







黑产—秒拨IP
前言
IP,作为互联网空间中最基础的身份标识,一直以来都是黑产与甲方争夺对抗最激烈的攻防点。
黑产技术迭代进化的速度令人咋舌,但是不少甲方却对黑产的研究和认知依旧停留在早些年的初级阶段。黑产发展迅速,而甲方对黑产的了解却停滞不前,必然造成在攻防过程中的信息不对成,防御难度加大,防守响应滞后,效率和效果大打折扣。
举个例子,对于黑产而言,”秒拨“早已不是一个新词,秒拨IP资源早已成为当下主流的黑产IP资源,可是,威胁猎人在与多个甲方客户沟通交流的过程中发现,很多在甲方做业务安全的同学对秒拨的概念一知半解,甚至完全不了解。
这个现象值得反思,秒拨在2014年前后已经是成熟的IP资源解决方案,到现在2019年,被广泛用于批量注册、投票、刷量等短时间内需要大量IP资源的风险场景,并且由于秒拨IP难以识别的特性,对当前互联网业务安全场景已造成巨大危害,但是很多安全行业的同学居然觉得这个东西很新鲜。
不论是在IP这个对抗点,还是在手机号、设备指纹、风险流量和行为等其他对抗点上,传统的【先被攻击】,然后【事后发现】,最后【补充规则】的被动式的对抗方式已经完全无法适应当前与黑产的攻防节奏,研究黑产、了解黑产、掌握黑产的最新技术和动向,才能把控更多主动权。
想打赢业务安全的战争,必须由”亡羊补牢“式的攻防形态向”未雨绸缪“式的攻防形态转型。
下文梳理了黑产IP资源的进化史,并着重阐述了威胁猎人对秒拨技术和资源相关研究。
秒拨的前世今生
自从甲方开始在IP层面根据一些简单的规则(如设定单位时间内IP的访问次数阈值、限制触发特定行为的IP等)做风控起,就正式向黑产在IP战场上宣战。
早期黑产主要是通过代理IP的方式绕过甲方的风控规则,售卖代理IP的网站便如雨后春笋般涌现。这些网站收集代理IP的方式主要利用高性能的服务器对全网进行扫描,扫描开放代理服务的服务器,或者是直接爬取其他代理网站的数据,收录有效代理IP和端口,以免费或者付费的形式交付给用户。此方式最大的弊端是代理IP的有效性和数量无法把控,代理网站无法把控,用户更无法把控,这就非常影响黑产做自动化攻击的效率。也有黑产利用VPN绕过甲方风控,VPN相对稳定,但是成本更高且有效IP数量有限,并不适用于黑产大规模批量化的攻击。
全网的代理IP数量相对有限,且早期代理服务一般都架设在数据中心的服务器上,不少甲方慢慢开始积累代理IP池,进一步打压了黑产使用代理IP的效果。
------------------------------------分割线--------------------------------------
不少做业务安全的同学对黑产IP资源的认知就停留在了此处。
------------------------------------分割线--------------------------------------
然而不甘心的黑产开始做资源升级,研发出秒拨的技术。
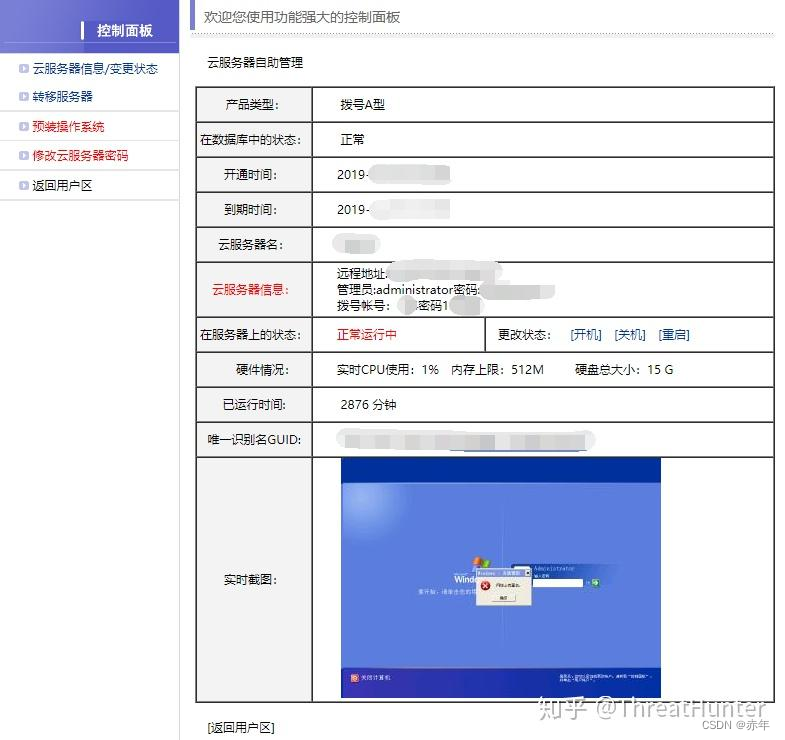
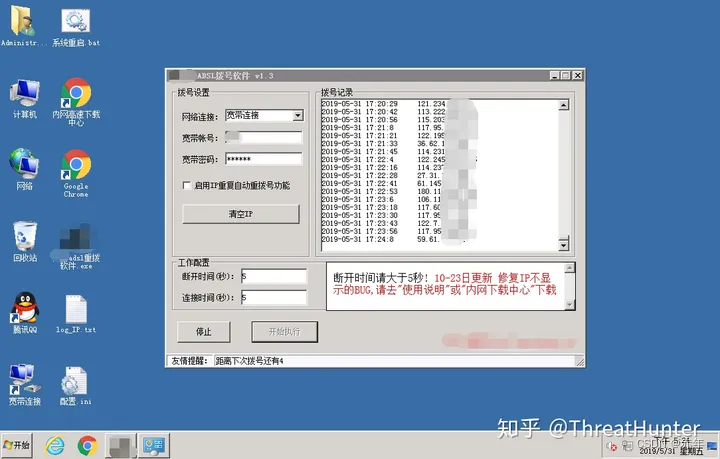
通俗的讲,秒拨的底层思路就是利用国内家用宽带拨号上网(PPPoE)的原理,每一次断线重连就会获取一个新的IP。与时俱进的黑产掌握大量宽带线路资源,利用虚拟化和云计算的技术整体打包成了云服务,并利用ROS(软路由)对虚拟主机以及宽带资源做统一调配和管理。这种云服务交付给黑产用户其实就是云主机(俗称”秒拨机“),黑产用户可安装Windows或Linux系统,通过RDP、VNC或者SSH连接,部署自动断线重连切换IP以及攻击的工具后,便可发起攻击。
秒拨机web管理页面截图:
秒拨机桌面以及某拨号软件截图(黑产用户可在秒级切换IP):
上文中提到了,秒拨的底层思路就是利用国内家用宽带拨号上网(PPPoE)的原理,每一次断线重连就会获取一个新的IP。这在与甲方的IP策略对抗层面,给予秒拨两个天然的优势:
IP池巨大:假设某秒波机上的宽带资源属于XX地区电信运营商,那么该秒拨机可拨到整个XX地区电信IP池中的IP,少则十万量级,多则百万量级;
秒拨IP难以识别:因为秒拨IP和正常用户IP取自同一个IP池,秒拨IP的使用周期(通常在秒级或分钟级)结束后,大概率会流转到正常用户手中,所以区分秒拨IP和正常用户IP难度很大。
这两个天然的优势也是秒拨是当前黑产主流IP资源的核心原因。
一台秒拨机上发现大量注册机以及其他黑产工具和资源:
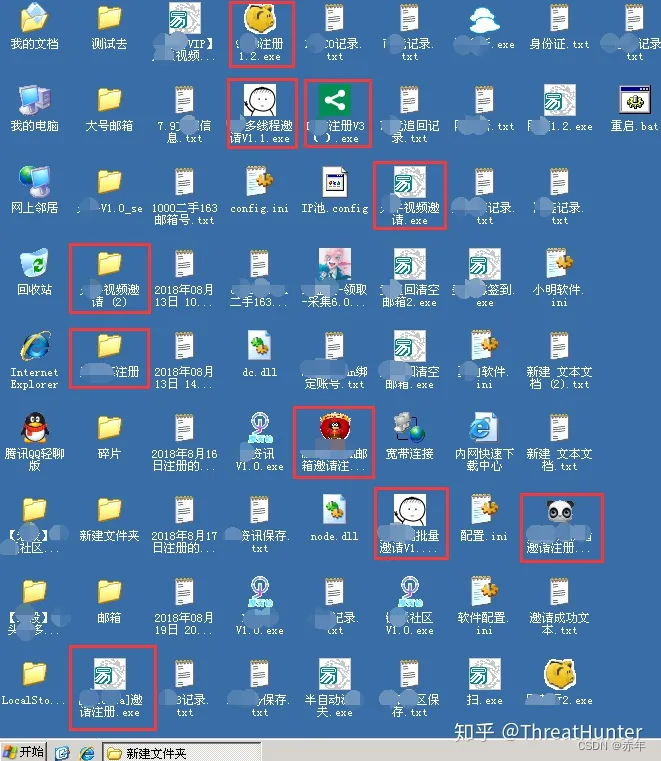
此外,黑产对秒拨还做了升级,称为”混拨“,即黑产把多个省市地区的秒拨资源打通,实现在单台秒拨机上就可以拨到全国上百个地区的IP资源。一台混拨机,成本低至48元/月。
我们对市面上提供秒拨机的主流平台做了统计,其提供的秒拨IP可覆盖全国所有约300个城市。
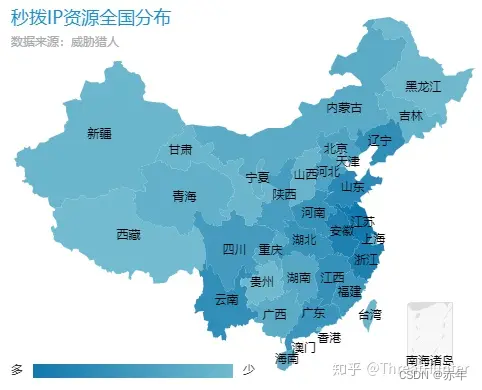
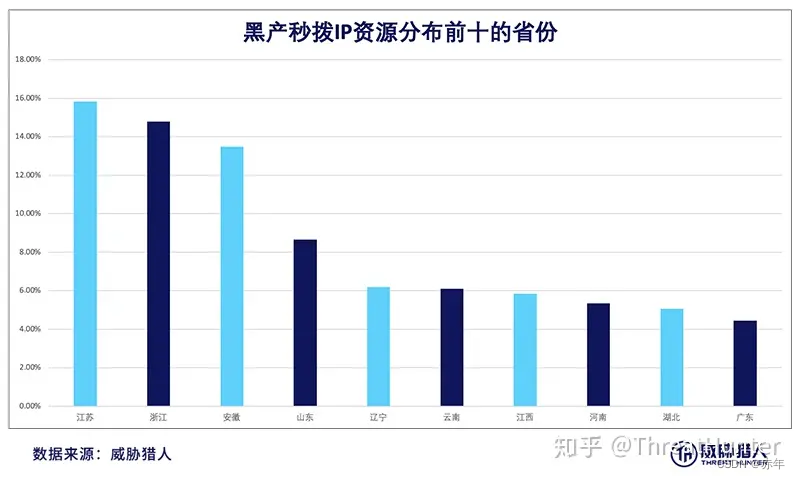
黑产秒拨IP资源分布前十的省份为:
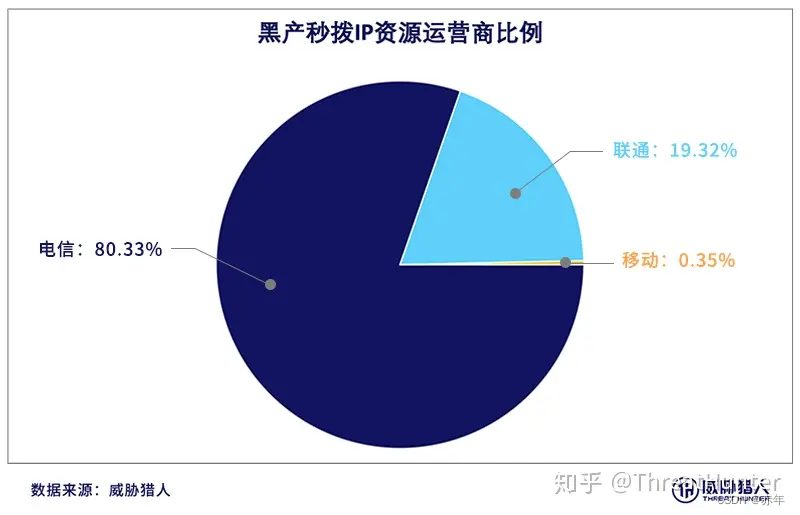
另外,黑产秒拨IP资源运营商比例分别为:
黑产还在不断扩大覆盖其秒拨IP资源的地域覆盖范围,甚至部分平台也可以提供美国、韩国。香港等非大陆IP资源。
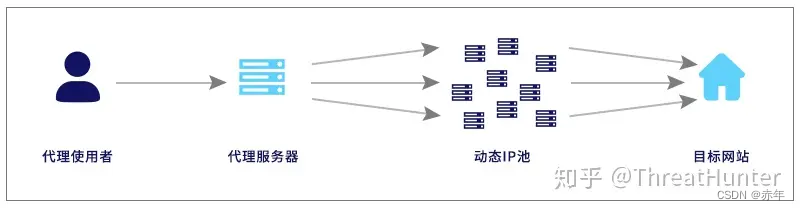
另外,前文中提到过,早期黑产收集代理IP的方式是全网扫描,可用性无法保证。其实黑产早已把秒拨的技术应用于代理IP,黑产利用秒拨技术积蓄代理IP池,再提供给下游黑产用户,并且此类代理IP继承了秒拨IP的优势,一是IP池巨大,二是难以识别。秒拨型代理IP常见的实现方式是动态转发,如下图所示:
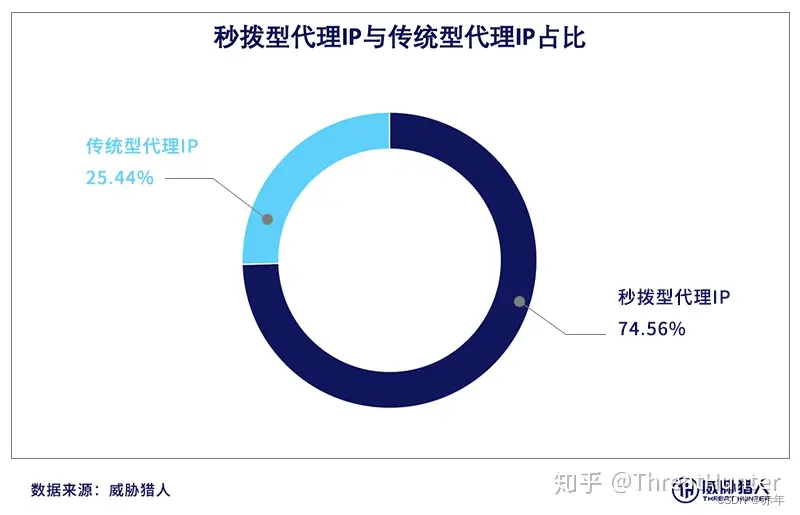
根据我们的情报监测平台监测到的数据显示,当前黑产使用的代理IP资源中,秒拨型代理IP占74.56%,传统型代理IP仅占25.44%。甲方如果还想以积累IP池的传统方式与黑产对抗,必然会引入大量误报。
此外,使用代理平台提供的Windows/Android/iOS客户端,通过PPTP/LT2P等VPN协议,可把黑产终端直接变成“秒拨机”,大大提高了黑产作恶的便捷性。
写在最后
总之,秒拨已然成为支撑黑产与甲方在IP层面攻防的核心技术,也是当下业务安全行业的痛点之一。文中提到秒拨的两个天然优势,对于黑产而言,是两道天然的屏障,但是给甲方在风险IP识别和判定上带来极大的难度。
当前形势下与黑产在IP层面上的对抗,依靠传统地积累IP威胁情报库的方式,根本无法直接应用和落地到业务侧,典型的使用效果是,对黑IP的检出率很高,对正常用户IP的误判率也很高。
所以,识别风险IP的核心依据应该是,该IP是否当下被黑产持有,IP的黑产使用周期和时间有效性这两个指标尤为重要,尤其是对于像家庭宽带IP、数据中心主机IP这种“非共享型”的IP。针对基站、专用出口等“共享型”的IP,由于单个IP背后会有大量用户,风控阈值应该相对更宽松,但是如果能准确识别IP是否当下被黑产使用,也能提供很重要的参考价值。
威胁猎人长期致力于黑产IP资源的研究,旨在帮助甲方解决业务安全场景下风险IP的识别问题,并于近日实现突破,通过对黑产ROS秒拨节点的布控,可实时监控和收集黑产当下使用的秒拨IP。

















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









