







本文是对之前的五篇文章的汇总和优化。
一、安装 JDK
1. 解压安装包
- 将JDK 安装包解压并移动到 /usr/local/src 路径。
tar -zxvf jdk-8u162-linux-x64.tar.gz
mv jdk1.8.0_162 /usr/local/src
2. 配置环境变量
- 只对 root 用户生效。如果要设置全局变量则修改 /etc/profile 文件
- 修改 /root/.bash_profile 文件,设置 JDK 环境变量。
vi /root/.bash_profile
在文末追加以下文字:
# set java environment
export JAVA_HOME=/usr/local/src/jdk1.8.0_162
export PATH=$PATH:$JAVA_HOME/bin:$JAVA_HOME/jre/bin
- 让环境变量生效
source /root/.bash_profile
- 分别执行 “java” 和 “javac” 命令。如果有输出就说明 JDK 安装完成。
java
javac
二、重命名节点
1. 添加主机名和 ip 映射
- 修改 /etc/hosts 文件,添加主机名和 ip 的映射
vi /etc/hosts
在文末追加以下文字:
# 主机IP地址 映射
192.168.1.101 master # 主节点
192.168.1.102 slave1 # 子结点
192.168.1.103 slave2 # 子结点
- 要给所有节点配置映射
scp /etc/hosts root@slave1:/etc/
scp /etc/hosts root@slave2:/etc/
2. 配置无密码登录
- master生成密钥
ssh-keygen -t rsa
- 将master的公钥拷贝到其他机器
ssh-copy-id master # 这里就用到了上面的ip映射
ssh-copy-id slave1
ssh-copy-id slave2
- 所有节点都要配置到其他节点的免密登录,包括节点本身
master 免密登录到 master、slave1、slave2 …
slave1 免密登录到 master、slave1、slave2 …
slave2 免密登录到 master、slave1、slave2 …
…
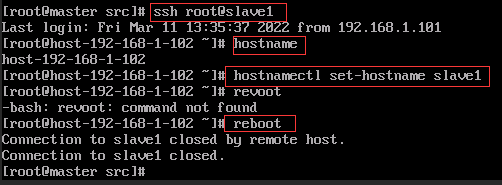
3. 重命名
- 将三个节点分别命名为 master、slave1、slave2。
hostname # 查看本机的用户名
hostnamectl set-hostname master
reboot
- 登录 slave1 和 slave2,修改他们的用户名。
ssh root@slave1 # 如果没有配置上面的免密登录,那么每次都要输入一次密码
hostname
hostnamectl set-hostname slave1
reboot
ssh root@slave2
hostname
hostnamectl set-hostname slave2
reboot
三、给节点配置 JDK
1. 传输文件
- 用 scp 把 JDK 环境变量文件以及 JDK 解压后的安装文
件到 slave1、slave2 节点。 - 如果不知道怎么使用 scp,转到 Linux 之间传输文件。
scp -r /usr/local/src/jdk1.8.0_162 root@slave1:/usr/local/src/
scp -r /usr/local/src/jdk1.8.0_162 root@slave2:/usr/local/src/
scp /root/.bash_profile root@slave1:/root/
scp /root/.bash_profile root@slave2:/root/
2. 验证
登录 slave1、slave2 节点,分别执行 “java” 和 “javac” 命令,验证 JDK 是否安装完成。如果没有输出就执行 source /root/.bash_profile
四、全分布式 Hadoop 安装
1. 解压安装包
- 将 Hadoop 安装包解压并移动到 /usr/local/src 路径。
tar -zxvf hadoop-2.7.7.tar.gz
mv hadoop-2.7.7 /usr/local/src
2. 配置环境变量
- 修改 /root/.bash_profile 文件,设置 Hadoop 环境变量。
vi /root/.bash_profile
在文末追加以下文字:
# set hadoop environment
export HADOOP_HOME=/usr/local/src/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 让环境变量生效
source /root/.bash_profile
- 执行 “hadoop” 命令。如果有输出就说明 Hadoop 安装完成。

3. 配置 hadoop-env.sh 和 yarn-env.sh 文件
- 所有配置文件都在 /hadoop-2.7.7/etc/hadoop/ 文件夹下。(/hadoop-2.7.7 是我的 Hadoop 安装目录,详细路径是 /usr/local/src/hadoop-2.7.7)

cd /usr/local/src/hadoop-2.7.7/etc/hadoop/
vi hadoop-env.sh
# 修改完 hadoop-env.sh 后再修改 yarn-env.sh,添加的内容一样
在文末追加以下文字:
export JAVA_HOME=/usr/local/src/jdk1.8.0_162
4. 配置 core-site.xml 文件
- 先在 Hadoop 安装路径新建 hdfs 文件夹,再在 hdfs 文件夹下新建 tmp、name、data。
cd /usr/local/src/hadoop-2.7.7
mkdir hdfs
cd hdfs
mkdir tmp
mkdir name
mkdir data
- 修改 Hadoop 核心配置文件 core-site.xml,这里配置的是 HDFS 的地址和端口号。
cd /usr/local/src/hadoop-2.7.7/etc/hadoop
vi core-site.xml
在文末追加以下文字:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop-2.7.7/tmp</value>
</property>
<property>
<name>fs.default.name</name>
<!--这是 master 的 ip-->
<value>hdfs://master:9000</value>
</property>
</configuration>
备注: 如没有配置hadoop.tmp.dir参数,此时系统默认的临时目录为:/tmp/hadoo-hadoop。而这个目录在每次重启后都会被干掉,必须重新执行format才行,否则会出错。
5. 配置 hdfs-site.xml文件
vi hdfs-site.xml
- 修改Hadoop中HDFS的配置,replication 是数据副本数量,默认为3,slave少于3台就会报错(副本数量需要小于等于slave数)。自己练习只设置1个副本就可以了。我这里根据要求设置为3。
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/home/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdfs/data</value>
</property>
</configuration>
6. 配置 mapred-site.xml 文件
- 只有 mapred-site.xml.template 文件, 则先在 mapred-site.xml.template 中写配置,然后再复制一份,并命名为mapred.xml。
vi mapred-site.xml.template
在文末追加以下文字:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
复制一份
cp mapred-site.xml.template mapred-site.xml
7. 配置 yarn-site.xml 文件
vi yarn-site.xml
在文末追加以下文字:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
8. 修改 slaves 文件
vi slaves
去掉里边的 localhost,添加集群中的所有结点。
master
slave1
slave2

五、给节点配置 Hadoop
1. 传输文件
-
将修改好的 Hadoop上传到节点中。
-
如果不知道怎么使用 scp,转到 Linux 之间传输文件。
scp -r /usr/local/src/hadoop-2.7.7/ root@slave1:/usr/local/src/
scp -r /usr/local/src/hadoop-2.7.7/ root@slave2:/usr/local/src/
scp /root/.bash_profile root@slave1:/root
scp /root/.bash_profile root@slave2:/root
2. 验证
登录 slave1、slave2 节点,执行 hadoop 命令,验证 Hadoop 是否安装完成。如果没有输出就执行 source /root/.bash_profile
六、启动及验证 Hadoop
1. 格式化HDFS文件系统
切换到 master。
hadoop namenode -format

输出比较多,大致是这样的。
2. 启动 Hadoop
start-all.sh
输出的结果:

可以看出,首先启动 namenode 接着启动datanode1,datanode2,…,然后启动secondarynamenode。再启动 yarn,然后启动 nodemanager1,nodemanager2,…。
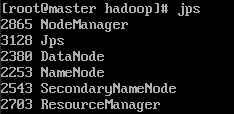
3. 验证hadoop
在Master上用 java自带的小工具 jps 查看进程。
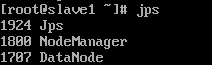
在Slave上用jps查看进程。
4. 网页查看集群
- 如果访问不了就关闭防火墙。
systemctl stop firewalld
-
查看hdfs集群状态,也就是namenode的访问地址,默认访问地址:http://namenode的ip:50070

-
查看secondary namenode的集群状态,默认访问地址:http://namenode的ip:50090

















 3373
3373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











