







InnoDB 引擎,每一个数据表有两个文件 .frm和.ibd,分别为表结构,数据和索引,数据挂在主索引的叶子节点上,此主索引称为聚簇索引。
MyISAM 引擎,每一个数据表有三个文件.frm和.MYI和.MYD,分别为表结构,索引,数据;也就是说其索引和数据是分开的,索引的叶子节点存储的不是数据而是磁盘地址,称为非聚簇索引。
下面只分析 InnoDB 引擎。
一、为什么是 B+Tree 而不是 B-Tree
B-Tree
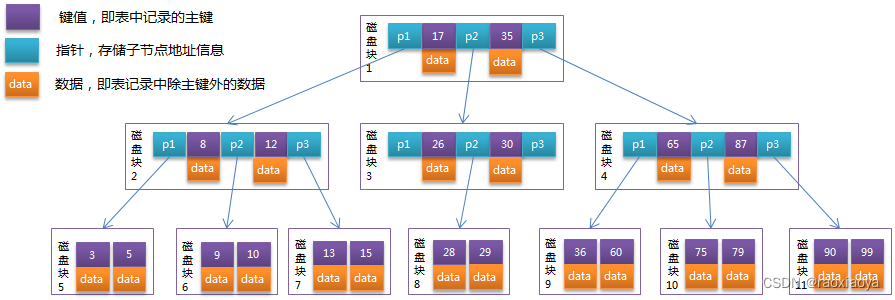
B+Tree
他两最大的区别就是 B+Tree 将data部分下沉到了最后一级,即叶子节点。
对于基于磁盘的存储,一般使用对磁盘的IO次数来评判索引结构的优劣,假设操作系统对磁盘的每次IO能读取 4K 数据(块),假设索引结构的每一个节点有16K的固定空间,这个16K称为页,索引以页作为最基本的管理单位,所以每一次读取要4次IO,从节省IO次数的角度讲,如果每个节点上如果能存储更多的key就能减少IO的次数,而B+Tree是将所有的data下放到叶子节点,其他节点全部用来存储key和指针,显然IO效率更高。
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。在B+Tree的每个叶子节点增加一个指向相邻叶子节点的指针,做这个优化的目的是为了提高区间访问的性能。也就是说,通过这个指针你可以访问到已经排序好的key的列表。
二、InnoDB 引擎读写磁盘的过程
我们经常听人说Mysql对磁盘的写操作是随机寻址的,所以需要WAL组件。但是为什么Mysql对磁盘的写操作是随机寻址的呢?这就需要了解它读写磁盘的过程。
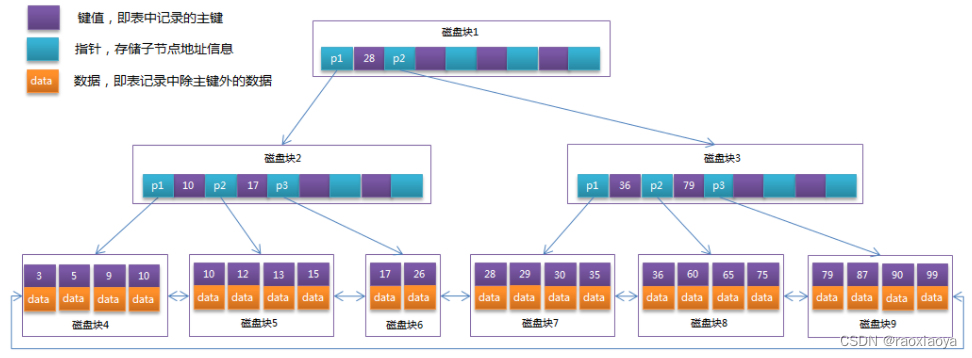
就以InnoDB引擎为例,其索引结构和源数据都存在.ibd文件里,文件是一块大的连续的磁盘空间,收到查询请求后引擎就去读取此文件的主索引,以页(16K)为单位读取,从B+Tree的根节点开始,当然有时候一个节点不止一页,如果没有找到这个key就要接着读,直到找到了data。
从根节点指向一级节点的时候,那么一级节点存在文件中的哪个位置呢,或者说即便你知道了它在文件中的位置,你要怎么读到它呢,我们可以使用相对于文件起始位置的偏移量来读取那一块的数据,或者计算出其在磁盘上的地址,然后直接读取磁盘,所以指向子节点使用的是指针,整个的读取过程是跳跃的随机的。
同样的,在写入的时候,要写入的目标磁盘块的位置也是跳跃的,所以说写操作是随机的寻址,它不是append模式。有时候在写入后现有节点还要调整。
说到底这些节点都还是存在于文件中,文件是一块大的连续的磁盘空间,所以这里的指针应该是相对于文件起始地址的相对地址,而不能是磁盘的绝对地址,否则你一移动文件那岂不都失效了。
在机械硬盘上面,这种随机寻址会严重影响磁盘的IO性能。
三、需要 WAL (Write-Ahead Logging)
既然直接落盘性能堪忧,那就改成异步落盘。基本上所有的数据库都使用WAL模式来解决这个问题,实现方式可能各有不同,但大致思路都是一样的。
一个修写入请求,先写入日志文件,成功之后才写入缓存,然后有后台程序将日志文件的内容落盘。
在写日志文件的时候,使用 append模式,这就是顺序写,要比随机写好很多。
redo log:保证数据一致性。如果Mysql宕机了,重启的时候可以将日志文件中未落盘的数据落盘。
undo log:保证事务的原子性,实现多版本并发控制(MVCC)。它相当于在修改之前做一下备份。
组提交机制:将多个小的事务合并成一组再执行落盘,可以大幅度降低磁盘的 IOPS 消耗。















 1693
1693











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









