







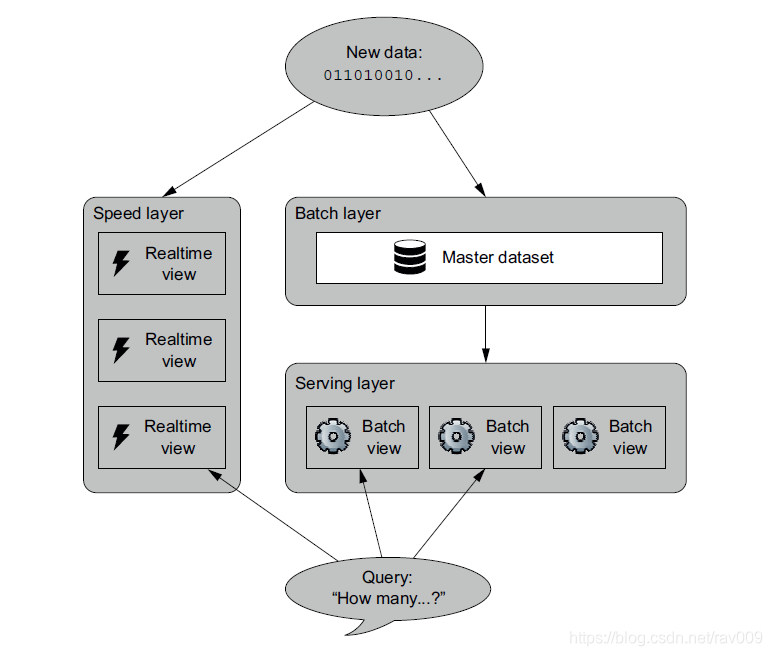
上图就是lambda结构的一个示意, 来自图书Big Data Principles and best practices of scalable realtime data system, 该书的作者就是lambda架构的创造者Nathan Marz。
大数据的技术手段百花齐放, 各种NoSQL数据库或者分布式计算框架层出不穷, 但是很少有理论来讲一讲应该怎么把这些组件有机地组合起来, lambda框架应运而生, 是一种理论指导大数据项目的顶层设计, 帮助企业以数据来驱动。
从业务的角度来思考对于数据的应用有不同的时效性要求, 有的数据比如 E-commerce ,时效性要求非常高, 有的数据比如客户画像分析 对时效性要求比较低. 道理很简单, 电商的促销推荐瞬息万变, 而客户的行为画像变得很慢(并不是每天都有人从工薪阶层变成百万富翁,从单身汉突然变成已婚人士)。
lambda架构从这点出发, 有两套解决办法, 正如图上的两条分支, 一条叫Speed Layer 顾名思义 快速的处理实时数据以供查询, 而另一条分支, 又分作两层(Batch Layer & Serving Layer) 处理那些对时效性要求不高的数据。
Speed Layer处理实时数据 代价是对计算资源要求很高, 而且逻辑复杂度也会很高, 通常采用的技术比如 Redis,Storm,Kafka,Spark Streaming等。而另外两层使用的典型技术比如MR或Spark,Hive。这条路线处理延迟比较大, 结果逻辑相对简单,往往把它的处理叫做“离线处理”, 与Speed Layer的“实时处理”相对应。这种设计被称作:Complexity Isolation(复杂度分离)。
两者其实是相辅相成的, Batch Layer会持续地吸收增量数据加以处理(比如渐变维度,增加索引,划分分区,预计算聚合值等操作), 当新增数据被Batch Layer处理完成后, 它们的分析就不再由Speed Layer处理了(交由Serving Layer处理),所以保证了Speed Layer处理的历史数据量永远不会太大,毕竟对于Speed Layer来说 “快” 是关键。
在另一些场景下, 比如在用户浏览购物网站时的推荐系统, 会结合实时分析结果和离线处理结果: 以电商为例, 用户给购物车加了一件商品,根据这个操作"实时处理"会向用户做出推荐(用户把一条裙子加入购物车,立刻推荐这条裙子的搭配商品比如一双鞋子),但同时也要结合用户历史的行为来做推荐(用户喜欢红色,脚的尺码M), 这依赖于离线处理的结果。两者结合(该鞋子的红色款且尺码M)就是最终用户在网页上看到的推荐商品列表。
以上就是Lambda框架的简介。


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











