






我们是某电商平台类企业,公司会在我们平台根据需求注册若干个供应商账号(Vendor Code)。最近获取到了一个业务部门的需求,是根据供应商公司在平台的若干个账号中,选取GMS最大的一个进行发送邮件的task。
本来感觉挺简单的,根据公司进行开窗函数,取编号为1的Vendor。可是业务部门根据SQL结果发信后发现,有些明显的GMS很大的供应商没发到邮件,中间过程检查了很多,最后定位在了最后的排序那里。
原来AWS Redshift和常用的MySQL在开窗函数上是有不同的,这里我简单举了一个例子供大家引以为鉴:
SQL脚本(不用做任何调整,Redshift和MySQL均支持这条简单的查询语句):
with tmp as (
select 'a' as com, 100 as money
union all
select 'a' as com, 200 as money
union all
select 'a' as com, 300 as money
union all
select 'a' as com, null as money
)
select com, money, row_number() over(partition by com order by money desc) as rk from tmp
结果展示:
1、MySQL:
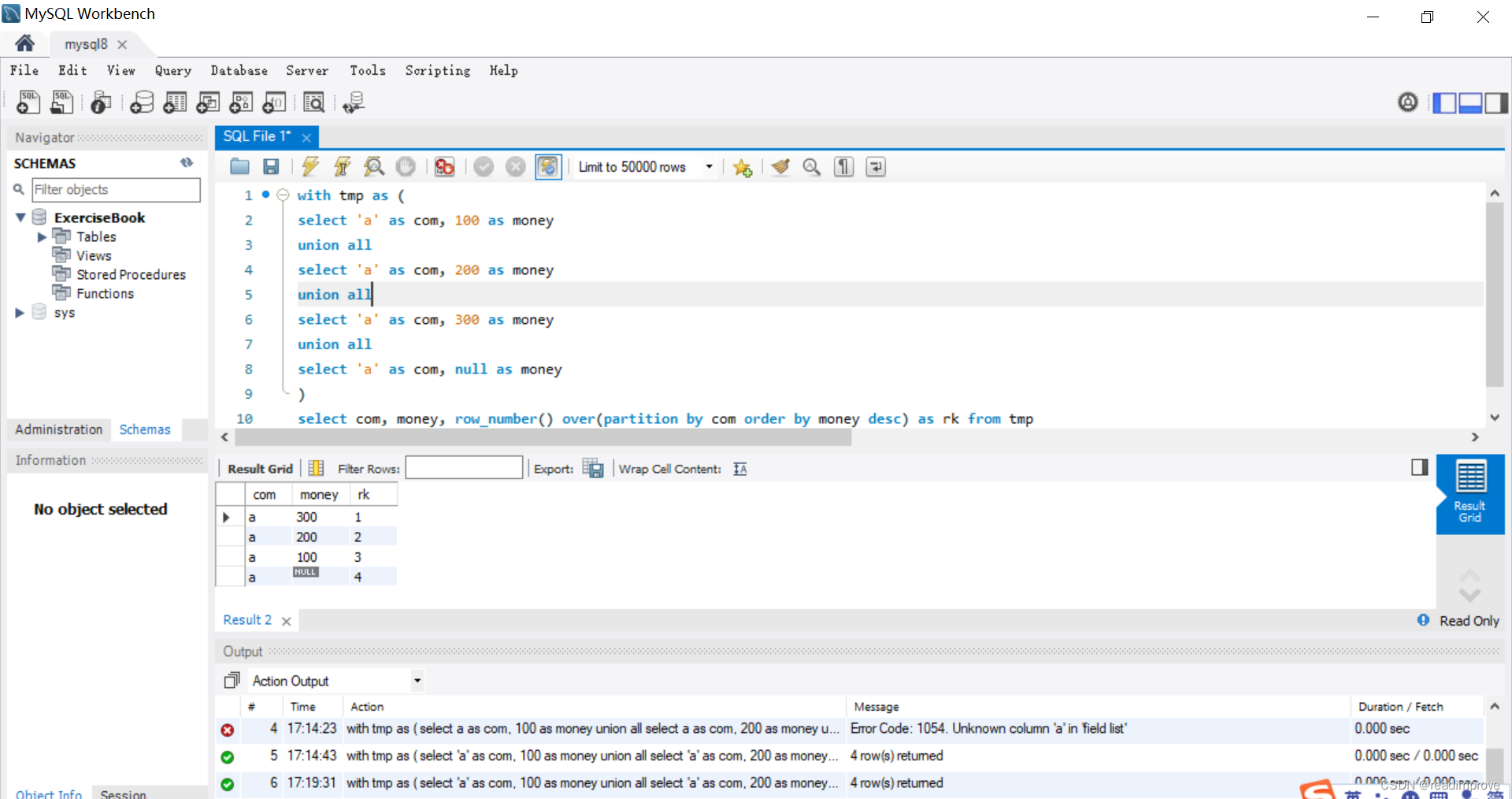
2、Redshift:
结果分析:
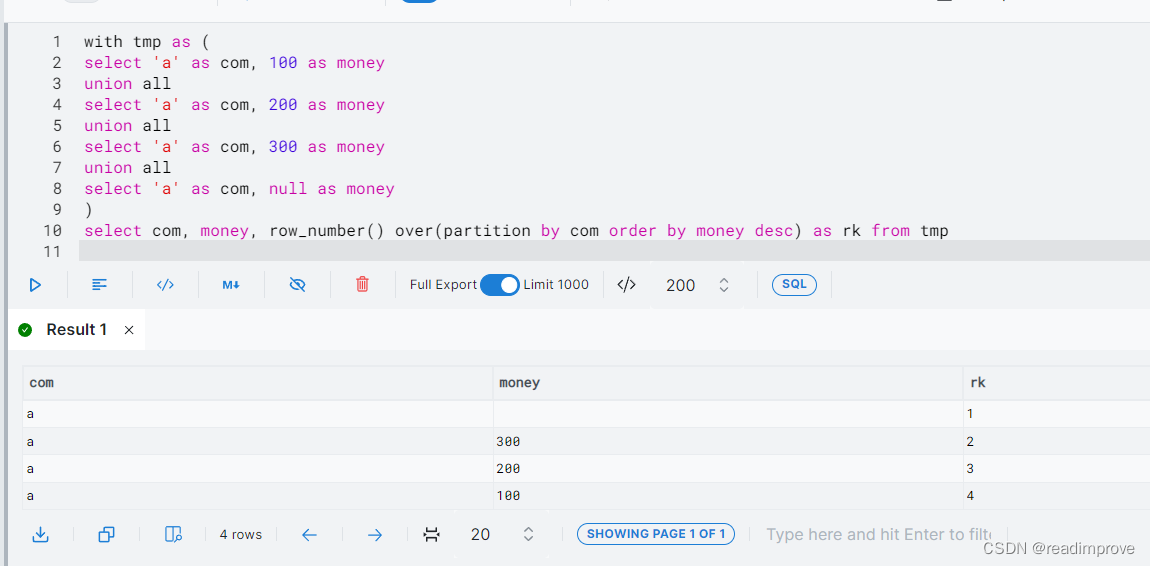
从上面的截图可以看到,在开窗操作(row_number())时,MySQL将null值往后面放;然而Redshift是将null值往前放的,要得出有意义的排序,就需要将Redshift为null的值手动匹配成0,然后参与排序,这样才是我们要的操作。















 421
421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









