的存储单元依次存储线性表的数据元素。
假设线性表的每个元素占用个存储单元,并以所占的第一个单元的地址作为数据元素的存储位置。则线性表中第
个数据元素的存储位置
和第
个数据元素的存储位置
之间满足以下关系:
一般来说,线性表的第个数据元素
的存储位置为
注:式中表示元素
的地址,可以把它理解为C语言中的&a[i]。
以下为示意图

数据元素的存储位置,通常称为线性表的起始位置或基地址。
通过上述性质,我们发现线性表可以根据数据元素间“物理位置相邻”来实现随机存取,所以线性表的顺序存储结构是一种随机存取的存储结构。
2、代码实现顺序存储方式
在两本书的学习过程中,发现他们通过不同的方式来实现顺序存储结构,以下我将根据掌握程度的难易来进行分析。
(1)一维数组实现
根据概念性质的描述,大家很容易发现线性表的顺序存储简直就是数组,所以《大话数据结构中》选择了更易理解,更易操作的数组来实现顺序表,其结构定义如下:
#define MAXSIZE 20 //存储空间初始分配量
typedef int ElemType; //简单理解为给int类型起了个外号,这样做的方便之处是修改的时候可以全局修改
typedef struct{
ElemType data[MAXSIZE]; //数组用来存储数据元素
int length; //线性表当前长度
}Sqlist; //线性表表名注:初始申请空间大小不代表线性表表长,即数组长度要大于等于线性表长度。
如此定义,使得该表的初始化操作极为简易。
void InitList(SqList *L)
{
L->length=0;
}
没错,只有这一句,让当前表长为0。因为在申明结构体变量(主函数中)时,唯一没有在这步完成的步骤就是初始化表长,所以只需要写这句。
(2)基址+存储单元数实现
相比一维数组实现,这个方法步骤较多,但实际上它的原理跟数组的相同,我想严教授是想让大家自己动手去完整实现顺序存储结构。其结构定义如下:
#define MAXSIZE 20 //存储空间初始分配量
typedef int ElemType; //为int起外号。。
typedef struct{
ElemType *data; //线性表基地址
int length; //线性表当前长度
}SqList;我将严教授的定义稍做了修改,未将其定义中的冗余设计(在存储空间不够的时候增加表长)写在里面,若想扩展学习的同学可翻阅原书(22页)中的定义学习。
不一样的结构定义,也带来了不同的初始化方法。
void InitList(SqList *L)
{
L->elem=(ElemType *)malloc(MAXSIZE*sizeof(ElemType));
if(!L->elem)
exit(OVERFLOW);
L->length=0;
}函数中第一句就是为整个表申请足够的空间,在一维数组实现的方法中未用到是因为当你申明结构体变量的时候人家就帮你把数组储存的空间申请好了,不需要你再malloc一遍;第二、三行则是判断是否成功申请到了空间;第四行应该不用再说。
四、顺序存储结构的操作实现
1、获得元素操作(GetElem)
对线性表的顺序存储来说,想要实现获得位序为i的元素,十分简单,这得益于顺序存储结构支持随机存取。就程序而言,只需将下标i-1的元素返回即可。
//初始条件:线性表L已存在,i>=1&&i<=L.length
//操作结果:用e返回L中第i个元素
Status GetElem(SqList L,int i,ElemType *e)
{
if(L.length==0||i<0||i>L.length)
return ERROR;
*e=L.data[i-1];
return OK;
}此操作实现较为容易,便不再赘述。
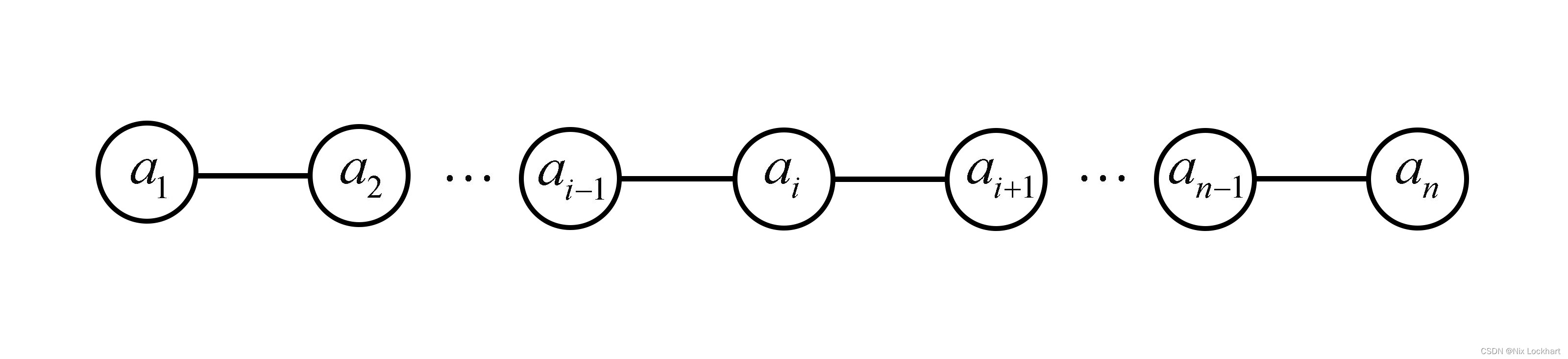
2、插入元素操作(ListInsert)
线性表的插入操作就是在线性表的第和
之间(即第
个位置上)插入一个新的元素,使一个长度为
的线性表
变为一个长度为的线性表
线性表变化如图所示
 不难看出除了在第
不难看出除了在第个位置插入的情况, 其他情况均需要把第
个元素及往后所有的元素后移一位。
操作较多,我们捋一捋:
①判断插入位置是否合理;
②若线性表长度大于等于数组长度,抛出异常或者动态增加容量(自学);
③从最后一个元素向前遍历到第i个位置,依次向后移一位;
(思考:如果从第i个元素遍历到最后一个位置,依次后移可以吗?)
④将元素插入i处;
⑤表长加1。
代码实现如下:
//初始条件:线性表L已存在,i>=1&&i<=L.length
//操作结果:L中第i个位置插入新元素e,表长加1
Status ListInsert(SqList *L,int i,ElemType e)
{
int j;
if(L->length==MAXSIZE) //判断线性表是否已满
return ERROR;
if(i>L.length||i<1) //判断输入位置是否合理
return ERROR;
if(i<=L.length) //若不在最后插入
{
for(j=L->length-1;j>i-1;j--)
L->data[j+1]=L->data[j]; //第i~length个元素均后移
}
L->data[i-1]=e; //将元素插在第i处,下标为i-1
L->length++; //表长加1
return OK;
}代码应该不难理解,大家也可以根据自己的思路来写,实现方式还是比较灵活的。
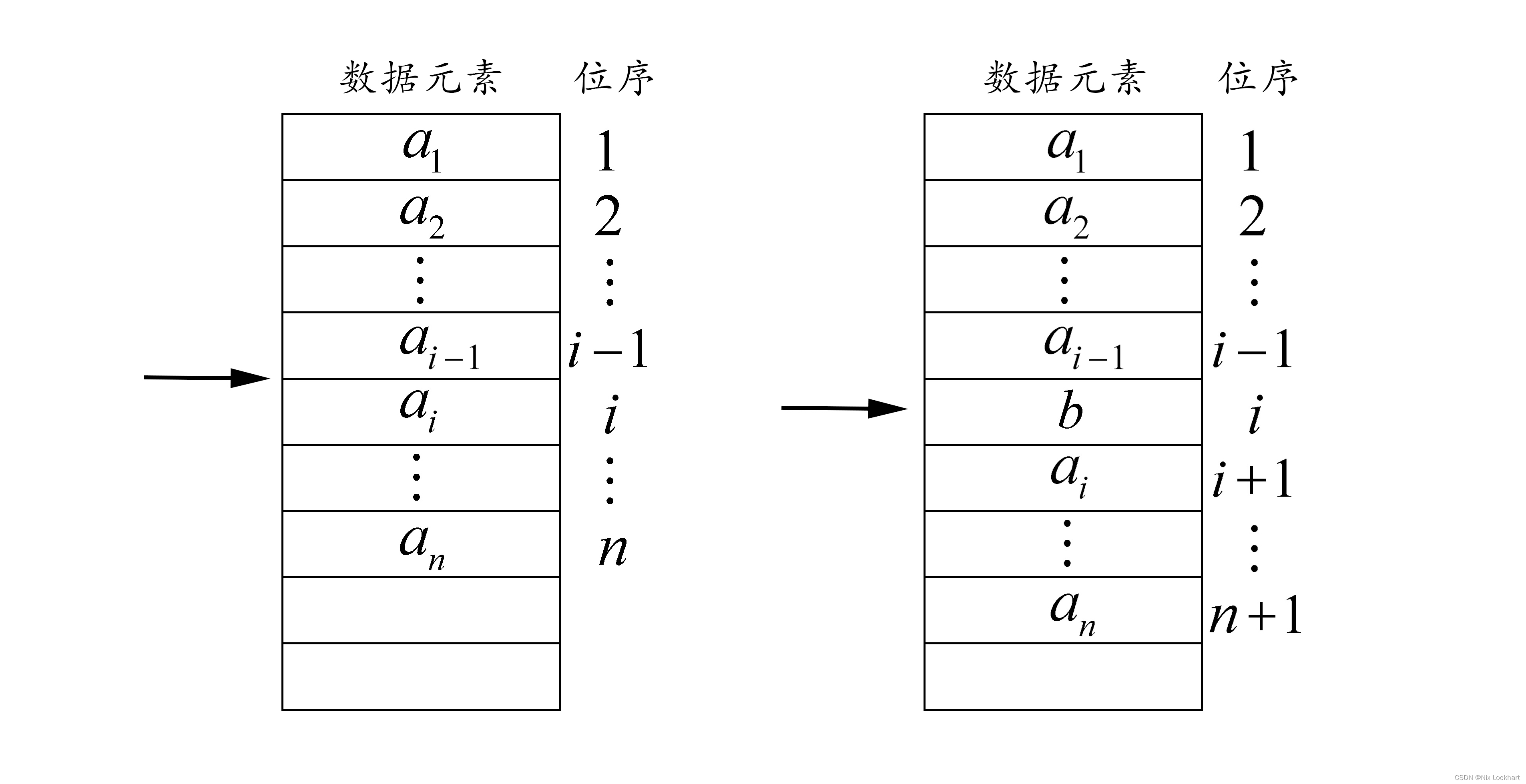
3、删除元素操作(ListDelete)
线性表的删除操作就是删去第个位置上的数据,使一个长度为
的线性表
变为一个长度为的线性表
线性表变化如图所示:
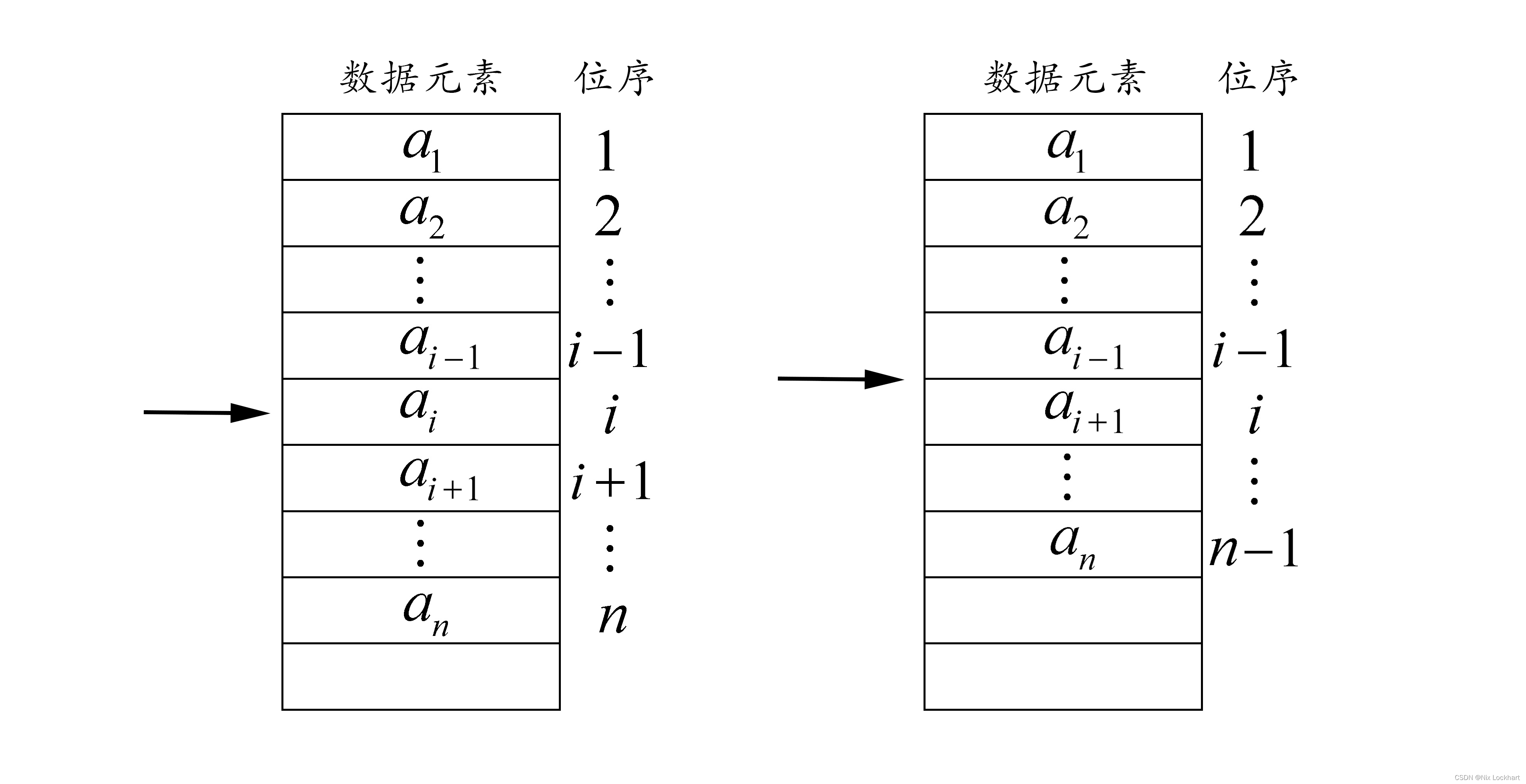
删除其实也只是在字面上叫删除,实际是从遍历到最后一位,每个元素依次前移一位。
同样,我们来捋一捋思路:
①判断输入的位置是否合理;
②取出删除元素;
③从删除位置开始遍历到最后一个位置,每个元素依次前移一位;
(思考:如果从最后一个位置遍历到删除位置,依次前移可以吗?)
④表长减一。
代码实现如下:
//初始条件:线性表L已存在,i>=1&&i<=L.length
//操作结果:删除L中的第i个数据元素,用e返回其值,表长减1
Status ListDelete(SqList *L,int i,ElemType *e)
{
int j;
if(L->length==0) //判断线性表是否已空
return ERROR;
if(i<1||i>L->length) //判断输入位置是否合理
return ERROR;
*e=L->data[i-1] //用元素e取出待删除元素
if(i<L->length)
{
for(j=i;j<L->length;j--)
L->data[j-1]=L->data[j]; //第i+1~length个元素均前移
}
L->length--; //表长减1
return OK;
}同样,不同的思路有不同的实现方式,大家可以自己进行修改。
4、线性表的顺序存储下插入、删除的时间复杂度
从思路、算法上可以看出来,顺序存储结构上在某个位置插入或删除一个数据元素时,时间主要耗费在移动数据元素上,而移动数据元素的个数又取决于插入或删除元素的位置。
先来看看最好的情况,即要插入元素的位置是或删除的元素位置是
,此时没有数据元素需要被移动,时间复杂度为
;再看最坏情况,即要在第1位插入元素或删去第1位的元素,那就意味着将要移动所有元素,所以时间复杂度为
。
至于平均情况,也是我们真正应该关注的一般性情况,由于插入在每个位置或删除每个位置都是等概率的,故最终平均移动次数和最中间位置移动次数相等,为。根据前面的推导,插入和删除操作的时间复杂度还是
。
目前已知,对于顺序存储结构:
(1)在存、读数据时,无论哪个位置,其时间复杂度都是。
(2)而插入和删除时,其时间复杂度都是。
关于线性表的顺序存储结构的其他算法就不再展开细讲,可自行根据其性质实现。
5、线性表的顺序存储结构的优缺点
(1)优点
- 无需为表示表中元素之间的逻辑关系而增加额外的存储空间。
- 可以快速地存取表中任意位置的元素。
(2)缺点
- 插入和删除操作需要移动大量元素。
- 当线性表长度变化较大时,难以确定存储空间的容量。
- 造成存储空间的“碎片”。
五、线性表的链式存储结构
在顺序存储结构中,我们已经知道了它的缺点是定长,当数据元素少时,易造成存储空间的浪费,大学生有个习惯是帮忙占座,顺序存储结构申请空间时就好像学生占座,占好了五个座,结果有俩人没来,就出现俩座被浪费的情况,而如果占好了五个座却来了八个人,就出现了占的座不够的情况。它还有一个缺点是插入和删除元素时需要移动大量数据元素。
为了解决以上两个缺点,我们引入了另外一种存储结构——链式存储结构。
大家先试想一个假设,你跟你的三个好友一起去上课,结果教室里面没有连着的四个空座了,大家会决定怎么做呢?A:这课不上也罢;B:散开坐吧。
我想正常情况下大家会选B,先散开坐,看好同伴坐的位置,下课再去找对方。而这就是链式存储结构的具象化。
1、概念性质
线性表的链式存储结构:用一组任意的存储单元(可连续也可不连续)来存储线性表当中的数据元素。
但是这样任意存储后会产生一个问题,该怎么反映这些数据元素的逻辑关系。
为了表示每个数据元素与其直接后继数据元素
之间的逻辑关系,对数据元素
来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(直接后继的存储位置)。将存储数据元素信息的域称为数据域,把存储直接后继的位置的域称为指针域。指针域中存储的信息称作指针或链。这两部分信息组成元素
的存储映像,称为结点(Node)。
个节点链结成一个链表,即为线性表
的链式存储结构,因为此链表中的每个节点中只包含一个指针域,所以叫做线性链表或单链表。
例如,以下表是一个线性表
的链式存储结构的抽象示意:
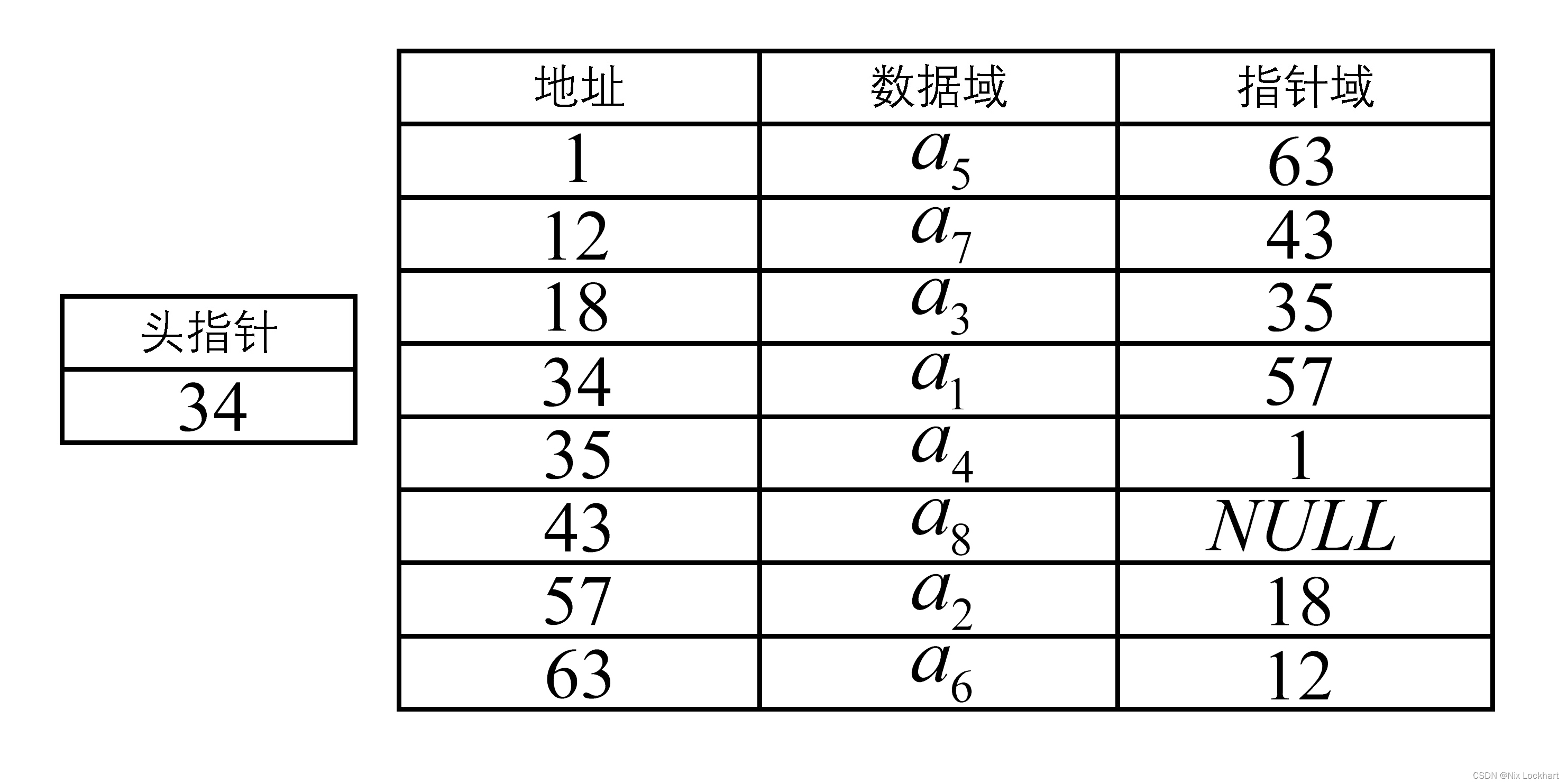
对于线性表来说,总得有个头有个尾,链表当然也不例外。我们将链表中第一个结点的存储位置叫做头指针,故整个表的存取就必须得从头指针开始进行了。那最后一个呢?因为最后一个不存在直接后继,所以我们规定最后一个结点的指针域指向“空”(通常用"NULL"或"^"表示)。
通常我们不会将链式存储结构画成上表所示的样子,因为无法表示出其逻辑结构,所以我们用箭头链接结点的示意图来表示链式存储结构,如下:
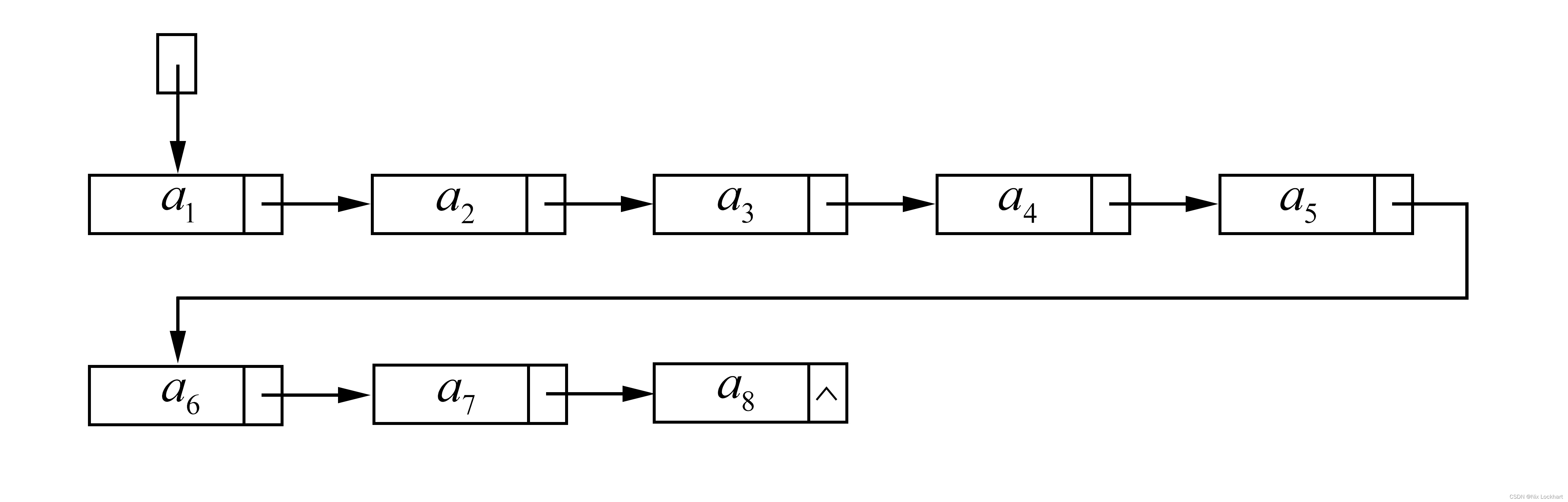
这样来表示链表是不是更加形象了。
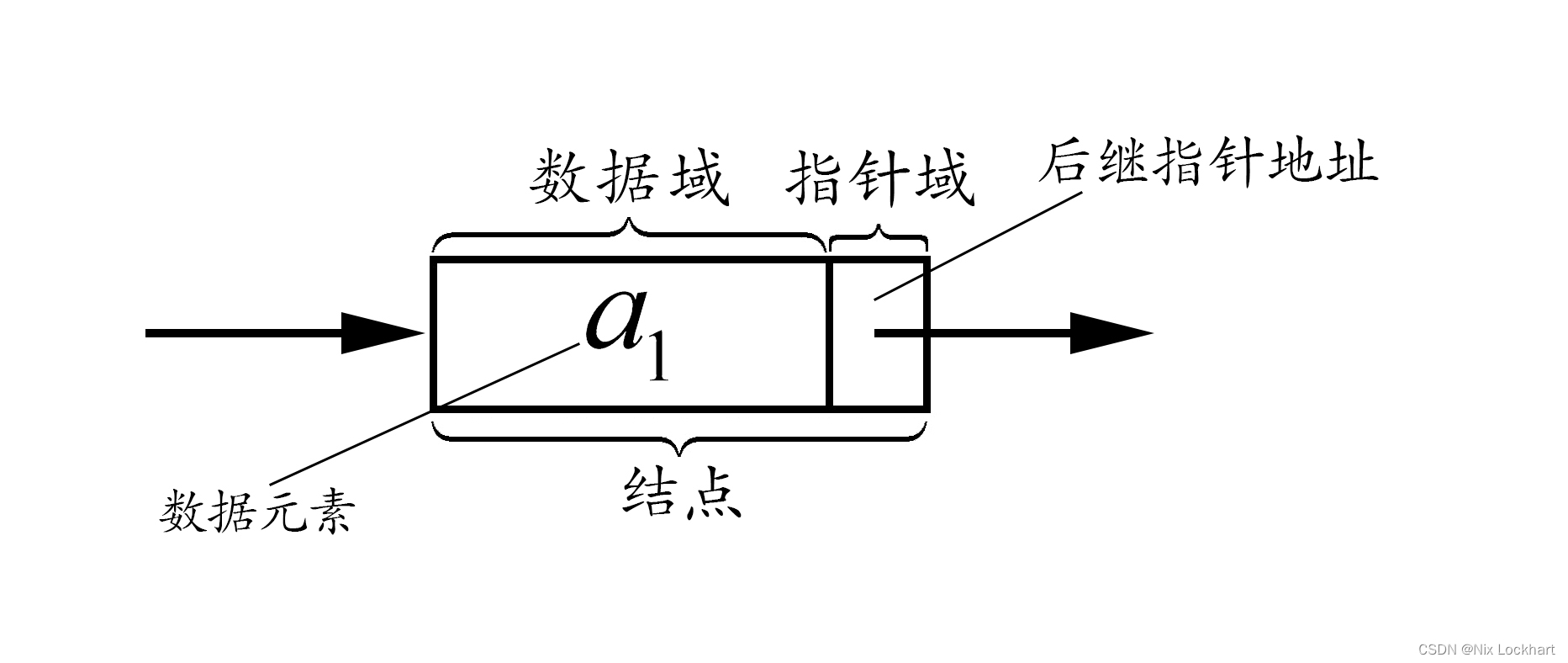
有时,为更加方便地对链表进行操作,会在其第一个结点之前附设一个结点,称为头结点,头结点的指针域用来指向第一个元素的指针,而它的数据域可以不存储任何值,也可以储存整表表长或其他有关信息。
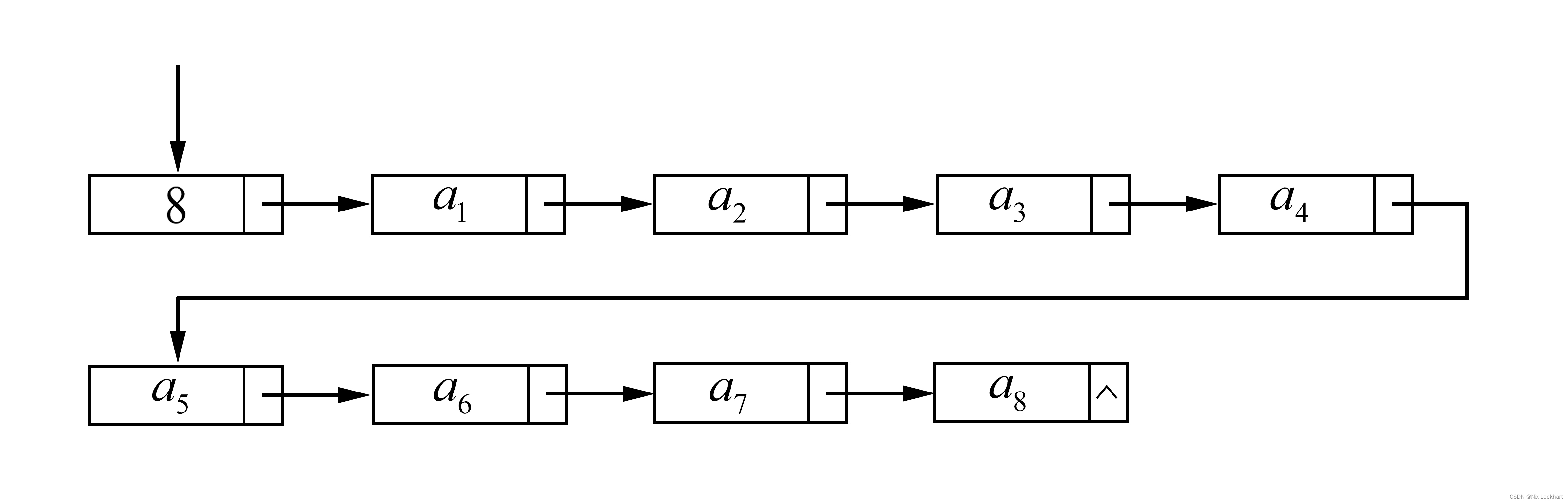
当链表中不存在头结点,其头指针指向地址为“空”时,或者链表中存在头结点,且头结点指针域指向“空”时,我们说这个表是空表,它的长度length=0。
2、头结点与头指针的异同
(1)头指针:头指针是指向链表第一个结点的指针,若链表有头结点,则是指向头结点的指针;头指针具有标识作用,所以常用头指针冠以链表的名字;无论链表是否为空,头指针均不为空。头指针是链表的必要元素。
(2)头结点:头结点是为了操作的统一和方便而设立的,放在第一元素的结点之前,其数据域一般无意义;有了头结点,对在第一元素结点之前的插入和删除第一节点,其操作与其他节点就可以统一了;头结点不是链表必须要素。
3、代码实现链式存储方式
typedef struct Node{
ElemType data; //数据域
struct Node *next; //指针域
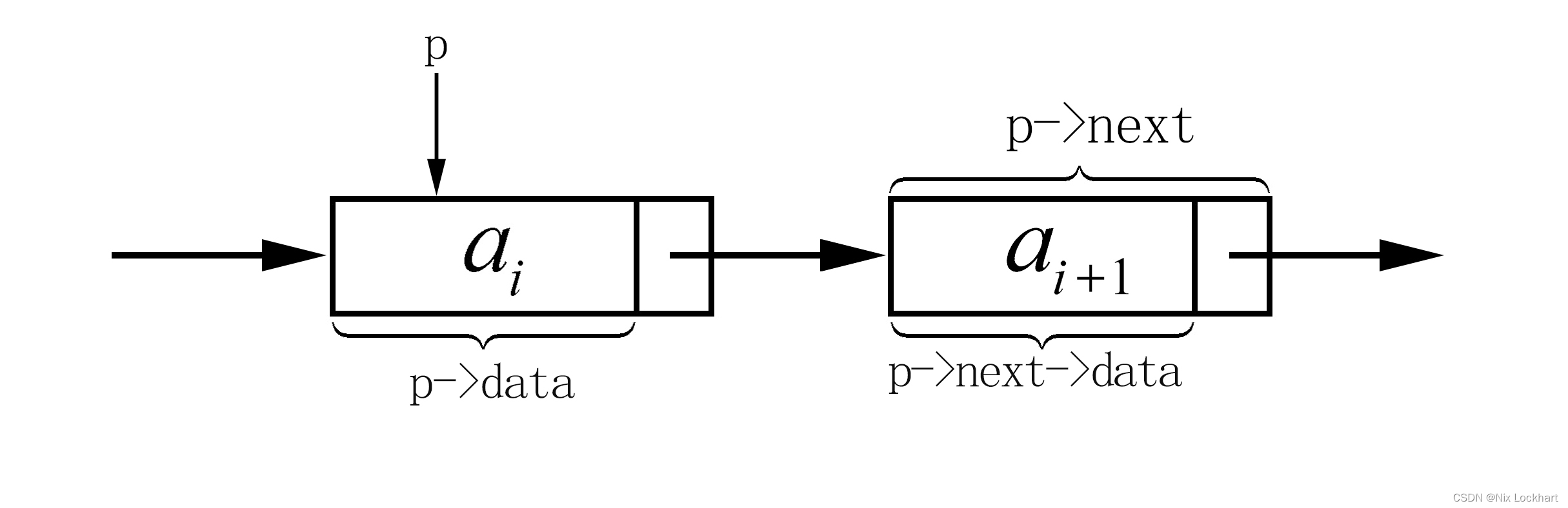
}Node,*LinkList; //结构体类型为Node,其指针类型为Linklist如何来理解其定义呢,我们假设此时已有一个链表,指针p是指向其第i个元素的指针,此时第i个结点的数据域我们就可以用p->data来表示,它的指针域我们就可以用p->next来表示,它的指针域存放的是一个(地址)指针,这个指针指向谁呢?当然是第i+1个结点。同样的,p->next->data就是第i+1个数据元素了。
六、链式存储结构的操作实现——单链表(linear linked list)
1、获得元素操作(GetElem)
在线性表的顺序存储结构中,我们可以直接通过位序(下标)来获取数据元素,那么在单链表中呢?我们无法一开始就知道第i个元素在哪,必须得从头开始找,在算法上,也不如顺序存储结构那么简洁。
同样,我们先写出思路:
①声明一个结点指针p让其指向链表中第一个结点
②在还未找到表尾时,循环遍历链表,并用变量j计次
③若指针p指向空,即找到表尾,则说明第i个元素不存在
④否则找到第i个元素将其返回给e
实现代码如下:
//初始条件:线性链表L已存在,i>=Length(L)&&i<=Length(L)
//操作结果:用e返回链表L中第i个数据元素
Status GetElem(LinkList L,int i,ElemType *e)
{
int j=1;
LinkList p=L->next; //声明结构体指针变量p,让其指向链表第一个结点
while(p&&j<i) //当p没有跑到链表外且循环次数小于i时执行循环
{
p=p->next; //p向后跑一个结点
j++; //循环次数加1
}
if(!p||j>i) //当p跑到链表外或循环次数大于i时
return ERROR; //即未找到该元素,退出函数
*e=p->data; //将找到的元素返回给e
return OK;
} 其实这个算法说白了就是挨个往后找,所以找的次数取决于的位置,易知它的时间复杂度为
。这时就有同学纳闷了,怎么读取的时间复杂度比顺序表读取不仅麻烦,还慢了,别急,世间万物都是有两面的,有坏处,它也必定有它的好处的,让我们来看一下链表的插入和删除操作。
2、插入元素操作(ListInsert)
假设现在有一个链表,且有一个指针p指向第i个结点,现有一个数据元素想要插在
和
之间,该如何实现?
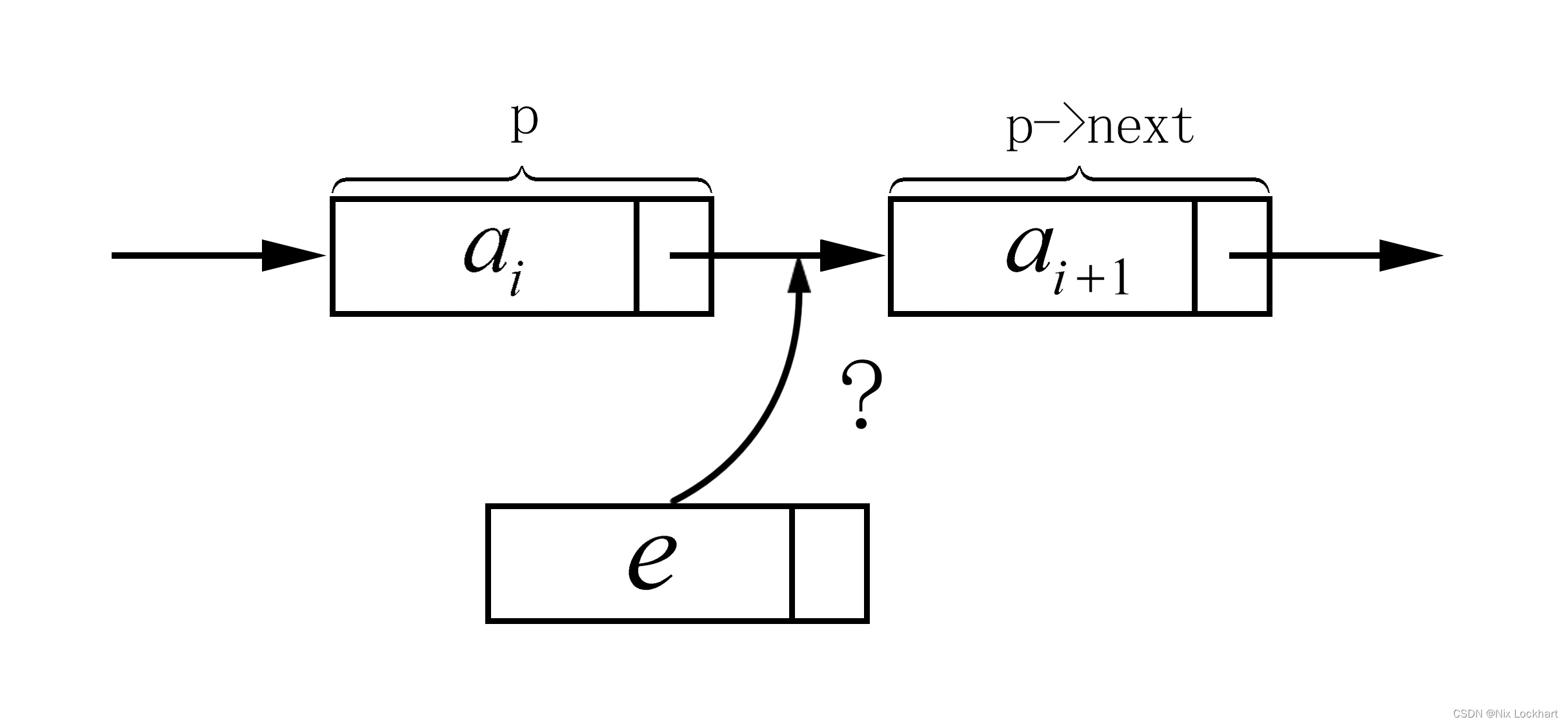
得益于它的随机存储地址,我们不需要移动别的元素,只需要将它随便存在一个地方,然后将其链在我们的链表中即可, 可以看出,我们只需要将的后继改为
(
为新节点,其数据元素为
),
的后继设为
即可。
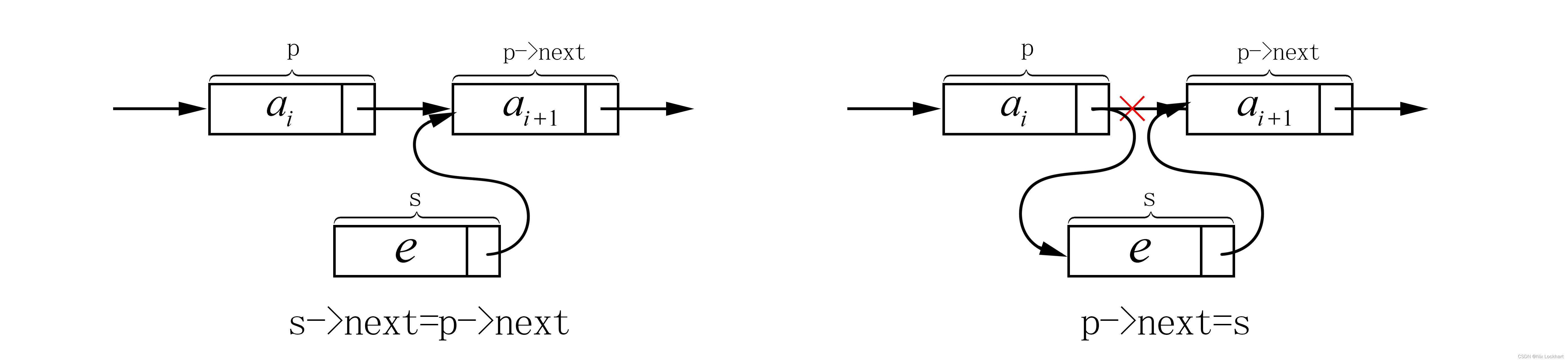
请大家考虑一下这两句代码有没有顺序。
是有顺序的,必须先将后面的结点链在
结点后面,再将
链在
后面,如果颠倒了顺序,会导致先将
链在了
的后面,
的指针域又指向了
现在的后继,即
自己,而
原来的后继就再也找不到了。
好了,现在大家基本理解了过程,我们依旧先来捋一下思路:
①声明一个结点指针p指向链表的第一个结点
②在还未找到表尾时,循环遍历链表,用j计次
③若找到p为空,即找到表尾,则说明第i个元素不存在
④否则查找成功,此时指针p指在第i-1个节点上
⑤申请新节点s用s->data存放数据元素e
⑥将新节点插入在p与p->next之间
实现代码如下:
//初始条件:线性链表L已存在,i>=1&&i<=Length(L)
//操作结果:在L的第i个位置插入数据元素e
Status ListInsert(LinkList L,int i,ElemType e)
{
int j=1;
LinkList s,p=L; //声明新节点s的指针和工作指针p
while(p&&j<i) //循环:工作指针后移遍历
{
p=p->next;
j++;
}
if(!p||j>i) //找到表尾,第i个元素不存在
return ERROR;
s=(Node *)malloc(sizeof(Node)); //为新节点申请空间,并将其地址返回给s
s->data=e; //将新节点插入链表
s->next=p->next;
p->next=s;
return OK;
}3、删除元素操作(ListDelete)
同样假设现在有一个单链表,设储存元素的结点为q,该如何实现结点q的删除呢?
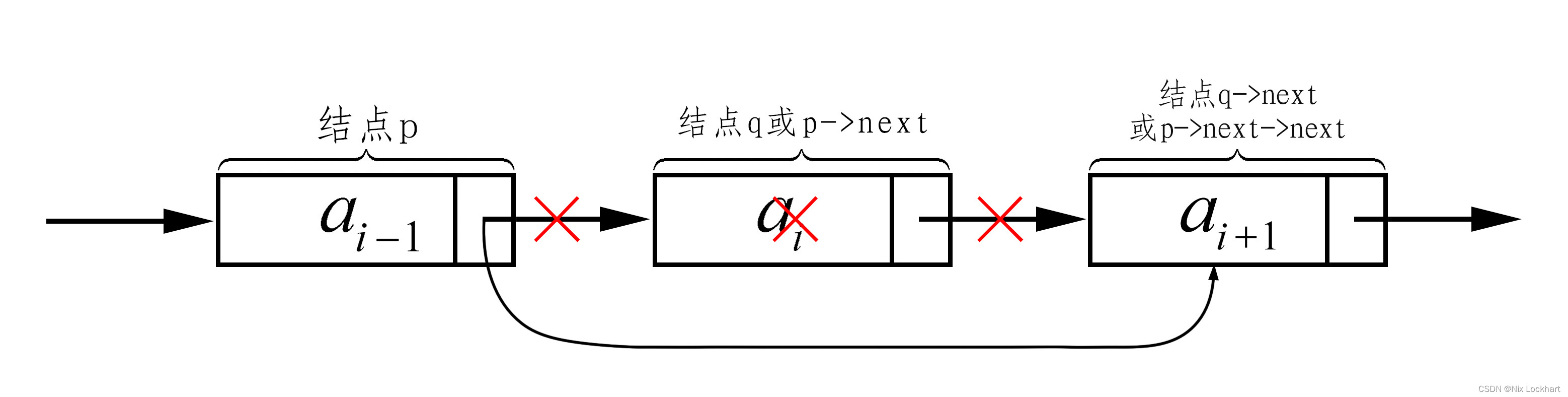
实际上,图示已经给出了大致思路,让其前驱结点的指针域指向其后继即可将其从链表中独立出来,即q=p->next;p->next=q->next;当然,也可以写成p->next=p->next->next。
按照惯例,先整理思路:
①声明一个结点指针p让其指向链表中第一个结点
②在还未找到表尾时,循环遍历链表,并用变量j计次
③若p->next为空则说明第i个结点不存在
④否则查找成功(此时p指向第i-1个结点)让q指向欲删除的结点p->next
⑤将q->next链在p后面(将q孤立出来)
⑥将q->data赋给元素e
⑦释放结点q
以下是实现代码:
//初始条件:线性链表L已存在,i>=1&&i<=Length(L)
//操作结果:删除L中的第i个结点,并将其数据元素返回给e
Status ListDelete(LinkList L,int i,ElemType *e)
{
int j=1;
LinkList p=L,q; //声明工作指针p指向表头和临时指针q
while(p->next&&j<i) //注意条件:判断p->next是否为空
{
p=p->next; //工作指针后移
j++;
}
if(!(p->next)||j>i) //找到表尾,第i个元素不存在
return ERROR;
q=p->next; //让临时指针指向p->next(要删除的结点)
p->next=q->next; //将q->next(也就是p->next->next)链在p后面
*e=q->data; //将删除的结点数据元素返回给e
free(q); //释放结点q
return OK;
}
在单链表的代码中我们看到了C语言中两个标准函数malloc和free,不同于顺序存储,链式存储是一种动态结构,它的空间是随用随取(从系统申请存储空间),而在程序结束的时候,也应当将程序中申请到的空间返还给系统。
4、线性表的链式存储结构下插入、删除的时间复杂度
分析一下刚才所讲的单链表插入删除,发现都是由两部分组成,第一部分就是遍历查找第i个元素,第二部分就是插入/删除。不难得出,它们俩的时间复杂度均为。
5、单链表的整表创建(CreateList)
说了半天单链表上的的操作,还没提过单链表怎么创建,接下来我们看一看如何创建一个单链表。先来回顾一下,顺序存储结构的创建就是初始化一个数组并赋值的过程,而链表可以根据实际情况动态申请位置。
所以创建单链表的过程就是一个动态生成链表的过程,即从“空表”状态依次建立各元素结点,并逐个插入链表。
(1)单链表的头插法建表
“头插法”,顾名思义,就是从表头插入新元素,具体一点就是将新元素插入到头结点与前一个新节点之间。
实现思路:
①声明结点指针p和计次变量i
②初始化一个带头结点的空链表L
③循环:申请一个新结点并将其地址赋值给p
键盘输入值赋给p的数据域p->data
将p插入在头结点与前一个新元素之间
以下是代码实现:
//初始条件:此时已有结点指针L,且已知初始结点个数n
//操作结果:输入n个值用头插法建立单链表L
void CreateList_Head(LinkList *L,int n)
{
LinkList p; //结点指针p
int i;
*L=(Node *)malloc(sizeof(Node)); //为链表L申请头结点
(*L)->next=NULL;
for(i=0;i<n;i++) //循环:头插法创建链表
{
p=(Node *)malloc(sizeof(Node)); //申请新结点
scanf("%d",&(p->data)); //输入数据元素
p->next=(*L)->next; //将原本在头结点后面的结点链在新结点后
(*L)->next=p; //将新结点链在头结点后
}
}有些同学可能比较疑惑:为什么用这么别扭的方法建表,正常建表不是新元素排在最后吗?存在即合理,这种建表方法虽与正常思路不同,但肯定是会有它起作用的地方的。
(2)单链表的尾插法建表
既然头插法比较不常用,那还是来学学实用的尾插法吧。
按照惯例,先整理思路:
①声明结点指针p,工作指针r
②初始化一个带头结点的链表
③循环:申请新结点将其地址赋给p
键盘输入值赋给p->data
将结点p链在表尾
以下是代码实现:
//初始条件:此时已有结点指针L,且已知初始结点个数n
//操作结果:输入n个值用头插法建立单链表L
void CreateList_Tail(LinkList *L,int n)
{
LinkList p,r; //结点指针p,工作指针r
int i;
*L=(Node *)malloc(sizeof(Node)); //为链表L申请头结点
r=*L; //让工作指针r指向L头结点
for(i=0;i<n;i++) //循环:尾插法创建链表
{
p=(Node *)malloc(sizeof(Node)); //申请新结点
scanf("%d",&(p->data)); //输入数据元素
r->next=p; //将新结点链在r后面(即链表最后)
r=p; //让r指向新结点(链表中最后一个元素)
}
r->next=NULL;
}6、单链表的整表删除(ClearList)
当我们不再使用一个链表时,我们应该将其删除,也就是在内存中将其释放掉,为其他程序留出空间。
整理思路:
①声明结点指针p,q
②让p指向第一个结点
③循环:让q指向下一结点
释放p
将q赋值给p
实现代码如下:
//初始条件:单链表L存在
//操作结果:将链表L置为空表
Status ClearList(LinkList L)
{
LinkList p,q;
p=L->next; //让p指向第一个结点
while(p) //循环:释放每个结点
{
q=p->next; //让q指向下一个结点
free(p);
p=q; //让p指向下一个结点(此时q指向下一个结点)
}
L->next=NULL; //头结点指针域为空
return OK;
}在这段代码中,出现了两个工作指针p、q,真的有必要用两个吗?
当然,其实这段代码置空链表的方法就是挨个释放结点,若只有一个工作指针p,在free(p)之后便无法再接着往后找了,因为在释放结点的时候,其指针域也就无了,此时就无法通过p来找到p->next了,而q正是为解决这个问题而引入的。
总结:单链表结构与顺序存储结构优缺点
(1)存储分配方式
顺序存储结构:用一段连续的存储单元依次存储线性表的数据元素。
单链表:采用链式存储结构,用一组任意的存储单元存放线性表的数据元素。
(2)时间性能
①查找:
顺序存储结构:
单链表:
②插入和删除:
顺序存储结构:
单链表:
(3)空间性能
顺序存储结构:需要预分配存储空间,分多易产生浪费,分少易发生上溢。
单链表:不需要分配存储空间,只要有空就可以分配,元素个数也不受限制。
总之,线性表的顺序存储结构和单链表结构各有其优缺点, 不能简单的说哪个好,哪个不好,需要根据实际情况,来综合平衡采用哪种数据结构更能满足和达到需求和性能。
七、线性链表的一维数组实现——静态链表
学习过C语言的同学应该都听说过:C语言的一大特色就是指针。指针的操作十分灵活方便。但是,对于一些早期的没有指针的编程高级语言,按照我们对链表结构的定义,它就没办法实现了,这该如何是好?此时就有人提出了用数组来实现单链表,以下是该方法的实现思路。
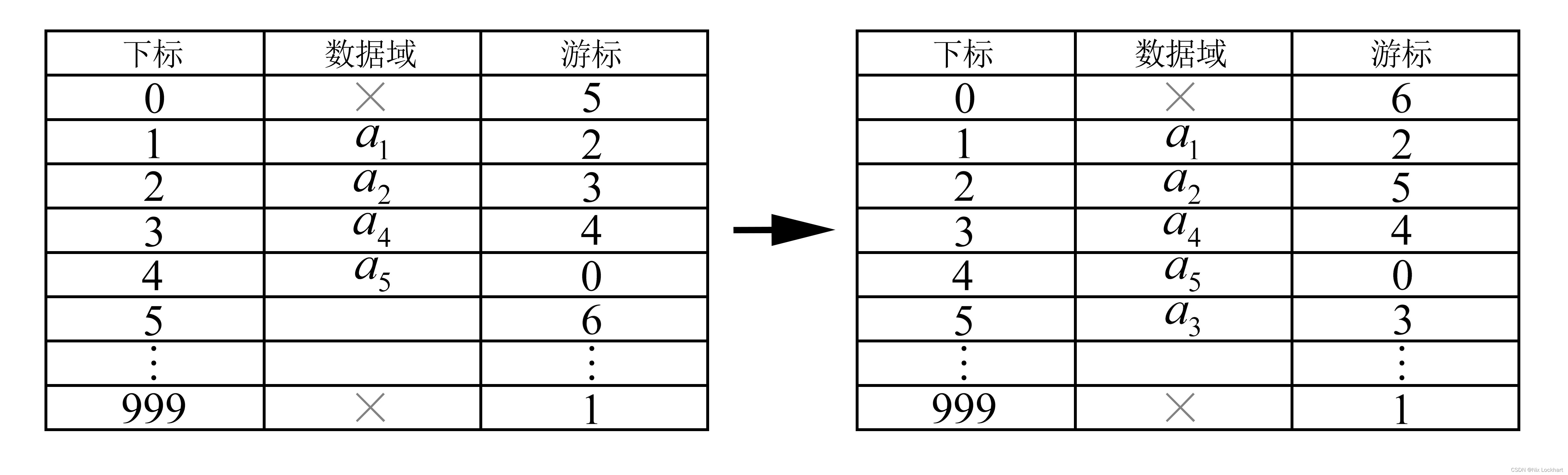
首先让数组元素都由两个数据域组成,data和cur。数据域data用来存放数据元素,也就是我们要处理的数据;而游标cur相当于单链表中的next指针,存放该元素的后继在数组中的下标。
我们把这种用数组描述的链表叫做静态链表。
还有为了方便插入数据,我们通常会把数组建立得大一些,以防插入时出现溢出。
1、代码实现静态链表
#define MaxSize 1000
typedef struct{
ElemType data;
int cur;
}Component,StaticLinkList[MaxSize];在上述结构定义中,我们对数组的第一个元素和最后一个元素作为特殊元素处理,不存数据。我们通常把未被使用的数组怨怒是称为备用链表。而数组的第一个元素,即下标为0的元素的cur就存放备用链表的第一个结点的下标;而数组的最后一个元素的cur则存放第一个有数值的元素的下标,相当于单链表中的头结点。
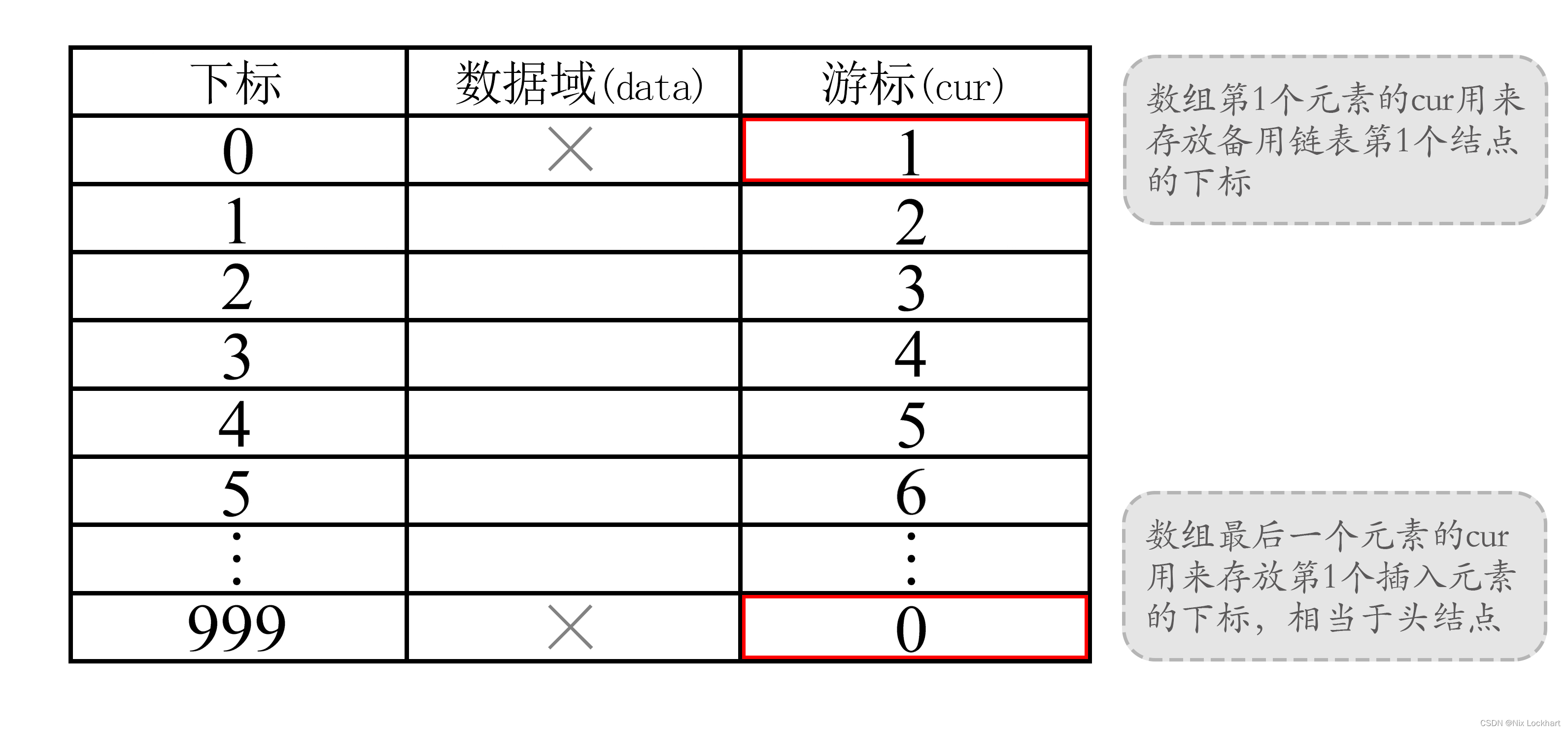
这种存储结构仍需要预先分配一个较大的空间,但在作线性表的插入和删除操作时不需移动元素,仅需修改指针,故仍具有链式存储结构的主要优点。
下面是静态链表的初始化:
Status InitList(StaticLinkList space)
{
int i;
for(i=0;i<MaxSize-1;i++) //将数组中各分量链接到一起
space[i].cur=i+1; //将每个数组元素的cur值设置为其下一个元素的下标
space[MaxSize-1].cur=0; //目前静态链表为空,最后一个元素的cur为0
return OK;
}2、静态链表的插入操作(ListInsert)
在链表中,我们可以用malloc和free实现需要时申请,不需要时释放空间的操作,但此时在一个静态链表(数组)中,我们又该如何实现/模拟动态链表结构存储空间的分配。
既然没法直接搬过来用,我们就自己实现这两个函数,依靠这两个函数来在静态链表中模拟动态分配。
为了辨明数组中哪些分量未被使用,解决的办法是将所有未被使用过的及已被删除的分量用游标链成一个备用的链衰, 每当进行插入时,便可以从备用链装上取得第一个结点作为待插入的新结点。
以下是我们自行实现的malloc函数。
//若备用空间链表非空,则返回分配的结点下标,否则返回0
int Malloc_SLL(StaticLinkList space)
{
int i=space[0].cur;
if(space[0].cur)
space[0].cur=space[i].cur; //此时要拿出一个分量来使用,所以就将它的下一个分量用来做备用
return i;
}这段代码的作用就是返回一个下标值,也就是数组头元素的cur存储的第一个空闲的下标。
现在我们就可以编写插入操作了:
Status ListInsert(StaticLinkList L,int i,ElemType e)
{
int j,k,l;
k=MaxSize-1; //注意k首先是最后一个元素的下标
if(i<1||i>ListLength(L)+1)
return ERROR;
j=Malloc_SLL(L); //获得空闲分量的下标
if(j)
{
L[j].data=e; //将数据赋值给此分量的data
for(l=1;l<=i-1;l++) //找到第i个元素之前的位置
k=L[k].cur;
L[j].cur=L[k].cur; //把第i个元素之前的cur赋值给新元素的cur
L[k].cur=j; //把新元素的下标赋值给第i个元素之前元素的cur
return OK;
}
return ERROR;
}
就这样,我们实现了在数组中,丝毫未移动元素,却插入了数据的操作。没理解可能觉得有些复杂,理解了,也就那么回事。
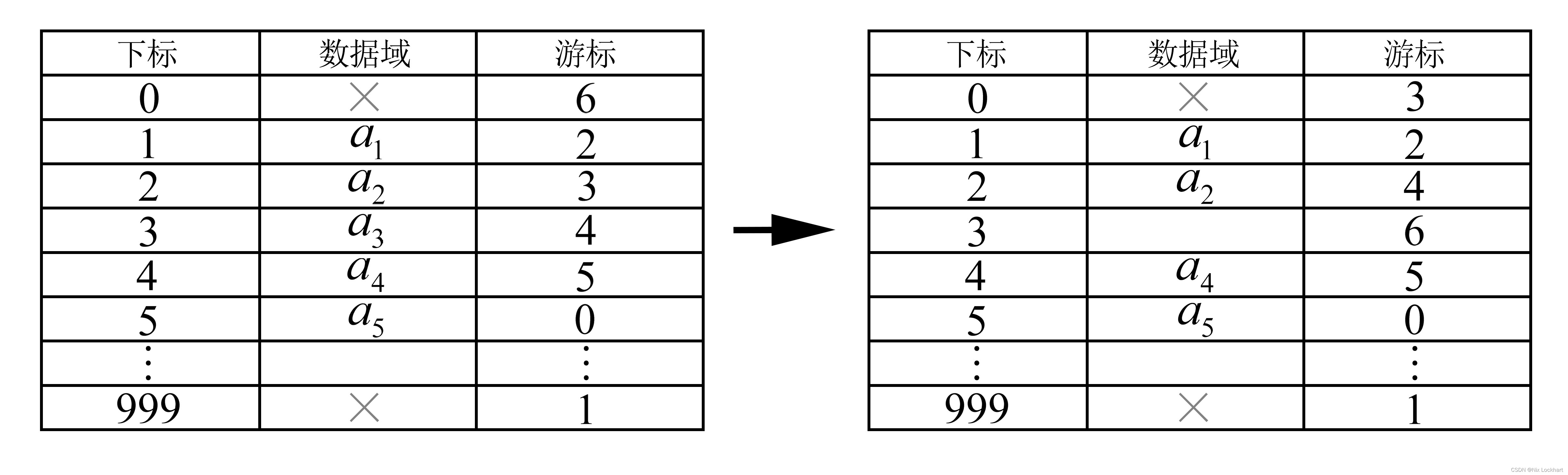
3、静态链表的删除操作(ListDelete)
和插入一样,我们删除链表元素的时候也需要free函数来归还申请到的空间,这也需要我们自己实现。
void Free_SSL(StaticLinkList space,int k)
{
space[k].cur=space[0].cur; //把第一个元素cur值赋给要删除的分量cur
space[0].cur=k; //把要删除的分量下标赋值给第一个元素的cur
}free函数已经实现了,现在我们便可以编写删除操作了。
Status ListDelete(StaticLinkList L,int i)
{
int j,k;
if(i<1||i>ListLength(L)) //判断i值是否合法
{
return ERROR;
}
k=MaxSize-1; //将k指向头结点
for(j=1;j<=i-1;j++) //找到第i个结点的位置
{
k=L[k].cur;
}
j=L[k].cur; //将要删除的结点赋值给j
L[k].cur=L[j].cur; //将要删除结点的后继赋值给前驱
Free_SLL(L,j); //释放j结点
return OK;
}
当然,静态链表也有其他相关操作,比如删除操作中出现的ListLength,以下是它的代码:
//前提条件:静态链表L已存在
//操作结果:返回L中元素个数
int ListLength(StaticLinkList L)
{
int j=0;
int i=L[MaxSize-1].cur; //i指向第一个元素
while(i)
{
i=L[i].cur;
j++;
}
return j;
}4、静态链表的优缺点
优点:在插入和删除操作时,只需要修改游标,不需要移动元素,从而改进了在顺序存储结构中的插入和删除操作需要移动大量元素的缺点。
缺点:没有解决连续存储分配带来的表长难以确定的问题。
失去了顺序存储结构随机存取的特性。
总之,静态链表只是为没有指针的高级程序语言设计的一种实现链表的方法。尽管以后不一定用得上,但学到就是赚到,了解一下它的设计思路也是收获。
八、线性链表的前驱解决方案一——循环链表(Circylar linked lists)
在前面我们说了单链表的缺点,它只能找到一个元素的后继,无法访问其前驱,那有什么解决方案呢?
这时候就有人会想了,我再为每个结点开辟一个指针域,让它存储上一个结点的地址不就行了。嘘——,这是下一节的内容,我们先不讲。
不知大家还记不记得单链表有一个指针域未被使用,就是它最后一个结点的指针域,何不让它指向第一个结点,让这个链表形成一个环呢。
将单链表中终端结点的指针域由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单循环链表,简称循环链表。
为了使空链表与非空链表处理方式一致,我们还是设一个头结点,带有头结点的空循环链表如下。
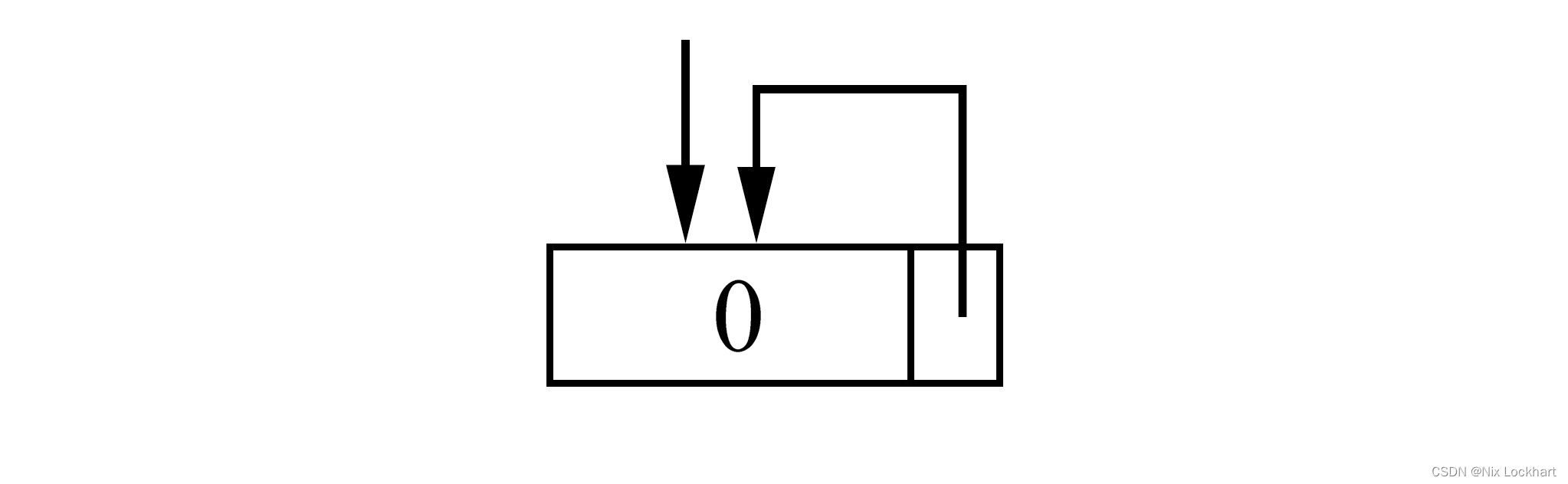
非空的循环链表则如下:
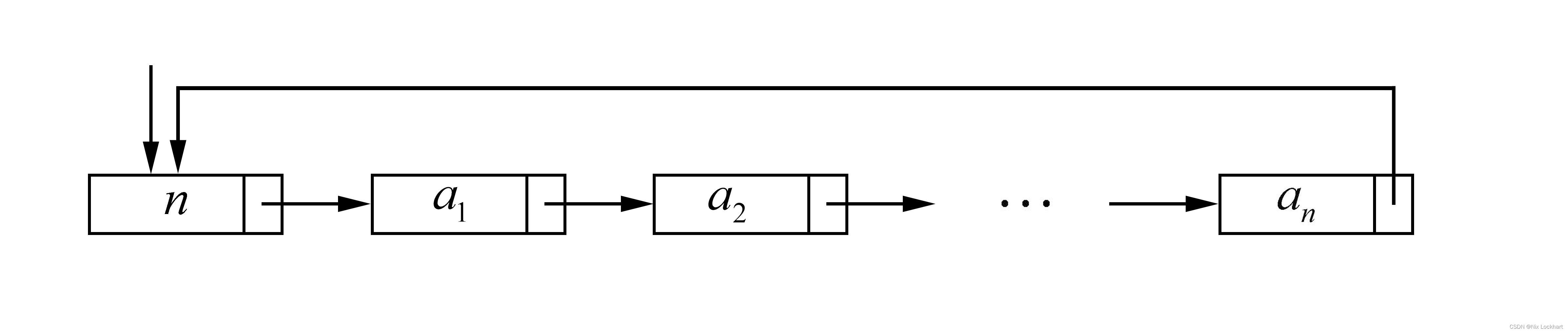
而循环链表在操作上和单链表的差别就是在单链表中判断p->next是否为空(表尾)的地方判断p->next是否为头结点了。
在单链表中,我们访问头结点的时间复杂度为,但是访问尾结点却需要遍历一整个链表,即
的复杂度,那有没有一种方法可以直接访问尾结点呢?实际上我们可以把链表的指示由头结点(head)改为尾结点(rear)即可。
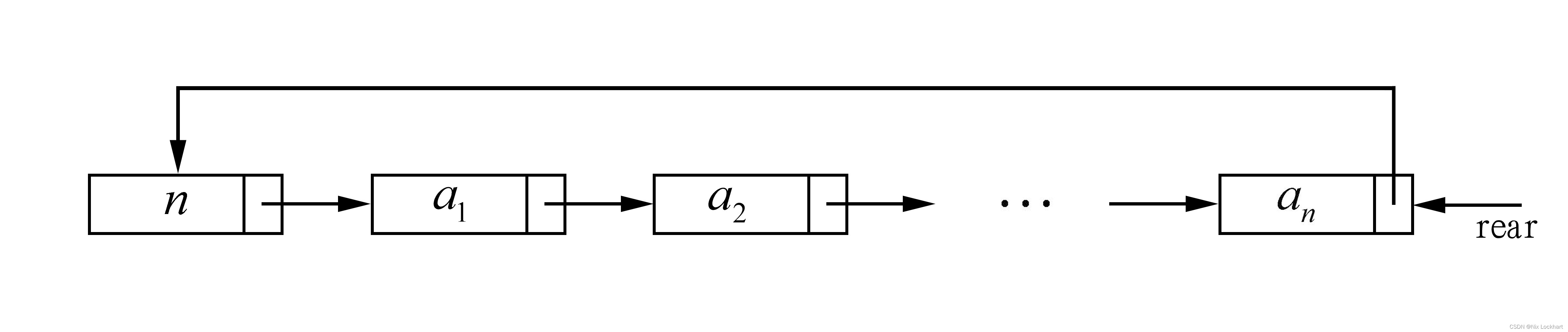
这样的结构存在也是有它存在的意义的,说不定哪天就用上了,需要注意的是,此时的头结点就是rear->next->next了。
九、线性链表的前驱解决方案二——双向链表(Double linked lists)
前一节中给大家放了一个预告,但是没有跟大家细讲,就是在单链表中再为每个结点开辟一个指针域存放其前驱的地址,这种链表结构我们叫双向链表。所以在双向链表中的结点都有两个指针域, 一个指向直接后继,另一个指向直接前驱。
1、代码实现双向链表
typedef struct DulNode{
ElemType data; // 数据域
struct DulNode *prior; // 前驱指针
struct DulNode *next; // 后继指针
}DulNode, *DuLinkList;它的结构如下
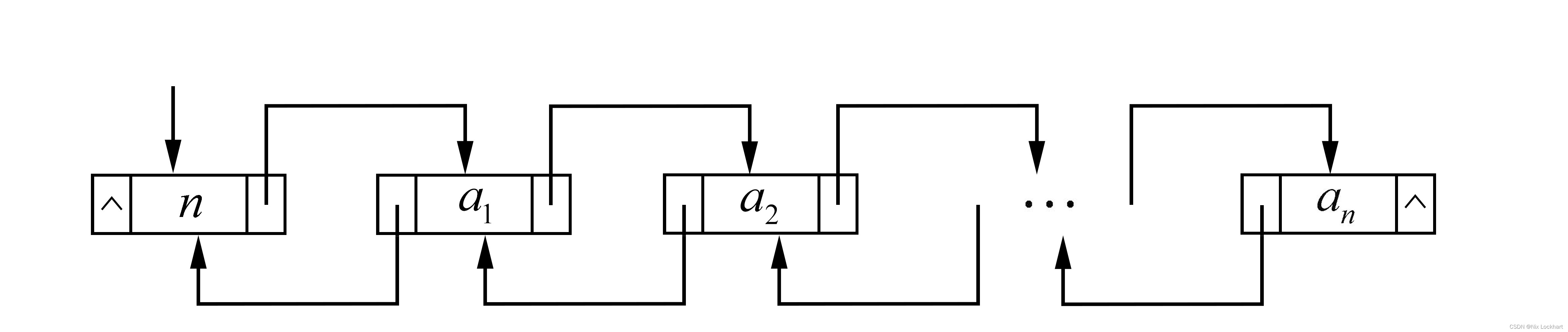
由于这是双向链表,那么对于链表中的某一个结点p,它的后继的前驱是谁?当然是它自己,同样,它的前驱的后继也是它自己。也就是说p->next->prior、p、p->prior->next指的都是p。
既然单链表有循环链表,双向链表当然也有循环链表,它叫双向循环链表,它的结构如下:

由于双向链表是单链表扩展出来的结构,像查找元素(GetElem)、求表长(ListLength)类似的操作并没有因为增添了一个前驱指针而发生改变,简言之就是和单链表完全一致,因为这些操作都只涉及一个指针。
2、双向链表的插入操作(ListInsert)
既然加了一个前驱指针,那么插入操作和删除操作必然就要多些处理前驱的步骤,让我们再来看看双向链表如何实现插入操作。
先看思路:
①声明一个结点指针p指向链表的第一个结点
②在还未找到表尾时,循环遍历链表,用j计次
③若找到p为空,即找到表尾,则说明第i个元素不存在
④否则查找成功,此时指针p指在第i-1个节点上
⑤申请新节点s用s->data存放数据元素e
⑥让s的前驱指针(s->prior)指向结点p
⑦让s的后继指针(s->next)指向结点p->next
⑧让p的后继的前驱指针(p->next->prior或者s->next->prior)指向s
⑨让p的后继指针(p->next)指向s
代码实现:
//初始条件:双向链表L已存在,i>=1&&i<=L.length
//操作结果:L中第i个位置插入新元素e
Status ListInsert(DuLinkList L,int i,ElemType e)
{
DuLinkList p = L, s; //p指向头结点
int j=0; //j为计数器
while(p&&j<i-1) //寻找第i-1个结点
{
p=p->next;
++j;
}
if(!p||j>i-1) //位置不合法
return ERROR;
s=(DulNode *)malloc(sizeof(DulNode)); //生成新结点
s->data=e; //将结点数据域置为e
s->prior=p; //让s的前驱指向p
s->next=p->next; //让s的后继指向p的后继
p->next->prior=s; //让p的后继的前驱指向s
p->next=s; //让p的后继指向s
return OK;
}以下是每一步的示意图:
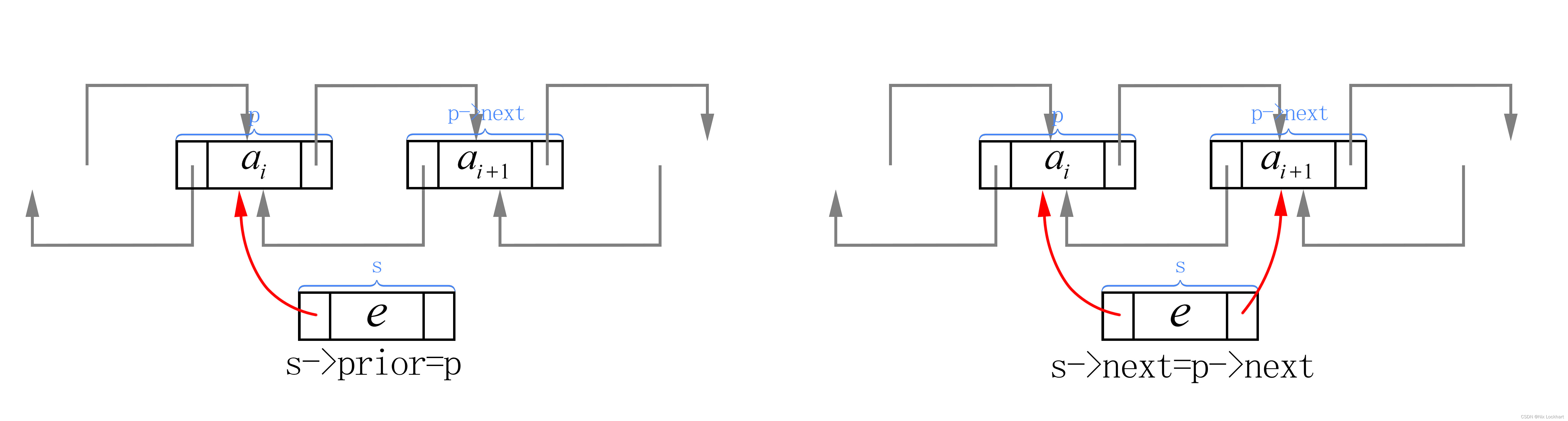
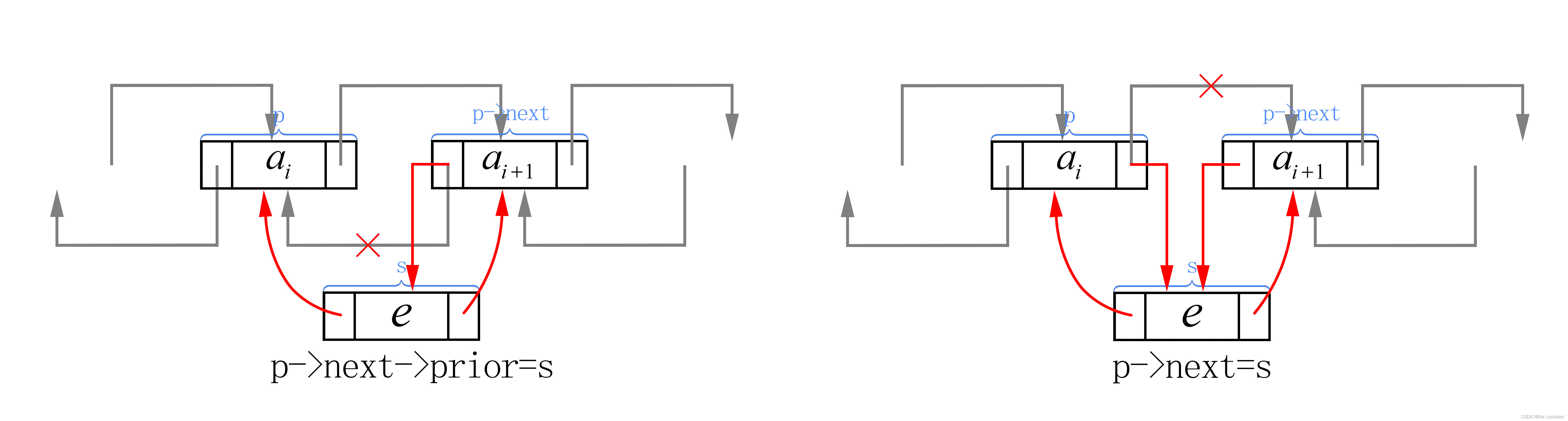 同样,在双向链表的插入时我们仍需考虑每个语句的顺序,避免出现一步顺序出错而导致的后面工作无法完成的情况。
同样,在双向链表的插入时我们仍需考虑每个语句的顺序,避免出现一步顺序出错而导致的后面工作无法完成的情况。
3、双向链表的删除操作(ListDelete)
如果插入操作能理解,那么删除操作就简单了。
我们直接看思路:
①声明工作指针p和q
②在还未找到表尾时,循环遍历链表,用j计次
③若找到p->next为空,即找到表尾,则说明第i个元素不存在
④否则查找成功,此时指针p指在第i-1个节点上
⑤让q指向p->next,即第i个结点
⑥返回q->data给e
⑦将第i个元素(q或p->next)后面的元素(q->next或q->next->next)链在p后面
⑧如果q后面有元素,让其后面元素的前驱指针(q->next->prior)指向p
⑨释放结点q
//初始条件:双向链表L已存在,i>=1&&i<=L.length
//操作结果:将L中第i个位置的元素返回给变量e,并将其删除
Status ListDelete(DuLinkList L,int i,ElemType *e)
{
int j=0;
DuLinkList p=L,q; //申明工作指针p,q
while(p->next&&j<i-1) //寻找第i个结点
{
p=p->next;
j++;
}
if(!(p->next)||j>i-1) //第i个结点不存在
return ERROR;
q=p->next; //q为第i个结点
*e=q->data; //用e返回其值
p->next=q->next; //将q->next即p->next->next链在p后面
if(q->next) //若q的后继结点存在,让其前驱指针指向p
q->next->prior=p;
free(q); //释放结点的存储空间
return OK;
}实际上,双向链表的删除操作也只是多了前驱指针的处理,只要掌握了单链表的原理和操作,理解其他形式的链表应该不成问题。
十、本章总结回顾
看到这儿,你已经完成了《算法与数据结构》中线性表的学习,让我们再来回顾一下本章提及的知识点。
首先,我们学习了线性表这种数据结构的概念,知道了它是指n个(0个或多个)数据元素组成的有限序列。后来,我们又学习了它的两种实现方式,即顺序存储方式(顺序表)和链式存储方式(链表)以及在不同的存储方式下的增、删、查等操作,并对它们进行了性能分析。再后来我们又了解了如何在没有指针的情况下实现链表,即静态链表。最后,我们又在单链表的基础上,了解了它的两种前驱解决方案,循环链表和双向链表。
正如我在本章开始所说,学好本章至关重要,它为一整本《算法与数据结构》打下了基础,没有看懂的同学也可以私信联系本人,在本人的能力范围内尽可能帮大家解决问题。















 2061
2061











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











