






Python爬取问卷星内容
问卷星标题和选项内容爬取
从以下博客中学习到的,加了些自己的解释
Python3 爬虫— 问卷星内容爬取
先贴代码:
import time
from requests_html import HTMLSession
wenjuanxing_URL = "https://ks.wjx.top/jq/55123312.aspx"
def parse_post_data(resp):
questions = resp.html.find('fieldset', first=True).find('.div_question')
for i, q in enumerate(questions):
title = q.find('.div_title_question_all', first=True).text
choices = [t.text for t in q.find('label')]
print(title)
for choice in choices:
print(choice)
print('***************************************************\n')
time.sleep(0.5)
def main():
print('开始爬取问卷内容')
print('链接:%s' % wenjuanxing_URL)
session = HTMLSession()
resp = session.get(wenjuanxing_URL)
parse_post_data(resp)
if __name__ == '__main__':
main()
需要导入time和requests_html包,没有的可以在python目录下用pip下载
questions = resp.html.find('fieldset', first=True).find('.div_question')
这里的filedset是包含所有题目和答案的标签
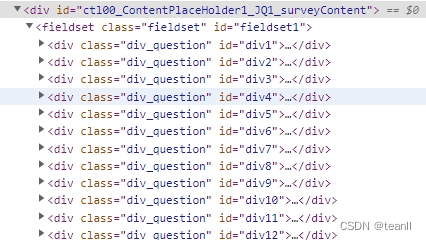
题目内容
title = q.find('.div_title_question_all', first=True).text
对应题目选项
choices = [t.text for t in q.find('label')]
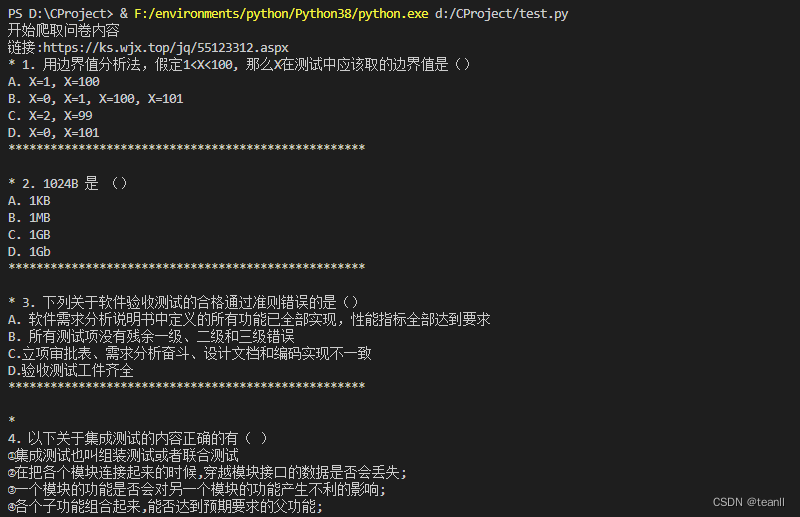
控制台运行:

















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









