







- 1、删除kubeflow后namespace无法删除
- 2、jupyter pod报错MountVolume.SetUp failed for volume
- 3、手动pull了镜像,并重新打了tag,但是一直提示无法pull镜像
- 4、某个pod状态一直是pending
- 5、Pod状态一直是CrashLoopBackOff
- 6、minio和mysql Pod一直是pending状态
- 7、删除pv,pv状态一直是terminating
- 8、a container name must be specified for
- 9、疑似有相同的pod
- 10、重新安装后,kubeflow相关的所有pod都查询不到
- 11、Mysql节点报错Operation not permitted
- 12、访问notebook提示错误
- 13、Katib-db pod不断重启
- 14、重装后katib-db pod一直是CrashLoopBackOff
- 15、重装后访问kubeflow,不显示创建namespace的界面
- 16、界面创建notebook的时候,一直创建中
1、删除kubeflow后namespace无法删除
问题
[root@ master kubeflow]# kfctl delete -f kfctl_k8s_istio.0.7.0.yaml
Error: couldn't delete KfApp: (kubeflow.error): Code 500 with message: kfApp Delete failed for kustomize: (kubeflow.error): Code 400 with message: couldn't delete namespace kubeflow Error: Operation cannot be fulfilled on namespaces "kubeflow": The system is ensuring all content is removed from this namespace. Upon completion, this namespace will automatically be purged by the system.
Usage:
kfctl delete [flags]
Flags:
--delete_storage Set if you want to delete app's storage cluster used for mlpipeline.
-f, --file string The local config file of KfDef.
-h, --help help for delete
-V, --verbose verbose output default is false
couldn't delete KfApp: (kubeflow.error): Code 500 with message: kfApp Delete failed for kustomize: (kubeflow.error): Code 400 with message: couldn't delete namespace kubeflow Error: Operation cannot be fulfilled on namespaces "kubeflow": The system is ensuring all content is removed from this namespace. Upon completion, this namespace will automatically be purged by the system.
解决
[root@master kubeflow]# kubectl get ns
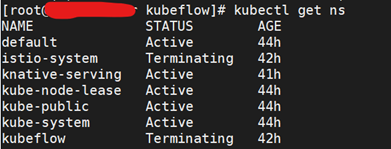
[root@ master kubeflow]#kubectl get namespace kubeflow -o json > tmp.json
删除tmp.json中的spec节点,k8s集群是携带认证的

新开一个窗口,手动kube-apiserver开代理端口
[root@ master kubeflow]#kubectl proxy --port=8080
[root@ master kubeflow]#curl -k -H "Content-Type: application/json" -X PUT --data-binary @tmp.json http://127.0.0.1:8080/api/v1/namespaces/kubeflow/finalize

再执行删除操作操作
[root@master kubeflow]# kfctl delete -f kfctl_k8s_istio.0.7.0.yaml

2、jupyter pod报错MountVolume.SetUp failed for volume
问题
Normal Scheduled 19m default-scheduler Successfully assigned kubeflow/jupyter-web-app-deployment-84
Warning FailedMount 19m kubelet, node1 MountVolume.SetUp failed for volume "config-volume" : couldntimed out waiting for the condition
Warning FailedMount 19m kubelet, node1 MountVolume.SetUp failed for volume "jupyter-web-app-serviceldn't propagate object cache: timed out waiting for the condition
Warning Failed 15m kubelet, node1 Failed to pull image "gcr.io/kubeflow-images-public/jupyter-: code = Unknown desc = Get https://gcr.io/v1/_ping: dial tcp xx.xx.xx.xx:443: i/o timeout
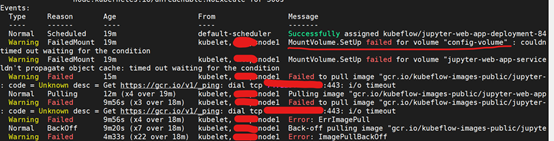
解决
查看pvc信息
[root@master kubeflow]#kubectl -n kubeflow get pvc

[root@master kubeflow]# kubectl describe pvc minio-pv-claim -n kubeflow

发现pv未创建
使用nfs作为文件服务。如果不熟nfs可以搜索网上资料。
for i in $(seq 1 4); do
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: PersistentVolume
metadata:
name: kubeflow-pv${i}
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
nfs:
server: 172.18.43.250
path: /ssd/nfs-data/kubeflow/kubeflow-pv${i}
EOF
done

3、手动pull了镜像,并重新打了tag,但是一直提示无法pull镜像
问题
[root@master kubeflow]# kubectl describe pod admission-webhook-bootstrap-stateful-set -n kubeflow

上图image,镜像的tag要和本地镜像一致,如果不一致,在这里修改。
比如有的pod pull镜像是docker pull gcr.azk8s.cn/kubeflow-images-public/notebook-controller@sha256:6490f737000bd1d2520ac4b8cbde2b09749cdb291b1967ddda95d05131db49db
那么在上图,要将@sha256:6490f737000bd1d2520ac4b8cbde2b09749cdb291b1967ddda95d05131db49db改成重新打的tag
怎么区分是statefulset还是deployment?
pod的name的后面如果是-0、-1、-2数字,那么就是statefulset,否则就是deployment
最准确的方式是通过查看kubectl describe pod {podname} -n {namespace}
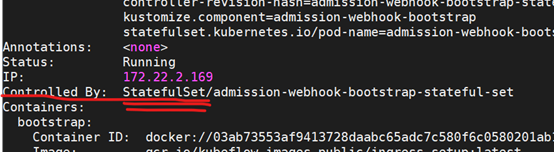
解决
imagePullPolicy策略是Always,要修改成IfNotPresent
修改镜像拉取策略
[root@master kubeflow]# kubectl edit statefulset admission-webhook-bootstrap-stateful-set -n kubeflow
[root@master kubeflow]# kubectl edit deployment admission-webhook-deployment -n kubeflow
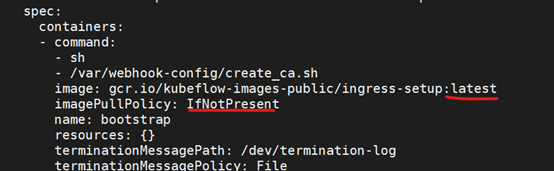
修改后重建pod。删除pod后会自动重建。
[root@master kubeflow]#kubectl delete pod admission-webhook-bootstrap-stateful-set-0 -n kubeflow
4、某个pod状态一直是pending
问题
[root@master ~]#kubectl get pods --all-namespaces
查看到某个pod状态一直是pending
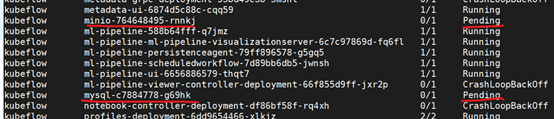
[root@master ~]# kubectl describe pod mysql-c7884778-g69hk -n kubeflow
Warning FailedScheduling 19s (x14 over 18m) default-scheduler 0/3 nodes are available: 1 node(s) had taints that the pod didn't tolerate, 2 node(s) didn't find available persistent volumes to bind.

直译意思是节点有了污点无法容忍
使用kubeadm搭建的集群默认就给 master 节点添加了一个污点标记,所以pod 都没有被调度到 master 上去
[root@master ~]#kubectl get no -o yaml | grep taint -A 5
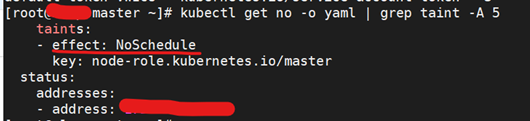
解决
[root@master ~]#kubectl describe node master(注:master node name)

允许master节点部署pod,使用命令如下:
[root@master ~]#kubectl taint nodes --all node-role.kubernetes.io/master-
输出如下:
node “k8s” untainted
如果输出error: taint “node-role.kubernetes.io/master:” not found 错误忽略
再describe一下

另:禁止master部署pod
[root@master ~]#kubectl taint nodes k8s node-role.kubernetes.io/master=true:NoSchedule
5、Pod状态一直是CrashLoopBackOff
问题
describe和log都没有发现pod有错误,但是pod一直是CrashLoopBackOff状态
解决
删除重建pod
[root@master ssd]# kubectl delete pod kfserving-controller-manager-0 -n kubeflow
6、minio和mysql Pod一直是pending状态
问题
[root@master pvc]# kubectl get pods --all-namespaces

查看pod信息,发现pvc没有绑定
[root@master ~]# kubectl -n kubeflow describe pod minio-764648495-s4wxn
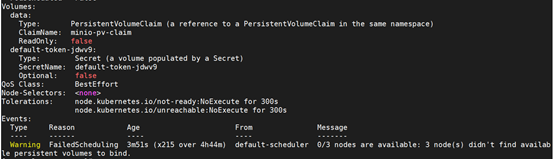
解决
[root@master pvc]# kubectl -n kubeflow get pvc
pvc一直pending状态

查看pvc描述
[root@master pvc]# kubectl get pvc minio-pv-claim -n kubeflow -o yaml

创建pv
[root@master pvc]# vi metadatapv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: metadata-pv
labels:
type: local
spec:
storageClassName: local
capacity:
storage: 25Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/ssd/nfs-data/kubeflow/metadata
创建nfs pv
apiVersion: v1
kind: PersistentVolume
metadata:
name: metadata-pv
spec:
capacity:
storage: 25Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.1.100
path: /ssd/nfs-data/kubeflow/metadata
再查看minio、mysql状态

7、删除pv,pv状态一直是terminating
问题
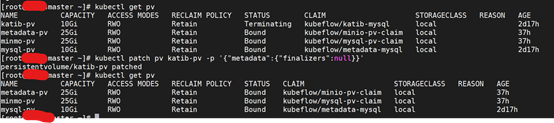
[root@master pvc]# kubectl -n kubeflow get pvc
[root@master pvc]# kubectl get pv
[root@master pvc]# kubectl delete pv katib-pv

解决
执行
[root@master pvc]# kubectl patch pv katib-pv -p '{"metadata":{"finalizers":null}}'
8、a container name must be specified for
问题
[root@master ~]# kubectl -n istio-system logs istio-policy-6f74d9d95d-6xq28
Error from server (BadRequest): a container name must be specified for pod istio-policy-6f74d9d95d-6xq28, choose one of: [mixer istio-proxy]
解决
一个pod有多个容器,命令要指定容器
[root@master ~]# kubectl -n istio-system logs istio-policy-6f74d9d95d-6xq28 -c mixer
9、疑似有相同的pod
问题
[root@master ~]# kubectl get pods --all-namespaces

解决
查看deploy
[root@master ~]# kubectl get deploy -n knative-serving
[root@master ~]# kubectl get rs -n knative-serving

删除多余的,把ImagePullBackOff的pod删除
遇到这种情况,先删除rs,再删除pod
[root@master ~]# kubectl delete rs activator-5484756f7b -n knative-serving
replicaset.extensions "activator-5484756f7b" deleted
10、重新安装后,kubeflow相关的所有pod都查询不到
问题
重新安装后,kubeflow相关的所有pod都查询不到,只能查询到rs、deploy、svc,但是rs、deploy状态都不对


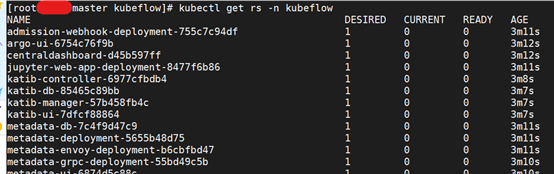
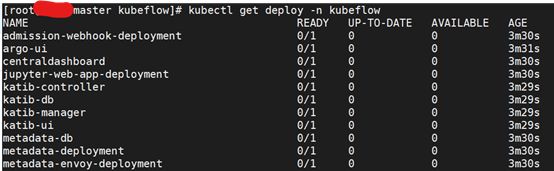
rs日志错误信息
[root@master kubeflow]# kubectl describe rs centraldashboard-d45b597ff -n kubeflow
Warning FailedCreate 60s (x16 over 5m15s) replicaset-controller Error creating: Internal error occurred: failed calling webhook "inferenceservice.kfserving-webhook-server.pod-mutator": Post https://kfserving-webhook-server-service.kubeflow.svc:443/mutate-pods?timeout=30s: service "kfserving-webhook-server-service" not found
原因:疑似与动态准入控制有关,还没有找到资料
解决
执行删除步骤之后,再执行如下命令
[root@master kubeflow]#kubectl get mutatingwebhookconfigurations
[root@master kubeflow]#kubectl delete mutatingwebhookconfigurations “资源名”
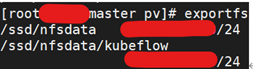
11、Mysql节点报错Operation not permitted
问题

Mysql要使用pv,pv挂载的目录是nfs目录,权限配置有问题,mysql无法修改目录权限
解决
报错的nfs的配置
解决问题的配置
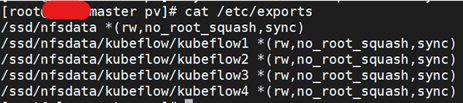
[root@master pv]# cat /etc/exports
/ssd/nfsdata *(rw,no_root_squash,sync)
/ssd/nfsdata/kubeflow/kubeflow1 *(rw,no_root_squash,sync)
/ssd/nfsdata/kubeflow/kubeflow2 *(rw,no_root_squash,sync)
/ssd/nfsdata/kubeflow/kubeflow3 *(rw,no_root_squash,sync)
/ssd/nfsdata/kubeflow/kubeflow4 *(rw,no_root_squash,sync)
使配置生效
[root@master pv]# exportfs -r
重启rpcbind、nfs服务
[root@master pv]# systemctl restart rpcbind && systemctl restart nfs
注:我使用nfs服务作为pv挂载目录,如果不是nfs服务,则是其他原因
12、访问notebook提示错误
问题
通过istio-ingressgateway访问Kubeflow Dashboard,进入notebook提示一个错误
No default Storage Class is set. Can’t create new Disks for the new Notebook. Please use an Existing Disk

原因是没有配置默认的StorageClass
解决
使用nfs作为provisioner,先安装插件
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-client-provisioner
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: nfs-provisioner
spec:
replicas: 1
strategy:
type: Recreate
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccount: nfs-client-provisioner
containers:
- name: nfs-provisioner
image: registry.cn-hangzhou.aliyuncs.com/open-ali/nfs-client-provisioner
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: kubeflow/nfs
- name: NFS_SERVER
value: 172.18.43.250
- name: NFS_PATH
value: /ssd/nfsdata/kubeflow/defstor
volumes:
- name: nfs-client-root
nfs:
server: 172.18.43.250
path: /ssd/nfsdata/kubeflow/defstor
集群使用了rbac,则需要创建。注意,这里的namespace如果不存在,要先创建
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: run-nfs-client-provisioner
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: kubeflow-anonymous
roleRef:
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: nfs-client-provisioner-runner
rules:
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
创建StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: kubeflow-nfs-storage
provisioner: kubeflow/nfs
将新创建的StorageClass设为默认
[root@master pv]# kubectl patch storageclass kubeflow-nfs-storage -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
再次进入notebook不报错了
13、Katib-db pod不断重启
问题
查看日志
[root@master pv]# Kubectl logs katib-db-76c4bd88b-x9cks -n kubeflow
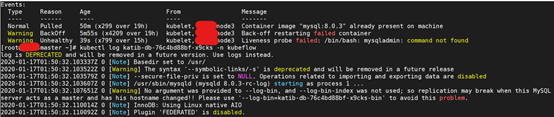
查看pod描述
[root@master pv]# Kubectl describe pod katib-db-76c4bd88b-x9cks -n kubeflow

katib-db pod的健康探测机制,执行mysqladmin一直失败
进入pod容器,查找mysqladmin,发现确实没有mysqladmin
[root@node3 ~]# kubectl exec -it katib-db-76c4bd88b-x9cks -n kubeflow bash

解决
1、 如果确定pod启动没有问题,可以去掉健康探测机制
查询
[root@master pv]# kubectl get deploy katib-db -n kubeflow -o yaml

编辑去掉livenessProbe
[root@master pv]# kubectl edit deploy katib-db -n kubeflow -o yaml
2、 换个有mysqladmin的镜像
14、重装后katib-db pod一直是CrashLoopBackOff
问题
重装后katib-db pod一直是CrashLoopBackOff,logs看了一下pod日志,报错如下
2020-02-12T01:09:10.520333Z 1 [Note] InnoDB: Completed initialization of buffer pool
2020-02-12T01:09:10.521524Z 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().
2020-02-12T01:09:10.537059Z 1 [ERROR] InnoDB: Unsupported redo log format. The redo log was created with MySQL 8.0.19. Please follow the instructions at http://dev.mysql.com/doc/refman/8.0/en/upgrading-downgrading.html
2020-02-12T01:09:10.537081Z 1 [ERROR] InnoDB: Plugin initialization aborted with error Generic error
2020-02-12T01:09:11.137510Z 1 [ERROR] Failed to initialize DD Storage Engine
2020-02-12T01:09:11.137679Z 0 [ERROR] Data Dictionary initialization failed.
原因是pv目录旧文件导致mysql重做日志格式失败
解决
进入pv目录,清理所有文件
删除所有旧文件和目录

Delete pod重建



15、重装后访问kubeflow,不显示创建namespace的界面
问题


原因是缺少profile配置文件
官方文档多租户指导
https://www.kubeflow.org/docs/other-guides/multi-user-overview/#current-integration-and-limitations
解决
创建profile
[root@master defstor]# kubectl create -f fish.yaml
apiVersion: kubeflow.org/v1beta1
kind: Profile
metadata:
name: fish # replace with the name of profile you want
spec:
owner:
kind: User
name: fish@fish.com # replace with the email of the user
16、界面创建notebook的时候,一直创建中
问题
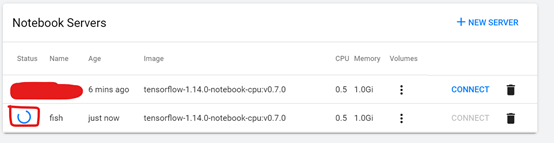
原因是pv没有创建

[root@master defstor]# kubectl describe pod fish-0 -n namespace


解决
创建workspace和Volume使用的pv
[root@master defstor]# kubectl create -f workspace-pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: workspace-fish
namespace: fish
spec:
storageClassName: kubeflow-nfs-storage
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.1.100
path: /ssd/nfsdata/k8s/defstor
[root@master defstor]# kubectl create -f vol-pv.yaml
kind: PersistentVolume
apiVersion: v1
metadata:
name: fish-vol-1
namespace: fish
spec:
storageClassName: kubeflow-nfs-storage
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
nfs:
server: 192.168.1.100
path: /ssd/nfsdata/k8s/defstor















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









