









声明:
该文章为学习使用,严禁用于商业用途和非法用途,违者后果自负,由此产生的一切后果均与作者无关
一、找出需要加密的参数
- js运行 atob(‘aHR0cHM6Ly93d3cucWNjLmNvbS93ZWIvc2VhcmNoP2tleT0lRTQlQjglODclRTglQkUlQkUlRTklOUIlODYlRTUlOUIlQTI=’) 拿到网址,F12打开调试工具,点击分页找到 search/searchMultit 请求,鼠标右击请求找到Copy>Copy as cUrl(cmd)
- 打开网站:https://spidertools.cn/#/curl2Request,把拷贝好的curl转成python代码
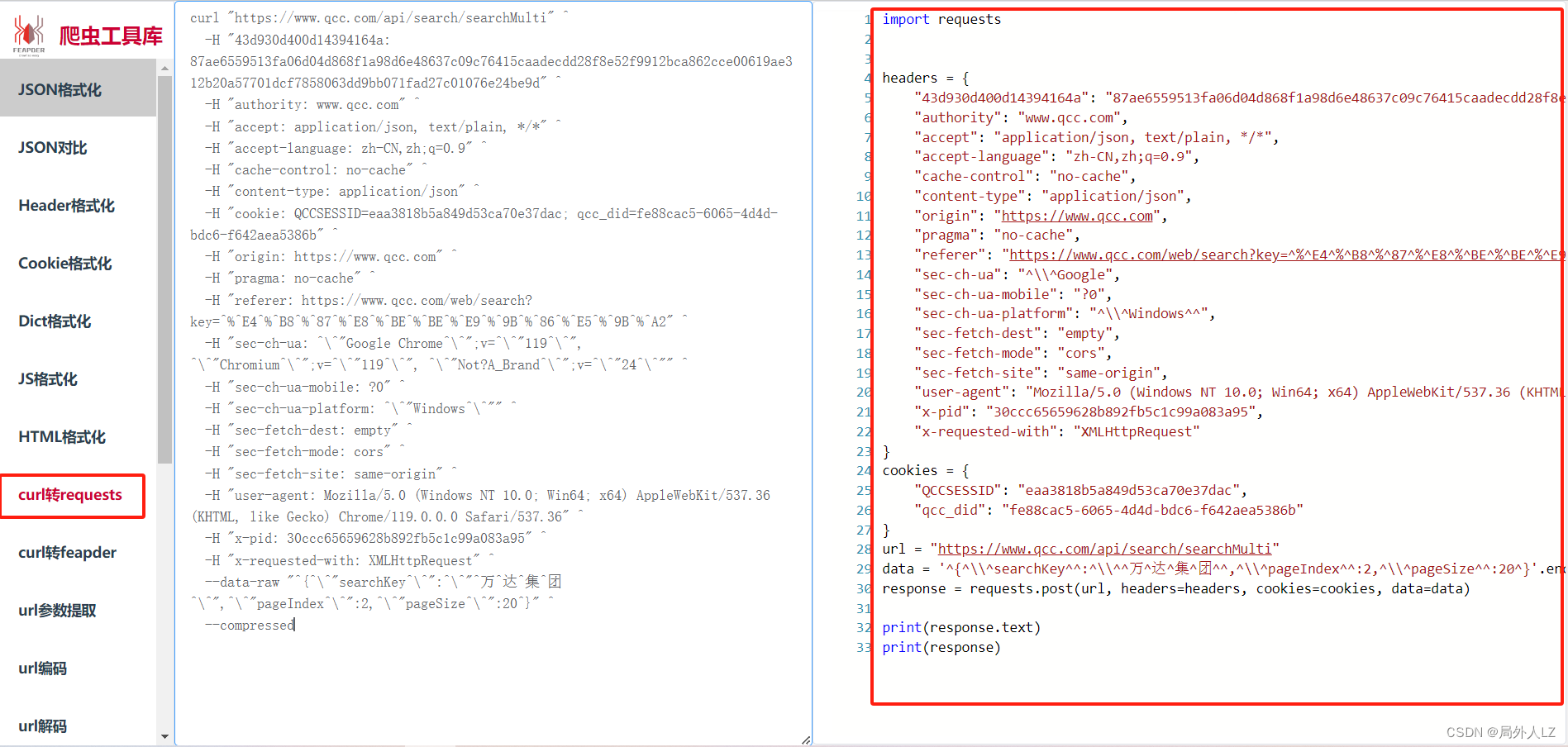
- 新建qichacha.py文件,把代码复制到该文件内,把请求中的参数拷贝给data,请求中的data参数换成json,运行文件,发现请求成功并成功获取到数据
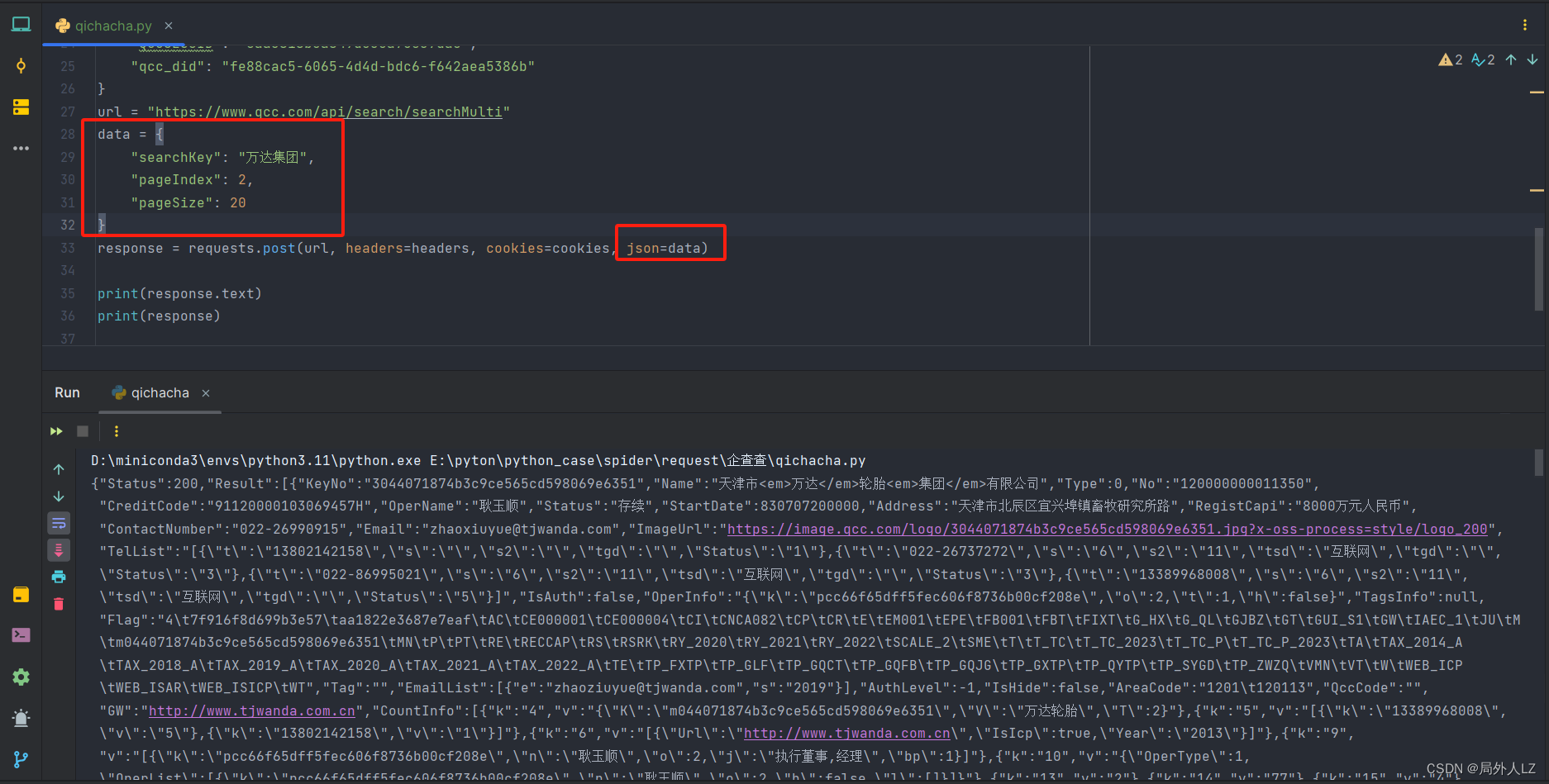
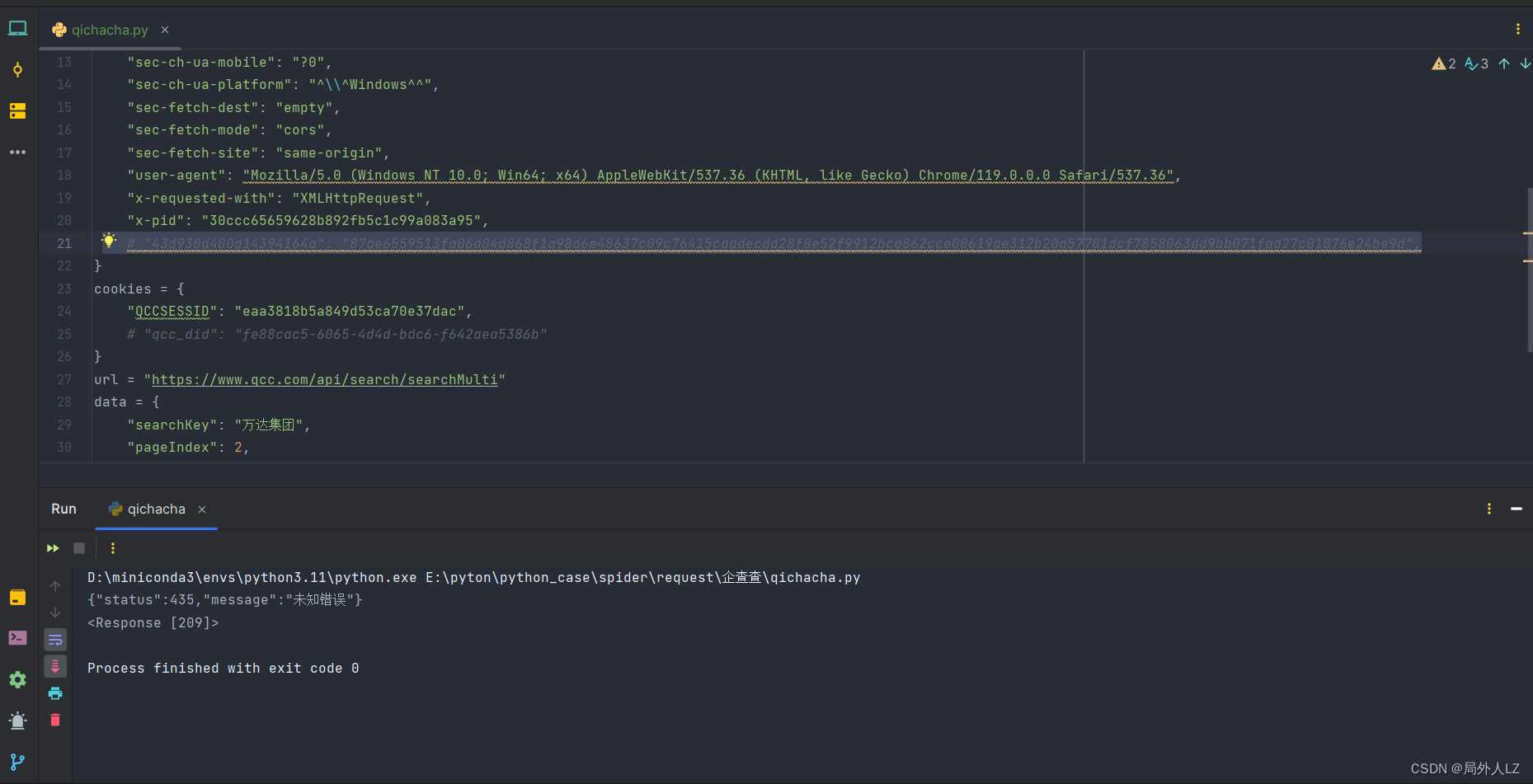
- 然后把代码中header、cookie注释调试后会发现一个虽生成的header、QCCSESSID是加密的
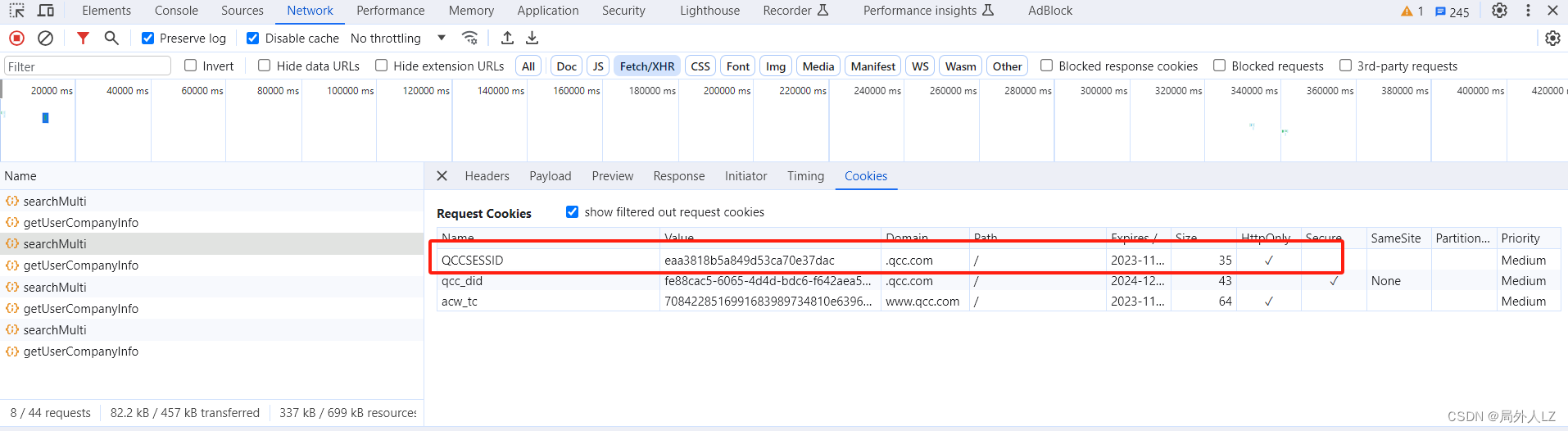
- 在请求cookies中分析得知 ,QCCSESSID是后端生成的可以不用管
二、定位参数加密位置
- 由于加密的header是动态生成的,显然使用关键字搜索无法定位到,直接切换到sources,添加XHR拦截 search/searchMulti
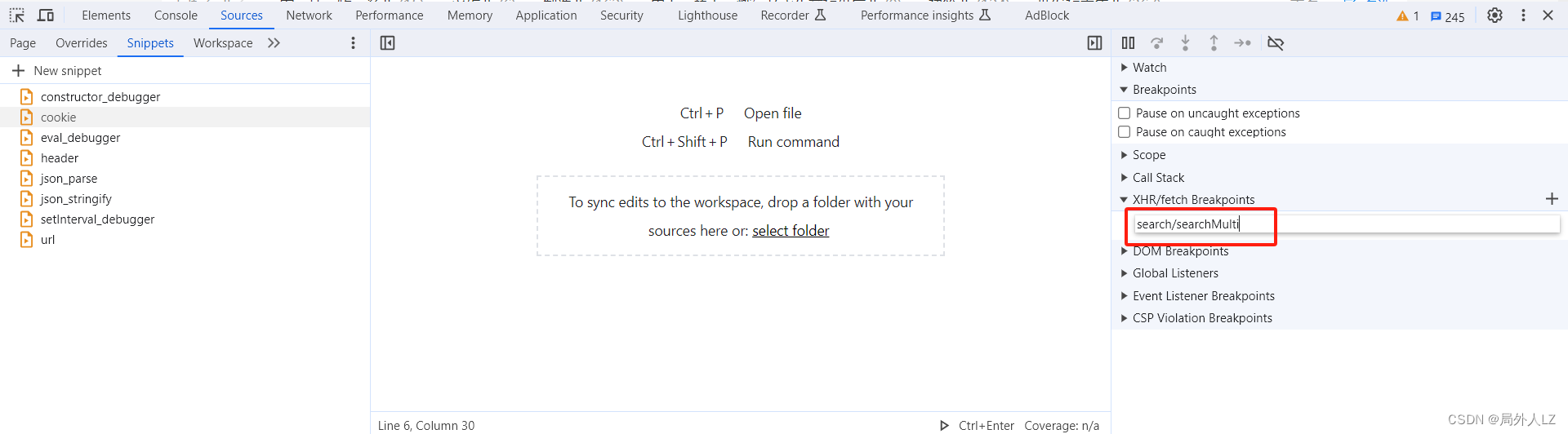
- 一直点击跳到下一个函数,会看到作用域header里面已经没有请求头,在代码里又看到熟悉的参数 x-pid,可以尝试的分析里面的代码
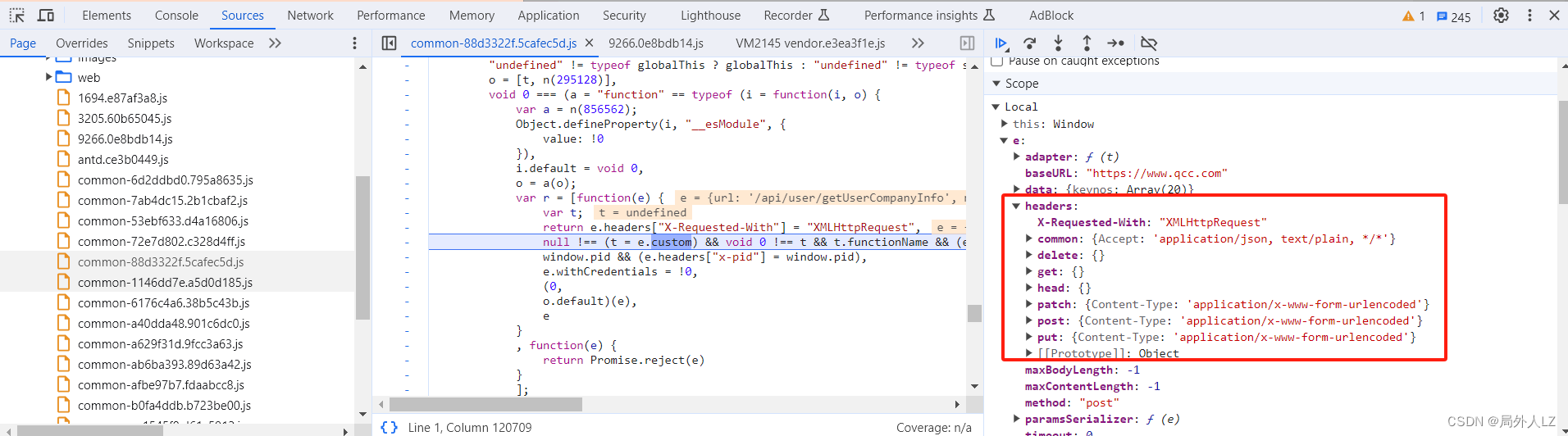
- 鼠标悬浮到 o.default 找到该函数的位置,会发现里面有个header 赋值的代码,在该代码打上断点
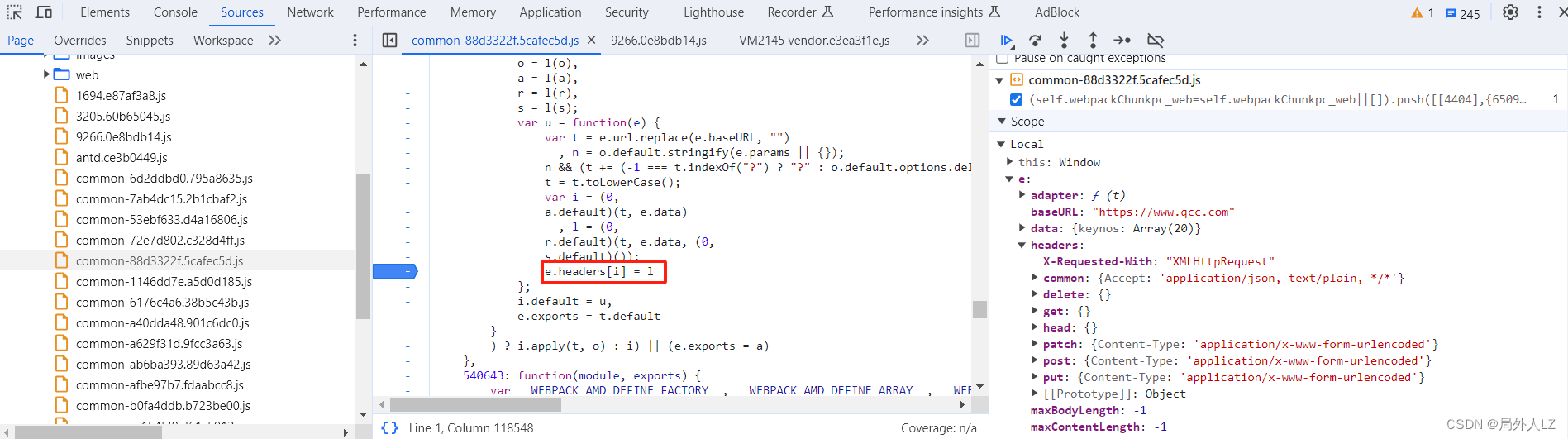
- 结束此次断点调试,点击分页重新发送请求,鼠标悬浮到 i 上发现有随机生成的 header,并且很容易就找到 i = (0, a.default)(t, e.data),l = (0, r.default)(t, e.data, (0, s.default)()),i 是header的key,l是header的value
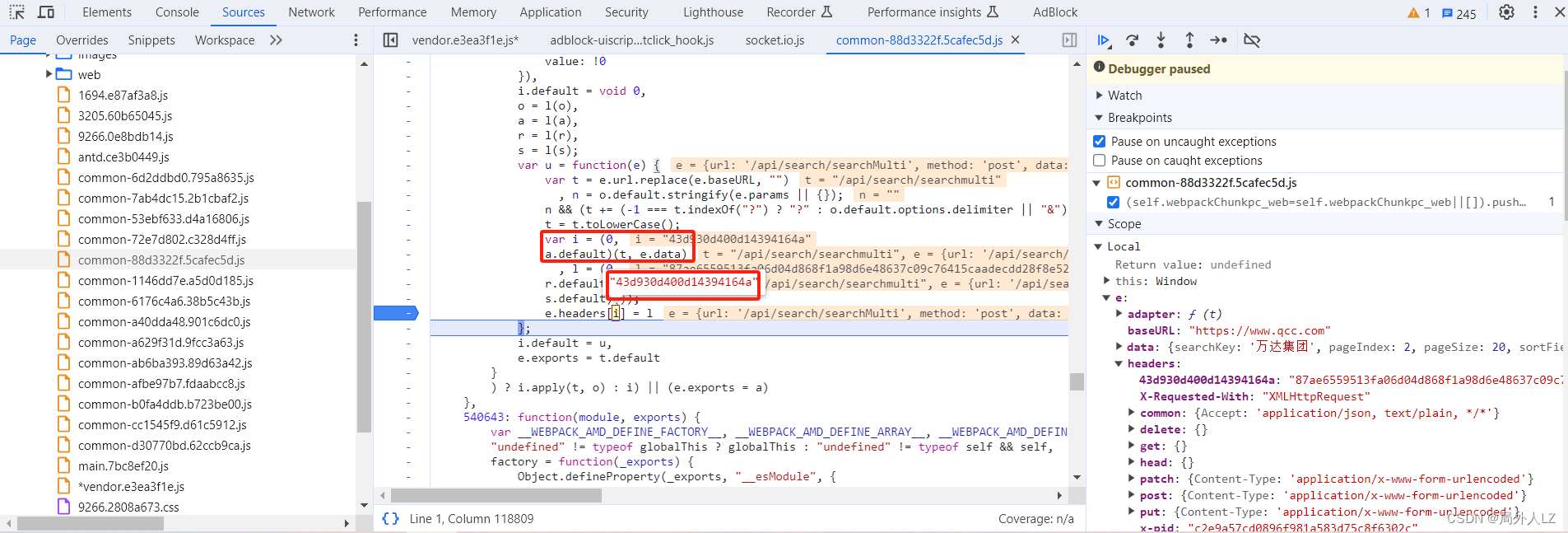
三、扣出加密代码
- 创建qichacha.js文件,用于放扣出的js代码
- 先把 header 的 key 和 value 扣出来,i = (0, a.default)(t, e.data),l = (0, r.default)(t, e.data, (0, s.default)()),把 t、e.data 在控制台打印出来会发现 t 是请求路径,e.data是请求参数
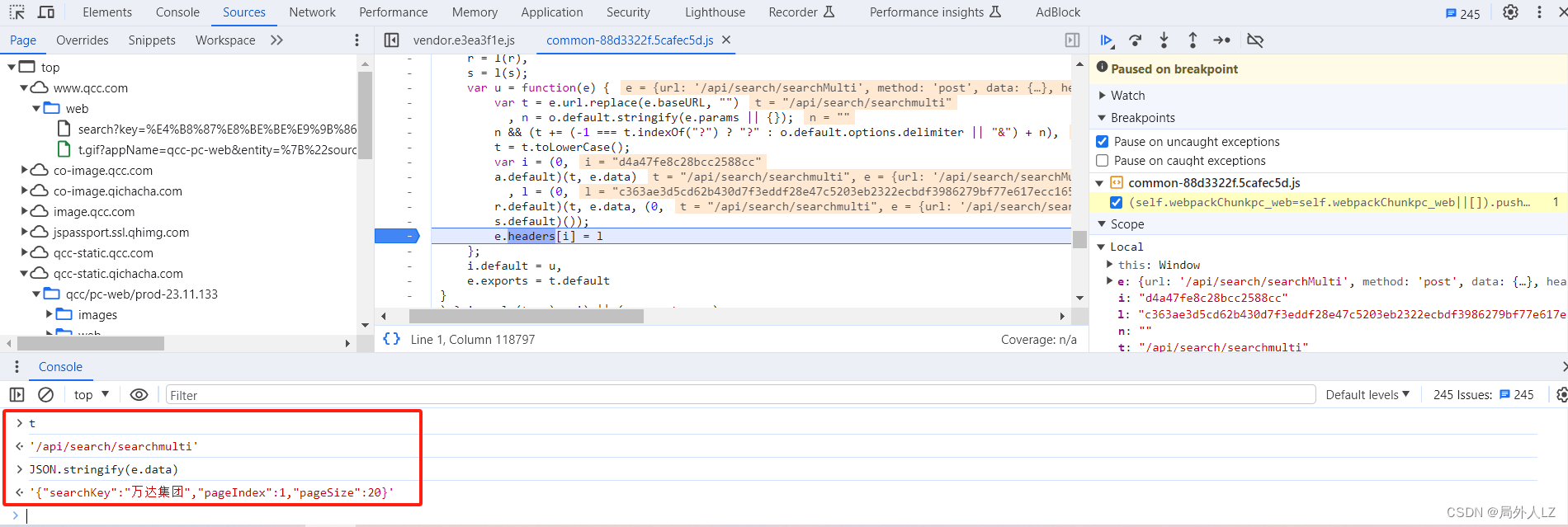
- 扣出加密header的key:i = (0, a.default)(t, e.data)
- 根据第二步已经知道 t 是请求路径,e.data是请求参数,所以只要扣出 a.default 就行, 把 a.default 打印出来会发现,a.default是方法
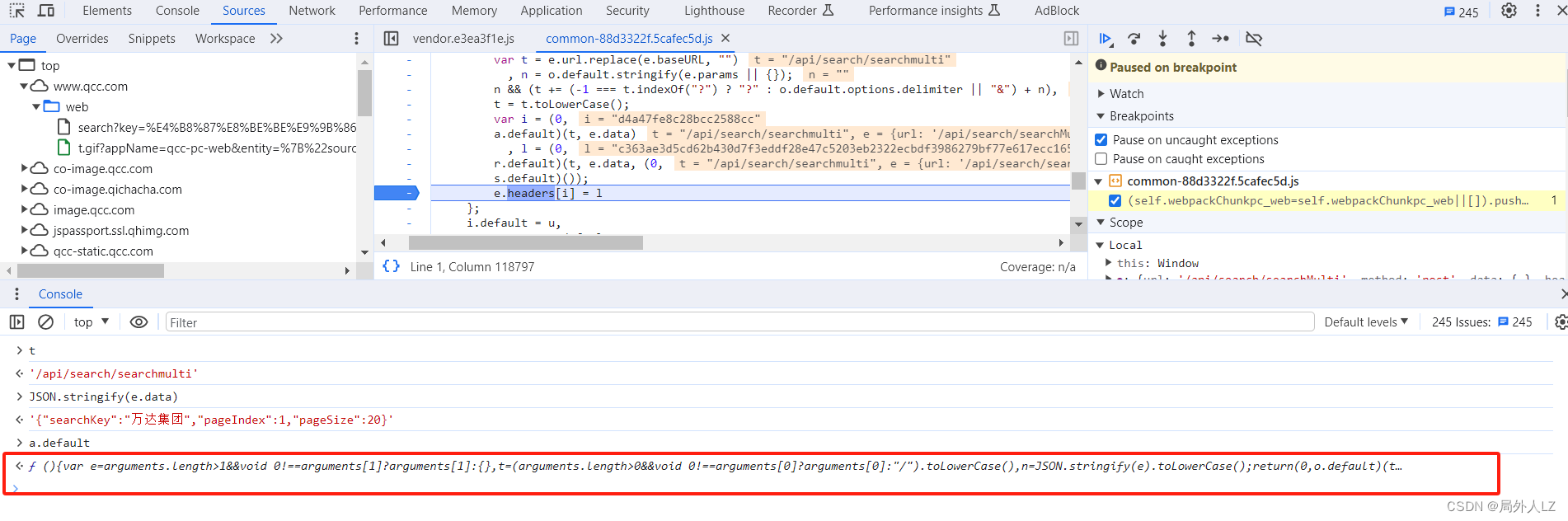
- 点击打印出的 a.default 方法,会快速找到该方法的位置,会发现只有 o.default、a.default是值得注意的方法,其他都是js语法,在方法内部打上断点,并把 s 方法扣到qichacha.js,把 a.default 换成 s
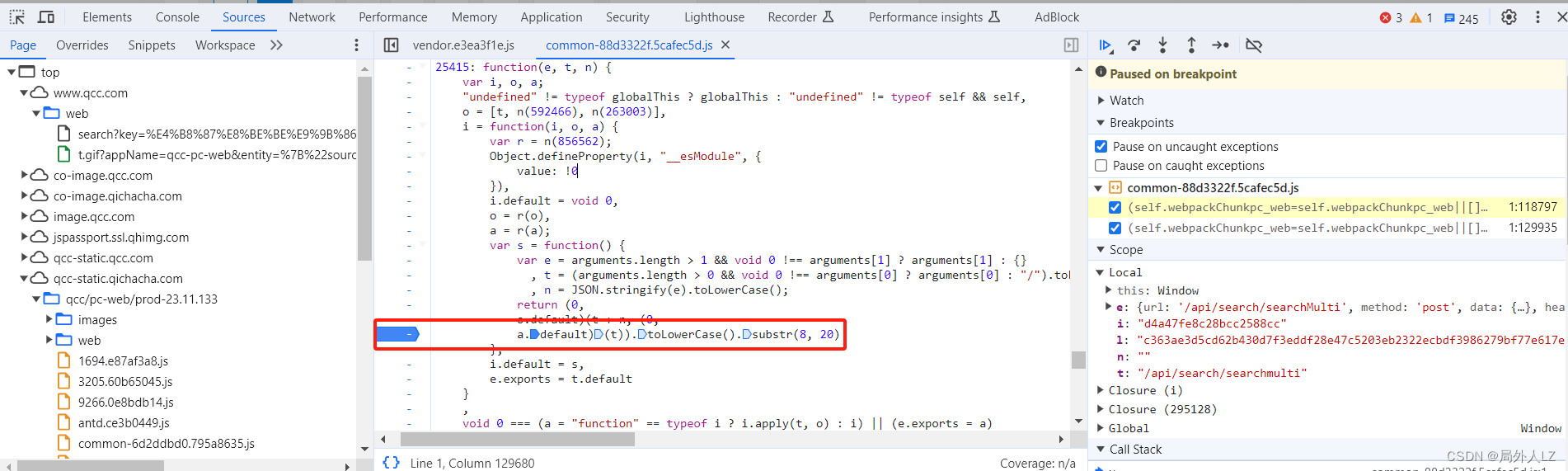
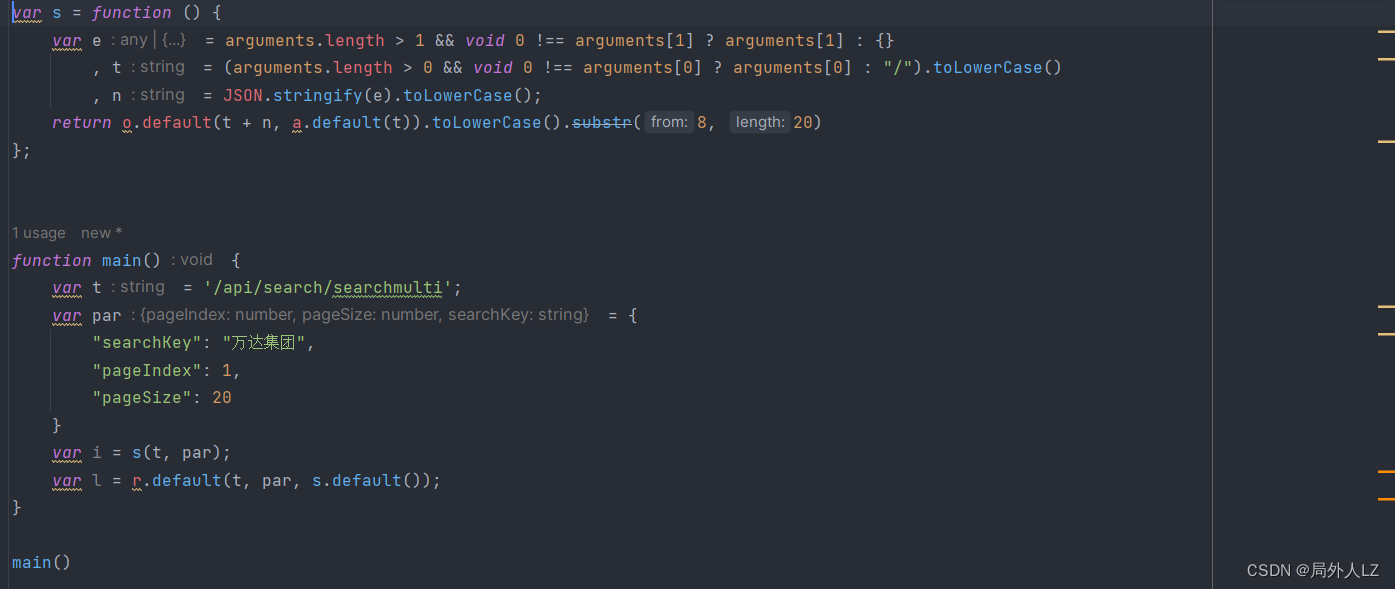
- 开始扣出 s 方法中的 o.default:结束本次调试,点击分页重新发送请求,鼠标悬浮到 o.default,点击蓝色部分找到该方法,会再次发现 o.default 方法在该代码打上断点,并把 r 方法 js扣到qichacha.js,并把 s 中 o.default 替换成 r
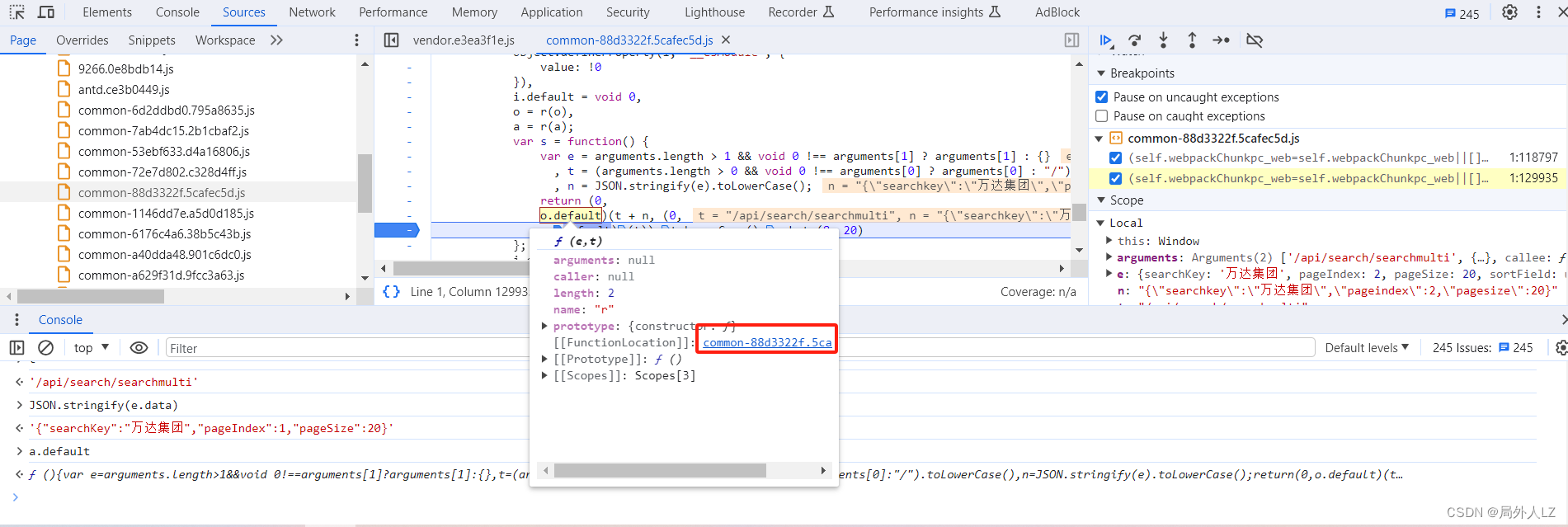
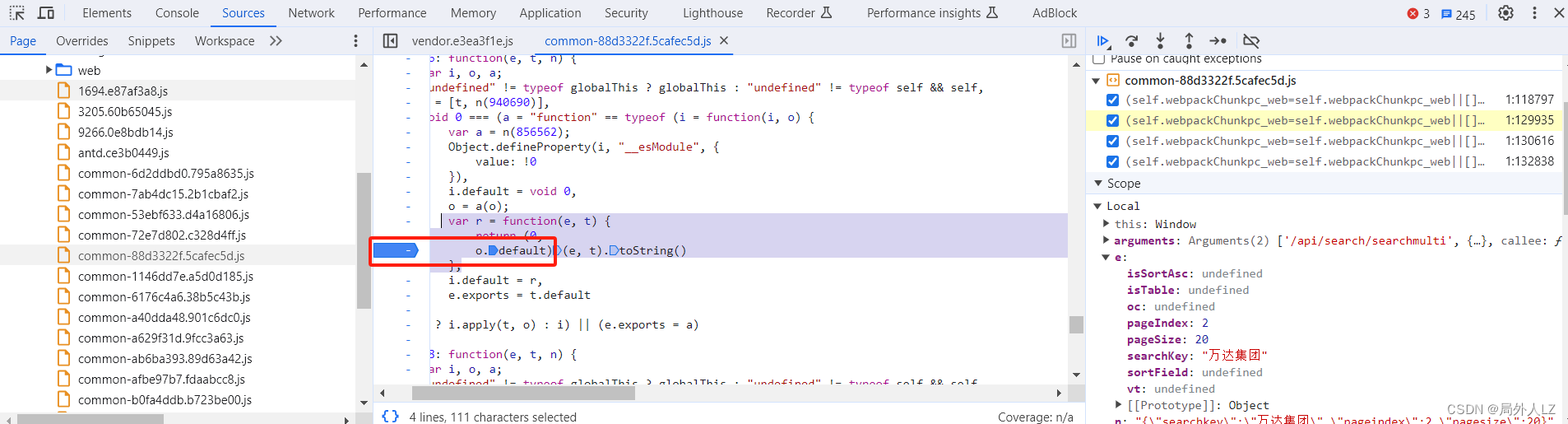
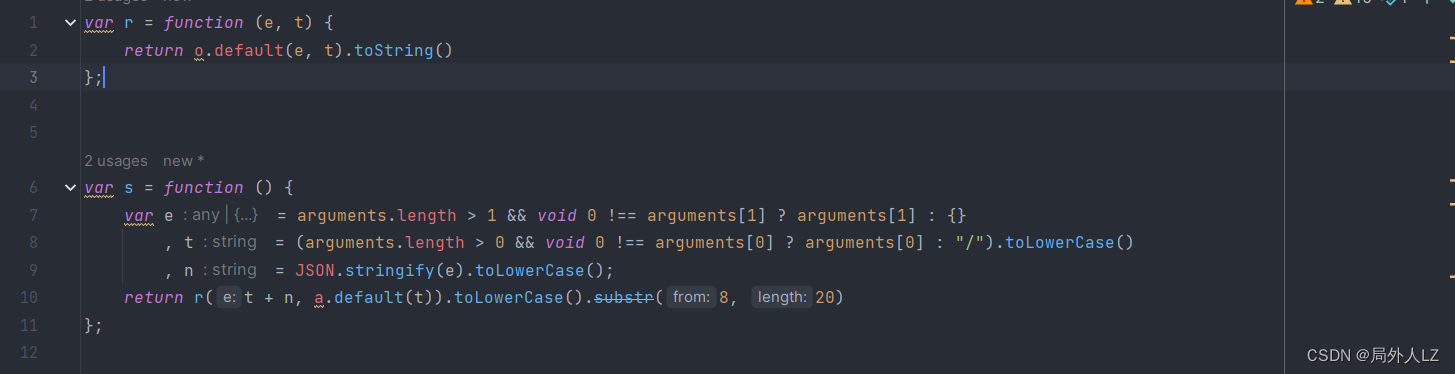
- 结束本次断点,点击分页重新发送请求,一直点击跳到断店调试,看到 e 是路径+参数的字符串时,鼠标悬浮到 r 方法中的 o.default,点击蓝色部分找到该方法,会发现是个HMAC加密
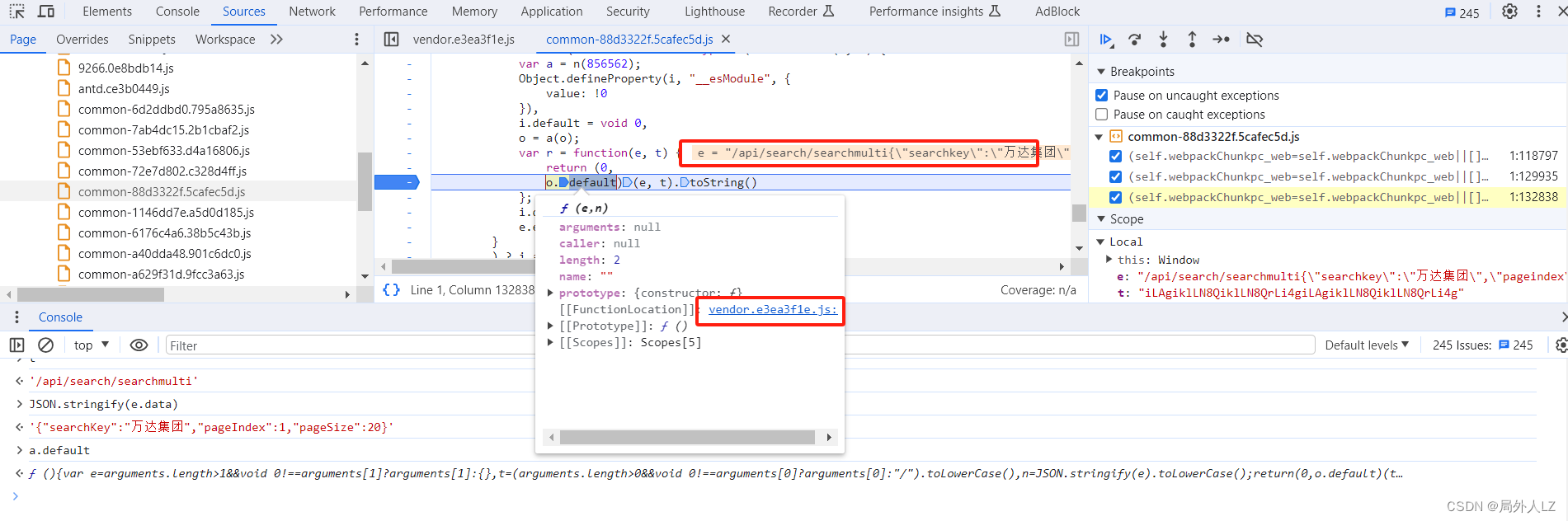
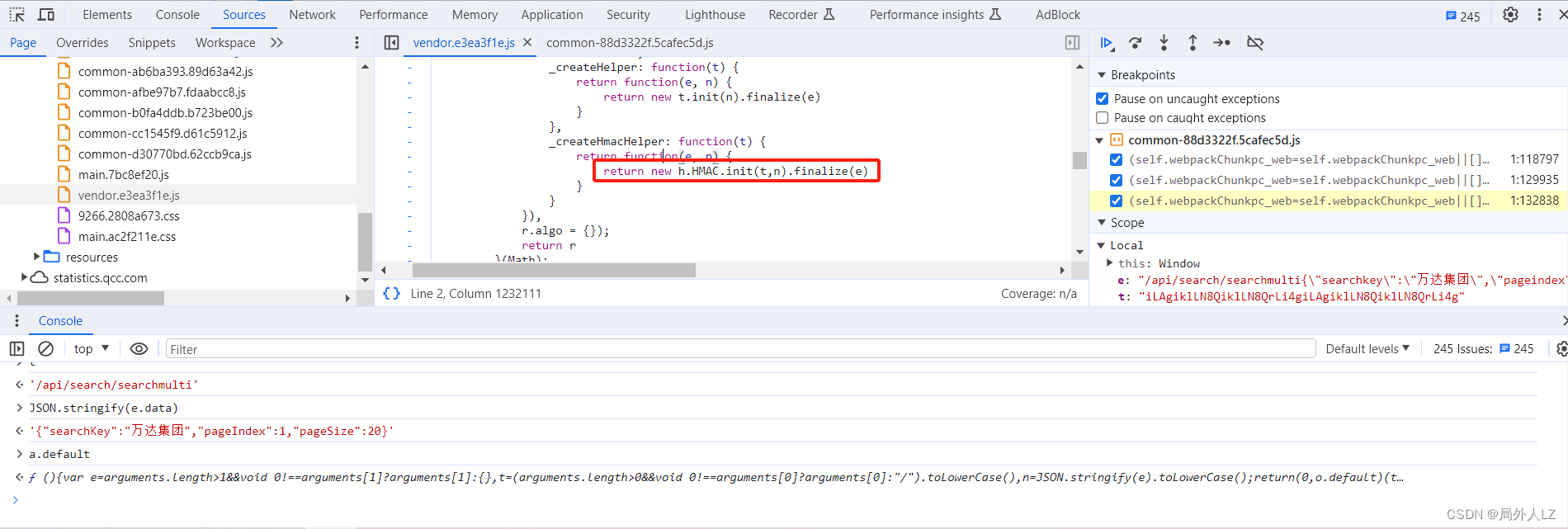
- 分析是哪种 HMAC 加密,在控制台分别打印出:加密数据 e、加密密钥 t、解密结果(0,o.default)(e, t).toString(),打开网站 https://www.dute.org/hmac?ref=search,输入密钥 、加密数据,加密算法是 HMAC SHA 512
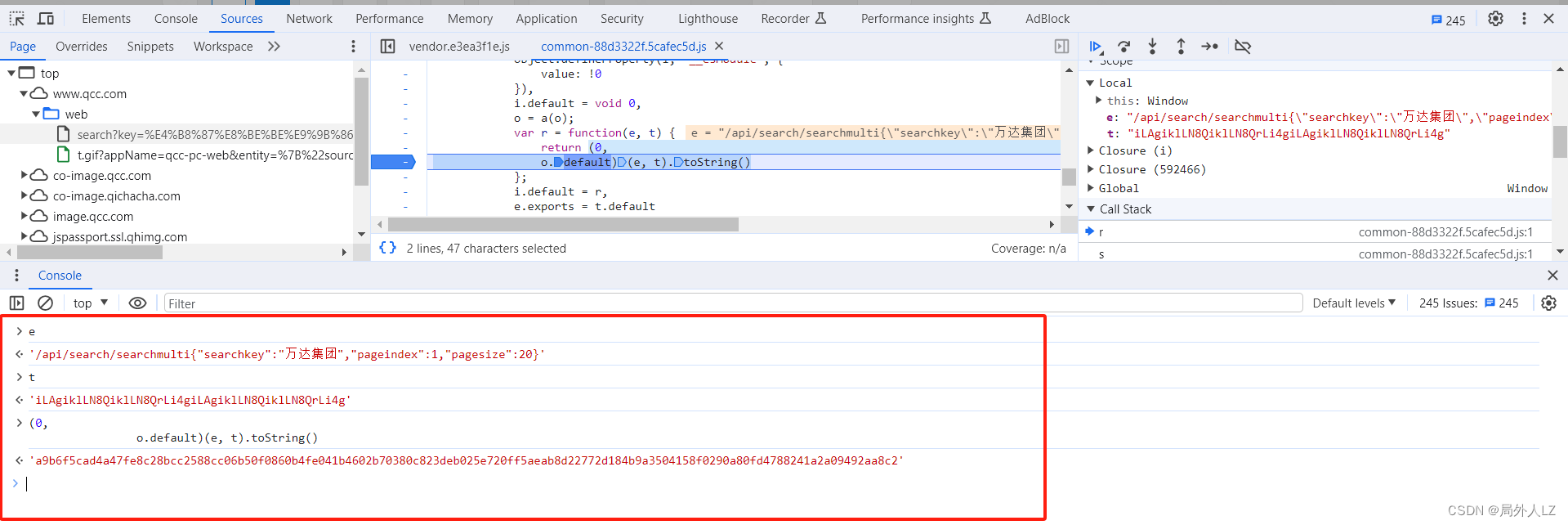
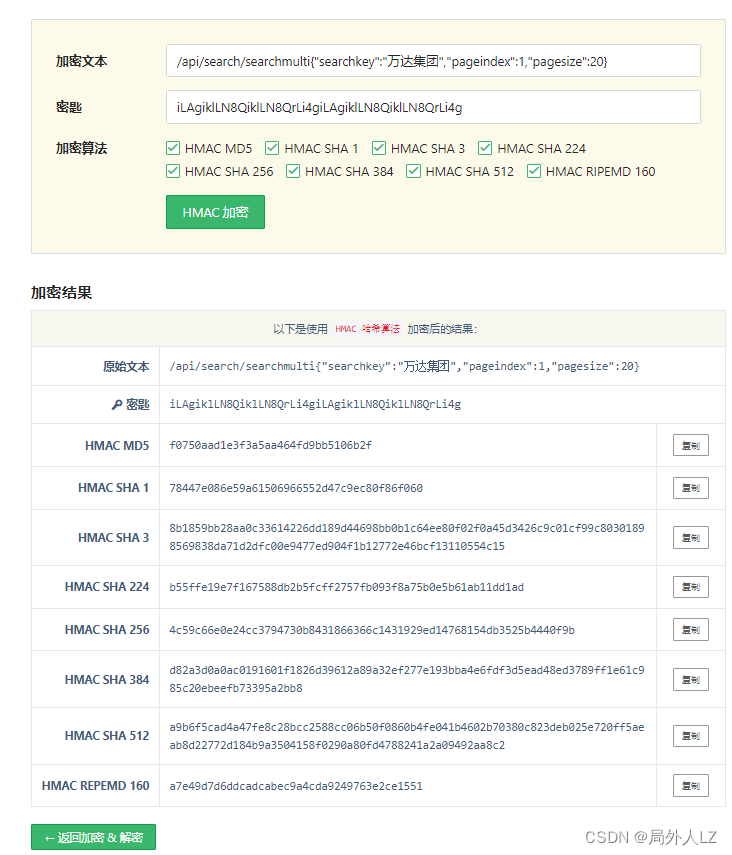
- 根据 HMAC SHA 512 算法完成 r 方法,经过测试相同的加密数据和加密密钥,解密结果相同,至此 s 方法中的 o.default 完全扣出,至此 s 方法中的 o.defaul 完全扣出
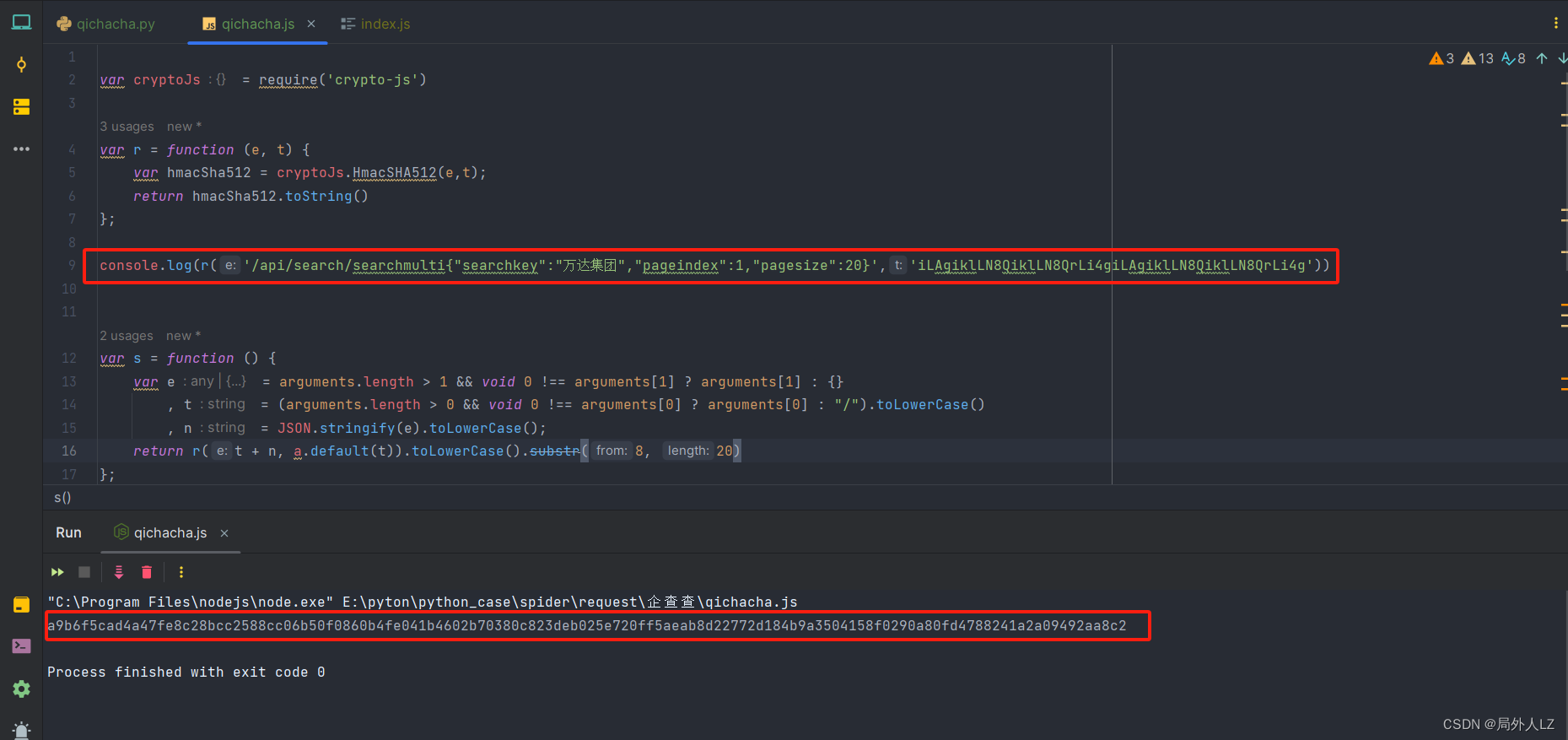
- 开始扣出 s 方法中的 a.default:分析 s 方法中的 a.default,点击蓝色部分找到该方法,会发现是个 r 方法,里面值得注意的是 o.default,其他都是js语法,在 for循环打上断点,,并把 r 方法 js扣到 qichacha.js 因为和之前 r 方法冲突命名为 r1,并把 s 中 a.default 替换成r1
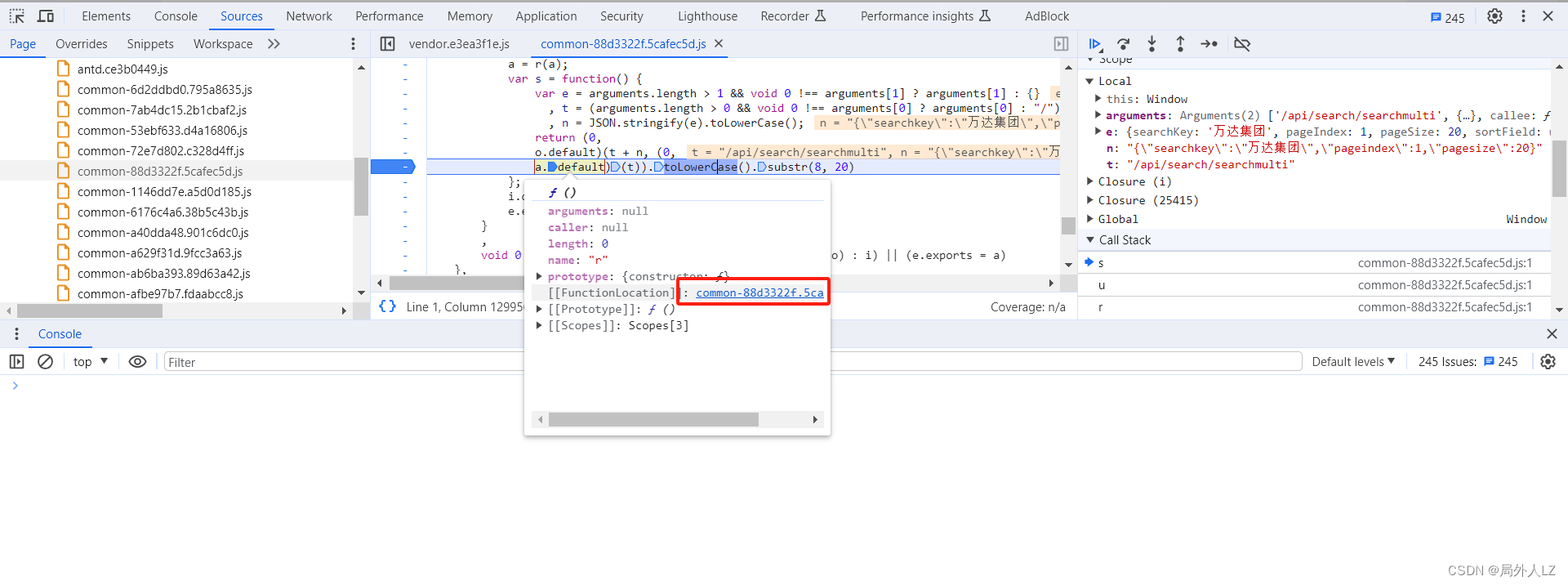
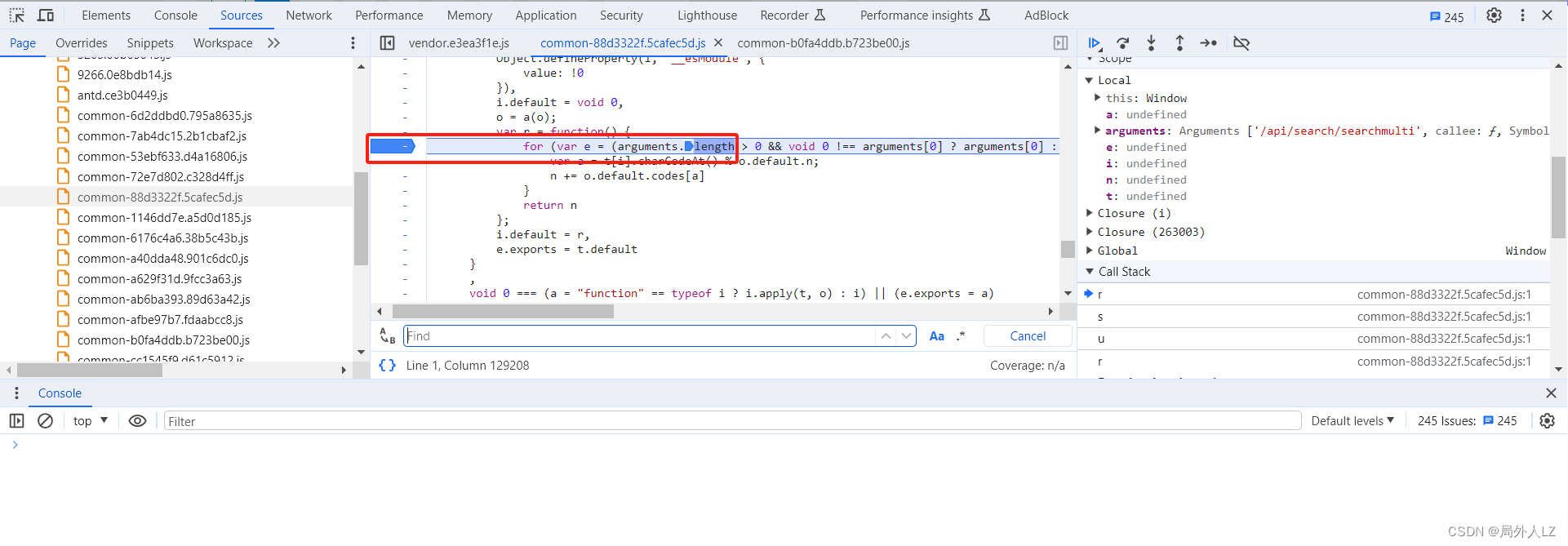
- 结束本次断点,点击分页重新发送请求,一直点击跳到断店调试,看到 r 方法停止调试,在控制台输出 o.default,把打印结果复制出来,补全 r1 方法,至此 s 方法中的 a.default 完全扣出
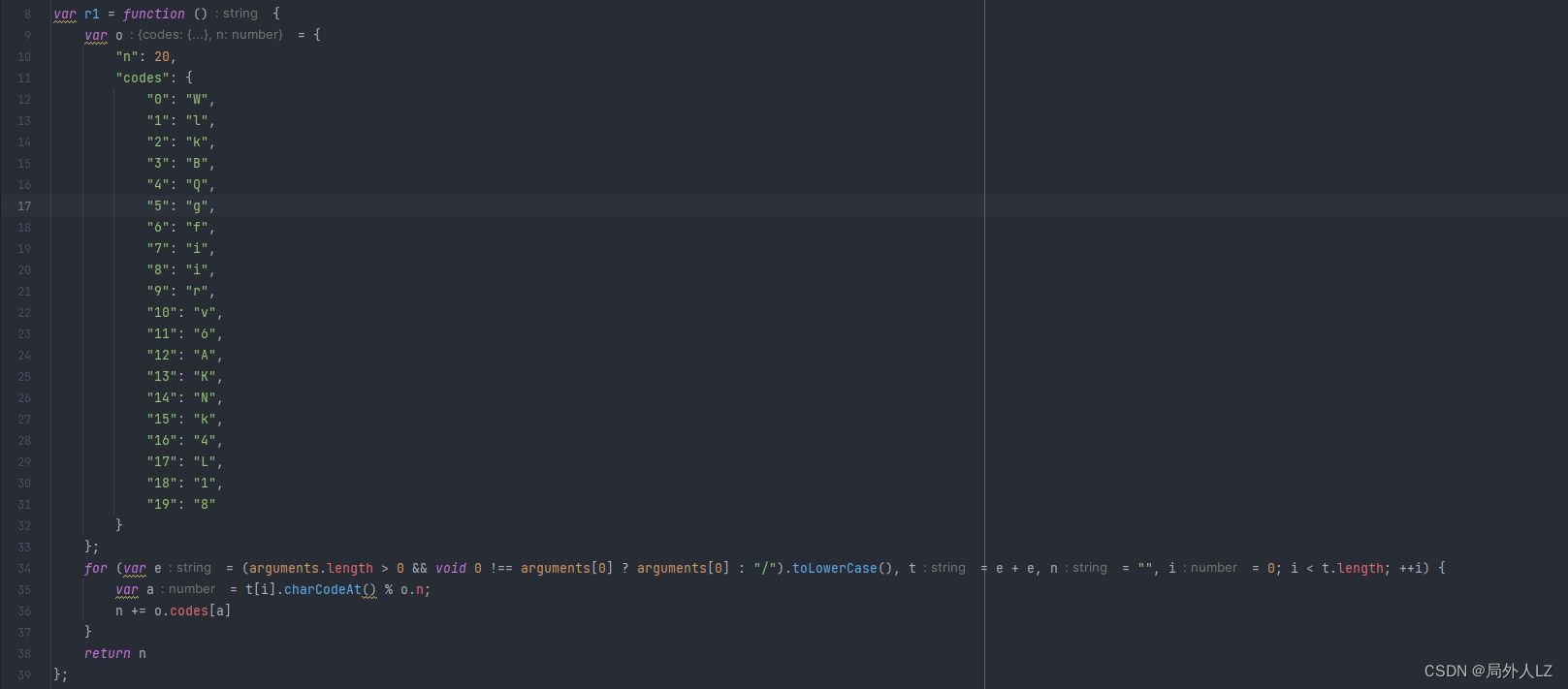
- 验证结果 i = (0, a.default)(t, e.data),删除除了 e.headers[i] = l 之外的其他断点,点击第一页发送请求,把 i 打印控制台,再运行 qichacha.js 文件打印 i,对比两个 i 会发现两个之一样
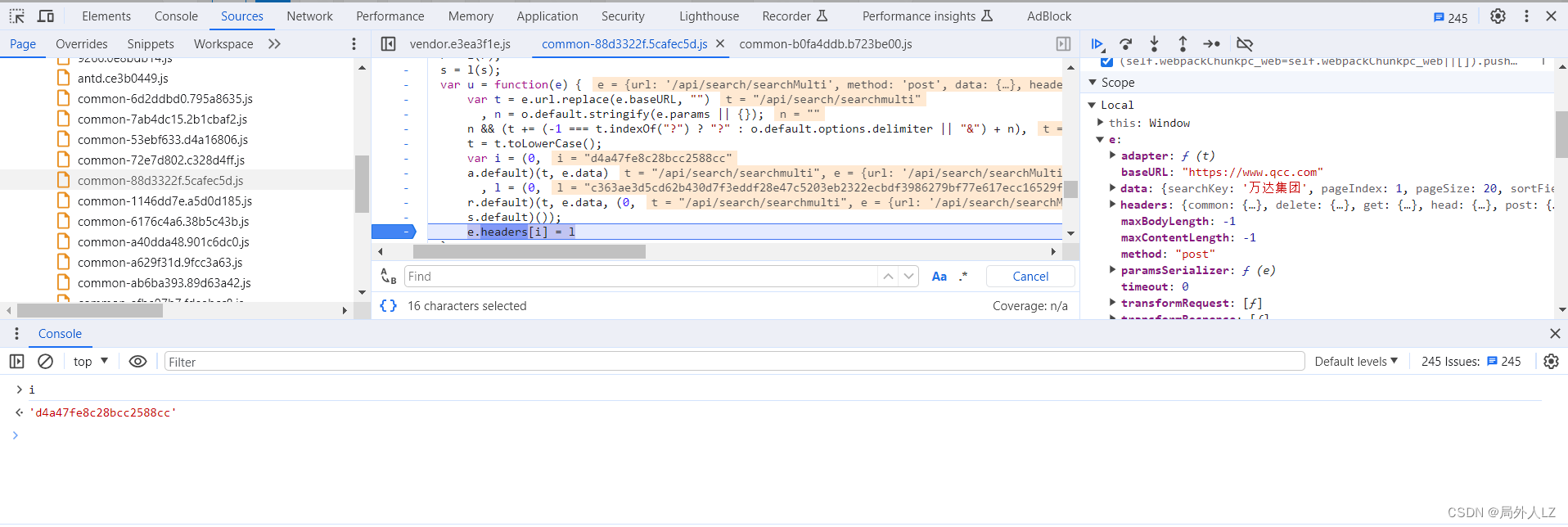
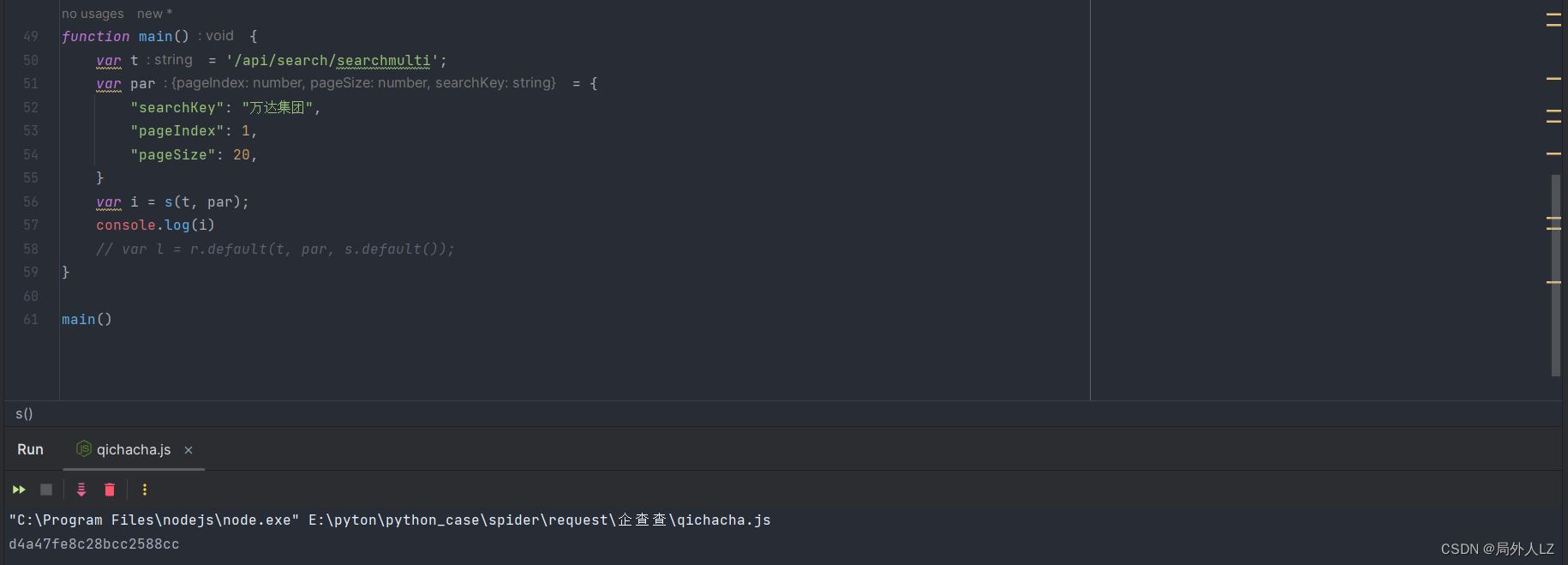
- 扣出加密header的key:l = (0, r.default)(t, e.data, (0, s.default)())
- 根据第二步已经知道 t 是请求路径,e.data是请求参数,所以只要扣出 r.default 、r.default 就行
- 点击分页重新发送请求,鼠标悬浮到 s.default,点击蓝色部分找到该方法,会发现 _default 方法,该方法中都是 js 语法,只需把该函数拷贝出来就行,拷贝出来后命名为 s1,把 s.default 换成 s1
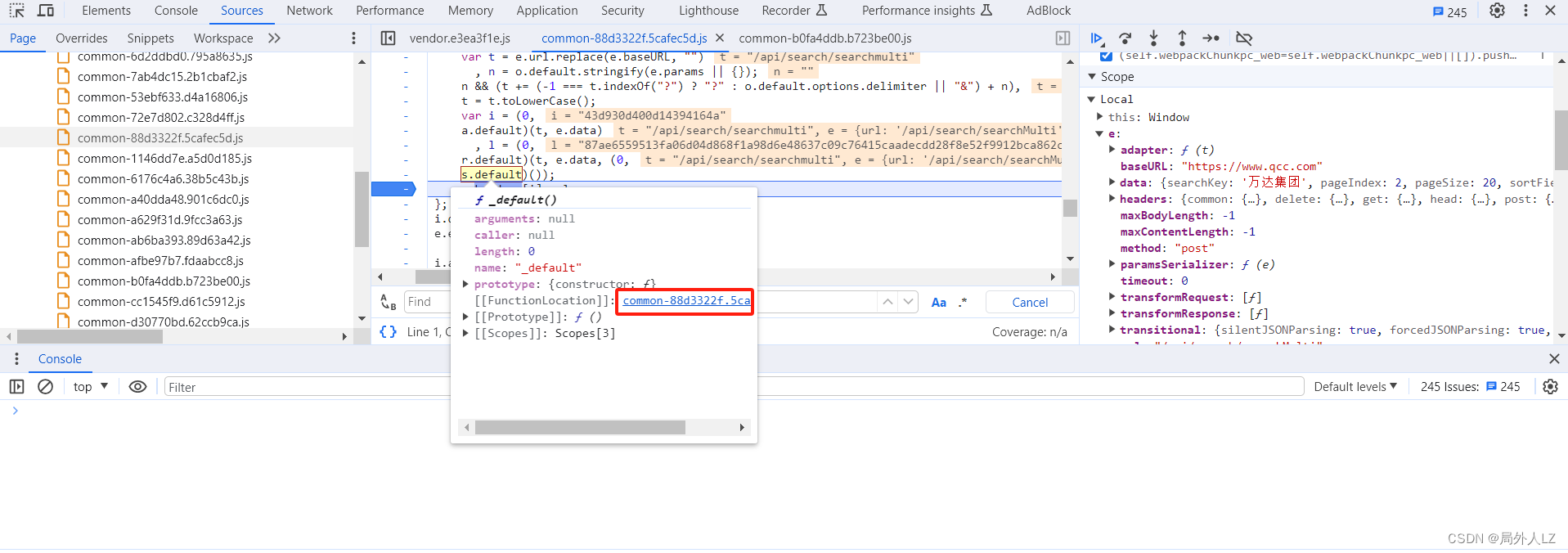

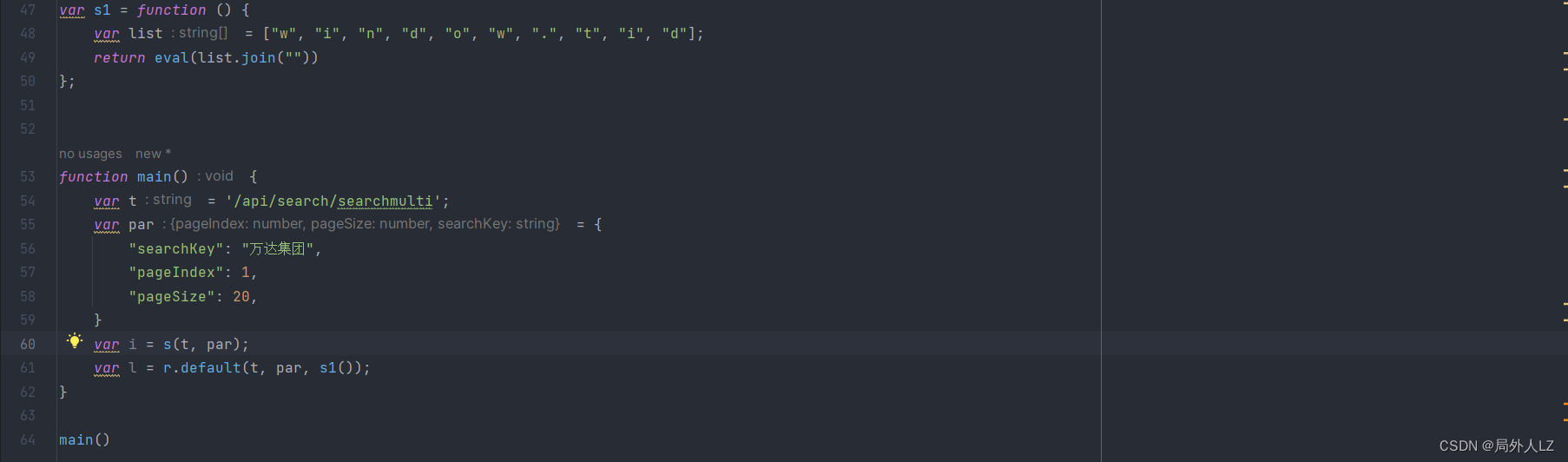
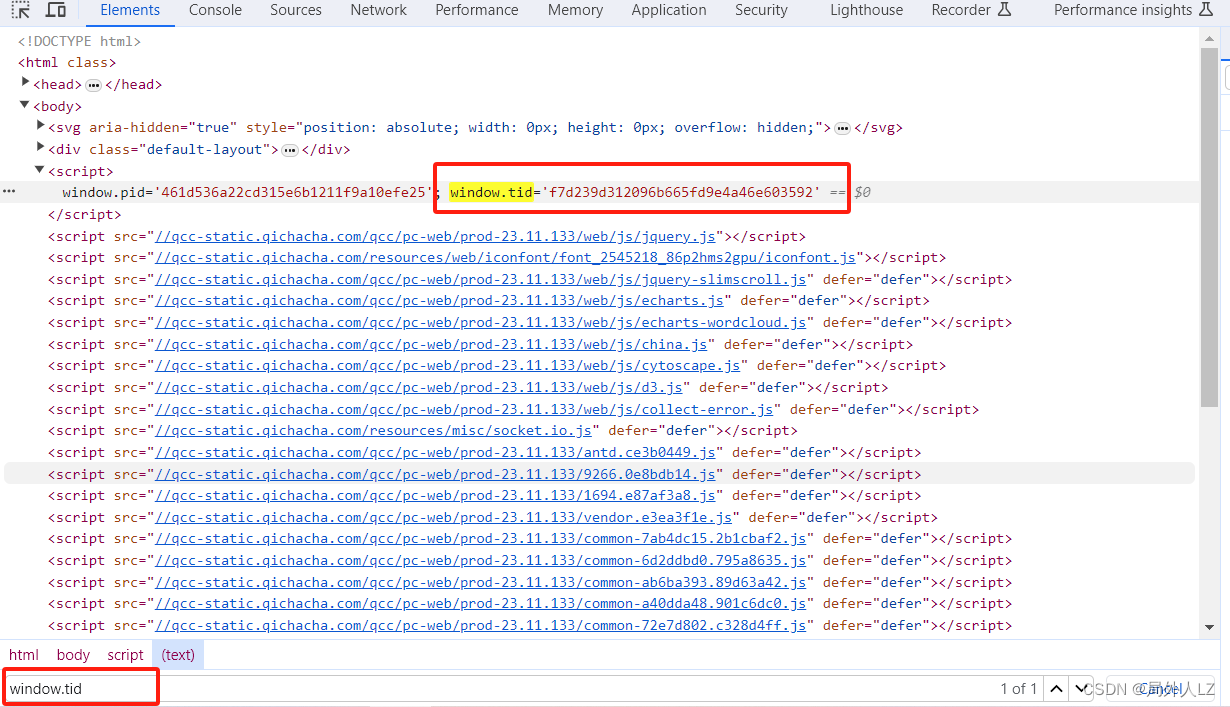
- 测试 s1 方法会发现,报 windows.tid 为 undefined的错误,切换到提示工具 Elements ,全局搜索 windows.tid 会发现该值是固定的值,把该值赋值下来替换 s1 并删除 s1


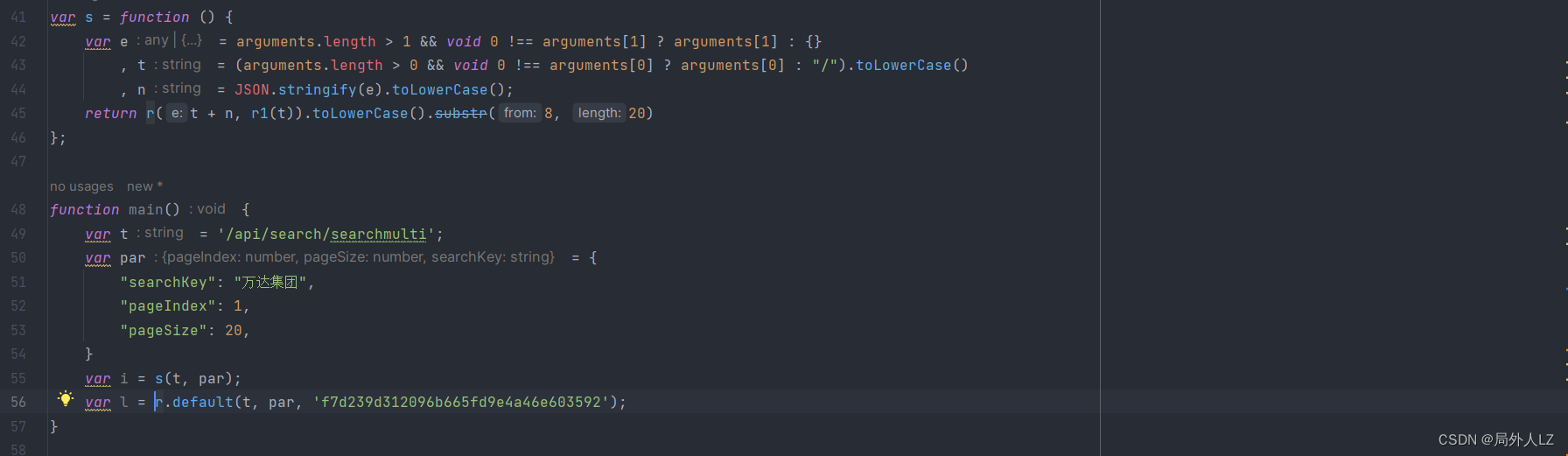
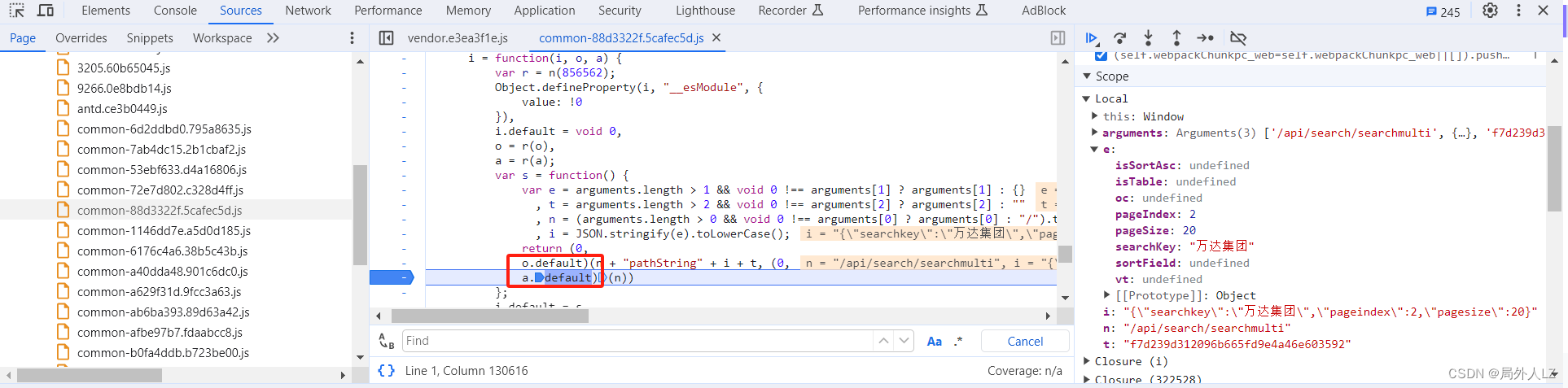
- 开始扣出 r.default 方法:鼠标悬浮到 r.defaul,点击蓝色部分找到该方法,会发现一个 s 方法,会发现只有 o.default、a.default是值得注意的方法,其他都是js语法,在方法内部打上断点,并把 s 方法扣到qichacha.js 命名为 s1,把 r.default 换成 s1
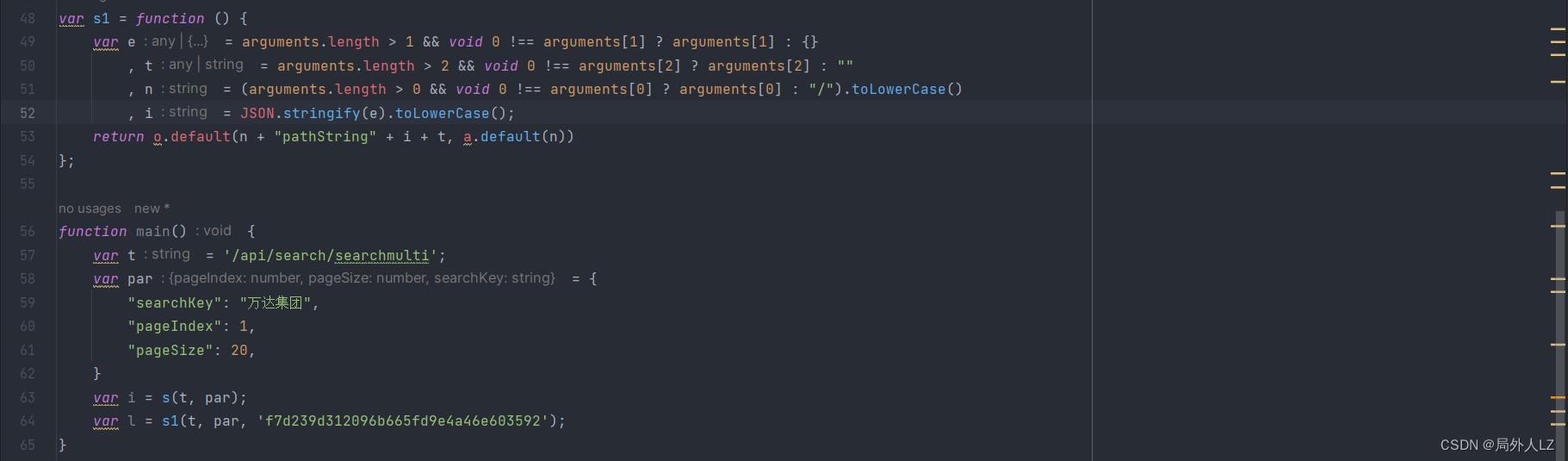
- 仔细分析 s1 会发现和之前的 s 方法类似,可以先试着,把 s1 方法中的 o.default、a.default 替换成之前的 r、r1

- 测试 s1 方法:把 n、i、(0,o.default)(n + “pathString” + i + t, (0,a.default)(n)) 输出控制台,把 n、i、tid值传给 s1 并打印出来,发现同样的参数,得到值一样,说明 s1 内部的 o.default、a.default 确实是 r、r1,结束断点调试
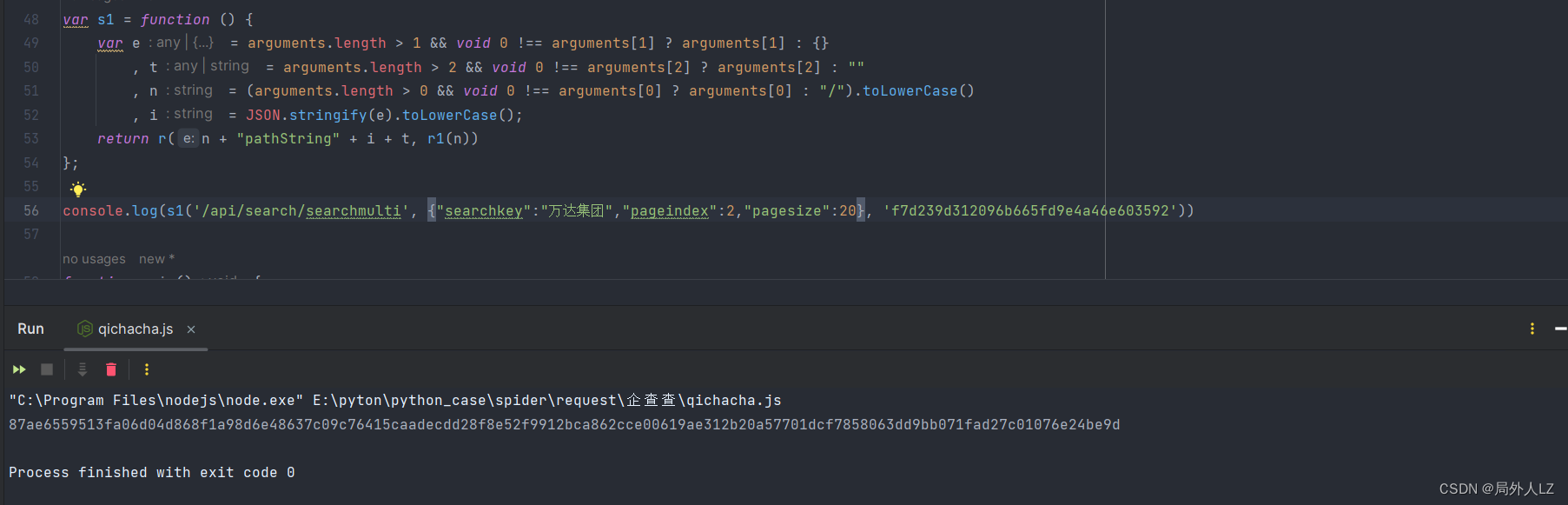
四、验证结果
- 修改qichacha.js,把 t、par作为参数传给 main 方法,并运行文件,打印出生成的 key、value
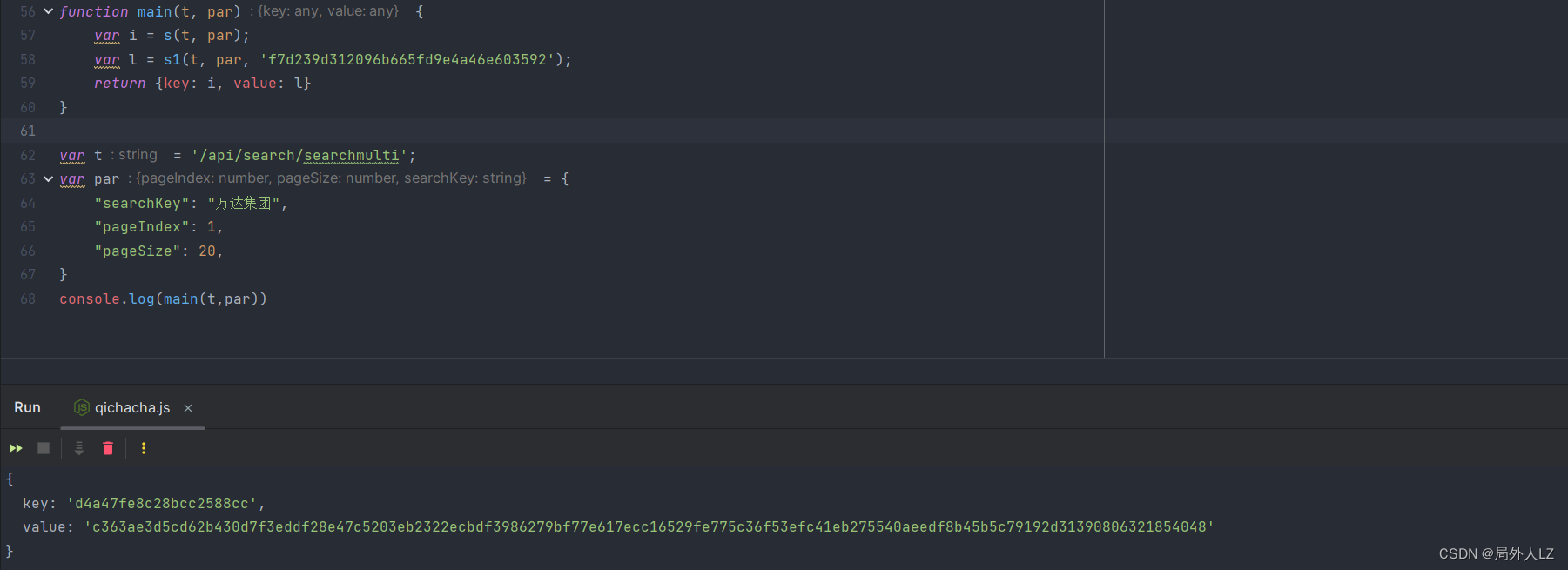
- 点击第一页重新请求,在控制台输出 i、l,对比发现值都是一样的

- 修改 qichacha.py 文件,运行文件,数据获取成功

五、最终代码
- qichacha.js
var cryptoJs = require('crypto-js')
var r = function (e, t) {
var hmacSha512 = cryptoJs.HmacSHA512(e, t);
return hmacSha512.toString()
};
var r1 = function () {
var o = {
"n": 20,
"codes": {
"0": "W",
"1": "l",
"2": "k",
"3": "B",
"4": "Q",
"5": "g",
"6": "f",
"7": "i",
"8": "i",
"9": "r",
"10": "v",
"11": "6",
"12": "A",
"13": "K",
"14": "N",
"15": "k",
"16": "4",
"17": "L",
"18": "1",
"19": "8"
}
};
for (var e = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase(), t = e + e, n = "", i = 0; i < t.length; ++i) {
var a = t[i].charCodeAt() % o.n;
n += o.codes[a]
}
return n
};
var s = function () {
var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}
, t = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase()
, n = JSON.stringify(e).toLowerCase();
return r(t + n, r1(t)).toLowerCase().substr(8, 20)
};
var s1 = function () {
var e = arguments.length > 1 && void 0 !== arguments[1] ? arguments[1] : {}
, t = arguments.length > 2 && void 0 !== arguments[2] ? arguments[2] : ""
, n = (arguments.length > 0 && void 0 !== arguments[0] ? arguments[0] : "/").toLowerCase()
, i = JSON.stringify(e).toLowerCase();
return r(n + "pathString" + i + t, r1(n))
};
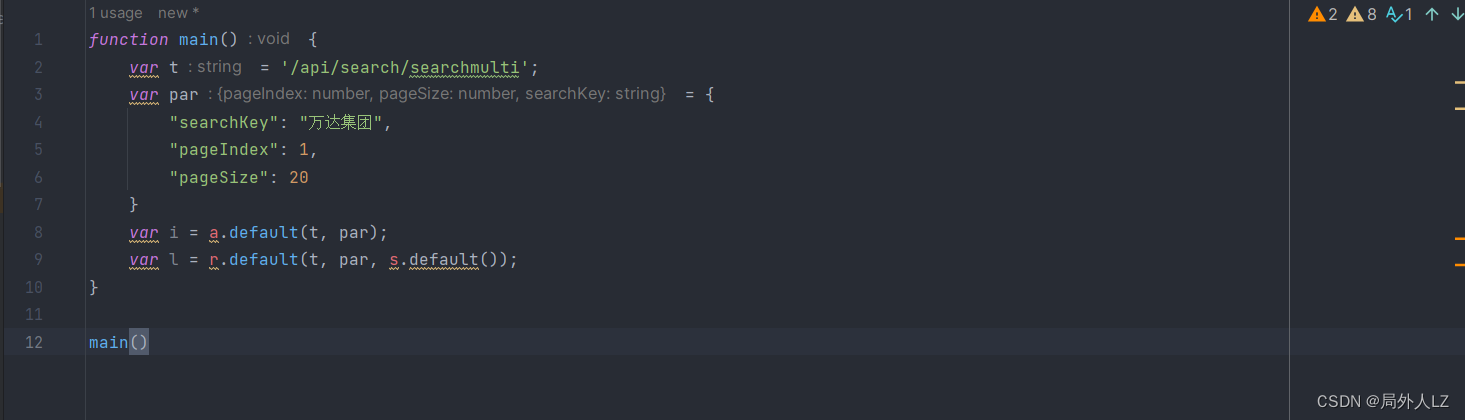
function main(t, par) {
var i = s(t, par);
var l = s1(t, par, 'f7d239d312096b665fd9e4a46e603592');
return {key: i, value: l}
}
var t = '/api/search/searchmulti';
var par = {
"searchKey": "万达集团",
"pageIndex": 1,
"pageSize": 20,
}
console.log(main(t,par))
- qichacha.py
import requests
import execjs
import furl
headers = {
"authority": "www.qcc.com",
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/json",
"origin": "https://www.qcc.com",
"pragma": "no-cache",
"referer": "https://www.qcc.com/web/search?key=^%^E4^%^B8^%^87^%^E8^%^BE^%^BE^%^E9^%^9B^%^86^%^E5^%^9B^%^A2",
"sec-ch-ua": "^\\^Google",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest",
"x-pid": "30ccc65659628b892fb5c1c99a083a95",
# "43d930d400d14394164a": "87ae6559513fa06d04d868f1a98d6e48637c09c76415caadecdd28f8e52f9912bca862cce00619ae312b20a57701dcf7858063dd9bb071fad27c01076e24be9d",
}
cookies = {
"QCCSESSID": "eaa3818b5a849d53ca70e37dac",
"qcc_did": "fe88cac5-6065-4d4d-bdc6-f642aea5386b"
}
url = "https://www.qcc.com/api/search/searchMulti"
data = {
"searchKey": "万达集团",
"pageIndex": 2,
"pageSize": 20
}
with open('qichacha.js','r') as js_file:
js = execjs.compile(js_file.read())
url_info = furl.furl(url)
get_headers = js.call('main',str(url_info.path),data)
headers[get_headers['key']] = get_headers['value']
print(headers)
response = requests.post(url, headers=headers, cookies=cookies, json=data)
print(response.text)
print(response)
















 539
539











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









