







从上一篇博文我们知道,哈希表是一种以关联方式存储数据的数据结构。 在哈希表中,数据以数组格式存储,其中每个数据值都有其自己的唯一索引值。 如果我们知道所需数据的索引,则数据访问将变得非常快。
因此,它成为一种数据结构,其中插入和搜索操作非常快,而与数据的大小无关。 哈希表使用数组作为存储介质,并使用哈希技术生成要在其中插入元素或从中定位元素的索引。
hash表实例
散列是一种将键值范围转换为数组索引范围的技术。 我们将使用模运算符来获取一系列键值。 考虑一个大小为20的哈希表的示例,以下各项将被存储。 项目采用(键,值)格式。

那么我们用%20来确定具体的映射,结果如下表:
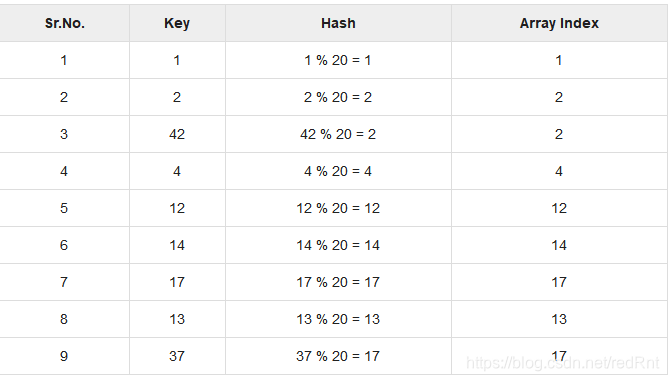
从表中我们可以看出,这样的hash表在第二行与第三行,和第七行与第九行之间中发生了碰撞(Collisions)。
在这种情况下,我们可以通过查看下一个单元格直到找到一个空单元格存放发生冲突的数据。 这种技术称为线性探测。使用线性探测后,得出的正确的hash表应该是这样的:
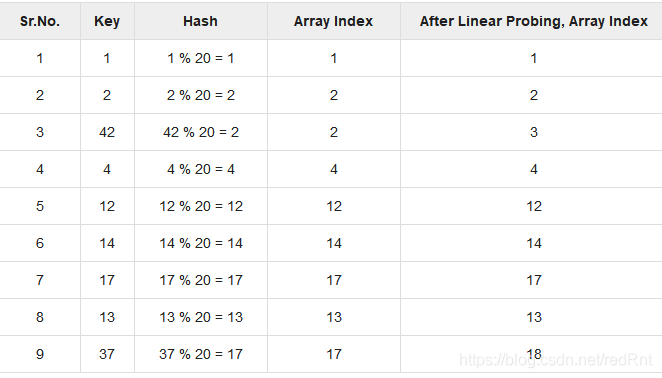
Hash表的基本操作
hash表的基本操作有:
- 查找
- 插入
- 删除
一般的,我们定义数据类型是一个(键,值)这样的数据对。
struct DataItem {
int data;
int key;
};
然后用定义一个hash函数来计算其hash编码:
int hashCode(int key){
return key % SIZE;
}
搜索操作
每当要搜索元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位元素。 如果在计算的哈希码中找不到元素,那么就使用线性探测使该搜索继续进行。
下面的这个函数,定位到需要找到的节点,然后返回指向这节点的指针。
struct DataItem *search(int key) {
//计算hash编码
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] != NULL) { //当计算的下标未未越界时
if(hashArray[hashIndex]->key == key)
return hashArray[hashIndex];
//继续往下走
++hashIndex;
//覆盖整个hash表
hashIndex %= SIZE;
}
return NULL; //不存在
}
插入操作
每当要插入元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来定位索引。 如果在计算出的哈希码中发现已经存在元素了,则使用线性探测寻找空位置。
void insert(int key,int data) {
//这里采用的是C语言的malloc,相当于C++中的new
struct DataItem *item = (struct DataItem*) malloc(sizeof(struct DataItem));
item->data = data;
item->key = key;
//get the hash
int hashIndex = hashCode(key);
//如果在计算出的哈希码中发现已经存在元素了,则使用线性探测寻找空位置
while(hashArray[hashIndex] != NULL && hashArray[hashIndex]->key != -1) {
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
hashArray[hashIndex] = item;
}
删除
每当要删除元素时,都要计算传递的键的哈希码,并使用该哈希码作为数组中的索引来找到该hash节点。 如果在计算的哈希码中找不到元素,那么使用线性探测寻找该元素。 找到后,在其中存储一个虚拟项目以保持哈希表的性能不变。
struct DataItem* delete(struct DataItem* item) {
int key = item->key;
//get the hash
int hashIndex = hashCode(key);
//move in array until an empty
while(hashArray[hashIndex] !=NULL) {
if(hashArray[hashIndex]->key == key) {
struct DataItem* temp = hashArray[hashIndex];
//assign a dummy item at deleted position
hashArray[hashIndex] = dummyItem;
return temp;
}
//go to next cell
++hashIndex;
//wrap around the table
hashIndex %= SIZE;
}
return NULL;
}
C与C++本身有着极强的联系,所以这段代码改成C++代码完全是没有问题的,暂时就不改动了。
碰撞处理
在少数情况下,多个键映射到相同的整数,则具有不同键的元素可以存储在哈希表的相同“槽”中。 显然,当使用散列函数查找潜在匹配项时,有必要将该元素的关键字与搜索关键字进行比较。 但是可能有多个元素应该存储在表的单个插槽中。 使用各种技术来解决此问题:
- 使用链接
一种简单的方案是将所有冲突链接到附加到适当插槽的列表中。 这允许处理无限数量的冲突,并且不需要先验知识即可知道集合中包含多少个元素。 需要权衡的是:在空间上(较小程度上在时间上)链表开销。 - 溢出区
另一种方案是将预分配的表分为两部分:主区域和冲突区域。键第一次映射到的区域称为主区域。冲突区域,通常称为溢出区域。
发生冲突时,溢出区域中的插槽将用于存放产生冲突的新元素,并像链式系统中那样建立来自主插槽的链接。这基本上与链接相同,除了溢出区域是预先分配的,因此访问起来可能更快。与重新哈希一样,必须预先知道最大元素数量,但是在这种情况下,必须估算两个参数:主要区域和溢出区域的最佳大小。
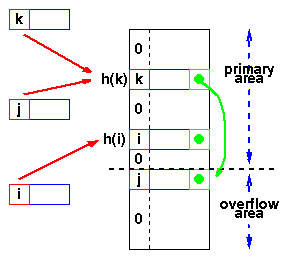
上图就表明了键值J发生一次冲突后被存放在溢出区。
当然,可以设计具有多个溢出表或具有用于处理溢出区域之外的溢出的机制的系统,这些系统可以提供灵活性而不会丢失溢出方案的优点。 - 重新hash
发生冲突时,Re-Hash方案使用调用第二个哈希操作。 如果还有进一步的冲突,我们将继续调用哈希操作,直到在表中找到一个空的位置。重新哈希函数可以是新函数,也可以是原始函数的重新应用。 只要将功能以相同顺序应用于某个键,就可以始终定位所需的键。具体过程可以看图:
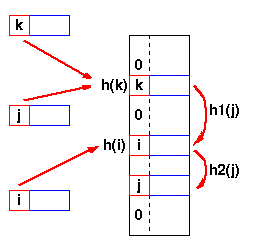
图中,第一次调用H(j)的时候,得出应该在k出存放数据,但是现在k处已经有值了(即发生冲突)于是使用下一个hash函数h1.得出应该放在位置i,但是现在位置 i 已经有了数据,因此使用下一个hash函数h2,发现找到了空的位置,于是把数据放进去。 - 线性探测
已介绍 - 二次探测
通常,通过二次探测可以获得更好的查询行为,其中二次哈希函数取决于重新利用下面的方式计算哈希索引:
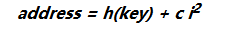
在第 T t h T^{th} Tth次重新哈希的时候。 (也可以使用i的更复杂的函数。)由于通过主哈希函数映射到相同值的键遵循相同的地址序列,因此二次探测也会产生聚集。但是,二次探测产生的聚集不如线性探针所示的严重。 - 随机探测
略














 2274
2274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









