










Revisiting adapters with adversarial training
1. 引言
在当今深度学习的研究领域,对抗性训练已成为一种广泛使用的防御机制,用以增强深度网络对微小干扰的鲁棒性。这些被称为对抗性扰动的干扰,通过向输入数据中添加几乎无法察觉的噪声,使得深度网络产生高置信度的错误预测。众多研究工作致力于构建对这类扰动的防御手段,其中最常见的方法是对抗性训练。这种训练方法由Madry等人于2018年提出,并随后经过多种变体的发展(如Zhang等人、Pang等人、Huang等人在2019和2020年的工作)。
然而,早期的研究发现,使用对抗性样本进行训练可能会降低模型在无扰动情况下的性能。2019年的AdvProp研究挑战了这一观点,证明了对抗性训练不仅可以作为防御机制,还可以作为正则化手段,从而在使用双批量归一化(BatchNorm)层时提高了对干净数据的分类精度。
在这篇论文中,我们进一步探讨了对抗性训练与适配器的结合。我们发现,与之前的研究相反,在对干净和对抗性输入共同训练时,并不需要分离批量统计数据。事实上,使用为每种类型的输入设计的少量领域特定参数的适配器就足够了。我们展示了如何使用视觉Transformer(Vision Transformer, VIT)的分类标记作为适配器(见下图),这种方法不仅在分类性能上与双归一化层相匹敌,而且还使用了更少的附加参数。
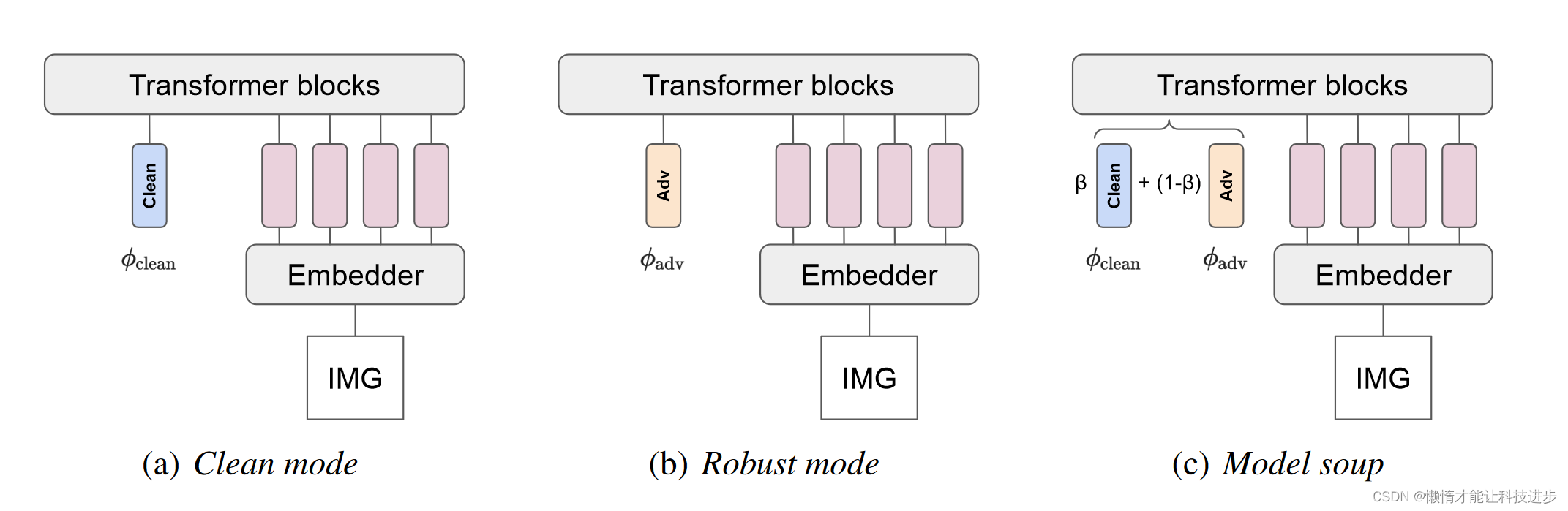
图1
本研究的主要贡献有两点:
1.改善了未经对抗性训练的VIT-B16模型在ImageNet上的top-1准确率,提高了1.12%,达到了83.76%。更重要的是,展示了通过适配器(adapters)的训练使模型能够通过干净和对抗性标记的线性组合来交换不同模式,这种方法被称为对抗性模型汤(model soups)。这些对抗性模型汤使我们能够在不牺牲效率的情况下在干净和鲁棒的准确率之间进行权衡。
2.我们展示了如何轻松地调整所得模型以应对分布变化,我们的VIT-B16在ImageNet的变体上平均比使用掩码自编码器(Masked Autoencoders)获得的top-1准确率高出4.00%。
2.主要概念解释
适配器(Adapters)
在深度学习模型中,适配器是一种结构,允许单个主干网络(backbone network)在多个任务或数据集上进行训练,同时保持大部分参数共享。适配器通过为每种类型的输入设计少量特定于领域的参数,从而实现高效的训练和推理。
适配器(Adapters)是一种在深度学习领域中使用的结构,特别是在迁移学习和多任务学习的场景中。其核心思想是在一个已经训练好的主干网络(例如一个大型的卷积神经网络或Transformer模型)中插入额外的小型网络层,从而在不显著改变原有网络架构的情况下,适应新的任务或数据集。
工作原理
-
主干网络共享:在适配器模式下,主干网络的权重在所有任务或数据集之间是共享的。这意味着,无论是处理新的任务还是新的数据集,主干网络都保持不变。
-
任务/数据集特定的适配器:对于每个新任务或数据集,会插入一个或多个专门设计的适配器。这些适配器通常是小型的神经网络层,只在特定任务或数据集上训练,而不影响主干网络的其他部分。
-
参数效率:适配器的关键优势之一是参数效率。由于主干网络在各任务之间共享,只有相对较小的适配器层需要针对新任务进行训练,大幅减少了所需训练参数的数量。
-
快速适应新任务:由于只有适配器层需要针对新任务进行调整,因此可以快速地适应新任务,尤其是在数据量有限的情况下。
举例说明
假设有一个用于图像识别的深度学习模型,该模型已在大规模数据集(如ImageNet)上进行了训练。现在,我们想使用这个模型来解决一个新的任务,比如医学图像的分类。直接在新任务上重新训练整个模型既耗时又计算昂贵。相反,我们可以在原有模型中插入适配器层,专门针对医学图像数据进行训练。
在这种情况下,适配器可以是一些额外的卷积层或全连接层,它们被插入到原有网络的特定层之间。这些适配器层仅使用医学图像数据进行训练,调整它们的权重以更好地处理此类图像,而不需要重新训练整个网络。通过这种方式,模型能够有效地适应新任务,同时保持在原始任务上的高性能。
其它:
对抗性训练(Adversarial Training):这是一种训练深度学习模型的方法,旨在提高模型对添加到输入数据中的小幅度扰动(即对抗性扰动)的鲁棒性。通过在训练过程中使用对抗性样本,模型学习识别并正确处理这些扰动,从而提高其在实际应用中的鲁棒性。
投影梯度下降(Projected Gradient Descent, PGD):PGD是一种优化算法,用于生成对抗性扰动。它通过迭代地调整输入数据,以最大程度地增加深度网络的输出误差,同时保持扰动在一定的范围内,确保其不易被察觉。
Vision Transformer (VIT):VIT是一种基于Transformer架构的深度学习模型,主要用于图像处理任务。它采用了Transformer中的自注意力机制来处理图像数据,提供了一种与传统卷积神经网络不同的图像理解方式。
Embedder:在深度学习模型中,embedder是一种用于将输入数据转换成适合模型处理的格式的组件。在图像处理任务中,它通常指的是将原始图像数据转换为一系列可供模型处理的特征向量的部分。
β参数(Beta Parameter):在本文的上下文中,β参数可能指的是用于调整模型在不同数据分布(如干净数据和对抗性数据)之间的权重的参数。这种调整有助于在保持模型性能的同时提高其对不同类型输入的适应性。
3. 研究方法
3.1 共同训练:标准与对抗性训练
Goodfellow等人在2015年提出的对抗性训练被用作标准训练的正则化方式。这一方法涉及在干净和对抗性图像上共同优化模型参数θ,使用以下共同训练损失函数:
α
L
(
f
(
x
;
θ
)
,
y
)
+
(
1
−
α
)
max
L
(
f
(
x
+
δ
;
θ
)
,
y
)
δ
∈
S
\alpha L(f(x; \theta), y) + (1 - \alpha) \max L(f(x + \delta; \theta), y) δ∈S
αL(f(x;θ),y)+(1−α)maxL(f(x+δ;θ),y)δ∈S
其中,x和y是从训练数据集中抽取的样本和标签对,
f
(
⋅
;
θ
)
f(·; θ)
f(⋅;θ)是由θ参数化的模型,L定义了损失函数(例如分类中的交叉熵损失),S是允许的扰动集合。将α设置为1相当于在干净图像上进行标准训练,而将α设置为0则转换为Madry等人在2018年定义的对抗性训练。在本研究中,考虑的是
ℓ
∞
ℓ∞
ℓ∞范数限制的扰动大小ϵ = 4/255。
3.2 分离批量统计数据非必需
BatchNorm是一种广泛使用的标准化层,已被证明可以提高图像分类器的性能和训练稳定性。批量归一化是一种在训练深度神经网络时常用的技术,它通过标准化每个小批量数据来减少内部协变量偏移(internal covariate shift)。具体来说,它会对每个小批量数据进行以下操作:
- 归一化:计算批量数据的均值和标准差,并使用这些统计数据对数据进行归一化,使其均值为0,标准差为1。
- 缩放和偏移:接着对归一化后的数据应用可学习的比例(scale)和偏移(offset)参数,以恢复网络所需的表示能力。
本研究指出,尽管Xie等人在2019年提出的AdvProp方法中使用了针对干净和对抗性图像不同的BatchNorm层,但我们发现并不一定需要分离这些批量统计数据。实验表明,使用具有特定于领域的比例和偏移参数的单一批量统计集合也能够达到类似于AdvProp的标准和鲁棒分类结果。
在具有特定于领域的比例和偏移参数的设置中,所有的输入数据(无论是干净图像还是对抗性图像)都使用相同的均值和标准差进行归一化,但是每种类型的数据都有自己独特的比例和偏移参数。这意味着虽然所有数据都通过相同的统计数据进行标准化,但它们在经过BatchNorm层后的表现形式会因为不同的比例和偏移参数而有所区别,从而允许模型更有效地处理来自不同领域的数据。
此方法与AdvProp方法中使用的不同之处在于,AdvProp为每种类型的数据(干净和对抗性)使用不同的批量统计数据,而不是仅使用不同的比例和偏移参数。通过这种方式,可以在不牺牲对干净图像和对抗性图像的处理能力的情况下,简化模型的结构和训练过程。
3.3 重新审视对抗性训练中的适配器
这一研究部分关注于探索不同于仅分离标准化层的适配器。在这里,干净图像和对抗性图像被视为两个不同的领域。模型参数θ可以被分解为在各个领域之间共享的参数ψ和特定于某个领域的参数ϕ。例如,在使用双LayerNorm层的情况下,这些标准化层的比例和偏移包含在ϕ_clean和ϕ_adv中,而模型的其余参数位于ψ中。基于方程1,我们优化以下损失函数:
α
L
(
f
(
x
;
ψ
∪
ϕ
c
l
e
a
n
)
,
y
)
+
(
1
−
α
)
max
L
(
f
(
x
+
δ
;
ψ
∪
ϕ
a
d
v
)
,
y
)
δ
∈
S
\alpha L(f(x; \psi \cup \phi_{clean}), y) + (1 - \alpha) \max L(f(x + \delta; \psi \cup \phi_{adv}), y) δ∈S
αL(f(x;ψ∪ϕclean),y)+(1−α)maxL(f(x+δ;ψ∪ϕadv),y)δ∈S
这个公式是用于共同训练干净数据和对抗性数据的损失函数。这里的
α
\alpha
α是一个权衡参数,它决定了在训练过程中干净数据和对抗性数据各自的重要性。
-
L ( f ( x ; ψ ∪ ϕ c l e a n ) , y ) L(f(x; \psi \cup \phi_{clean}), y) L(f(x;ψ∪ϕclean),y) 是对干净数据 ( x ) 的预测和真实标签 ( y ) 之间的损失函数。这里,( f ) 是模型, ψ \psi ψ是在所有领域(干净和对抗性)之间共享的参数,而 ϕ c l e a n \phi_{clean} ϕclean是仅用于干净数据的适配器参数。
-
max L ( f ( x + δ ; ψ ∪ ϕ a d v ) , y ) \max L(f(x + \delta; \psi \cup \phi_{adv}), y) maxL(f(x+δ;ψ∪ϕadv),y)是对添加了对抗性扰动 δ \delta δ 的数据 ( x ) 的预测和真实标签 ( y ) 之间的损失函数。这里, δ \delta δ 是对抗性扰动,它在集合 ( S ) 中取值,( S ) 定义了允许的扰动范围。 ϕ a d v \phi_{adv} ϕadv 是仅用于对抗性数据的适配器参数。
整个损失函数是这两部分的加权和。当 α \alpha α接近1时,模型主要优化对干净数据的性能;当 α \alpha α 接近0时,模型更重视对抗性数据的性能。这种训练方法旨在提高模型在面对干净和对抗性攻击时的总体性能。
此外,我们还引入了在推理时使用适配器的模型的一些符号。使用适配器在干净数据上训练时,我们称之为“干净模式”预测,而使用在扰动数据上训练的适配器时,我们称之为“鲁棒模式”。
3.4 使用适配器的训练可以实现对抗性MODEL SOUPS
首先我们来了解一下什么是MODEL SOUPS?
Model soups 是一种深度学习模型集成方法,由 Wortsman 等人在 2022 年提出。这个概念来自于厨房中的汤(soup),它通常由多种成分混合而成,每种成分都加入自己独特的风味,合在一起则产生了一个全新的味道。在深度学习中,model soups 指的是将多个不同的模型参数进行平均,创建一个新的模型,这个新模型结合了各个原始模型的特点。
在实践中,model soups 通常是通过以下方式构建的:
-
预训练模型:首先,有一个在大型数据集上预训练好的基础模型。
-
微调:然后,这个基础模型在不同的数据集或任务上进行微调,生成多个不同版本的模型。
-
权重平均:最后,这些微调过的模型的权重被平均,得到一个单一的模型。这个最终的模型能够从每个原始模型中获益,提高了泛化能力。
Model soups 的一个关键优势是,它在推理时不会增加额外的计算和存储成本,因为你只需要存储和运行一个模型,而不是原来的所有模型。这种方法已在实践中显示出能够提高性能,并且特别适用于那些参数空间巨大的深度学习模型。
在本文中,作者探讨了使用适配器训练模型是否能够启用对抗性模型汤。在对抗性模型汤的情况下,模型是在干净和对抗性样本上共同训练的,模型汤通过线性插值适配器的权重来合并干净和鲁棒模式的优势。
如何使用适配器的训练能够实现MODEL SOUPS?
在本论文中,作者探讨了适配器在对抗性训练中的使用,并提出了使用适配器能够实现所谓的“对抗性模型汤(adversarial model soups)”。适配器是特定于领域的模型参数,它们允许同一个主干网络架构(backbone architecture)在多个领域或任务中被重用,而只在某些参数上有所区分。这些区分的参数允许模型特别适应于特定的数据集——在这项工作中,即干净的图像数据和有对抗性扰动的图像数据。
具体来说,模型参数 θ \theta θ被分解为两部分:共享参数 ψ \psi ψ和特定于领域的参数 ϕ \phi ϕ。对于干净图像的训练,使用 ϕ c l e a n \phi_{clean} ϕclean参数;而对于对抗性图像的训练,使用 ϕ a d v \phi_{adv} ϕadv参数。这样,在推理时,可以根据需要使用针对干净数据训练的适配器 ϕ c l e a n \phi_{clean} ϕclean或针对对抗性数据训练的适配器 ϕ a d v \phi_{adv} ϕadv。
作者提出了使用适配器的训练能够实现模型汤,这是因为适配器训练方法本质上意味着大多数模型参数已经是共享的,所以模型汤可以通过对两种模式的适配器权重进行线性插值来创建。对抗性模型汤是指在干净和对抗性样本上共同训练的模型汤。
这可以通过以下参数化模型表达:
f
(
⋅
;
ψ
∪
(
β
ϕ
c
l
e
a
n
+
(
1
−
β
)
ϕ
a
d
v
)
)
f(\cdot; \psi \cup (\beta\phi_{clean} + (1 - \beta)\phi_{adv}))
f(⋅;ψ∪(βϕclean+(1−β)ϕadv))
其中, β \beta β是在平均适配器时的权重因子。当 β = 1 \beta = 1 β=1时,模型汤相当于仅使用干净图像训练的模型,而当 β \beta β接近0时,它更偏向于对抗性训练的模型。通过这种方式,可以创建一个既考虑到干净数据的性能,又能够处理对抗性攻击的新模型,无需在推理时决定使用哪种模式,从而简化了模型的使用并增强了其适应性。
4. 实验结果和分析
4.1 实验设置
在实验中,研究聚焦于Vision Transformer (VIT-B16) 的B16变体。采用了He等人(2022)提出的修改:线性分类器应用于最终标记的平均值,而不包括分类标记。网络从零开始进行监督训练。
在攻击策略方面,考虑了对抗 ℓ ∞ − b o u n d e d ℓ_{∞-bounded} ℓ∞−bounded未定向攻击,半径为ϵ = 4/255。这是对于ImageNet模型最常见的设置,比Xie & Yuille(2019)使用的定向威胁模型更具挑战性。为了生成对抗性扰动,训练时使用了名为PGD2的投影梯度下降方法,评估时使用了40步的PGD40。
实验评估聚焦于ImageNet数据集,并报告了整个验证集的干净和对抗性准确率。此外,还测试了通过几个ImageNet变种对分布偏移的鲁棒性。
4.2 实验结果
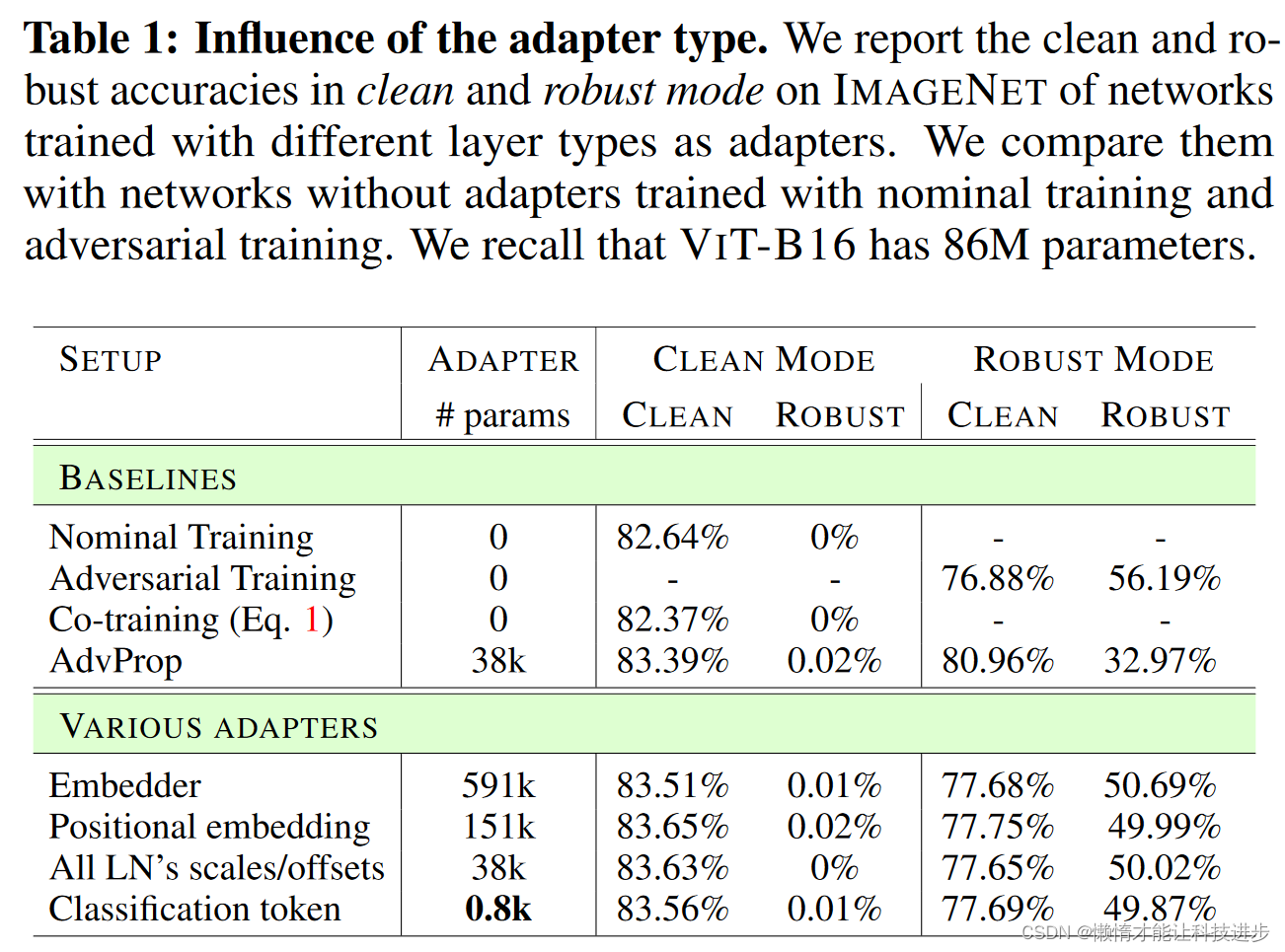
与3.2节中对RESNET-50的观察类似,完全共享的VIT-B16在使用联合训练损失Eq. 1训练时未能保持任何鲁棒性。因此,首先研究了VIT-B16的各种适配器,以找到高效的训练设置。
4.2.1 寻找高效设置
实践中的适配器:
在论文中提到使用两个分类标记作为适配器的实验设置,并不是说Transformer块会输出两个分类标记,而是指在模型中为两种不同类型的输入(干净图像和对抗性图像)分别引入了一个特定的分类标记。
这种设置允许模型针对每种类型的输入有特定的参数,使得在进行干净图像的分类预测时使用一组参数,在对抗性图像上进行分类预测时使用另一组参数。这样,模型可以更有效地学习并适应这两种不同的数据分布,从而提高模型在面对对抗性攻击时的鲁棒性。
在实践中,这可能意味着在模型的最后,有两个不同的头(或者说输出层),每个都连接到其对应的分类标记。在训练时,根据输入数据是干净图像还是经过对抗性扰动的图像,选择相应的头进行前向传播和反向传播。这种方法实质上是在模型内部实现了一种适配器机制,允许模型在保持整体结构不变的情况下,对不同类型的输入进行特化处理。
选择适配器时,需要考虑增加参数的数量。选择作为适配器的层将具有双倍的参数:一组用于干净图像,另一组用于对抗性图像。因此,为了避免过度增加网络的内存占用,限制了适配器研究仅包含参数较少的层,这意味着排除了自注意力层和MLP层。在剩下的选项中,分类标记的参数最少,远少于其他候选层(详见表1)。通过使用两个分类标记作为适配器(只增加了768个额外参数),在ImageNet上的干净准确率达到了83.56%,比标准训练提高了+0.92%。此外,在鲁棒模式下获得了49.87%的鲁棒准确率,接近使用对抗性训练得到的鲁棒准确率。显著的是,适应其他层,如所有LayerNorm的比例和偏移,结果在干净和鲁棒模式下表现相似,表明(i) 无需分离标准化层就可以复制AdvProp的效果,以及(ii) 即使是非常少量的双参数也足以使网络的共享部分适应两种模式。
代码示例
import torch
import torch.nn as nn
class SimpleViT(nn.Module):
def __init__(self, num_classes, hidden_dim):
super(SimpleViT, self).__init__()
# 假设有一个Transformer编码器
self.transformer = nn.TransformerEncoderLayer(d_model=hidden_dim, nhead=8)
# 两个不同的分类头
self.classifier_clean = nn.Linear(hidden_dim, num_classes)
self.classifier_adv = nn.Linear(hidden_dim, num_classes)
# 分类标记
self.cls_token_clean = nn.Parameter(torch.randn(1, 1, hidden_dim))
self.cls_token_adv = nn.Parameter(torch.randn(1, 1, hidden_dim))
def forward(self, x, is_adv=False):
# 假设x是[batch_size, seq_len, hidden_dim]的特征序列
# 添加CLS标记
cls_token = self.cls_token_adv if is_adv else self.cls_token_clean
x = torch.cat((cls_token.expand(x.shape[0], -1, -1), x), dim=1)
# 通过Transformer层
x = self.transformer(x)
# 取CLS标记的输出
cls_output = x[:, 0, :]
# 根据输入类型选择分类头
if is_adv:
return self.classifier_adv(cls_output)
else:
return self.classifier_clean(cls_output)
# 实例化模型
model = SimpleViT(num_classes=1000, hidden_dim=768)
# 假设输入特征
fake_input = torch.randn(32, 10, 768) # batch_size=32, seq_len=10
# 前向传播
clean_logits = model(fake_input, is_adv=False) # 对于干净图像
adv_logits = model(fake_input, is_adv=True) # 对于对抗性图像
以上只是一个简单的代码示例,辅助大家的理解。
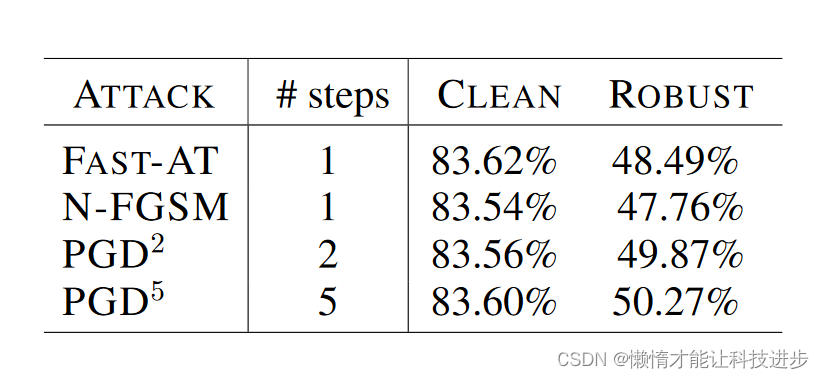
4.2.2 攻击步数的影响
由于表1中的结果是用PGD2获得的,因此检查是否可以减少攻击步骤以提高计算效率。在表2中,报告了两种一步方法(N-FGSM和FAST-AT)的结果。如果使用相应论文中推荐的步长,这两种方法都会遭受灾难性过拟合,因此根本没有鲁棒性。通过将步长减少到ϵ和0.75ϵ,避免了灾难性过拟合,但是这两种方法在鲁棒准确率上比PGD2低了1%以上。增加到5步的PGD5鲁棒准确率略有提高,干净准确率则相当。因此,PGD2似乎是效率和分类性能之间的一个良好折衷。
6. 总结和未来展望
总结
本研究提供了对适配器与对抗性训练结合使用的新见解,特别是在Vision Transformer (ViT) 模型中实现了显著的性能提升。实验结果显示,即使是非常少量的双参数适配器也足以适应干净和对抗性图像,这表明我们不必分离正则化层就能复制AdvProp的效果。通过使用两个分类标记作为适配器,增加了768个额外参数,实现了在ImageNet上83.56%的干净准确率,以及在鲁棒模式下49.87%的鲁棒准确率,这表明这种方法是在提升模型性能的同时增强其抵抗对抗性攻击的有效策略。
权重的共同训练损失
在共同训练损失中,α超参数控制着损失函数倾向于干净样本或对抗性样本的程度。例如,设置α = 0意味着模型完全在对抗性样本上进行训练。在评估α的几个值时,我们发现仅α在0到0.4之间的值构成了一个帕累托前沿,这严格优于其他区间。事实上,在α从1减少到0.4的过程中,模型在干净和鲁棒模式下的性能都得到了提升。
未来展望
这项工作为未来的研究指明了方向,提示我们在设计鲁棒的深度学习模型时可以考虑如下几点:
-
适配器的进一步优化:探索不同类型和配置的适配器,以进一步提高模型在处理各种扰动下的准确率。
-
损失函数权重的调整:实验不同的α值,找到最佳平衡点,以在保证模型对干净图像的高准确性的同时,提高对抗性攻击的鲁棒性。
-
模型汤的扩展应用:探索模型汤在其他架构和任务中的应用,以及它们在不同攻击下的性能。
-
鲁棒性与效率的平衡:研究如何在不牺牲推理效率的前提下,增强模型对对抗性攻击的防御能力。
-
分布偏移的鲁棒性:测试模型在面对真实世界数据时的表现,包括各种分布偏移和未见过的攻击类型。
随着对抗性攻击技术的不断发展,构建鲁棒的深度学习模型是一个持续的挑战。本研究的发现为深度学习社区提供了新的工具和思路,有望推动这一领域的进一步发展。未来,我们期待看到这些概念在更广泛的应用中得到实践和优化,为构建更安全、更智能的机器学习系统奠定基础。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











