







倒排索引
为了完成对文本的快速搜索,ES使用了一种称为“倒排索引”的数据结构。
倒排索引中的所有词语存储在词典中,每个词语又指向包含它的文档信息列表。
倒排:
“金都” -> doc_1 ,doc_2
“嘉怡” -> doc_1
“假日” -> doc_1
“酒店”-> doc_1 ,doc_2
即: 词项=>包含当前词项的doc_id的列表的映射。倒排索引的优势是可以快速查找包含某个词项的文档有哪些。例如:可以快速找到 含有 “金都”的文档
正排:
doc_1 -> “金都”,“嘉怡”,“假日”, “酒店”
doc_2 -> “金都”,“酒店”
即: doc_id=>当前文档包含的所有词项的映射。正排索引的优势在于可以快速的查找某个文档里包含哪些词项。例如:可以轻松从doc_1 中 找到 “金都”,“嘉怡”,“假日”, “酒店” 这些词语
ES 在文本索引的建立和搜索过程中依赖两大组件,lucene 和 分析器。
lucene 负责进行倒排索引的物理构建
分析器负责在建立倒排索引前和搜索前 对 文本进行分词和语法处理。
分析器
分析器是ES 构建倒排索引的核心组件。
其负责在建立倒排索引前和搜索前 对 文本进行分词和语法处理
分析器 由 字符过滤器,分词器,和分词过滤器 三部分组成,
其中规定:分词器有且只有一个,字符过滤器和分词过滤器 可以有0或多个
三部分的数据流向为:字符过滤器 ->分词器 -> 分词过滤器
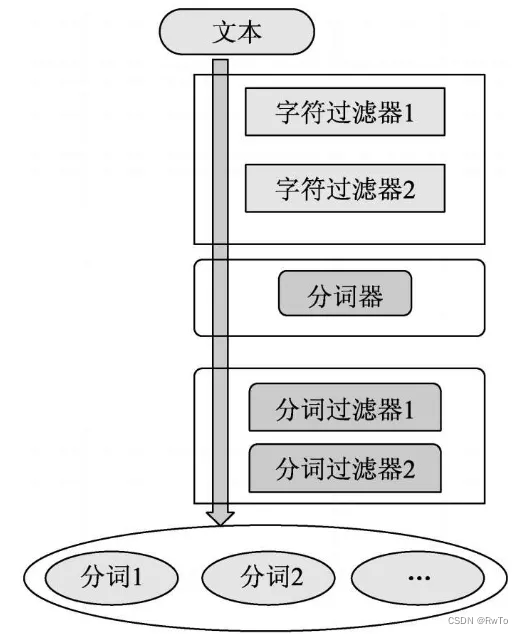
对于不同的分析器,上述三部分的工作内容是不同的,为了正确匹配,如果在数据写入时指定了某个分析器,那么在匹配查询时也需要设定相同的分析器对查询语句进行分析。
通过 不同 过滤器和分词器的设置,可以实现分析器的多样化。
字符过滤器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-charfilters.html
字符过滤器是处理文本数据的第一道关卡。
其处理文本的基本单位是字符。
它接收字符流,并对原始字符流中的字符进行添加,删除或者转化。
ES 内置了一些字符过滤器

分词器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-tokenizers.html
分词器是分析器中最重要的一环,有且只能指定一个
其处理的是整个字符串文本
分词器负责接收 字符过滤器 处理过的字符流,将字符串按照某种规则切分成词语
ES 默认使用标准分词器,对于英文按照标点符号,空格进行切分,对于中文按照单字拆分
ES 内置了一些分词器

分词过滤器
官网:https://www.elastic.co/guide/en/elasticsearch/reference/7.10/analysis-tokenfilters.html
分词过滤器是分析器的最后一道关卡
其处理的基本单位是经过分词器切分后的词语
其可以将切分好的词语进行价格和修改,对分词结果进一步规范化。例如:删除一些停用词(这,那,的),也可以为某个分词增加同义词
ES 内置了一些分词过滤器

倒排索引建立过程
假设需要对下面的文档建立倒排索引
文档001,“金都嘉怡假日酒店”
文档002,“金都欣欣酒店”
(案例来源于《Elasticsearch搜索引擎构建入门与实战》)
ES 首先将文档内容 交给分析器 处理,经过分析器(字符过滤器,分词器,和分词过滤器)的处理。最终将得到一系列关键词的组合,如下:
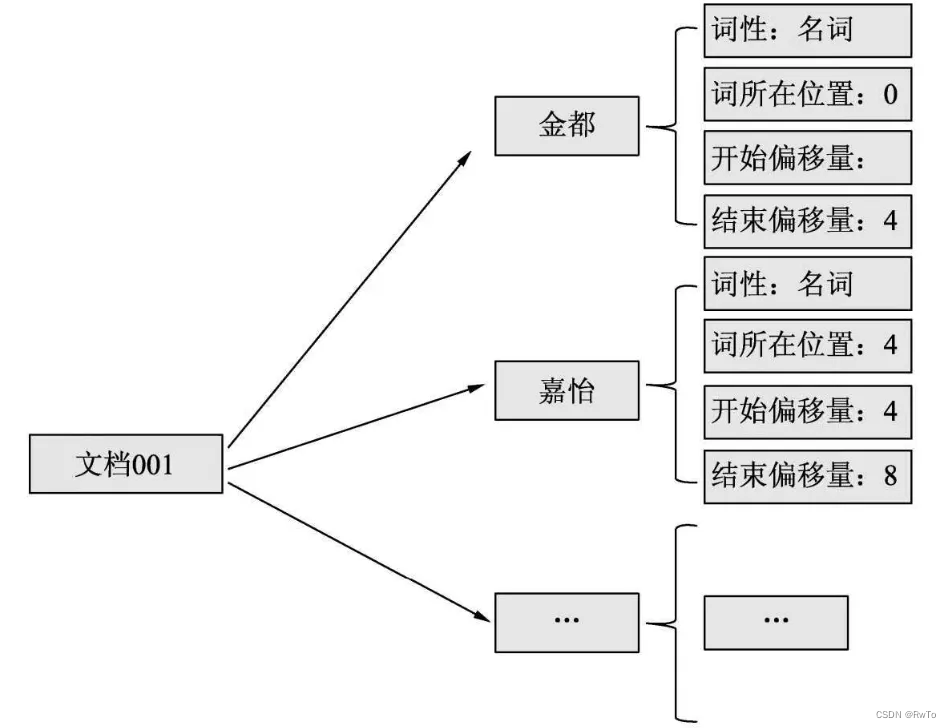 根据上述关键词信息,ES会生成 词语——文档矩阵,用来表示词语在文档中是否存在
根据上述关键词信息,ES会生成 词语——文档矩阵,用来表示词语在文档中是否存在
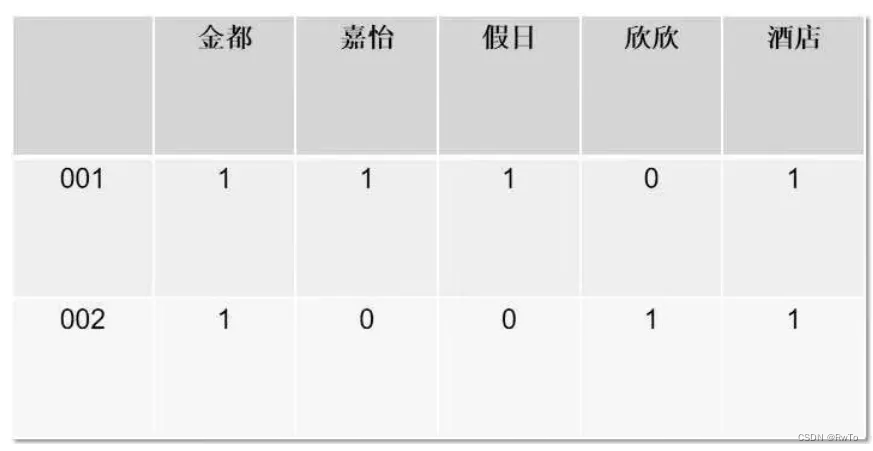
之后,ES会遍历文档中的所有词语。然后建立词语与文档信息的映射关系。
其中
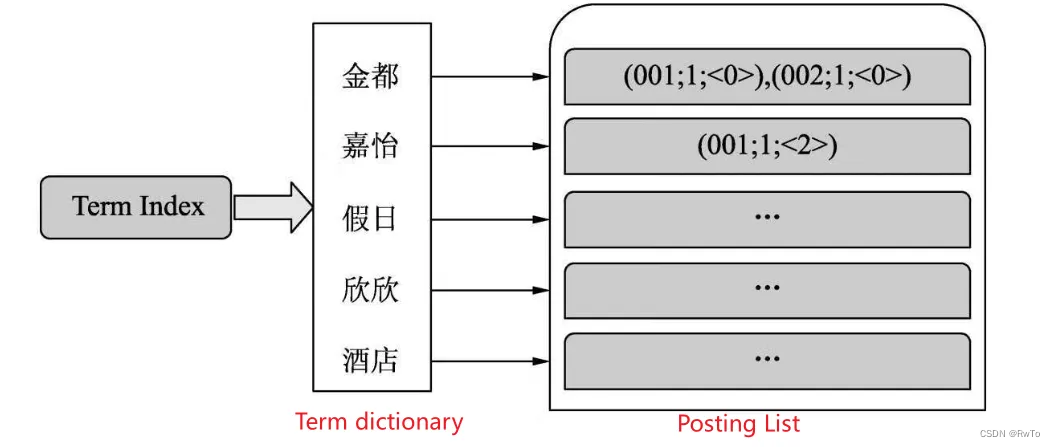
词语集合 被称为 Term dictionary(词典)
文档信息 被称为 Posting List
对于一个规模很大的文档集合,可能包含几十上百万的词语集合,为了快速定位某个词语。ES 使用一种特殊的数据结构,来快速定义一个词语。被称为 Term Index,其本质是一个 Tire Tree (词典树)
Term Index ,Term dictionary ,Posting List 三者 组成ES的倒排索引。三者关系如图
文本搜索过程
在ES中,一般使用match查询对文本字段进行搜索。match查询过程一般分为如下几步:
- ES将查询的字符串传入对应的分析器中,分析器的主要作用是对查询文本进行分词,并把分词后的每个词语变换为对应的底层lucene term查询。
- ES用term查询在倒排索引中查找每个term,然后获取一组包含该term的文档集合。
- ES根据文本相关度对每个文档进行打分计算,打分完毕后,ES把文档按照相关性进行倒序排序。
- ES根据得分高低返回匹配的文档
例如:match查询 “金都嘉怡” 的过程如下
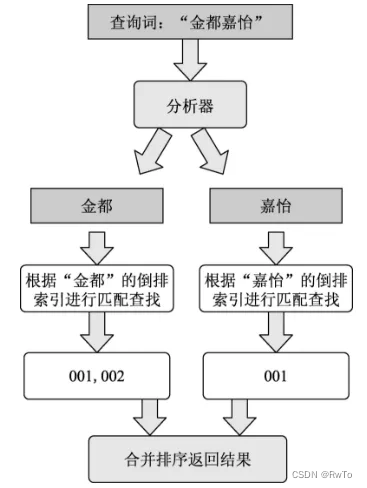
ES 经过 分析器(字符过滤器,分词器,分词过滤器)将 ”金都嘉怡“ 拆分成 “金都”,“嘉怡”
针对分词结构分别执行 term查询,
找到 含有 “金都” 的文档有 001, 002 ,含有“嘉怡”的文档有 001
结果合并计算相关性,很明显001 更符合要求,001的相关性较大,返回的顺序为 001,002
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











