







日常工作中我们经常遇到这样的场景,某某些逻辑特别不稳定,随时根据线上实际情况做调整,比如商品里的评分逻辑,比如规则引擎里的规则。
- JDK自带的ScriptEngine
- 使用groovy,如GroovyClassLoader、GroovyShell、GroovyScriptEngine
- 使用Spring的<lang:groovy/>
- 使用JavaCC实现自己的DSL
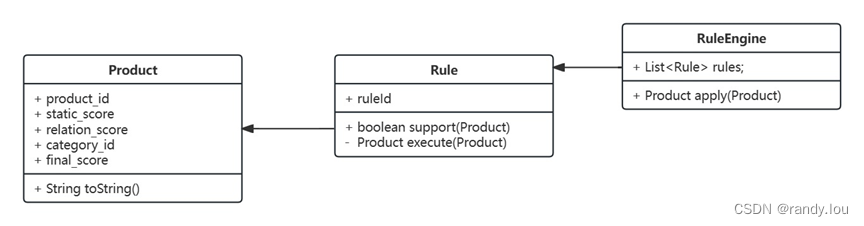
后续我们会对每一个方案做具体说明。为了方便解说,我们假定有这样一个场景,我们有一些商品对象(Product),商品上有商品ID、静态评分、相关度评分、所属类目ID,我们想要计算商品的最终得分(final_score),后续流程会基于这个评分对商品做排序。Rule是我们对评分计算逻辑的抽象,support用于提示当前Rule是否适用给定Product,execute用于对给定Product做处理。RuleEngine负责维护一组Rule对象,当调用apply时,用所有Rule对给定Product做处理。
package com.lws.rule;
import lombok.Data;
@Data
public class Product {
private long id;
private float staticScore;
private float relationScore;
private float finalScore;
private int categoryId;
}
package com.lws.rule;
public interface Rule {
public boolean support(Product p);
public Product execute(Product p);
}package com.lws.rule;
import java.util.ArrayList;
import java.util.List;
public class RuleEngine {
private List<Rule> rules = new ArrayList<>();
public Product apply(Product p) {
for (Rule rule : rules) {
if (p != null && rule.support(p)) {
p = rule.execute(p);
}
}
return p;
}
}1.ScriptEngine
1.1 前景提要
JDK自带ScriptEngine实现,JDK15之后默认ECMAScript引擎实现已经从JDK里移除,使用前需要自己引入nashorn-core的依赖
<dependency>
<groupId>org.openjdk.nashorn</groupId>
<artifactId>nashorn-core</artifactId>
<version>15.4</version>
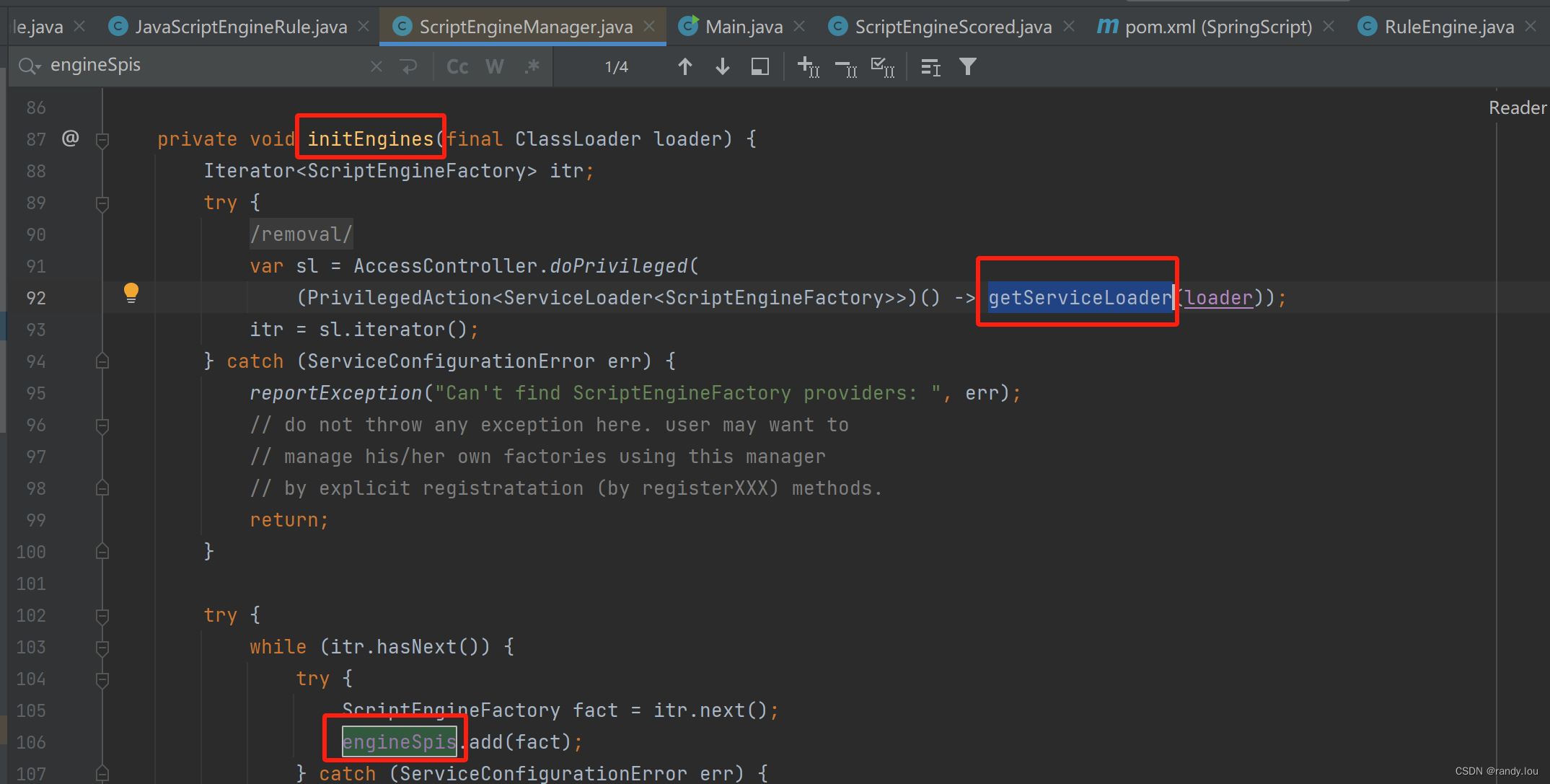
</dependency>通过引入依赖自动添加ScriptEngine的实现,采用的是Java SPI的机制,关于Java SPI的更多信息查看文章Java SPI。通过ScriptEngineManager的代码能确定具体实现
1.2 具体实现
我们将通过ScriptEngine执行脚本的逻辑封装到一个方法内部,将一个Map对象绑定到Bindings上做为执行上下文
private Object eval(String expr, Map<String, Object> context) {
try {
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("JavaScript");
Bindings bindings = engine.createBindings();
bindings.putAll(context);
return engine.eval(expr, bindings);
} catch (Exception e) {
log.error("fail to execute expression: " + expr, e);
return null;
}
}新建一个类JavaScriptEngineRule做为Rule的实现类,support和execute都通过执行脚本返回的结果做为输出,而这两个脚本是可配置的,甚至可以从数据库、配置中心里读取
public class JavaScriptEngineRule implements Rule {
private Logger log = LoggerFactory.getLogger(JavaScriptEngineRule.class);
private String supportExpr;
private String executeExpr;
public JavaScriptEngineRule(String supportExpr, String executeExpr) {
this.supportExpr = supportExpr;
this.executeExpr = executeExpr;
}
@Override
public boolean support(Product p) {
if (StringUtils.isBlank(supportExpr)) {
return true;
} else {
Boolean b = (Boolean) eval(supportExpr, Maps.of("product", p));
return b != null && b;
}
}
@Override
public Product execute(Product p) {
Product np = (Product) eval(executeExpr, Maps.of("product", p));
return np;
}
private Object eval(String expr, Map<String, Object> context);
}1.3 测试结果
Product p = new Product();
p.setId(1);
p.setCategoryId(1001);
p.setStaticScore(1F);
p.setRelationScore(3F);定义执行的脚本,可以看到我们只处理id是基数,categoryId大于1000的Product,将finalScore修改为staticScore、relationScore按比例加层后总分。一段脚本代码里可以有多个语句,最后一条语句的执行结果做为ScriptEngine.eval的执行结果返回。
String supportExpr = "product.id % 2 == 1 && product.categoryId > 1000";
String executeExpr = "product.finalScore = product.staticScore * 0.6 + product.relationScore * 0.4; product";
实际测试代码,后续的测试都会重复使用预定义的数据和执行输出,但不会再反复贴出
Rule rule = new JavaScriptEngineRule(supportExpr, executeExpr);
if (rule.support(p)) {
p = rule.execute(p);
}
System.out.println(p);2. 使用Groovy能力
通过JavaScript的ScriptEngine使用动态逻辑,用起来还算简单,但是也有一个明显的问题,JavaScript引擎没法调用工程内的Java类库,如果我想要在动态逻辑里发生HTTP请求、使用JDBC、发生MQ消息等等,就很难做到。而Groovy能帮助我们达成这些目标。
2.1 GroovyClassLoader
将完整的Rule实现存储到字符串中(数据库、配置中心),由GroovyClassLoader解析生成Class,再通过反射创建实例。我们创建的Rule实现类名字是GroovyClassLoaderRule,他会将所有调用委托给通过反射创建的实例。
public class GroovyClassLoaderRule implements Rule {
private String subClass = """
package com.lws.rule.impl;
import com.lws.rule.Product;
import com.lws.rule.Rule;
public class TemporaryGroovySubClass implements Rule {
@Override
public boolean support(Product p) {
return p.getId() % 2 == 1 && p.getCategoryId() > 1000;
}
@Override
public Product execute(Product p) {
double score = p.getStaticScore() * 0.6 + p.getRelationScore() * 0.4;
p.setFinalScore((float)score);
return p;
}
}
""";
private Rule instance;
public void init() throws InstantiationException, IllegalAccessException {
GroovyClassLoader classLoader = new GroovyClassLoader();
Class clazz = classLoader.parseClass(subClass);
instance = (Rule)clazz.newInstance();
}
@Override
public boolean support(Product p) {
return instance.support(p);
}
@Override
public Product execute(Product p) {
return instance.execute(p);
}
}可以看到subClass字符串里已经是正常的Java代码了,Java1.7的代码基本都能正常编译。通过调用init方法,我们创建了Rule的实例。这里由一个比较容易成为陷阱的问题是,使用完全相同的subClass内容,创建两个GroovyClassLoaderRule实例时,实际创建的是两个ClassLoader实例,存在完全不同的两个Class对象,会占用两份JVM永久代空间
GroovyClassLoaderRule rule = new GroovyClassLoaderRule();
rule.init();
GroovyClassLoaderRule rule1 = new GroovyClassLoaderRule();
rule1.init();
System.out.println(rule.getInstance().getClass().getName()); // 这里输出的名字完全相同
System.out.println(rule1.getInstance().getClass().getName());
System.out.println(rule.getInstance().getClass() == rule1.getInstance().getClass()); // 但Class对象却不是一个问题根本的原因是同一个ClassLoader同一个类只能加载一次,要反复加载同一个类名就需要使用不同的ClassLoader。为了解决这个问题可以:
2.2 GroovyShell
GroovyClassLoader通过动态的源码直接创建了一个Class对象,有时候我们的动态逻辑并没有那么复杂。GroovyShell的使用方式更像ScriptEngine,可以指定一段脚本直接返回计算结果。
如果是直接执行脚本来获取结果,GroovyShell的实现和之前的JavaScriptEngineRule基本一致,执行修改eval方法的实现
private Object eval(String expr, Product product) {
Binding binds = new Binding();
binds.setVariable("product", product);
GroovyShell shell = new GroovyShell(binds);
Script script = shell.parse(expr);
return script.run();
}这段代码里的先执行shell.parse,再执行script.run,可以用evaluate方法直接代码,evaluate方法内部实际调用的parse、run方法
private Object eval(String expr, Product product) {
Binding binds = new Binding();
binds.setVariable("product", product);
GroovyShell shell = new GroovyShell(binds);
return shell.evaluate(expr);
}
测试脚本可以用JavaScriptEngineRule的脚本,也可以自己稍作修改,在返回值前在return关键字
String supportExpr = "product.id % 2 == 1 && product.categoryId > 1000";
String executeExpr = "product.finalScore = product.staticScore * 0.6 + product.relationScore * 0.3; product";
GroovyShellRule rule = new GroovyShellRule(supportExpr, executeExpr);除了直接调用脚本之外,GroovyShell还允许我们定义和调用函数,比如我们将上面的executeExpr逻辑通过一个函数实现的话
private String functions = """
def support(p) {
return p.id % 2 == 1 && p.categoryId > 1000
}
def execute(p) {
p.finalScore = p.staticScore * 0.6 + p.relationScore * 0.3;
return p;
}
""";
private Object eval(String method, Product product) {
GroovyShell shell = new GroovyShell();
Script script = shell.parse(functions);
return script.invokeMethod(method, product);
}2.3 GroovyScriptEngine
GroovyScriptEngine和GroovyClassLoader类似,不同的是GroovyScriptEngine指定根目录,通过文件名自动加载根目录下的文件,创建了instance实例之后,逻辑和GroovyClassLoader的实现就完全相同了。
public void init() throws Exception {
GroovyScriptEngine engine = new GroovyScriptEngine("src/main/java/groovy");
Class<TemporaryGroovySubClass> clazz = engine.loadScriptByName("TemporaryGroovySubClass.java");
instance = clazz.newInstance();
}3. Spring的lang:groovy
当今主流的Java应用,尤其是Web端应用,基本都托管在Spring容器下,如果代码由变更的情况下,Bean实例的逻辑自动变更的话,还是很方便的。我定义几个最简单的类
public interface ProductFactory {
public Product getProduct();
}我们期望动态加载的实现,测试过程中,我会修改id字段的值,来查看Bean是否重新加载
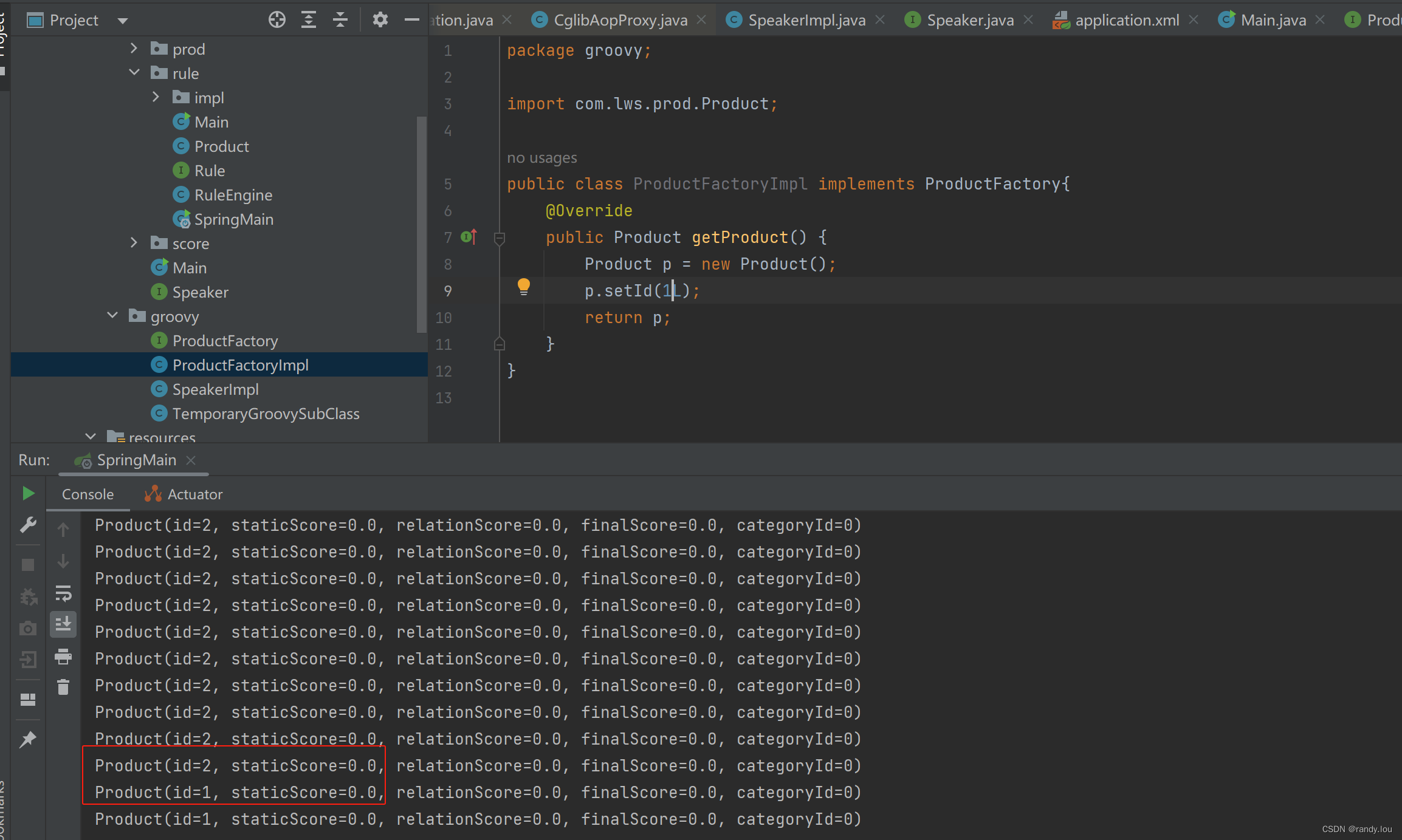
public class ProductFactoryImpl implements ProductFactory{
public Product getProduct() {
Product p = new Product();
p.setId(1L);
return p;
}
}<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:lang="http://www.springframework.org/schema/lang"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/lang http://www.springframework.org/schema/lang/spring-lang-2.5.xsd">
<lang:groovy id="factory" refresh-check-delay="5000" script-source="file:D:/Workspace/groovy/ProductFactoryImpl.java"/>
</beans>public class SpringMain {
public static void main(String[] args) throws InterruptedException {
ClassPathXmlApplicationContext context = new ClassPathXmlApplicationContext("application.xml");
ProductFactory factory = (ProductFactory) context.getBean("factory");
while (true) {
Thread.sleep(1000);
System.out.println(factory.getProduct());
}
}
}3.1 实现原理
<lang:groovy/>生成的Bean是Spring提供的代理Bean,通过AOP生成代理对象,代理对象下面包含实际的数据对象,通过刷新这个数据对象让Bean表现的像是自动更新。
3.2 无法转型
一开始我没有为ProductFactoryImpl定义接口,在Java的main方法里直接引用了ProductFactoryImpl类(因为他也在ClassPath下),这回导致Java的类加载器加载这个Class对象。<lang:groovy/>运行时再次加载ProductFactoryImpl,成为一个新的Class对象。而这两个Class对象分属于不同的类加载,相互之间无法转换,也无法赋值。
同样是因为一开始没有定义接口,导致<lang:groovy/>设置必须使用类代理proxy-target-class="true"配置,最终导致如下报错
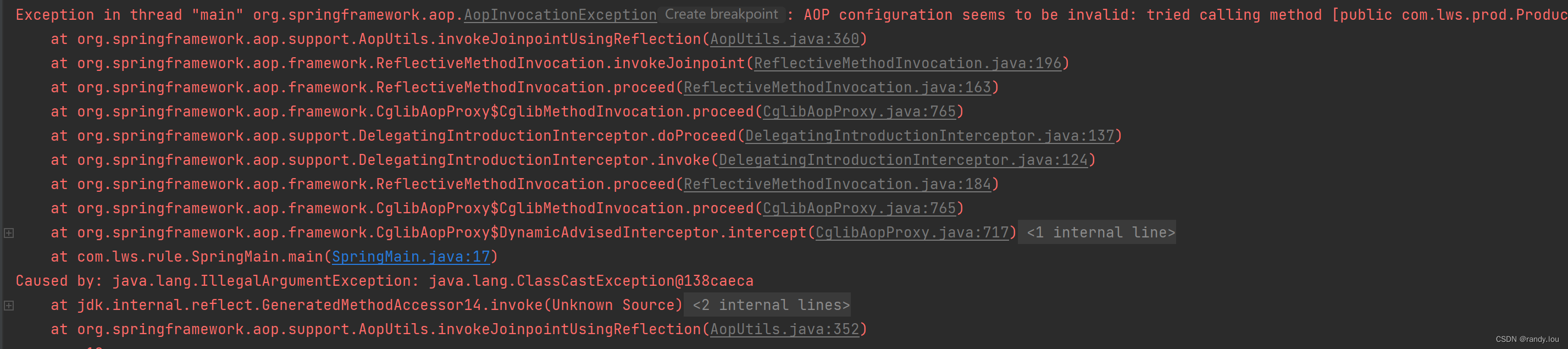
究其原因是在AOP调用的时候,通过method实例反射调用,而执行过程中却发现这个method不是target对象里的method。具体证据如下:
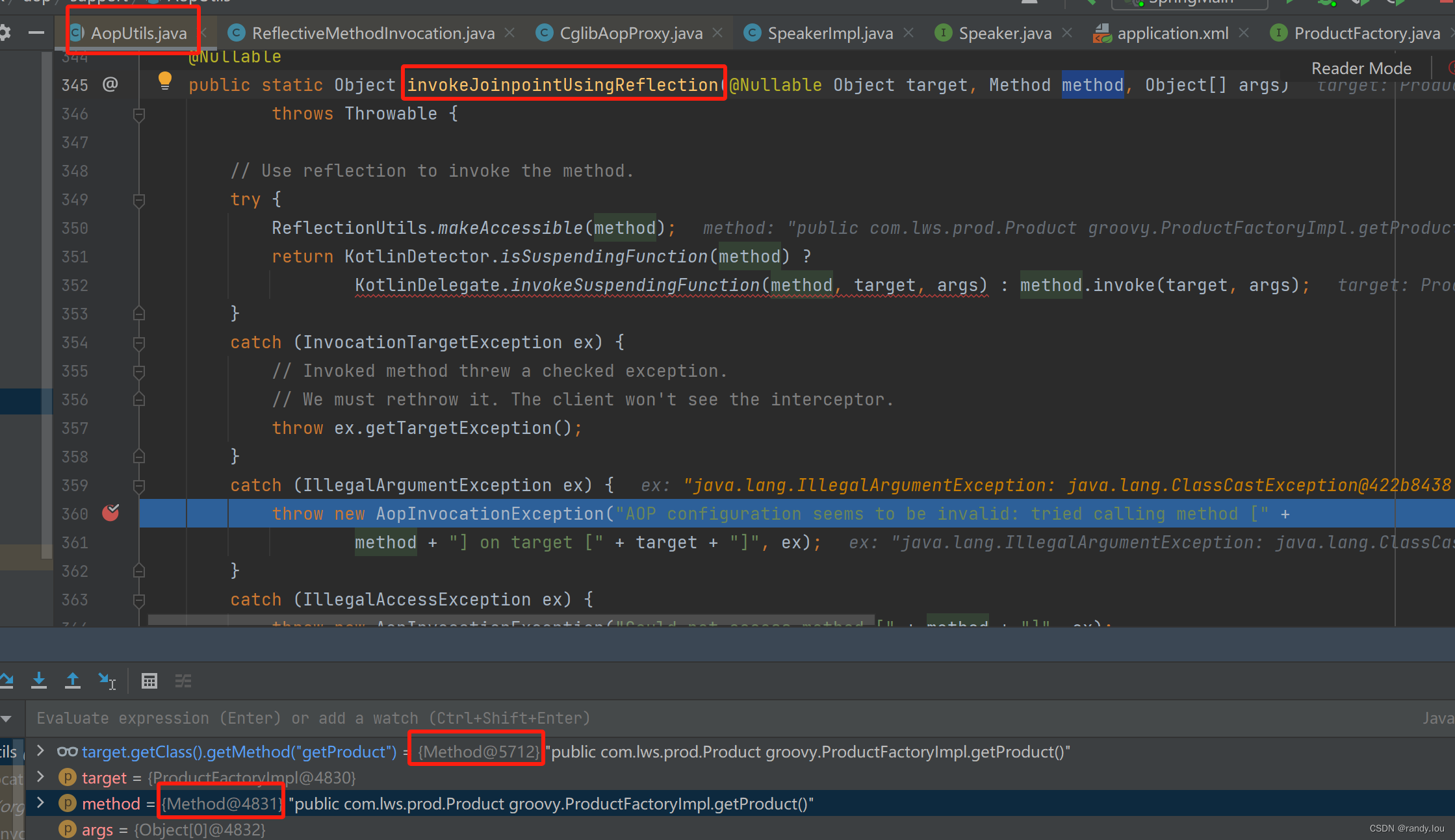
target上的getProduct方法,和invokeJoinpointUsingReflection的method方法已经不是同一个实例。
总的来说,要想正确的使用<lang:groovy/>,需要注意两点,为script-source执行的对象设计接口,不用指定proxy-target-class。通过日志可以看到product.id的修改是生效的。
4. JavaCC自定义DSL
JavaCC定义自己的DSL提供了更多的灵活性,也会大大的增加成本,自己定义的DSL可能会有潜在的问题,后续我们会专门出一篇JavaCC的文章,敬请期待。
5. 我该如何选择
如果只支持简单的逻辑,ScriptEngine够用的情况下直接用ScriptEngine即可。对动态脚本的能力要求较高时选择Groovy的方案,要注意Class的回收。<lang:groovy/>做成通过数据库/配置中心加载动态代码的改造相对较大,如果不介意依然依赖文件系统特定位置的文件的话,也不失为一种选择。















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









