






今天是参加昇思25天学习打卡营的第24天,今天打卡的课程是“Diffusion扩散模型”,这里做一个简单的分享。
1.简介
本次学习的扩散模型(Diffusion Models)主要是基于denoising diffusion probabilistic model (DDPM)的模型。DPM已经在(无)条件图像/音频/视频生成领域取得了较多显著的成果,现有的比较受欢迎的的例子包括由OpenAI主导的GLIDE和DALL-E 2、由海德堡大学主导的潜在扩散和由Google Brain主导的图像生成。
2.模型架构及原理
如果将Diffusion与其他生成模型(如Normalizing Flows、GAN或VAE)进行比较,它并没有那么复杂,它们都将噪声从一些简单分布转换为数据样本,Diffusion也是从纯噪声开始通过一个神经网络学习逐步去噪,最终得到一个实际图像。 Diffusion对于图像的处理包括以下两个过程:
- 我们选择的固定(或预定义)正向扩散过程 𝑞𝑞 :它逐渐将高斯噪声添加到图像中,直到最终得到纯噪声
- 一个学习的反向去噪的扩散过程 𝑝𝜃𝑝𝜃 :通过训练神经网络从纯噪声开始逐渐对图像去噪,直到最终得到一个实际的图像
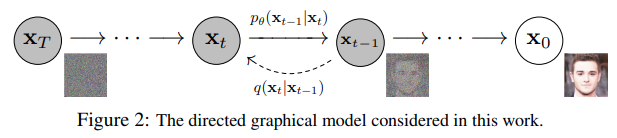
由 𝑡𝑡 索引的正向和反向过程都发生在某些有限时间步长 𝑇𝑇(DDPM作者使用 𝑇=1000𝑇=1000)内。从𝑡=0𝑡=0开始,在数据分布中采样真实图像 𝐱0𝑥0(本文使用一张来自ImageNet的猫图像形象的展示了diffusion正向添加噪声的过程),正向过程在每个时间步长 𝑡𝑡 都从高斯分布中采样一些噪声,再添加到上一个时刻的图像中。假定给定一个足够大的 𝑇𝑇 和一个在每个时间步长添加噪声的良好时间表,您最终会在 𝑡=𝑇𝑡=𝑇 通过渐进的过程得到所谓的各向同性的高斯分布。
整个模型主要包括两个部分:
- 前向扩散过程

- 反向扩散过程

- 训练过程

在每一轮的训练过程中,包含以下内容:
- 每一个训练样本选择一个随机时间步长 t。
- 将 time step t 对应的高斯噪声应用到图片中。
- 将 time step 转化为对应 embedding。
下面是每一轮详细的训练过程:

- 从高斯噪声中生成原始图片(反向扩散过程)

上图的 Sample a Gaussian 表示生成随机高斯噪声,Iteratively denoise the image 表示反向扩散过程,如何一步步从高斯噪声变成输出图片。可以看到最终生成的 Denoised image 非常清晰。
注:以上图片引用自文章https://mp.weixin.qq.com/s?__biz=MzI1MjQ2OTQ3Ng==&mid=2247625397&idx=2&sn=e67b0e7ccf51aeedb4c0ab23310637b5&chksm=e9efe33ede986a28499a27014dcf7b44cbfe5841cf8d95b17f9ab46ab379cb2f237b204e1a9f&scene=27
3.小结
Diffusion模型是文生图任务中的一个重要模型。该模型最重要的两个环节是Difusion的前向扩散和反向扩散的两个过程。前向扩展过程实现了对模型对图像的特征的理解,反向扩展过程则可以通过对前向过程的逆过程来实现的图像的生成,这与文本生成中的编码器-解码器的过程很相似。通过今天的学习和查询相关资料,对基于diffusion的图像生成过程有了一个初步的了解,后续还需要更加深入的学习。
以上是第24天的学习内容,附上今日打卡记录:
















 646
646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









