







最近想到以前的一个面试题,是关于从某个网站采集表格,然后用pandas处理成指定的格式,当时看了完全是不知如何着手,现在用了一些时间,终于把这题给解决了,虽然耗时不少,还是挺有成就感的。下面就分享下个人的处理方式:
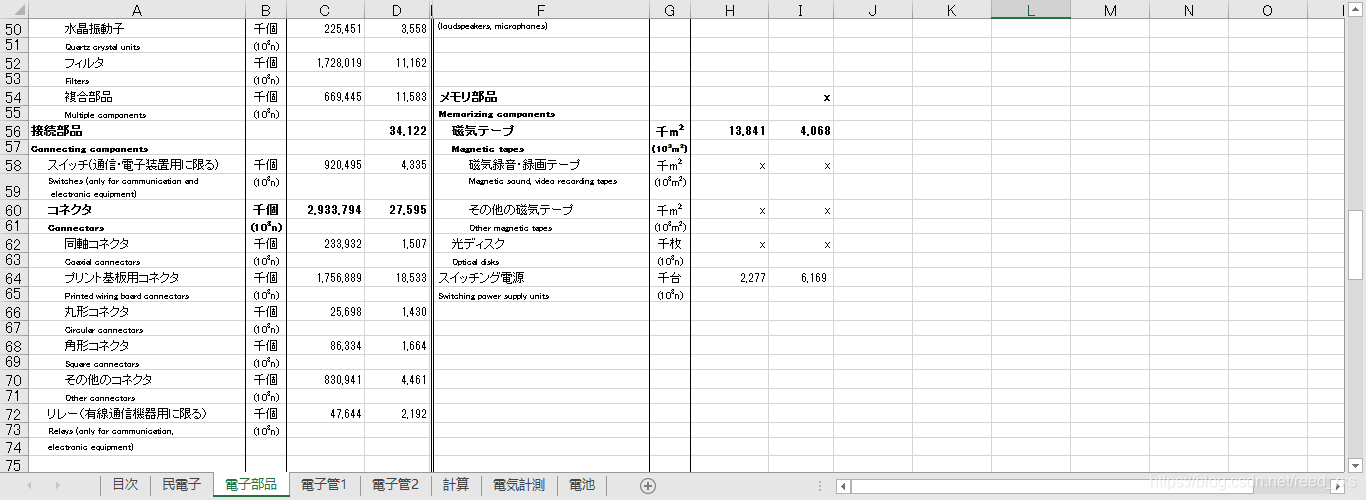
采集的表格样式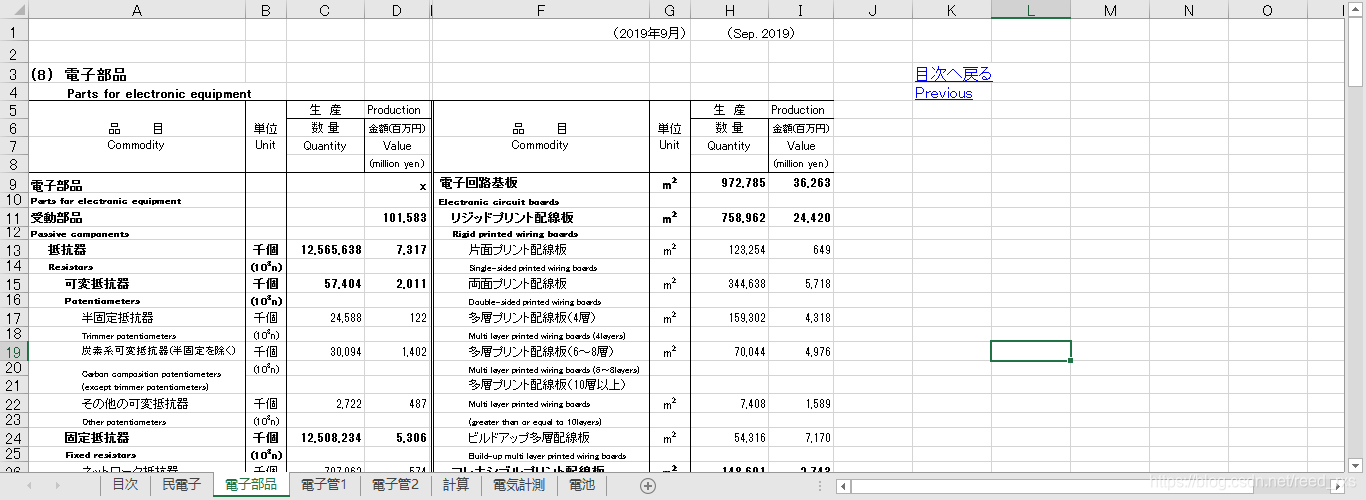
对方要求处理后的样式

爬取下载表格的方式这里就不做赘述了,毕竟这部分代码大同小异,着重分享下处理表格的代码:
# 先导入需要的包
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import random
import numpy as np
import re
import calendar
import datetime
import os
os.chdir(r'D:\CDA\File')
# 考虑带有数字的行对应英文的描述,故做个英文判断
def is_english(keyword): # 判断是否为全英文,是返回True
return all(ord(c) < 128 for c in keyword)
def add_str(data_,n): # 当数字行对应英文描述时,不确定向上找几行才是日文名称,故用个向上查找方式进行
h=''
for e in data_.iloc[n-1::-1,0]:
if is_english(e[:3]):
h=e+h
else:
h=e+':'+h
break
return h
def item(data,k): # 对有数据的行进行名称是否为英文的判断,一般都是先日文,再英文描述。把一种产品的日文、英文捆在一起,中间用:隔开
a=[]
for j in data.iloc[k:,0]:
if type(j)==str:
if not is_english(j[:3]):
b=j+':'
a.append(b)
if len(a)>1:
del b
break
else:
try:
b
except:
b=add_str(data,k)
a.append(b)
b=b+j
else:
b=b+j
z=b.replace(' ','').replace('\n','')
return z
def isfloat(x): # 判断产品日文、英文描述的几行是否有数据,有则返回True,最终可被执行处理
if pd.isna(x):
return False
try:
float(x)
except:
return False
else:
return True
def get_all_lines(row_df): # 先将品目(含日文、英文描述,生成单位)及数值清洗为标准格式
all_line=[]
for i,row in row_df.iterrows():
if isfloat(row[3]): # 金额
line=':'.join([item(row_df,i),'生産(P):金額(百万円):(millionyen)']),row[3]
all_line.append(line)
if isfloat(row[2]): # 数量
quantity = row_df.iloc[i+1,1]
quantity = quantity if pd.notnull(quantity) else f'({row[1]})'
if re.search('千.+',row[1]) == None: # 对方要求的格式中涉及到数量单位都要求化大至千,而有些产品单位需要进行转换
quantity='(10³'+f'{row[1]})'
row[1]='千'+row[1]
row[2]=int(row[2]/pow(10,3))
line=':'.join([item(row_df,i),'生産(P)',f'数量({row[1]})',
f'Quantity{quantity}']),row[2]
all_line.append(line)
return all_line
def last_day(date): # 得到对方要求格式中的日期,表格中获取
year=date.year
month=date.month
x,y = calendar.monthrange(year,month) # 得到当年当月第一天所处的星期数,及最后一天
final_date=datetime.date(year=year,month=month,day=y)
return final_date
# 下载文件,通过爬虫代码下载的表格
file_name=data_file()
# 解析文件
df=pd.read_excel(file_name,sheet_name='電子部品',header=None)
df1=df.iloc[:,:4] # 获取第一段产品数据
df1.columns=['品目','单位','数量','金额']
df2=df.iloc[:,5:9] # 获取第二段产品数据
df2.columns=['品目','单位','数量','金额']
df_=pd.concat([df1,df2],ignore_index=True) # 两端拼凑为一段
df_.dropna(how='all',inplace=True) # 去除全为空的记录
df_.reset_index(drop=True,inplace= True) # 原表格上重置索引
all_lines=get_all_lines(df_) # 执行前面的函数,将品目及数值处理成标准格式
row_date = df.iloc[0,5]
use_date = last_day(row_date) # 执行前面函数,处理日期
result_df=pd.DataFrame(all_lines,columns=["品目","值"])
result_df["时间"]=use_date
result_df=result_df.reindex(columns=["品目", "时间", "值"]) # 整理成最终版本,及对方需要的格式
save_name = 'doc'+os.path.sep+"电子部品整理后_" + file_name.split('\\')[-1]
result_df.to_excel(save_name,index=False) # 存为标准格式文件


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









